GPU-powered in-memory databases and analytics platforms are the logical successors to CPU in-memory systems, largely due to recent increases in the onboard memory available on GPUs. With sufficient memory, GPUs possess numerous advantages over CPUs, including much greater compute and memory bandwidth, as well as a native graphics pipeline for visualization.
In this tutorial, Aaron Williams, VP of Community at MapD, will demo how MapD is able to leverage multiple GPUs per server to extract orders-of-magnitude performance increases over CPU-based systems, bringing interactive querying and visualization to multi-billion (with a ‘b’) row datasets.
{kind=link}
{kind=link}
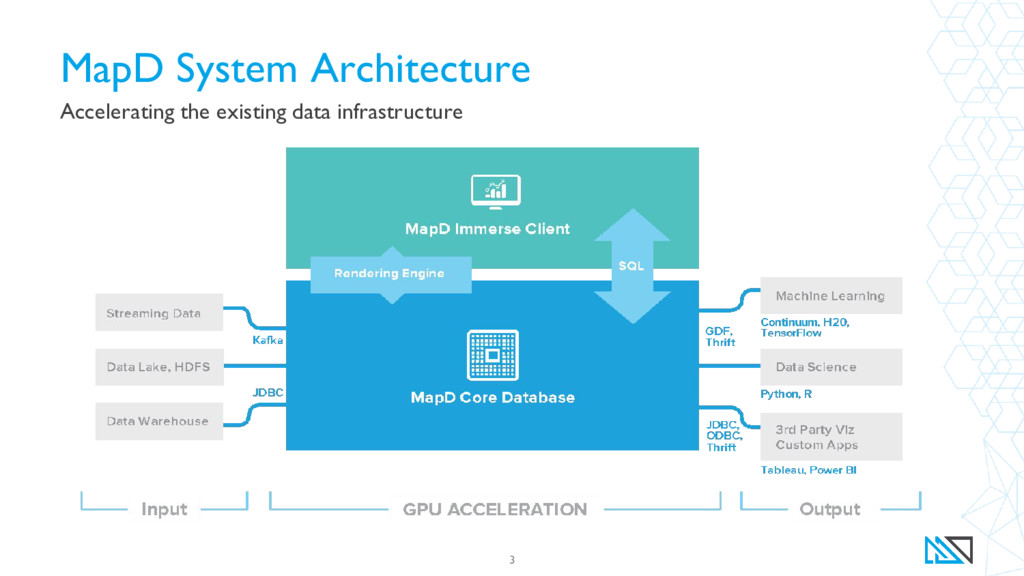{kind=link}
{kind=link}
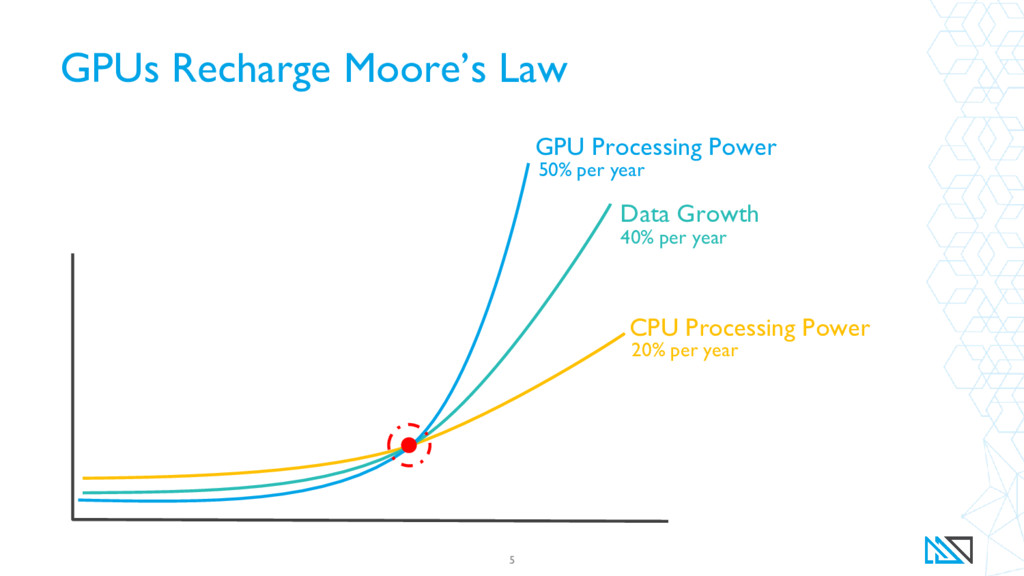{kind=link}
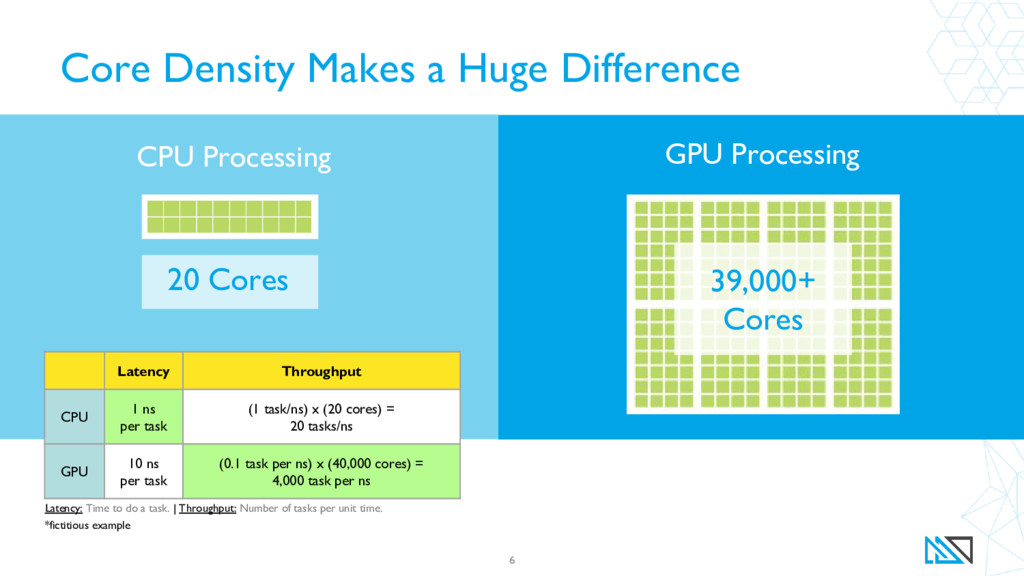{kind=link}
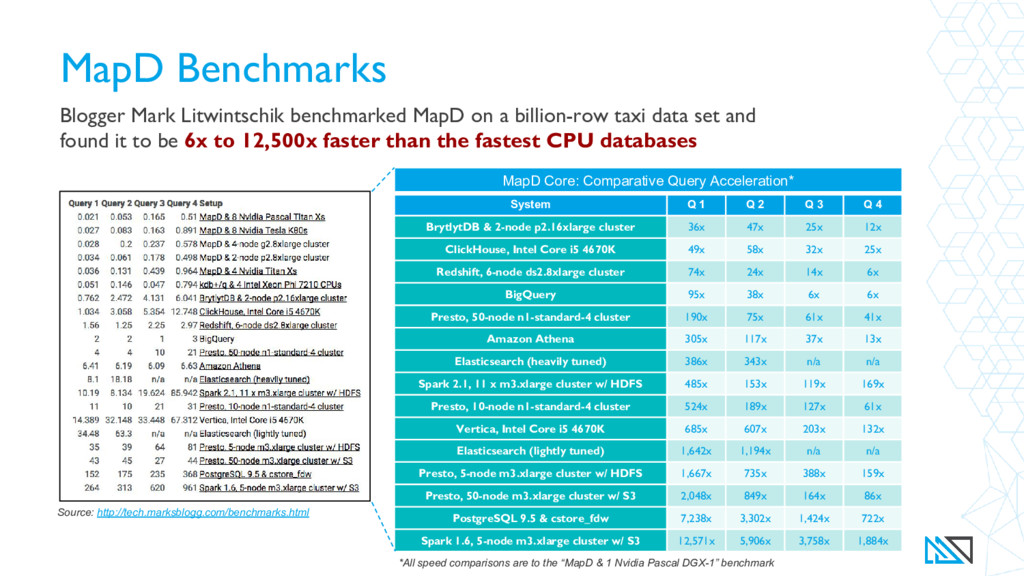{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Aaron Williams VP of Global Community @_arw_ [email protected] /in/aaronwilliams/ /williamsaaron](https://files.speakerdeck.com/presentations/a325633ba52c497d8859fd0af8a5cc85/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}