(1991); Babuška, Tempone, and Zouraris (2004); Babuška, Nobile, and Tempone (2007), Nobile, Tempone, and Webster (2008); Doostan and Iaccarino (2009); Doostan, Validi, and Iaccarino (2013); Doostan and Owhadi (2011); Gunzburger, Webster, and Zhang (2014); Chen, Gittelson, Jakeman, and Xiu (2015) Cohen, DeVore, and Schwab (2010, 2011); Chkifa, Cohen, and Schwab (2014); Cohen and DeVore (2015) Prud’homme, Rovas, Veroy, Machiels, Maday, Patera, Turinici (2002); Barrault, Maday, Nguyen, and Patera (2004); Rozza, Huynh, and Patera (2007); Haasdonk and Ohlberger (2008) Graham, Kuo, Nuyens, Scheichl, and Sloan (2012); Kuo and Nuyens (2016); Parametric PDEs: Sparse or Low-Rank Approximations? Bachmayr, Cohen, and Dahmen (arXiv, 2017)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
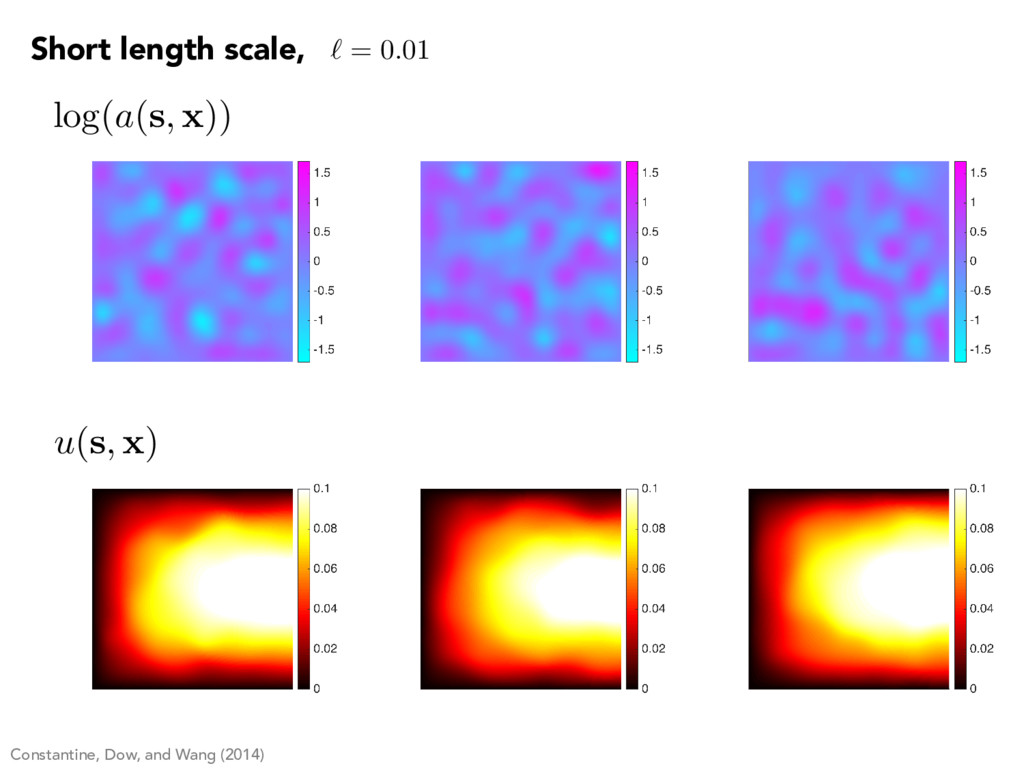{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
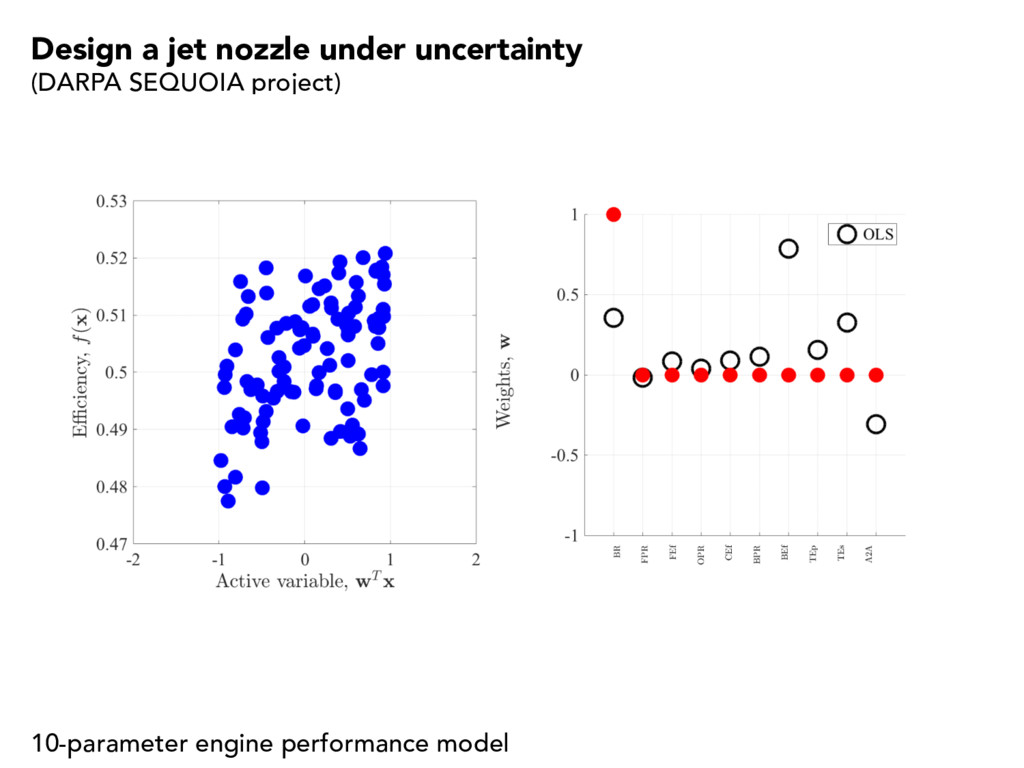{kind=link}
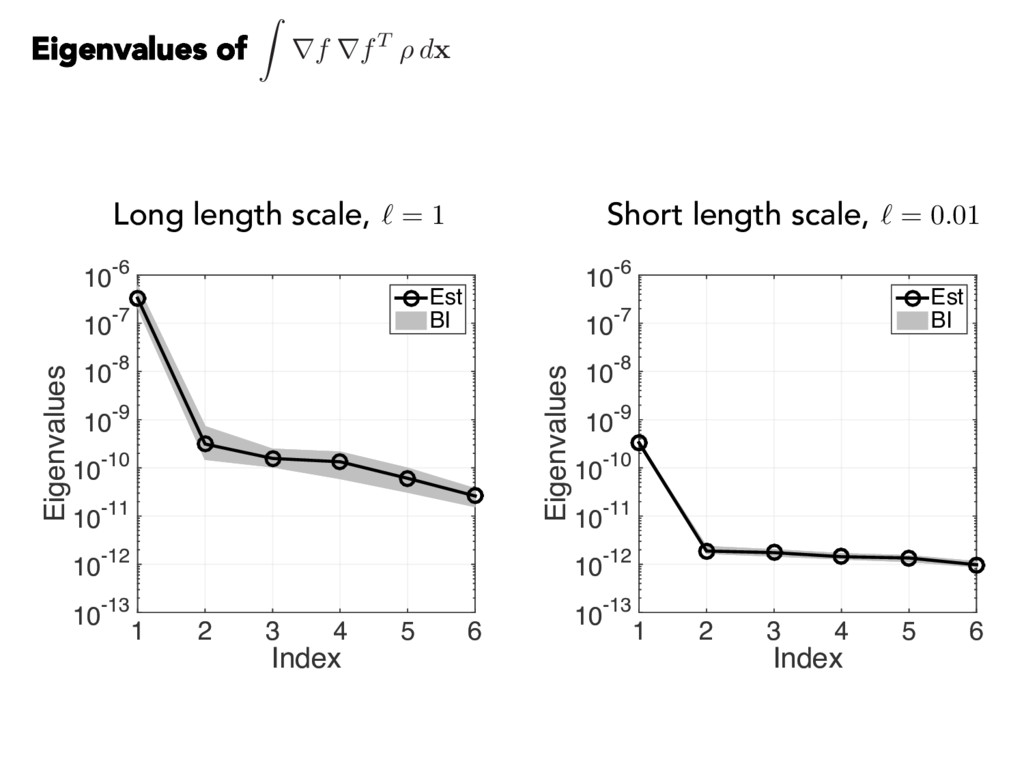{kind=link}
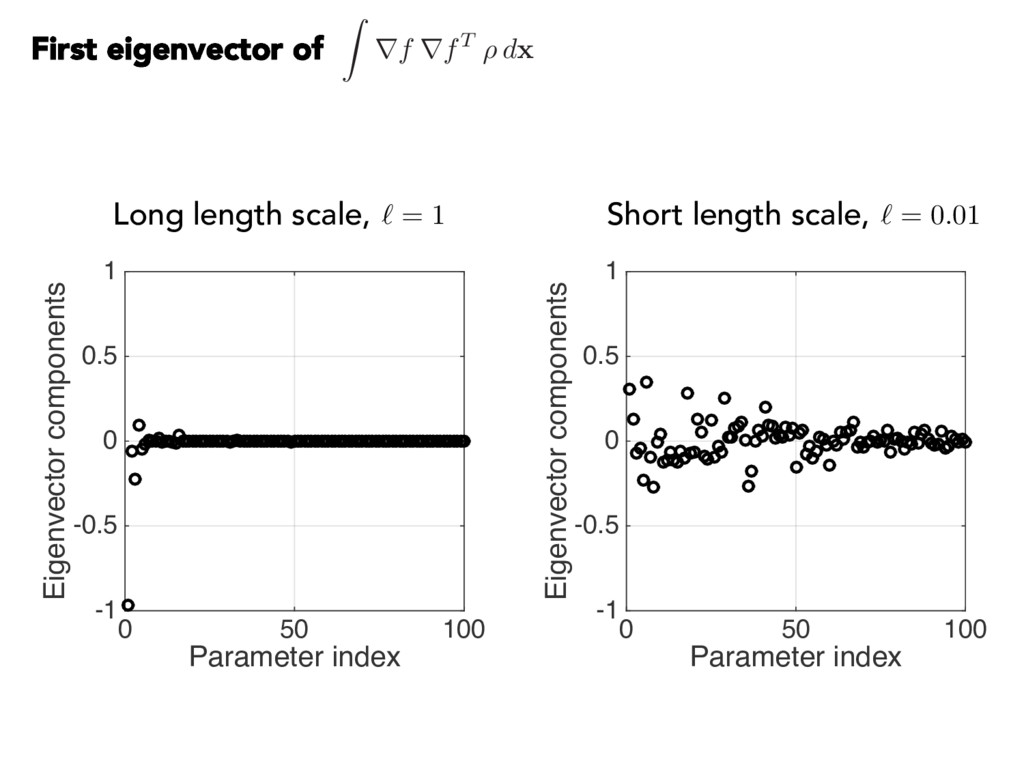{kind=link}
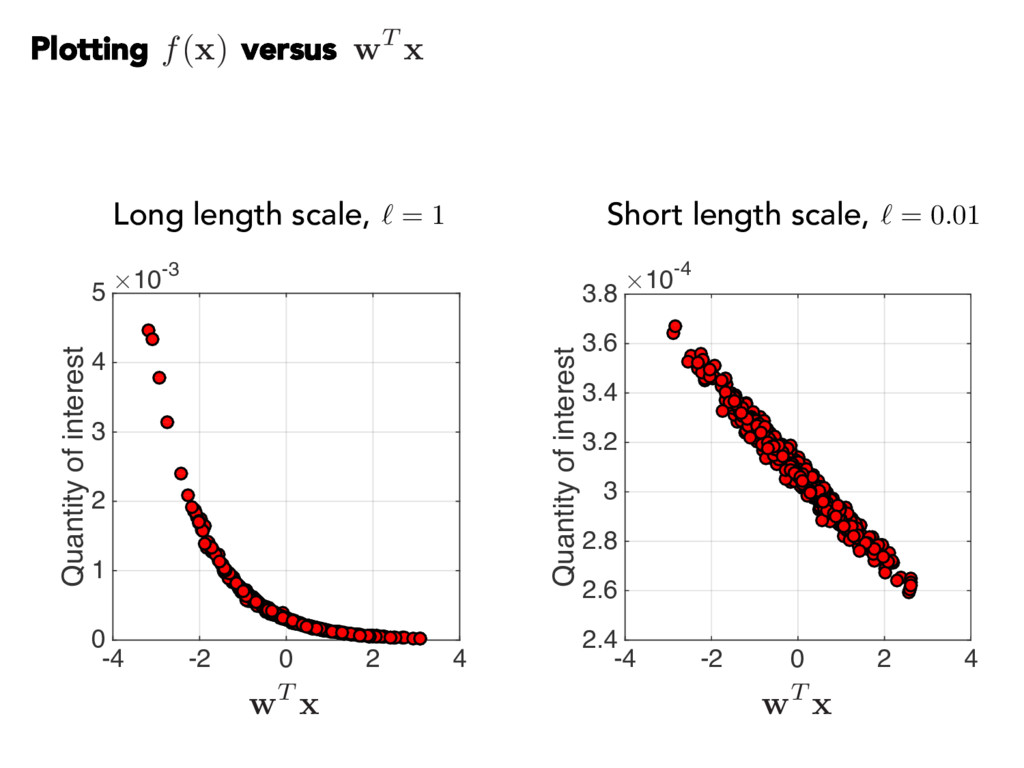{kind=link}
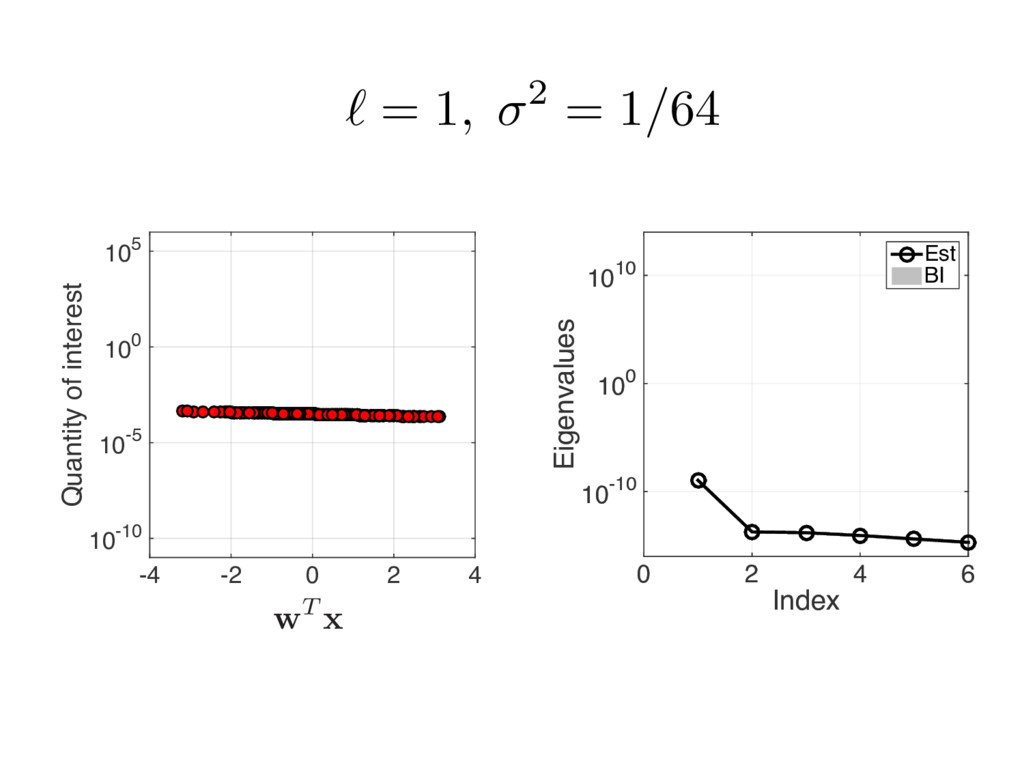{kind=link}
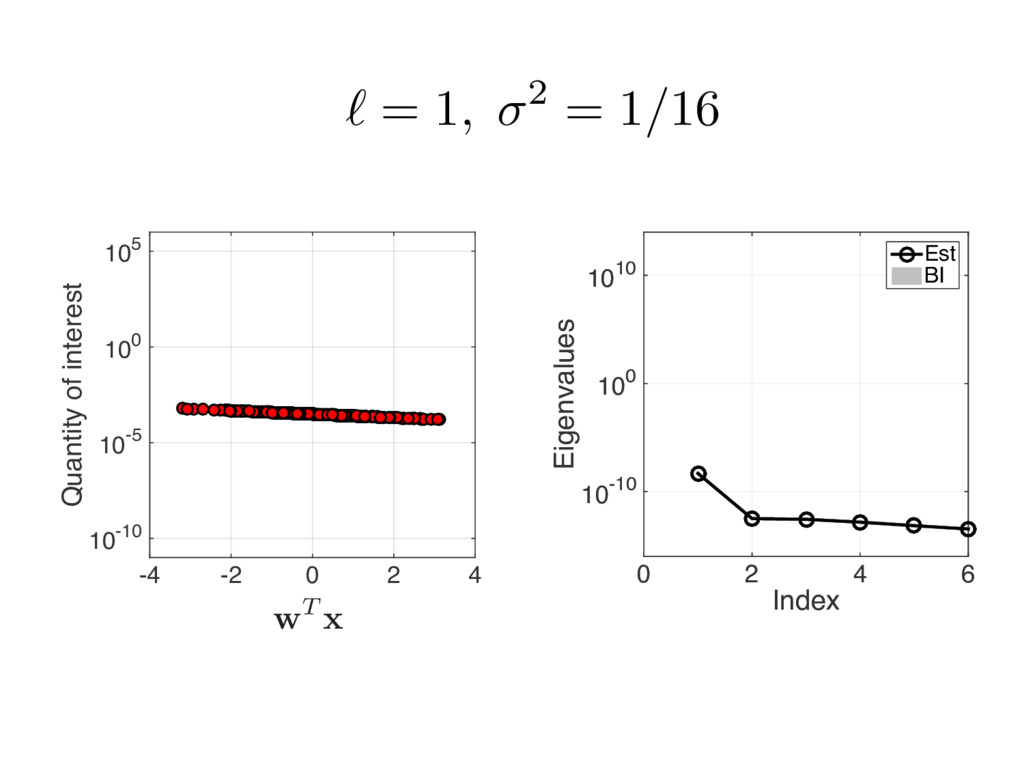{kind=link}
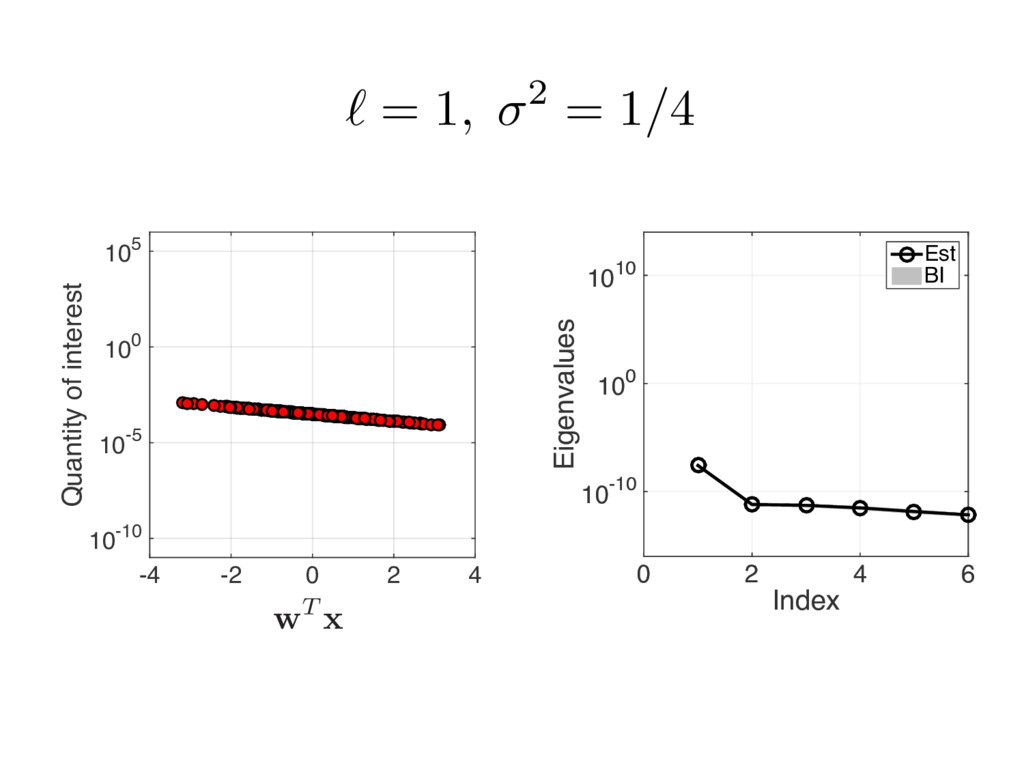{kind=link}
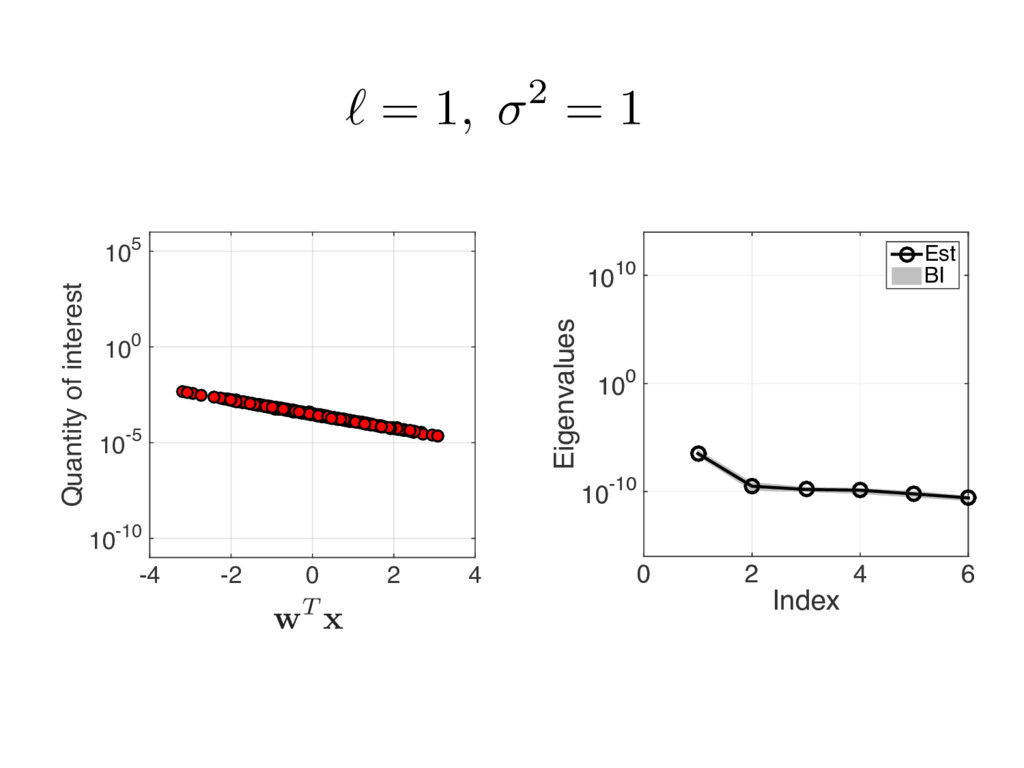{kind=link}
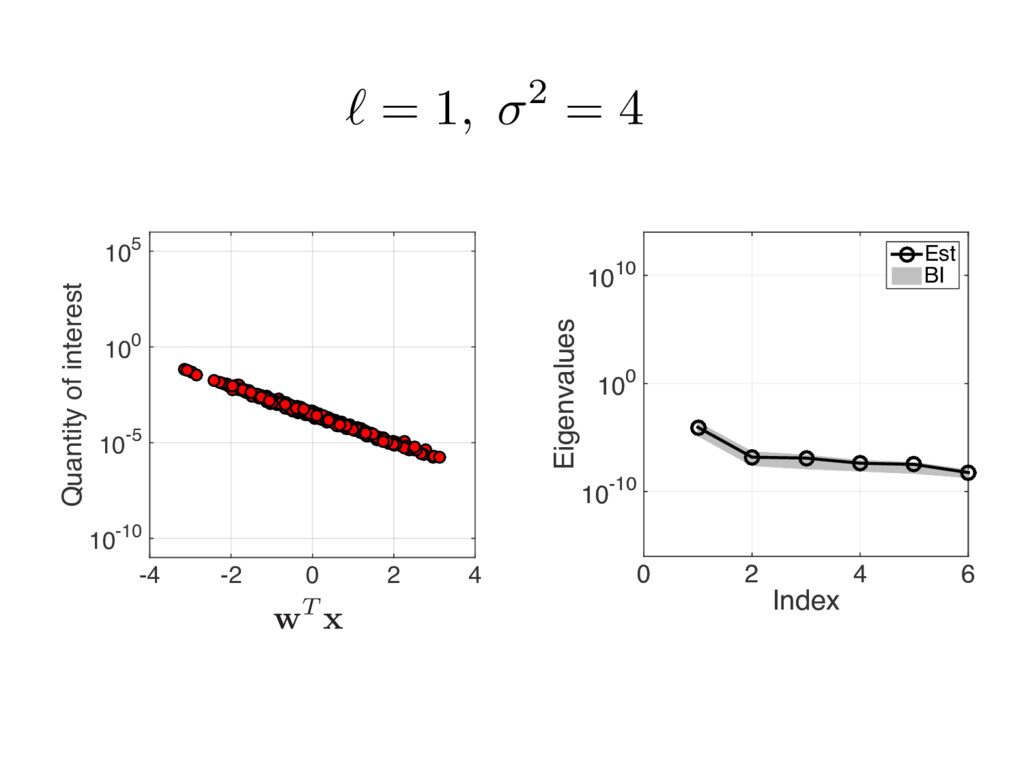{kind=link}
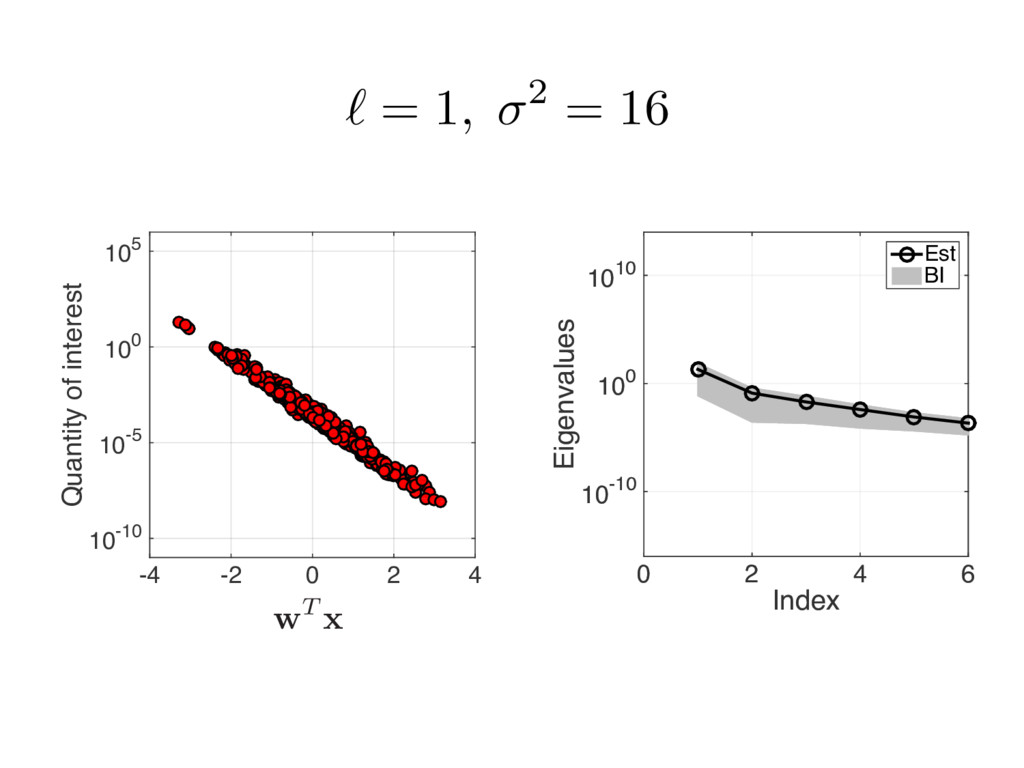{kind=link}
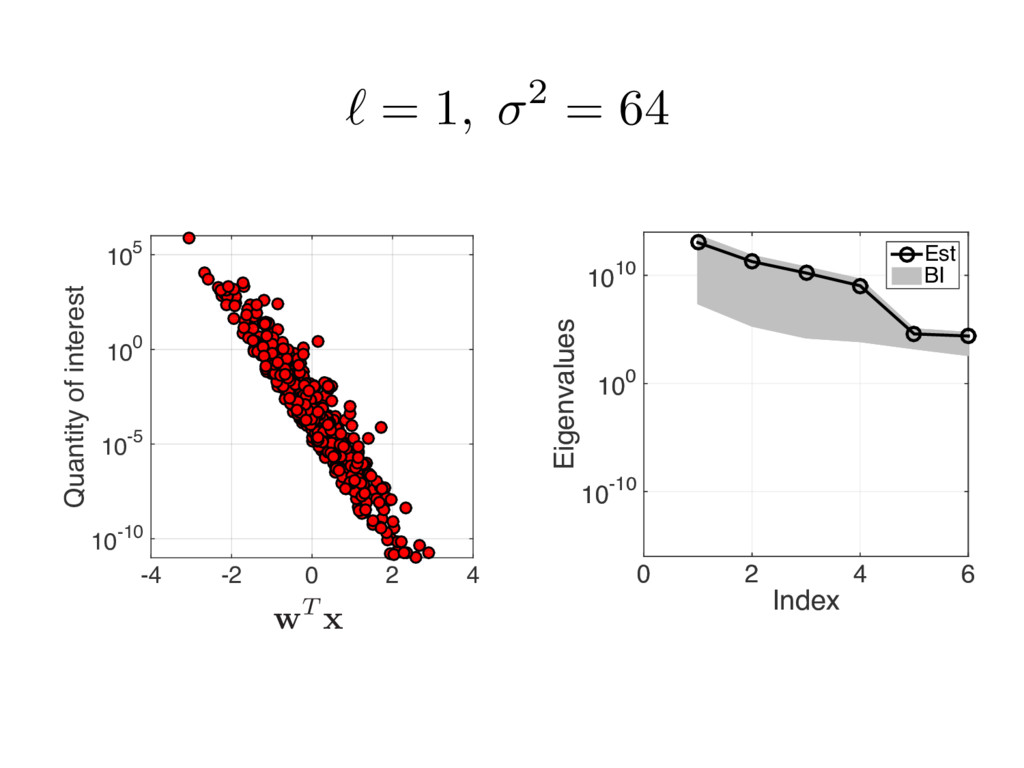{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}