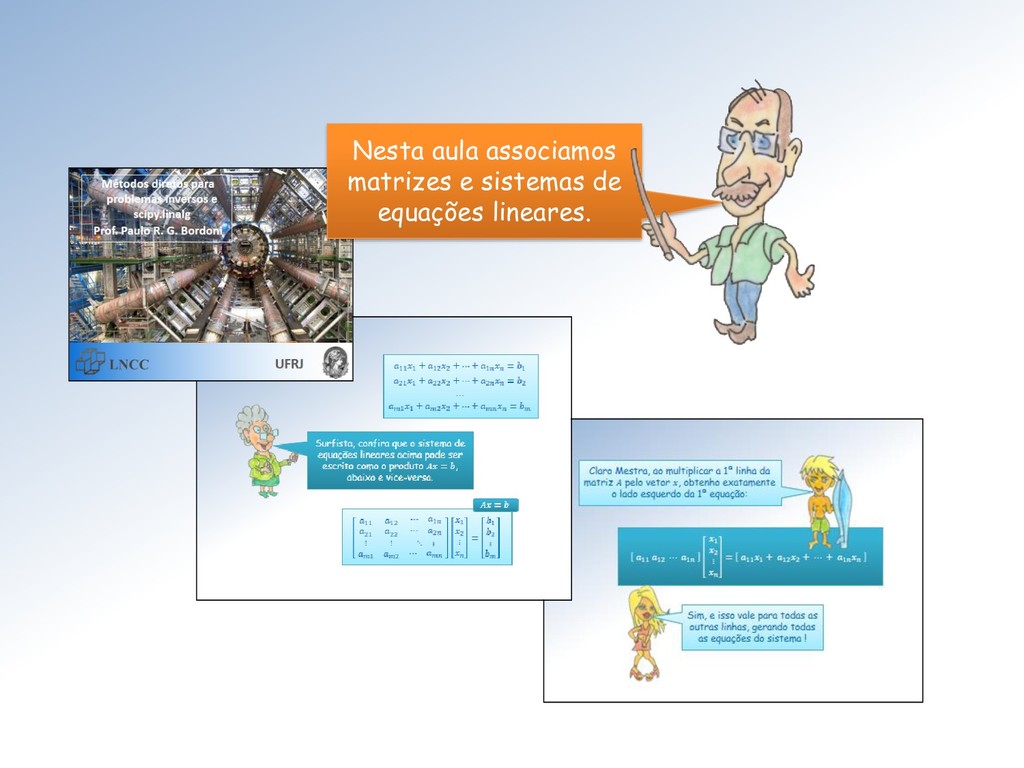
incógnitas” é o problema inverso descrito matricialmente por: “Obter um vetor ∈ ℝ tal que = , sendo dado ∈ ℝ.” Já o problema direto associado a uma matriz de tamanho × é: “Dado ∈ ℝ, obter o vetor ∈ ℝ para o qual = .”
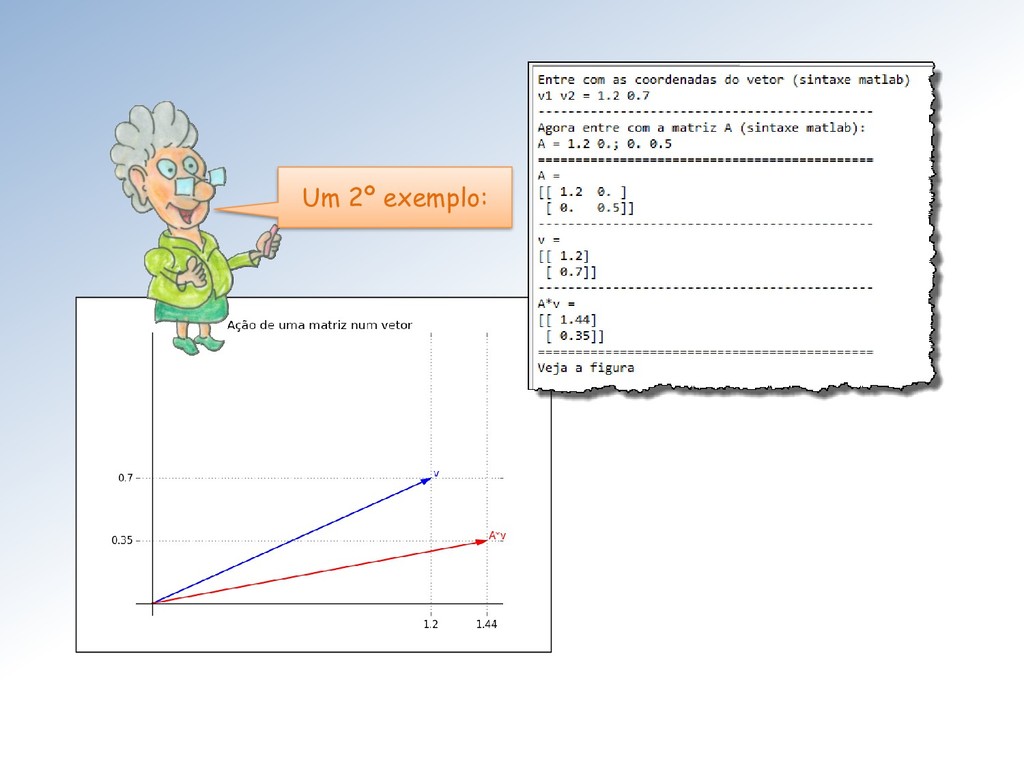
caso (usando a mesma letra, num abuso usual de notação), à função : ℝ ⟶ ℝ ⟼ = . Sim, e na NumPy, o valor é calculado através produto interno = np. dot (, ) de com o vetor .
ℝ associada à matriz através da multiplicação define uma transformação linear de ℝ em ℝ. Transformações lineares constituem uma classe muito ampla de funções definidas entre espaços vetoriais.
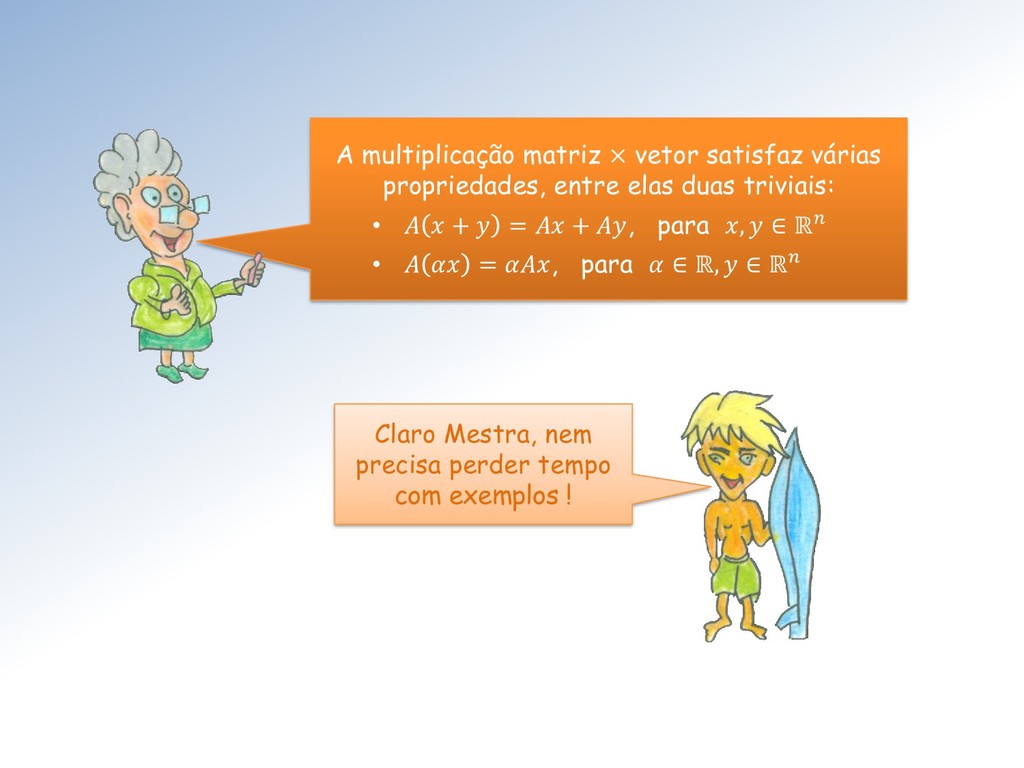
é uma função ∶ → satisfazendo as duas propriedades: • + = + , ∀, ∈ , • = , ∀ ∈ ℝ , ∀ ∈ . A definição abaixo é tão importante que merece ser colocada numa moldura de ouro !
vocês a um passo gigantesco em abstração. Adiantando as coisas: Outros dois exemplos de transfor- mações lineares são a integral e a derivada, que operam entre espaços de funções (aula futura).
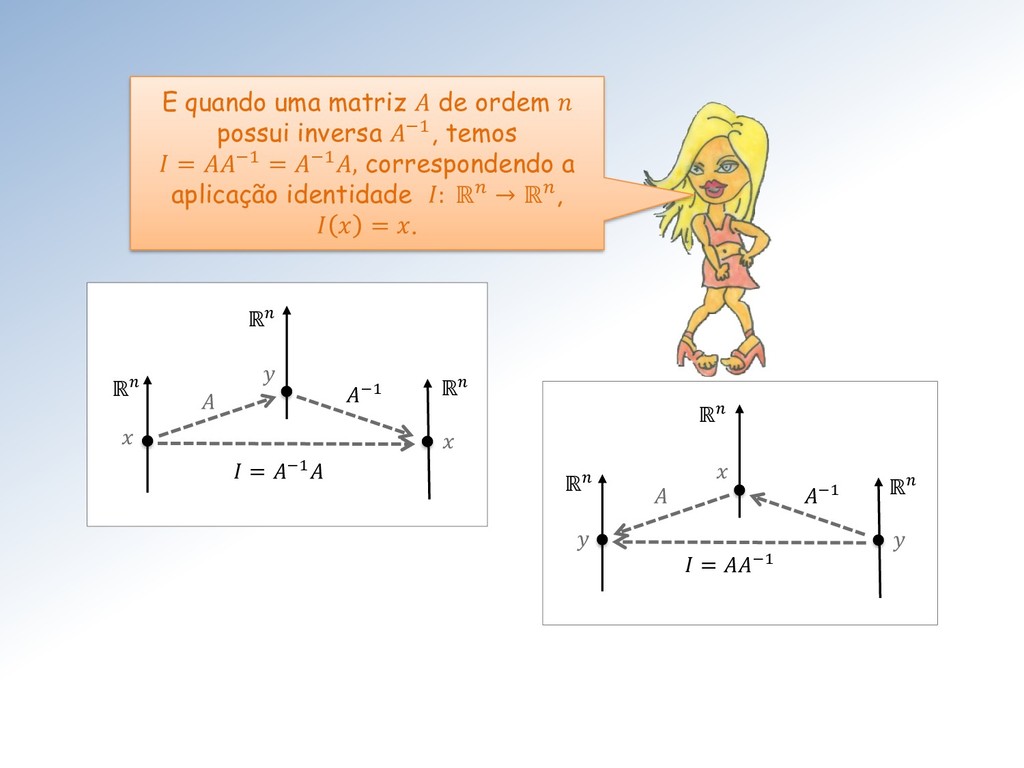
A de uma matriz B por uma matriz A corresponde à aplicação linear composta ∘ de A seguida por B. Sim, para todo ∈ ℝ temos ∘ = = e portanto ∘ = . Mais um bom motivo para dispensar os parênteses em ().
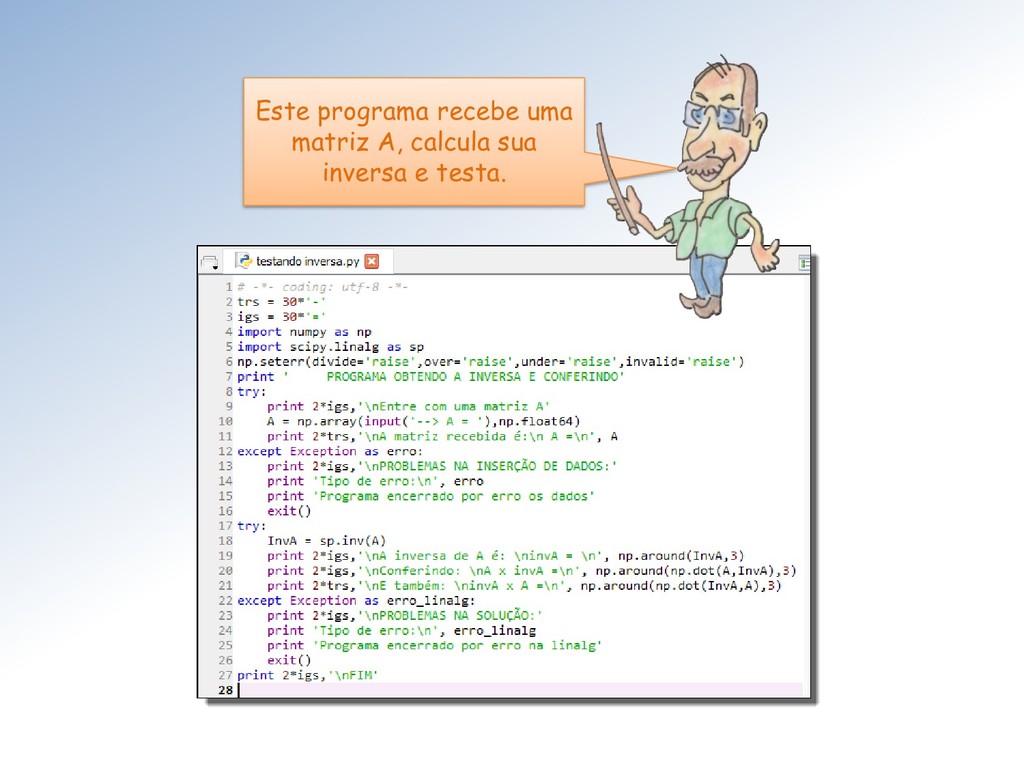
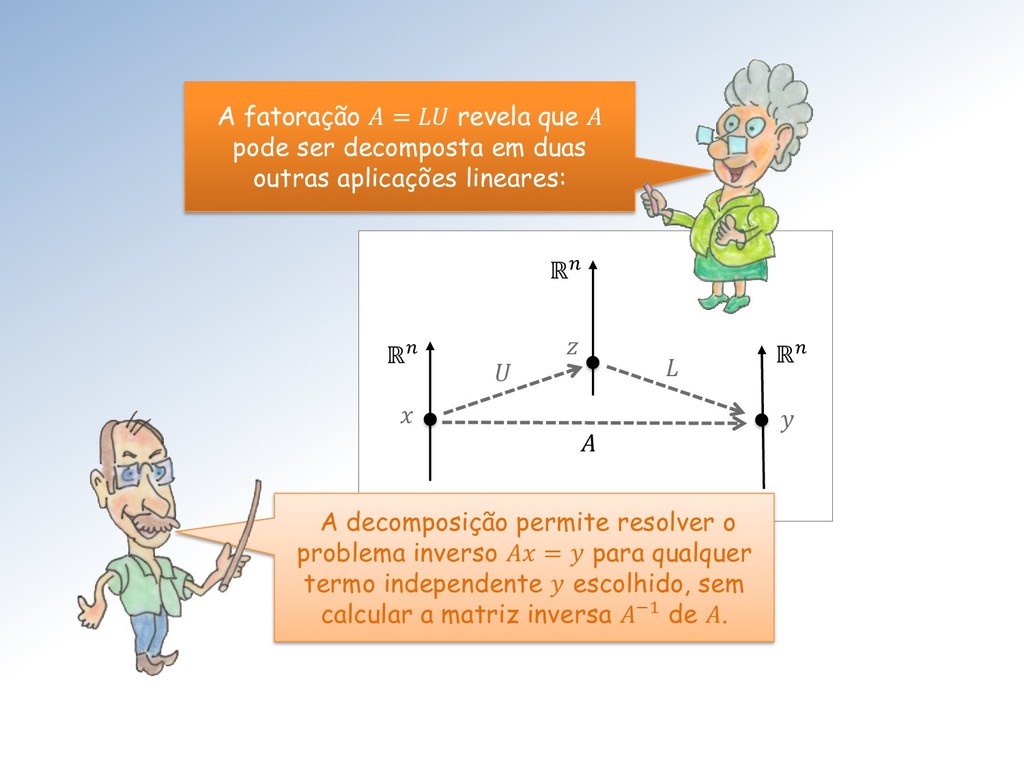
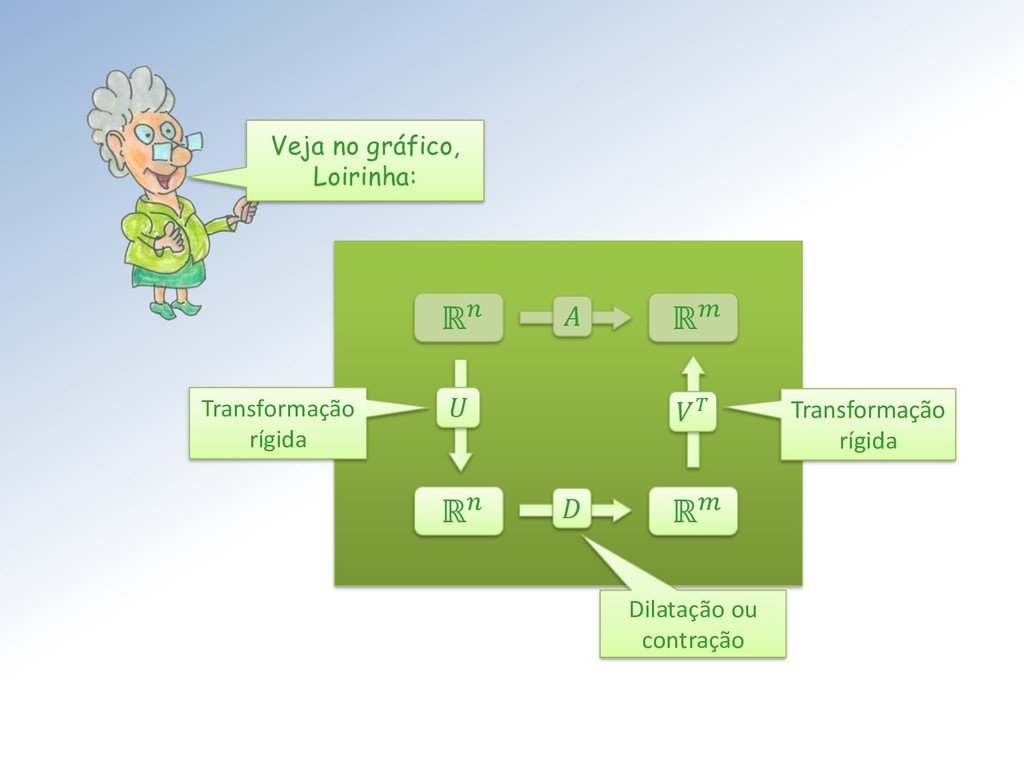
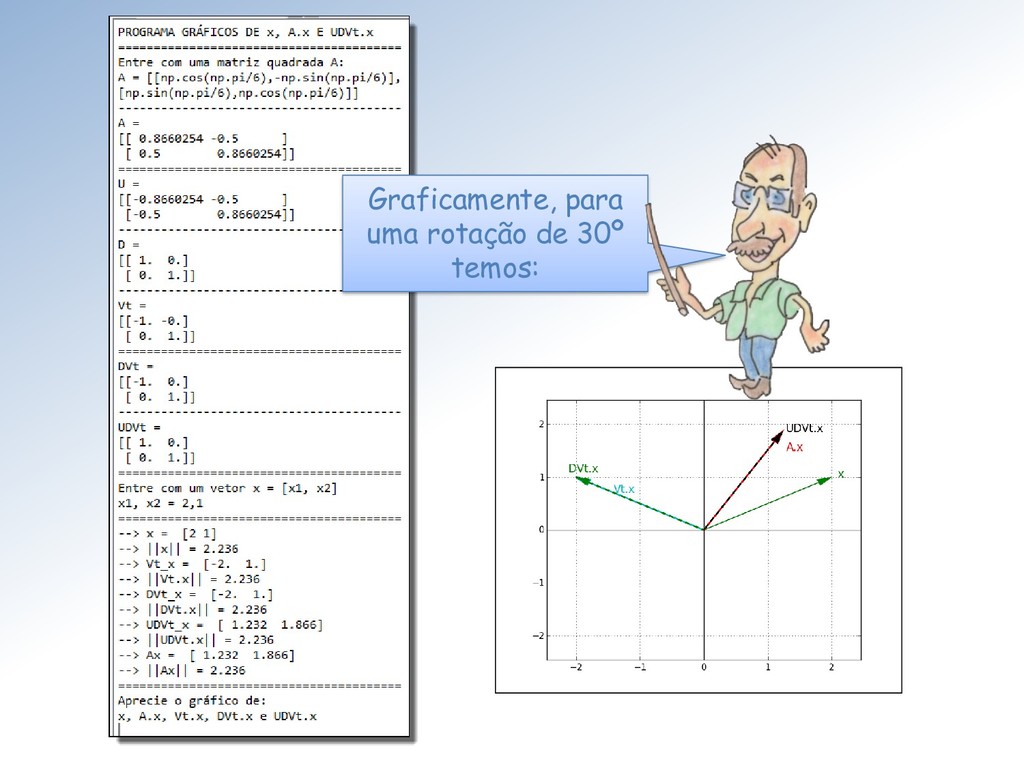
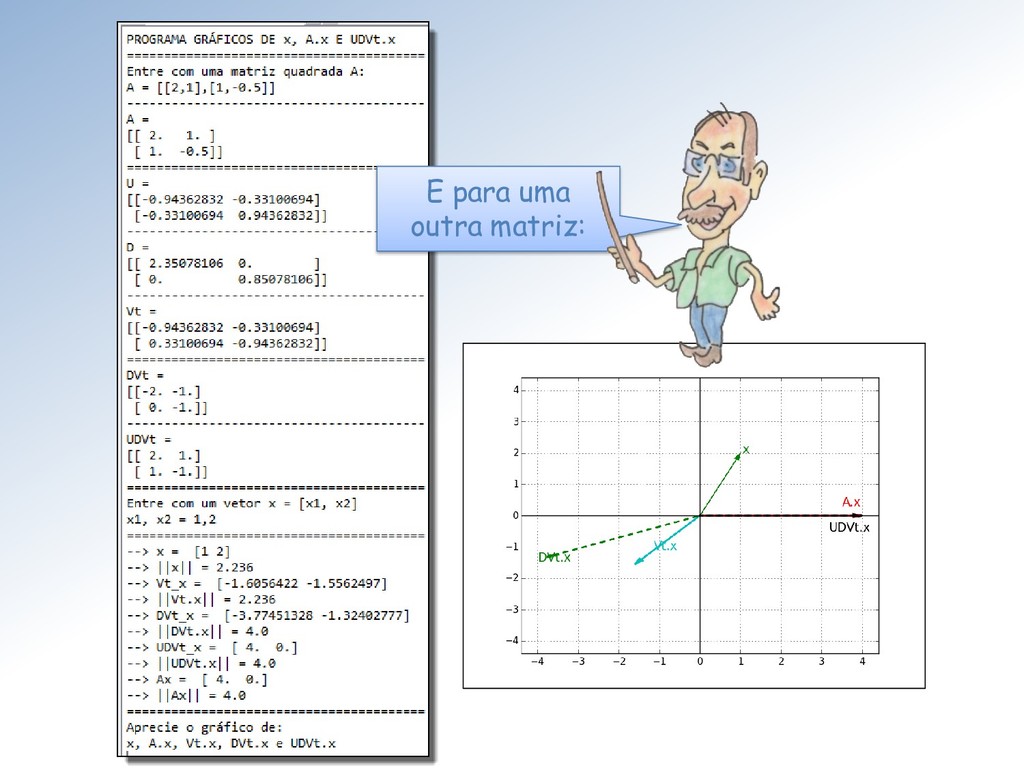
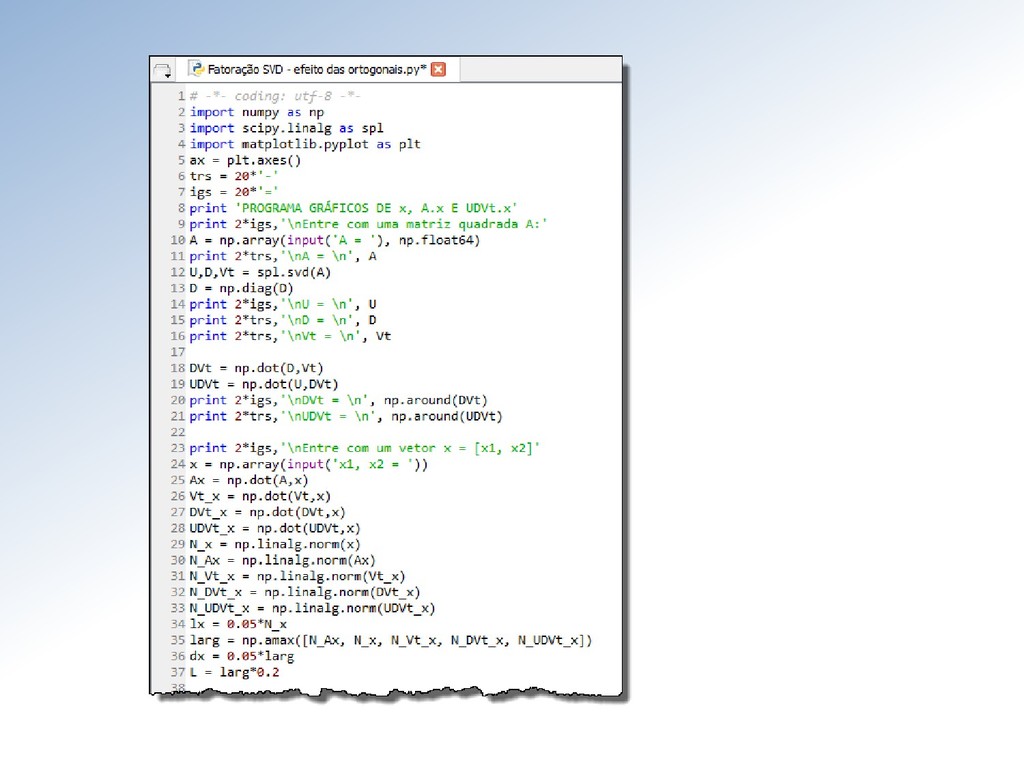
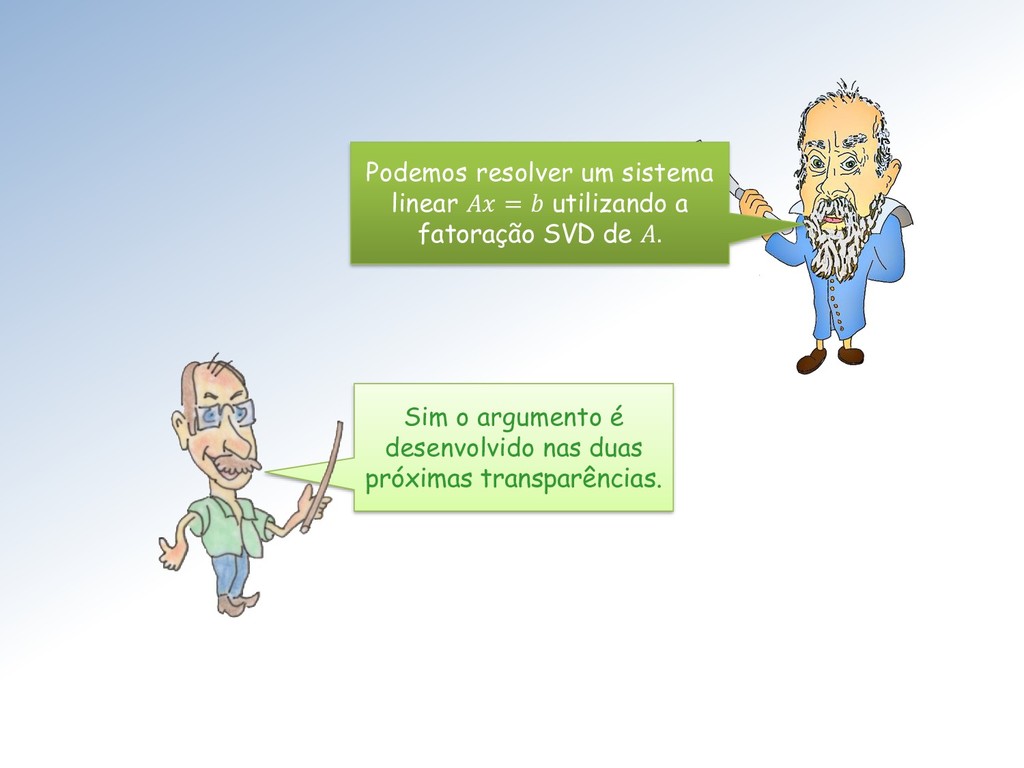
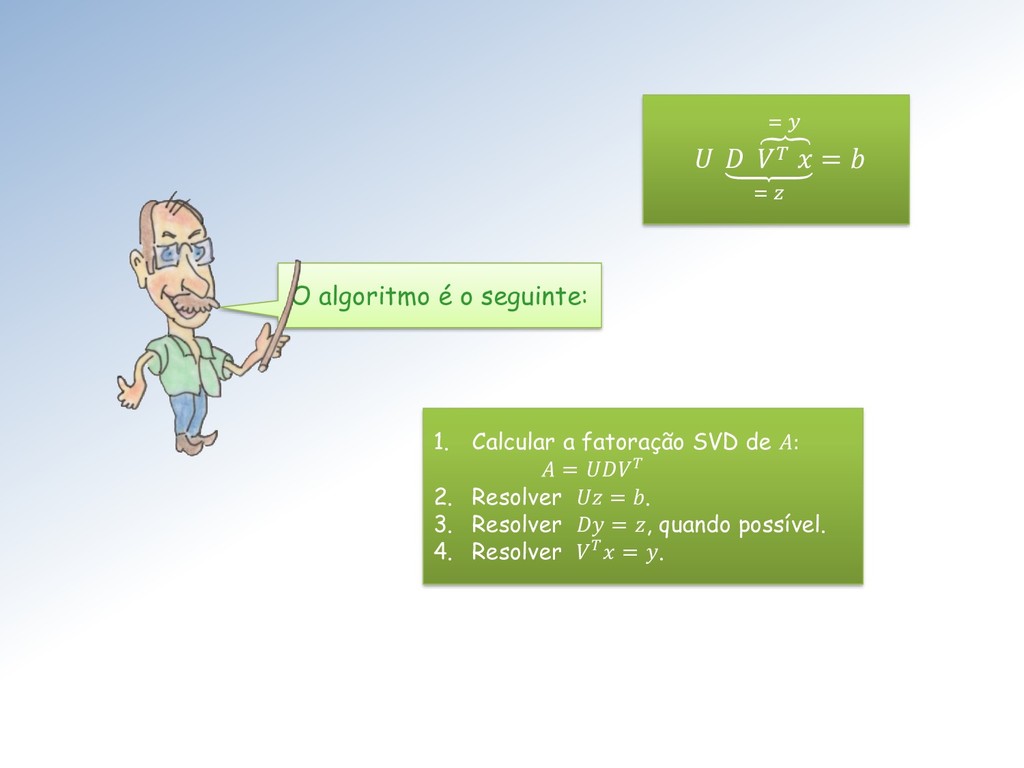
revela que pode ser decomposta em duas outras aplicações lineares: A decomposição permite resolver o problema inverso = para qualquer termo independente escolhido, sem calcular a matriz inversa −1 de .
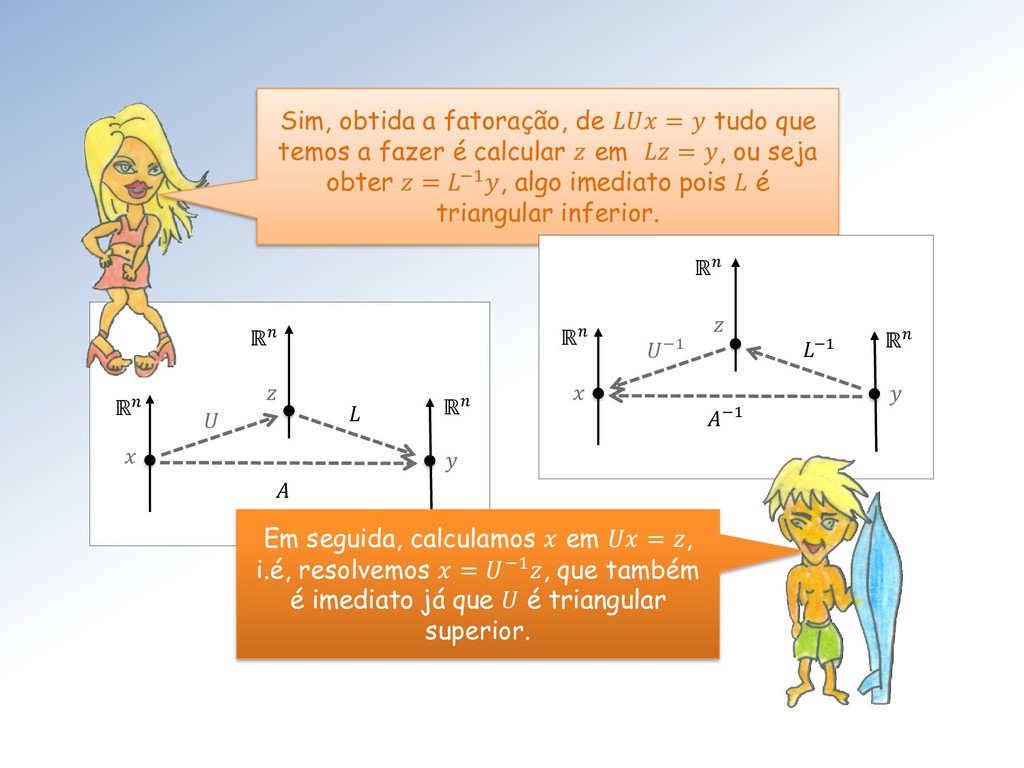
tudo que temos a fazer é calcular em = , ou seja obter = −1, algo imediato pois é triangular inferior. −1 ℝ ℝ ℝ −1 −1 Em seguida, calculamos em = , i.é, resolvemos = −1, que também é imediato já que é triangular superior.
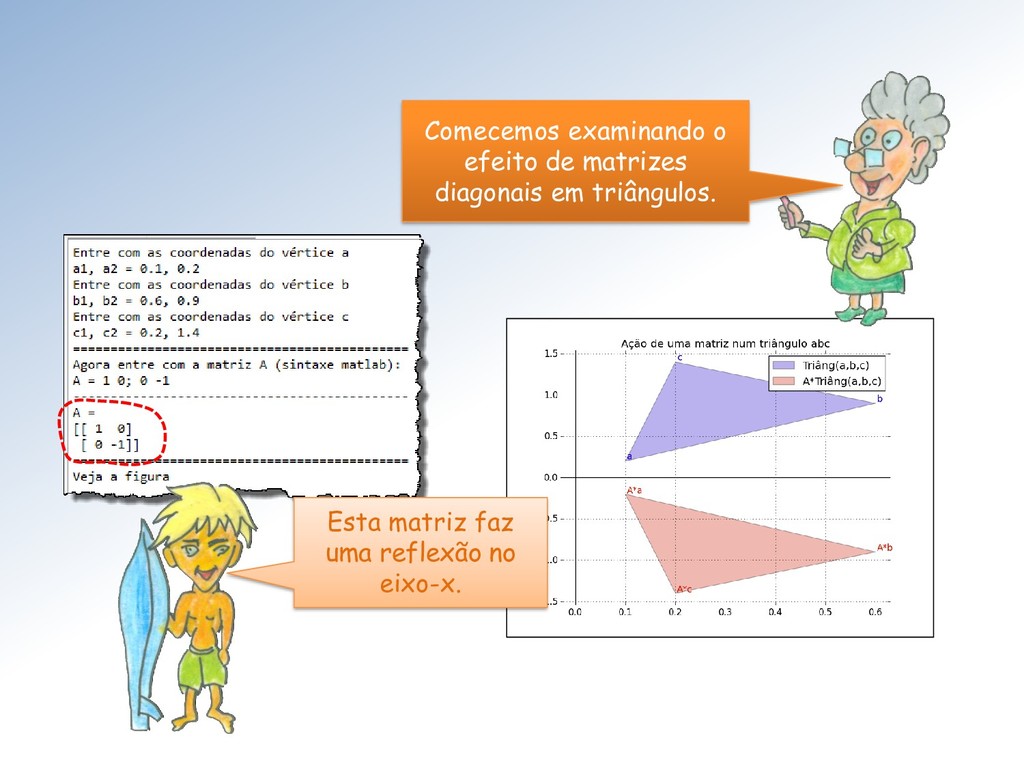
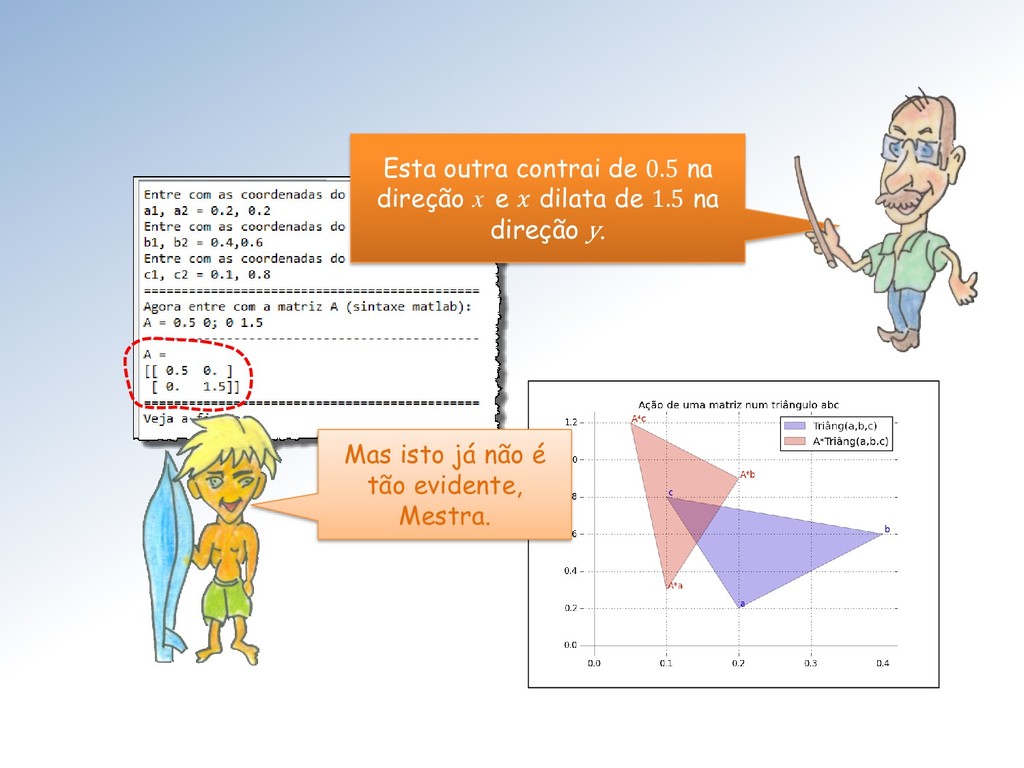
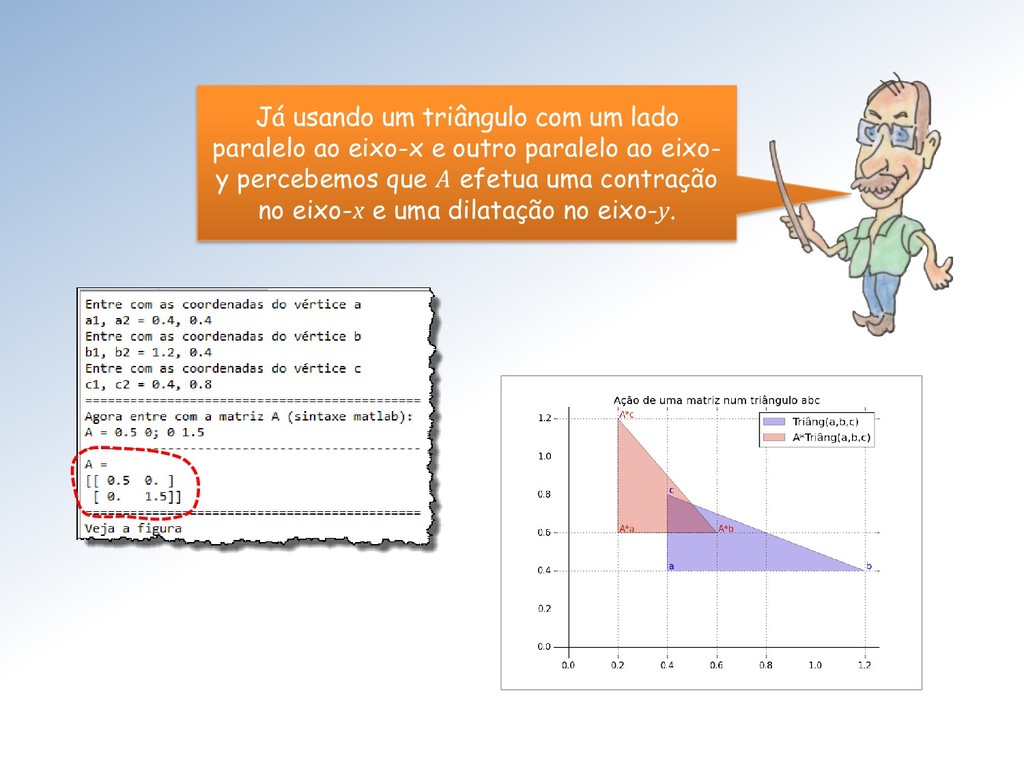
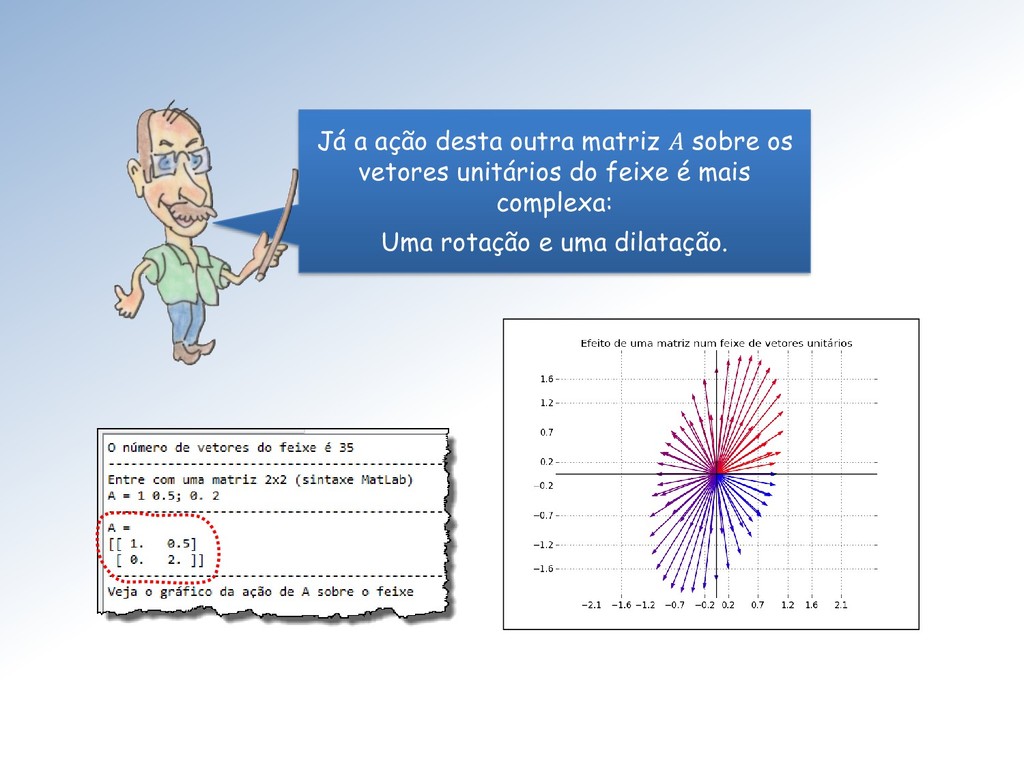
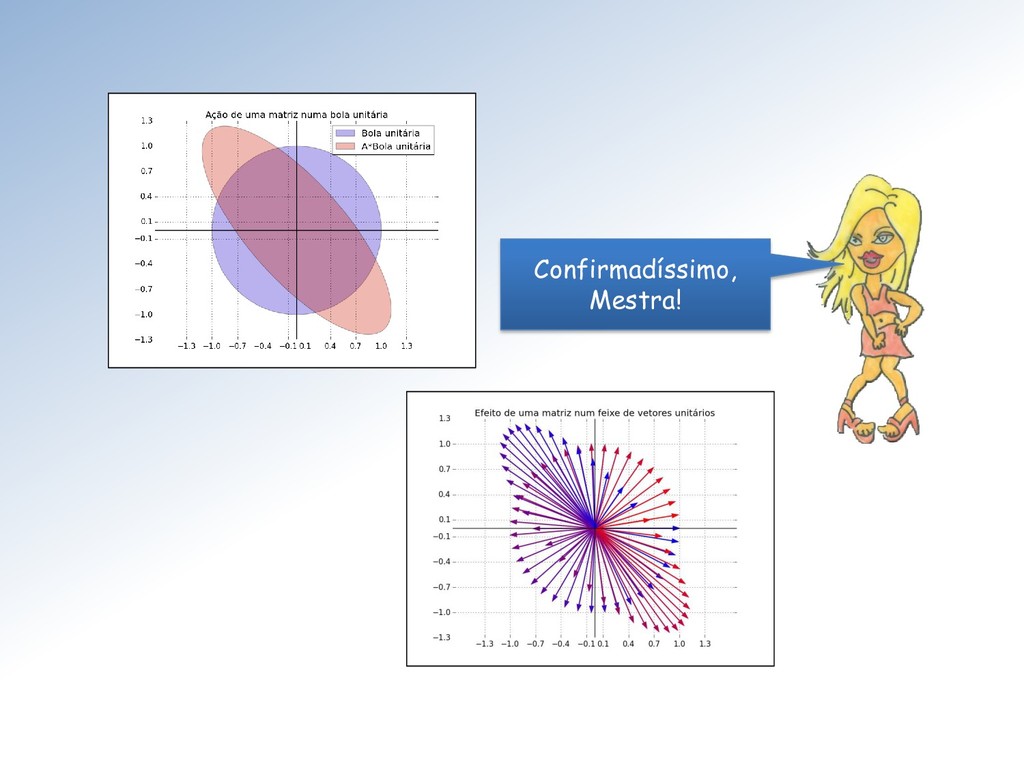
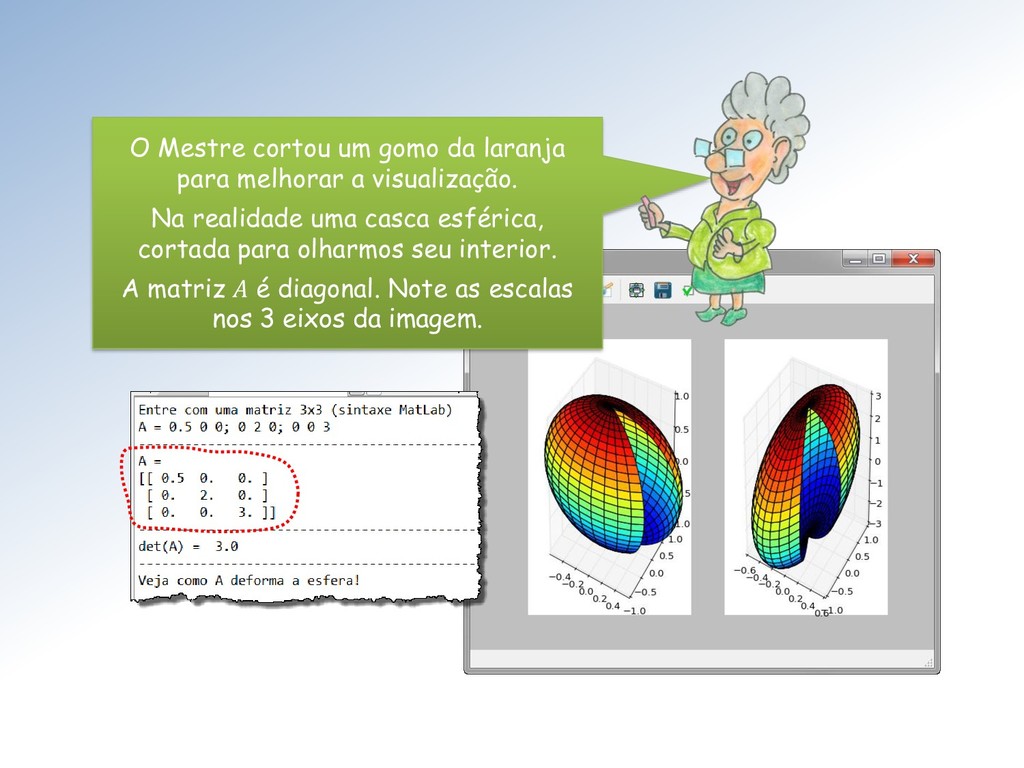
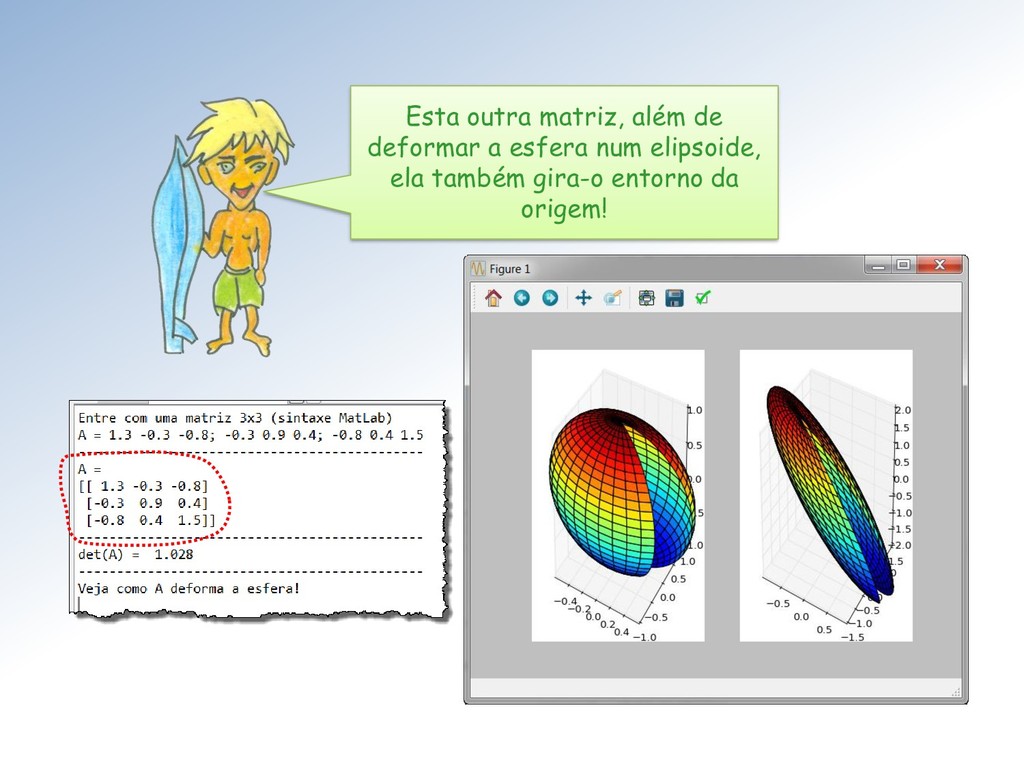
tamanho unitário é clarificada pela imagem abaixo: A ação é dilatar a componente vertical dos vetores do feixe por um fator de escala = 2 e manter a componente horizontal inalterada.
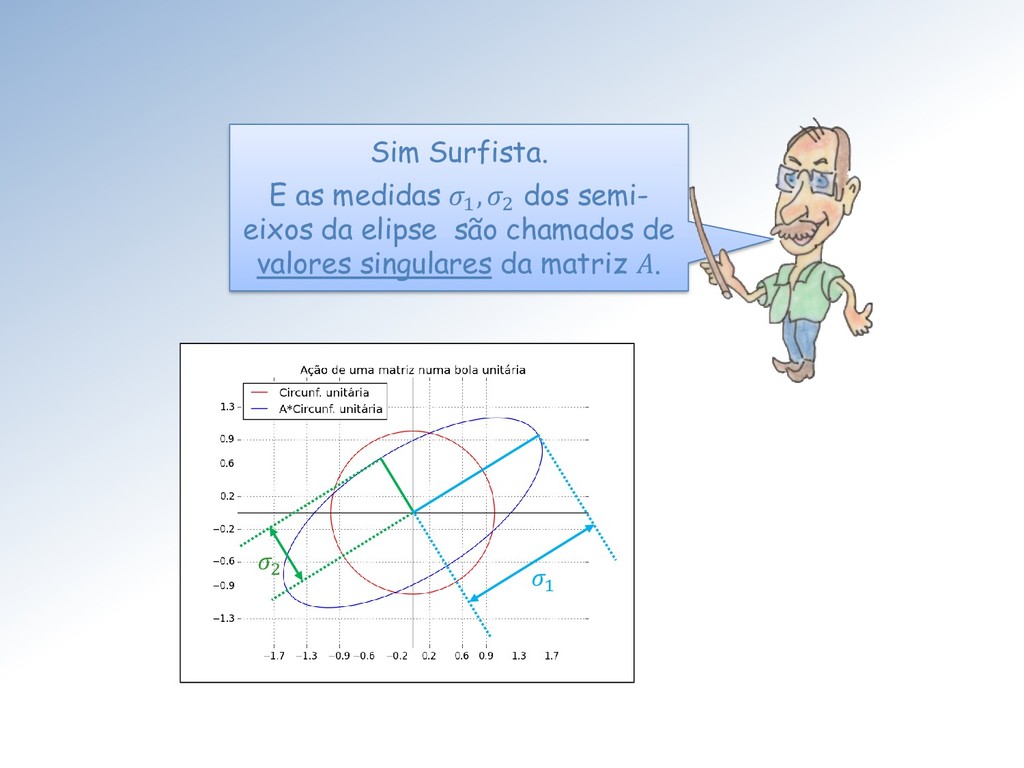
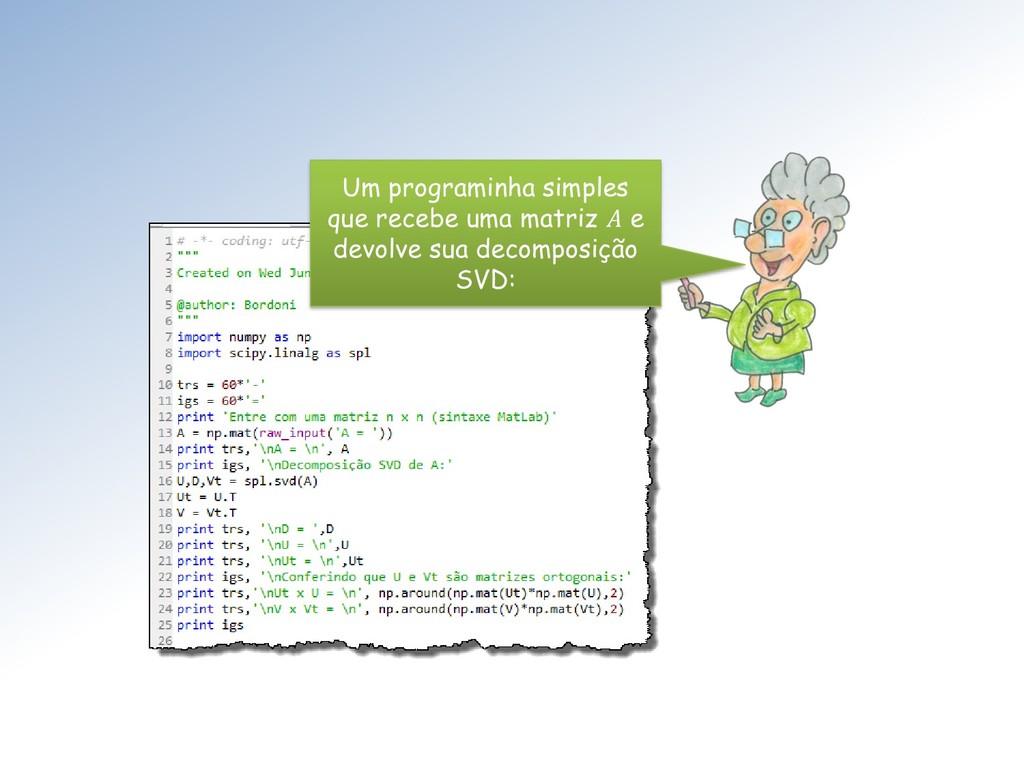
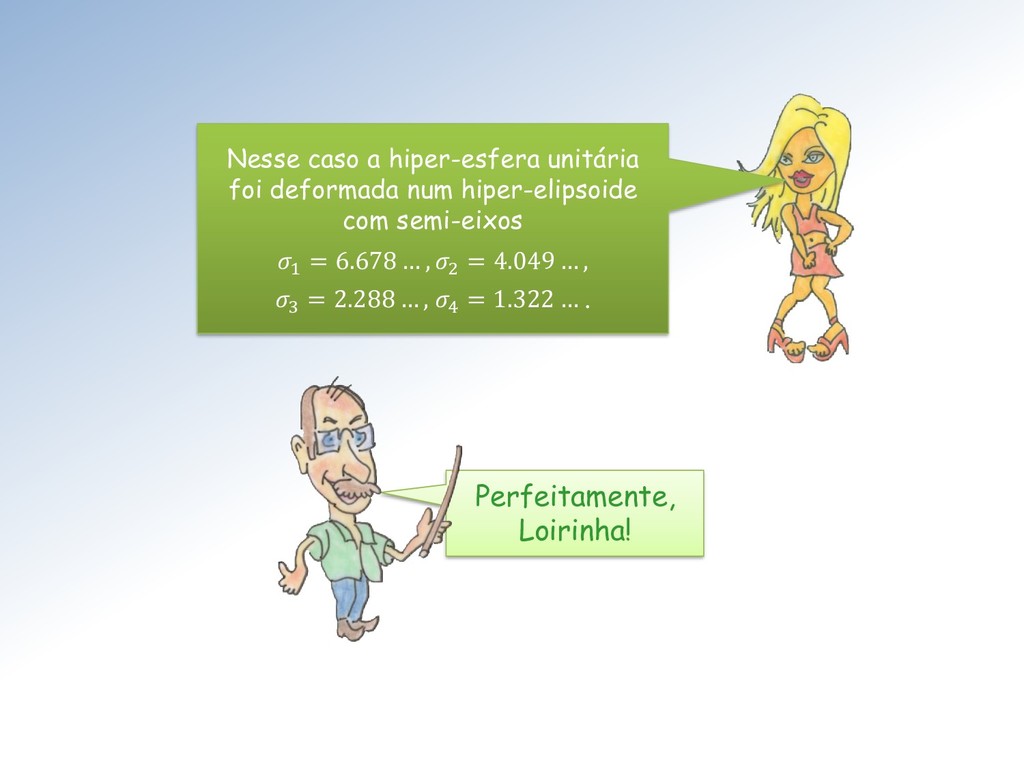
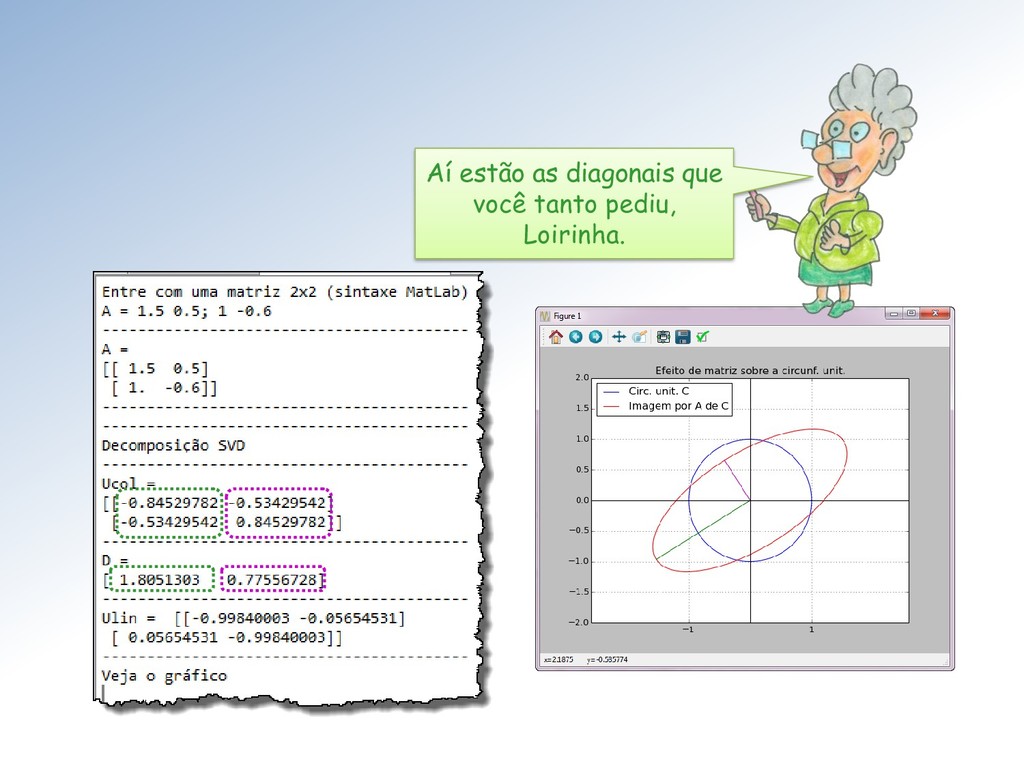
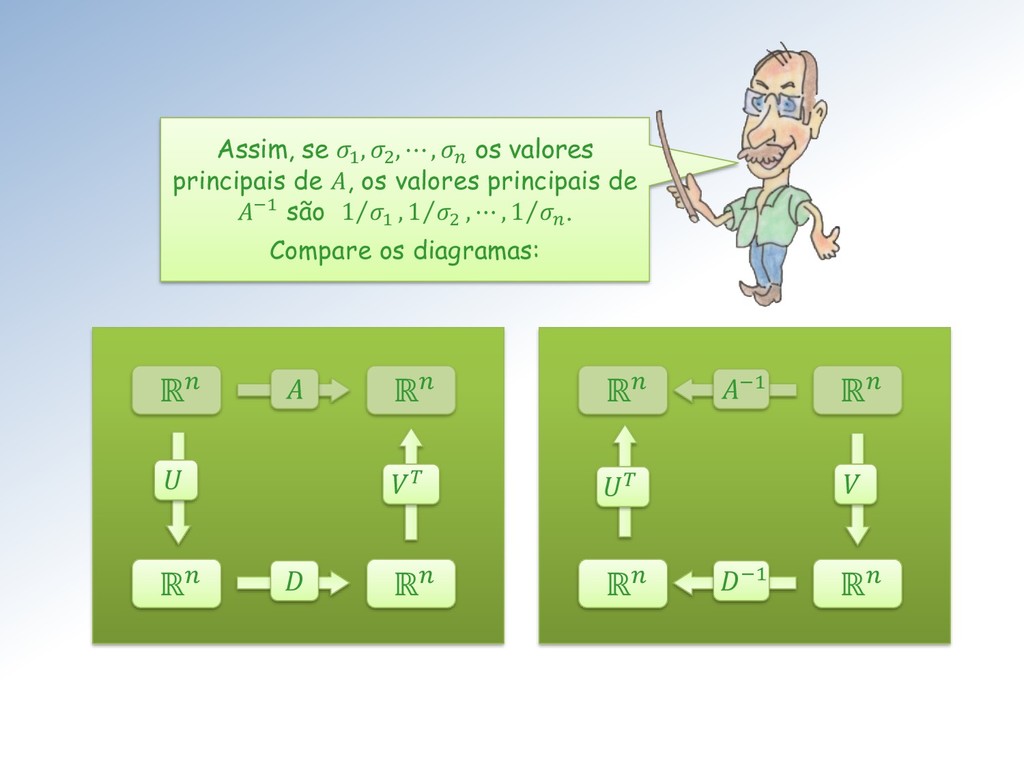
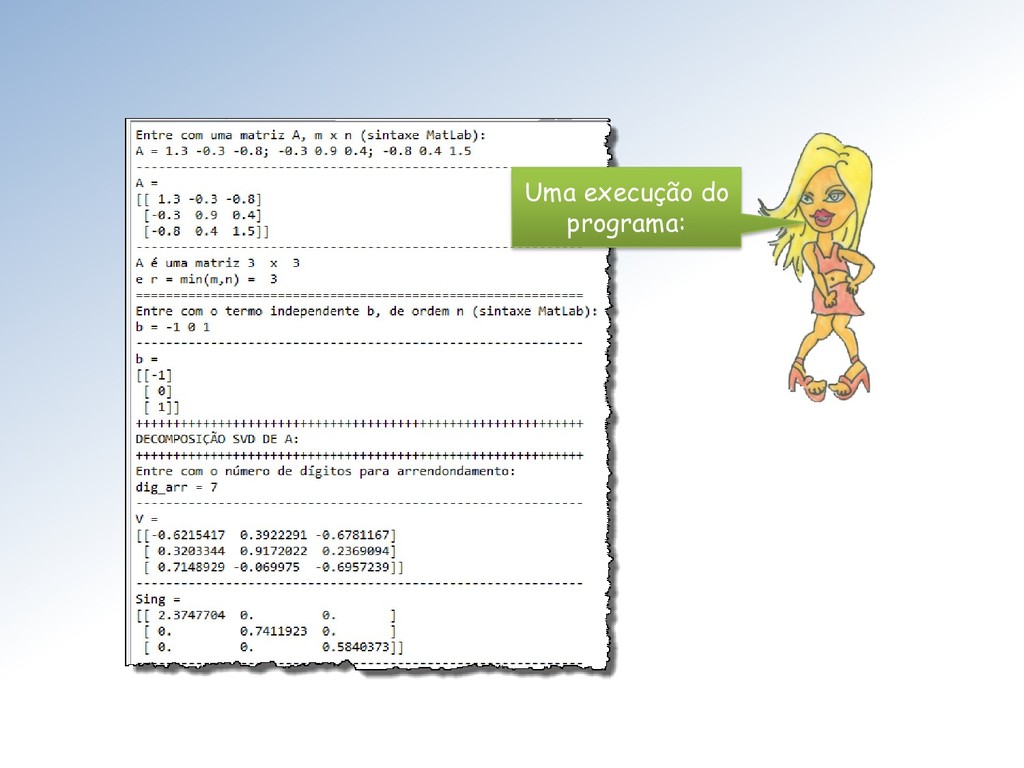
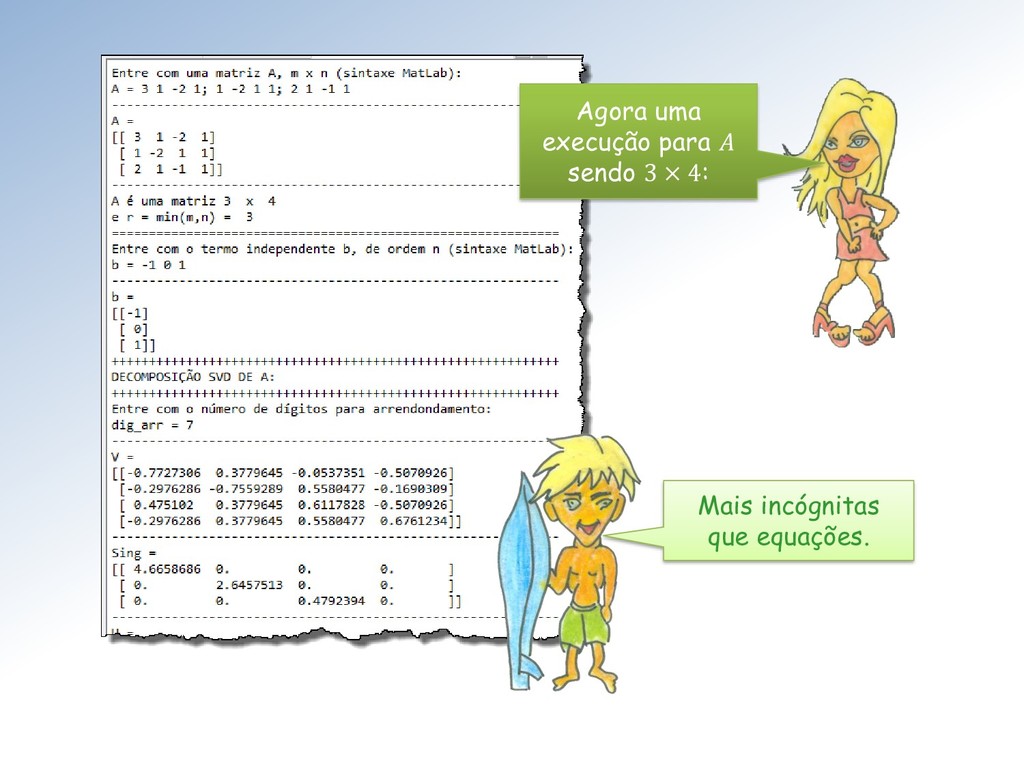
Seja ∈ ℳ× uma matriz com elementos ∈ ℂ. Então existem matrizes unitárias ∈ ℳ× e ∈ ℳ× tais que = = (1 , 2 , ⋯ , ), com = { , } e 1 ≥ 2 ≥ ⋯ ≥ ≥ 0. Os ′ são chamados de valores singulares. As colunas de U e V são os vetores singulares da esquerda e direita, respectivamente.
matrizes ortogonais ∈ ℳ× e ∈ ℳ× tais que = = (1 , 2 , ⋯ , ), com = { , } e 1 ≥ 2 ≥ ⋯ ≥ ≥ 0. Vamos nos restringir à matrizes reais ∈ ℝ. Nesse caso o teorema fica:
4 , que constituem as colunas da matriz e os vetores 1 , 2 , 3 , 4 que constituem as linhas da matriz são ortonormais. Sim Galileu, uma vez que: • ∙ = , • ∙ = .
ℳ× , ∈ ℳ× , ∈ ℳ× e ∈ ℳ× . Isto significa que, como transformação linear, : ℝ → ℝ é a composta de três transformações lineares: ∶ ℝ → ℝ, ∶ ℝ → ℝ e ∶ ℝ → ℝ, como mostro na próxima transparência.
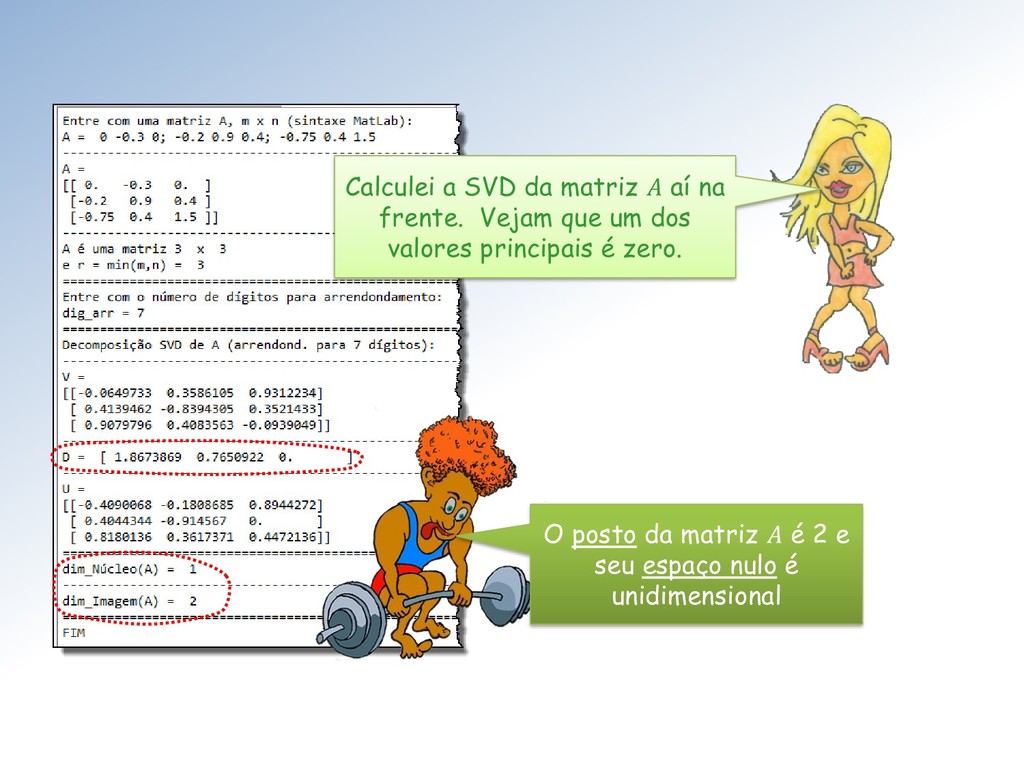
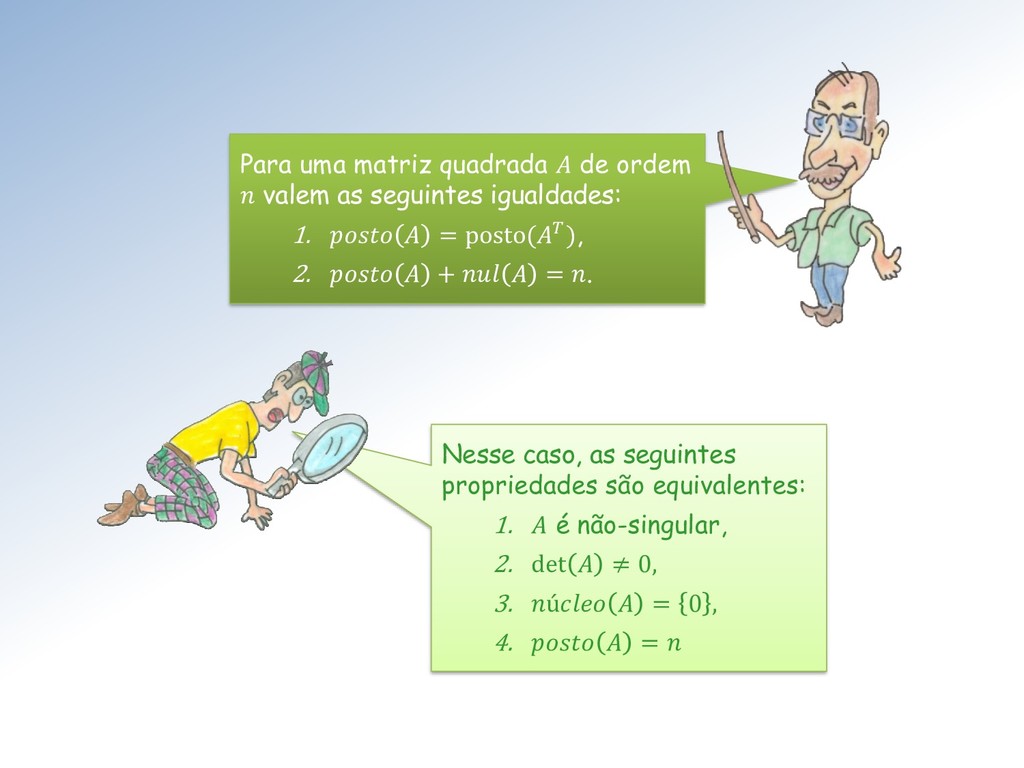
obtida de eliminando-se − linhas e − colunas de . O posto de , anotado () é definido por: = 1 ≤ ≤ min , ≠ 0 } . A definição de posto de uma matriz ∈ ℳ× é a seguinte:
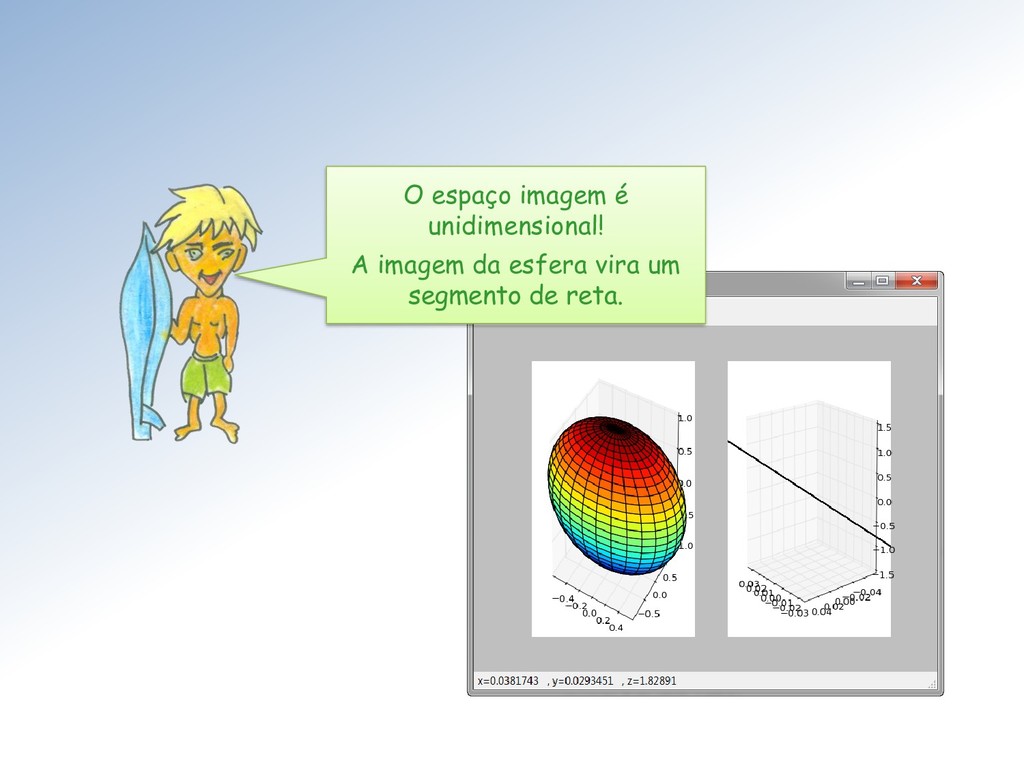
linearmente independentes ou seja é a dimensão da imagem de : = ∈ ℝ y = Ax, x ∈ ℝ } O núcleo de uma matriz ∈ ℳ× é o subespaço ú = ∈ ℝ = 0 }. A dimensão de ú é denominada nulidade de , e anotada .
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}