Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
MN-Core™勉強会: MN-Core Architecture Deep Dive
Search
Preferred Networks
PRO
February 22, 2024
Video
Technology
1.6k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
MN-Core™勉強会: MN-Core Architecture Deep Dive
2024年2月21日にPreferred Networsが開催したMN-Core勉強会のスライドです(発表者: Ryo Sakamoto)
Preferred Networks
PRO
February 22, 2024
Video
More Decks by Preferred Networks
See All by Preferred Networks
The Making of AI Chips
pfn
PRO
1
1k
国産生成AI PLaMoを支える事後学習と推論最適化
pfn
PRO
13
5.3k
Japanese SimpleQA: 日本語における事実に基づいた回答能力の評価ベンチマーク
pfn
PRO
1
410
Headlampと独自プラグインを活用したKubernetesダッシュボードの機能拡張
pfn
PRO
2
430
AI/MLのマルチテナント基盤を支えるコンテナ技術
pfn
PRO
6
1.9k
単一Kubernetesクラスタで実現する AI/ML 向けクラウドサービス
pfn
PRO
1
1k
2.5x Speedup of GPSampler by Batching (PFN 2025 夏期国内インターンシップ)
pfn
PRO
0
140
ストレージエンジニアの仕事と、近年の計算機について / 第58回 情報科学若手の会
pfn
PRO
7
1.9k
エンタメとAIのための3Dパラレルワールド構築(GPU UNITE 2025 特別講演)
pfn
PRO
0
1.8k
Other Decks in Technology
See All in Technology
Multicaで30個のミニプロジェクトをAIエージェント運用して見えてきたこと
eiei114
1
600
GoでCコンパイラを作った話
repunit
0
150
データエンジニアリングとドメイン駆動設計
masuda220
PRO
14
2.3k
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
3
720
インシデント事例と パッケージの全量解析に学ぶ ソフトウェアサプライチェーンの守り方 / supply-chain-attack-defense
flatt_security
0
840
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.2k
DatabricksにおけるMCPソリューション
taka_aki
1
330
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.5k
【公開用】AI_Dev_Ex2026_AI_登壇資料
matsuritechnologies
PRO
1
440
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
110
AI_Dev_Day_製造業領域でのAI活用から見た活用の罠と成功に導く実践知.pdf
kintotechdev
0
120
SREとQA 二人三脚で進めるSLO運用/sre-qa-slo
sugitak
0
1.2k
Featured
See All Featured
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
Between Models and Reality
mayunak
4
380
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
What does AI have to do with Human Rights?
axbom
PRO
1
2.3k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
330
Chasing Engaging Ingredients in Design
codingconduct
0
240
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
910
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
How STYLIGHT went responsive
nonsquared
100
6.2k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Transcript
2024-2-21 MN-Core勉強会 Ryo Sakamoto / Preferred Networks, Inc. MN-Core Architecture
Deep Dive 1
MN-Core勉強会へようこそ! MN-Core勉強会へようこそ
Q: MN-Coreシリーズ ご存知ですか?
MN-Core2 whitepaper
DeepDive
PFN Confidential Green500 Techtalk @nu @thiguchi 2020/06 1st 2020/11 2nd
2021/06 1st 2021/11 1st
7 深層学習をはじめとするPreferred Networks (PFN)の中核技術は膨大な計算 を要求します PFNでは、多量の計算を効率的に実行するために独自の計算機クラスターを 複数運用しており、現在はMN-2、MN-3が稼働しています MN-3は、PFNが自社開発した深層学習用プロセッサーMN-Coreを初めて用 いた計算機クラスターです MN-Core
MN-Core Board x 4 CPU Intel Xeon 8260M 2way (48物理core) Memory 384GB DDR4 Storage Class Memory 3TB Intel Optane DC Persistent Memory Network MN-Core DirectConnect(112Gbps) x 2 Mellanox ConnectX-6(100GbE) x 2 On board(10GbE) x 2 MN-3のサーバ1台あたりのスペック(MN-3は、以下サーバが48台で構成) 深層学習用プロセッサーMN-Core 深層学習用に設計したスーパーコンピューター MN-1 MN-2 MN-3
Our MN-3 supercomputer is certified as the world’s most efficient
supercomputer (Green500 List Nov. 2021). Important effort towards achieving carbon neutral AI datacenter MN-Core Accelerates World’s Most Efficient Supercomputer Deep learning processor MN-Core 8
実際のワークロードの例: Matlantis
実際のワークロードの例: 3d-Scan
MN-Core series MN-Core™ Series MN-Core MN-Core 2
ͦΕͧΕͷҐஔ͚ͮʁ MN-Core 第一世代 MN-Core • TSMC 12nm • 500MHz /
500W Flops GFlops/W 倍精度 32.8 T 66 単精度 131 T 260 半精度 524 T 1000
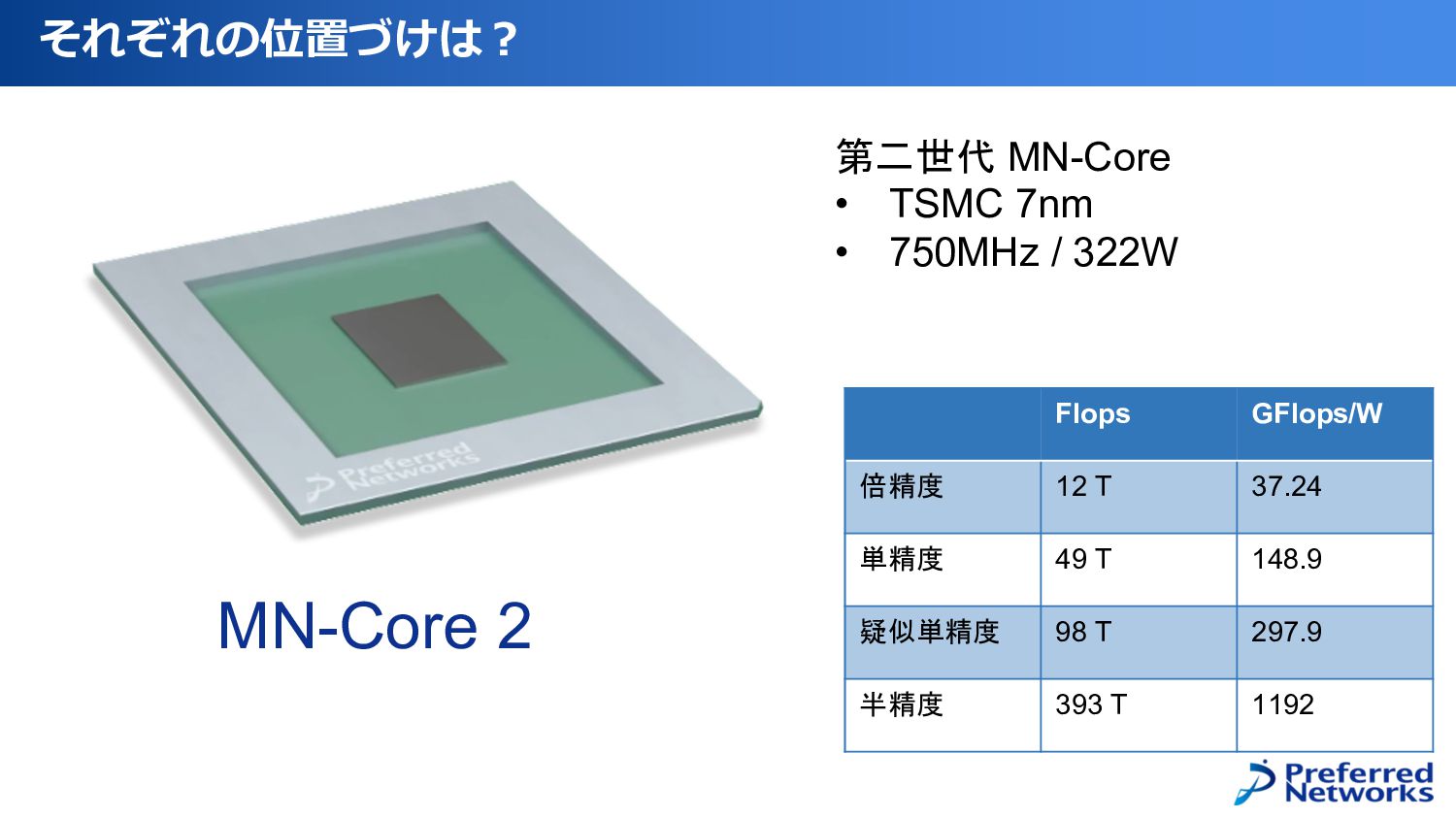
それぞれの位置づけは︖ MN-Core 2 第二世代 MN-Core • TSMC 7nm • 750MHz
/ 322W Flops GFlops/W 倍精度 12 T 37.24 単精度 49 T 148.9 疑似単精度 98 T 297.9 半精度 393 T 1192
MN-Core シリーズの位置付け MN-Core 実証実験モデル 実際にどういった用途で使えるのか どういったモデルが動くのかを実証 した MN-Core 2 実験
+ 普及モデル MN-Coreを取り回しが良くなるよう に修正・改良。実ワークロードへの 適用を目指す
ラックあたり密度 MN-Pod 倍精度 524.29 T 単精度 2097.15 T 半精度 8388.61
T
ラックあたり密度 MN-Pod 2 倍精度 590 T 単精度 2359 T 疑似単精度
4719 T 半精度 18874 T
MN-Core Architecture Deep Dive
MN-Core Architecture Deep Dive
Q: MN-Coreって DL以外で使えるんですか? 速いんですか?
A: 使えます(がんばれば) 速いです
• Himeno Benchmark ◦ 某アクセラレータ比で 4.7倍の実行性能(19.6倍の実行効率) を達成 Himeno bench on
MN-Core 某Accelerator MN-Core メモリ帯域 4.8 TB/s 400 GB/s 理論性能 33.5 TFlops 8.2 TFlops 実行性能 1.27 TFlops 5.99 TFlops 実行効率 3.79 % 73.05 %
• どのようにしてHimeno benchmarkを高速化したのか? ◦ これを知るためには、MN-Coreに対する理解が必要になる… ◦ というわけで、少し深い解説をしていきたいと思います。 ▪ ここからは主にMN-Core 2をターゲットにした話になります
• たまにMN-Core 1の話も出てきます Himeno bench on MN-Core
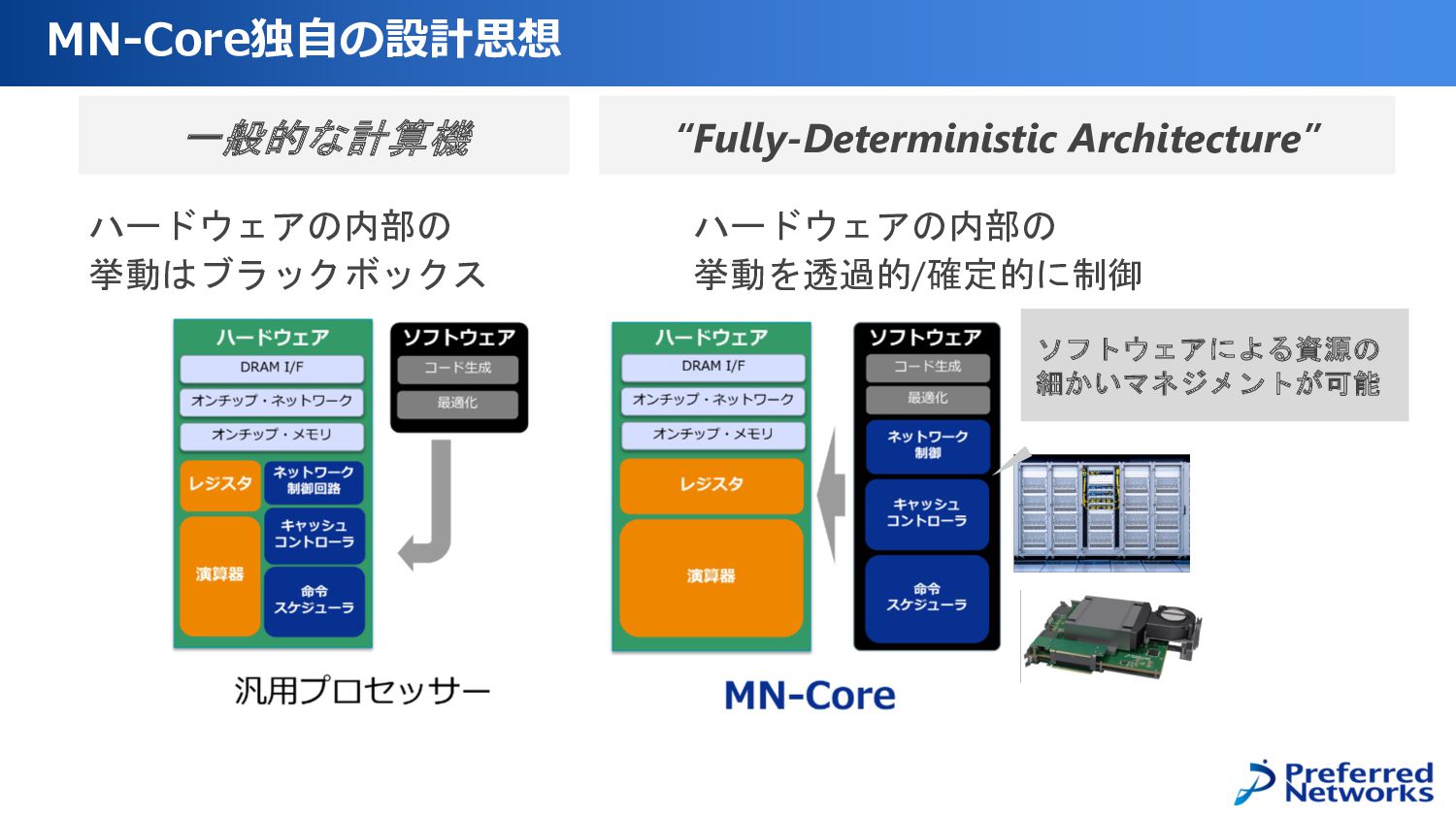
MN-Core独⾃の設計思想 “Fully-Deterministic Architecture” 1: 高いシリコン利用効率を狙った チップ設計 時間方向および空間方向の両方での資源利用効率を 意識した設計 + 2:
ソフトウェア最適化を前提とした アーキテクチャ ハードウェア資源をソフトウェアで細粒度制御できるMN- Coreアーキテクチャ 完全に事前スケジューリング可能な深層学習/AIワークロードを前提とした 計算機アーキテクチャの進化 2つの特徴 ソフトウェアから透過的/確定的に動作 ハードウェアを最大限活用
MN-Core独⾃の設計思想 ソフトウェアによる資源の 細かいマネジメントが可能 一般的な計算機 ハードウェアの内部の 挙動はブラックボックス ハードウェアの内部の 挙動を透過的/確定的に制御 “Fully-Deterministic Architecture”
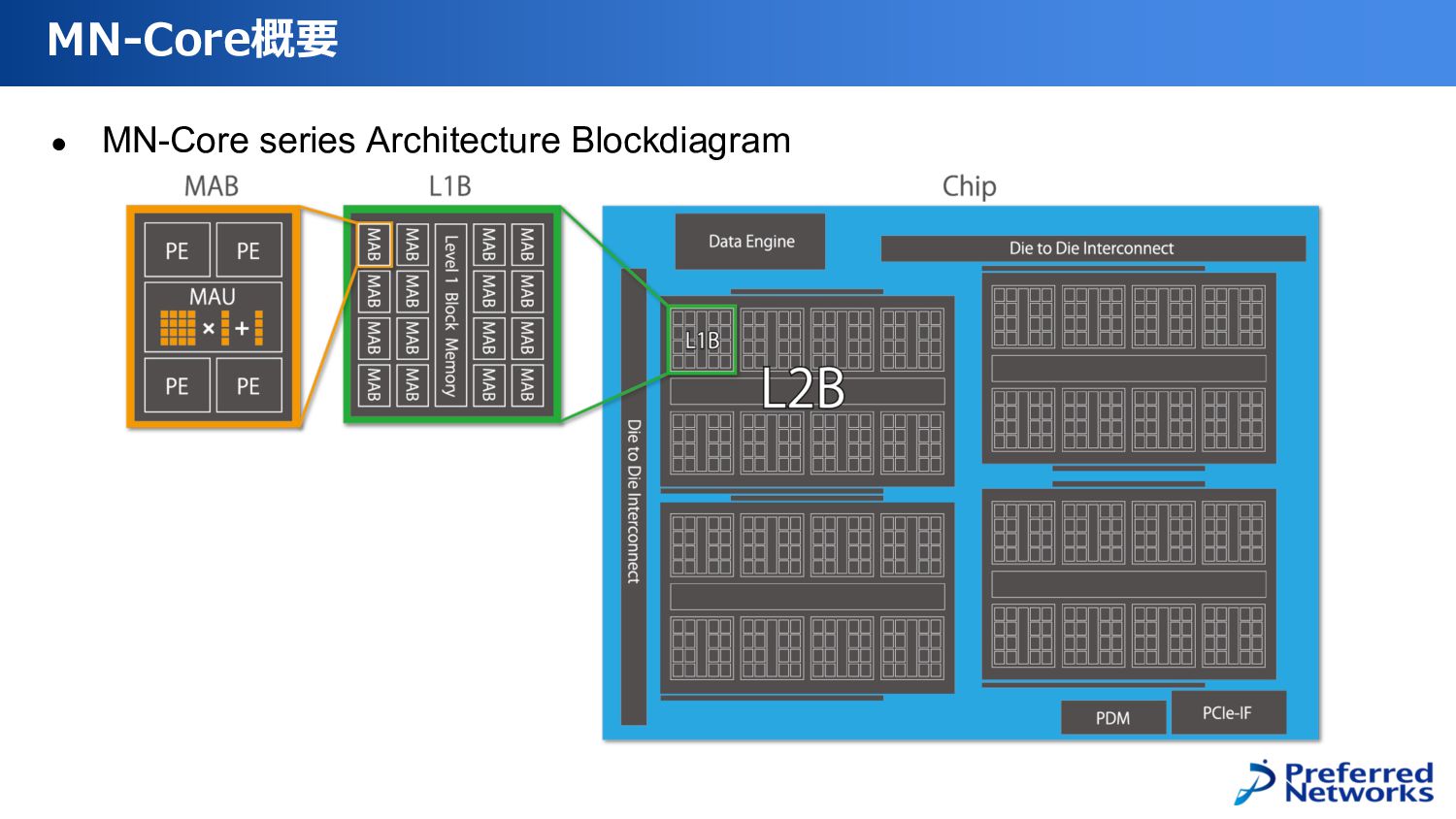
• MN-Core series Architecture Blockdiagram MN-Core概要
• PE ◦ 実際に演算を担当するコア部分 ◦ ALUでは整数演算を処理可能 ▪ 特殊な命令ではReLUやBlock Float変換など ◦
PE内 64bit SIMDもある ▪ double: 64x1 ▪ float: 32x2 ▪ half: 16x4 ◦ たくさんのSRAMにより構成されている PE
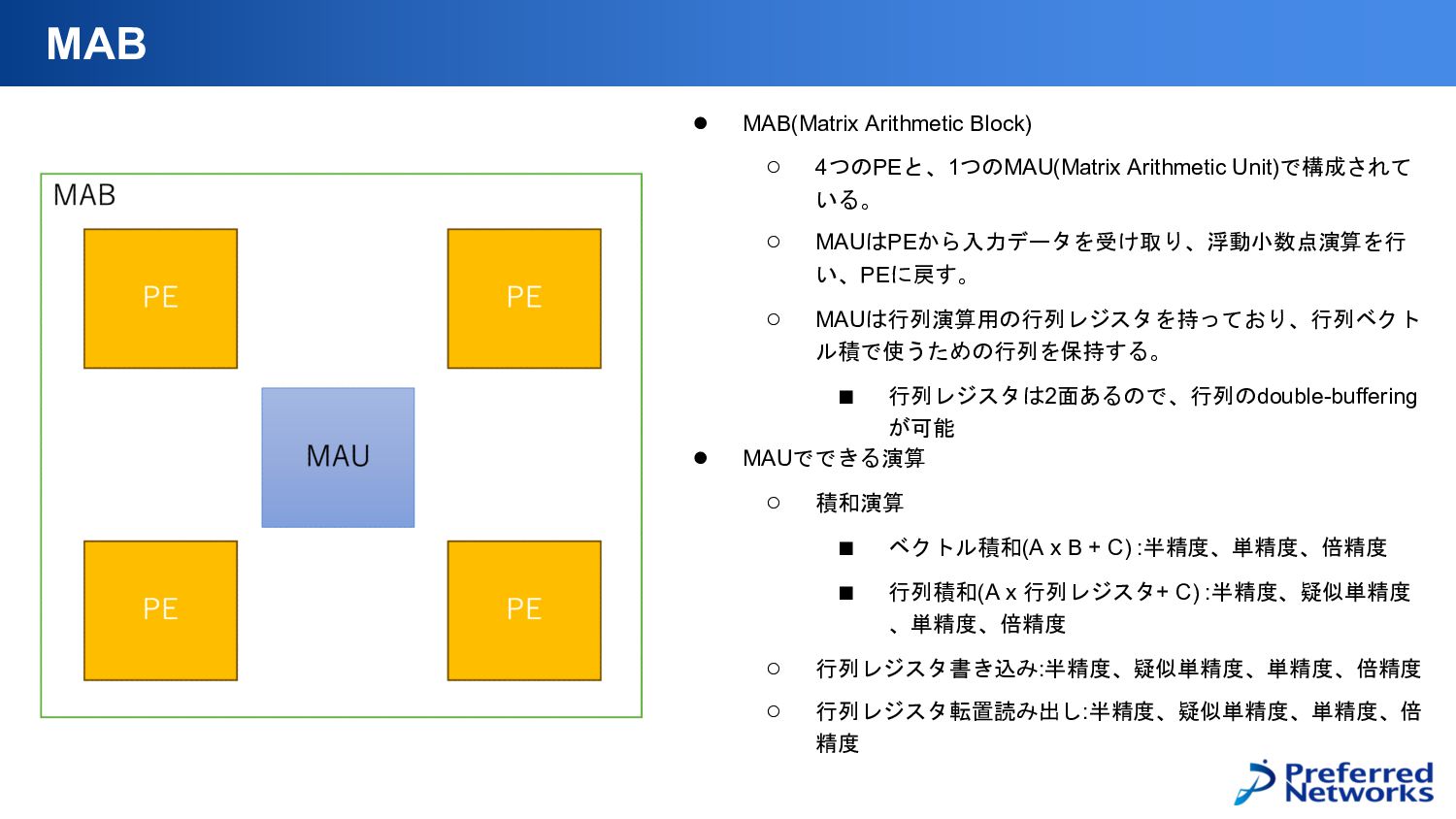
• MAB(Matrix Arithmetic Block) ◦ 4つのPEと、1つのMAU(Matrix Arithmetic Unit)で構成されて いる。 ◦
MAUはPEから入力データを受け取り、浮動小数点演算を行 い、PEに戻す。 ◦ MAUは行列演算用の行列レジスタを持っており、行列ベクト ル積で使うための行列を保持する。 ▪ 行列レジスタは2面あるので、行列のdouble-buffering が可能 • MAUでできる演算 ◦ 積和演算 ▪ ベクトル積和(A x B + C) :半精度、単精度、倍精度 ▪ 行列積和(A x 行列レジスタ+ C) :半精度、疑似単精度 、単精度、倍精度 ◦ 行列レジスタ書き込み:半精度、疑似単精度、単精度、倍精度 ◦ 行列レジスタ転置読み出し:半精度、疑似単精度、単精度、倍 精度 MAB
L1B
L2B
1. メモリ空間が独立している 2. アクセラレータ上にハードウェアとしての制御機構を一切持っていない MN-Core アーキテクチャ 2つの重要ポイント
1. メモリ空間が独立している 2. アクセラレータ上にハードウェアとしての制御機構を一切持っていない MN-Core アーキテクチャ 2つの重要ポイント
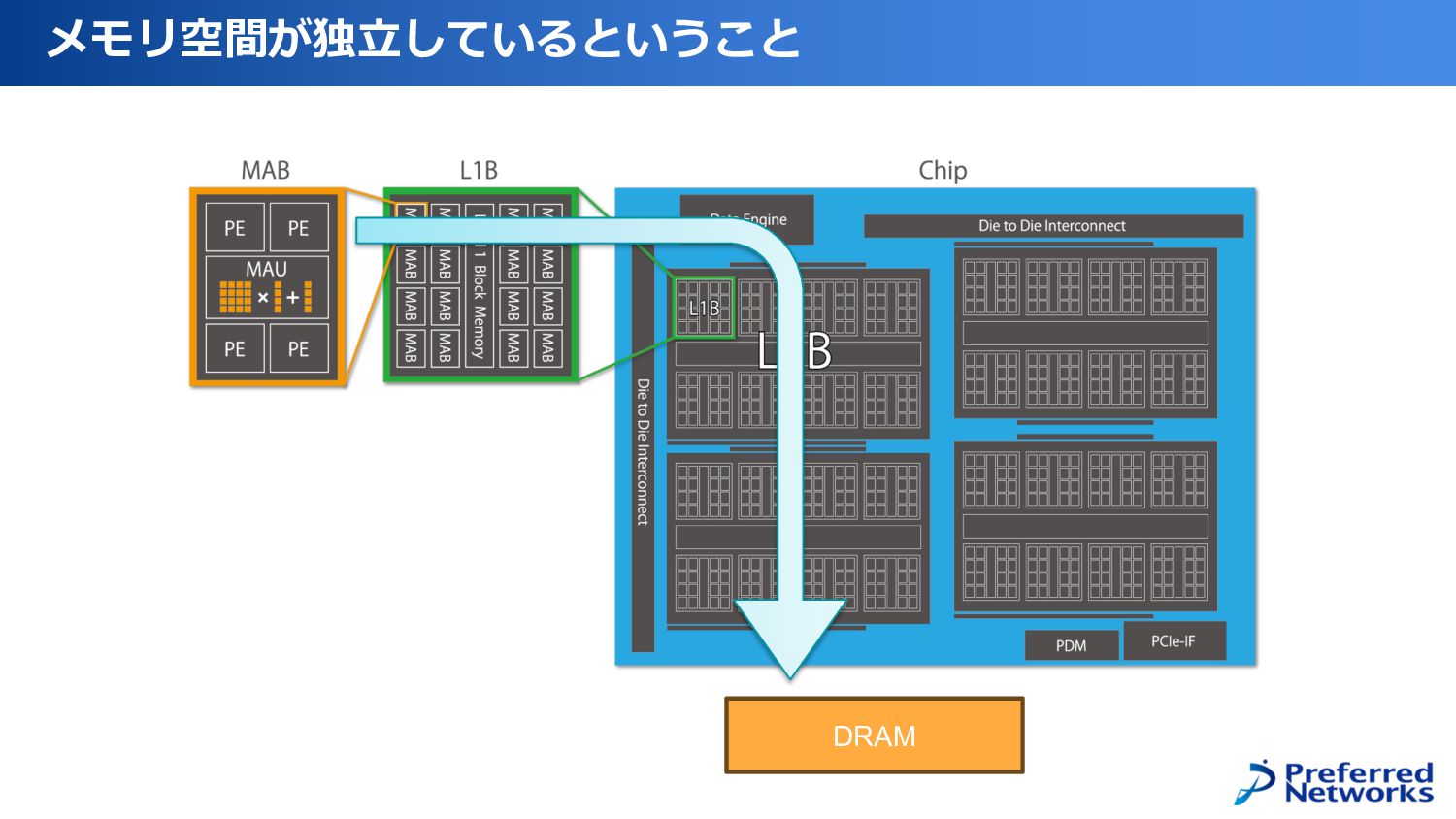
メモリ空間が独⽴しているということ DRAM
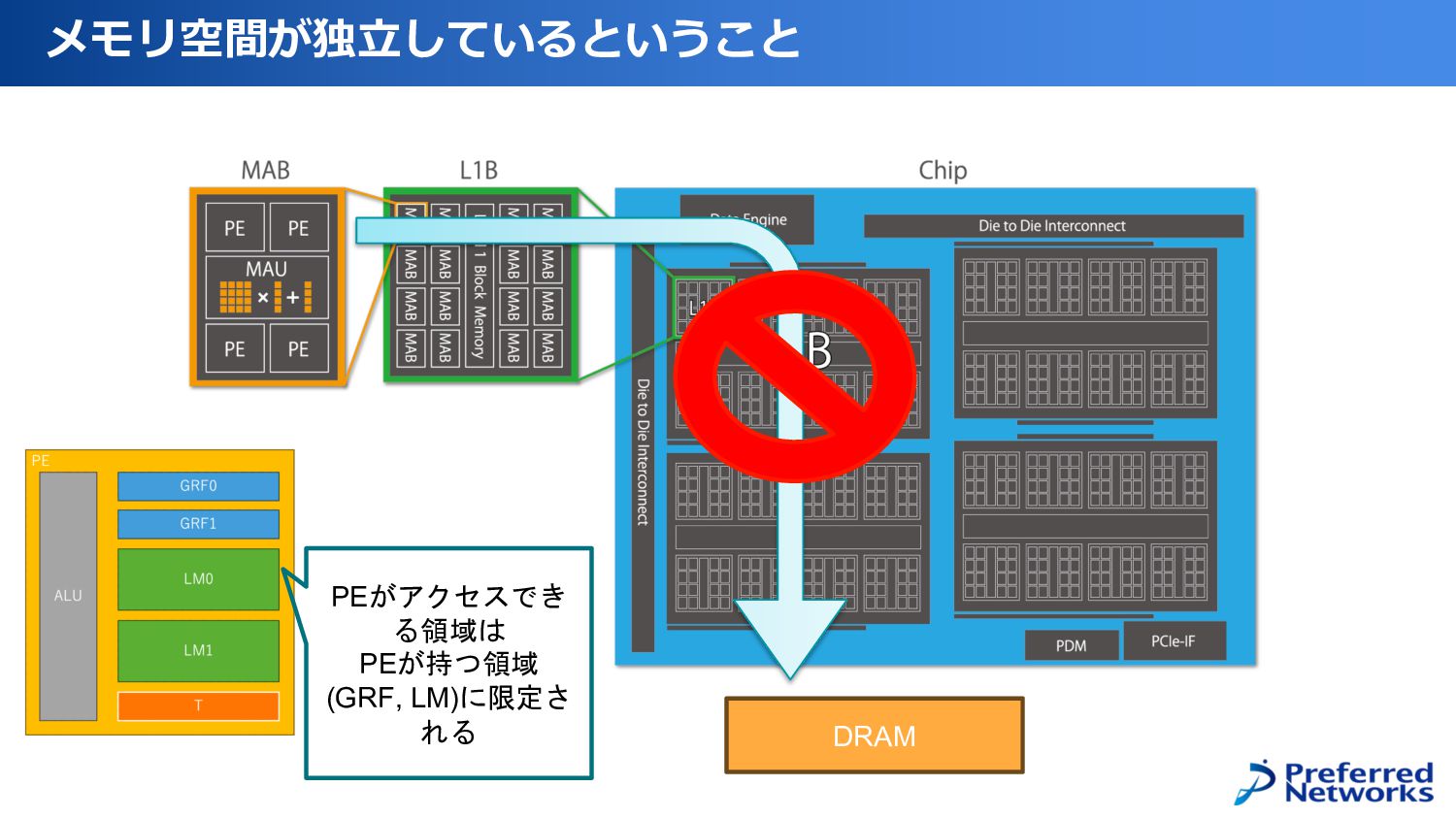
メモリ空間が独⽴しているということ DRAM PEがアクセスでき る領域は PEが持つ領域 (GRF, LM)に限定さ れる
メモリ空間が独⽴しているということ DRAM PEが実際に演算を行うためには、 DRAM-> L2B -> L1B -> PE というデータ転送を行う必要がある
1. メモリ空間が独立している 2. アクセラレータ上にハードウェアとしての制御機構を一切持っていない MN-Core アーキテクチャ 2つの重要ポイント
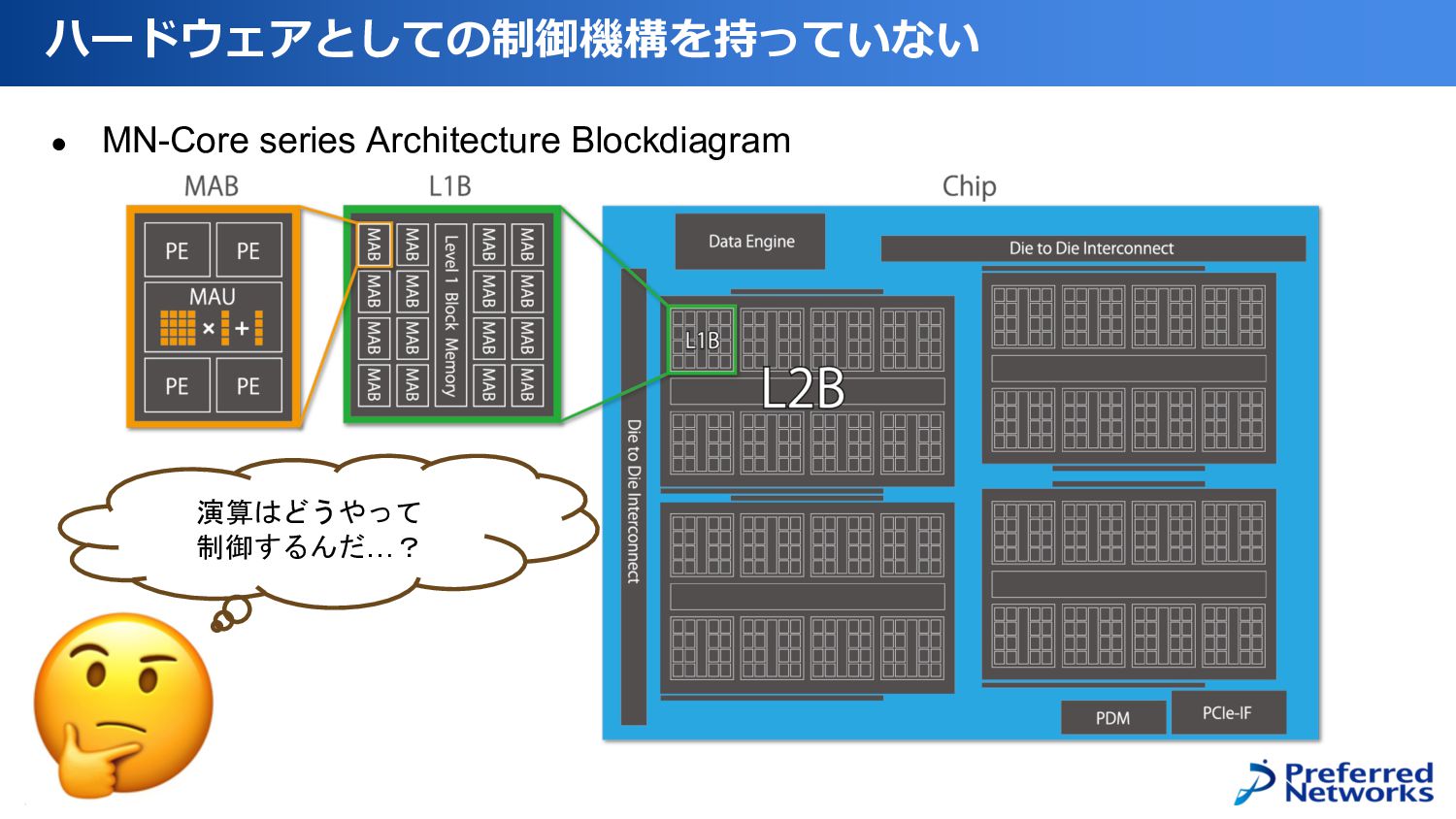
• MN-Core series Architecture Blockdiagram ハードウェアとしての制御機構を持っていない 演算はどうやって 制御するんだ…?
• MN-Coreは、PEに命令発行ユニットを持たない! • 同様に、PEに制御ユニットも持たない! ◦ プログラムカウンタとかもない! • ではどのように演算を制御するの? つまりどういうこと︖
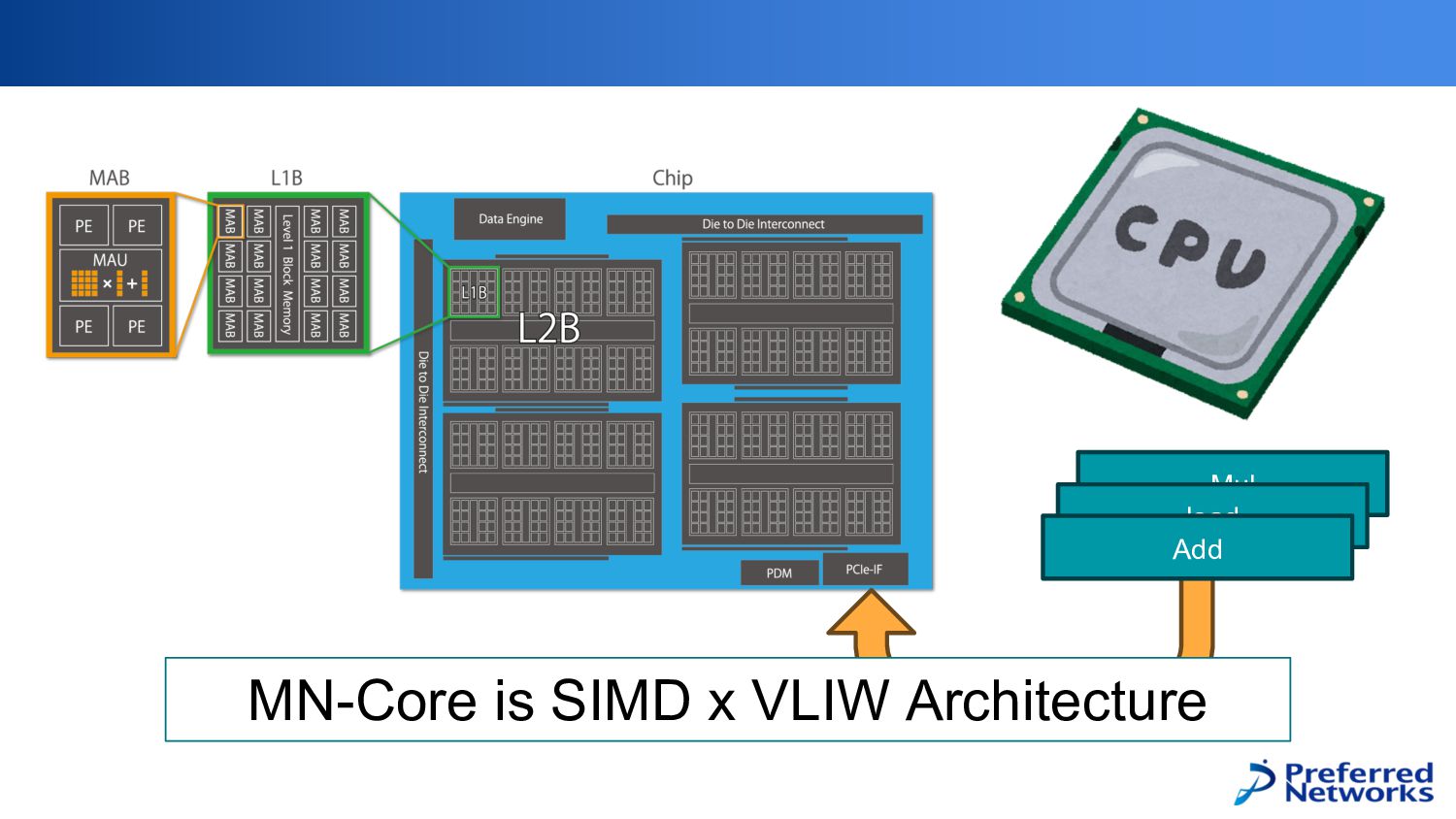
Mul load Add ホストプロセッサ上で命令列を生成し、PCIe経由で流し込む
• MN-Coreにおける命令とは以下のように定義されている ◦ PE命令 ◦ MAU命令 ◦ L1B 転送命令(L1B <=>
MAB間転送命令) ◦ L2B 転送命令(L2B <=> L1B間転送命令) ◦ DRAM / PDM 転送命令(DRAM <=> L2B間転送命令) • これらは、すべて同時に発行することができる MN-Coreにおける命令とは︖ PE命令 MAU命令 L1B転送命令 L2B転送命令 DRAM転送命令 Very Long Instruction Word
• PE命令, MAU命令は更に、4サイクルの間、同一命令を実行する ◦ サイクルごとにアドレスをインクリメントする仕組み、または異なるアドレスを 指定する仕組みが存在する ◦ dvadd $lm0v $lr0v
$ln0v ▪ LM0のアドレス0とGRF0のアドレス0を開始位置として、64bit長単位でアクセスし、読 み込んだ2つの64bit長データに対して倍精度加算を行う。結果を64bit長単位でアクセス し、LM1のアドレス0を開始位置とする場所に書き込む。各アドレスは毎サイクル1ず つインクリメントされる。 ◦ hvmul $lm0v $lr0v $ln0v ▪ LM0のアドレス0とGRF0のアドレス0を開始位置として、64bit長単位でアクセスし、読 み込んだ2つの64bit長データに対して、半精度 * 4と見なして半精度乗算を行う。結果 を64bit長単位でアクセスし、LM1のアドレス0を開始位置とする場所に書き込む。各ア ドレスは毎サイクル1ずつインクリメントされる。 MN-Coreにおける命令実⾏
• 条件分岐は、Maskとして表現できる ◦ 各種SIMD命令によくある、フラグを見て特定のスロットのみ出力するcmp + selectと同様のイメージ ◦ dvadd/0101 $lm0v $lr0v
$ln0v ▪ LM0のアドレス0とGRF0のアドレス0を開始位置として、64bit長単位でアクセス し、読み込んだ2つの64bit長データに対して倍精度加算を行う。結果を64bit長単 位でアクセスし、LM1のアドレス0を開始位置とする場所に、2サイクル目と4サ イクル目のみ書き込む。各アドレスは毎サイクル1ずつインクリメントされる。 MN-Coreにおける命令実⾏
Mul load Add MN-Core is SIMD x VLIW Architecture
• Himeno Benchmark ◦ 某アクセラレータ比で 4.7倍の実行性能(19.6倍の実行効率) を達成 Himeno bench on
MN-Core 某Accelerator MN-Core メモリ帯域 4.8 TB/s 400 GB/s 理論性能 33.5 TFlops 8.2 TFlops 実行性能 1.27 TFlops 5.99 TFlops 実行効率 3.79 % 73.05 %
• どのようにしてHimeno benchmarkを高速化したのか? ◦ Himeno benchmarkはStencil計算のベンチマーク ▪ 計算特性としてメモリ帯域で律速する ▪ 計算の並列化を行うためには袖領域の交換が必要になる
▪ ナイーブに実装すると、袖交換にはかなり時間がかかる • これを解決するために… ◦ Near-memory Computing ◦ 演算とデータ転送のオーバーラップ Himeno bench on MN-Core ステンシル計算の高速化のための C++テンプレートによるGPUカーネル生成 https://ipsj.ixsq.nii.ac.jp/ej/?action=repository_uri&item_id=142401&file_id=1&file_no=1
• Near-memory Computingとは? Near-memory Computing From Google Gemini
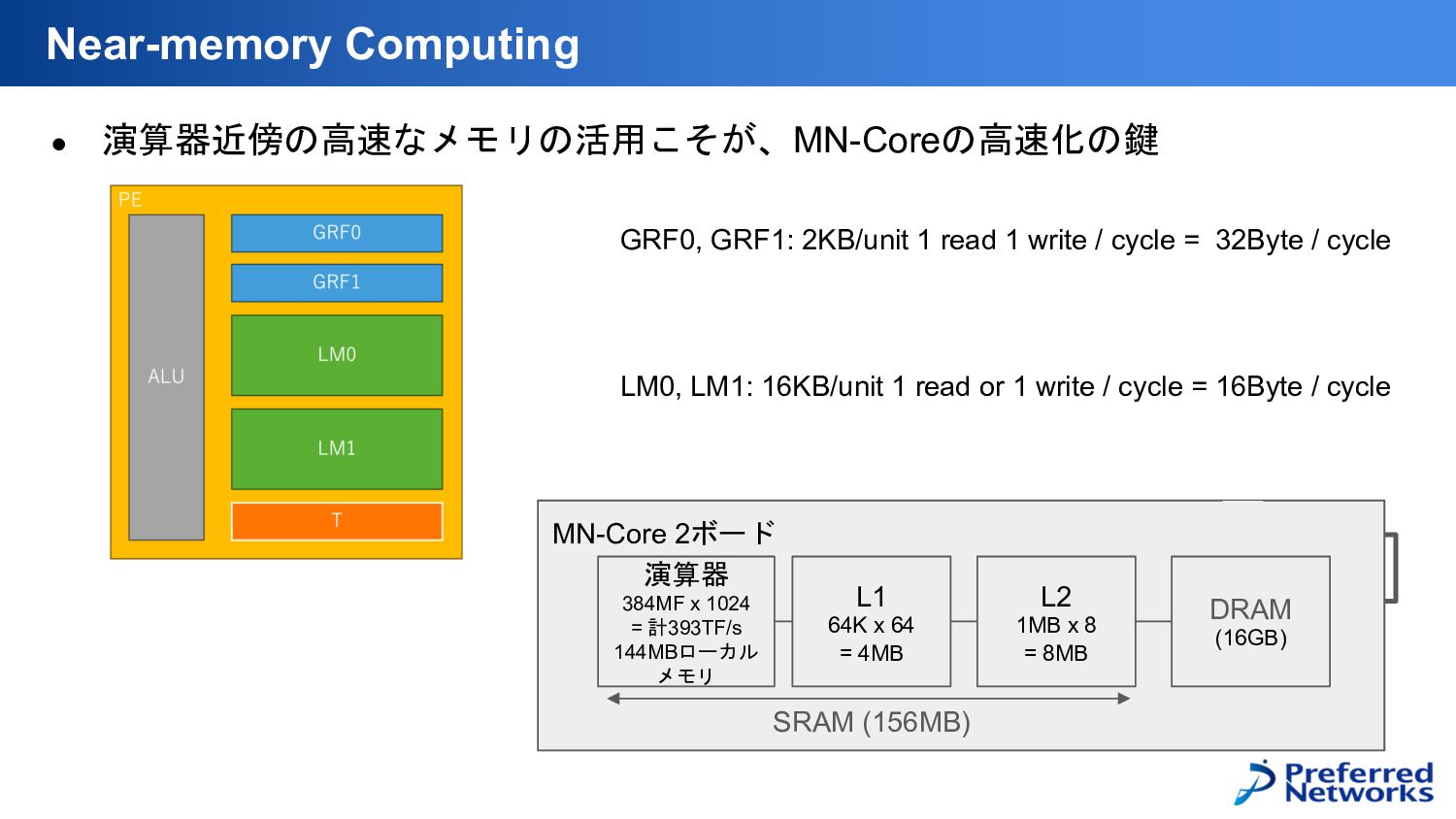
• 演算器近傍の高速なメモリの活用こそが、MN-Coreの高速化の鍵 Near-memory Computing MN-Core 2ボード L1 64K x 64
= 4MB 演算器 384MF x 1024 = 計393TF/s 144MBローカル メモリ L2 1MB x 8 = 8MB DRAM (16GB) SRAM (156MB) GRF0, GRF1: 2KB/unit 1 read 1 write / cycle = 32Byte / cycle LM0, LM1: 16KB/unit 1 read or 1 write / cycle = 16Byte / cycle
• 演算器近傍のメモリが巨大だと、計算にどういった影響がある? ◦ DRAMへのアクセスを緩和することができる ▪ メモリ帯域ネックのアプリケーションの性能を向上させうる可能性があ る ▪ Temporal Blocking
◦ DRAMにデータを退避するのではなく、再計算してデータを再構成する ▪ 再計算を用いたMN-Core向けコンパイラの最適化 Near-memory Computing
演算とデータ転送のオーバーラップ PE命令 MAU命令 L1B転送命令 L2B転送命令 DRAM転送命令 VLIW
• ただし、これを行うためには、制約を満たすレジスタ割り付け問題を解く必要が ある 演算とデータ転送のオーバーラップ GRF0, GRF1: 2KB/unit 1 read 1
write / cycle = 32Byte / cycle LM0, LM1: 16KB/unit 1 read or 1 write / cycle = 16Byte / cycle PE : ladd $lm0 $ln0 $lr0 MAU: dvadd $lm2 $ln2 $lr2 L1B : l1bmp $lb0 $ln16
• ただし、これを行うためには、制約を満たすレジスタ割り付け問題を解く必要が ある 演算とデータ転送のオーバーラップ GRF0, GRF1: 2KB/unit 1 read 1
write / cycle = 32Byte / cycle LM0, LM1: 16KB/unit 1 read or 1 write / cycle = 16Byte / cycle PE : ladd $lm0 $ln0 $lr0 MAU: dvadd $lm2 $ln2 $lr2 L1B : l1bmp $lb0 $ln16 SRAMのアクセス制約に引っかかっている!
• SRAM割り付けパズル ◦ GRF0, GRF1: 1 read and 1 write
/ cycle ▪ 書き込み後に同一アドレスから読めるようになるまでに2サイクル必要 ◦ LM0, LM1: 1 read or 1 write / cycle ▪ 書き込み後に同一アドレスから読めるようになるまでに2サイクル必要 ◦ T register ▪ 書き込み後に読めるようになるまで1サイクル必要 ◦ Forwarding Path 演算とデータ転送のオーバーラップ
• Himeno Benchmark ◦ 某アクセラレータ比で 4.7倍の実行性能(19.6倍の実行効率) を達成 Himeno bench on
MN-Core 某Accelerator MN-Core メモリ帯域 4.8 TB/s 400 GB/s 理論性能 33.5 TFlops 8.2 TFlops 実行性能 1.27 TFlops 5.99 TFlops 実行効率 3.79 % 73.05 %
• 本日公開のVSM Samplesでは、技巧的なコードがいくつもあるはず… ◦ ぜひ皆さん、お手元でコンパイルして実行してみてください 実際にはどのようなコードを書いているか︖
Q: MN-Coreって アセンブリでコード書くんです か?
A:そんなことはないです
MN-Coreのソフトウェア開発環境 MNGraph L3IR DNN op level, SIMD parallelism strategy, …...
Global Layout Planner Re- computation Scheduler L2IR ndarray op level, optimized DNN op impl, …... Generic Conv Impl. MNTensor PEVector Reshape Impl. L1IR MN-core op level, memory allocation, scheduling, optimization, …... Layer Impl. Scheduling Graph Instruction Merger ONNX model
• 静的な計算グラフが手に入ることを前提に最適なコード生成を行うDL向けコンパイラ • この仕組みを応用(あるいは類似のことをする別種の仕組みを用意) すれば、汎用計算も可能 になるのでは…? MN-Coreのソフトウェア開発環境 深層学習の 計算グラフ MN-Core上の
プログラム いい感じに 何とかする 深層学習の 計算グラフ MN-Core上の プログラム いい感じに 何とかする 汎用計算 言語処理系
MN-Coreのソフトウェア開発環境(現在開発中) OpenACC、粒⼦法等むけDSL 中間表現 共通⾼レベル表現 低レベル表現 OpenCL(拡張) MN-Core 実⾏コード OpenCLコード例(構想) 現在鋭意開発中です
開発者募集中です
• MN-Core Architecture について解説しました。 • MN-Core でHimeno benchmarkが高速に動作することを示しました。 ◦ MN-CoreでのHimeno
benchmarkの詳細については、また別途どこかで論文等にしま す • MN-Core のソフトウェア開発環境を示しました ◦ ソフトウェア開発環境を開発する人も、MN-Core上のアプリケーションを開発する人 も絶賛募集中です。ぜひ皆様ご一緒しましょう まとめ
Making the real world computable
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}