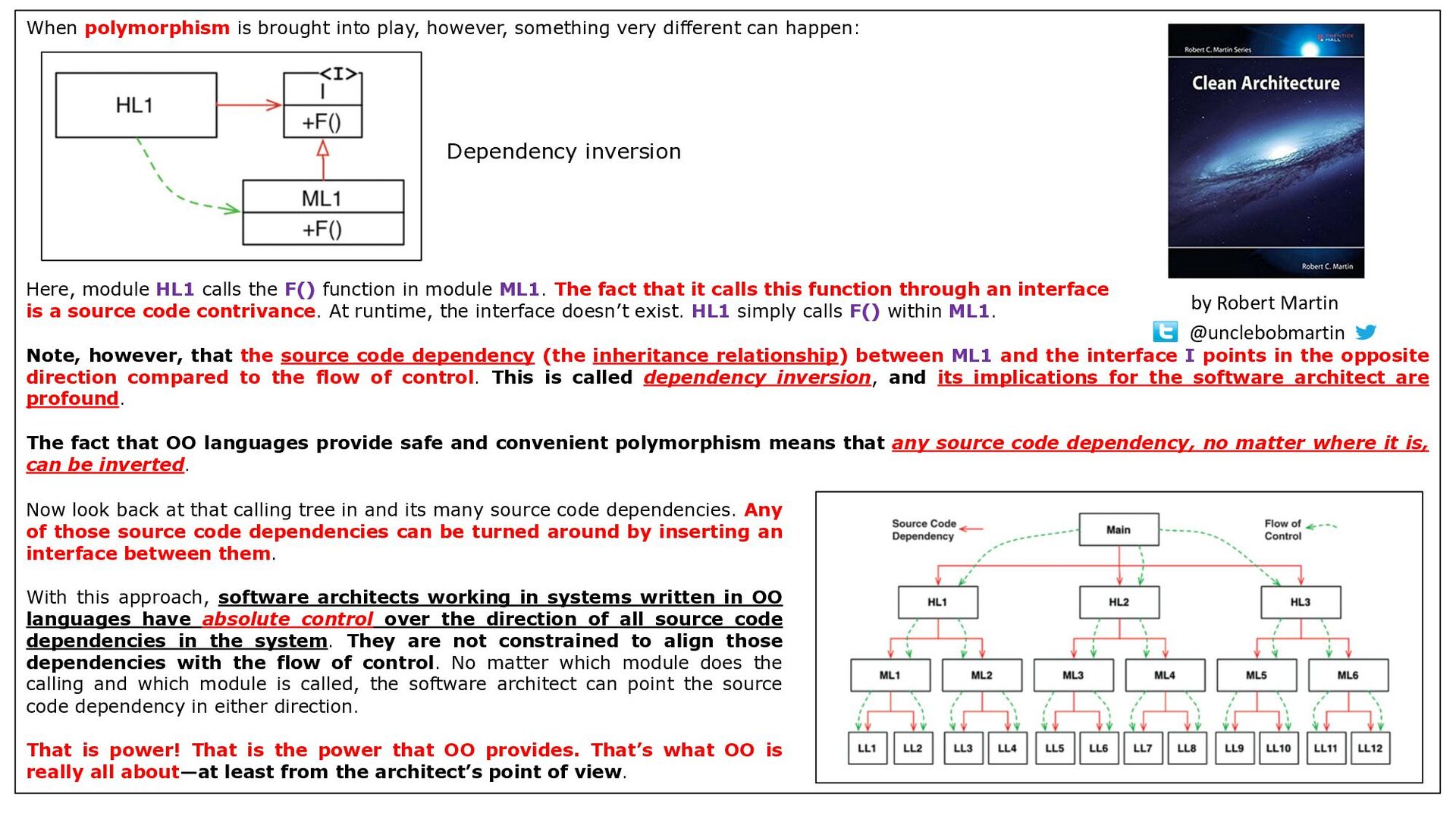
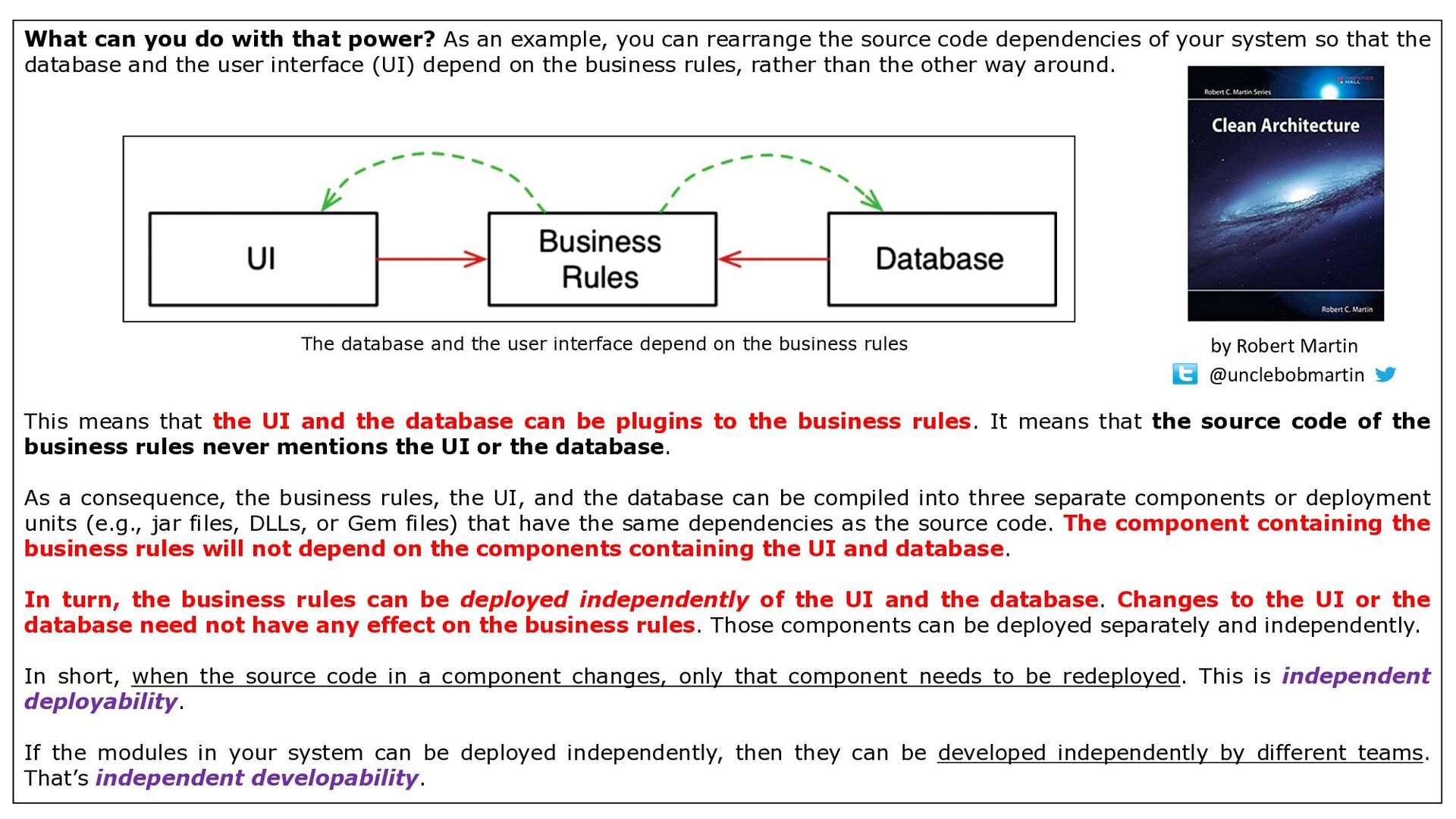
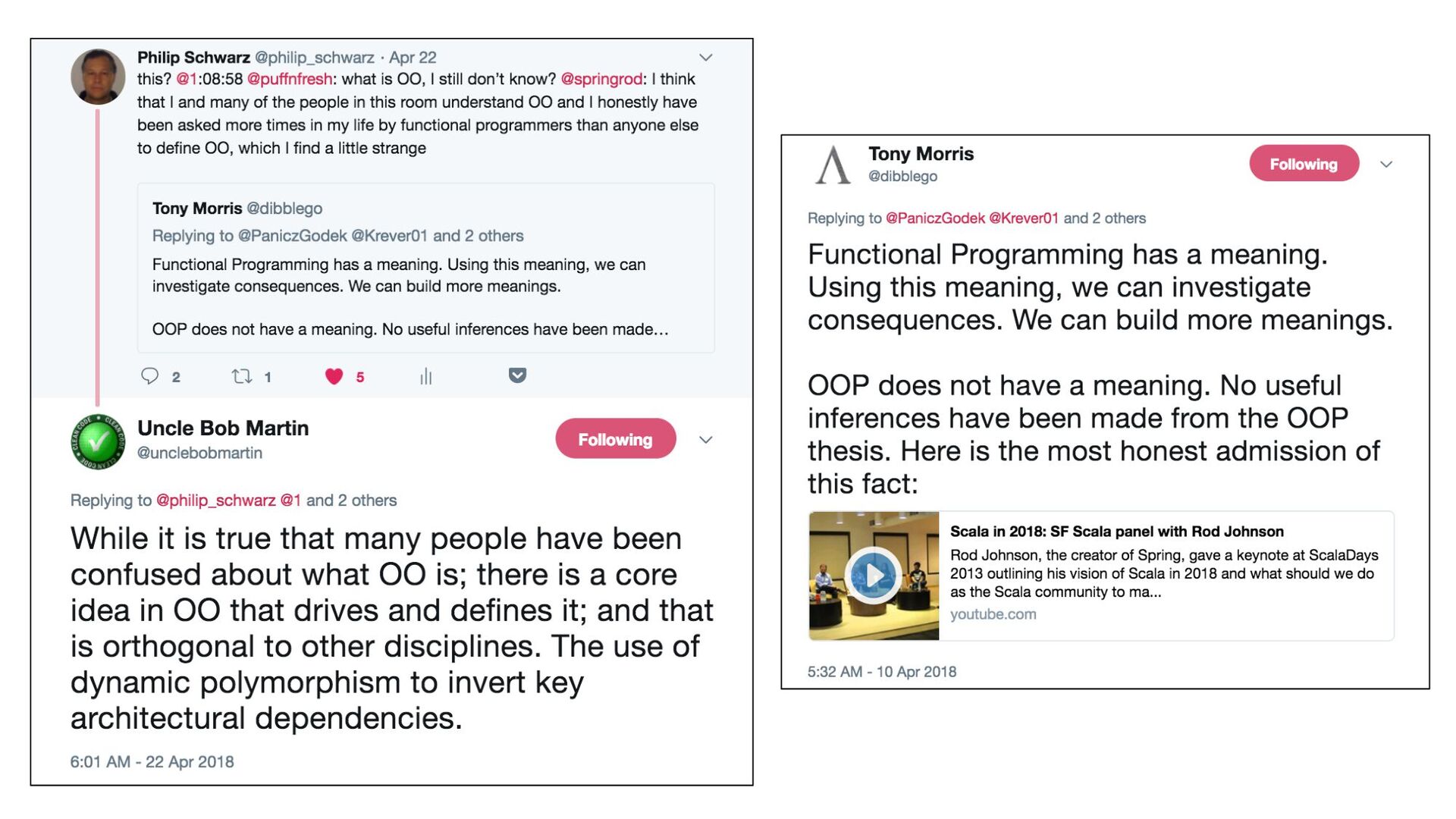
Inspired by the following tweet by Robert Martin: "While it is true that many people have been confused about what OO is; there is a core idea in OO that drives and defines it; and that is orthogonal to other disciplines. The use of dynamic polymorphism to invert key architectural dependencies" https://twitter.com/unclebobmartin/status/988040056819539968
(download for better quality)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}