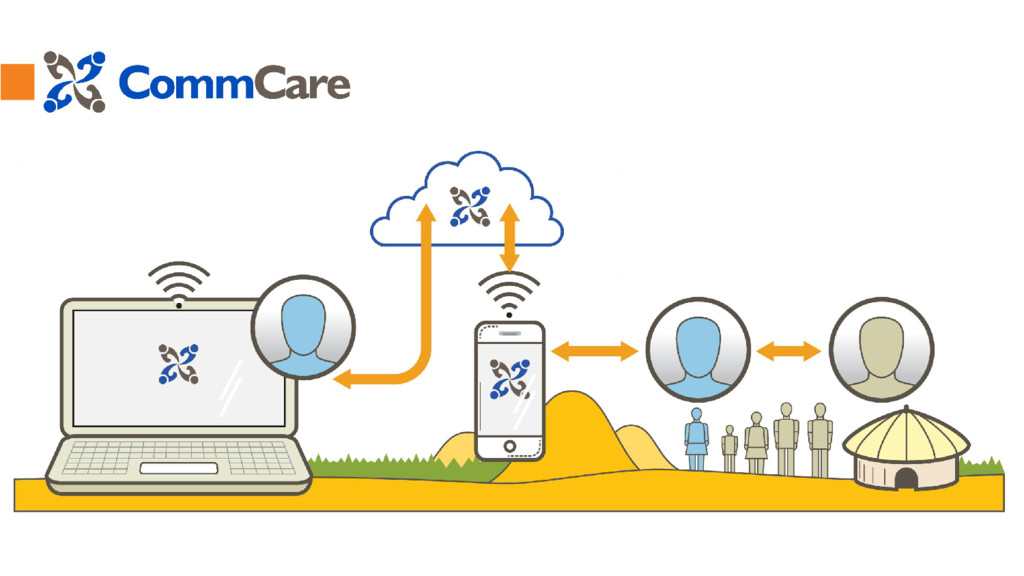
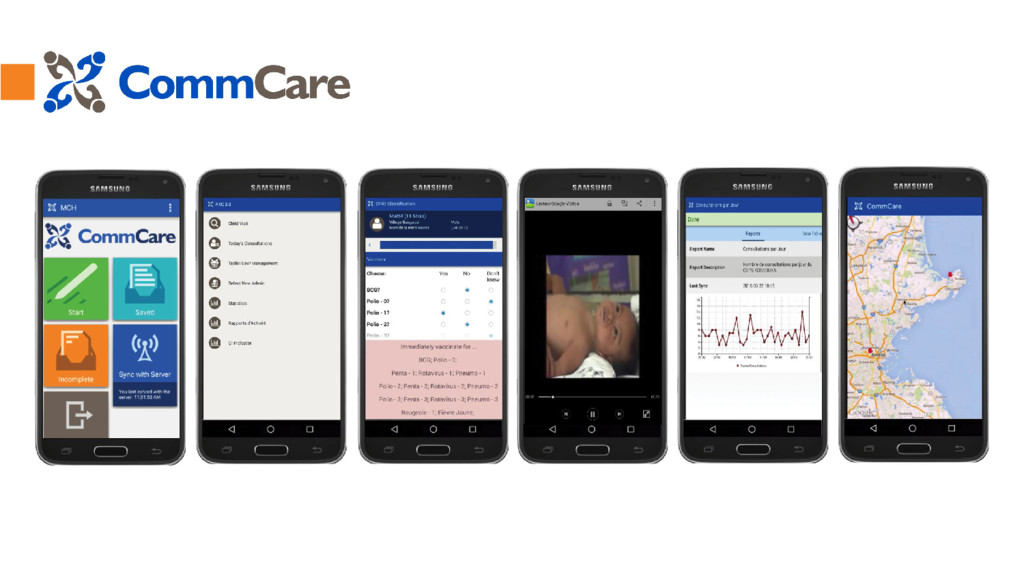
CommCare is an open source platform built in python (Django) designed for mobile data collection, longitudinal client tracking, decision support, and behavior change communication. CommCare provides an online application-building platform through which users build mobile applications for use by frontline workers.
The mobile application is used by client-facing frontline work workers as a client management, data collection and educational tool. Data entered in the mobile application is submitted to the CommCare servers.
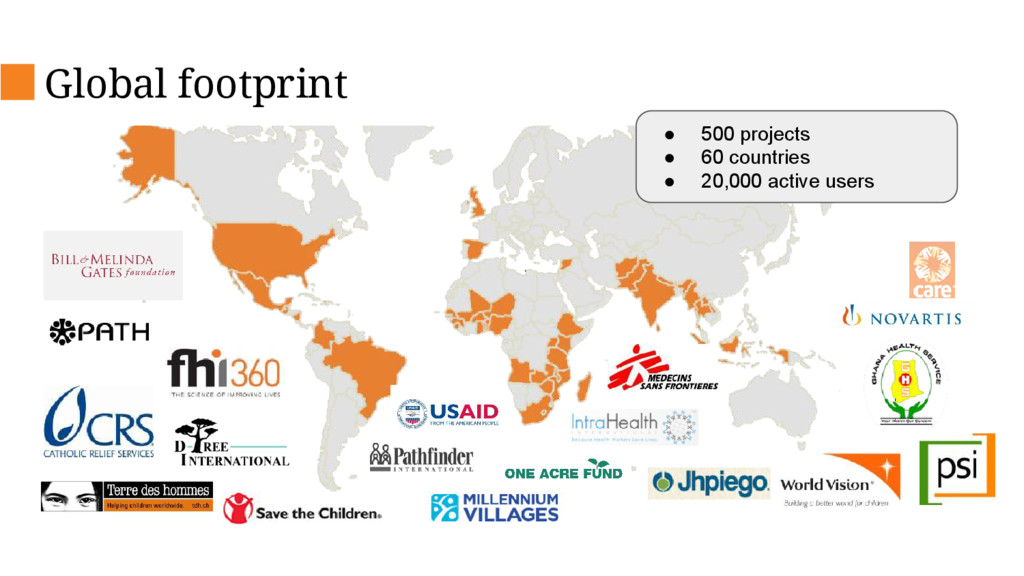
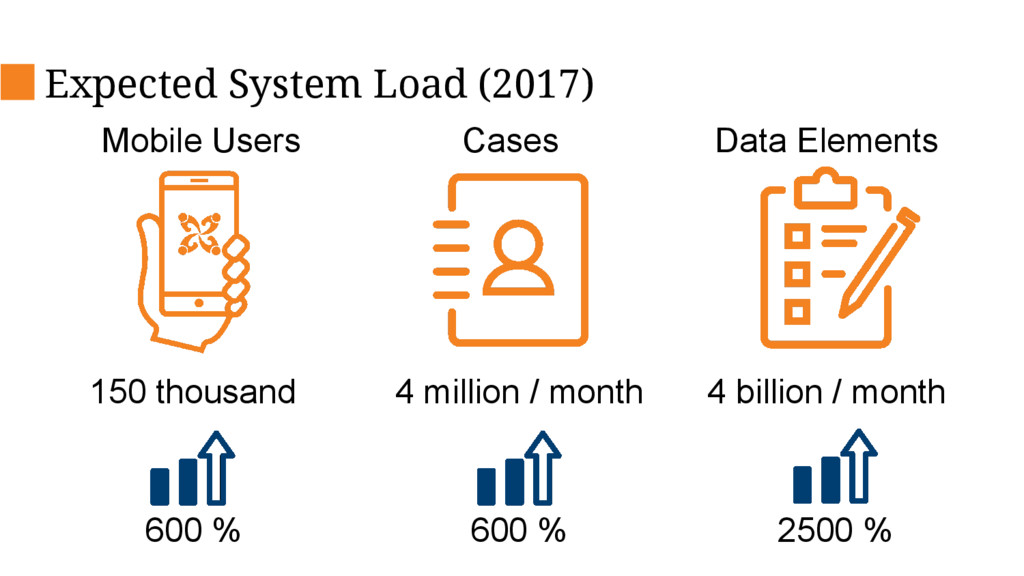
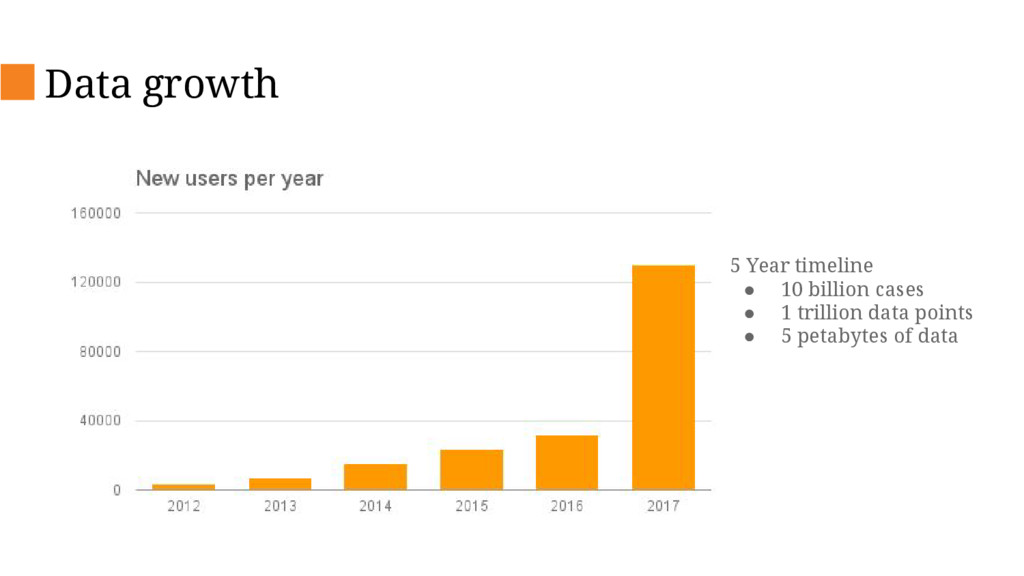
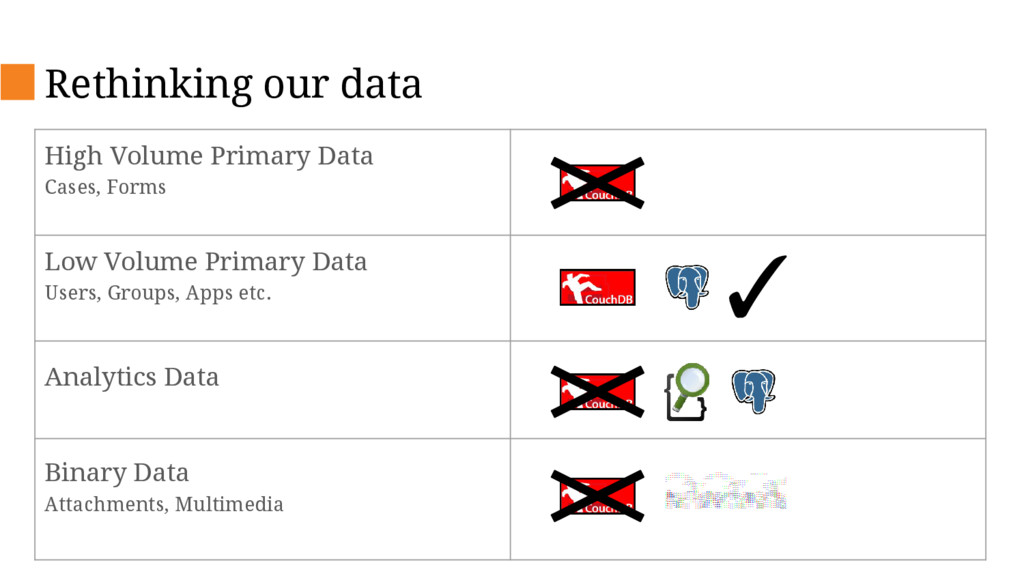
Currently CommCare supports 14K active mobile users submitting over 1 million forms a month. With new national projects launching soon, it will need to be able to support 100K users and up to 10 million monthly forms by the end of 2016 and 1.4M users within the next few years. The current architecture would not scale to that level due to limitations of the database and increasing cost of ownership so we have embarked on an internal project to re-design critical pieces of the platform in order to support this scale up.
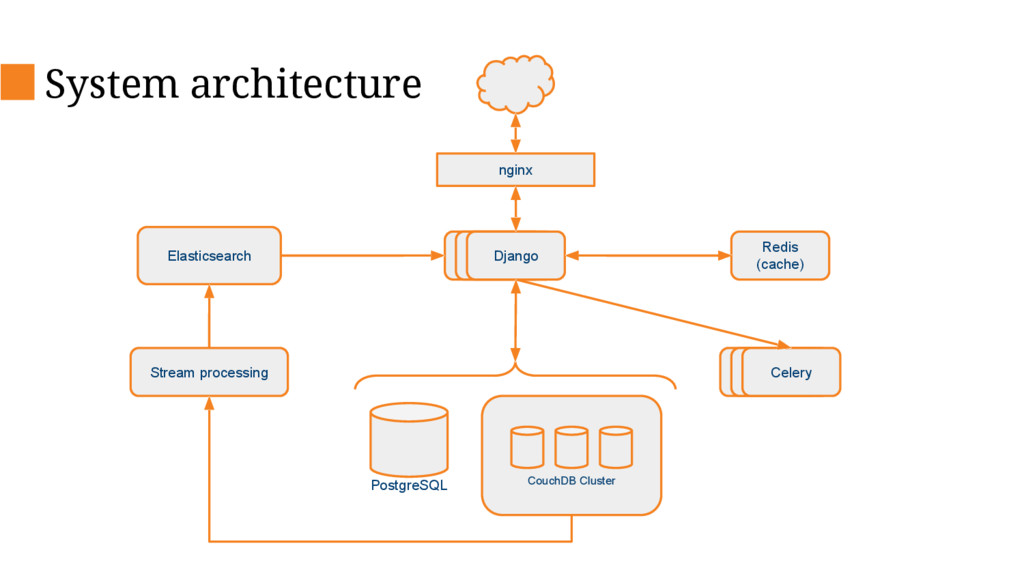
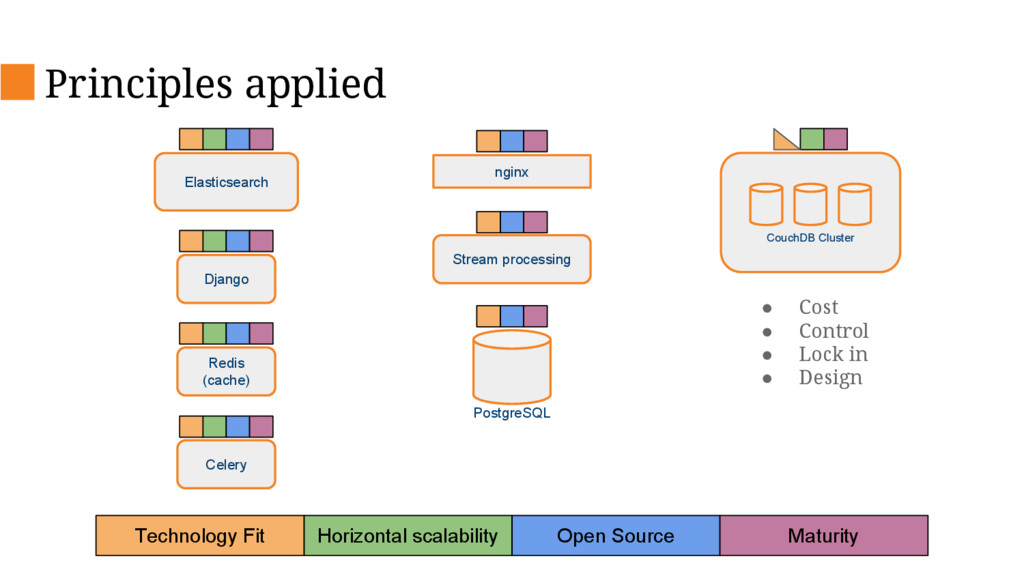
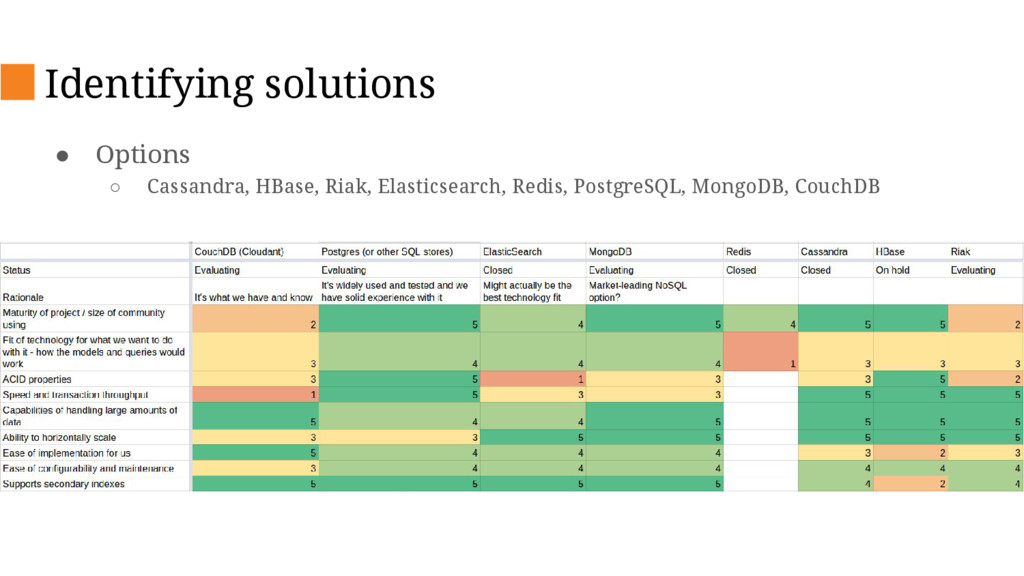
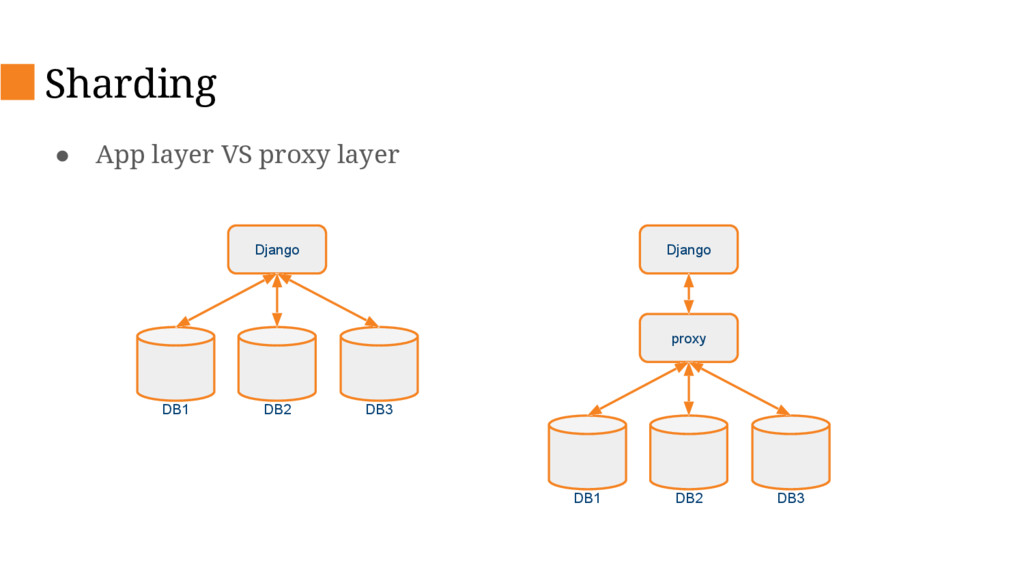
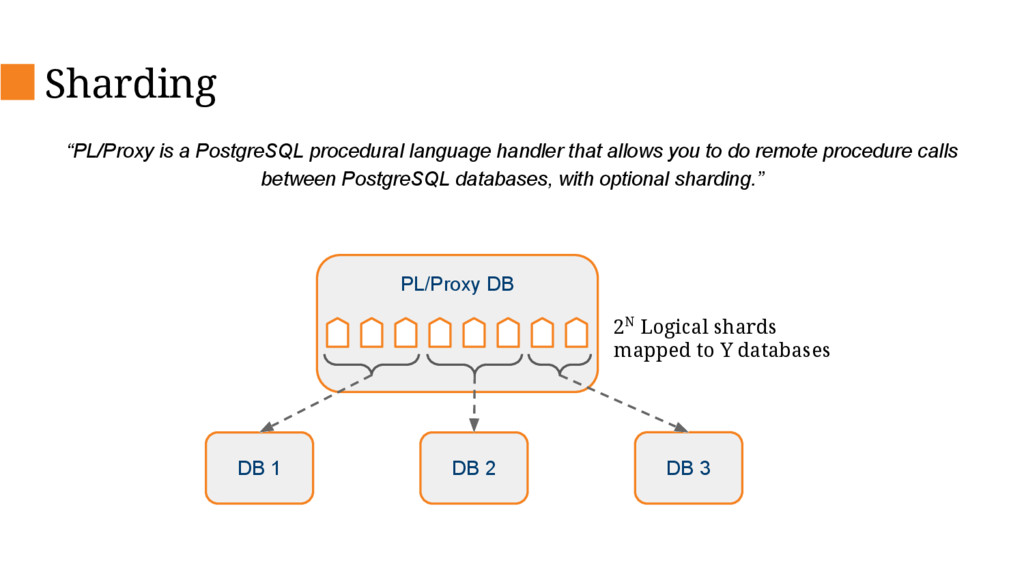
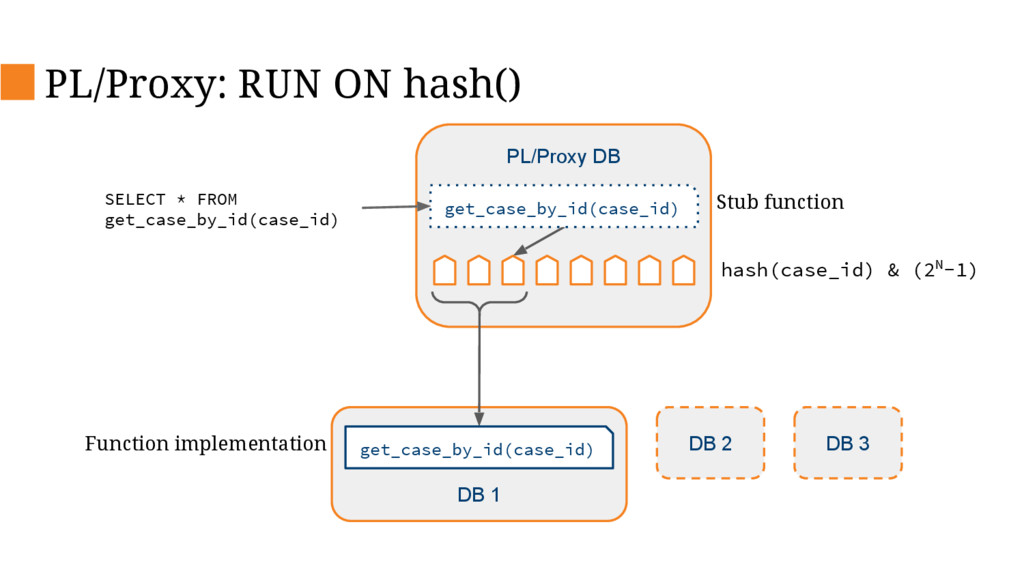
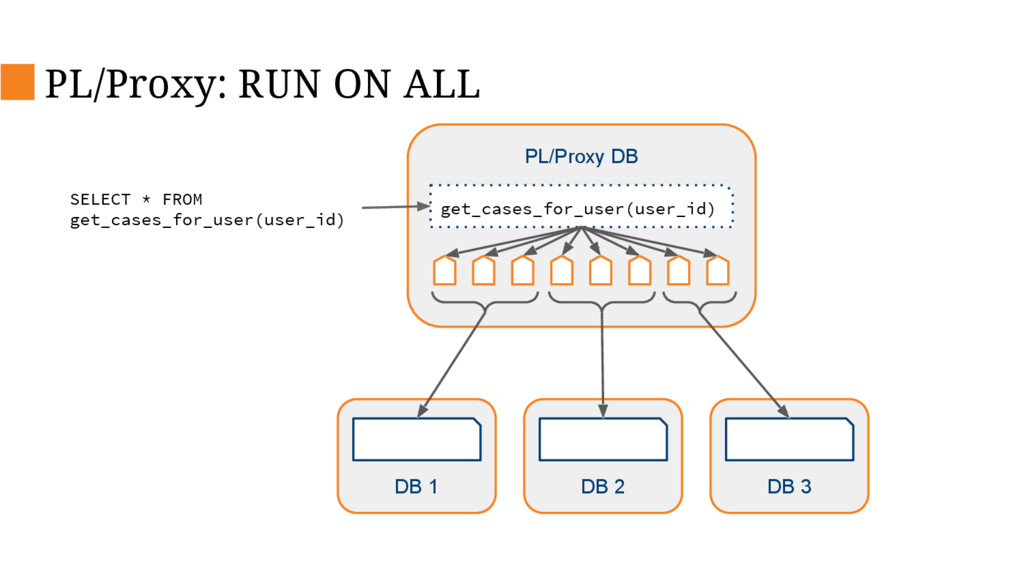
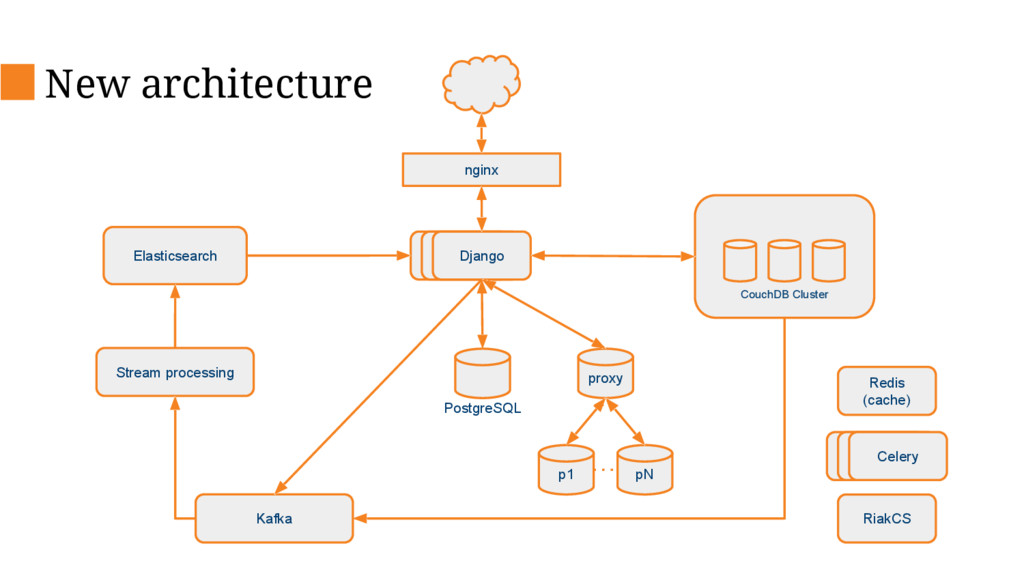
This talk will describe the old and new architecture and delve into some of the details of the new architecture and decisions we’ve made along the way such as changing our primary database, database sharding and stream processing.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
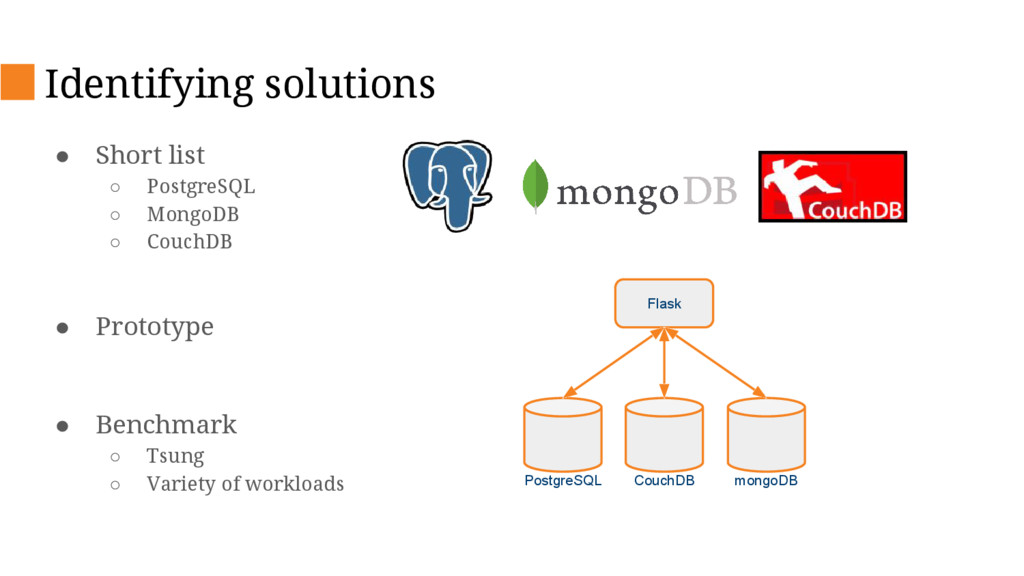{kind=link}
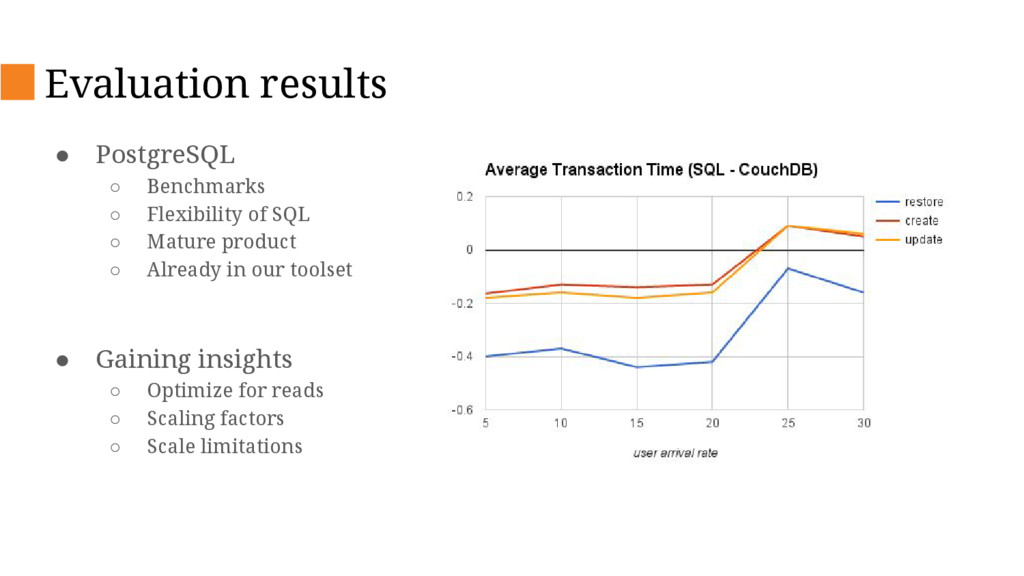{kind=link}
{kind=link}
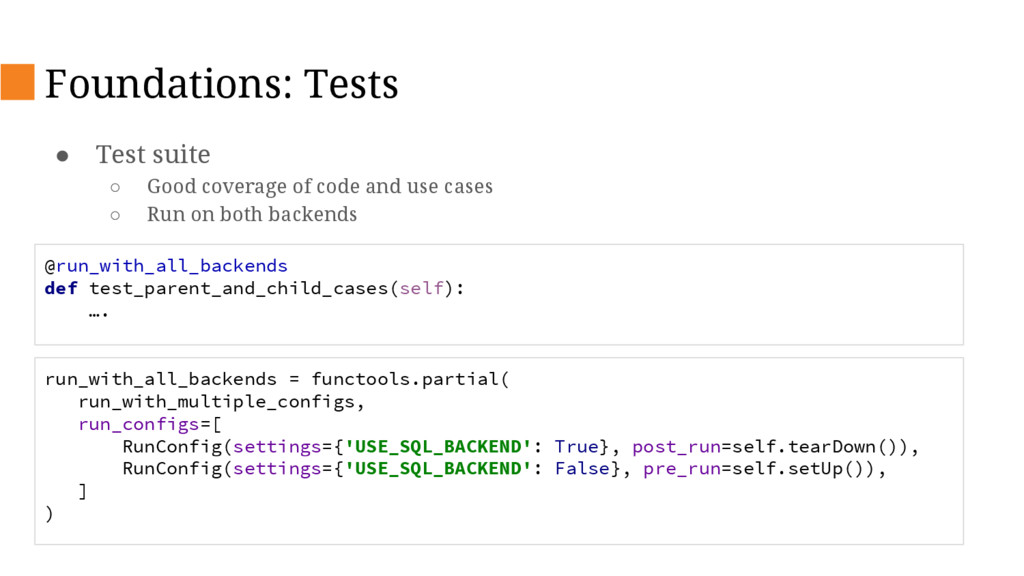{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
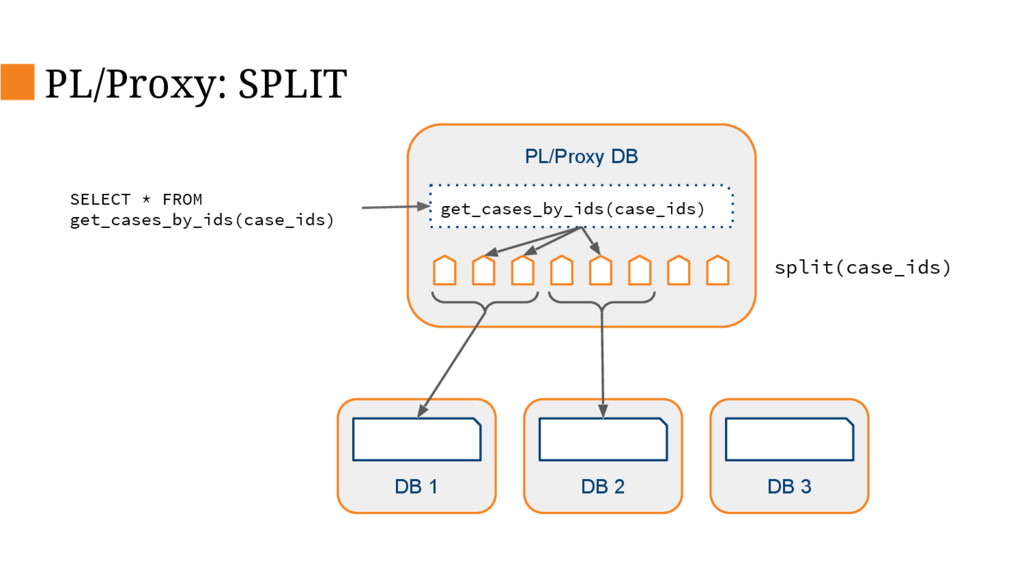{kind=link}
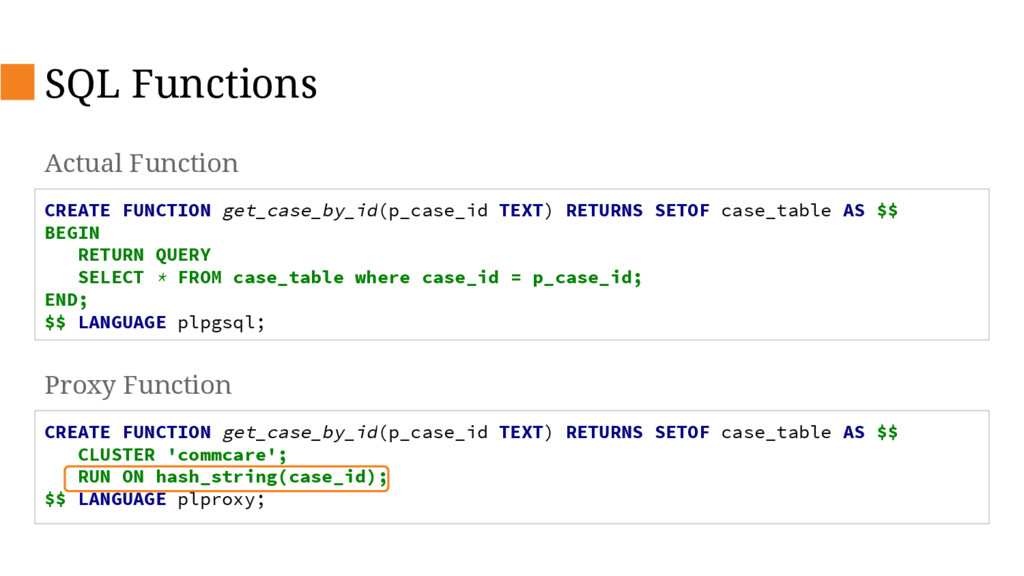{kind=link}
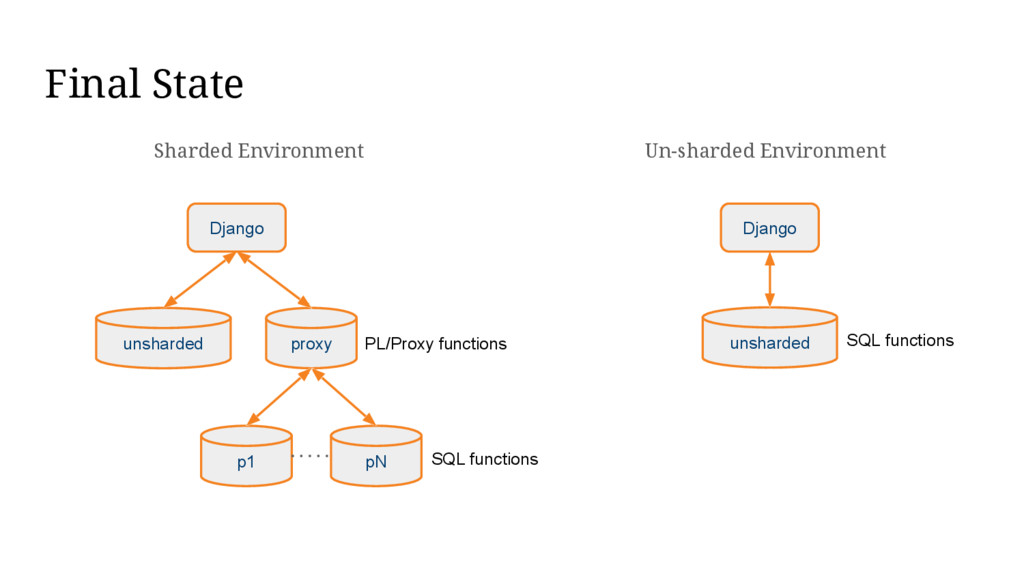{kind=link}
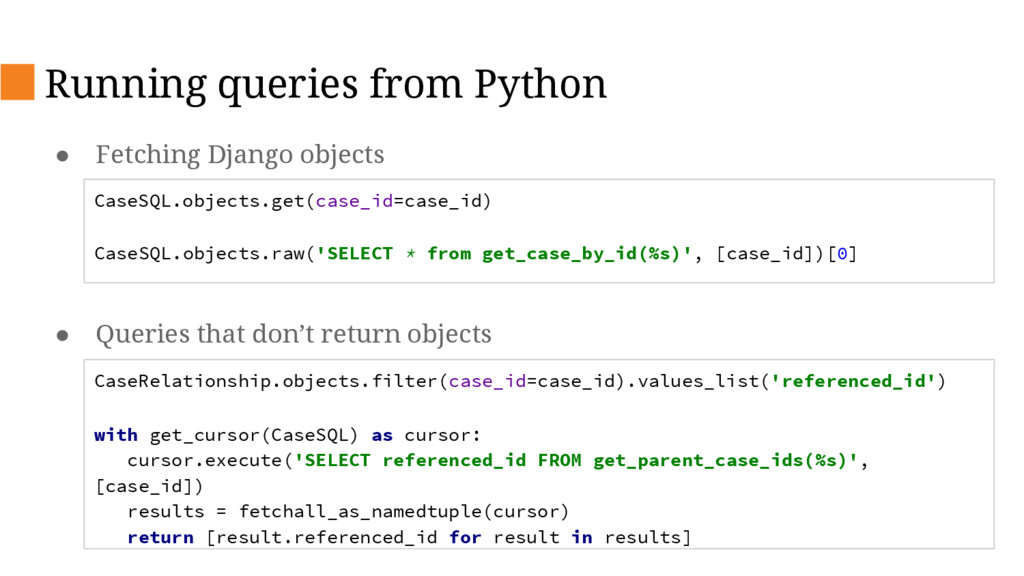{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}