AUDIENCE
data scientists (current and aspiring)
those who want to know more about data mining, analysis, and processing
those interested in functional programming
DESCRIPTION
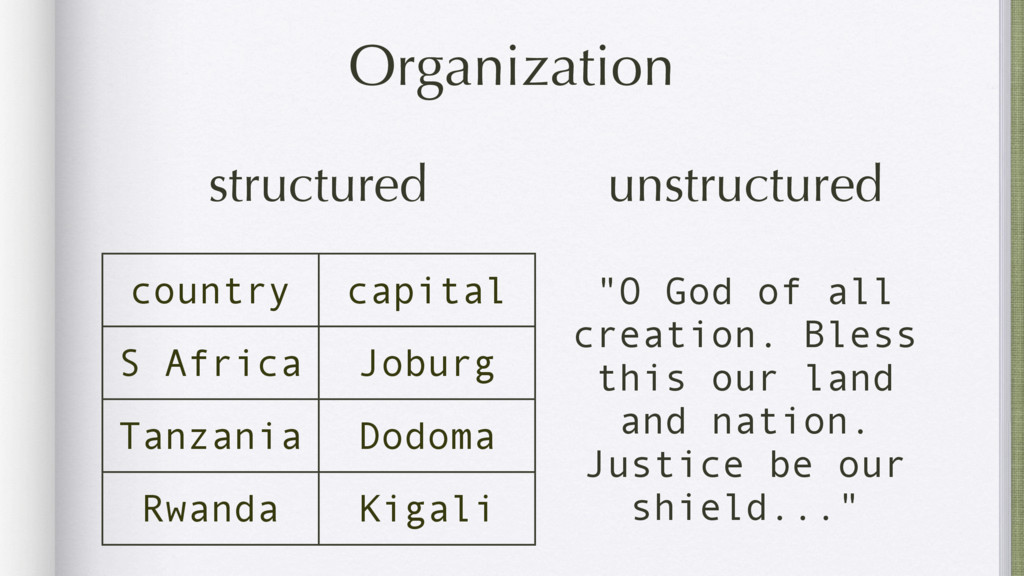
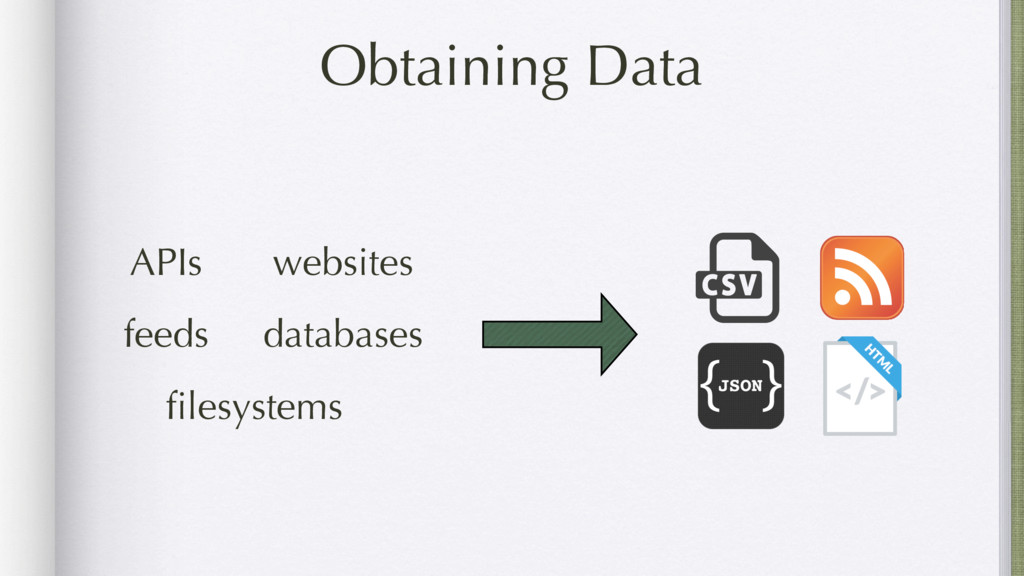
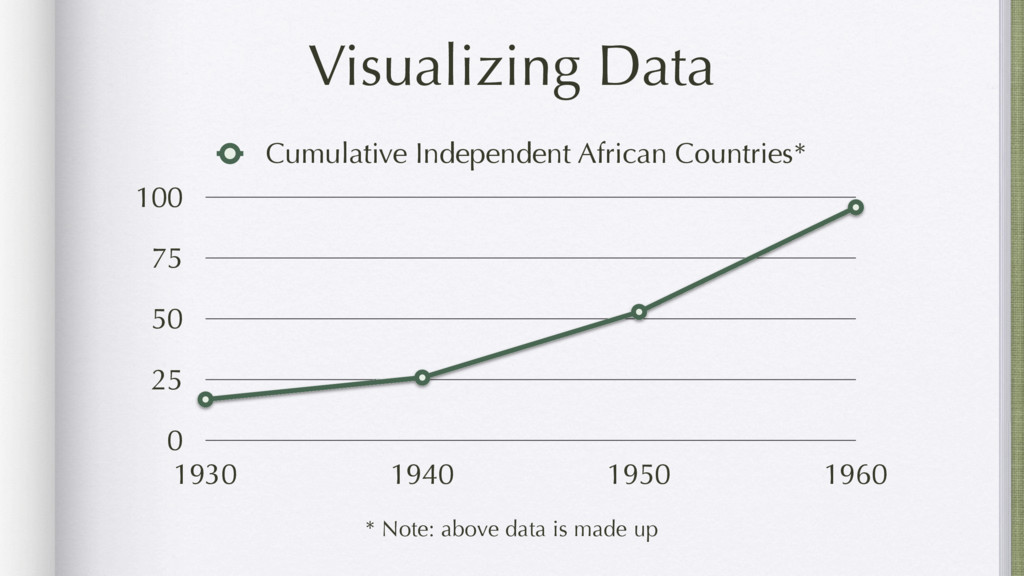
Data mining is a key skill that involves transforming data found online and elsewhere from a hodgepodge of numbers into actionable information. Using examples ranging from RSS feeds, open data portals, and web scraping, this tutorial will show you how to efficiently obtain and transform data from disparate sources.
ABSTRACT
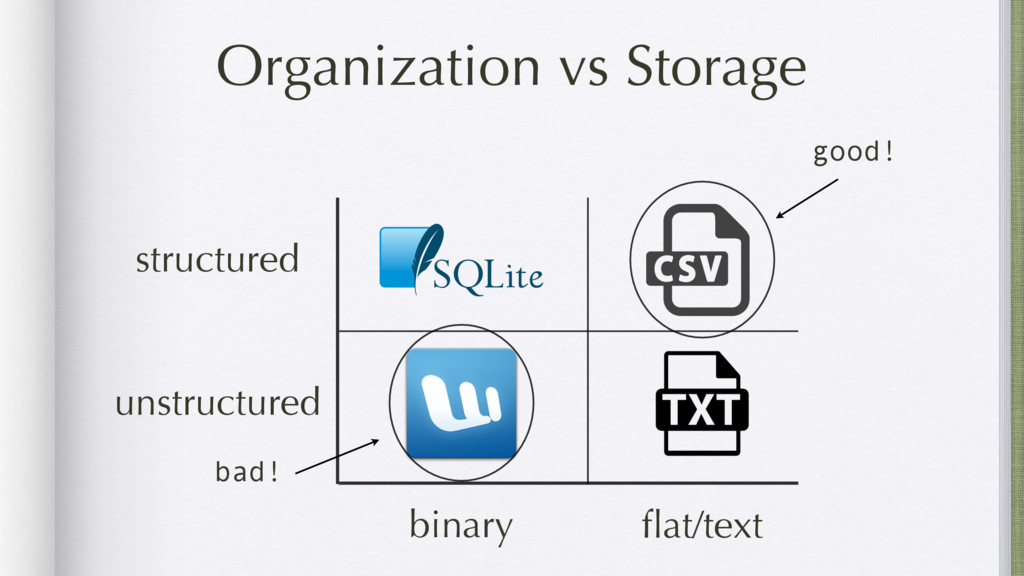
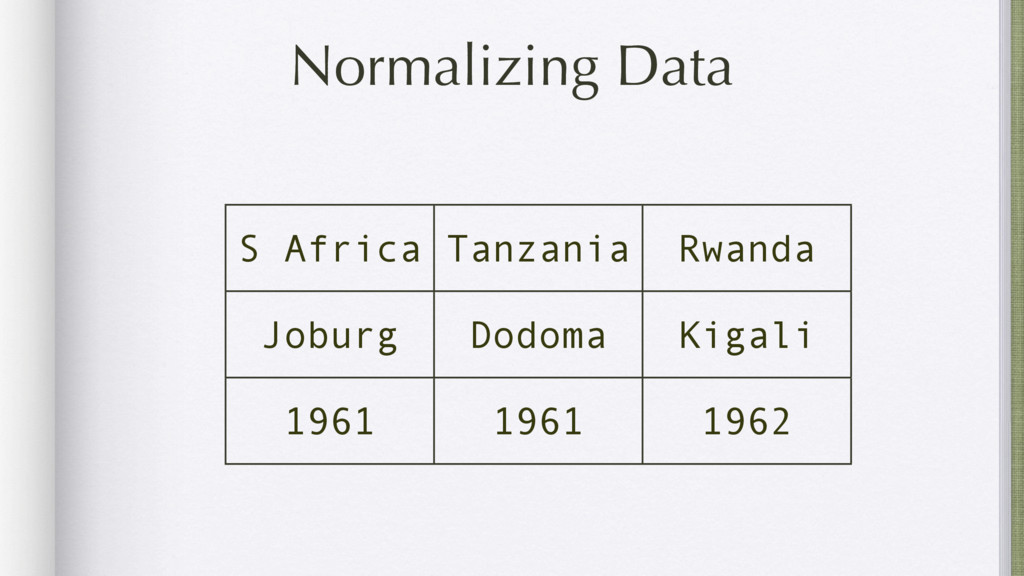
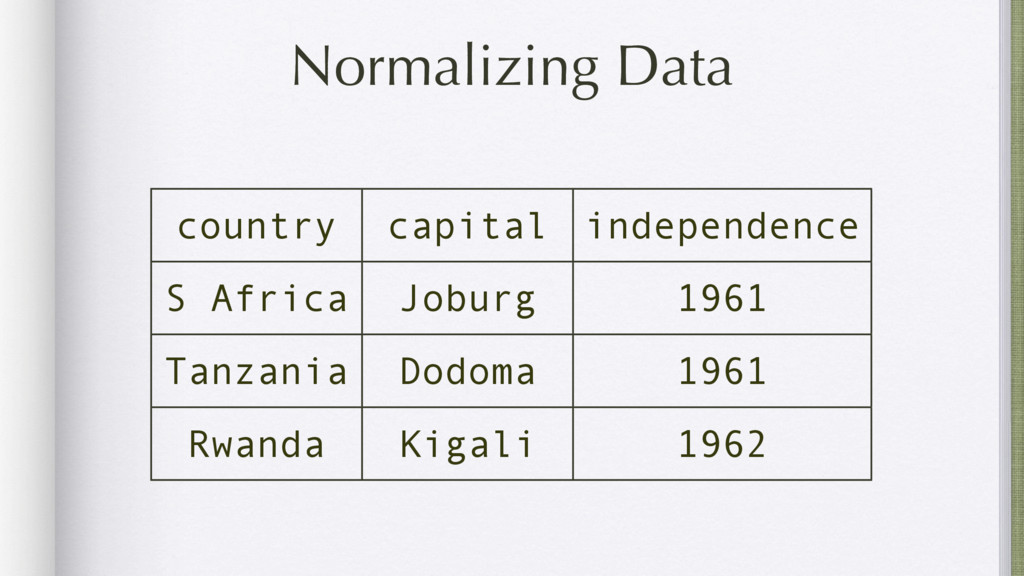
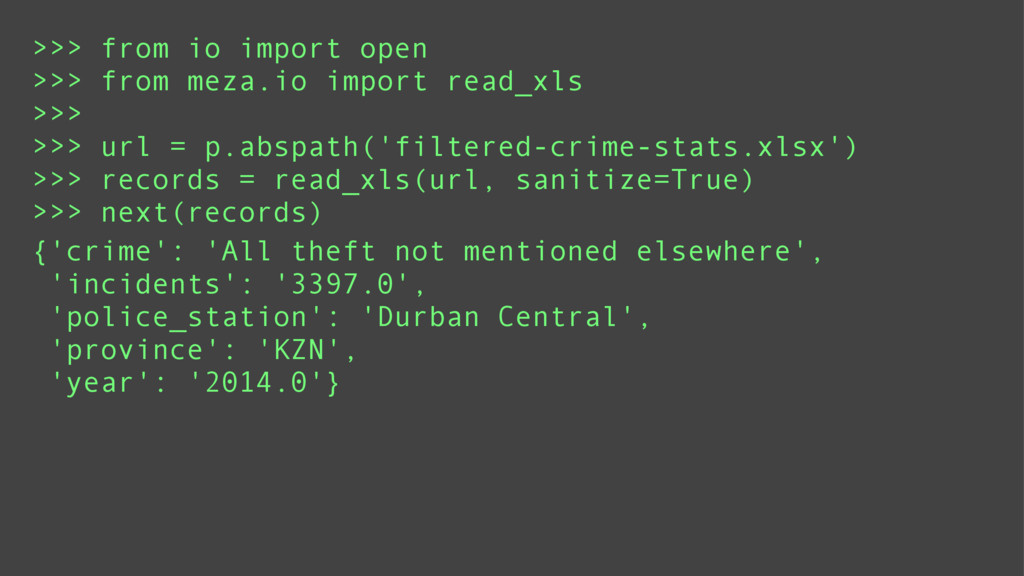
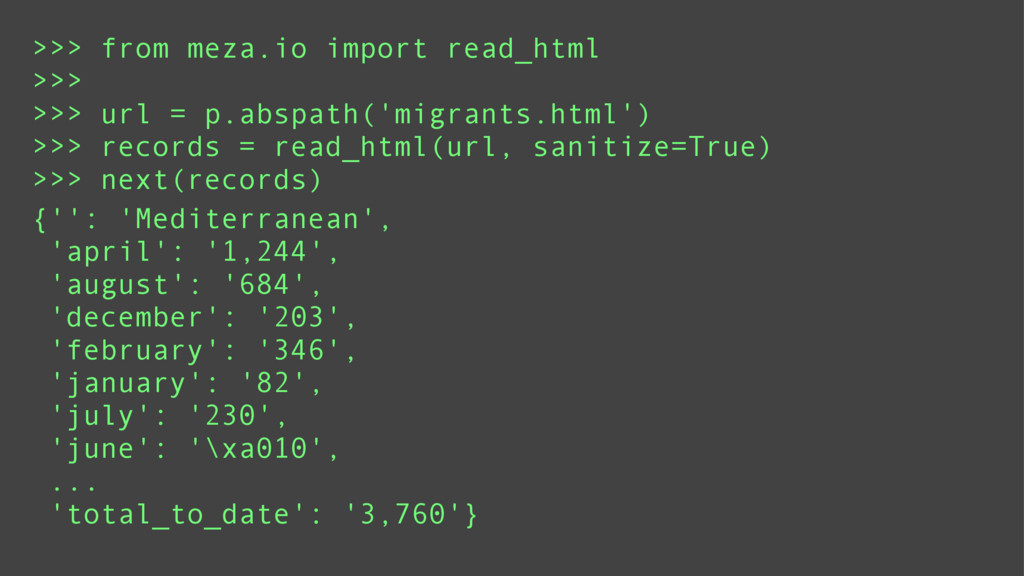
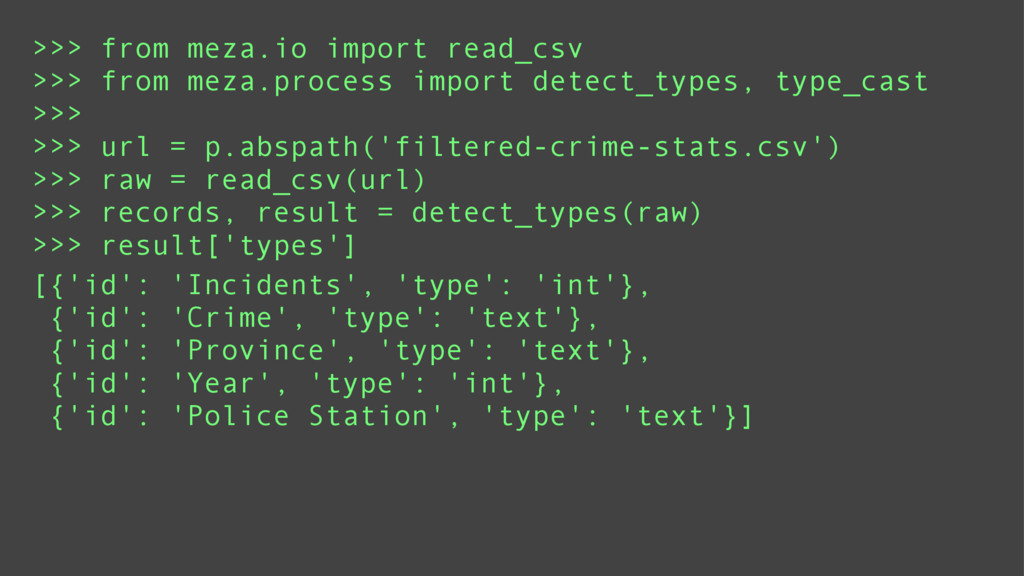
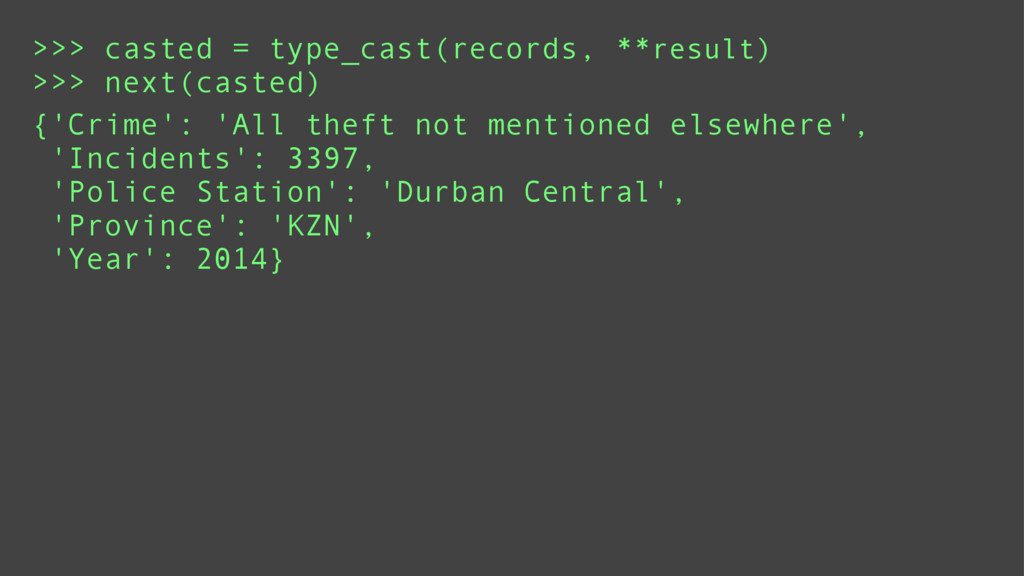
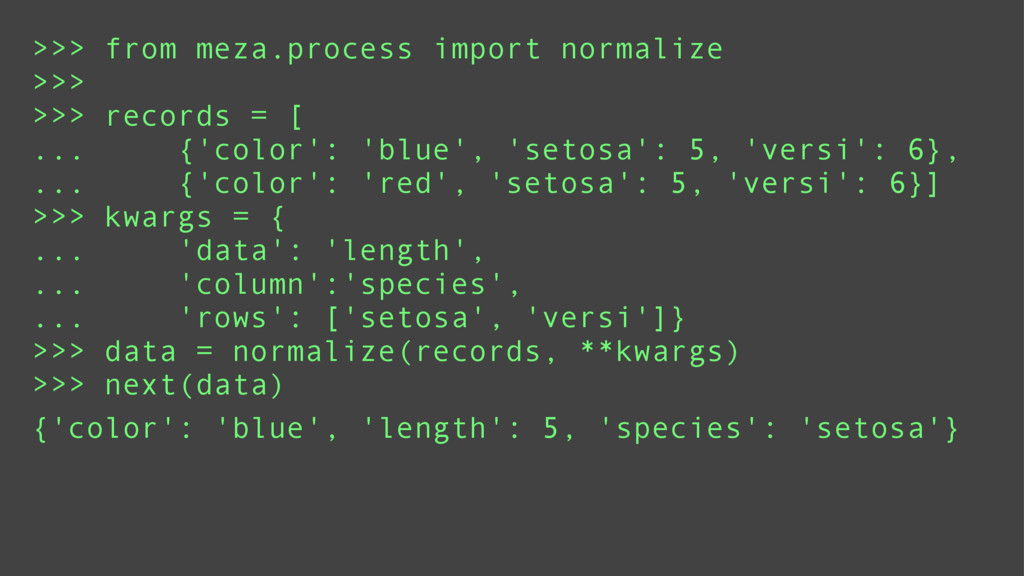
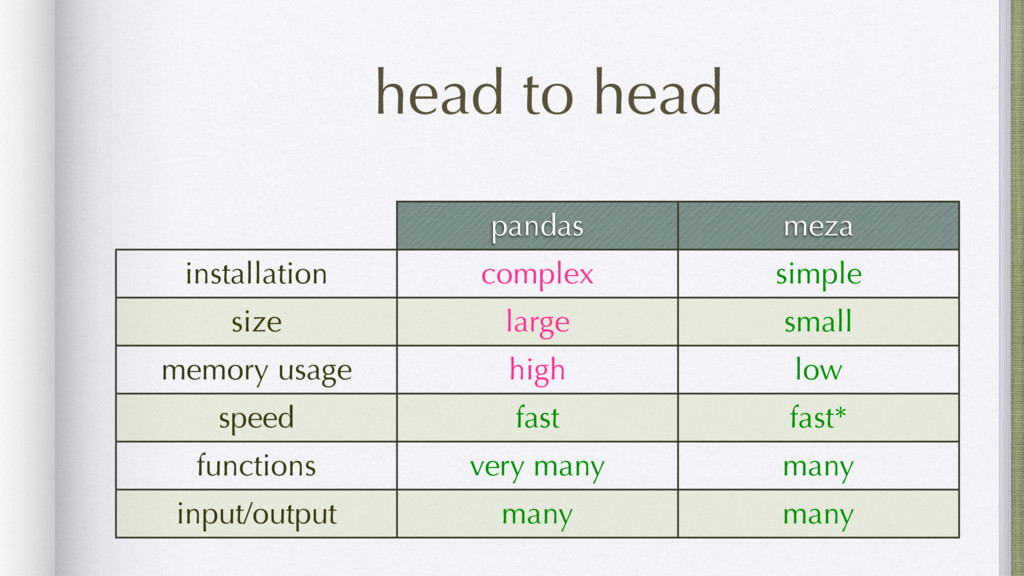
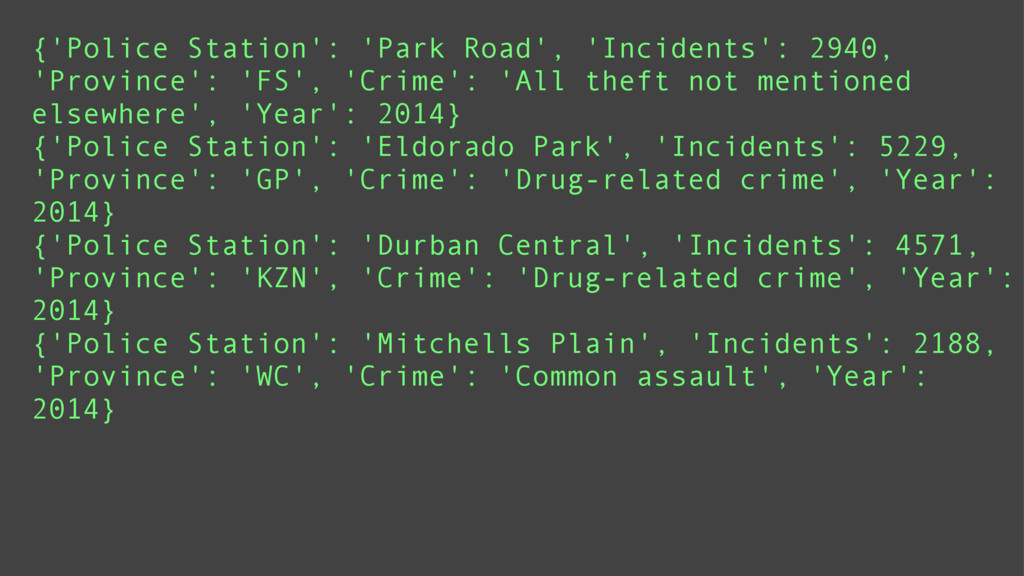
Data mining is a key skill that any self proclaimed data scientist should possess. It involves transforming data from disparate sources and a hodgepodge of numbers into actionable information. Tabular data, e.g., csv/excel files, is very common in data mining and greatly benefits from python's functional programming idioms. For better or for worse, the leading python data libraries, Numpy and Pandas, eschew the functional programming style for object-oriented programming.
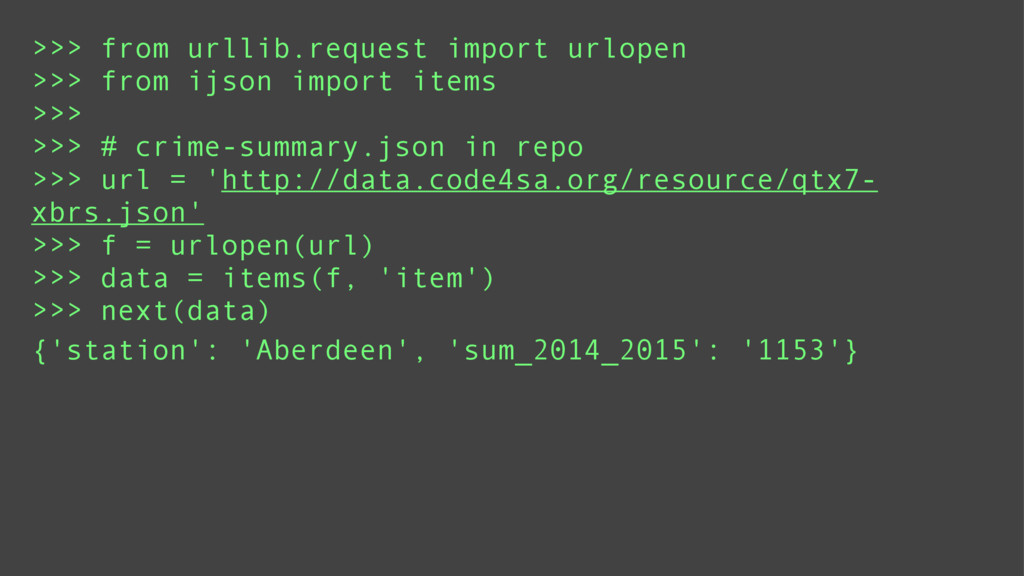
Using examples ranging from RSS feeds, the South Africa Data Portal API, raw excel files, and basic web scraping, this tutorial will show how to efficiently locate, obtain, transform, and remix data from the web. These examples will prove that you can do a lot with functional programming and without the need for Numpy or Pandas.
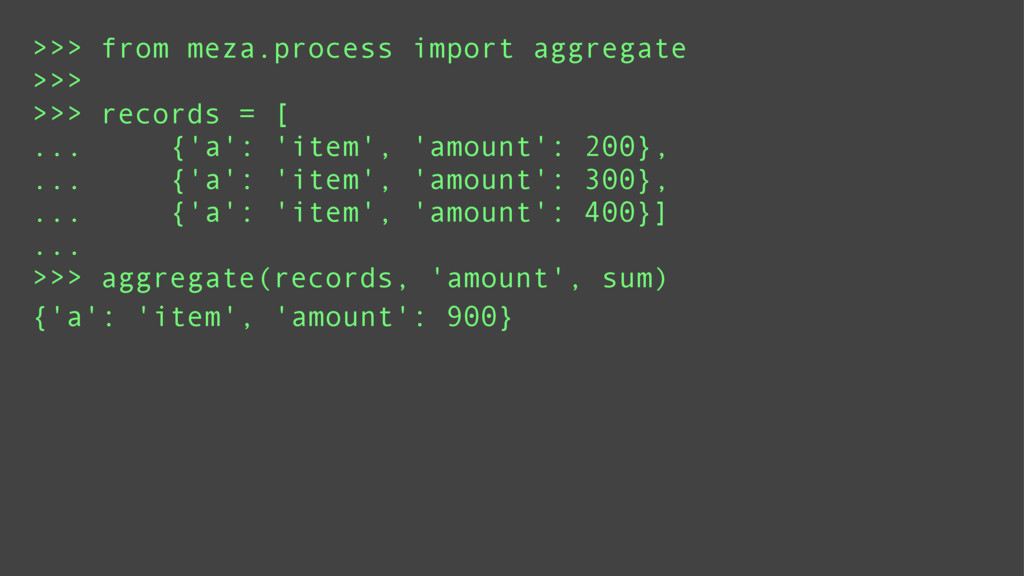
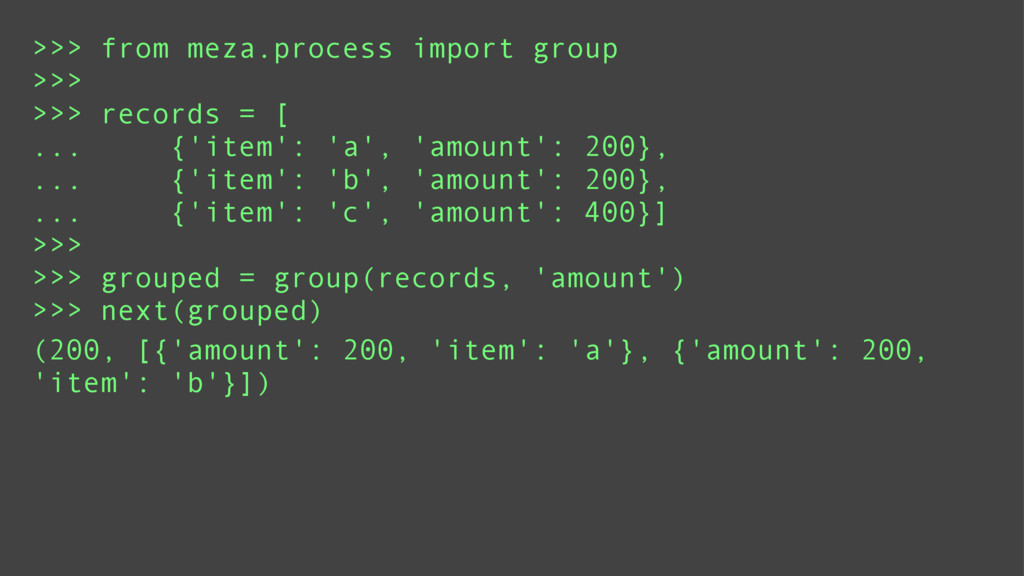
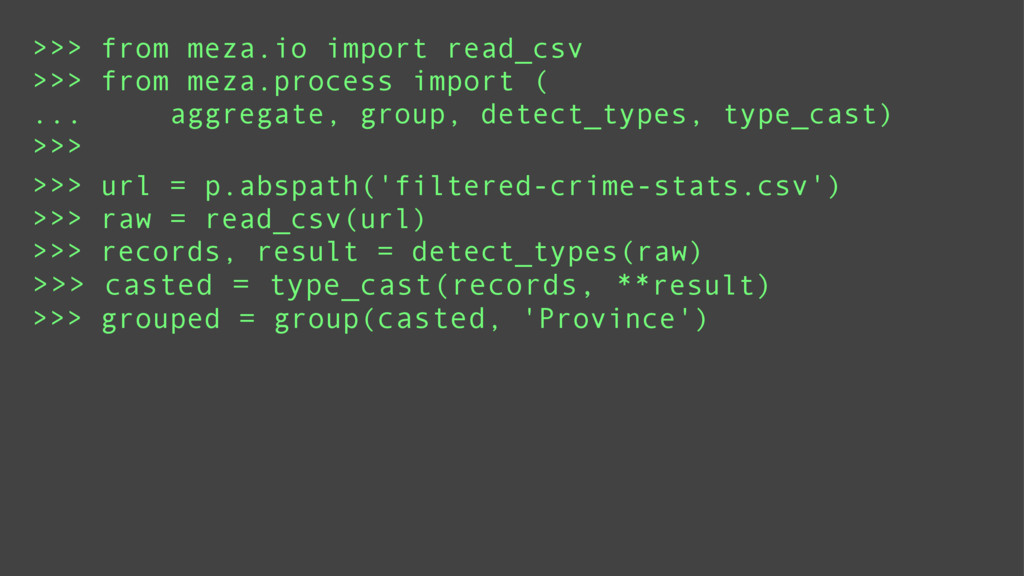
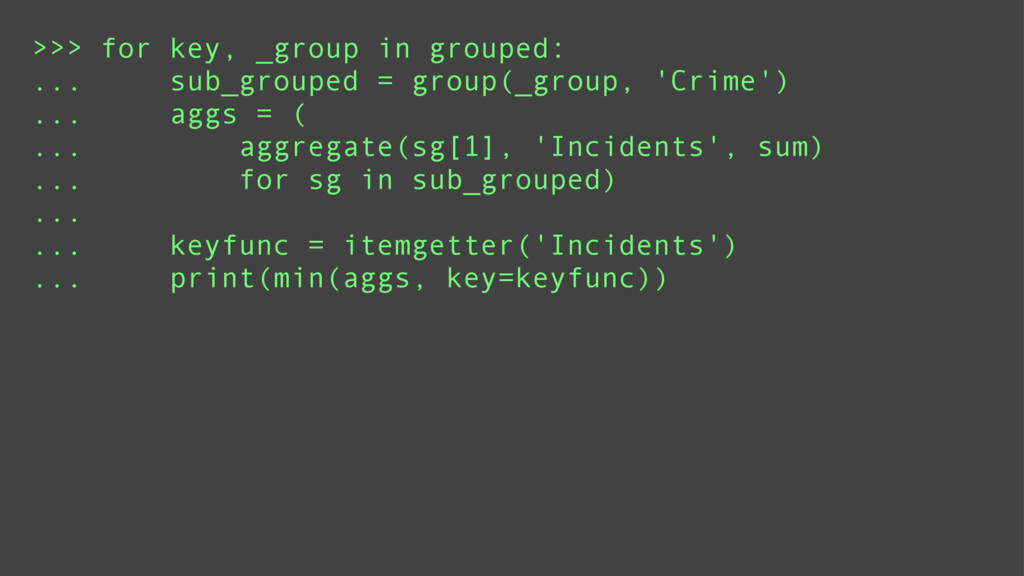
Finally, it will introduce meza: a pure python, functional, data analysis library and alternative to Pandas.
IPython notebooks and sample data files will be distributed beforehand on Github to facilitate code distribution.
OBJECTIVES
Attendees will learn what data and data mining are, why they are important. They will learn some basic functional programming idioms and see how it is ideally suited to data mining. They will also see in what areas the 20lb gorilla (Pandas) shines and when a lightweight alternative (meza) is more practical.
ADDITIONAL INFO
Level: Intermediate
Prerequisites
Students should have at least basic knowledge of python itertools and functional programming paradigms, e.g., map, filter, reduce, and list comprehensions.
Laptops should have python3 and the following pypi libs installed: bs4, requests, and meza.
Format
Students will be instructed in the completion of a series of exercises that will explore using python for data mining. It will involve lessons to introduce concepts; demos which implement the concepts using meza, beautiful soup, and requests; and exercises for students to apply the concepts.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! Reuben Cummings [email protected] https://github.com/reubano/meza #pyconza2016 @reubano](https://files.speakerdeck.com/presentations/82f3466b73e74a97b3d0d469cd0508f5/slide_69.jpg){kind=link}