For a number of months now work has been proceeding in order to bring perfection to the crudely conceived idea of a super-positioning of word vectors that would not only capture the tenor of a sentence in a vector of similar dimension, but that is based on the high dimensional manifold hypothesis to optimally retain the various semantic concepts. Such a super-positioning of word vectors is called the semantic concept embedding.
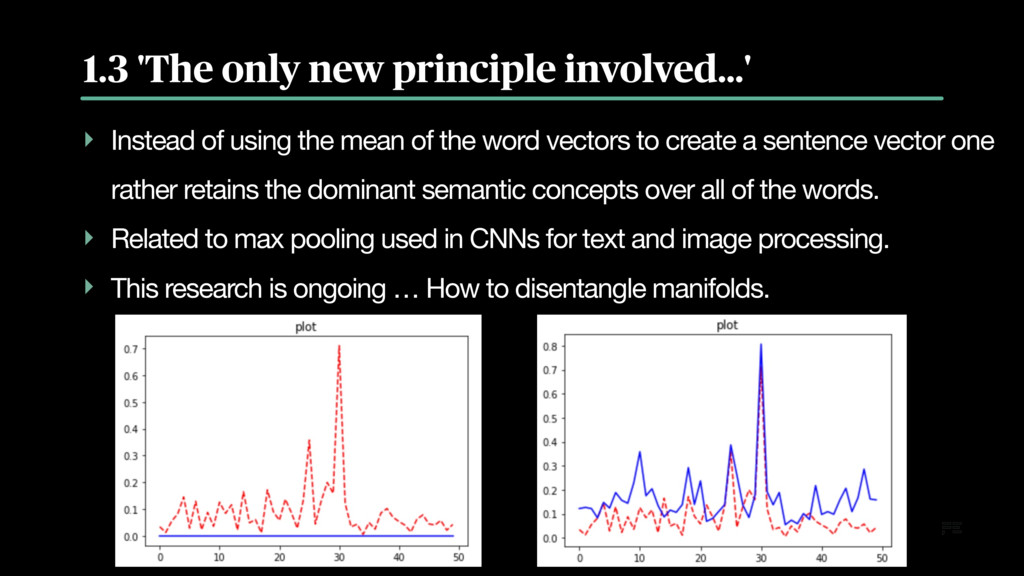
Now basically the only new principle involved is that instead of using the mean of the word vectors of a sentence one rather retains the dominant semantic concepts over all of the words. A modification informed by the aforementioned manifold hypothesis.
The original implementation retains the absolute maximum value over each of the dimensions of an embedding such as the GloVe embedding developed at Stanford University. The use of these semantic concept vectors then allows effective matching of users' questions to an online FAQ system which in turn allows a natural language adaptation of said system that easily achieves an F-score of 0.922 on the Quora dataset given only three examples of how any particular question may be asked.
The semantic concept embedding has now reached a high level of development. First, an analysis of the word embedding is applied to find the prepotent semantic concepts. The associated direction vectors are then used to transform the embeddings in just the right way to optimally detangle the principal manifolds and further increase the performance of the natural language FAQ system.
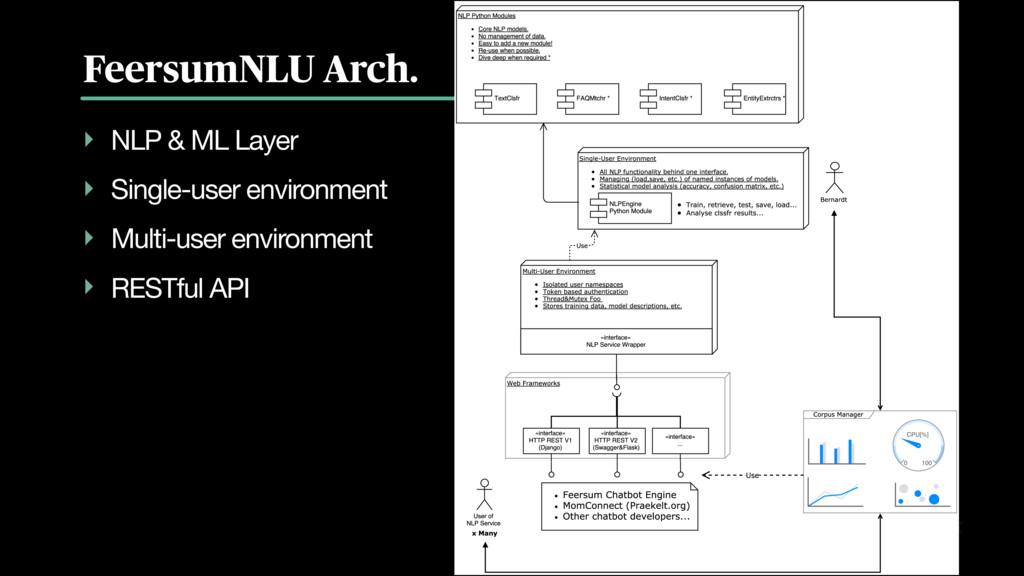
This talk will give an overview of:
• The problem of semantic sentence embedding.
• How NLTK, numpy, and Python machine learning frameworks are used to solve the problem.
• How semantic concept embedding is used for natural language FAQ systems in chatbots, etc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![1.2 Word Vectors [https://www.tensorflow.org/tutorials/word2vec]](https://files.speakerdeck.com/presentations/2beca0c52055497ab29cf90529ae4487/slide_11.jpg){kind=link}
{kind=link}
![1.3 The Manifold Hypothesis [http://colah.github.io/posts/2015-01-Visualizing-Representations]](https://files.speakerdeck.com/presentations/2beca0c52055497ab29cf90529ae4487/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}