• Bolsista do NTI(UFAL) • Bolsista da RIM(Blackberry) • Desenvolvedor de diversos projetos acadêmicos em Java, C++, VB6, HTML5, AngularJS • Membro do GDG Luanda ? f g+ in ? 3
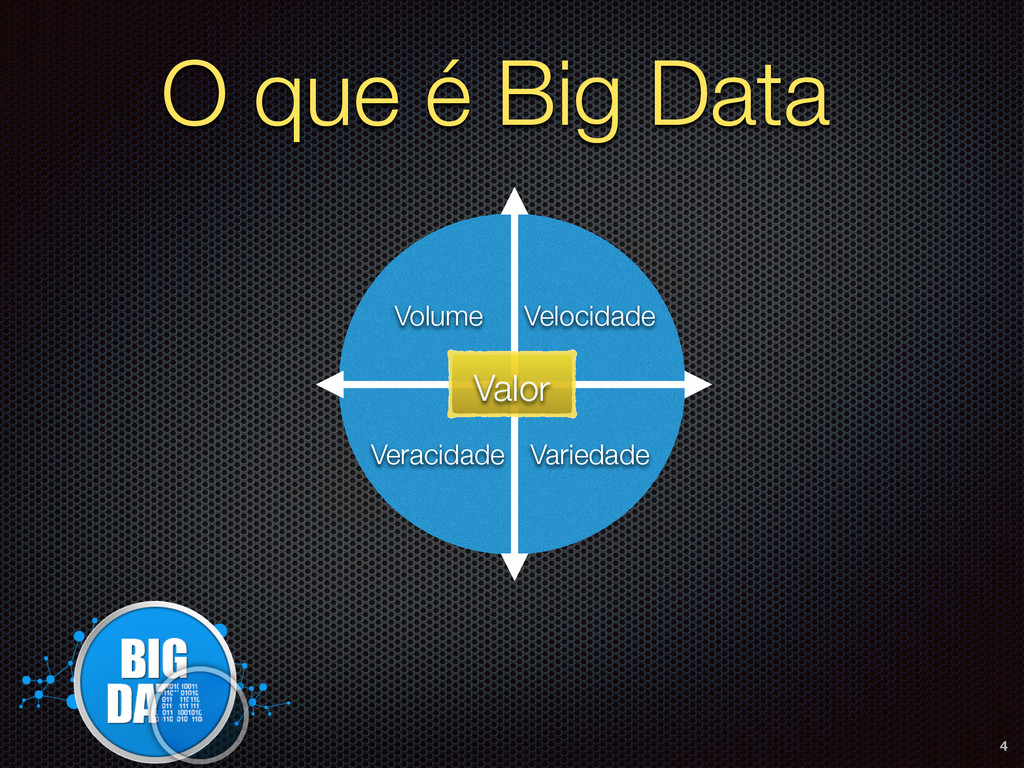
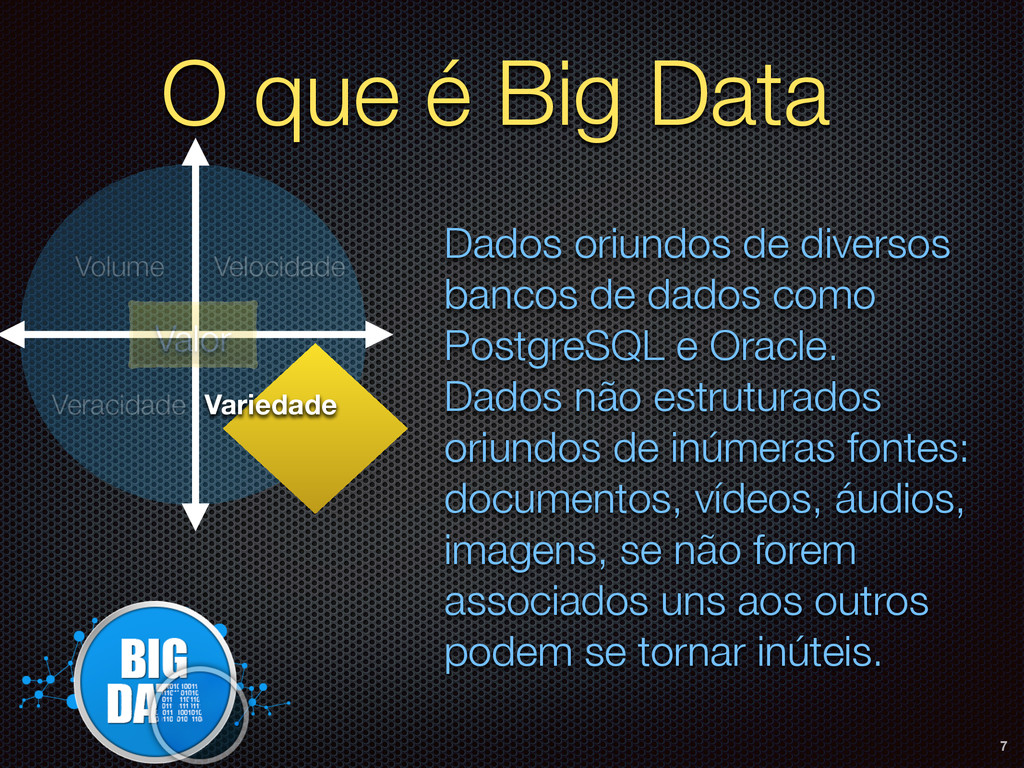
de diversos bancos de dados como PostgreSQL e Oracle. Dados não estruturados oriundos de inúmeras fontes: documentos, vídeos, áudios, imagens, se não forem associados uns aos outros podem se tornar inúteis. Volume Variedade 7
outro aspecto visto, uma solução de Big Data se tornará inviável se o resultado não trouxer benefícios significativos e que compensem o investimento. Volume Variedade Veracidade 9
estruturados(HTML). Processar as páginas para buscar citações(links). Calcular o PageRank das páginas segundo o número de citações. Criar um mecanismo de busca textual. 13
Google. • Out/2003 - Artigo sobre GFS. • Dez/2004 - Artigo sobre MapReduce. • Fev/2006 - Hadoop se torna um projeto oficial da Apache. • Abr/2007 - Yahoo! roda Hadoop em um cluster de 1000 nós. • Jan/2008 - Hadoop se torna no projeto principal da Apache 15
busca • Nutch é criado • Mesmos problemas que o Google (máquinas quebram) • Criado o HDFS(Hadoop Distributed File System) • Surge Hbase NoSQL baseado no BigTable da Google 16
“ABC”; SELECT a.* FROM a JOIN b ON (a.id = b.id) SELECT MARCA, sum(vl_pedido) Valor_Pedidos FROM `default.tb_orders` Group by MARCA ORDER by Valor_Pedidos DESC A = LOAD 'tabela' USING org.apache.hcatalog.pig.HCatLoader(); B = LIMIT A 100; C = FILTER B BY campo1 == 'Teste'; D = FOREACH C GENERATE symbol, date, close; E = DISTINCT D; F = GROUP E BY (campo1, campo2); G = ORDER F BY (campo1, campo2); H = JOIN G BY campo1, F BY campo1; DUMP C; A = LOAD 'default.tb_orders' USING org.apache.hcatalog.pig.HCatLoader(); B = GROUP A BY marca; X = FOREACH B GENERATE group, SUM(A.vl_pedido); DUMP X;
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}