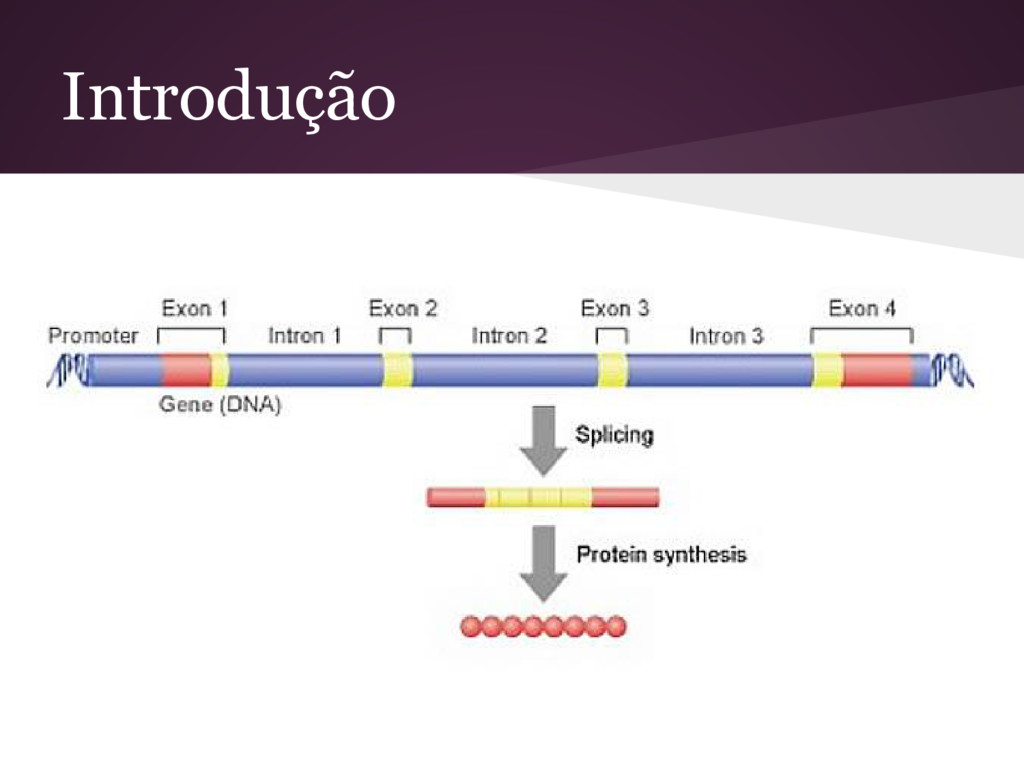
delimitadores de código genético. Delimitadores separam genes a serem processados na síntese protéica dos que não serão processados. • 3 classes: ◦ Intron - Exon - IE ◦ Exon - Intron - EI ◦ Nenhum - N
onde ocorre a classificação ◦ Nome: sequência de alfanum e hífens -> descartado ◦ Sequência de núcleotideos: entrada • exemplo: EI, ATRINS-DONOR-521, CAGCTGCATCACAGGAGGCCA GCGAGCAGGTCTGTTCCAAGGGCCTTCGAGCCAGTCTG
por todas as combinações possíveis (e.g. uma amostra com um caractere ’D’ passa a ser três amostras, uma com ’T’, ’A’, ’G’); IE, DGACGGGGCTGACCGCGGGGGCGGGTCC AGGGTCTCACACCCTCCAGAATATGTATGGCT
por todas as combinações possíveis (e.g. uma amostra com um caractere ’D’ passa a ser três amostras, uma com ’T’, ’A’, ’G’); IE, DGACGGGGCTGACCGCGGGGGCGGGTCC AGGGTCTCACACCCTCCAGAATATGTATGGCT IE, TGACGGGGCTGACCGCGGGGGCGGGTCC AGGGTCTCACACCCTCCAGAATATGTATGGCT IE, AGACGGGGCTGACCGCGGGGGCGGGTCC AGGGTCTCACACCCTCCAGAATATGTATGGCT IE, GGACGGGGCTGACCGCGGGGGCGGGTCC AGGGTCTCACACCCTCCAGAATATGTATGGCT
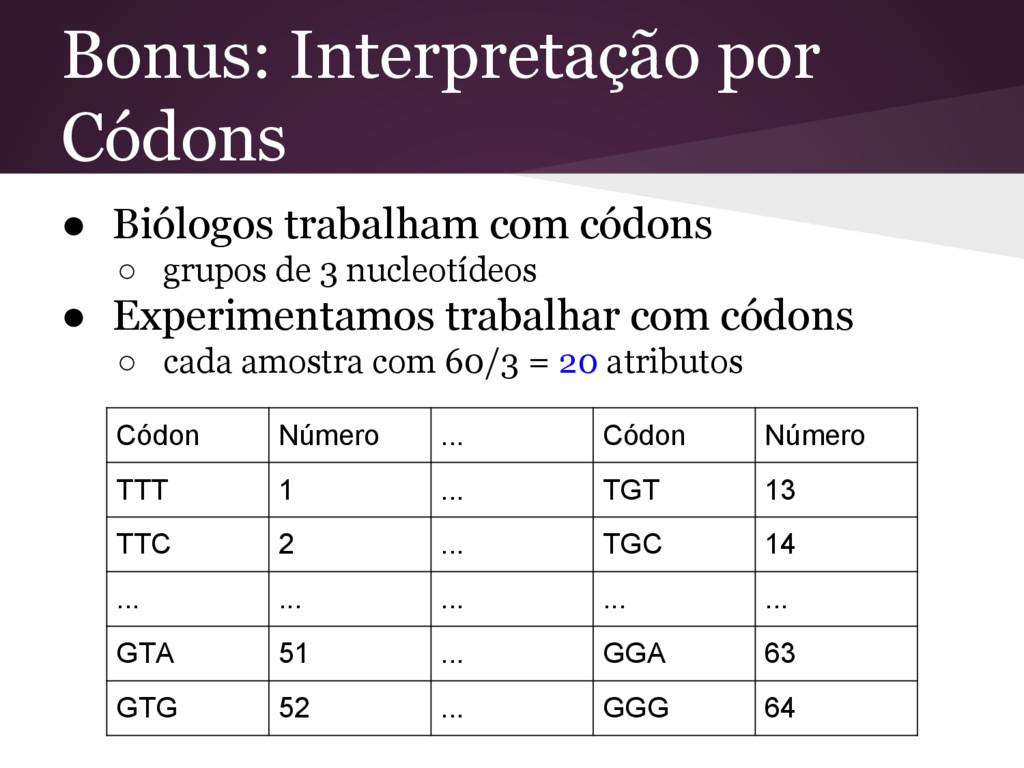
como 60 atributos individuais de uma amostra; TGACGGGGCTGACCGCGGGGGCGGGTCCA GGGTCTCACACCCTCCAGAATATGTATGGCT • Após o pré-processamento, a base de dados passou a ter 3321 amostras, com 60 atributos cada.
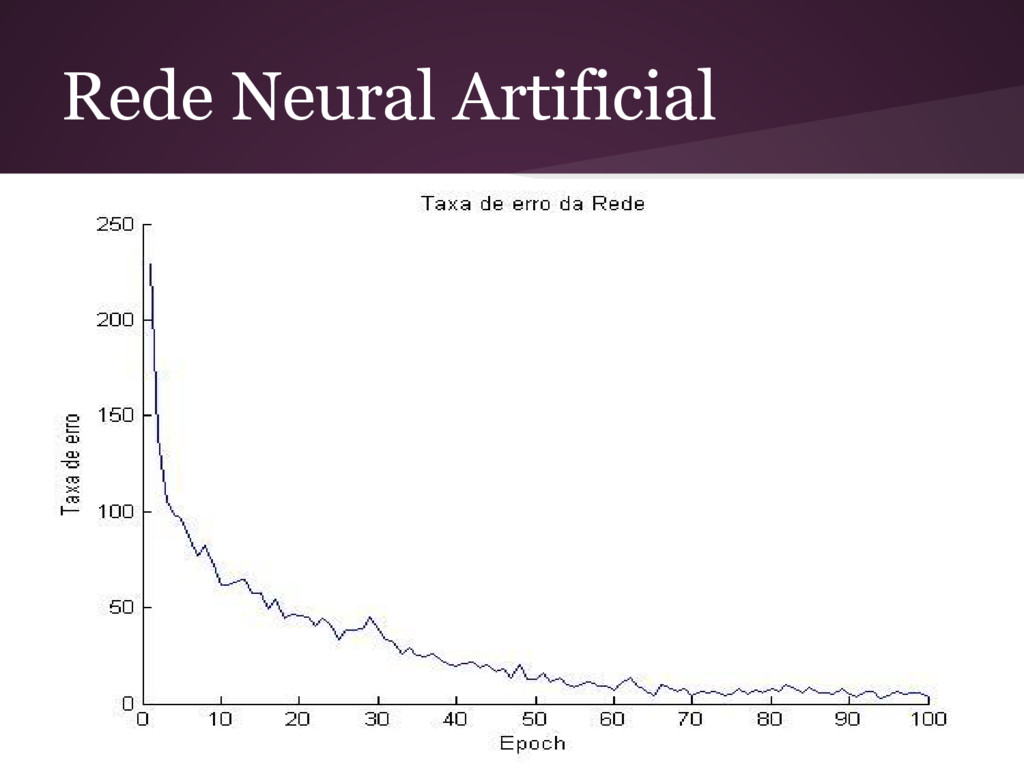
camada intermediária e 3 de saída. - Precisão média: 90% - Taxa de erro calculada ao fim de cada Época (ciclo de testes). - Erro = - A cada Epoch, é possível perceber a taxa de erro diminuindo, isto é, a rede chega cada vez mais perto das respostas ideais
Gene Sequences) Data Set.} UCI Machine Learning Repository http://archive.ics.uci.edu/ml Irvine, CA: University of California, School of Information and Computer Science. 2) Tarca AL, Carey VJ, Chen X-w, Romero R, Drăghici S (2007) Machine Learning and Its Applications to Biology. PLoS Comput Biol 3(6): e116. doi:10.1371/journal.pcbi.0030116 3) Chih-Chung Chang and Chih-Jen Lin, LIBSVM : a library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2:27:1--27:27, 2011. Software available at http://www.csie.ntu.edu.tw/~cjlin/libsvm 4) Mitchell, Tom M. Machine learning. McGraw-Hill, Maidenhead, U.K. 1997. 5) Leverington, D (2009). A Basic Introduction to Feedforward Backpropagation Neural Networks. http://www.webpages.ttu.edu/dleverin/neural_network/neural_networks.html 6) Conserved codon composition of ribosomal protein coding genes in Escherichia coli, Mycobacterium tuberculosis and Saccharomyces cerevisiae: lessons from supervised machine learning in functional genomics Kui Lin, Yuyu Kuang, Jeremiah S. Joseph, Prasanna R. Kolatkar Nucleic Acids Res. 2002 June 1; 30(11): 2599–2607. 7) MathWorks. MATLAB. http://www.mathworks.com/products/matlab/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}