• Aggregation regions: “All the tasks in a cluster” • How frequently measurements are made: “Every 10 seconds” • Which requests are included: “HTTP GETs from black-box monitoring jobs” • How the data is acquired: “Through our monitoring, measured at the server” • Data-access latency: “Time to last byte” 39
performance ◦ 不能只看眼前,要從全局出發 • Keep it simple ◦ 太複雜的匯總,會難以理解,同時會掩蓋系統性的變化 • Avoid absolutes (絕對值) ◦ 要求擴展系統而沒有增加任何 latency ,或者永遠 Available 都是不切實際的 • Have as few SLOs as possible ◦ 選擇足夠的 SLO 覆蓋系統屬性 • Perfection can wait (不完美也很美) ◦ 隨著時間了解系統之後,進行 SLO 定義與調整。 42
{kind=link}
{kind=link}
{kind=link}
{kind=link}
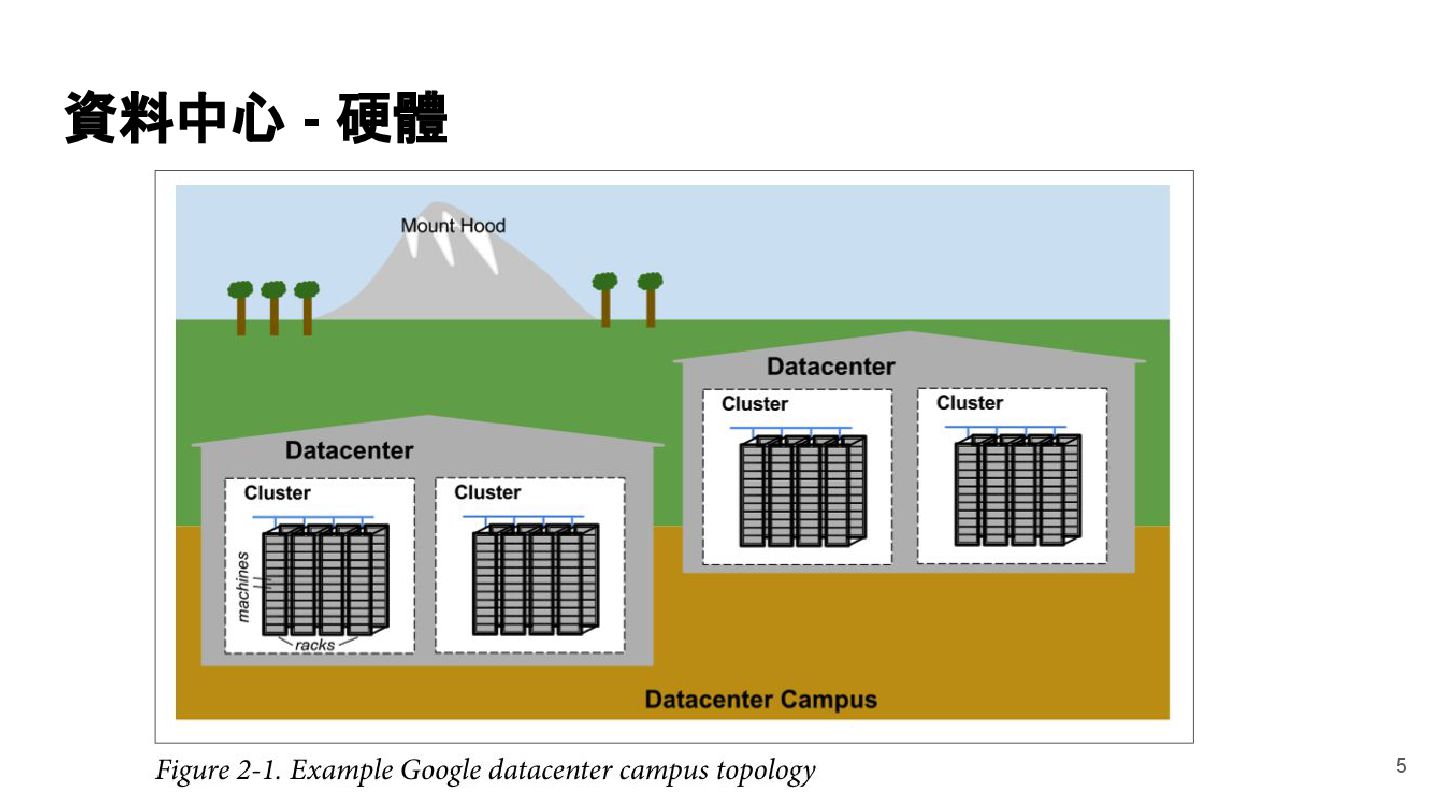{kind=link}
{kind=link}
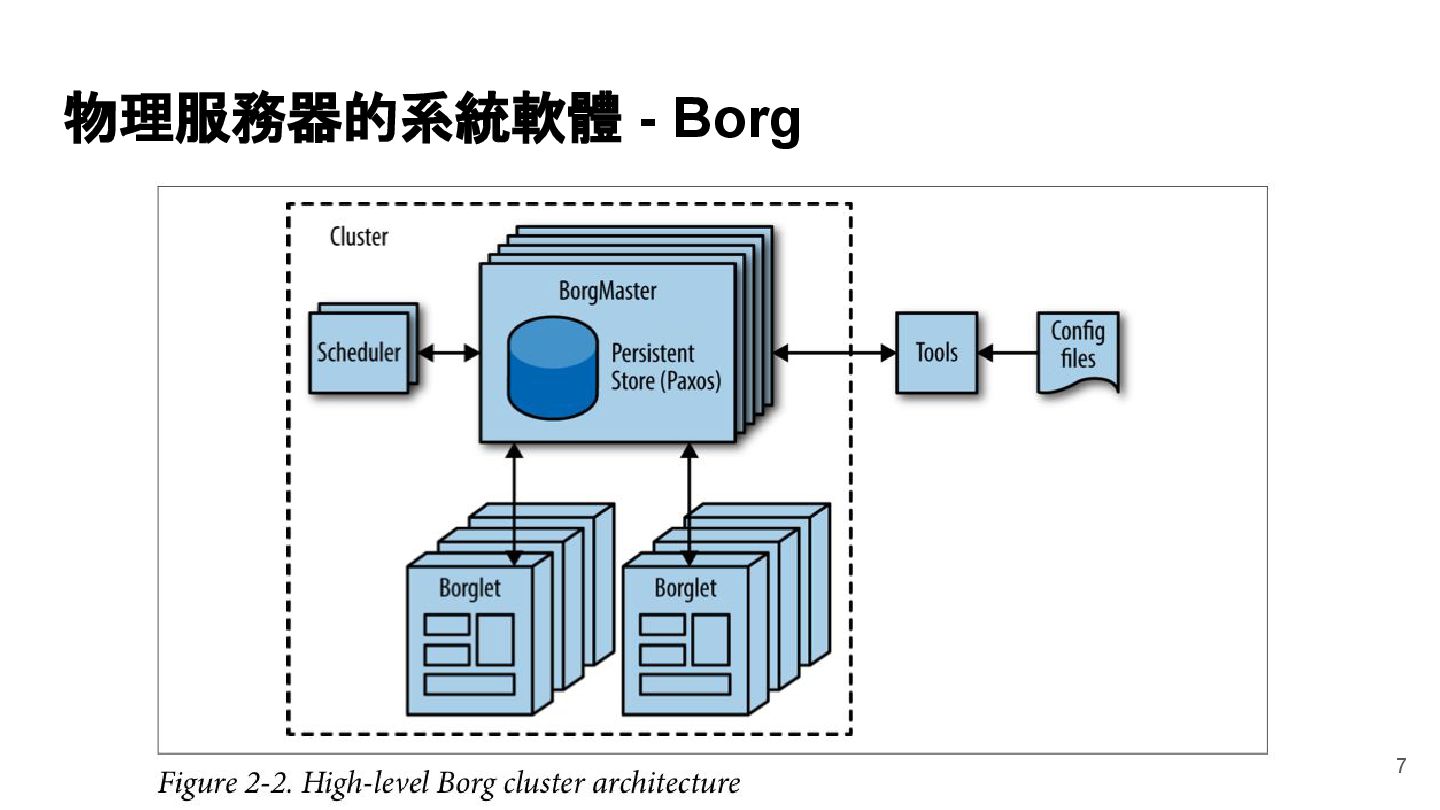{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
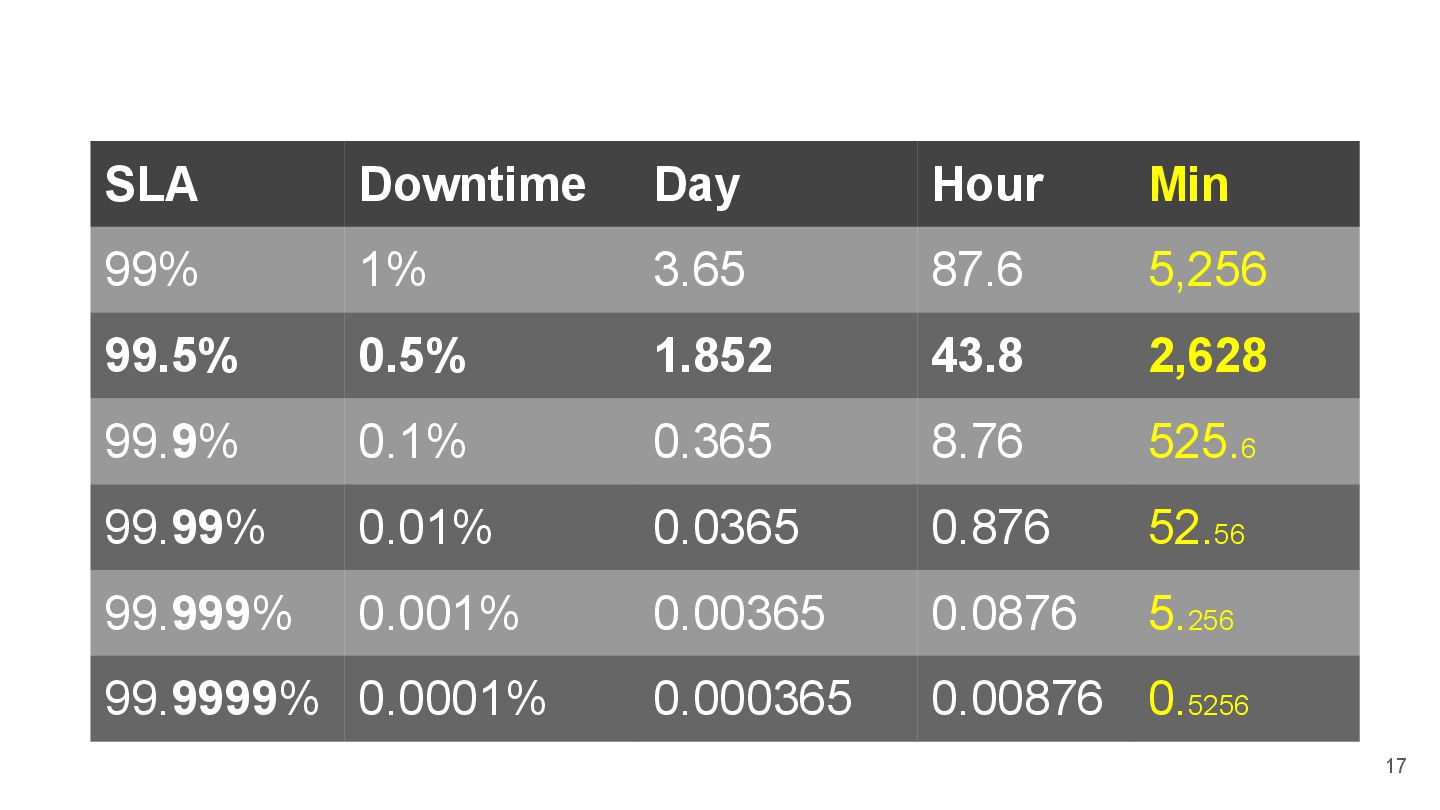{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
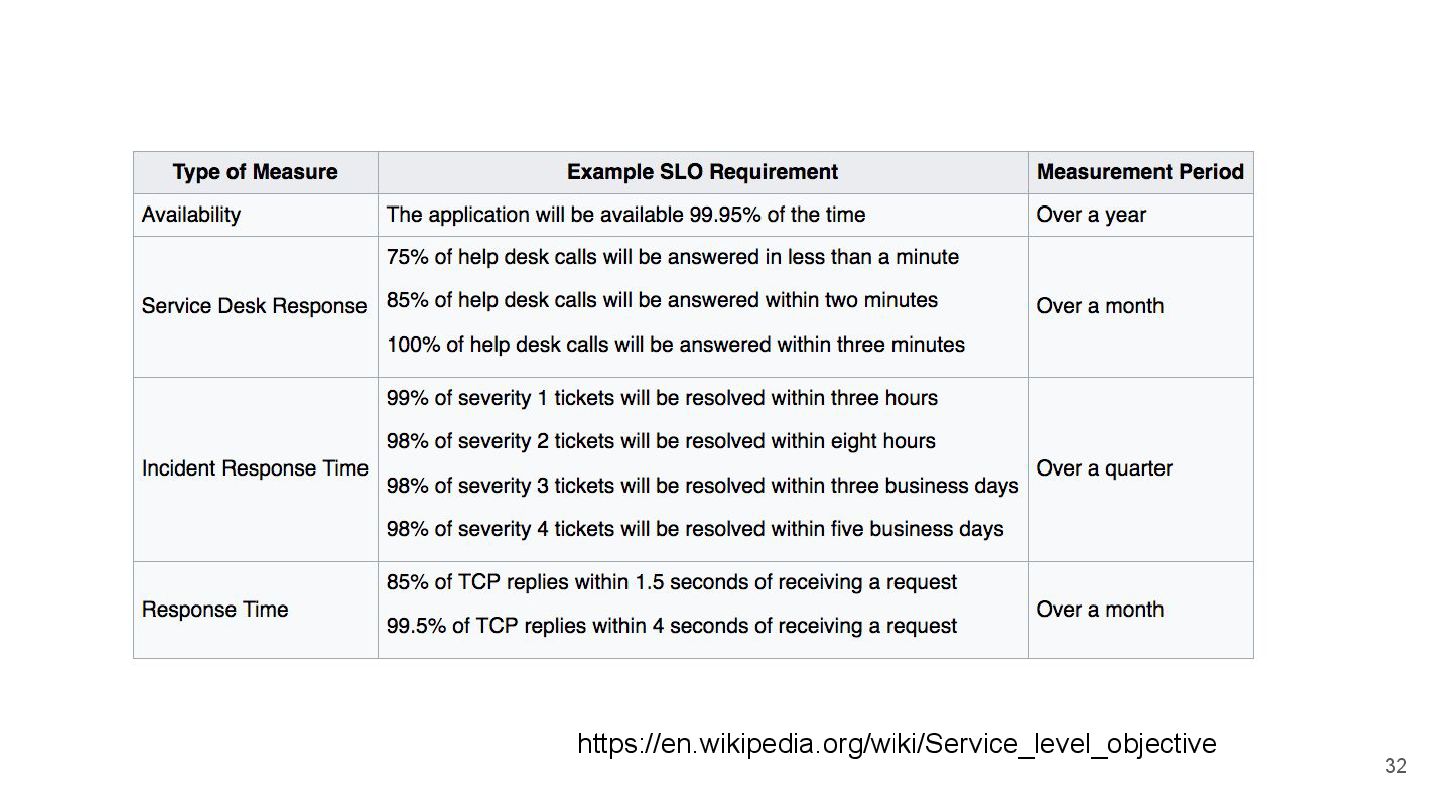{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}