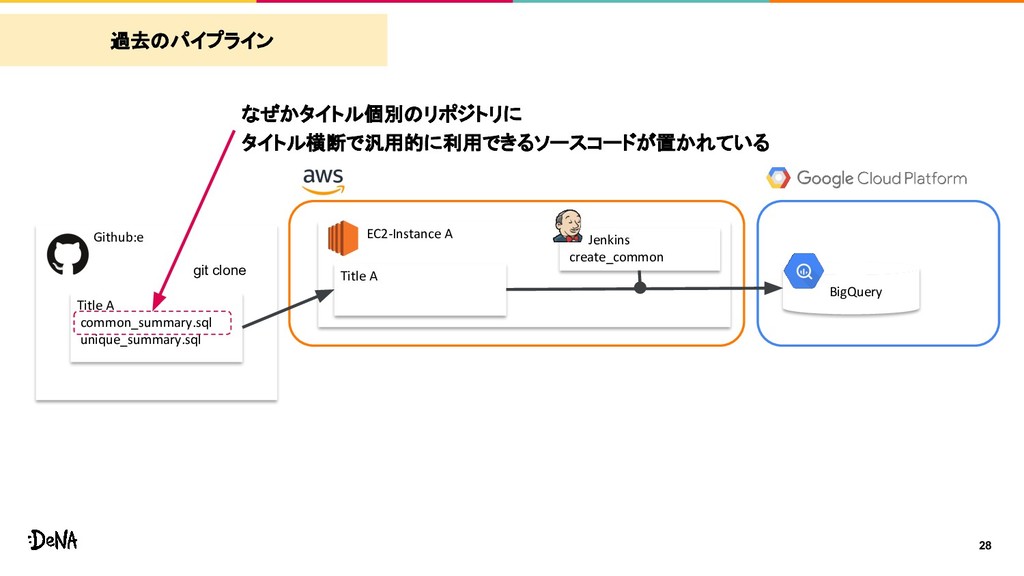
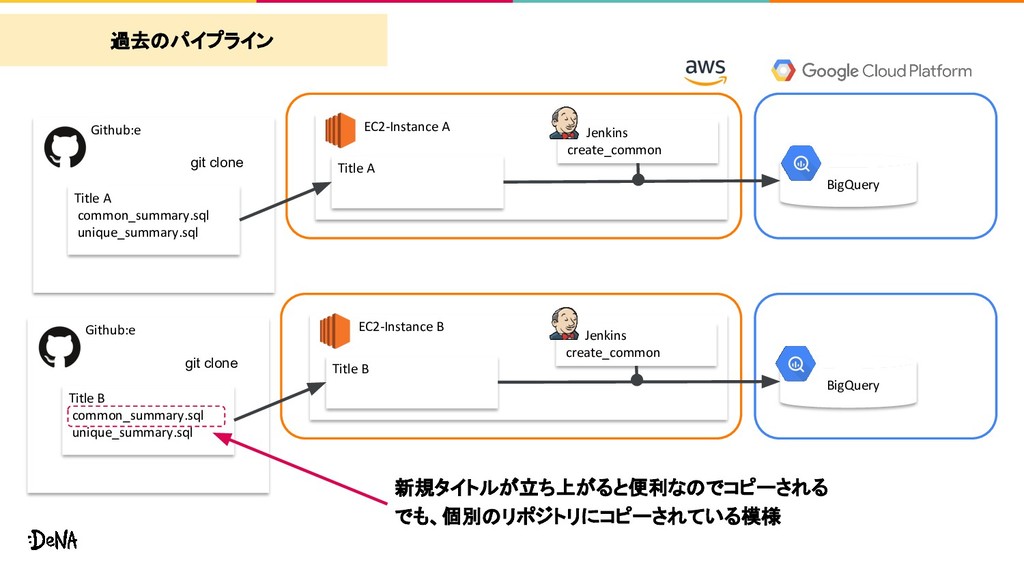
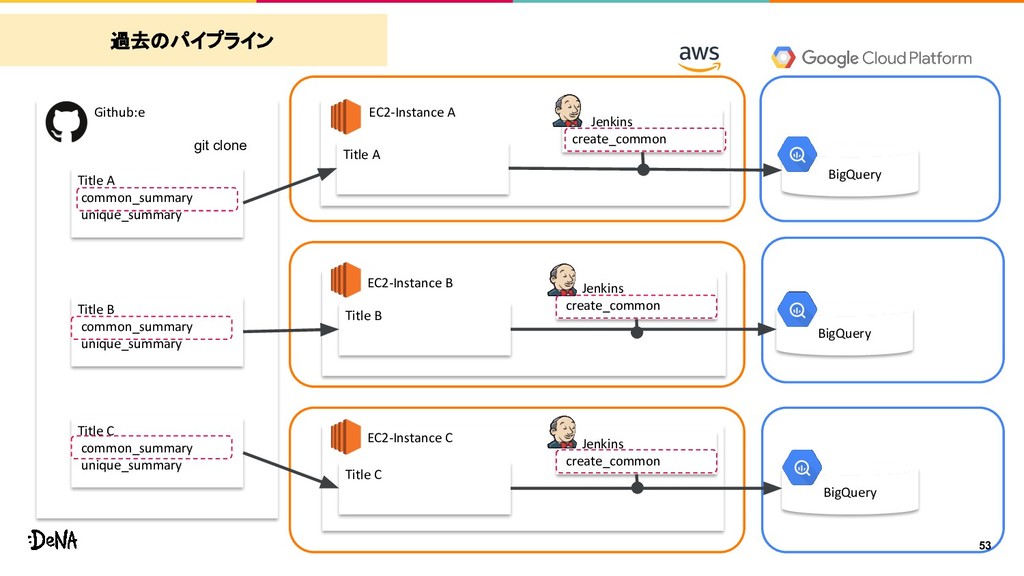
A BigQuery git clone Github:e EC2-Instance B Jenkins create_common Title B common_summary.sql unique_summary.sql Title B BigQuery git clone 過去のパイプライン 新規タイトルが立ち上がると便利なのでコピーされる でも、個別のリポジトリにコピーされている模様
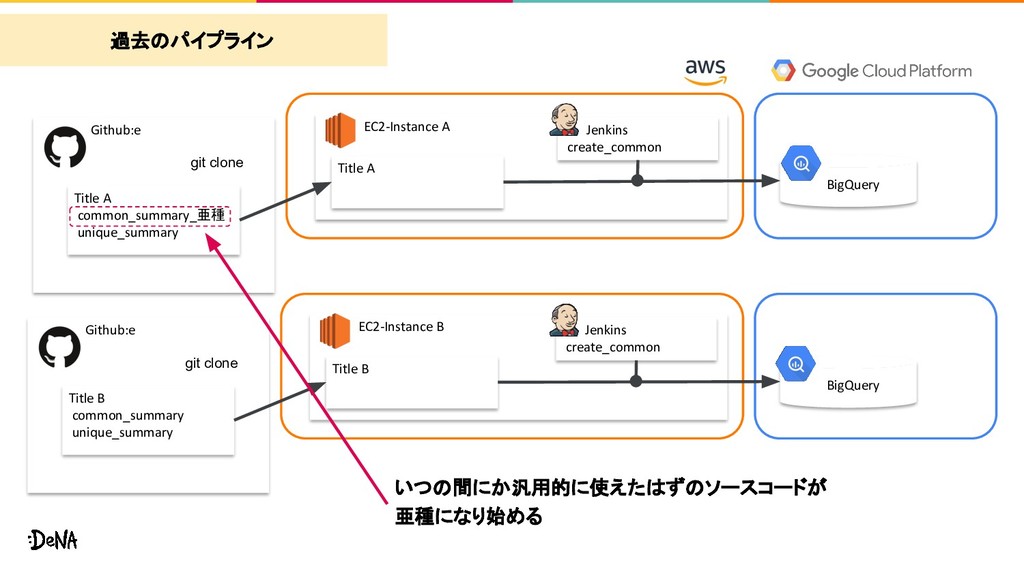
unique_summary Title A BigQuery git clone Github:e EC2-Instance B Jenkins create_common Title B common_summary unique_summary Title B BigQuery git clone 過去のパイプライン
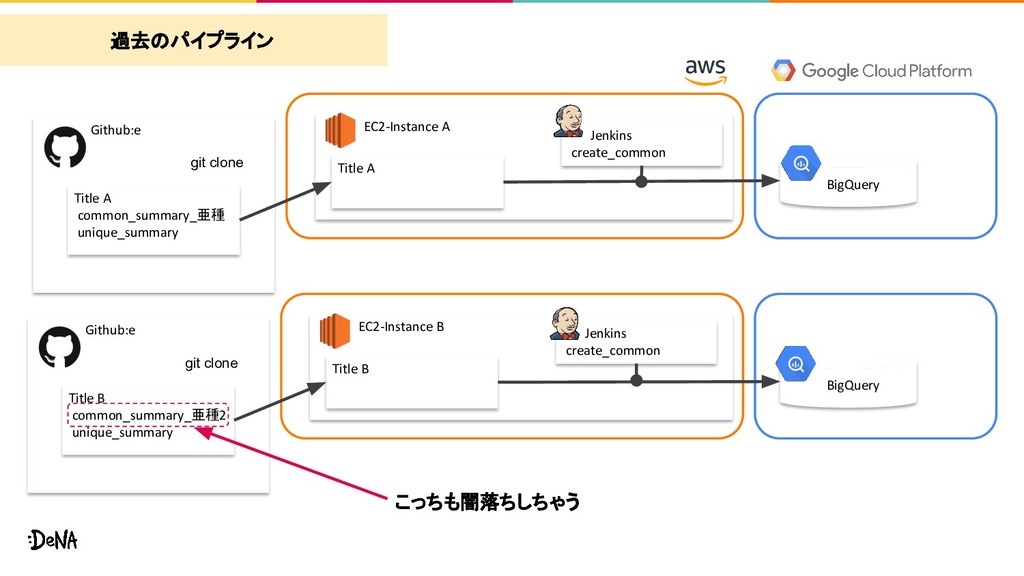
Title A BigQuery git clone Github:e EC2-Instance B Jenkins create_common Title B common_summary_亜種2 unique_summary Title B BigQuery git clone 過去のパイプライン
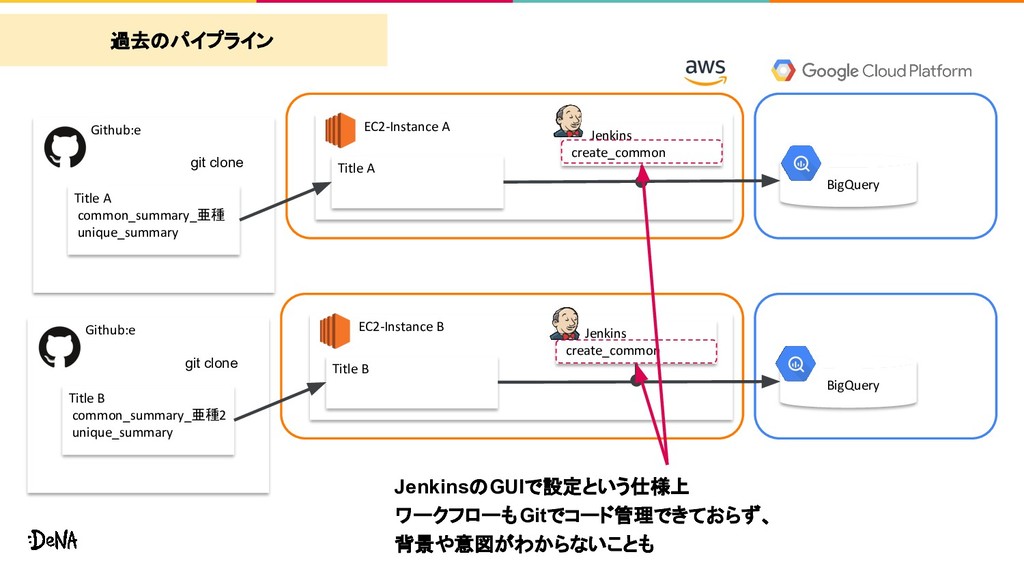
common_summary_亜種 unique_summary Title A BigQuery git clone Github:e EC2-Instance B Jenkins create_common Title B common_summary_亜種2 unique_summary Title B BigQuery git clone 過去のパイプライン
C Title A common_summary unique_summary Title B common_summary unique_summary Title C common_summary unique_summary Title A Title B Title C BigQuery BigQuery BigQuery Jenkins create_common Jenkins create_common git clone
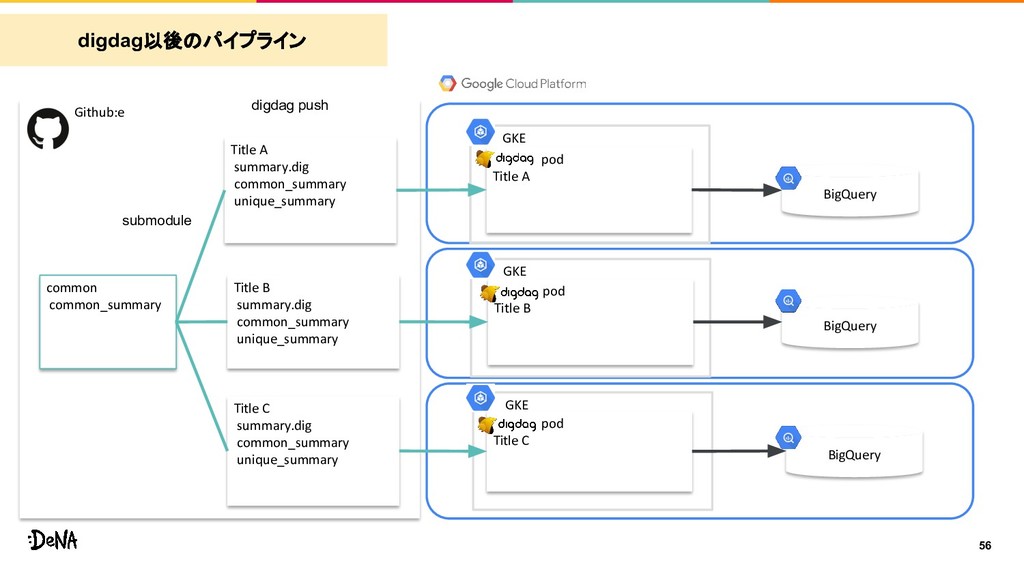
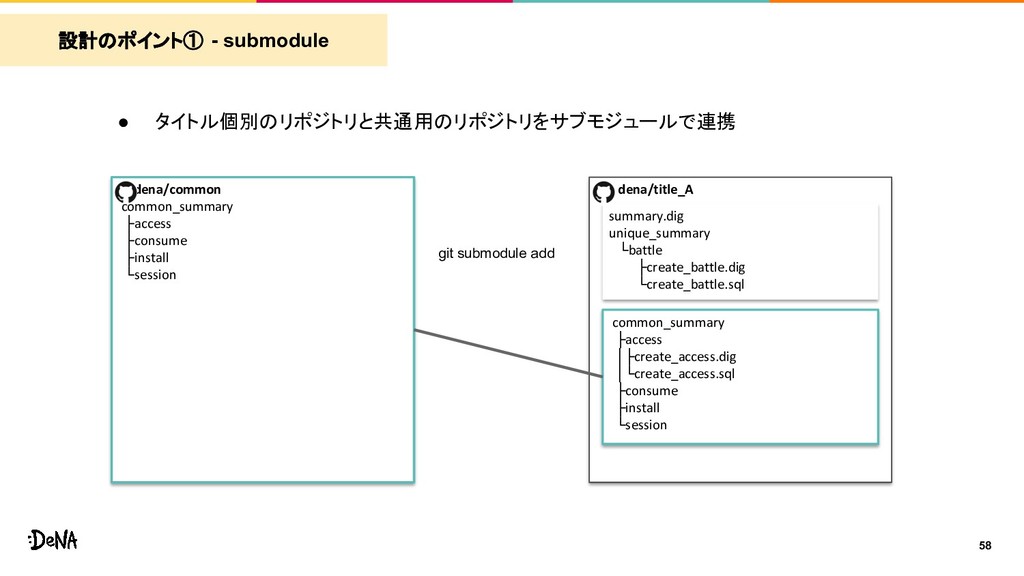
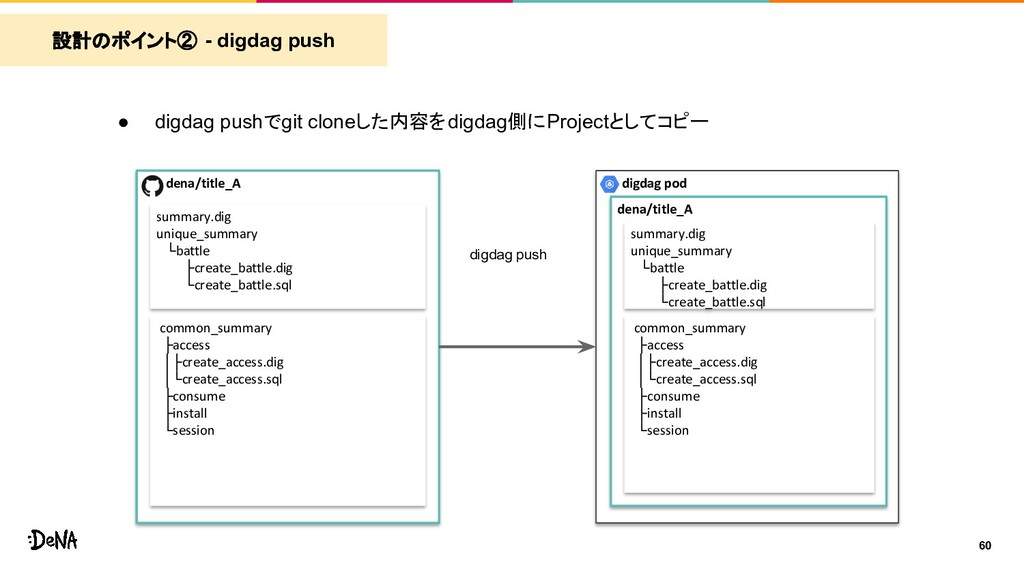
common_summary unique_summary Title B summary.dig common_summary unique_summary Title C summary.dig common_summary unique_summary BigQuery BigQuery BigQuery common common_summary submodule digdag push GKE pod Title B GKE pod Title C
common_summary unique_summary Title B summary.dig common_summary unique_summary Title C summary.dig common_summary unique_summary BigQuery BigQuery BigQuery common common_summary submodule digdag push GKE pod Title B GKE pod Title C
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}