Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
第二章-回帰と周辺の知識【数学嫌いと学ぶデータサイエンス・統計的学習入門】
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Ringa_hyj
June 15, 2020
Technology
440
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
第二章-回帰と周辺の知識【数学嫌いと学ぶデータサイエンス・統計的学習入門】
第二章【数学嫌いと学ぶデータサイエンス・統計的学習入門】
Ringa_hyj
June 15, 2020
More Decks by Ringa_hyj
See All by Ringa_hyj
DVCによるデータバージョン管理
ringa_hyj
0
410
deeplakeによる大規模データのバージョン管理と深層学習フレームワークとの接続
ringa_hyj
0
120
Hydraを使った設定ファイル管理とoptunaプラグインでのパラメータ探索
ringa_hyj
0
240
ClearMLで行うAIプロジェクトの管理(レポート,最適化,再現,デプロイ,オーケストレーション)
ringa_hyj
0
270
Catching up with the tidymodels.[Japan.R 2021 LT]
ringa_hyj
3
880
多次元尺度法MDS
ringa_hyj
0
420
因子分析(仮)
ringa_hyj
0
210
階層、非階層クラスタリング
ringa_hyj
0
160
tidymodels紹介「モデリング過程料理で表現できる説」
ringa_hyj
0
690
Other Decks in Technology
See All in Technology
iOS/Androidの二刀流エンジニアがFlutter & TypeScriptへ越境後の現在地 - Flutterがメインになって見えた景色と現在の醍醐味 / Dual-Platform Mobile Engineer Shifts to Flutter & TypeScript - The View and Real Thrill of Going Flutter-First
bitkey
PRO
0
110
データエンジニアこそ組織のオントロジーに向き合うべき — 問いに答えるAIから、事業を動かすAIへ
gappy50
3
720
Multicaで30個のミニプロジェクトをAIエージェント運用して見えてきたこと
eiei114
1
680
論語・武士道・産業革命から見る かわるもの、かわらないもの
ichimichi
8
1.3k
SRENEXT_2026_Chairs__Talks_in_Tamachi.sre.pdf
srenext
1
160
OPENLOGI Company Profile for engineer
hr01
1
75k
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
350
A Bag-of-Documents Model for Query Specificity
dtunkelang
0
110
インシデント事例と パッケージの全量解析に学ぶ ソフトウェアサプライチェーンの守り方 / supply-chain-attack-defense
flatt_security
0
1.1k
データベース研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
440
13年運用タイトルのサーバーサイドが辿り着いた現在地 ― モンスターストライクにおける技術・組織・AI活用から得た知見
mixi_engineers
PRO
1
160
AI研修(Day1)【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
1.6k
Featured
See All Featured
KATA
mclloyd
PRO
35
15k
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Skip the Path - Find Your Career Trail
mkilby
1
170
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
How to train your dragon (web standard)
notwaldorf
97
6.7k
Typedesign – Prime Four
hannesfritz
42
3.1k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
560
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
エンジニアに許された特別な時間の終わり
watany
108
250k
Transcript
1 第二章 1 第二章 @Ringa_hyj 日本一の数学嫌いと学ぶ データサイエンス ~第二章:回帰と周辺の知識~
2 第二章 2 第二章 対象視聴者: 数式や記号を見ただけで 教科書を閉じたくなるレベル
3 第二章 3 第二章 回帰・分類 とその歴史
4 第二章 4 第二章 「最小二乗法」によるモデル化の考え方は1800年代ごろ発表され、 回帰モデル(被説明変数が連続な数値)は天文学で使われていた 保険数理や経済判断などで、 顧客が⾧生きか死亡するか・株が上がるか下がるかなど 分類モデル(2クラス・3クラスに分けるモデル) 1900年代になりロジスティック回帰が使われ始めた
サポートベクターマシン・ボルツマンマシンなどのアルゴリズムが登場 この時代から「データをもとにモデルを学習する」という考え方が生まれていた。 しかし複雑(非線形)な問題はコンピューターの問題で使えなかった。 Least-squares method regression classification support vector machine, SVM Boltzmann machine
5 第二章 5 第二章 1980年ごろからコンピューターの発展もあり、 決定木(回帰木・分類(判別) 木)など多少複雑なアルゴリズムも使われ始める。 今までのアルゴリズムも複雑(非線形)まで拡張できるようになる 2000年に入る少し前、統計解析・処理を行うフリーソフト「R言語」が登場 機械学習の理論は専門的で複雑
→ R言語の知識 + コンピューター 専門的なアルゴリズムを試すことができる → 機械学習による回帰・分類 様々な分野で適応できる
6 第二章 6 第二章 AIの歴史 今のブームはここから (出典)総務省「ICTの進化が雇用と働き方に及ぼす影響に関する調査研究」(平成28年)
7 第二章 7 第二章 回帰(regression) 教師あり・なし 簡単な線形代数 パラメトリック・ノンパラメトリック モデルのバイアス、バリアンス モデル評価
評価できない問題
8 第二章 8 第二章 教師あり・なし 学習
9 第二章 9 第二章 本当のモデルを求めたいので、 傾きは適当でなく、未知の変数Aとする 真のモデルから得られている点(x=1,y=2)というデータを与える 予測したい対象 (ここではyの値) が既にいくつか与えられていて、
モデルを考える時の修正するための情報 (教師) として使える 教師あり学習 ・教師あり・なし 学習
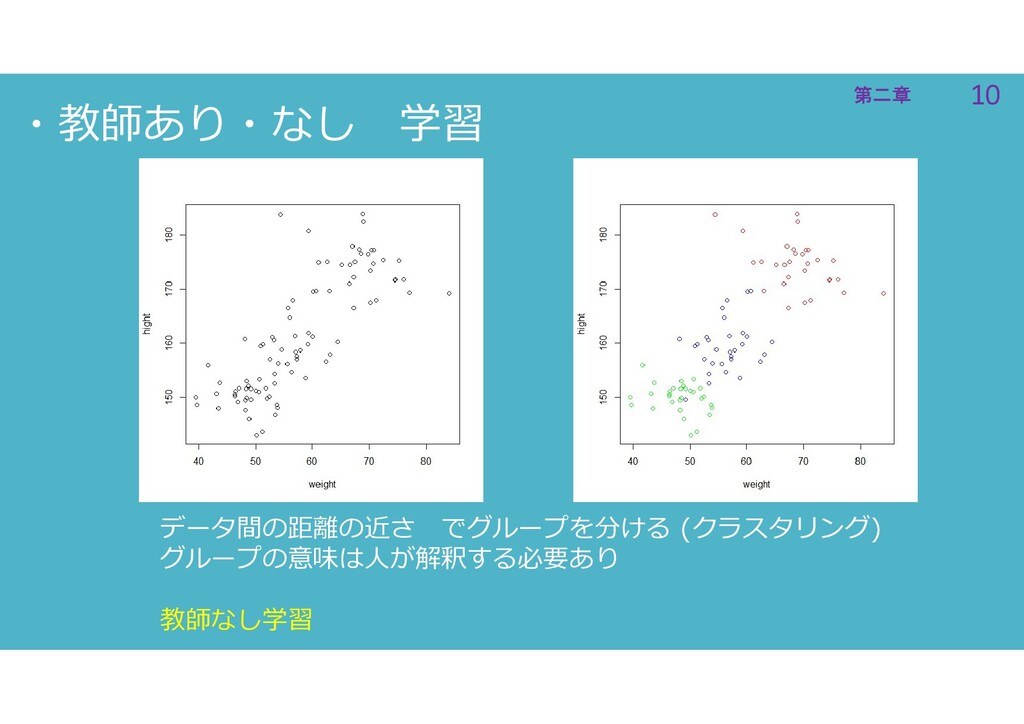
10 第二章 10 第二章 ・教師あり・なし 学習 データ間の距離の近さ でグループを分ける (クラスタリング) グループの意味は人が解釈する必要あり
教師なし学習
11 第二章 11 第二章 簡単な線形代数(ベクトル・行列)
12 第二章 12 第二章 ・簡単な線形代数(ベクトル・行列) No Speed dist 1 4
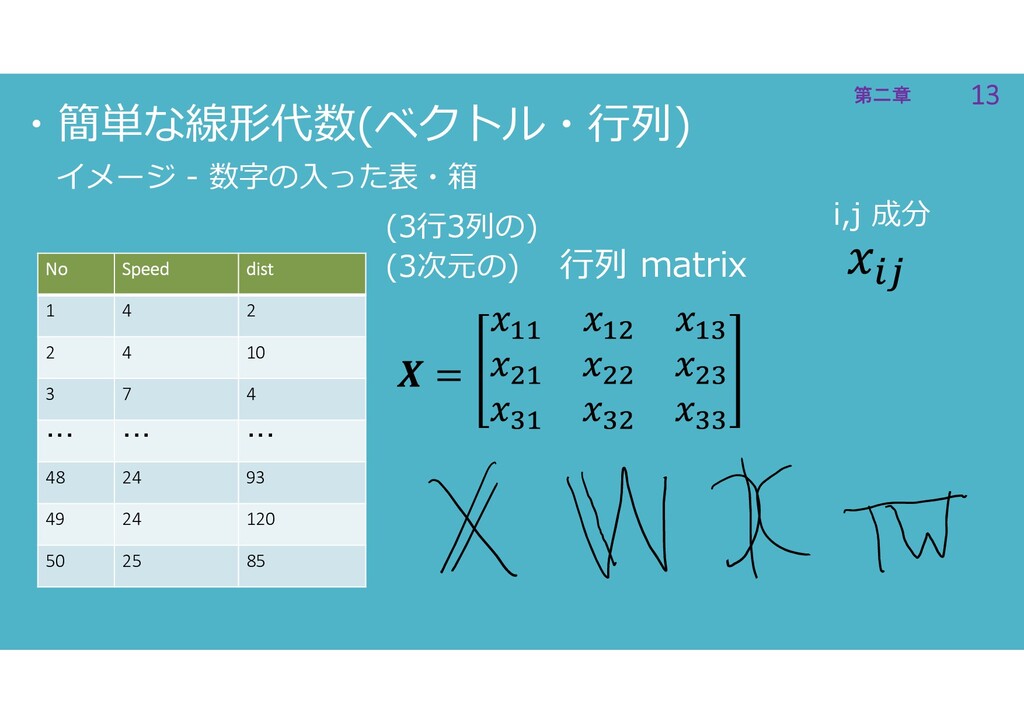
2 2 4 10 3 7 4 ・・・ ・・・ ・・・ 48 24 93 49 24 120 50 25 85 イメージ - 数字の入った表・箱 行ベクトル row vector 列ベクトル column vector 転置 T transpose
13 第二章 13 第二章 ・簡単な線形代数(ベクトル・行列) No Speed dist 1 4
2 2 4 10 3 7 4 ・・・ ・・・ ・・・ 48 24 93 49 24 120 50 25 85 イメージ - 数字の入った表・箱 (3行3列の) (3次元の) 行列 matrix i,j 成分
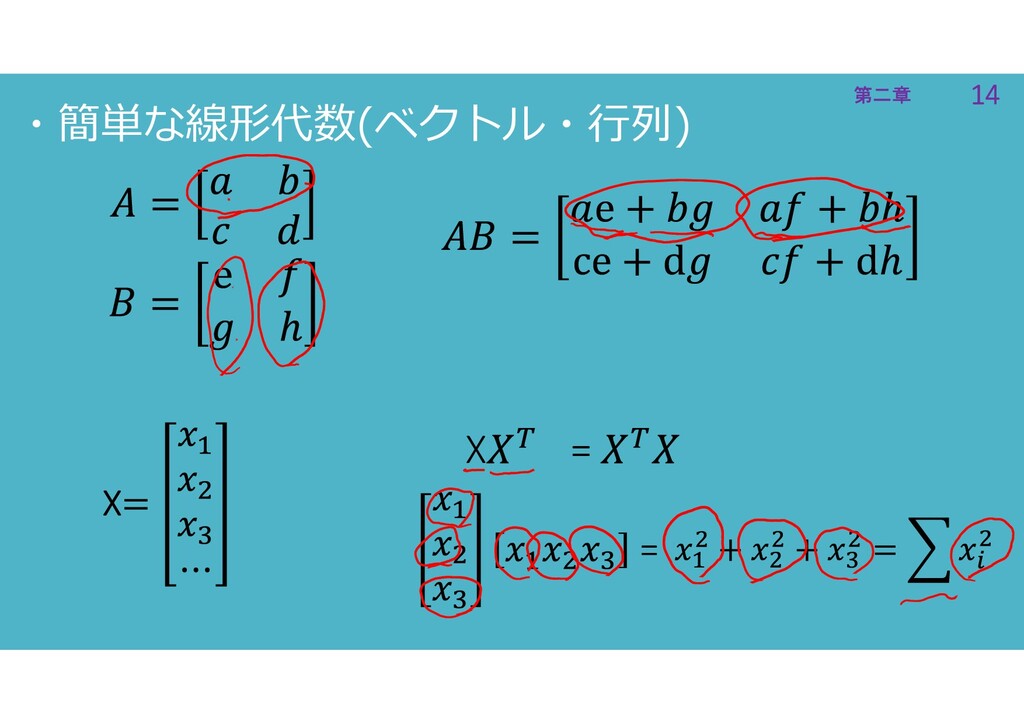
14 第二章 14 第二章 X = X = ・簡単な線形代数(ベクトル・行列)
15 第二章 15 第二章 現象の定式化(モデル化)と誤差
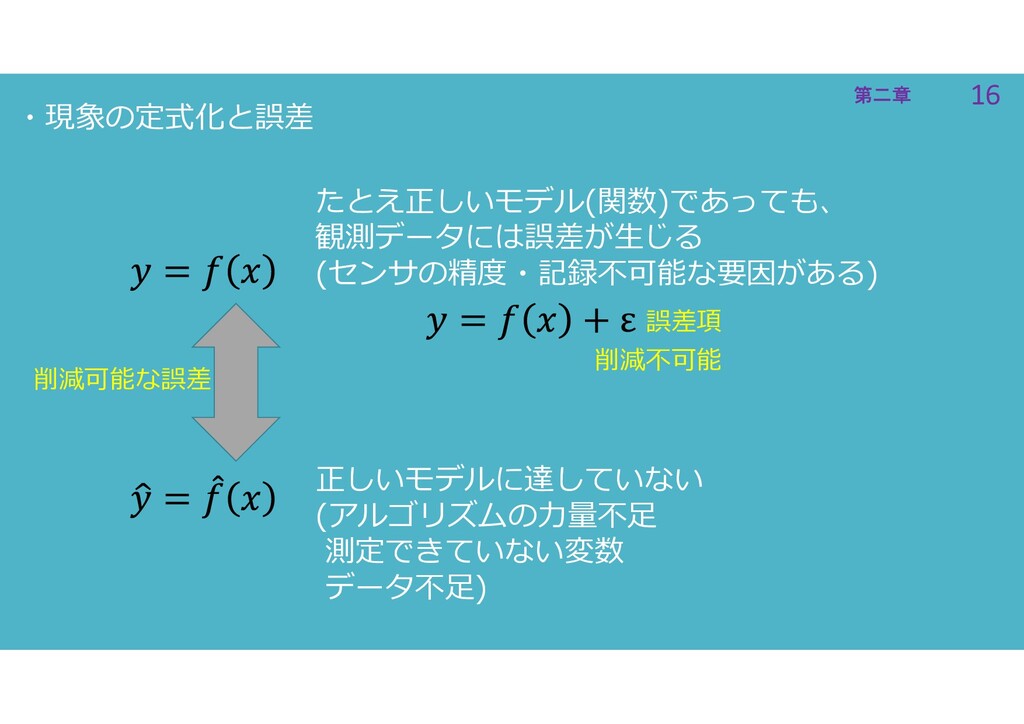
16 第二章 16 第二章 ・現象の定式化と誤差 たとえ正しいモデル(関数)であっても、 観測データには誤差が生じる (センサの精度・記録不可能な要因がある) 誤差項 正しいモデルに達していない
(アルゴリズムの力量不足 測定できていない変数 データ不足) 削減不可能 削減可能な誤差
17 第二章 17 第二章 パラメトリック ノンパラメトリック なモデルと 過学習
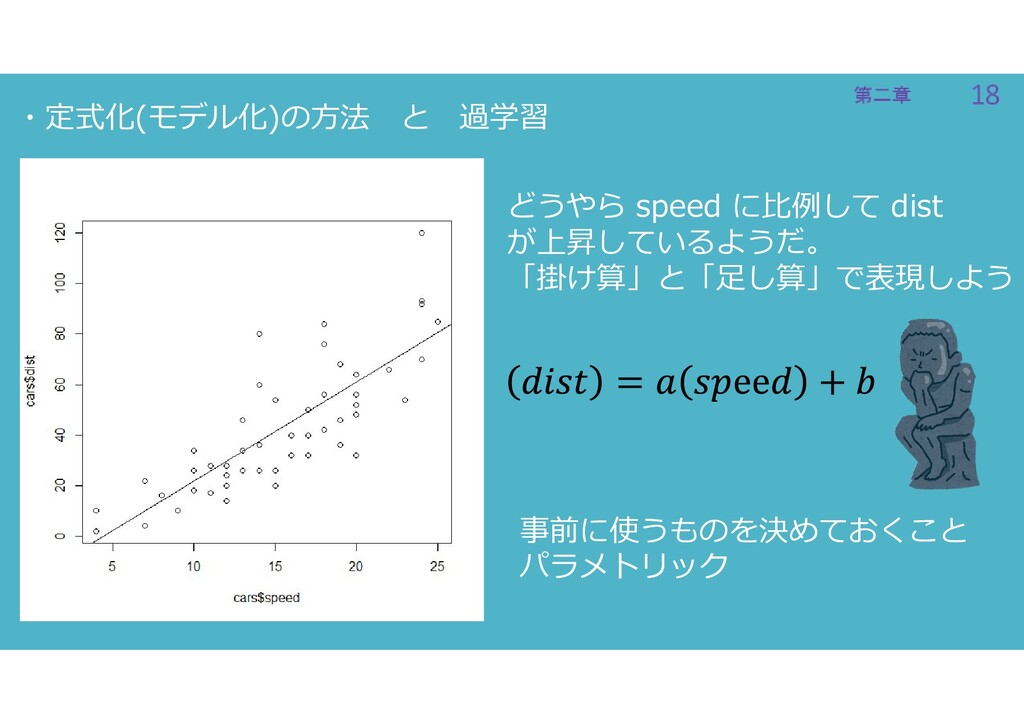
18 第二章 18 第二章 ・定式化(モデル化)の方法 と 過学習 どうやら speed に比例して
dist が上昇しているようだ。 「掛け算」と「足し算」で表現しよう 事前に使うものを決めておくこと パラメトリック
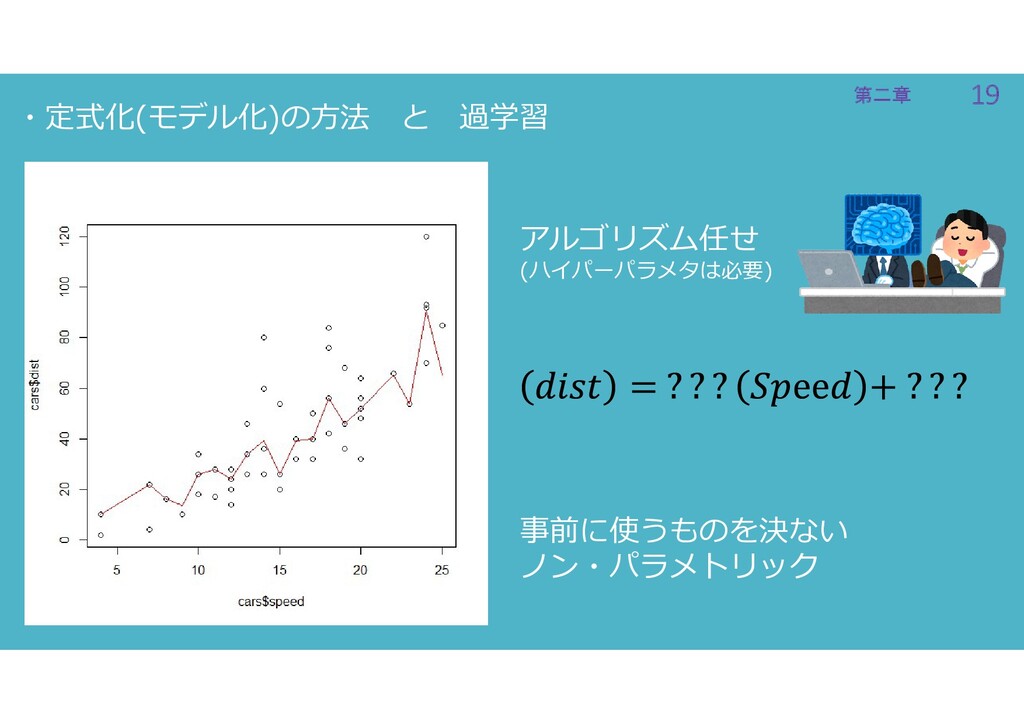
19 第二章 19 第二章 ・定式化(モデル化)の方法 と 過学習 アルゴリズム任せ (ハイパーパラメタは必要) 事前に使うものを決ない
ノン・パラメトリック
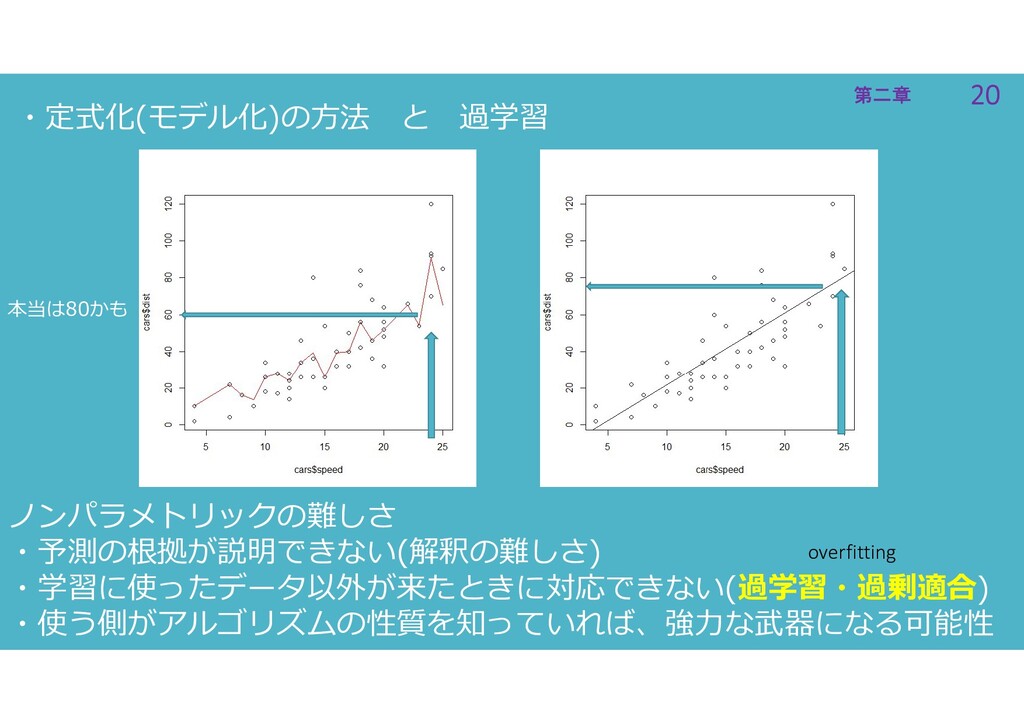
20 第二章 20 第二章 ・定式化(モデル化)の方法 と 過学習 ノンパラメトリックの難しさ ・予測の根拠が説明できない(解釈の難しさ) ・学習に使ったデータ以外が来たときに対応できない(過学習・過剰適合)
・使う側がアルゴリズムの性質を知っていれば、強力な武器になる可能性 本当は80かも overfitting
21 第二章 21 第二章 モデルの評価
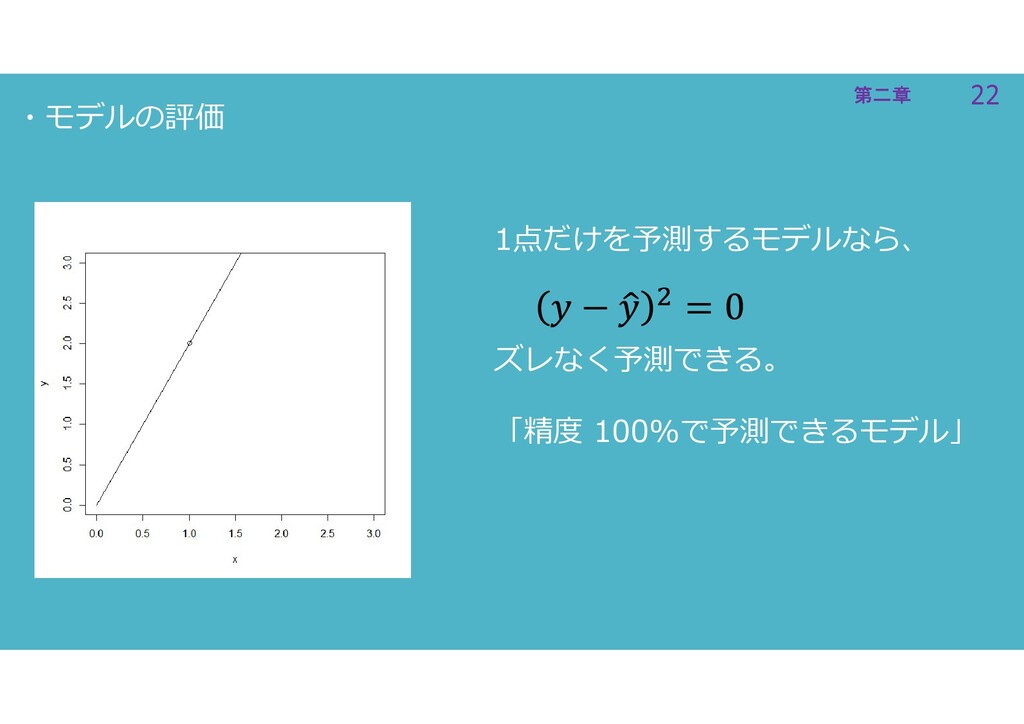
22 第二章 22 第二章 ・モデルの評価 1点だけを予測するモデルなら、 ズレなく予測できる。 「精度 100%で予測できるモデル」
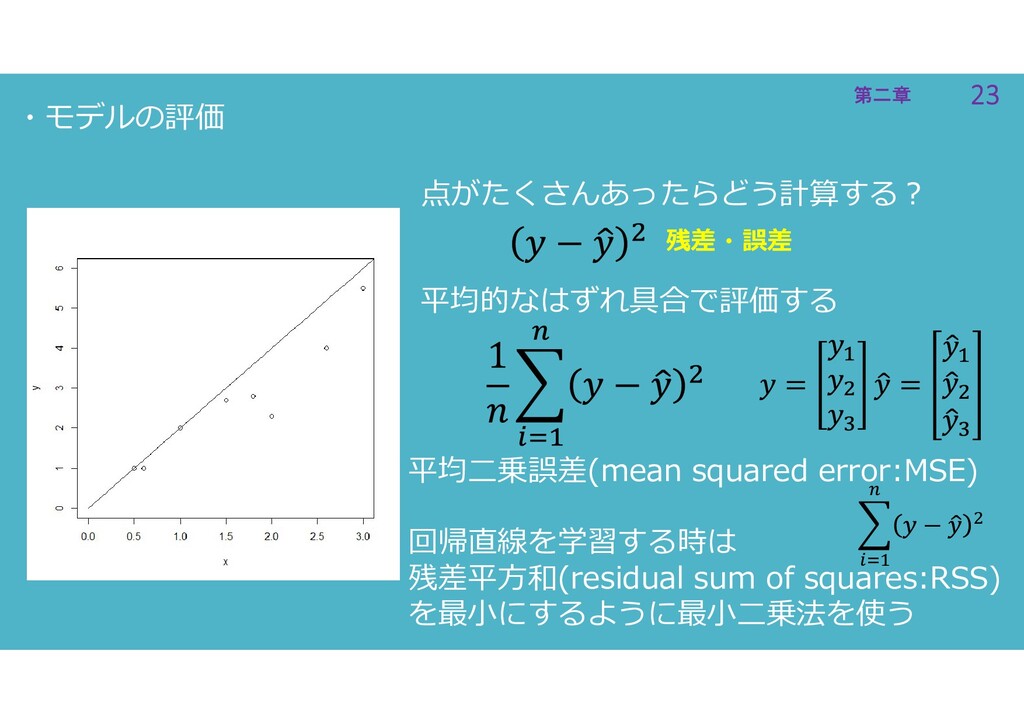
23 第二章 23 第二章 ・モデルの評価 点がたくさんあったらどう計算する? 平均二乗誤差(mean squared error:MSE) 回帰直線を学習する時は
残差平方和(residual sum of squares:RSS) を最小にするように最小二乗法を使う 平均的なはずれ具合で評価する 残差・誤差
24 第二章 24 第二章 ・モデルの評価 「残差」と「誤差」の使い分け ・真のモデルで推定しても残るのが「誤差」 ・仮定モデルと得られたデータの間が「残差」 (話し手によって使い方が異なる場合多し、文脈でくみ取る) 残差・誤差
error residual
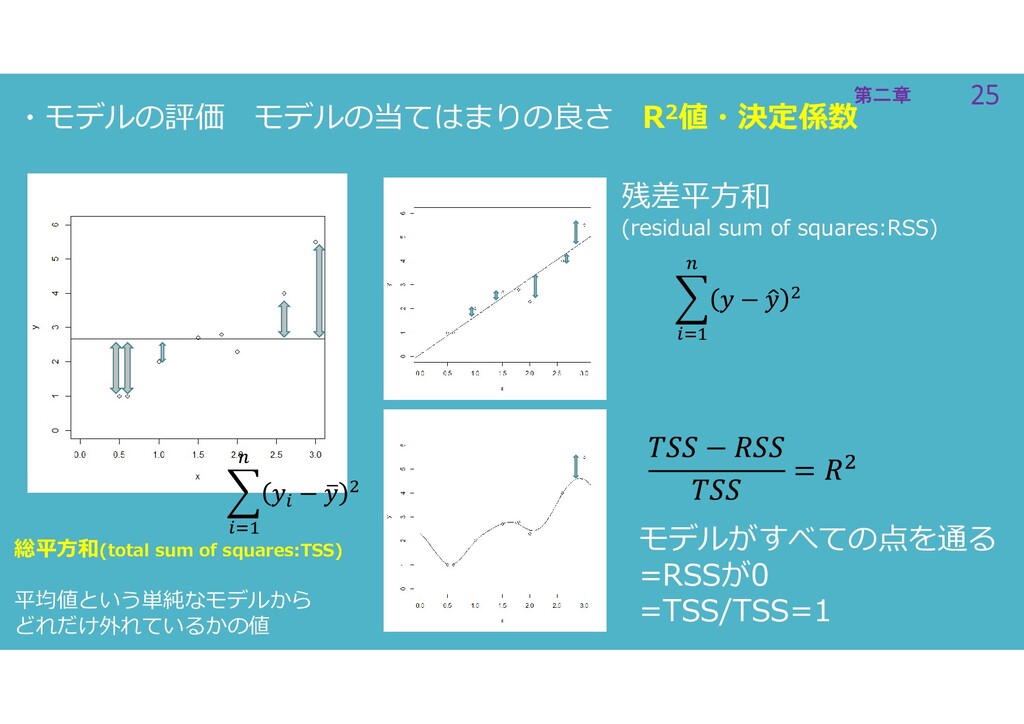
25 第二章 25 第二章 ・モデルの評価 モデルの当てはまりの良さ R2値・決定係数 総平方和(total sum of
squares:TSS) 平均値という単純なモデルから どれだけ外れているかの値 残差平方和 (residual sum of squares:RSS) モデルがすべての点を通る =RSSが0 =TSS/TSS=1
26 第二章 26 第二章 モデルの評価 バイアス・バリアンス
27 第二章 27 第二章 ・モデルの評価 (高・低) (バイアス・バリアンス) なモデル バイアス バリアンス
モデルが単純で、真のモデルと離れている 真のモデルも極めて単純ならば問題は起こりにくい 新しいデータに対して、モデルの予測値がどれだけ外れているか 「高バリアンスなモデル」とは既存のデータにあわせすぎて、 新しいデータに対応できないモデルのこと 汎化性 訓練(学習)データ
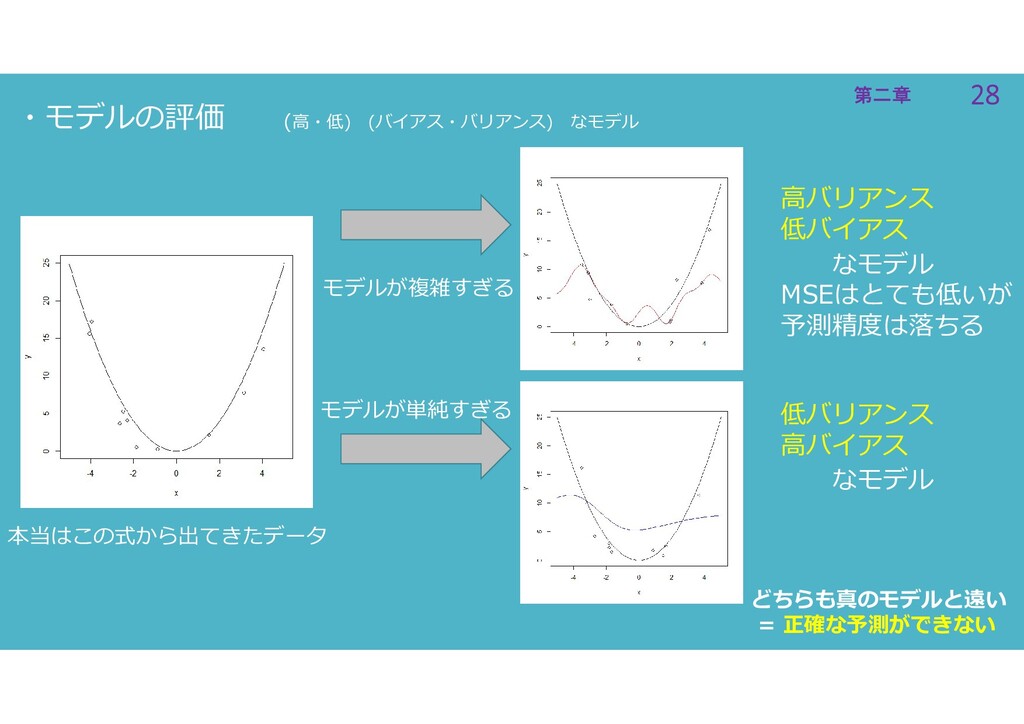
28 第二章 28 第二章 ・モデルの評価 (高・低) (バイアス・バリアンス) なモデル 本当はこの式から出てきたデータ モデルが複雑すぎる
モデルが単純すぎる 高バリアンス 低バイアス 低バリアンス 高バイアス なモデル MSEはとても低いが 予測精度は落ちる なモデル どちらも真のモデルと遠い = 正確な予測ができない
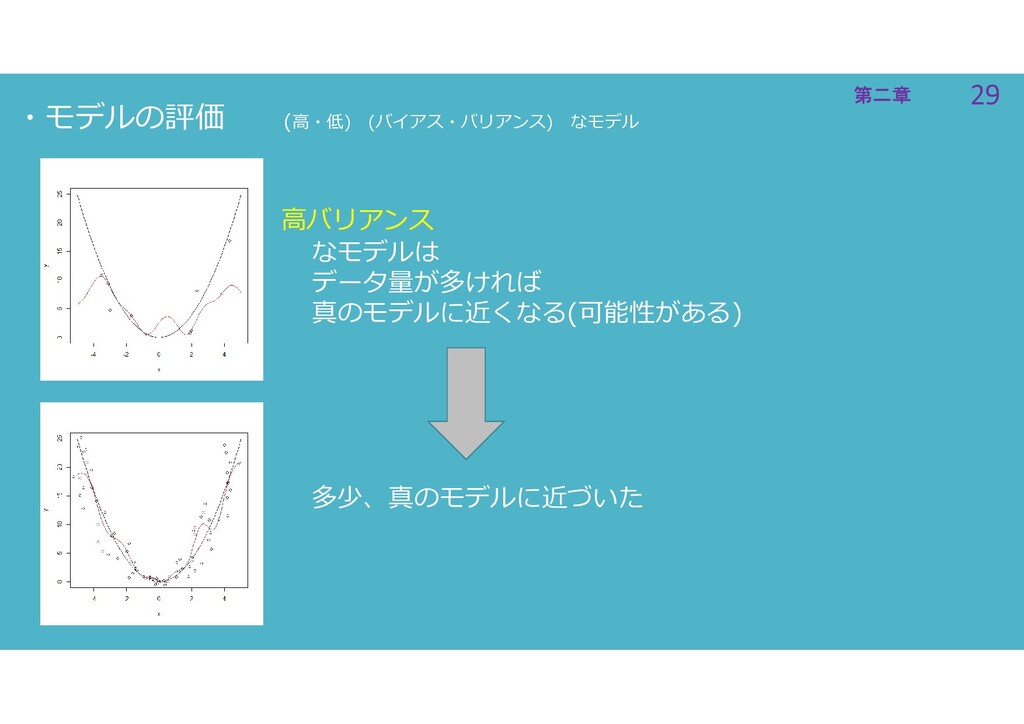
29 第二章 29 第二章 ・モデルの評価 (高・低) (バイアス・バリアンス) なモデル 高バリアンス なモデルは
データ量が多ければ 真のモデルに近くなる(可能性がある) 多少、真のモデルに近づいた
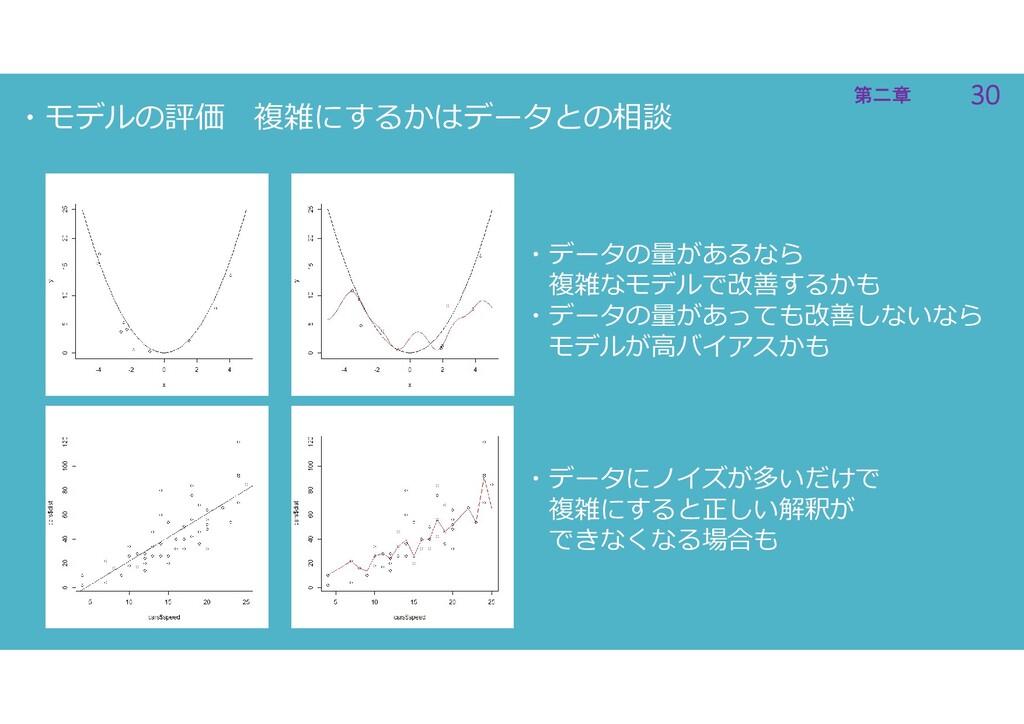
30 第二章 30 第二章 ・モデルの評価 複雑にするかはデータとの相談 ・データの量があるなら 複雑なモデルで改善するかも ・データの量があっても改善しないなら モデルが高バイアスかも
・データにノイズが多いだけで 複雑にすると正しい解釈が できなくなる場合も
31 第二章 31 第二章 重回帰
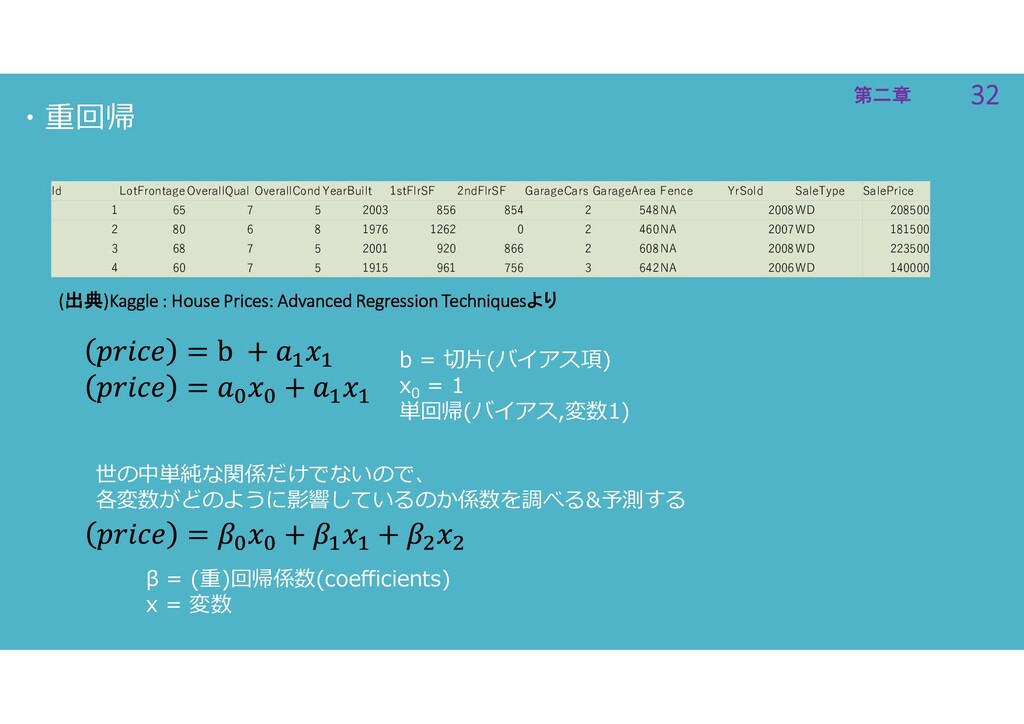
32 第二章 32 第二章 (出典)Kaggle : House Prices: Advanced Regression
Techniquesより Id LotFrontageOverallQual OverallCondYearBuilt 1stFlrSF 2ndFlrSF GarageCars GarageArea Fence YrSold SaleType SalePrice 1 65 7 5 2003 856 854 2 548NA 2008WD 208500 2 80 6 8 1976 1262 0 2 460NA 2007WD 181500 3 68 7 5 2001 920 866 2 608NA 2008WD 223500 4 60 7 5 1915 961 756 3 642NA 2006WD 140000 ・重回帰 β = (重)回帰係数(coefficients) x = 変数 b = 切片(バイアス項) x0 = 1 単回帰(バイアス,変数1) 世の中単純な関係だけでないので、 各変数がどのように影響しているのか係数を調べる&予測する
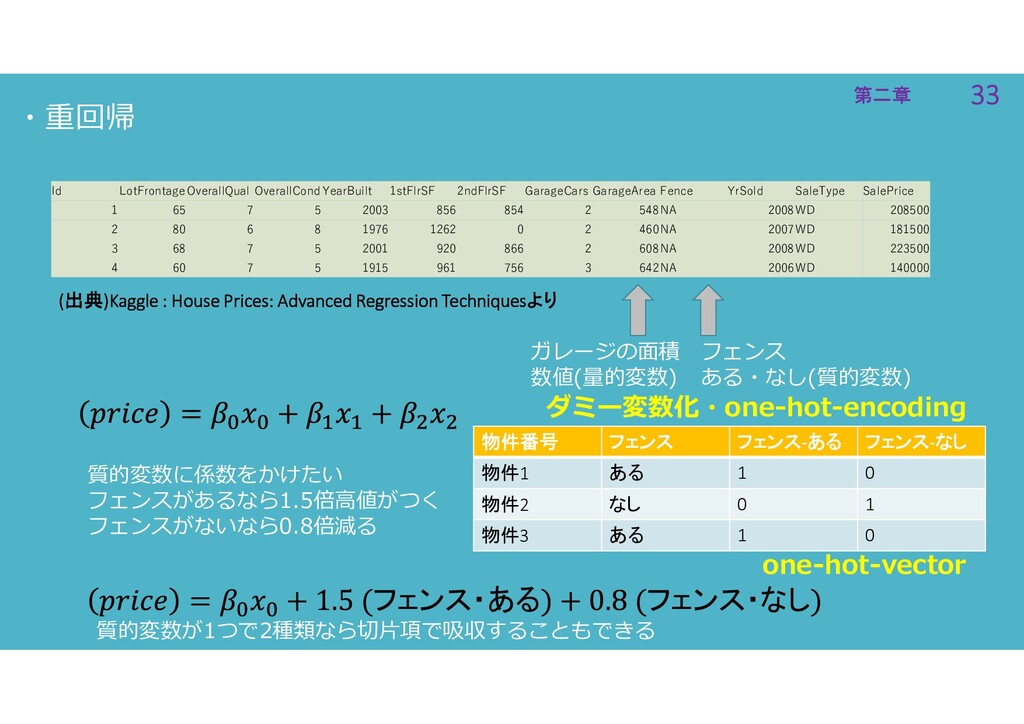
33 第二章 33 第二章 (出典)Kaggle : House Prices: Advanced Regression
Techniquesより Id LotFrontageOverallQual OverallCondYearBuilt 1stFlrSF 2ndFlrSF GarageCars GarageArea Fence YrSold SaleType SalePrice 1 65 7 5 2003 856 854 2 548NA 2008WD 208500 2 80 6 8 1976 1262 0 2 460NA 2007WD 181500 3 68 7 5 2001 920 866 2 608NA 2008WD 223500 4 60 7 5 1915 961 756 3 642NA 2006WD 140000 ・重回帰 ガレージの面積 数値(量的変数) フェンス ある・なし(質的変数) 質的変数に係数をかけたい フェンスがあるなら1.5倍高値がつく フェンスがないなら0.8倍減る 物件番号 フェンス フェンス-ある フェンス-なし 物件1 ある 1 0 物件2 なし 0 1 物件3 ある 1 0 フェンス・ある フェンス・なし ダミー変数化・one-hot-encoding one-hot-vector 質的変数が1つで2種類なら切片項で吸収することもできる
34 第二章 34 第二章 係数に関する検定(付録)
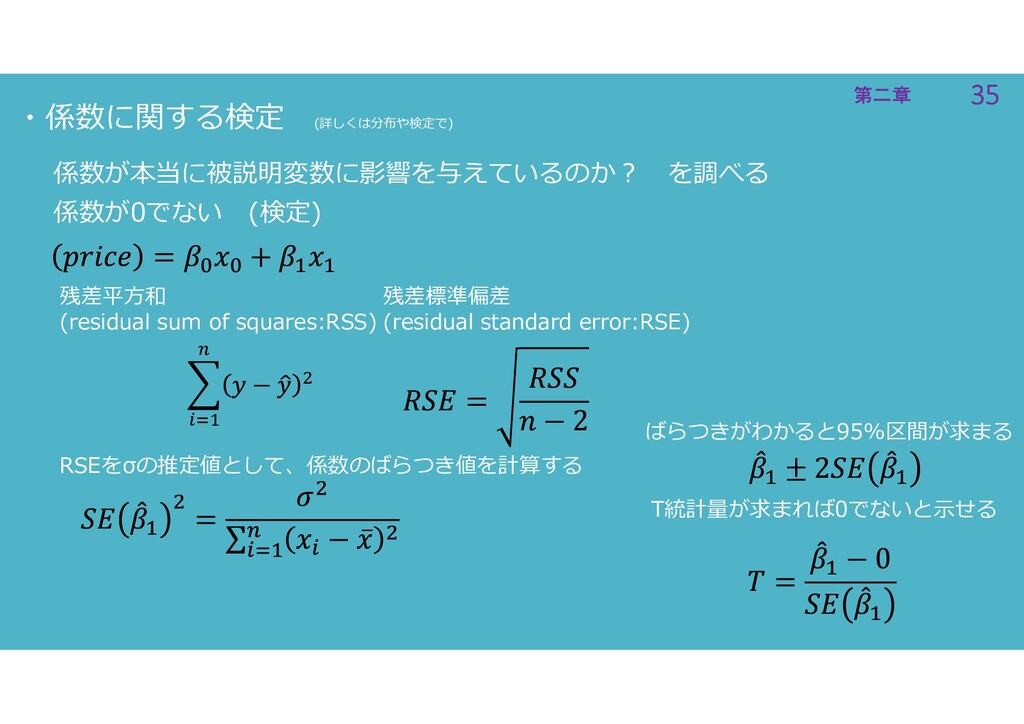
35 第二章 35 第二章 ・係数に関する検定 (詳しくは分布や検定で) 係数が本当に被説明変数に影響を与えているのか? を調べる 係数が0でない (検定)
残差平方和 (residual sum of squares:RSS) 残差標準偏差 (residual standard error:RSE) RSEをσの推定値として、係数のばらつき値を計算する ばらつきがわかると95%区間が求まる T統計量が求まれば0でないと示せる
36 第二章 36 第二章 重回帰のとき 係数が0でない (検定) それぞれの係数でT統計量を計算する もし係数が100個あったら(変数100の重回帰) 係数のうち5%は偶然で「影響あり」という結果を出してしまう
係数の数を考えたF統計量も求める ・係数に関する検定 (詳しくは分布や検定で)
37 第二章 37 第二章 線形回帰のモデル評価できない部分の問題 ①残差の湾曲
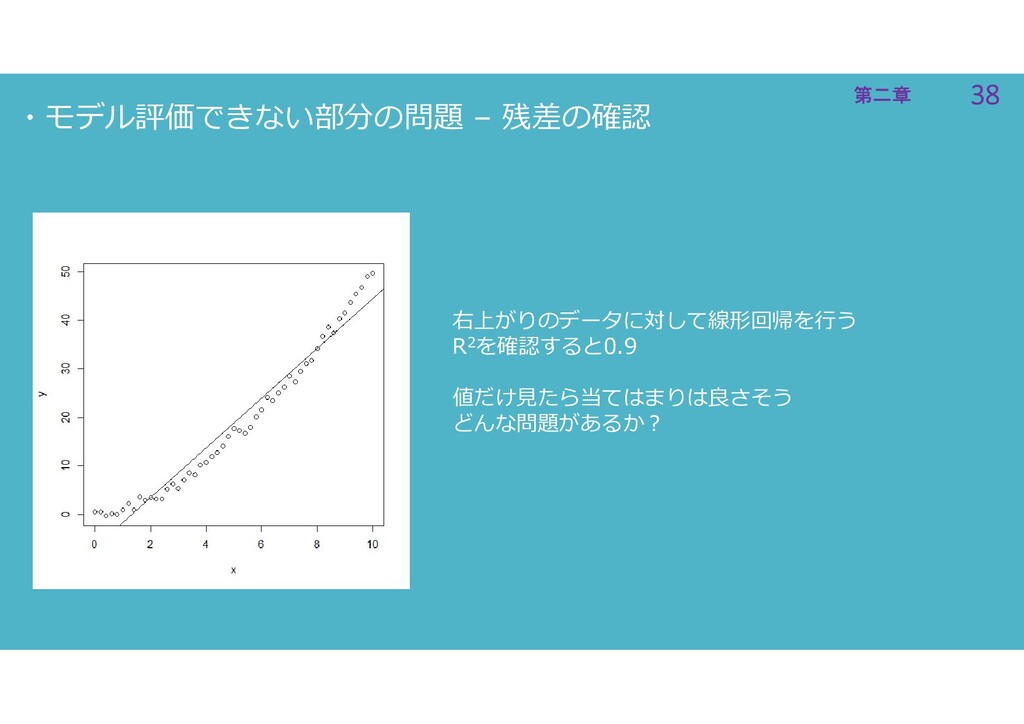
38 第二章 38 第二章 ・モデル評価できない部分の問題 – 残差の確認 右上がりのデータに対して線形回帰を行う R2を確認すると0.9 値だけ見たら当てはまりは良さそう
どんな問題があるか?
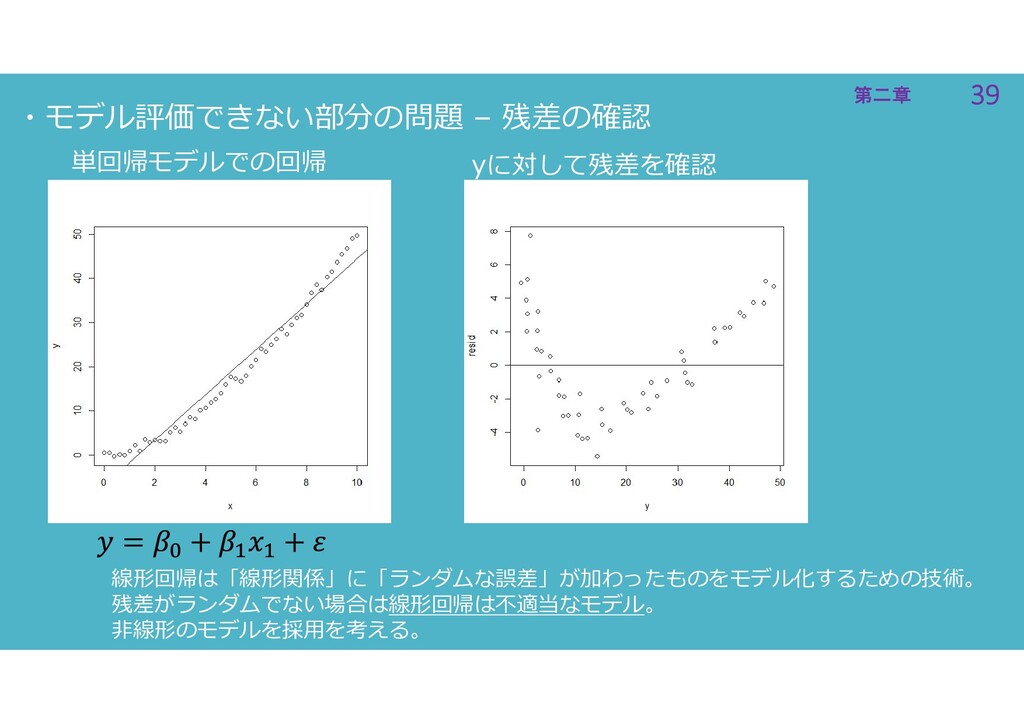
39 第二章 39 第二章 ・モデル評価できない部分の問題 – 残差の確認 yに対して残差を確認 線形回帰は「線形関係」に「ランダムな誤差」が加わったものをモデル化するための技術。 残差がランダムでない場合は線形回帰は不適当なモデル。
非線形のモデルを採用を考える。 単回帰モデルでの回帰
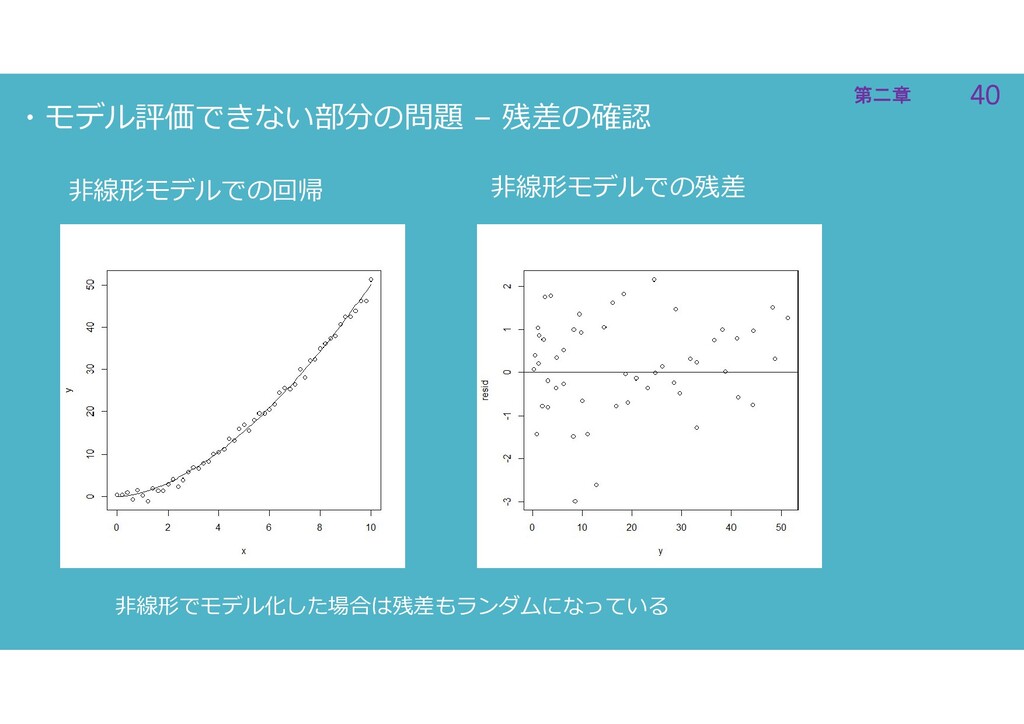
40 第二章 40 第二章 ・モデル評価できない部分の問題 – 残差の確認 非線形モデルでの残差 非線形モデルでの回帰 非線形でモデル化した場合は残差もランダムになっている
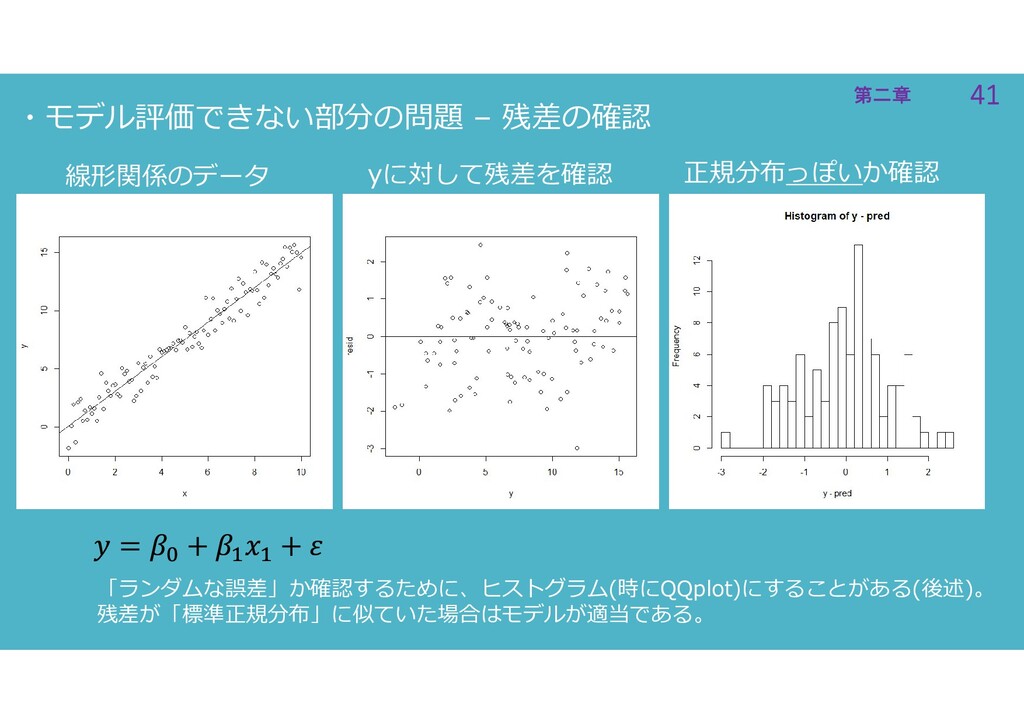
41 第二章 41 第二章 ・モデル評価できない部分の問題 – 残差の確認 線形関係のデータ 正規分布っぽいか確認 「ランダムな誤差」か確認するために、ヒストグラム(時にQQplot)にすることがある(後述)。
残差が「標準正規分布」に似ていた場合はモデルが適当である。 yに対して残差を確認
42 第二章 42 第二章 線形回帰のモデル評価できない部分の問題 ②分散不均一なデータ
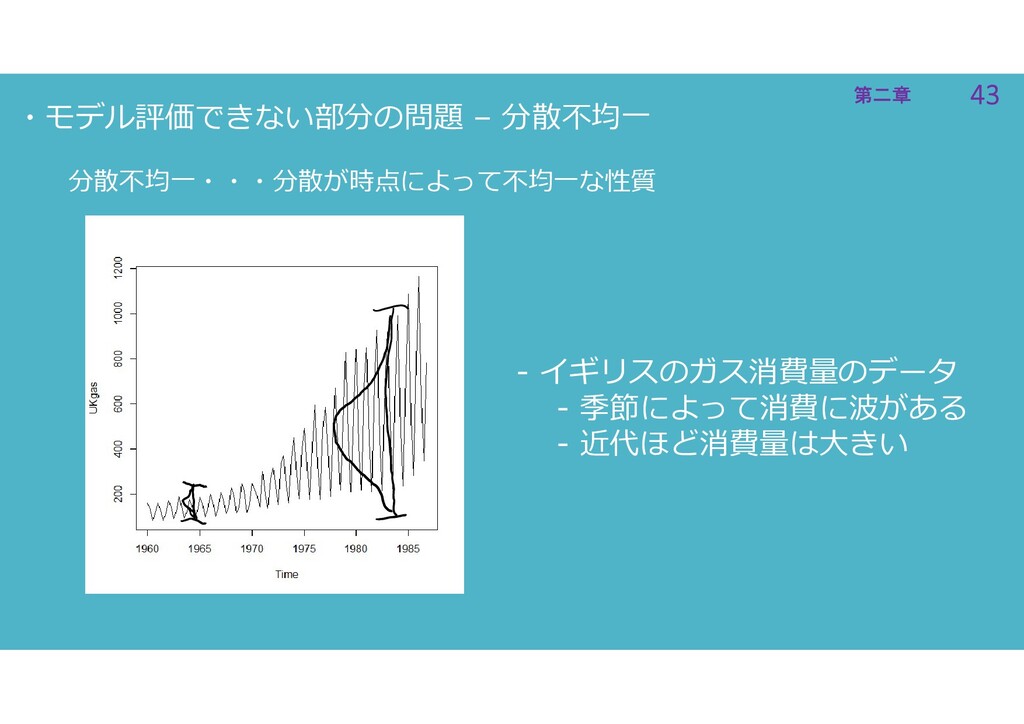
43 第二章 43 第二章 ・モデル評価できない部分の問題 – 分散不均一 分散不均一・・・分散が時点によって不均一な性質 - イギリスのガス消費量のデータ
- 季節によって消費に波がある - 近代ほど消費量は大きい
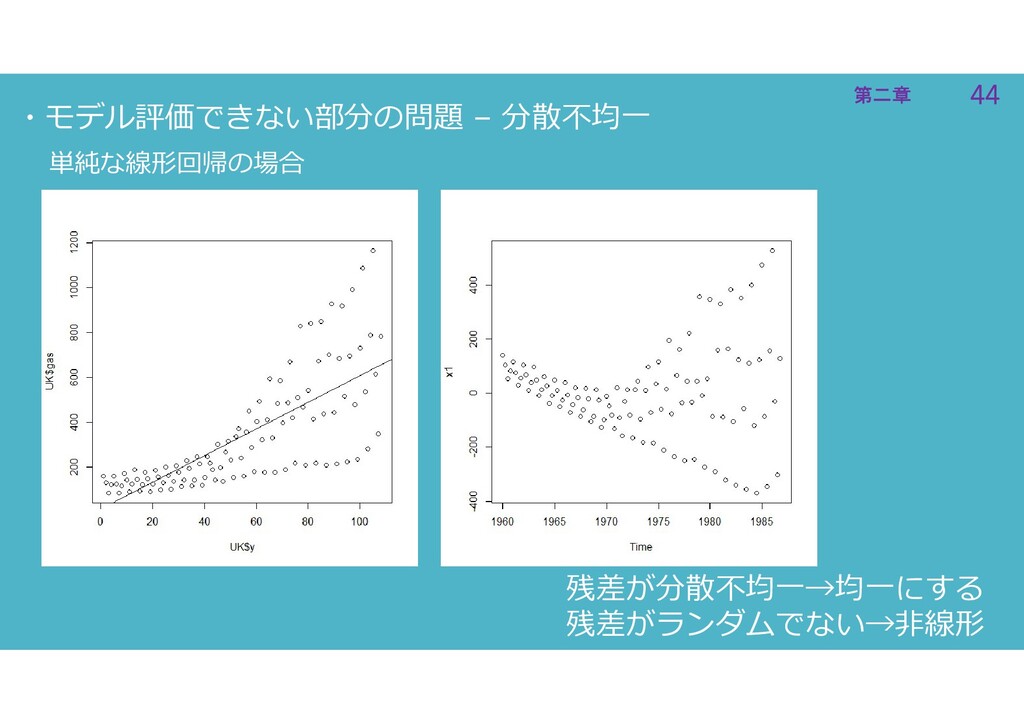
44 第二章 44 第二章 ・モデル評価できない部分の問題 – 分散不均一 単純な線形回帰の場合 残差が分散不均一→均一にする 残差がランダムでない→非線形
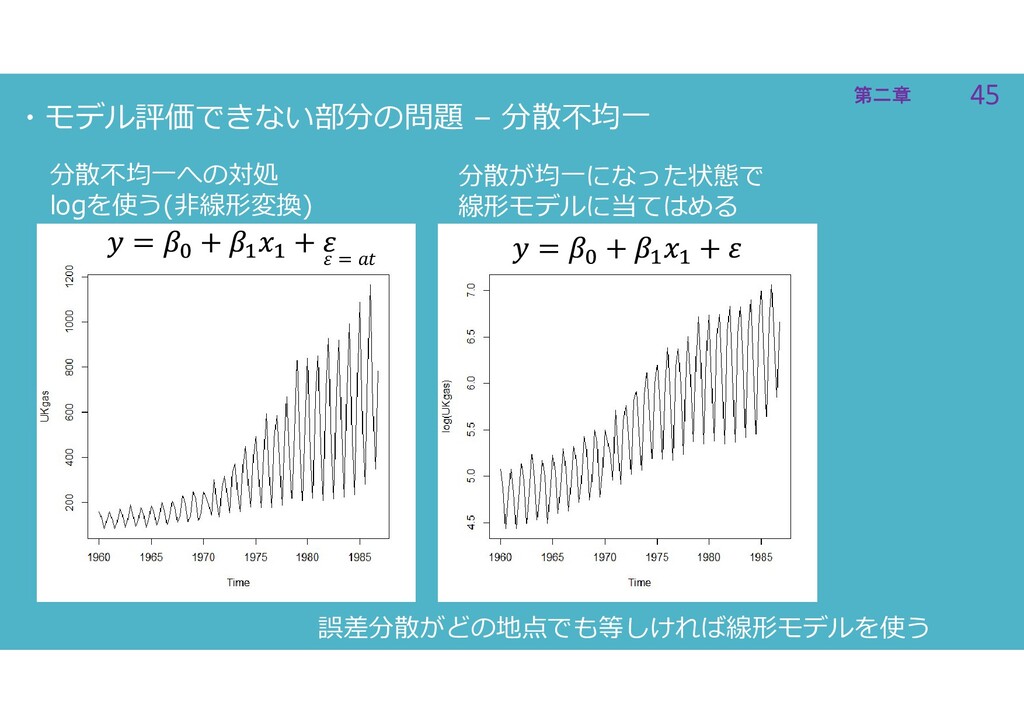
45 第二章 45 第二章 ・モデル評価できない部分の問題 – 分散不均一 分散不均一への対処 logを使う(非線形変換) 分散が均一になった状態で
線形モデルに当てはめる = 誤差分散がどの地点でも等しければ線形モデルを使う
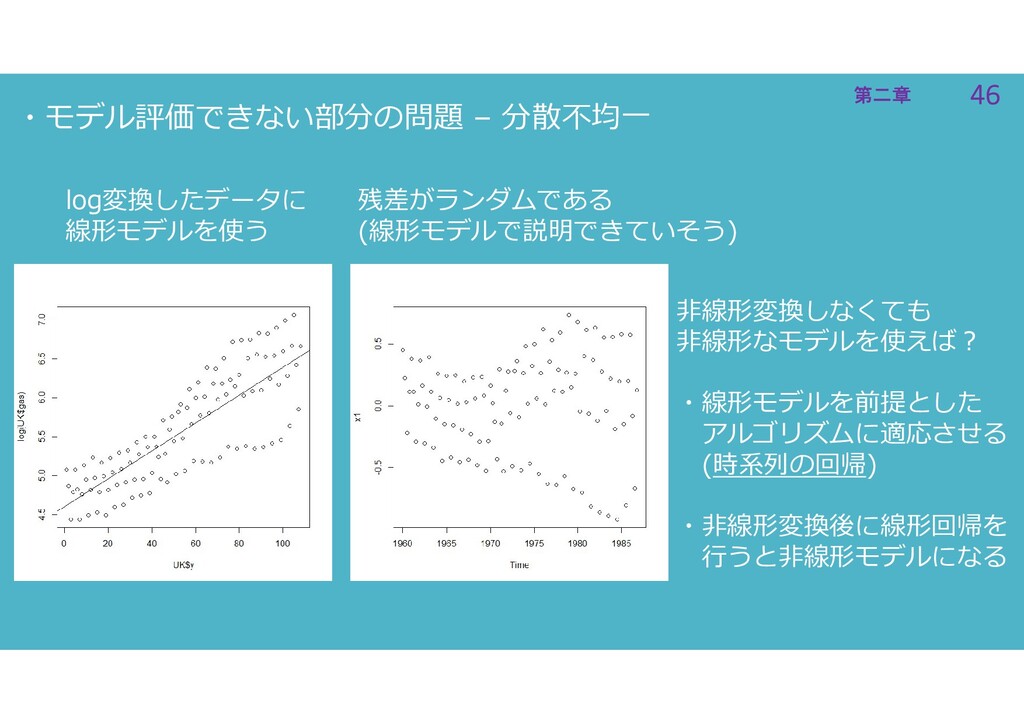
46 第二章 46 第二章 ・モデル評価できない部分の問題 – 分散不均一 log変換したデータに 線形モデルを使う 残差がランダムである
(線形モデルで説明できていそう) 非線形変換しなくても 非線形なモデルを使えば? ・線形モデルを前提とした アルゴリズムに適応させる (時系列の回帰) ・非線形変換後に線形回帰を 行うと非線形モデルになる
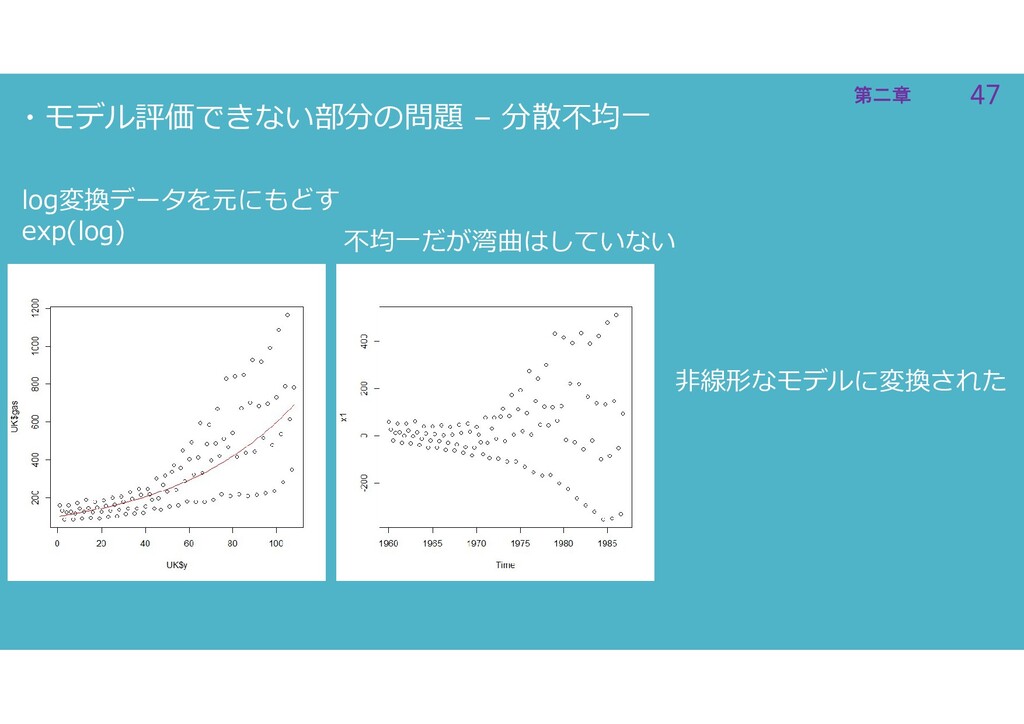
47 第二章 47 第二章 ・モデル評価できない部分の問題 – 分散不均一 log変換データを元にもどす exp(log) 不均一だが湾曲はしていない
非線形なモデルに変換された
48 第二章 48 第二章 線形回帰のモデル評価できない部分の問題 ③はずれ値の処理
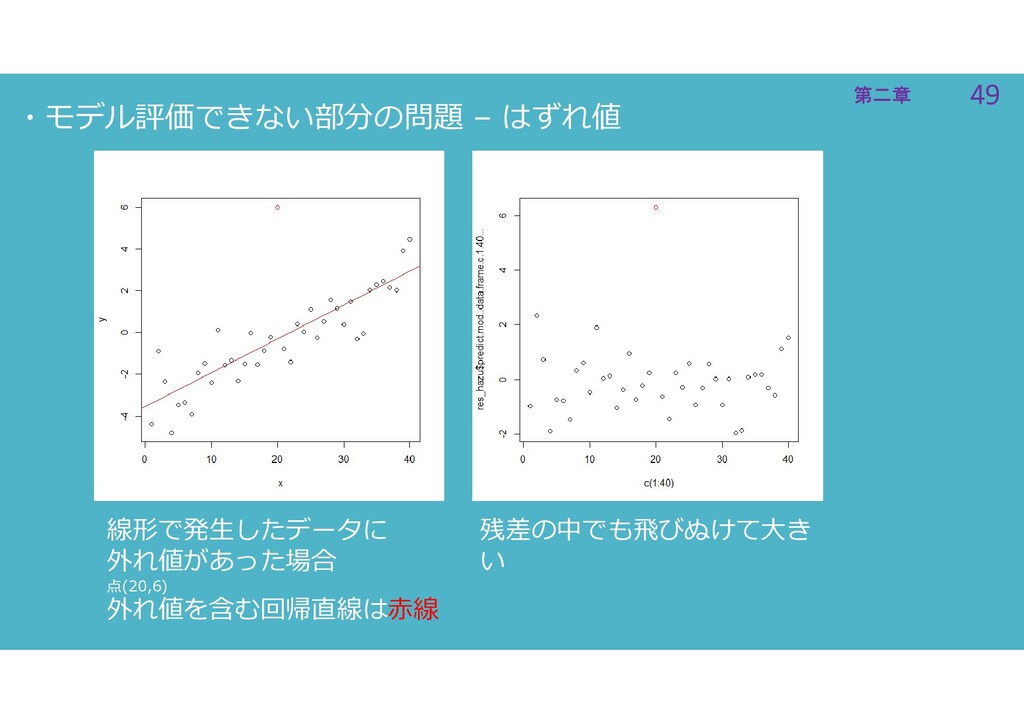
49 第二章 49 第二章 ・モデル評価できない部分の問題 – はずれ値 線形で発生したデータに 外れ値があった場合 点(20,6)
外れ値を含む回帰直線は赤線 残差の中でも飛びぬけて大き い
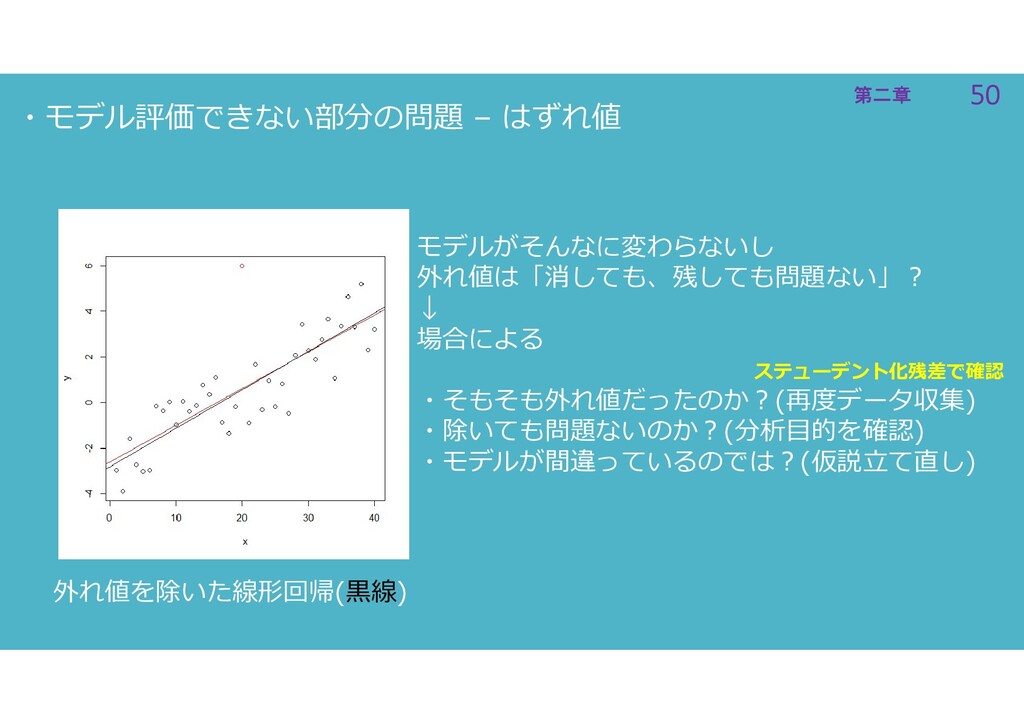
50 第二章 50 第二章 ・モデル評価できない部分の問題 – はずれ値 外れ値を除いた線形回帰(黒線) モデルがそんなに変わらないし 外れ値は「消しても、残しても問題ない」?
↓ 場合による ・そもそも外れ値だったのか?(再度データ収集) ・除いても問題ないのか?(分析目的を確認) ・モデルが間違っているのでは?(仮説立て直し) ステューデント化残差で確認
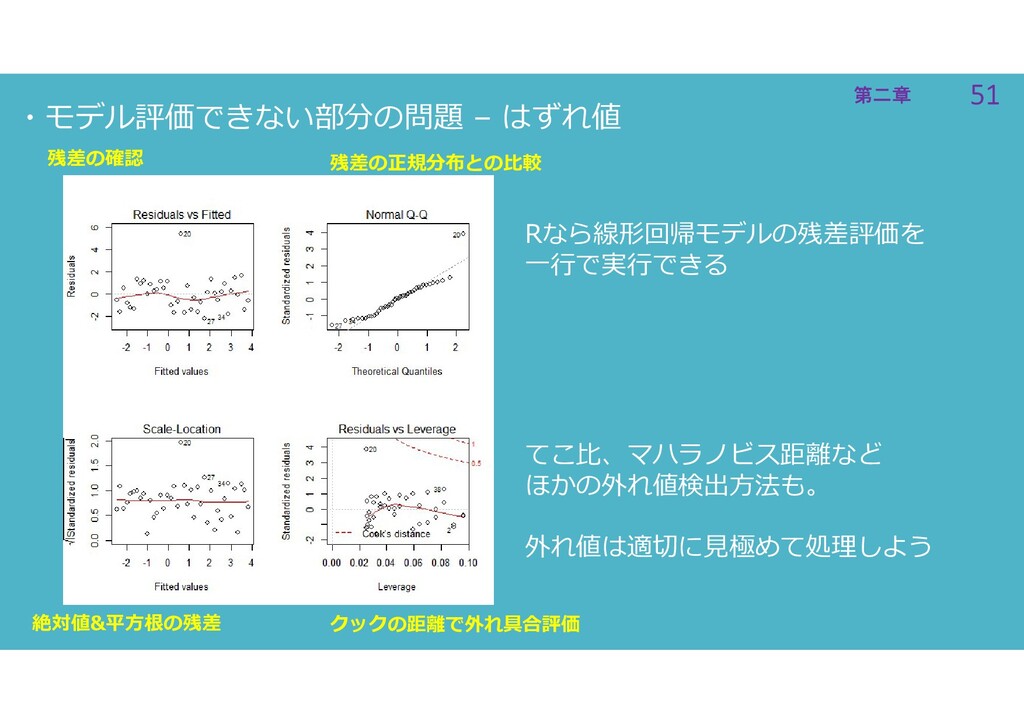
51 第二章 51 第二章 ・モデル評価できない部分の問題 – はずれ値 Rなら線形回帰モデルの残差評価を 一行で実行できる 絶対値&平方根の残差
残差の正規分布との比較 残差の確認 クックの距離で外れ具合評価 てこ比、マハラノビス距離など ほかの外れ値検出方法も。 外れ値は適切に見極めて処理しよう
52 第二章 52 第二章 線形回帰のモデル評価できない部分の問題 ④共線性
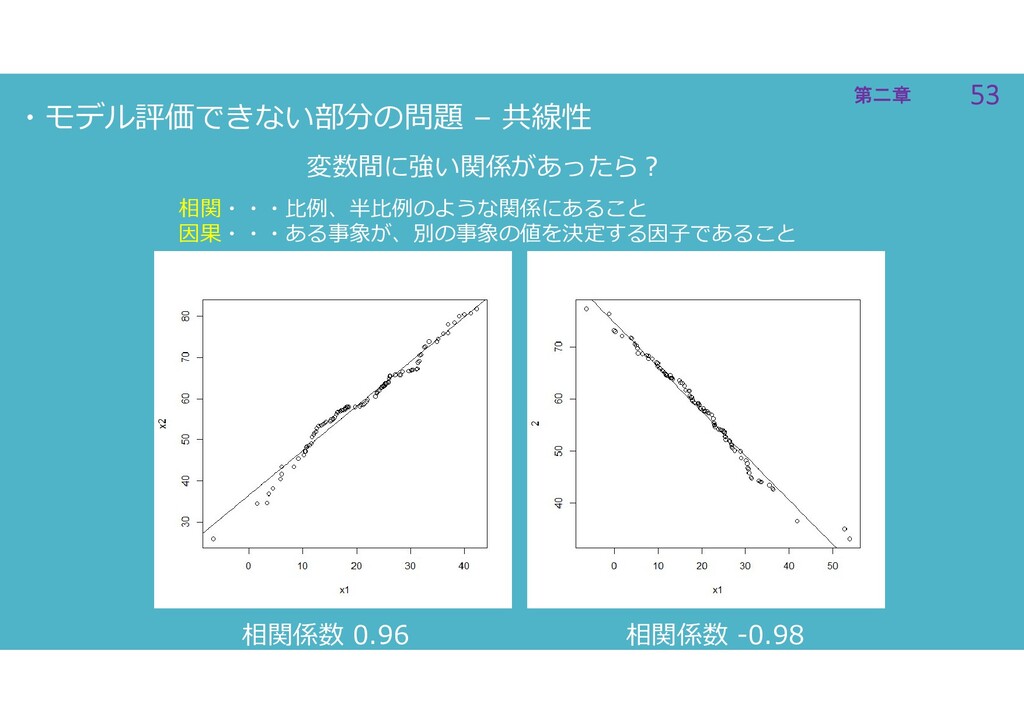
53 第二章 53 第二章 ・モデル評価できない部分の問題 – 共線性 変数間に強い関係があったら? 相関・・・比例、半比例のような関係にあること 因果・・・ある事象が、別の事象の値を決定する因子であること
相関係数 0.96 相関係数 -0.98
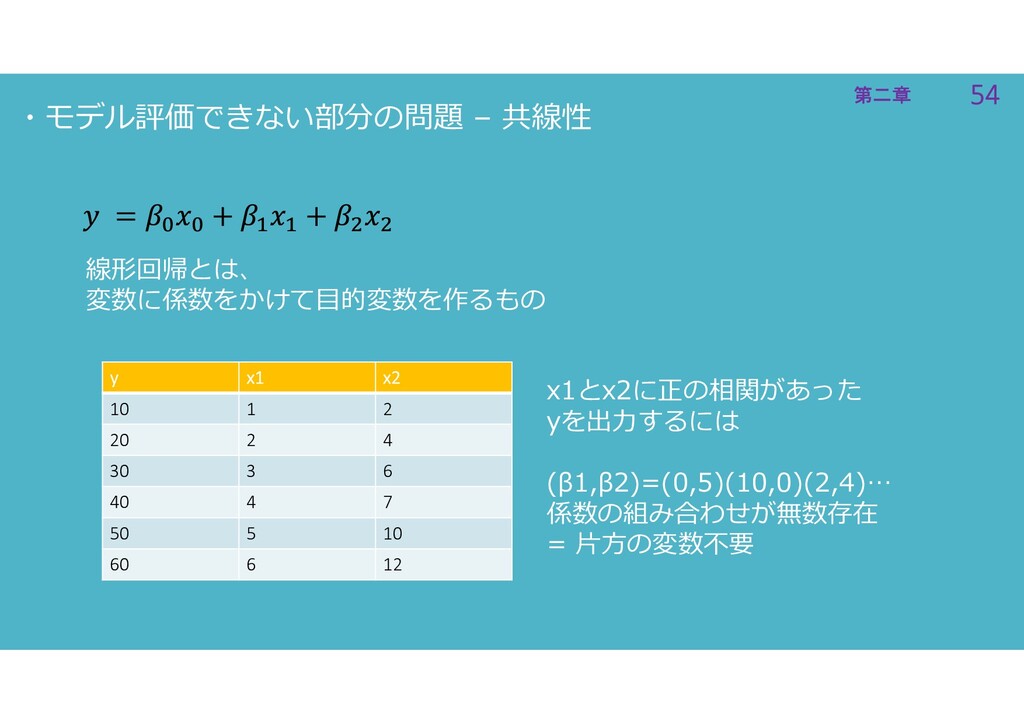
54 第二章 54 第二章 ・モデル評価できない部分の問題 – 共線性 線形回帰とは、 変数に係数をかけて目的変数を作るもの y
x1 x2 10 1 2 20 2 4 30 3 6 40 4 7 50 5 10 60 6 12 x1とx2に正の相関があった yを出力するには (β1,β2)=(0,5)(10,0)(2,4)… 係数の組み合わせが無数存在 = 片方の変数不要
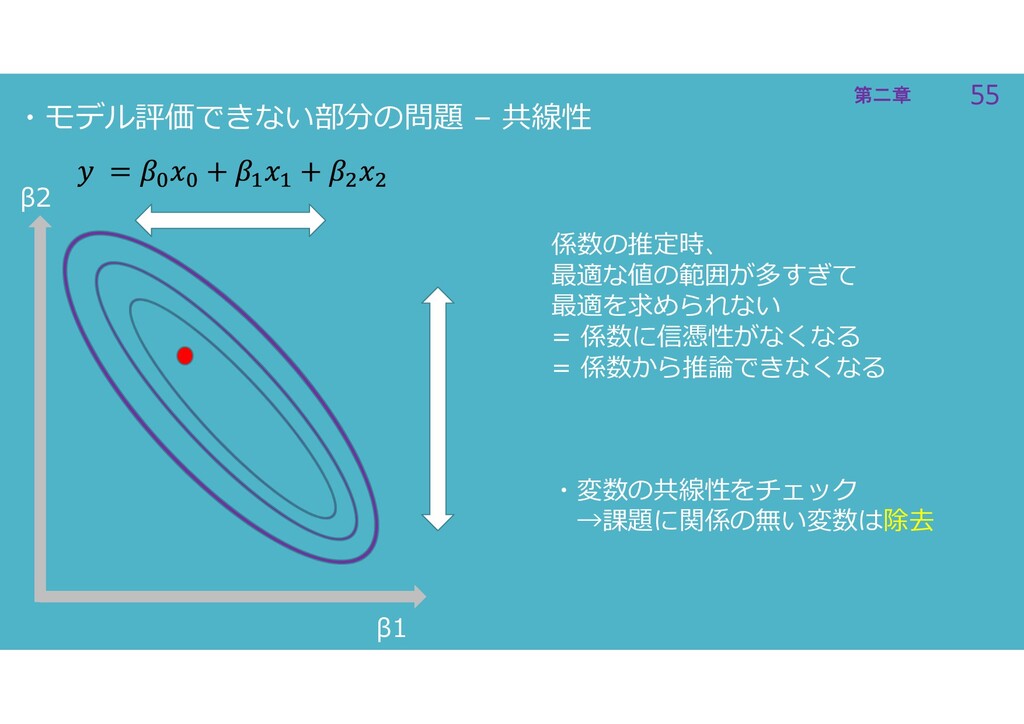
55 第二章 55 第二章 ・モデル評価できない部分の問題 – 共線性 β1 β2 係数の推定時、
最適な値の範囲が多すぎて 最適を求められない = 係数に信憑性がなくなる = 係数から推論できなくなる ・変数の共線性をチェック →課題に関係の無い変数は除去
56 第二章 56 第二章 非線形モデルの ハイパーパラメータの選び方 (K-nn.reg)
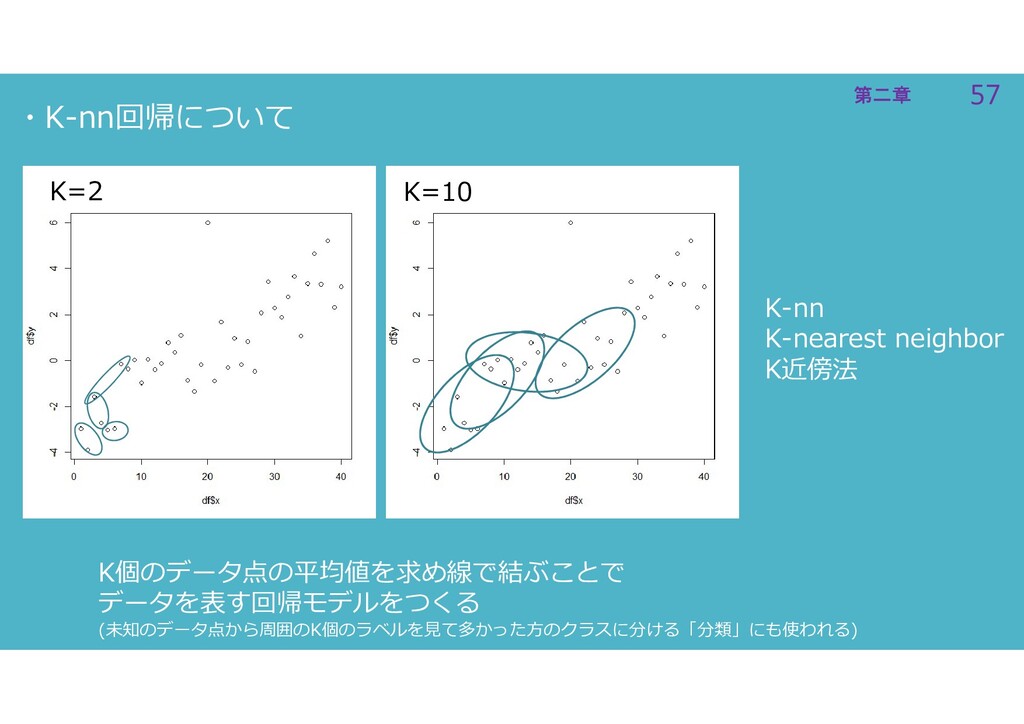
57 第二章 57 第二章 ・K-nn回帰について K-nn K-nearest neighbor K近傍法 K個のデータ点の平均値を求め線で結ぶことで
データを表す回帰モデルをつくる (未知のデータ点から周囲のK個のラベルを見て多かった方のクラスに分ける「分類」にも使われる) K=2 K=10
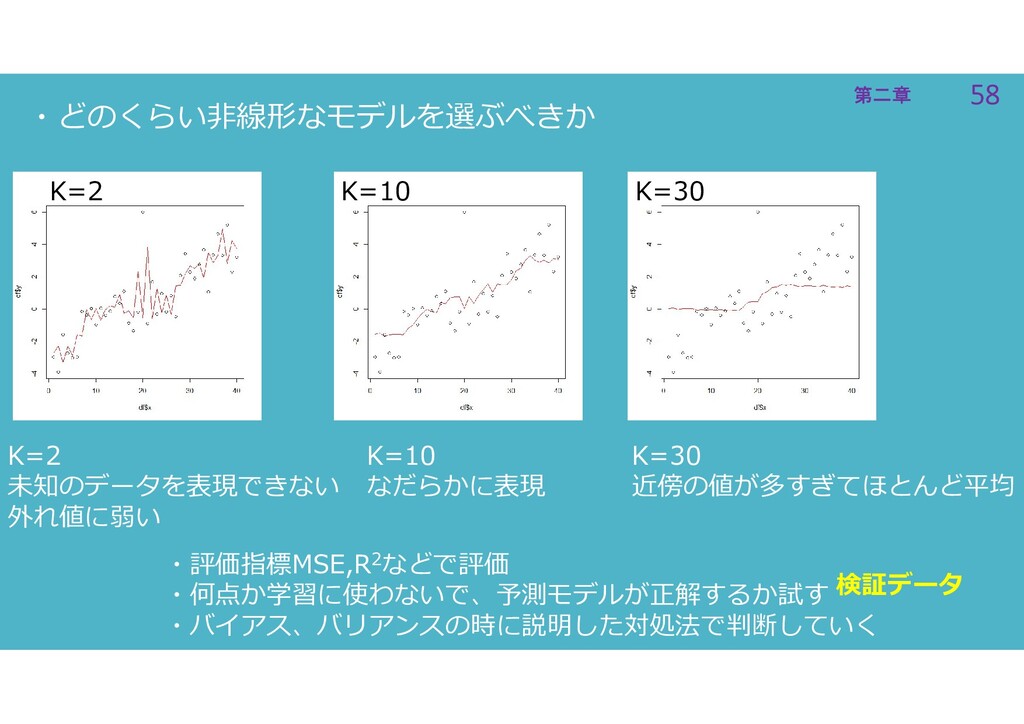
58 第二章 58 第二章 ・どのくらい非線形なモデルを選ぶべきか K=2 K=10 K=30 K=2 未知のデータを表現できない
外れ値に弱い K=10 なだらかに表現 K=30 近傍の値が多すぎてほとんど平均 ・評価指標MSE,R2などで評価 ・何点か学習に使わないで、予測モデルが正解するか試す ・バイアス、バリアンスの時に説明した対処法で判断していく 検証データ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}