Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
第九章-サポートベクターマシン【数学嫌いと学ぶデータサイエンス・統計的学習入門】
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Ringa_hyj
July 22, 2020
Technology
220
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
第九章-サポートベクターマシン【数学嫌いと学ぶデータサイエンス・統計的学習入門】
第九章【数学嫌いと学ぶデータサイエンス・統計的学習入門】
Ringa_hyj
July 22, 2020
More Decks by Ringa_hyj
See All by Ringa_hyj
DVCによるデータバージョン管理
ringa_hyj
0
410
deeplakeによる大規模データのバージョン管理と深層学習フレームワークとの接続
ringa_hyj
0
120
Hydraを使った設定ファイル管理とoptunaプラグインでのパラメータ探索
ringa_hyj
0
240
ClearMLで行うAIプロジェクトの管理(レポート,最適化,再現,デプロイ,オーケストレーション)
ringa_hyj
0
270
Catching up with the tidymodels.[Japan.R 2021 LT]
ringa_hyj
3
880
多次元尺度法MDS
ringa_hyj
0
420
因子分析(仮)
ringa_hyj
0
210
階層、非階層クラスタリング
ringa_hyj
0
160
tidymodels紹介「モデリング過程料理で表現できる説」
ringa_hyj
0
690
Other Decks in Technology
See All in Technology
システム監視入門
grimoh
3
610
歴史から理解するクラウドインフラのしくみ
kizawa2020
0
170
ダッシュボード"開発"について 〜使われるダッシュボードのつくりかた〜
kimichan
0
230
大 AI 時代におけるC# の事情 ~ぶっちゃけトークを交えながら~
nenonaninu
1
220
オートマトンと字句解析でRoslynを読む
tomokusaba
0
100
Jitera Company Deck
jitera
0
590
エンタープライズデータへ安全につなぐ Production-ready なエージェント設計 ― AI × MCP リファレンスアーキテクチャ ― #AIDevDay
cdataj
1
150
コンポーネント名には何を含めるべきなのか? / what-should-be-included-in-component-names
airrnot1106
0
120
データ活用研修 問いの発見と仮説構築【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
430
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.7k
Flutter研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
190
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
740
Featured
See All Featured
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.5k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.6k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Java REST API Framework Comparison - PWX 2021
mraible
34
9.6k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
510
RailsConf 2023
tenderlove
30
1.5k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1.1k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
330
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Transcript
日本一の数学嫌いと学ぶ データサイエンス ~入門~ @Ringa_hyj
@Ringa_hyj 日本一の数学嫌いと学ぶ データサイエンス ~第九章:サポートベクターマシン~
対象視聴者: 数式や記号を見ただけで 教科書を閉じたくなるレベル , , C , ,
サポートベクターマシン ・マージン最大化分類器 ・サポートベクター分類器 ・サポートベクターマシン ・ロジスティック回帰との関係
マージン最大化分類器
・サポートベクターマシン概要 1990年代から登場したSVMの手法 まず、完全に線形分離可能な場合としての マージン最大化分類木 完全分離でなくとも許す サポートベクター分類木 さらに非線形に拡張したサポートベクターマシン の順で説明する 一般的にはどれもまとめてサポートベクターマシン SVM
と呼ばれる
・マージン最大化分類器 マージン最大化分類器 線形分離が複数次元である場合、分離は線でなく面であり、3次元以上は超平面と呼ばれる p次元で、超平面は p-1次元の平坦なアフィン部分空間(原点を通らない部分空間)である p次元の分離線は β0 + β1X1 +
β2X2 ・・・ βpXp = 0 であり、この直線に対して、Xを当てはめたとき、0以上か0以下かで分類する β0 + β1X1 + β2X2 ・・・ βpXp > 0 ※yi = 1 β0 + β1X1 + β2X2 ・・・ βpXp < 0 ※yi = -1 つまり yi(β0 + β1X1 + β2X2 ・・・ βpXp) >0 という式で表現できる
・マージン最大化分類器 完全分離可能な2クラスの場合、それぞれを-1,1に対応させる -1,1に出力できるような関数をを用いて回帰していくことで分離できる ただし、完全分離可能な場合、分離線は複数引くことができてしまう。
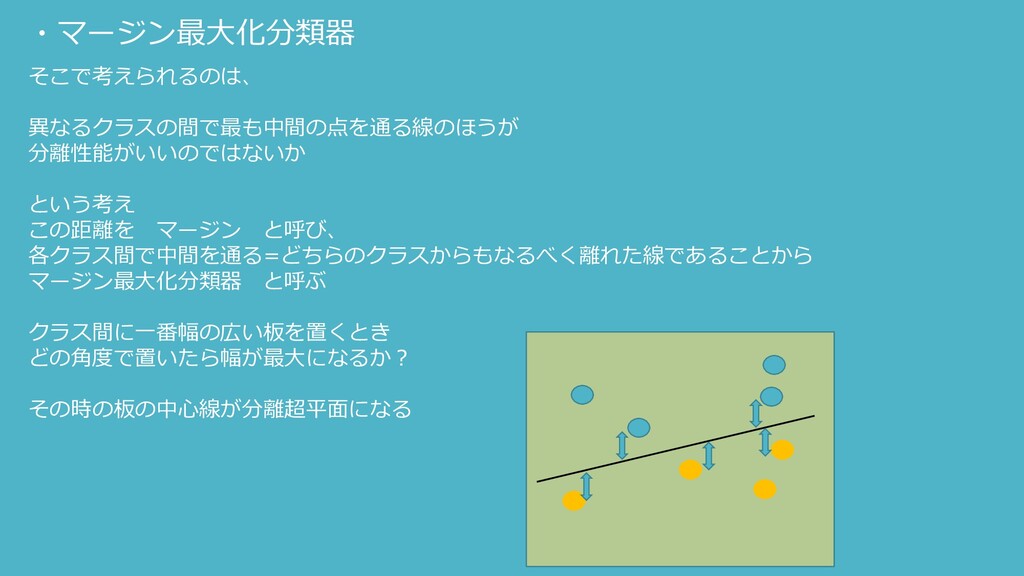
・マージン最大化分類器 そこで考えられるのは、 異なるクラスの間で最も中間の点を通る線のほうが 分離性能がいいのではないか という考え この距離を マージン と呼び、 各クラス間で中間を通る=どちらのクラスからもなるべく離れた線であることから マージン最大化分類器
と呼ぶ クラス間に一番幅の広い板を置くとき どの角度で置いたら幅が最大になるか? その時の板の中心線が分離超平面になる
・マージン最大化分類器 次元数pが大きいと過学習しやすい マージン最大化を考える時に、クラス間で近い点を採用して考える。 板にいくつかのデータ点が接することになる。 この時のデータ点を板を支える「サポート」ことから「サポートベクトル」と呼ぶ 完全分離可能なマージン最大化分類器の場合、 サポートベクトルの位置が変われば分類面も変わるが、 サポートベクトル以外の点は計算に関与しないので関わらない。
・マージン最大化分類器 p変数 n観測値 のデータ行列がある クラスラベルは1,-1 マージン最大化分類器の定式化は max ⅈⅈ ⅇ 0
~ =1 2 = 1 0 + 1 1 + ⋯ + ≥ ただし 係数に制約があり Mは「0を超える正の値」であれば分離平面を作ることができる。 ただし、M=0ということは、分離平面上にデータ点が乗ってしまうことであり 汎化性の面からこれは避けたいという話をした そこで点と線の距離がMだけは離れるように、Mを最大化していく。 制約付き最大化で解けば良い
サポートベクター分類器
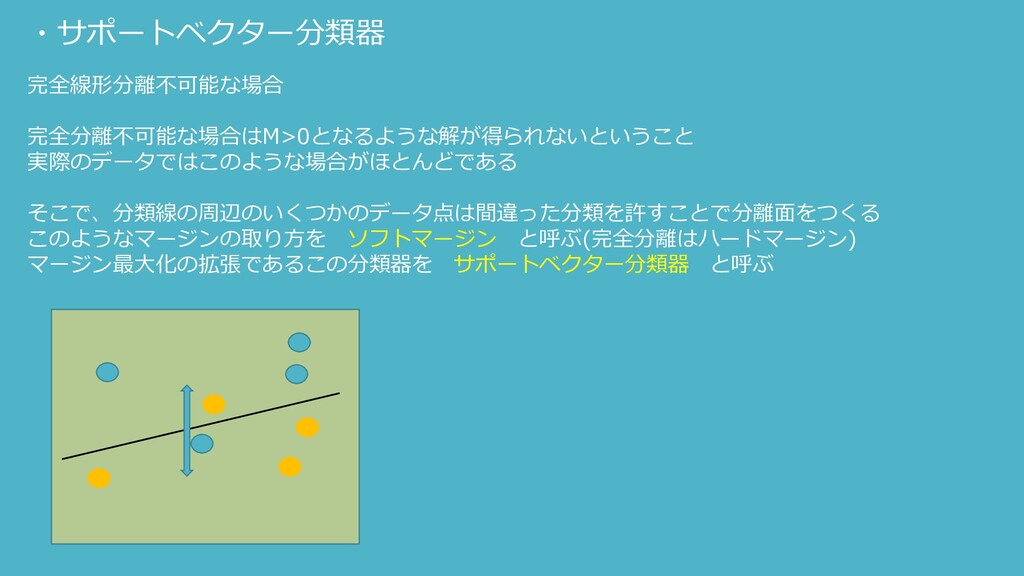
・サポートベクター分類器 完全線形分離不可能な場合 完全分離不可能な場合はM>0となるような解が得られないということ 実際のデータではこのような場合がほとんどである そこで、分類線の周辺のいくつかのデータ点は間違った分類を許すことで分離面をつくる このようなマージンの取り方を ソフトマージン と呼ぶ(完全分離はハードマージン) マージン最大化の拡張であるこの分類器を サポートベクター分類器
と呼ぶ
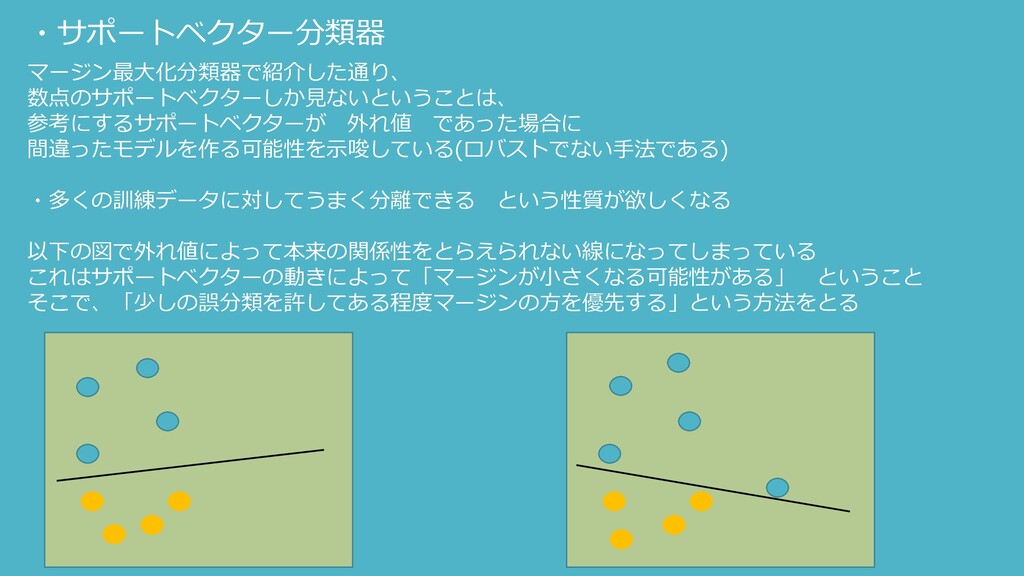
・サポートベクター分類器 マージン最大化分類器で紹介した通り、 数点のサポートベクターしか見ないということは、 参考にするサポートベクターが 外れ値 であった場合に 間違ったモデルを作る可能性を示唆している(ロバストでない手法である) ・多くの訓練データに対してうまく分離できる という性質が欲しくなる 以下の図で外れ値によって本来の関係性をとらえられない線になってしまっている
これはサポートベクターの動きによって「マージンが小さくなる可能性がある」 ということ そこで、「少しの誤分類を許してある程度マージンの方を優先する」という方法をとる
・サポートベクター分類器 Cはチューニングパラメタ εはスラックス変数 εi=0のとき正しいクラスに分離できている。 εi>0のときマージン内の?誤った側である ※i番目観測地はマージンに違反する という εi>1のとき分離平面の誤った側になる max ⅈⅈ
ⅇ 0 ~ ε 1 ~ε ただし 係数に制約があり =1 2 = 1 0 + 1 1 + ⋯ + ≥ (1 − ε ) ε i ≥0 =1 ε 2 ≤ C
・サポートベクター分類器 Cはスラックス変数の合計値を制限している マージンと平面の誤ったサンプルをどの程度許容するかである C=0でマージン最大化分類器となる C>0ならば、超平面の向こう側に超えていい個数は最高でC個である (平面を超えるとε>1のため) Cは交差検証により決められ、Cが大きくなるとマージンも大きくなっていく この分類器はマージン上、マージンに違反するもの のみに影響して学習される 他のデータ点は学習に必要がない
Cが大きければ分類線は適当になり Cが小さければ分類線は敏感に過学習する バイアス バリアンス のトレードオフに関係するパラメタである。
サポートベクターマシン
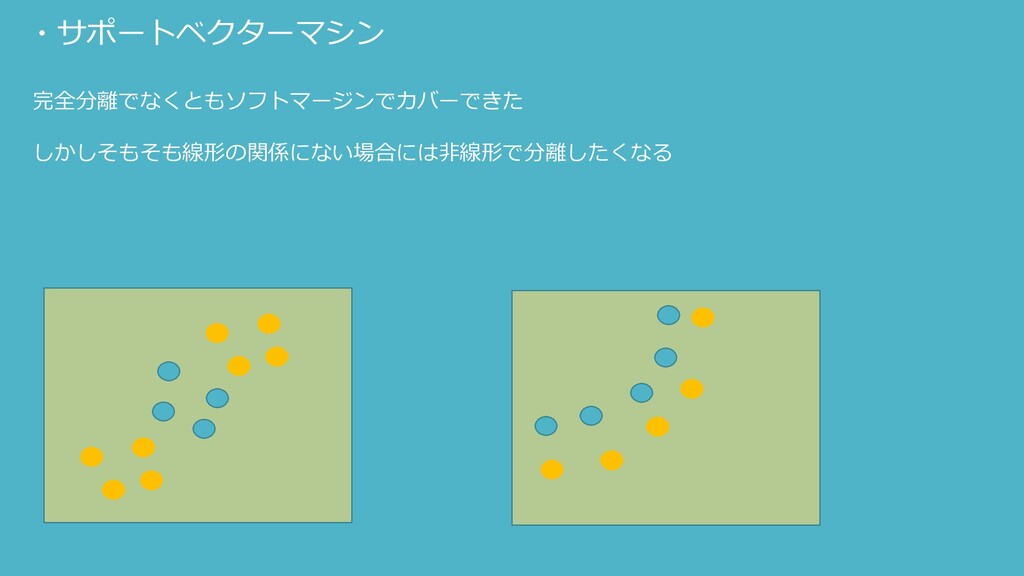
・サポートベクターマシン 完全分離でなくともソフトマージンでカバーできた しかしそもそも線形の関係にない場合には非線形で分離したくなる
・サポートベクターマシン 識別境界を次数を上げた多項式モデルにしてやることを考える 多項式モデルなのでp個の変数Xは2p個に増え、係数も2p個になる 0 + =1 1 +
=1 2 ⅈ 2 ≥ (1-εi ) max ⅈⅈ ⅇ 0 11 ~1 12 ~2 ε 1 ~ε =1 k=1 2 2 = 1 ε i ≥0 =1 ε 2 ≤ C 多項式にすることで使用できる変数が増えた(特徴量空間を広げた) 扱うパラメタも増え、計算量も増える
・サポートベクターマシン 2つのr次元ベクトルa,bの内積 <a,b> = Σ i=1~r a i b i
線形のサポートベクター分類器を内積を使って表現すると , ’ = =1 ’ = 0 + =1 , αはn個のパラメタである。 サポートベクター以外では0が入り、サポートベクターの時のみ0以上となる そのため、本来n個すべてに対して計算する必要はなく、 サポートベクターのデータ集合 S の時のみに計算すればいいので 以下のようにも表示する = 0 + ∊ ,
このKによる変換関数を「カーネル関数」と呼ぶ。 カーネルに相当する変換は内積に限らない 内積は類似度を表していると考えられる 以下の場合カーネル関数はd次多項式カーネルと呼ばれる このような非線形カーネルを使った分類局面をつくる場合を サポートベクターマシン と呼ぶ。d=1の時、サポートベクター分類器に等価 ・サポートベクターマシン 内積をKという関数で一般化して表すと =
, ’ = =1 ’ K(X i , X i’ ) = (1 + =1 ’ ) d K(X i , X i’ ) = 0 + ∊ K(, )
・サポートベクターマシン 他にもいろいろとカーネルの候補は存在するが、有名なカーネルとして 「動径基底関数(RBF)カーネル」が存在する K(X i , X i’ ) =
ⅇxp − =1 − ′ 2 γは正の定数 2次の多項式カーネルでは、単純な二次曲線がマージンとなり分離するが RBFカーネルでは特定のクラスを円形に囲うことができる。
・サポートベクターマシン 変数(特徴量)を増やしてサポートベクターマシンにかけるのと、 カーネル関数を使ってからサポートベクターマシンにかけるの どう違うのか? もしも特徴量を増やす方法だと、保持しておくメモリも必要となる このように明示的に拡大された特徴量空間での計算はコストが大変にかかる ちなみに RBFカーネルは明示的に拡大することができず、無限次元に拡大したものを表現している
ロジスティック回帰との関係
・ロジスティック回帰との関係 サポートベクター分類器は1990年代の登場期には謎めいた理論により 旧来のロジスティック回帰や線形判別と異なるように見えた。 しかし、古典的モデルと理論的につながりがあることが分かった。 サポートベクター分類器は以下のように 損失関数L(X,Y,β) と罰則関数λP(β) によって表現ができることが分かった =1
max 0,1 − + =1 2 minimize β0~βp λが大きいときβたちは小さくなり、マージンに違反する値が多く許される これはCに相当していることがわかる 対して線形回帰で見たRidgeやLassoの場合のコスト関数は以下である , , = ා =1 − 0 − =1 2
・ロジスティック回帰との関係 罰則関数はL1,L2を使うのがRidgeやLassoであった 今一度損失関数を書きならべる =1 max 0,1 − =1
max 0,1 − β 0 + β 1 1 + ・・・ + β = 0 + ∊ K(, ) K(X i , X i’ ) = (1 + =1 ’ ) d サポートベクターマシンの損失関数(ヒンジロス関数) より書き下すと
・ロジスティック回帰との関係 ロジスティック関数は二乗による誤差の計算を行う SVMのヒンジロス関数は1以下の時には損失が0になる 0 + 1 1 + ⋯ +
≥ 1 これはマージンよりも 正しい側に分類されている 観測値は無視することに相当する? 損失関数が似ていることから SVMとロジスティックは似た結果となる クラスがうまく分かれる場合はSVM 混在した領域があるとき ロジスティックがうまく働く SVM発表の当初、C=1のように決め打ち定数でいいと考えられていたが 損失関数と罰則で表せることが分かってから、 Cがバイアス・バリアンスに関係するとわかった
・カーネル法について カーネル関数を使った特徴量の拡張はSVMだけでなく ロジスティック回帰やほかの手法にも使える しかし、歴史的背景から非線形カーネルの活用場面はSVMで主に使われる SVMは回帰にも使える 今回は説明しない
None
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}