Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
第六章-回帰と正則化【数学嫌いと学ぶデータサイエンス・統計的学習入門】
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Ringa_hyj
June 15, 2020
Technology
250
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
第六章-回帰と正則化【数学嫌いと学ぶデータサイエンス・統計的学習入門】
第六章【数学嫌いと学ぶデータサイエンス・統計的学習入門】
Ringa_hyj
June 15, 2020
More Decks by Ringa_hyj
See All by Ringa_hyj
DVCによるデータバージョン管理
ringa_hyj
0
410
deeplakeによる大規模データのバージョン管理と深層学習フレームワークとの接続
ringa_hyj
0
120
Hydraを使った設定ファイル管理とoptunaプラグインでのパラメータ探索
ringa_hyj
0
240
ClearMLで行うAIプロジェクトの管理(レポート,最適化,再現,デプロイ,オーケストレーション)
ringa_hyj
0
270
Catching up with the tidymodels.[Japan.R 2021 LT]
ringa_hyj
3
880
多次元尺度法MDS
ringa_hyj
0
420
因子分析(仮)
ringa_hyj
0
210
階層、非階層クラスタリング
ringa_hyj
0
160
tidymodels紹介「モデリング過程料理で表現できる説」
ringa_hyj
0
690
Other Decks in Technology
See All in Technology
Claude Mythos、Fable...フロンティアAIの最新動向と企業のセキュリティ対策
flatt_security
0
150
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
1.6k
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
1.4k
AI研修(Day1)【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
1.6k
41歳でAWSが好きすぎてITエンジニアになったおっさんの話
yama3133
1
780
13年運用タイトルのサーバーサイドが辿り着いた現在地 ― モンスターストライクにおける技術・組織・AI活用から得た知見
mixi_engineers
PRO
1
160
実践が先生だった— 新卒サーバーエンジニア1年目のリアル
mixi_engineers
PRO
0
110
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
740
Vポイント分析基盤におけるデータモデリング20年史
taromatsui_cccmkhd
4
770
システム監視入門
grimoh
3
610
脱Jenkins、インターン生が挑んだCIツールGitHubActions移行
mixi_engineers
PRO
1
150
AI Agent を本番環境へ―― Microsoft Foundry × Azure Serverless で作る Enterprise-Ready な基盤
shibayan
PRO
1
570
Featured
See All Featured
For a Future-Friendly Web
brad_frost
183
10k
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
640
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
230
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
330
Crafting Experiences
bethany
1
230
Amusing Abliteration
ianozsvald
1
240
We Are The Robots
honzajavorek
0
290
Measuring & Analyzing Core Web Vitals
bluesmoon
9
920
So, you think you're a good person
axbom
PRO
2
2.1k
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
180
The Language of Interfaces
destraynor
162
27k
Transcript
1 第六章 1 第六章 @Ringa_hyj 日本一の数学嫌いと学ぶ データサイエンス ~第六章:線形モデルと正則化~
2 第六章 2 第六章 対象視聴者: 数式や記号を見ただけで 教科書を閉じたくなるレベル , , C
, ,
3 第六章 3 第六章 正則行列、変数選択、次元削減 ・行列計算で係数を求める(正則行列) ・列を減らす(変数選択・次元削減)
4 第六章 4 第六章 ・行列計算で係数を求める 今まで最小二乗法によって線形回帰の係数を求めていた 行列の計算規則なら一気に計算できる(計算機に乗せやすい) − ො =
− x,yは教師ありデータなら既知 上記を満たすようなaを求めたい = 11 21 12 22 13 23 14 24 = 1 2 3 4 = 1 2 − = 0 1 2 3 4 − 11 21 12 22 13 23 14 24 1 2 = 0
5 第六章 5 第六章 ・行列計算で係数を求める − = 0 1 2
3 4 − 11 21 12 22 13 23 14 24 1 2 = 0 −1 = aを求める式に書き直す aからXを除くためにXで割り算したい 行列の割り算とは、逆行列を掛け算すること = −1 11 1 + 21 2 12 1 + 22 2 13 1 + 23 2 14 1 + 24 2 Xの逆行列が存在する時、行列計算で係数が求められる
6 第六章 6 第六章 ・行列計算で係数を求める = − 逆行列はどんな行列(テーブルデータ)に対しても求められるわけではない (掃き出し法・公式) 例:行より列(次元)のほうが多い時
(擬似逆行列で解く) 逆行列を持つような正方行列を正則行列(regular matrix) = 1 − = −1 = −
7 第六章 7 第六章 ・行列計算で係数を求める 行より列(次元)のほうが多い時 ・逆行列が求められない 擬似逆行列を使う、次元を減らす ・複雑な式になり解釈ができない 次元を減らす、正則化(係数を0にする)
・調整項のほうが行より多く、 訓練データに過剰に適合する(過学習) 次元を減らす、正則化(係数を0にする) (行数=列数でも過学習しやすい)
8 第六章 8 第六章 列を減らす(部分集合の選択) ・ステップワイズ法(変数増減法) ・モデル間の性能の比較(自由度調整済R二乗値) ・縮小推定(正則化・ridge・lasso) ・係数推定の前処理としての正規化 ・主成分分析(次元削減)
・制約のある最適化(ラグランジュ未定乗数法)
9 第六章 9 第六章 ・ステップワイズ法 データの中で使える変数が100列あったとする すべて使わず、変数を徐々に増やし、 交差検証の結果から、最も結果の良い変数の組み合わせを選ぶ = 0
+ 1 1 + 2 2 + 3 3 = 0 + 1 1 + 2 2 = 0 + 1 1 = 0 + 2 2 変数増加法 (減らしていくと減少法) ※計算コストが高い 100変数あったら(2100-1)通りモデルを作り、 学習、検証しなくてはならない
10 第六章 10 第六章 ・性能比較のための自由度調整済R二乗値 = 0 + 1 1
+ 2 2 = 0 + 1 1 R二乗値 変数を増やせば性能はよくなるが、過学習になる ・変数を増やすことは罰則 ・それを補うほど精度を向上させるなら変数を入れる 自由度調整済 R二乗値 2 = 1 − = − ത 2 SS = − 2 2 = 1 − − − 1 − 1 d = 変数の数 n = データの行数 ・分母は定数 ・分子を最小にするようなモデルが最も 自由度調整済みR二乗を向上させる RSS residual sum of squares SSR sum of squared residuals SSE sum of squared errors of prediction 残差二乗和 残差平方和 誤差の推定量の二乗
11 第六章 11 第六章 ・縮小推定 正則化・ridge
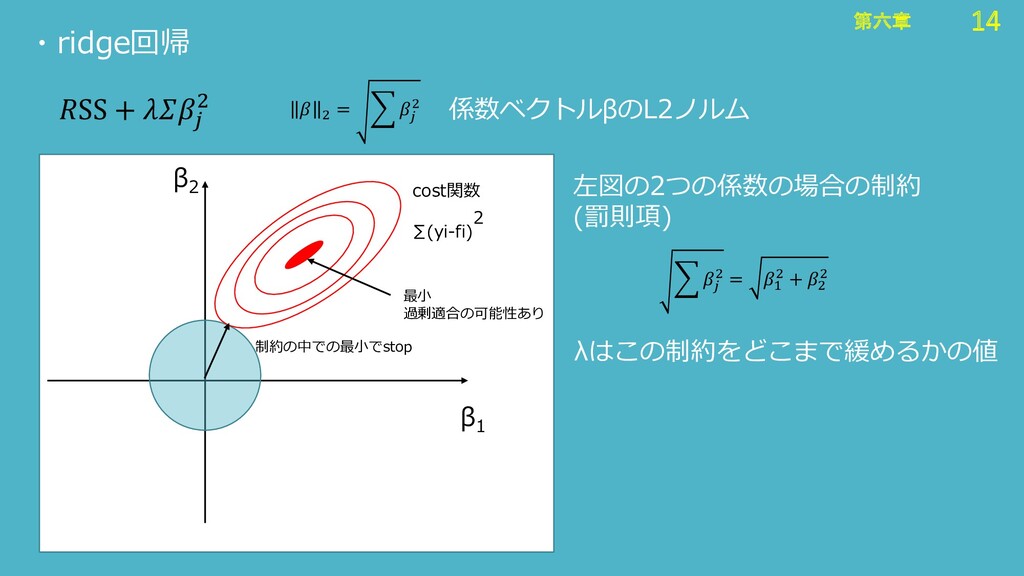
12 第六章 12 第六章 ・ridge回帰 = ා − 0 +
2 今まで最小二乗法によって、RSSを最小にするようなβを求めてきた ridgeはこのβに制約をかけ縮小させる SS + 2 この制約で求まるβの値をridge回帰係数と呼ぶ ※λは0より大きい実数 ※λが大きくなると係数はすべて0になる ※λが0ならばridge回帰の制約がかからないことと等しい ※制約は切片項にはかからない(λ=∞なら、切片はyの平均値)
13 第六章 13 第六章 ・ridge回帰 SS + 2 2 =
2 係数ベクトルβのL2ノルム 正則化のイメージ y = β 1 x 1 + β 2 x 2 + β 3 x 3 + β 4 x 4 ・・・ y = 100x 1 + 25x 2 + 30x 3 + 8x 4 ・・・ β 1 ~β n の合計が1になるように y = 0.7x 1 + 0.2x 2 + 0.25x 3 + 0.001x 4 ・・・
14 第六章 14 第六章 ・ridge回帰 SS + 2 2 =
2 係数ベクトルβのL2ノルム β 2 β 1 cost関数 ∑(yi-fi) 2 最小 過剰適合の可能性あり 制約の中での最小でstop 2 = 1 2 + 2 2 左図の2つの係数の場合の制約 (罰則項) λはこの制約をどこまで緩めるかの値
15 第六章 15 第六章 ・縮小推定 正則化・lasso
16 第六章 16 第六章 ・lasso回帰 = ා − 0 +
2 SS + 2 lasso 2 = 2 係数ベクトルβのL2ノルム ridge + 1 = 係数ベクトルβのL1ノルム
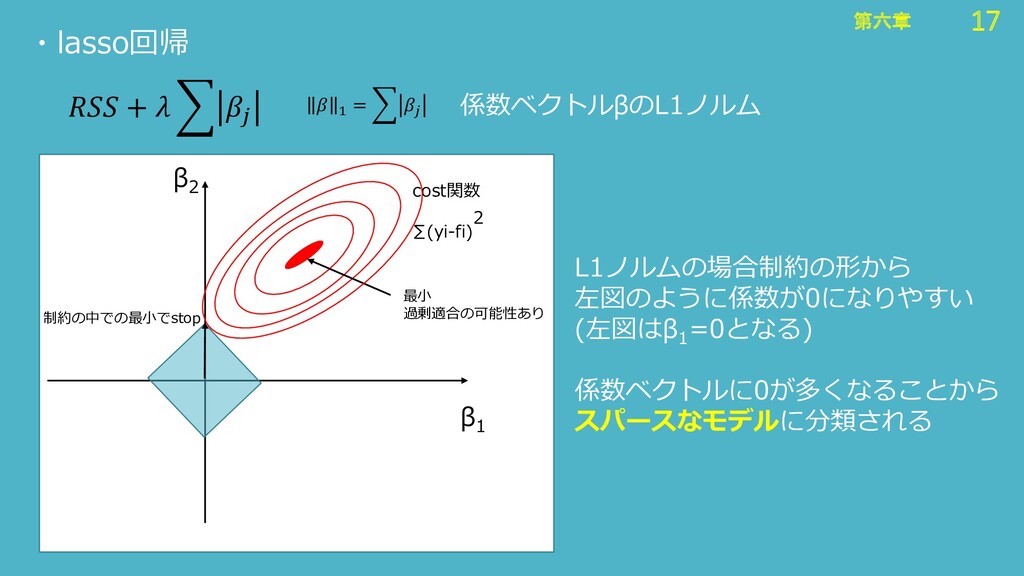
17 第六章 17 第六章 ・lasso回帰 + 1 =
係数ベクトルβのL1ノルム β 2 β 1 cost関数 ∑(yi-fi) 2 最小 過剰適合の可能性あり 制約の中での最小でstop L1ノルムの場合制約の形から 左図のように係数が0になりやすい (左図はβ 1 =0となる) 係数ベクトルに0が多くなることから スパースなモデルに分類される
18 第六章 18 第六章 ・ridge、lasso どっちを選べばいいの モデル比較・パラメータ探索は、 基本的に交差検証で最もいい方いい値 ・λはどう決めるべき 目的が「変数を減らして容易に解釈したい」なら
スパースになるlasso
19 第六章 19 第六章 ・前処理としての正規化
20 第六章 20 第六章 β 2 β 1 金額[円] 面積[m2]
10000 5 データの単位が異なる場合 パラメータもデータに影響される 左図のような状態で正則化の 制約を設けると β2の本当に求めたい値から 程遠い状態で計算が止まる (尺度の違いはその他弊害も多い) ・正規化(標準化) 平均・分散を統一するために 正規化(標準化)してから正則化
21 第六章 21 第六章 ・主成分分析(次元削減) (PCA : principal component analysis)
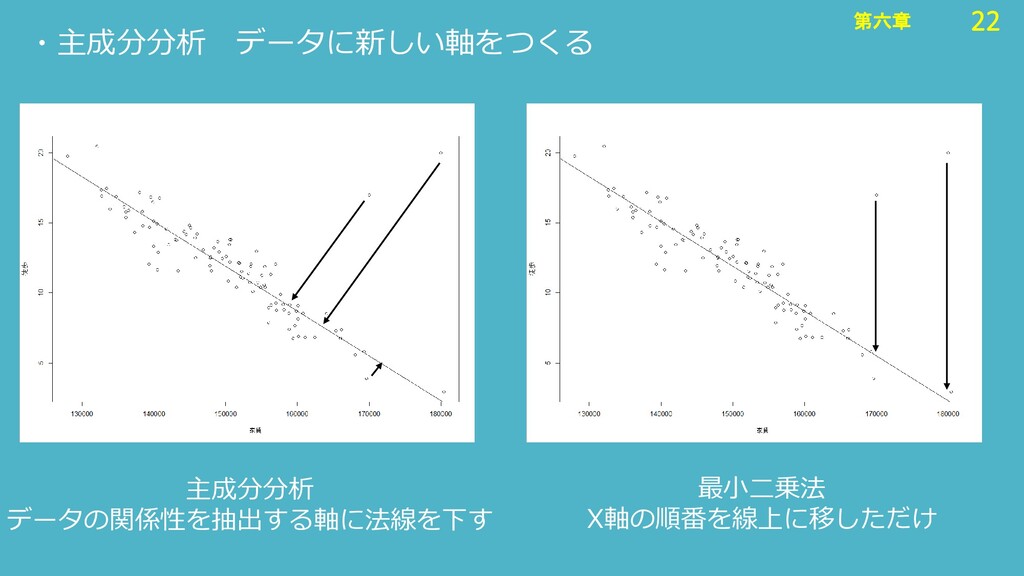
22 第六章 22 第六章 ・主成分分析 データに新しい軸をつくる 最小二乗法 X軸の順番を線上に移しただけ 主成分分析 データの関係性を抽出する軸に法線を下す
23 第六章 23 第六章 ・データに新しい軸をつくる 家賃と駅からの距離をplot データの相関方向に線を引く 二軸の数値の関係性を抽出した 第三の軸として解釈 (軸の名前:年収の高い人度数)
変数:減 この軸を主成分軸と呼ぶ 駅から近く、家賃も高い家には 所得の高い人が住める 駅から遠くても家賃が高ければ 年収高いと考えられる
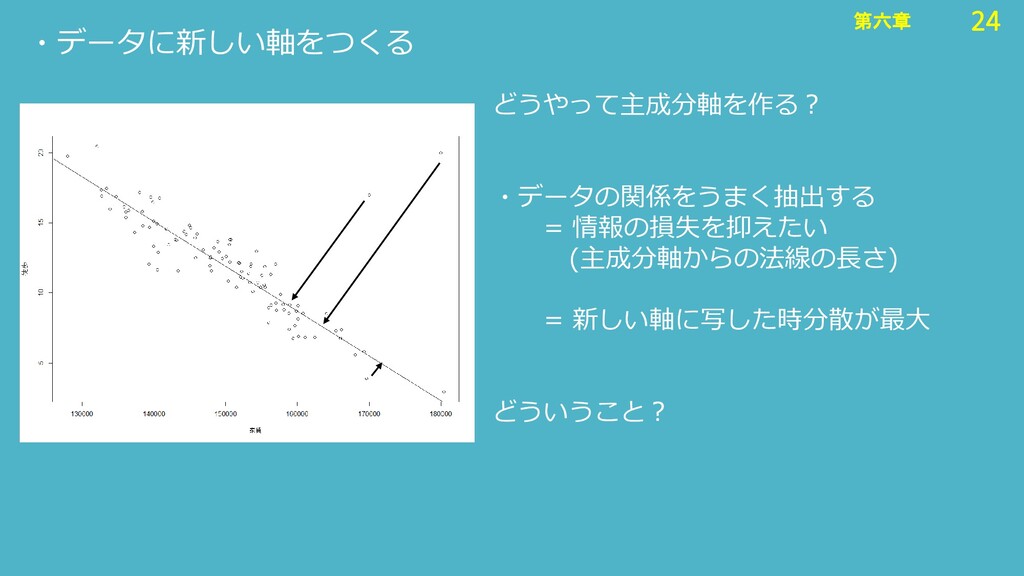
24 第六章 24 第六章 ・データに新しい軸をつくる どうやって主成分軸を作る? ・データの関係をうまく抽出する = 情報の損失を抑えたい (主成分軸からの法線の長さ)
= 新しい軸に写した時分散が最大 どういうこと?
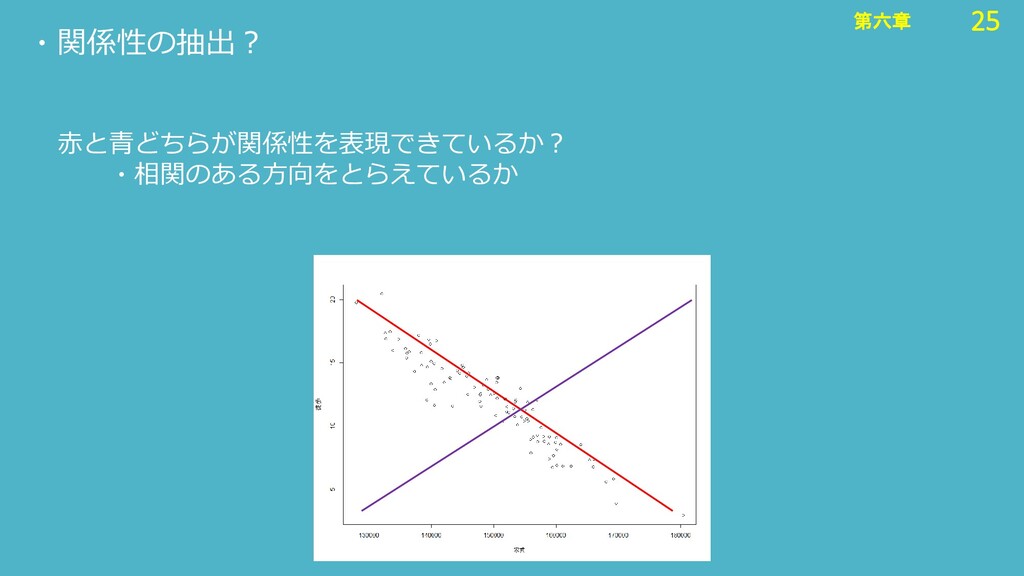
25 第六章 25 第六章 赤と青どちらが関係性を表現できているか? ・相関のある方向をとらえているか ・関係性の抽出?
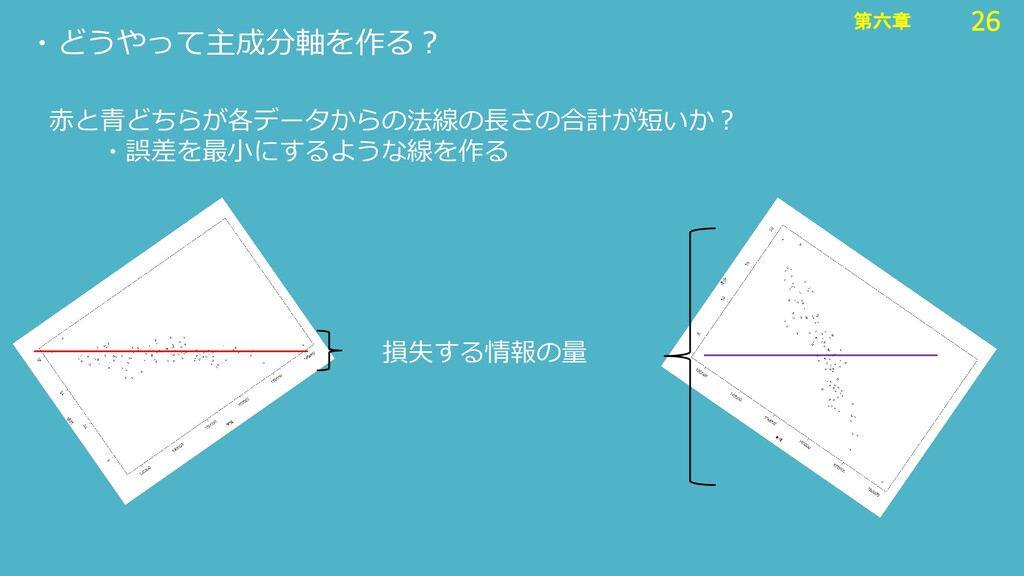
26 第六章 26 第六章 ・どうやって主成分軸を作る? 損失する情報の量 赤と青どちらが各データからの法線の長さの合計が短いか? ・誤差を最小にするような線を作る
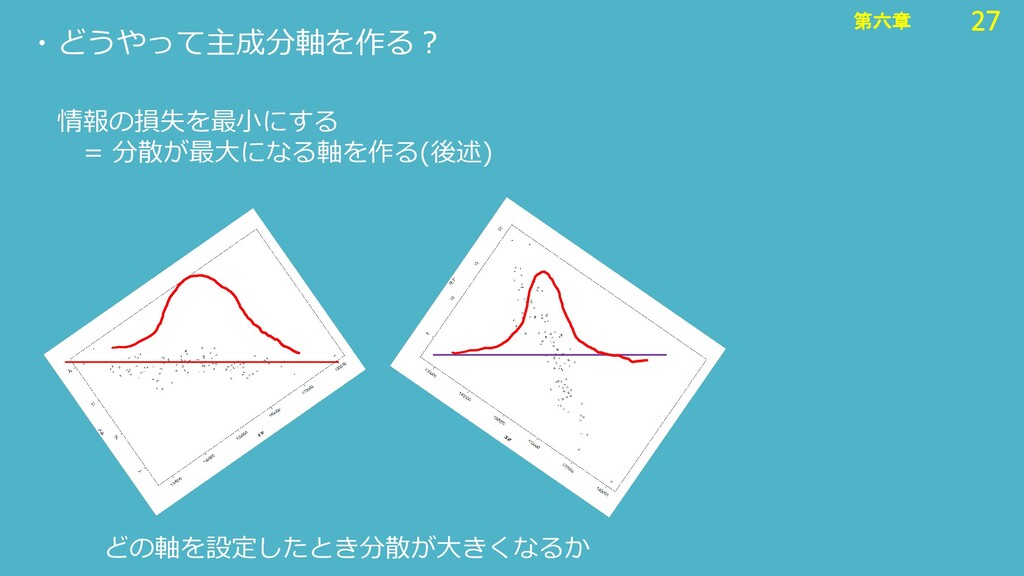
27 第六章 27 第六章 ・どうやって主成分軸を作る? どの軸を設定したとき分散が大きくなるか 情報の損失を最小にする = 分散が最大になる軸を作る(後述)
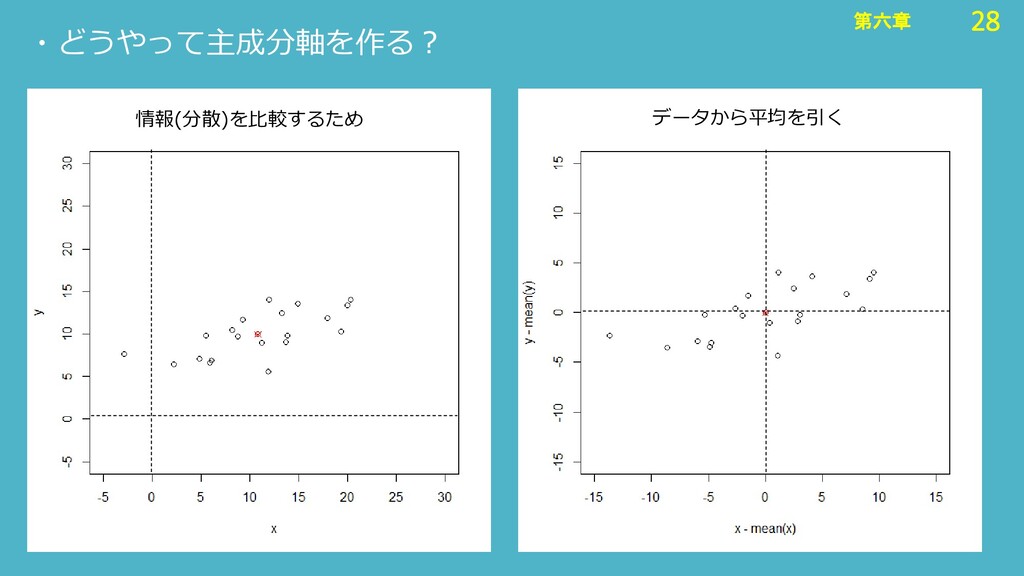
28 第六章 28 第六章 ・どうやって主成分軸を作る? 情報(分散)を比較するため データから平均を引く
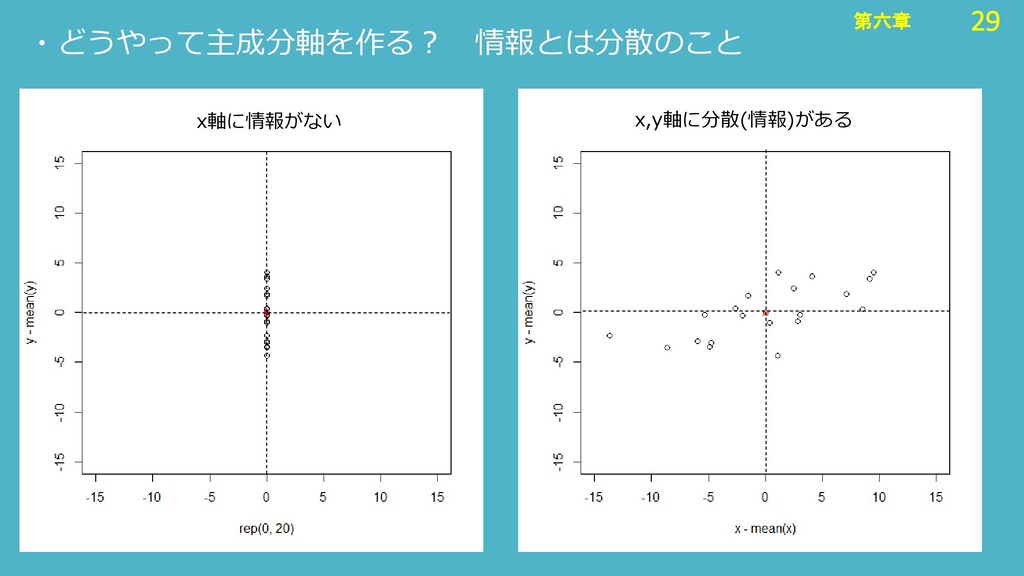
29 第六章 29 第六章 ・どうやって主成分軸を作る? 情報とは分散のこと x軸に情報がない x,y軸に分散(情報)がある
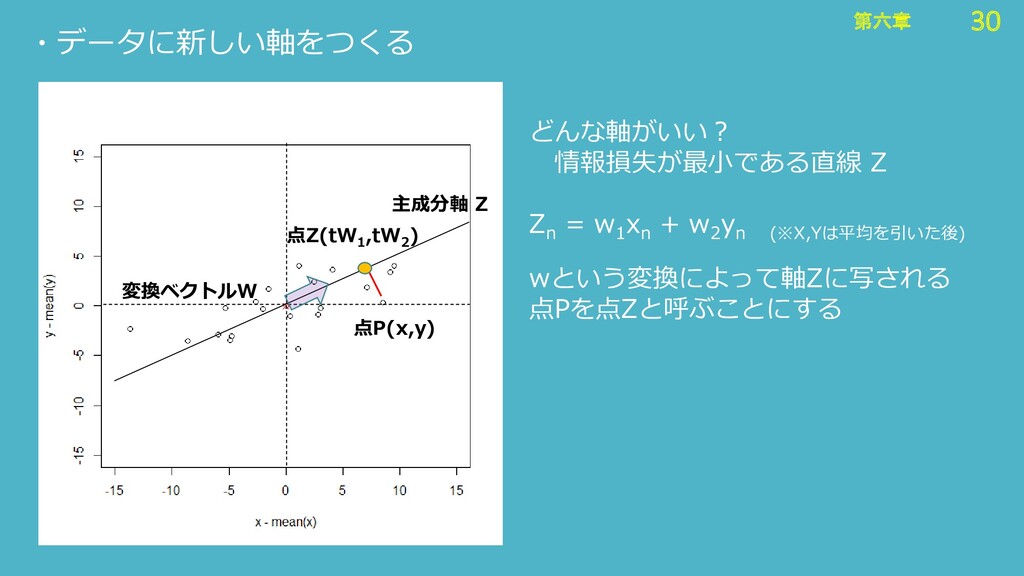
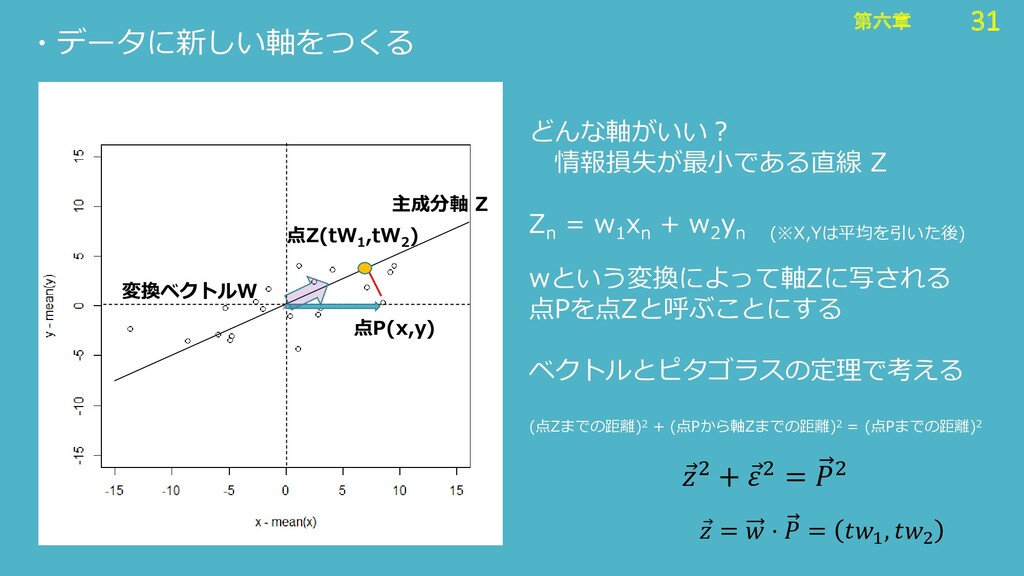
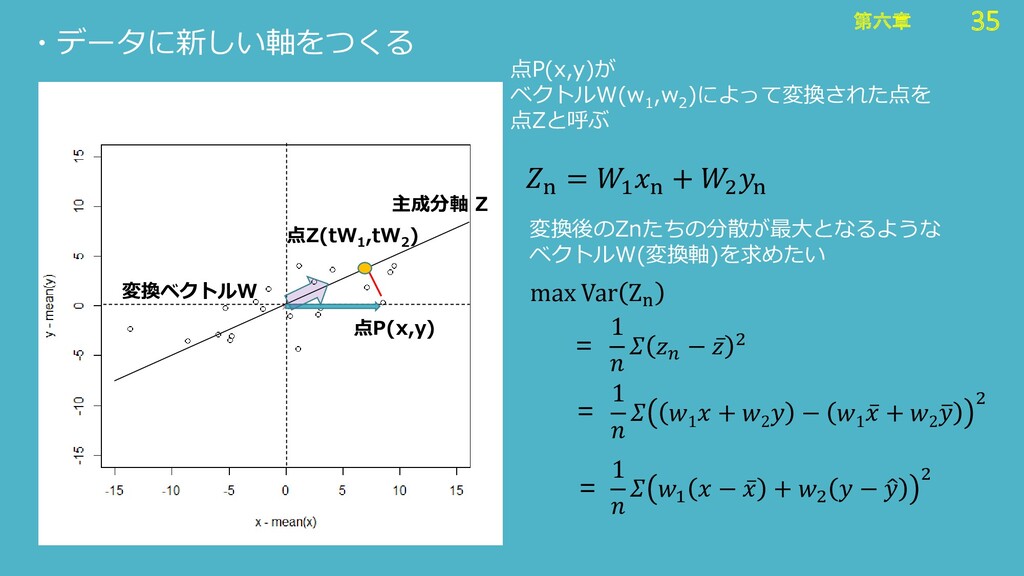
30 第六章 30 第六章 ・データに新しい軸をつくる 点P(x,y) 主成分軸 Z wという変換によって軸Zに写される 点Pを点Zと呼ぶことにする
どんな軸がいい? 情報損失が最小である直線 Z Z n = w 1 x n + w 2 y n (※X,Yは平均を引いた後) 変換ベクトルW 点Z(tW 1 ,tW 2 )
31 第六章 31 第六章 ・データに新しい軸をつくる wという変換によって軸Zに写される 点Pを点Zと呼ぶことにする ベクトルとピタゴラスの定理で考える (点Zまでの距離)2 +
(点Pから軸Zまでの距離)2 = (点Pまでの距離)2 点P(x,y) どんな軸がいい? 情報損失が最小である直線 Z Z n = w 1 x n + w 2 y n (※X,Yは平均を引いた後) 点Z(tW 1 ,tW 2 ) Ԧ 2 + Ԧ 2 = 2 主成分軸 Z 変換ベクトルW Ԧ = ⋅ = 1 , 2
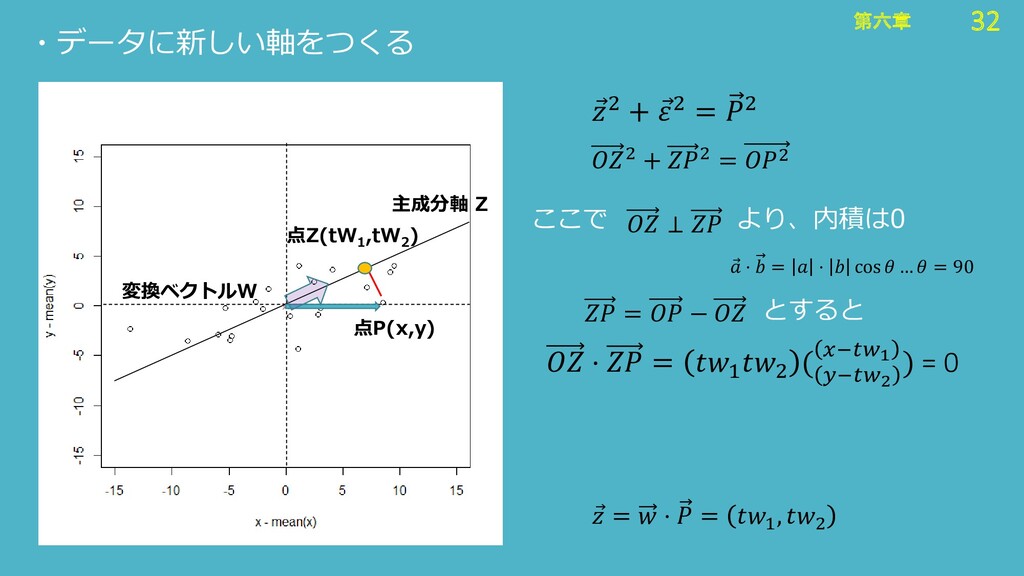
32 第六章 32 第六章 ・データに新しい軸をつくる 点P(x,y) 点Z(tW 1 ,tW 2
) Ԧ 2 + Ԧ 2 = 2 主成分軸 Z 変換ベクトルW Ԧ = ⋅ = 1 , 2 2 + 2 = 2 ⊥ ここで より、内積は0 Ԧ ⋅ = ⋅ cos … = 90 = − とすると ⋅ = 1 2 ( −2 −1 ) = 0
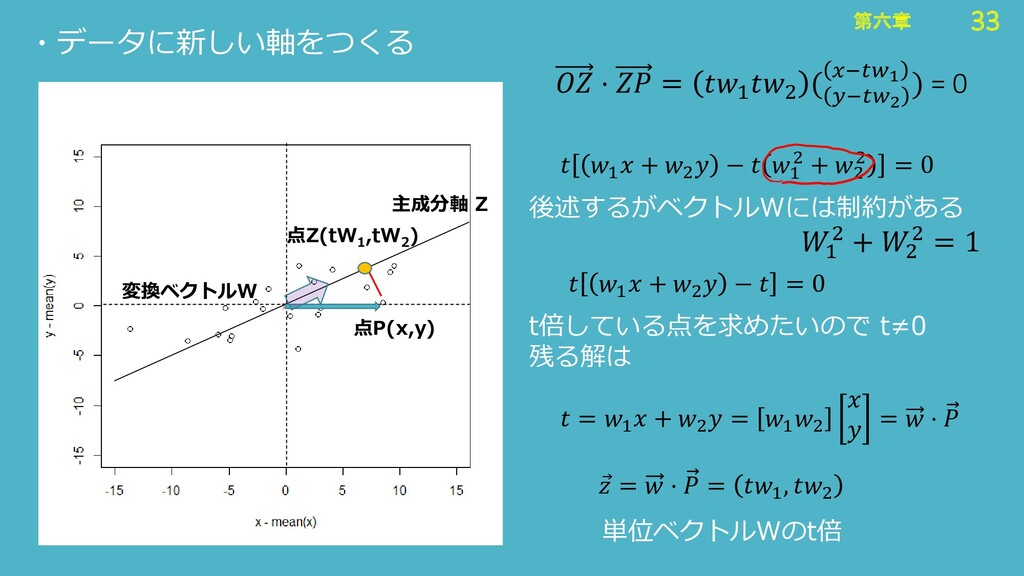
33 第六章 33 第六章 ・データに新しい軸をつくる 点P(x,y) 点Z(tW 1 ,tW 2
) 主成分軸 Z 変換ベクトルW Ԧ = ⋅ = 1 , 2 ⋅ = 1 2 ( −2 −1 ) = 0 1 + 2 − 1 2 + 2 2 = 0 1 2 + 2 2 = 1 後述するがベクトルWには制約がある 1 + 2 − = 0 t倍している点を求めたいので t≠0 残る解は = 1 + 2 = 1 2 = ⋅ 単位ベクトルWのt倍
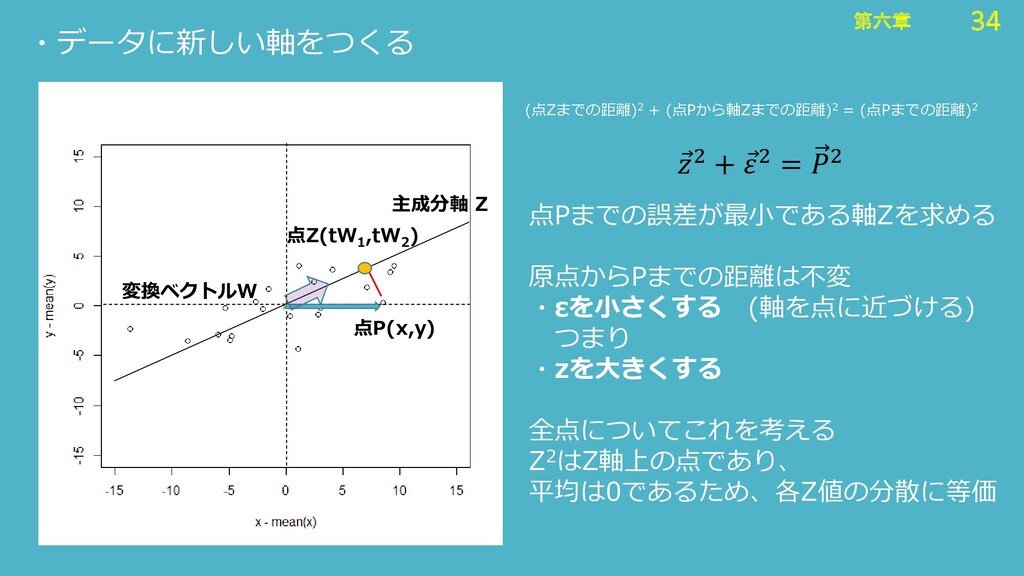
34 第六章 34 第六章 ・データに新しい軸をつくる (点Zまでの距離)2 + (点Pから軸Zまでの距離)2 = (点Pまでの距離)2
点P(x,y) 点Z(tW 1 ,tW 2 ) Ԧ 2 + Ԧ 2 = 2 点Pまでの誤差が最小である軸Zを求める 原点からPまでの距離は不変 ・εを小さくする (軸を点に近づける) つまり ・zを大きくする 全点についてこれを考える Z2はZ軸上の点であり、 平均は0であるため、各Z値の分散に等価 主成分軸 Z 変換ベクトルW
35 第六章 35 第六章 ・データに新しい軸をつくる 点P(x,y) 点Z(tW 1 ,tW 2
) 主成分軸 Z 変換ベクトルW max Var Zn n = 1 n + 2 n 点P(x,y)が ベクトルW(w 1 ,w 2 )によって変換された点を 点Zと呼ぶ 変換後のZnたちの分散が最大となるような ベクトルW(変換軸)を求めたい 1 − ҧ 2 1 1 + 2 − 1 ҧ + 2 ത 2 1 1 − ҧ + 2 − ො 2 = = =
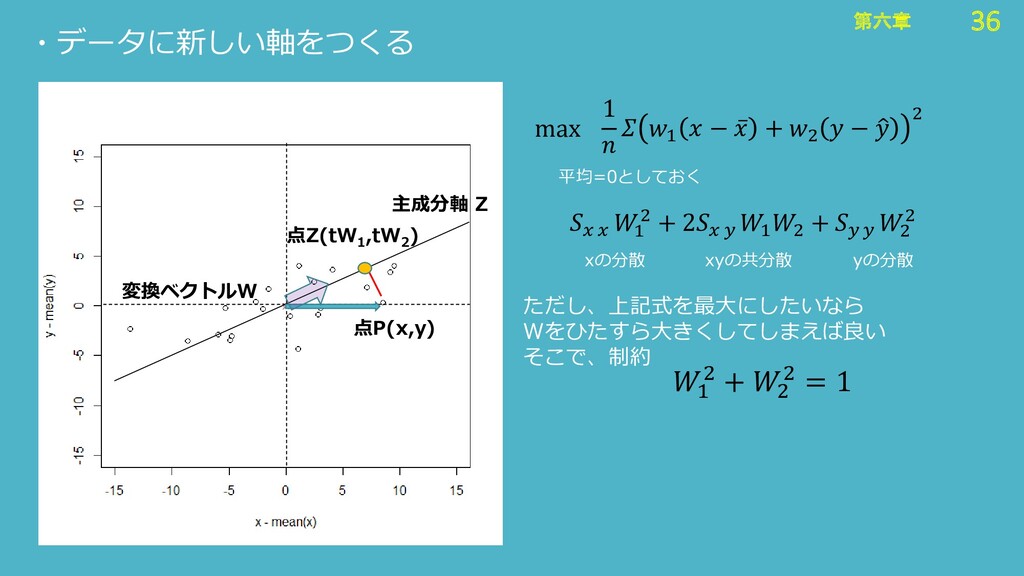
36 第六章 36 第六章 ・データに新しい軸をつくる 点P(x,y) 点Z(tW 1 ,tW 2
) 主成分軸 Z 変換ベクトルW 1 1 − ҧ + 2 − ො 2 max 平均=0としておく 1 2 + 2 1 2 + 2 2 xの分散 xyの共分散 yの分散 ただし、上記式を最大にしたいなら Wをひたすら大きくしてしまえば良い そこで、制約 1 2 + 2 2 = 1
37 第六章 37 第六章 ・制約付き最適化(ラグランジュ未定乗数法) 1 1 + 1 2
2 + ⋯ + n 1 + n 2 2 最適化したい関数 g(W 1 ,W 2 ) 制約 f(W 1 ,W 2 ) ∇ = 1 2 ∇f = 1 2 偏微分 法線ベクトル 1 = 2 = 1 = 2 = 2 1 2 + 2 2 + 3 2 1 + 2 1 1 + 2 2 + 3 3 2 2 1 1 + 2 2 + 3 3 1 + 2 1 2 + 2 2 + 3 2 2 1 2 + 2 2 − 1 = 0 21 22 1 = λ 1 2 = λ 2 未知の定数λ(ラグランジュ未定乗数)を 含めた以下の2つの式を解くことで、制約を満たす W(W 1 ,W 2 ) が求まる ※平均=0
38 第六章 38 第六章 ・制約付き最適化(ラグランジュ未定乗数法) 行列の形式で書く 1 2 = 1
2 行列の 固有値λ、固有ベクトルW を求める問題になった 1 = λ 1 2 = λ 2 これらを解いてもWは求まる
39 第六章 39 第六章 ・固有値、固有ベクトル問題として解く 固有値λ、固有ベクトルW の解き方 det − =
0 − 1 0 0 1 = − − − − − = 0 固有ベクトルWと固有値λの組み合わせは変数の個数だけ求まる 分散を最大にするようなW 1 W 2 が第1主成分 次に第一主成分に直行する軸であり、分散を最大にする軸 → 第2主成分 1 2 = 1 2
40 第六章 40 第六章
41 第六章 41 第六章 ・主成分軸がどれだけ情報を抽出できているのか 固有ベクトルの組み合わせがP個 固有値もP個 固有ベクトルの組み合わせを使って作った主成分軸が どれだけの情報を持っているかは固有値から確認できる 1
1 + 2 寄与率
42 第六章 42 第六章 ・主成分軸何個選べばいい ・交差検証で主成分軸何個使ったときが最もいい結果だったか ・上限があるとき、寄与率の大きい順から選ぶ ・主成分回帰 (PCR :
principal components regression) ・元の変数でなく、合成した主成分軸を変数として使い、回帰する
43 第六章 43 第六章 ・前処理としての正規化 その2 主成分分析でも事前に標準化を行う 分散最大化が目的 もともと分散の大きい変数が(本当は有効な変数でなくても) 優先的に重要視されてしまう
44 第六章 44 第六章 ・部分最小二乗法(PLS:partial least squares) ・教師データを考慮(変数との相関)しながら主成分分析を行う ・主成分Zの分散を計算する時、 変数と教師データの共分散を最大化するように変形する
1 1 + 2 2 n
45 第六章 45 第六章 ステップワイズ法・・・計算コスト高、R2値で比較(AIC,BIC) 正則化・・・ridge,lasso 主成分分析・・・列を減らす,主成分回帰,部分最小二乗法 ・変数の減らし方、まとめ
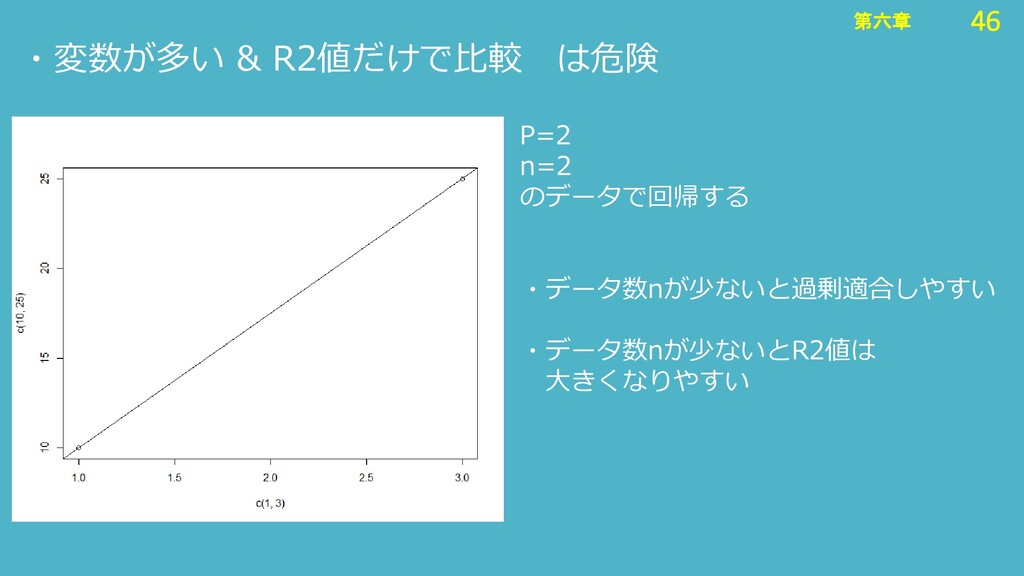
46 第六章 46 第六章 ・変数が多い & R2値だけで比較 は危険 P=2 n=2
のデータで回帰する ・データ数nが少ないと過剰適合しやすい ・データ数nが少ないとR2値は 大きくなりやすい
47 第六章 47 第六章
48 第六章 48 第六章
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
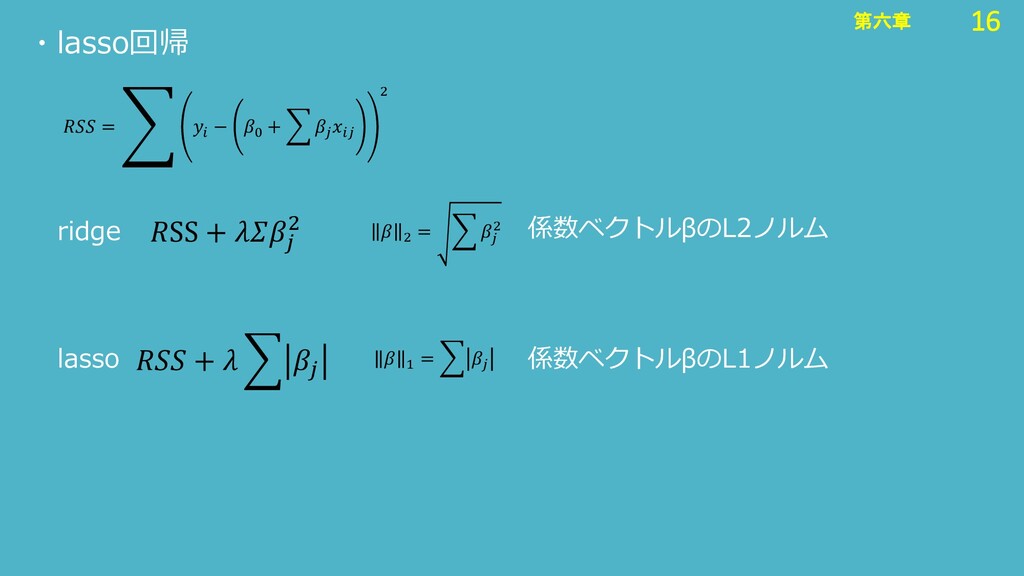{kind=link}
{kind=link}
{kind=link}
{kind=link}
![20 第六章 20 第六章 β 2 β 1 金額[円] 面積[m2]](https://files.speakerdeck.com/presentations/2cd18ce750a34a048a154f1a89e26d26/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
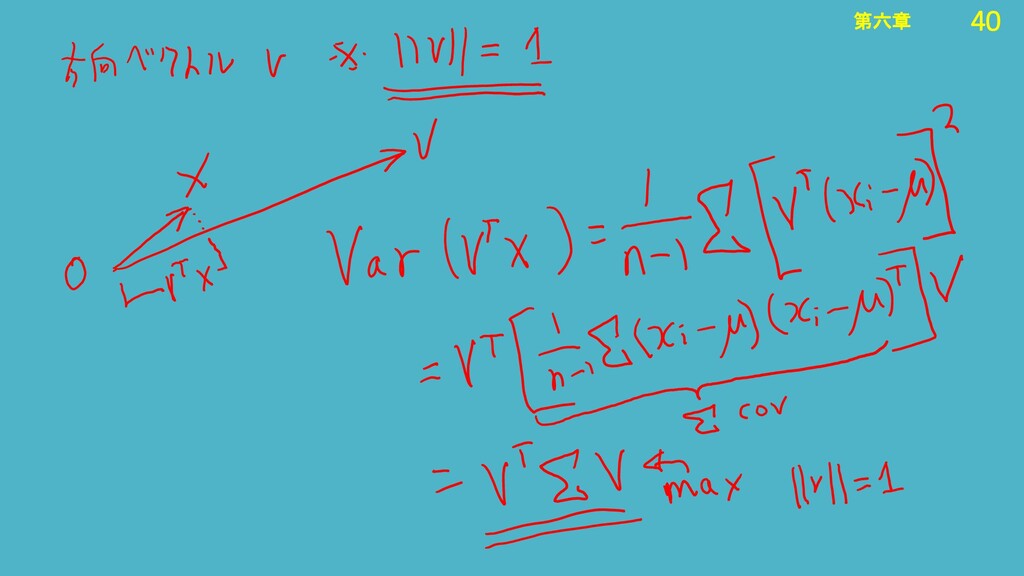{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}