Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
第四章-判別分析【数学嫌いと学ぶデータサイエンス・統計的学習入門】
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Ringa_hyj
June 15, 2020
Technology
470
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
第四章-判別分析【数学嫌いと学ぶデータサイエンス・統計的学習入門】
第四章【数学嫌いと学ぶデータサイエンス・統計的学習入門】
Ringa_hyj
June 15, 2020
More Decks by Ringa_hyj
See All by Ringa_hyj
DVCによるデータバージョン管理
ringa_hyj
0
410
deeplakeによる大規模データのバージョン管理と深層学習フレームワークとの接続
ringa_hyj
0
120
Hydraを使った設定ファイル管理とoptunaプラグインでのパラメータ探索
ringa_hyj
0
240
ClearMLで行うAIプロジェクトの管理(レポート,最適化,再現,デプロイ,オーケストレーション)
ringa_hyj
0
270
Catching up with the tidymodels.[Japan.R 2021 LT]
ringa_hyj
3
880
多次元尺度法MDS
ringa_hyj
0
420
因子分析(仮)
ringa_hyj
0
210
階層、非階層クラスタリング
ringa_hyj
0
160
tidymodels紹介「モデリング過程料理で表現できる説」
ringa_hyj
0
690
Other Decks in Technology
See All in Technology
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
360
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
30
17k
MCPをつなげて作る組織横断のAIエージェント基盤
tsubakimoto_s
0
170
基調講演:人とAIをつなぐIoTの今と未来 ー 「フィジカル」と「デジタル」が出会うその先へ【SORACOM Discovery 2026】
soracom
PRO
0
270
論語・武士道・産業革命から見る かわるもの、かわらないもの
ichimichi
8
1.3k
iOS/Androidの二刀流エンジニアがFlutter & TypeScriptへ越境後の現在地 - Flutterがメインになって見えた景色と現在の醍醐味 / Dual-Platform Mobile Engineer Shifts to Flutter & TypeScript - The View and Real Thrill of Going Flutter-First
bitkey
PRO
0
110
OPENLOGI Company Profile for engineer
hr01
1
75k
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
210
AI_Dev_Day_製造業領域でのAI活用から見た活用の罠と成功に導く実践知.pdf
kintotechdev
0
240
AI工学特論: MLOps・継続的評価
asei
11
2.8k
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
3
1k
なぜMIXIはゼロトラスト基盤として クラウドフレアを選んだのか - Cloudflare Peer Point SASE User Voices
mixi_engineers
PRO
2
100
Featured
See All Featured
Building Applications with DynamoDB
mza
96
7.1k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
YesSQL, Process and Tooling at Scale
rocio
174
15k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
370
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
760
Design in an AI World
tapps
1
270
A designer walks into a library…
pauljervisheath
211
24k
Writing Fast Ruby
sferik
630
63k
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
Unsuck your backbone
ammeep
672
58k
Raft: Consensus for Rubyists
vanstee
141
7.6k
Transcript
第四章 1 第四章 1 @Ringa_hyj 日本一の数学嫌いと学ぶ データサイエンス ~第四章:判別分析~
第四章 2 第四章 2 対象視聴者: 数式や記号を見ただけで 教科書を閉じたくなるレベル
第四章 3 第四章 3 線形判別分析 (linear discriminant analysis:LDA) ・ベイズ決定境界 ・精度と混同行列
・ROC曲線とAUC
第四章 4 第四章 4 ベイズ決定境界
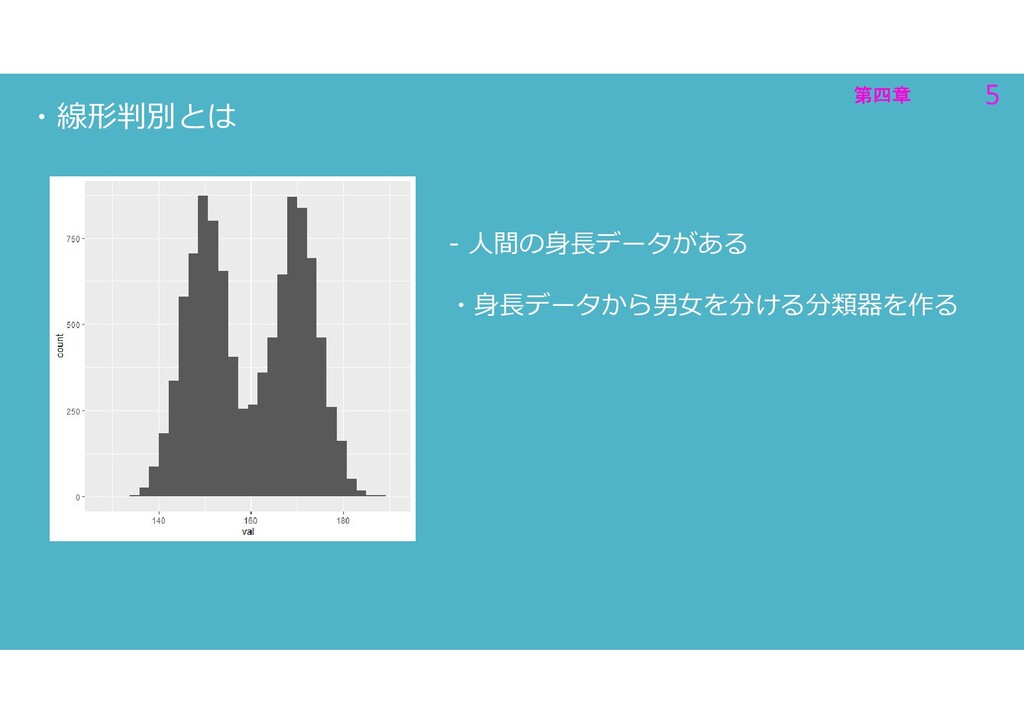
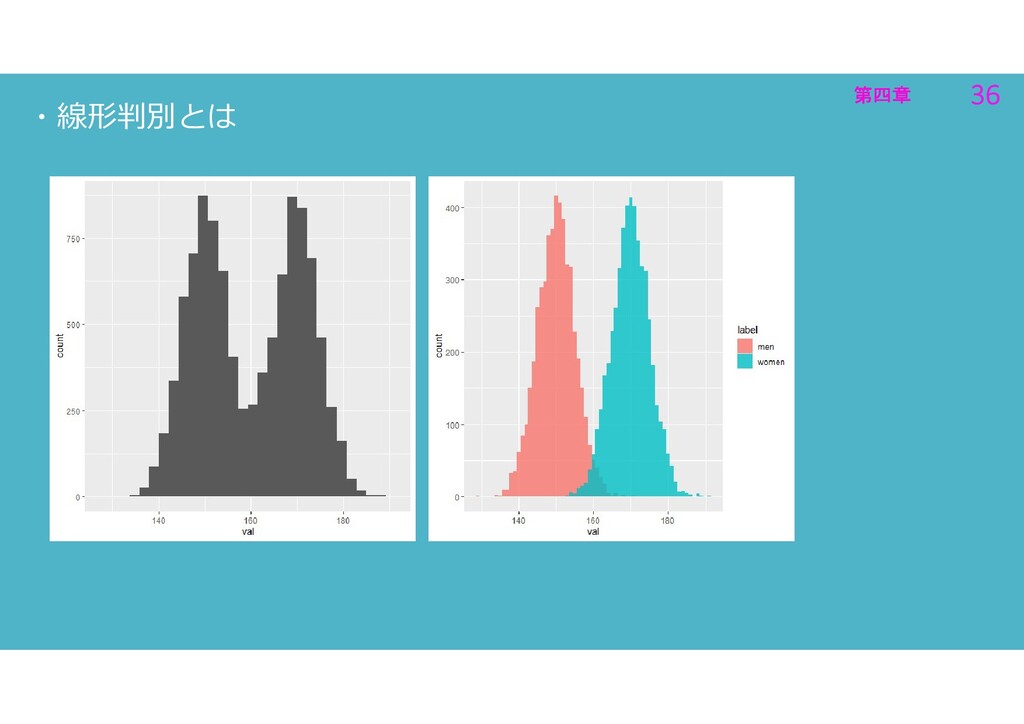
第四章 5 第四章 5 ・線形判別とは - 人間の身⾧データがある ・身⾧データから男女を分ける分類器を作る
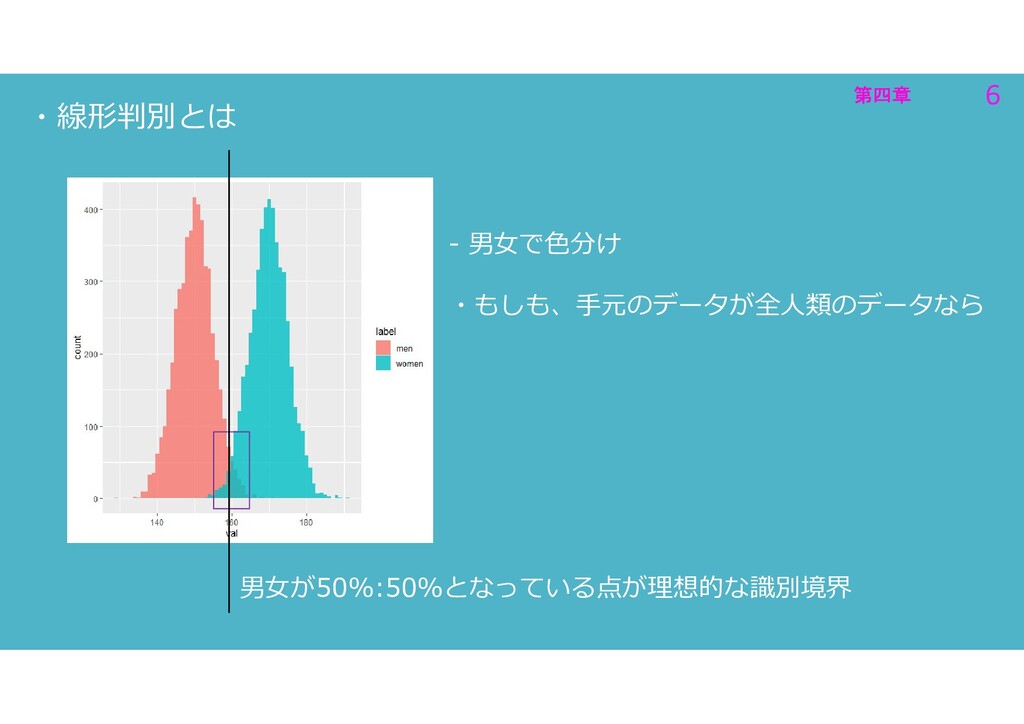
第四章 6 第四章 6 ・線形判別とは - 男女で色分け ・もしも、手元のデータが全人類のデータなら 男女が50%:50%となっている点が理想的な識別境界
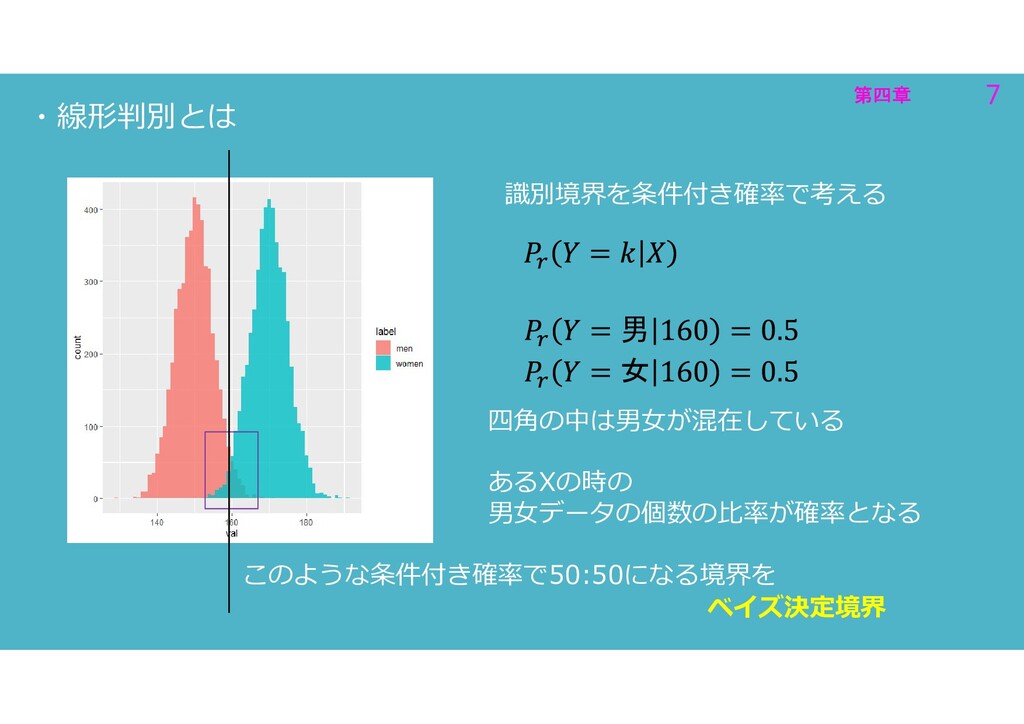
第四章 7 第四章 7 ・線形判別とは 識別境界を条件付き確率で考える 男 女 四角の中は男女が混在している あるXの時の
男女データの個数の比率が確率となる このような条件付き確率で50:50になる境界を ベイズ決定境界
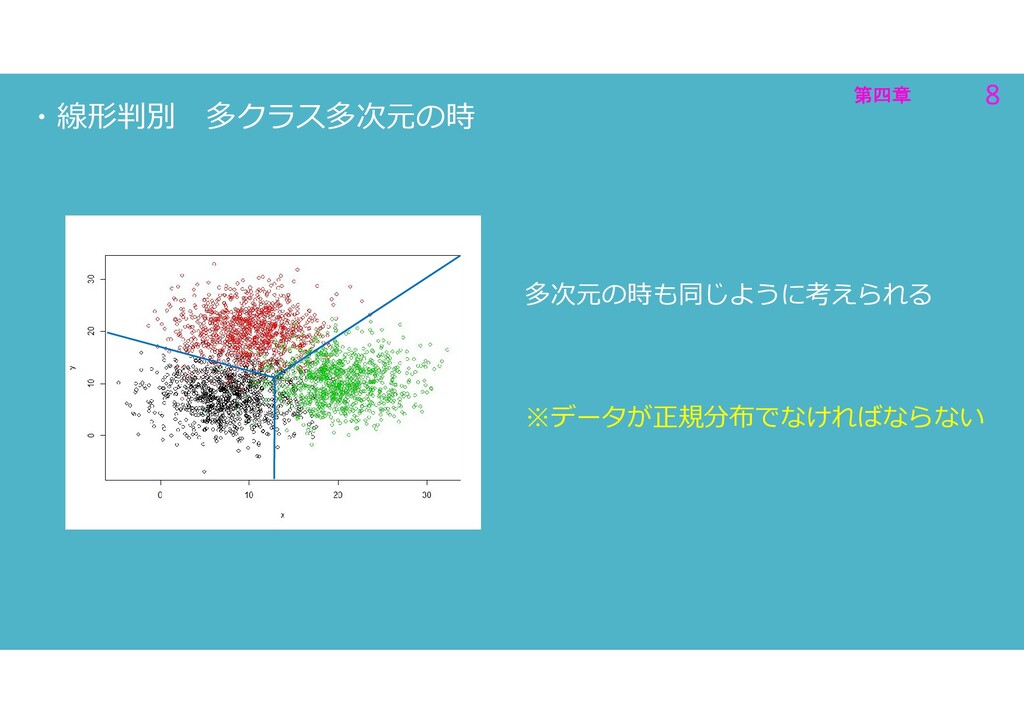
第四章 8 第四章 8 ・線形判別 多クラス多次元の時 多次元の時も同じように考えられる ※データが正規分布でなければならない
第四章 9 第四章 9 分類の精度
第四章 10 第四章 10 ・クラス分類の”精度” ウイルス検査の例で 分類器の精度について考える ウイルスを持っている人は陽性 ウイルスを持っていない人は陰性 と判断できるのが理想的な診断薬
第四章 11 第四章 11 ・クラス分類の”精度” 99.5%の精度で病気を診断できる検査薬です 本当に良い検査薬?
第四章 12 第四章 12 ・クラス分類の”精度” ヒトがその病気にかかっている割合は1000人に5人 全員陰性と判断する診断薬で 1000人に検査した時、 精度は99.5% になる
99.5%って「いい診断薬」なの? その検査で陽性と診断できなければ 次の日に亡くなるような病気なら?
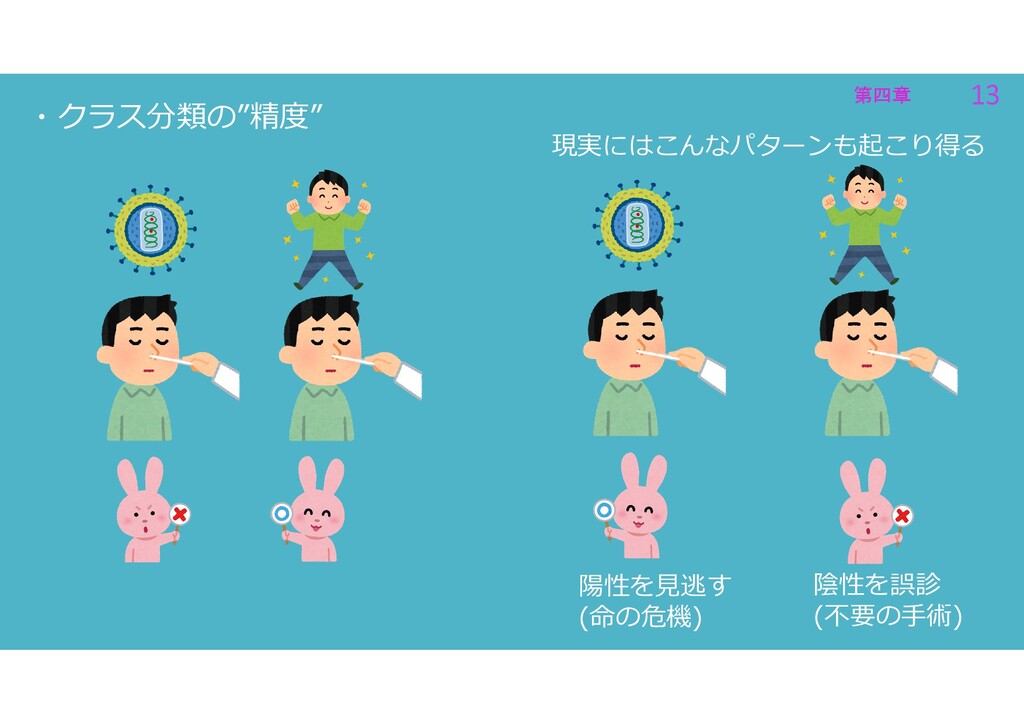
第四章 13 第四章 13 ・クラス分類の”精度” 現実にはこんなパターンも起こり得る 陽性を見逃す (命の危機) 陰性を誤診 (不要の手術)
第四章 14 第四章 14 精度だけを分類器の評価指標にすることの課題 課題 ・陽性が少ない時(不均衡なデータ) ・絶対に陽性(or陰性のどちらか)を見逃せない時 には、「精度」だけでは診断薬の指標にはならない ・クラス分類の”精度”
第四章 15 第四章 15 分類の精度 混同行列 (confusion matrix)
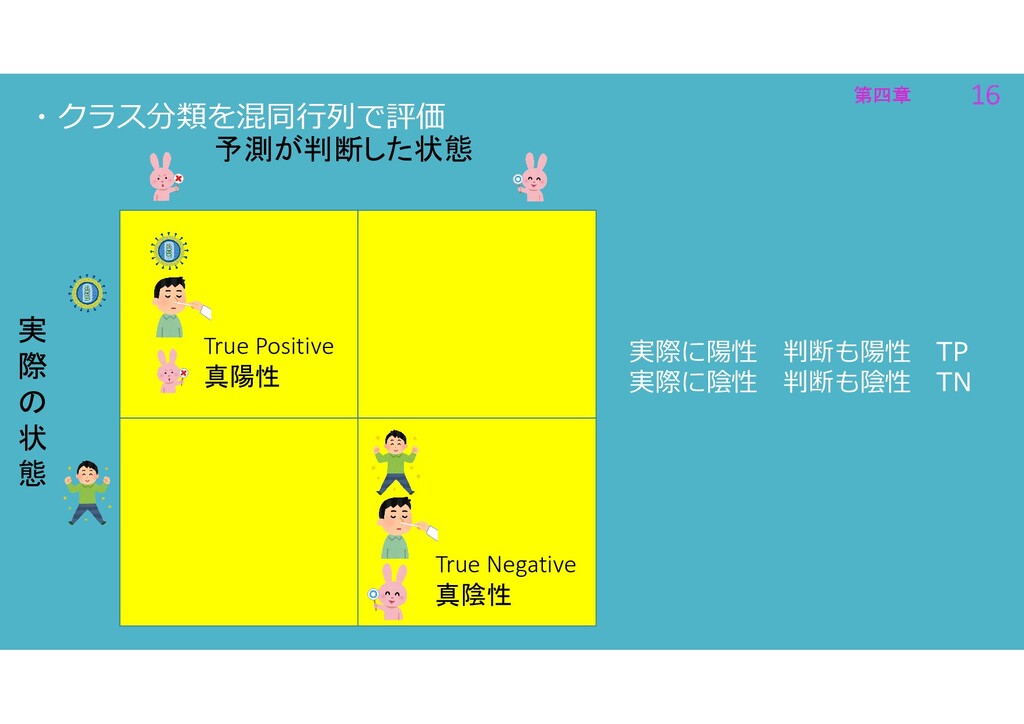
第四章 16 第四章 16 ・クラス分類を混同行列で評価 True Positive 真陽性 True Negative
真陰性 実際に陽性 判断も陽性 TP 実際に陰性 判断も陰性 TN 実 際 の 状 態 予測が判断した状態
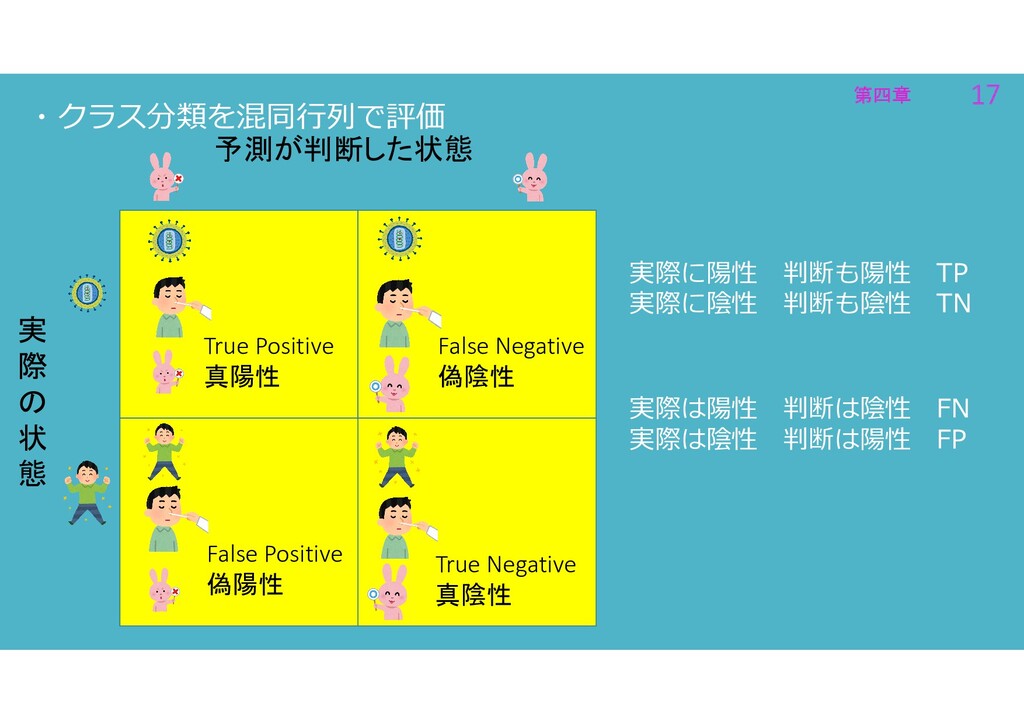
第四章 17 第四章 17 ・クラス分類を混同行列で評価 実 際 の 状 態
予測が判断した状態 True Positive 真陽性 True Negative 真陰性 False Positive 偽陽性 False Negative 偽陰性 実際は陽性 判断は陰性 FN 実際は陰性 判断は陽性 FP 実際に陽性 判断も陽性 TP 実際に陰性 判断も陰性 TN
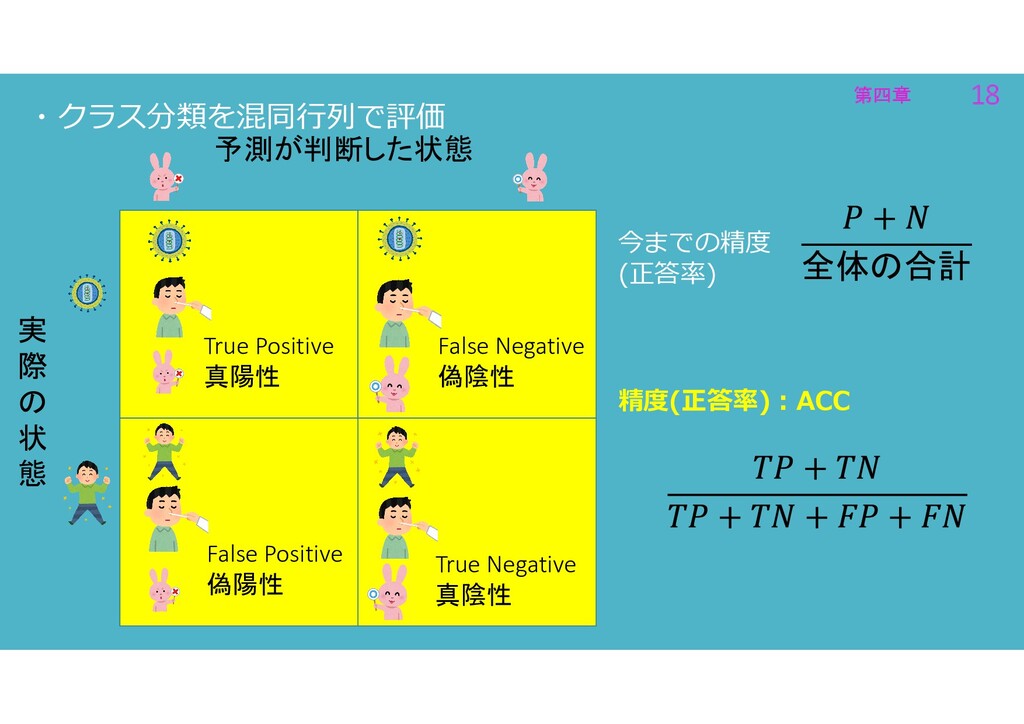
第四章 18 第四章 18 ・クラス分類を混同行列で評価 精度(正答率):ACC 全体の合計 今までの精度 (正答率) 実
際 の 状 態 予測が判断した状態 True Positive 真陽性 True Negative 真陰性 False Positive 偽陽性 False Negative 偽陰性
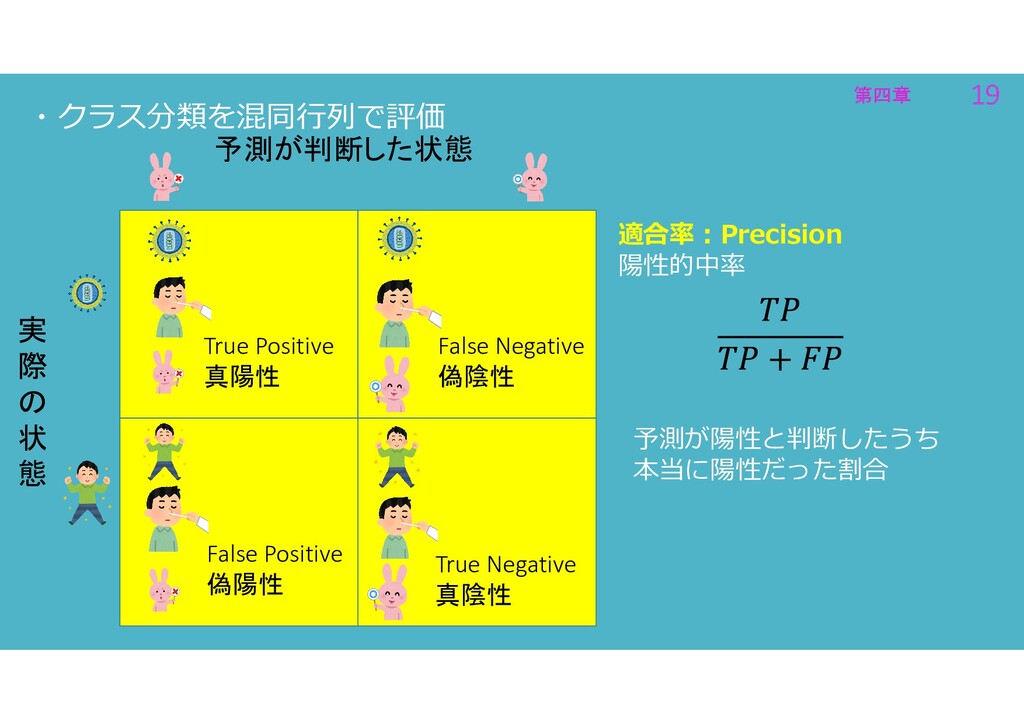
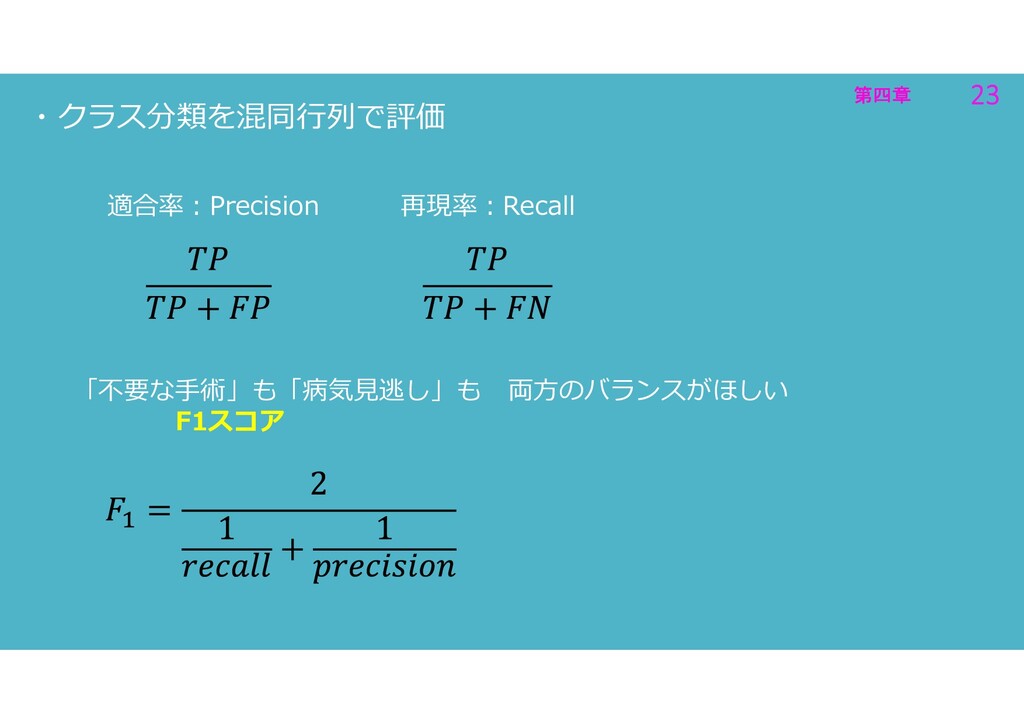
第四章 19 第四章 19 ・クラス分類を混同行列で評価 適合率:Precision 陽性的中率 予測が陽性と判断したうち 本当に陽性だった割合 実
際 の 状 態 予測が判断した状態 True Positive 真陽性 True Negative 真陰性 False Positive 偽陽性 False Negative 偽陰性
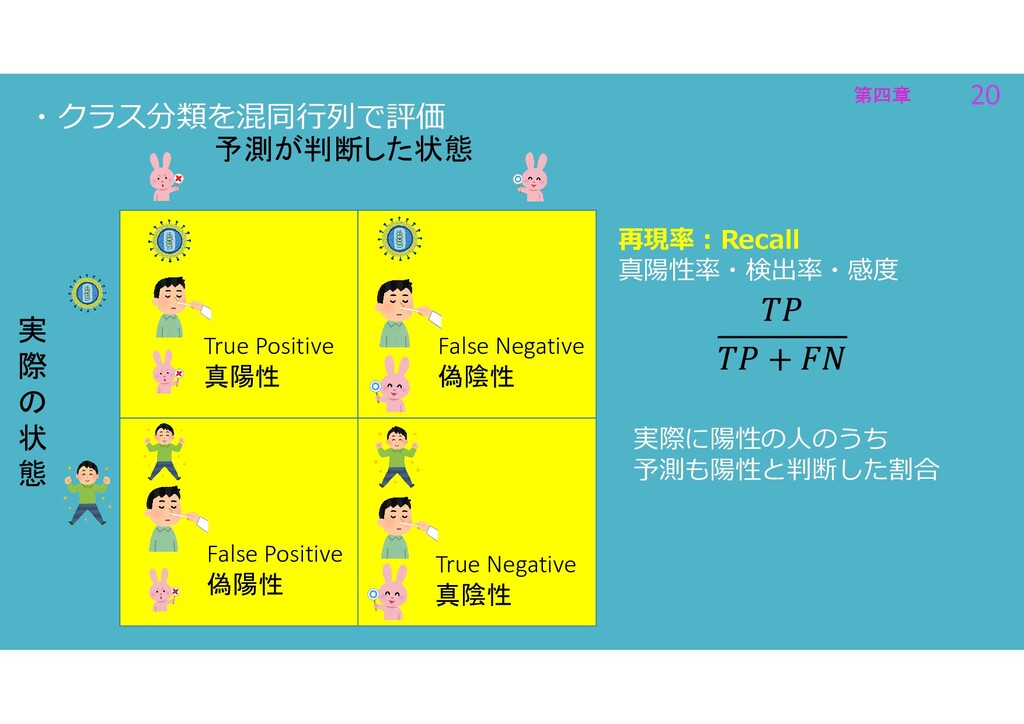
第四章 20 第四章 20 ・クラス分類を混同行列で評価 再現率:Recall 真陽性率・検出率・感度 実際に陽性の人のうち 予測も陽性と判断した割合 実
際 の 状 態 予測が判断した状態 True Positive 真陽性 True Negative 真陰性 False Positive 偽陽性 False Negative 偽陰性
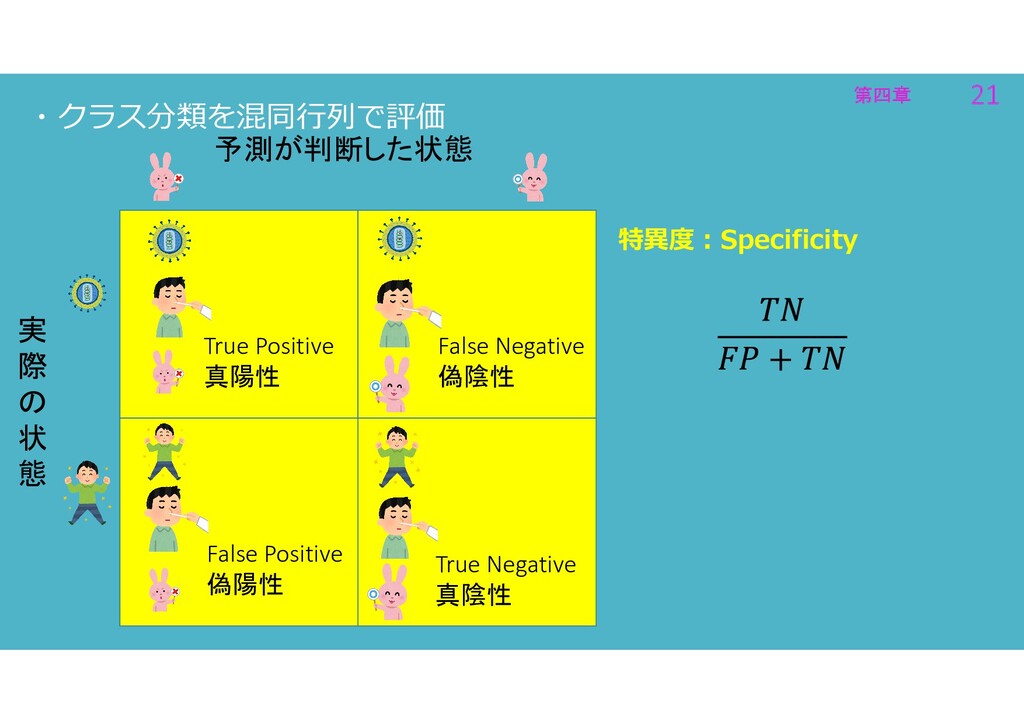
第四章 21 第四章 21 ・クラス分類を混同行列で評価 特異度:Specificity 実 際 の 状
態 予測が判断した状態 True Positive 真陽性 True Negative 真陰性 False Positive 偽陽性 False Negative 偽陰性
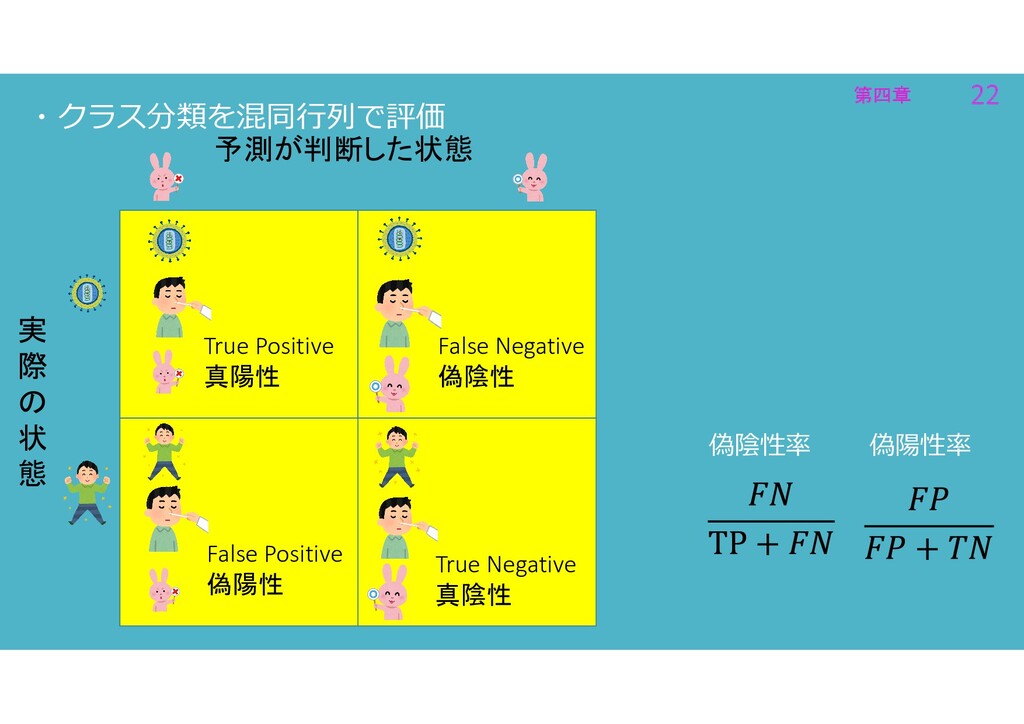
第四章 22 第四章 22 ・クラス分類を混同行列で評価 偽陽性率 偽陰性率 実 際 の
状 態 予測が判断した状態 True Positive 真陽性 True Negative 真陰性 False Positive 偽陽性 False Negative 偽陰性
第四章 23 第四章 23 ・クラス分類を混同行列で評価 適合率:Precision 再現率:Recall 「不要な手術」も「病気見逃し」も 両方のバランスがほしい F1スコア
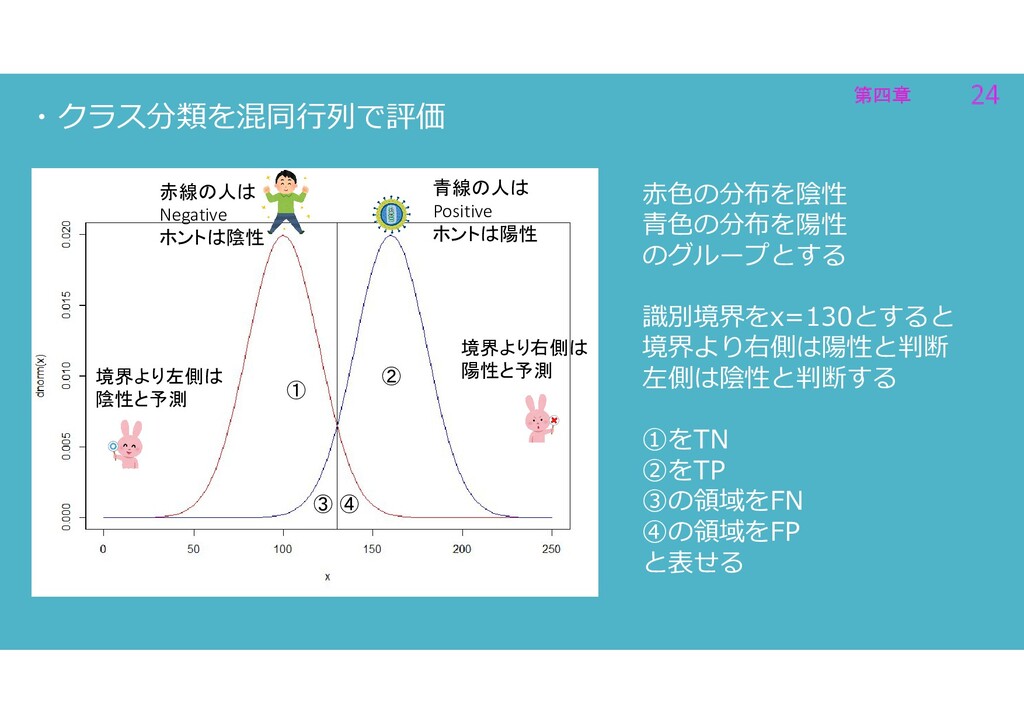
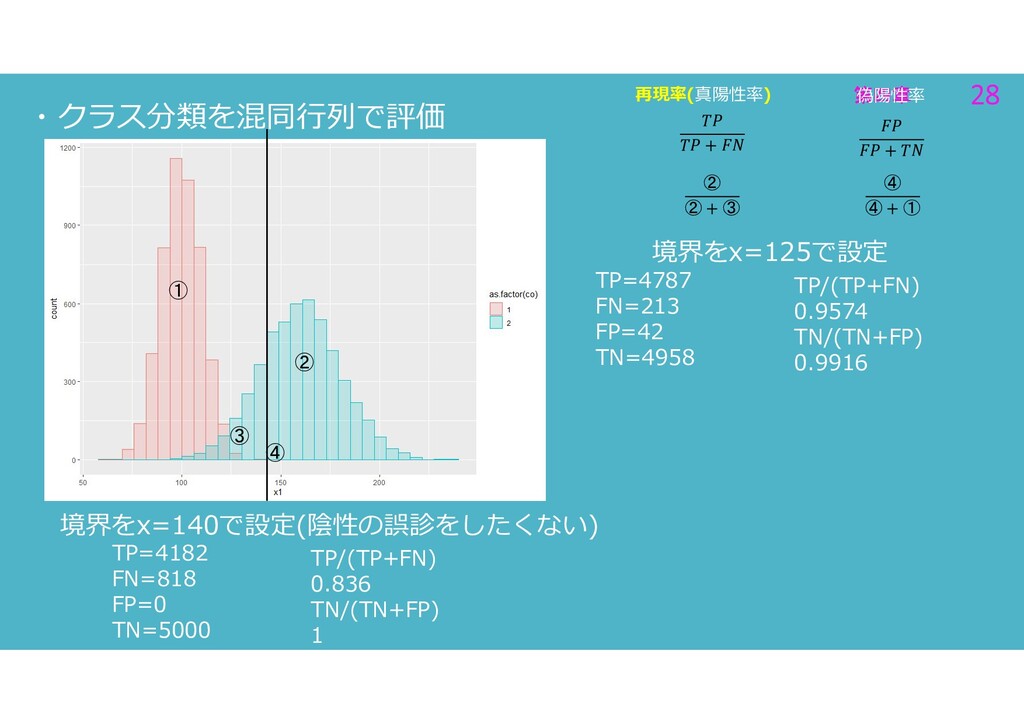
第四章 24 第四章 24 ・クラス分類を混同行列で評価 赤色の分布を陰性 青色の分布を陽性 のグループとする 識別境界をx=130とすると 境界より右側は陽性と判断
左側は陰性と判断する ①をTN ②をTP ③の領域をFN ④の領域をFP と表せる 境界より左側は 陰性と予測 ② ③ ④ ① 赤線の人は Negative ホントは陰性 青線の人は Positive ホントは陽性 境界より右側は 陽性と予測
第四章 25 第四章 25 ROC曲線と下側面積 (ROC : receiver operatorating characterisyic
curve) (AUC : area under the curve)
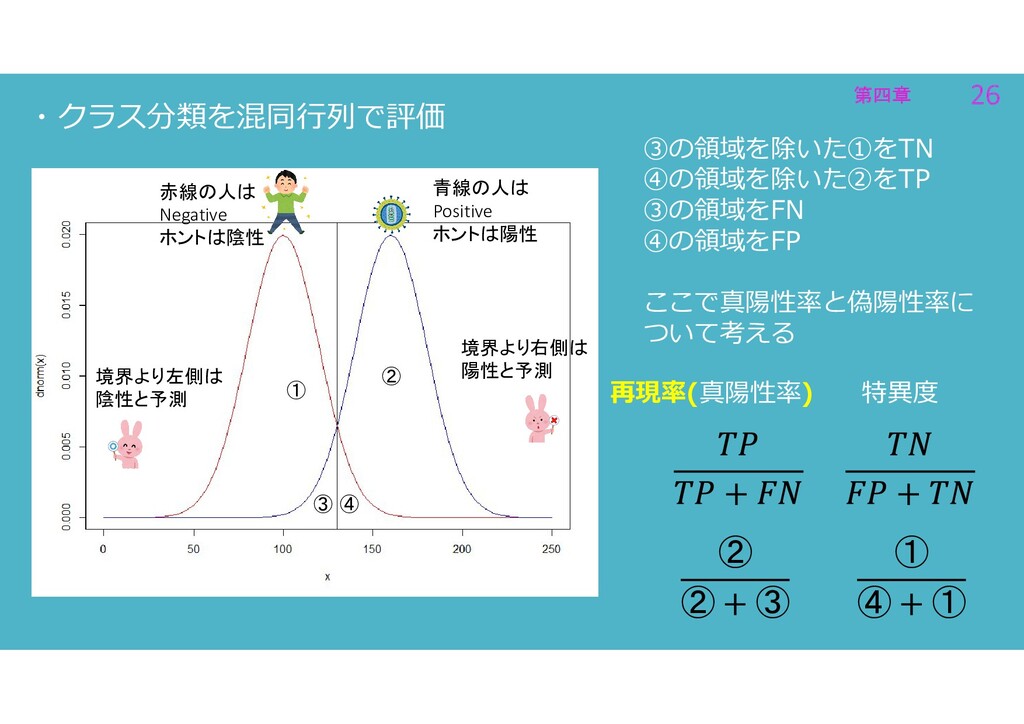
第四章 26 第四章 26 ・クラス分類を混同行列で評価 ③の領域を除いた①をTN ④の領域を除いた②をTP ③の領域をFN ④の領域をFP ここで真陽性率と偽陽性率に
ついて考える 境界より左側は 陰性と予測 ② ③ ④ ① 赤線の人は Negative ホントは陰性 青線の人は Positive ホントは陽性 境界より右側は 陽性と予測 特異度 再現率(真陽性率) ② ② ③ ① ④ ①
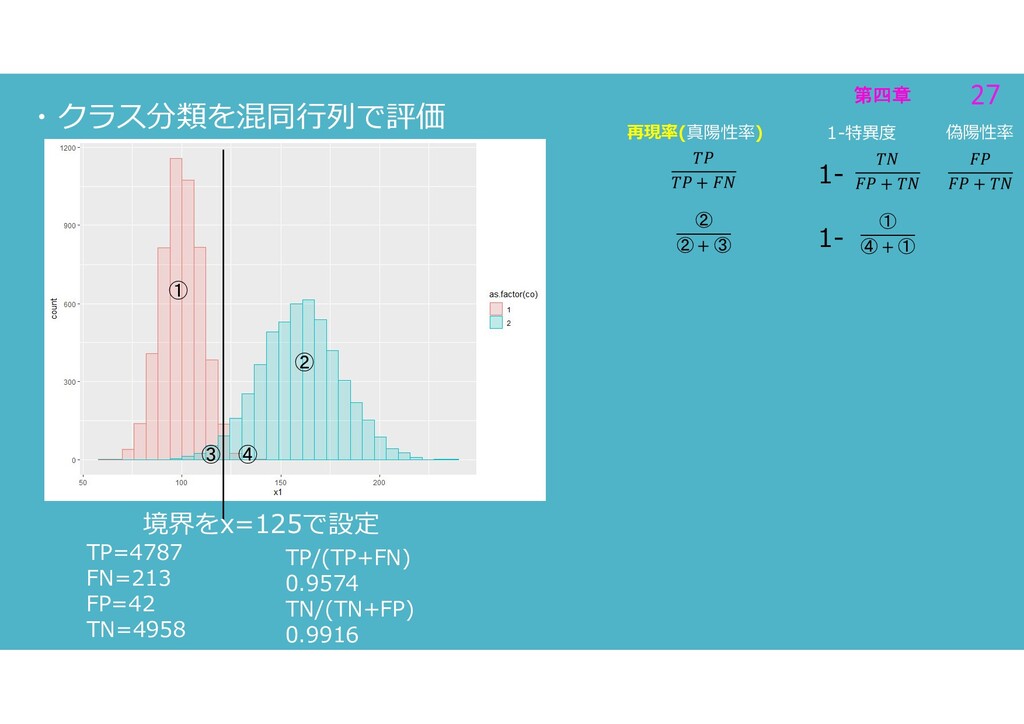
第四章 27 第四章 27 ・クラス分類を混同行列で評価 ② ③ ④ ① 1-特異度
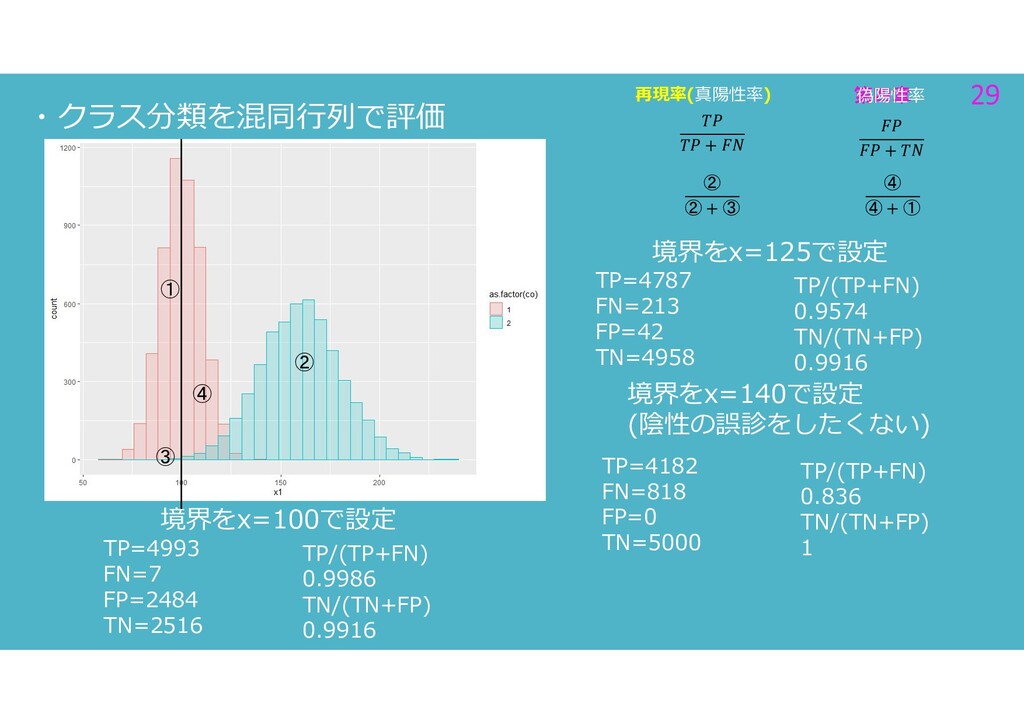
再現率(真陽性率) + ② ② + ③ TP=4787 FN=213 FP=42 TN=4958 TP/(TP+FN) 0.9574 TN/(TN+FP) 0.9916 境界をx=125で設定 + ① ④ + ① 1- 1- 偽陽性率 +
第四章 28 第四章 28 ・クラス分類を混同行列で評価 ② ③ ④ ① 偽陽性率
+ 再現率(真陽性率) + ② ② + ③ ④ ④ + ① TP=4787 FN=213 FP=42 TN=4958 TP/(TP+FN) 0.9574 TN/(TN+FP) 0.9916 境界をx=125で設定 TP=4182 FN=818 FP=0 TN=5000 TP/(TP+FN) 0.836 TN/(TN+FP) 1 境界をx=140で設定(陰性の誤診をしたくない)
第四章 29 第四章 29 ・クラス分類を混同行列で評価 ② ③ ④ ① 偽陽性率
+ 再現率(真陽性率) + ② ② + ③ ④ ④ + ① TP=4787 FN=213 FP=42 TN=4958 TP/(TP+FN) 0.9574 TN/(TN+FP) 0.9916 境界をx=125で設定 TP=4182 FN=818 FP=0 TN=5000 TP/(TP+FN) 0.836 TN/(TN+FP) 1 境界をx=140で設定 (陰性の誤診をしたくない) TP=4993 FN=7 FP=2484 TN=2516 TP/(TP+FN) 0.9986 TN/(TN+FP) 0.9916 境界をx=100で設定
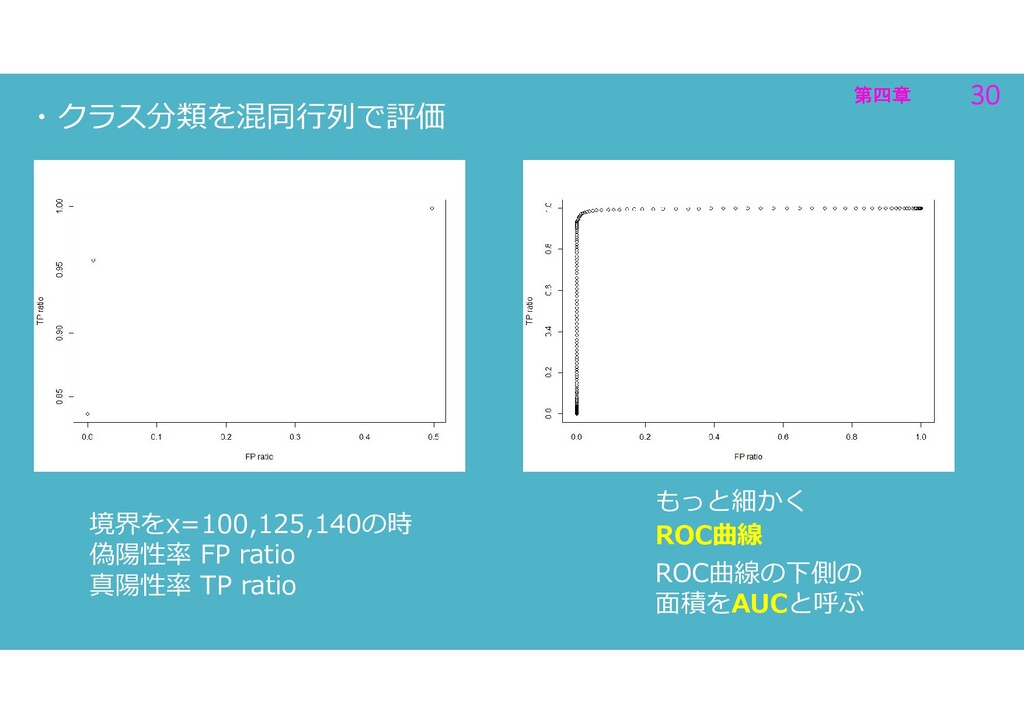
第四章 30 第四章 30 ・クラス分類を混同行列で評価 境界をx=100,125,140の時 偽陽性率 FP ratio 真陽性率
TP ratio もっと細かく ROC曲線 ROC曲線の下側の 面積をAUCと呼ぶ
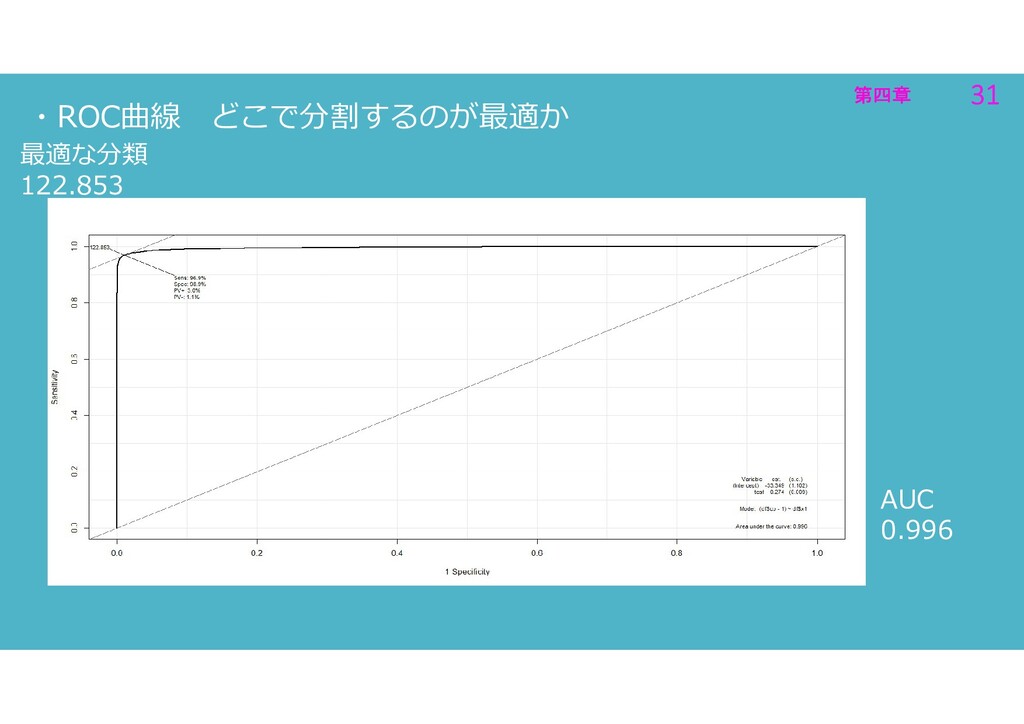
第四章 31 第四章 31 ・ROC曲線 どこで分割するのが最適か 最適な分類 122.853 AUC 0.996
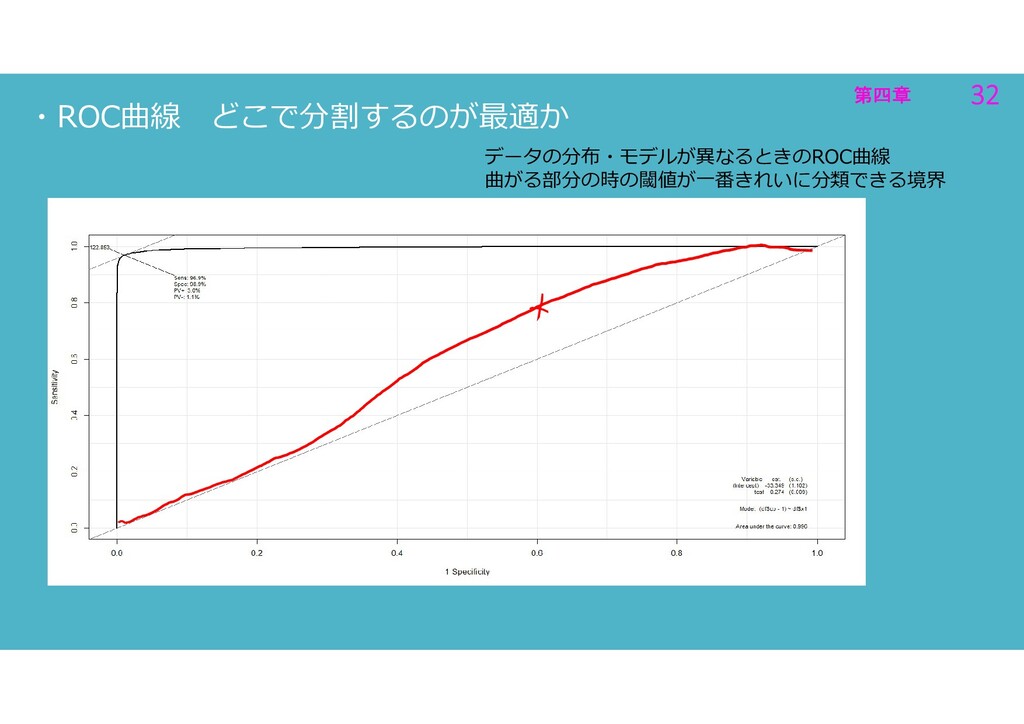
第四章 32 第四章 32 ・ROC曲線 どこで分割するのが最適か データの分布・モデルが異なるときのROC曲線 曲がる部分の時の閾値が一番きれいに分類できる境界
第四章 33 第四章 33 二次判別分析 (quadratic discriminant analysis:QDA)
第四章 34 第四章 34 ・二次判別分析(quadratic discriminant analysis:QDA) 線形判別(LDA)では、各群で分散は等しいと仮定した分析 クラス1もクラス2も同じ分散 計算するのは変数の数pとすると
p(p+1)/2 個のパラメータ 二次判別(QDA)では、各群で分散は等しいくないと仮定 クラス1もクラス2も異なる分散 計算するのは変数の数p クラス数kとすると kp(p+1)/2 個のパラメータ 各クラスの期待値からの二乗の距離で判別 (変数間の相関を考えた距離を使うのがマハラノビス距離)
第四章 35 第四章 35
第四章 36 第四章 36 ・線形判別とは
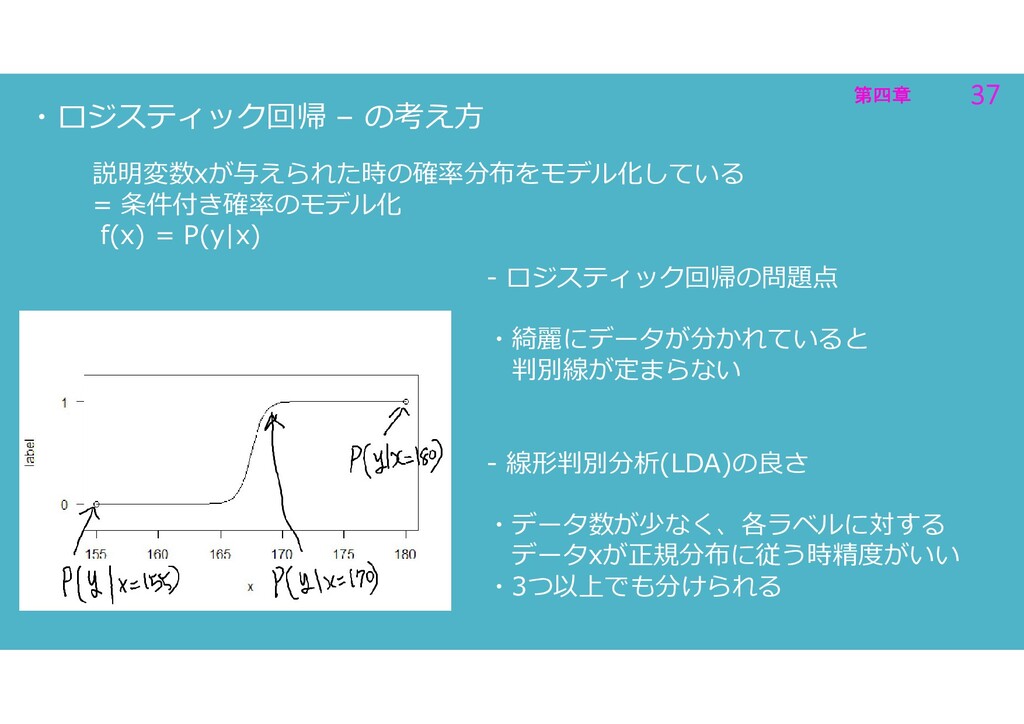
第四章 37 第四章 37 ・ロジスティック回帰 – の考え方 説明変数xが与えられた時の確率分布をモデル化している = 条件付き確率のモデル化
f(x) = P(y|x) - ロジスティック回帰の問題点 ・綺麗にデータが分かれていると 判別線が定まらない - 線形判別分析(LDA)の良さ ・データ数が少なく、各ラベルに対する データxが正規分布に従う時精度がいい ・3つ以上でも分けられる
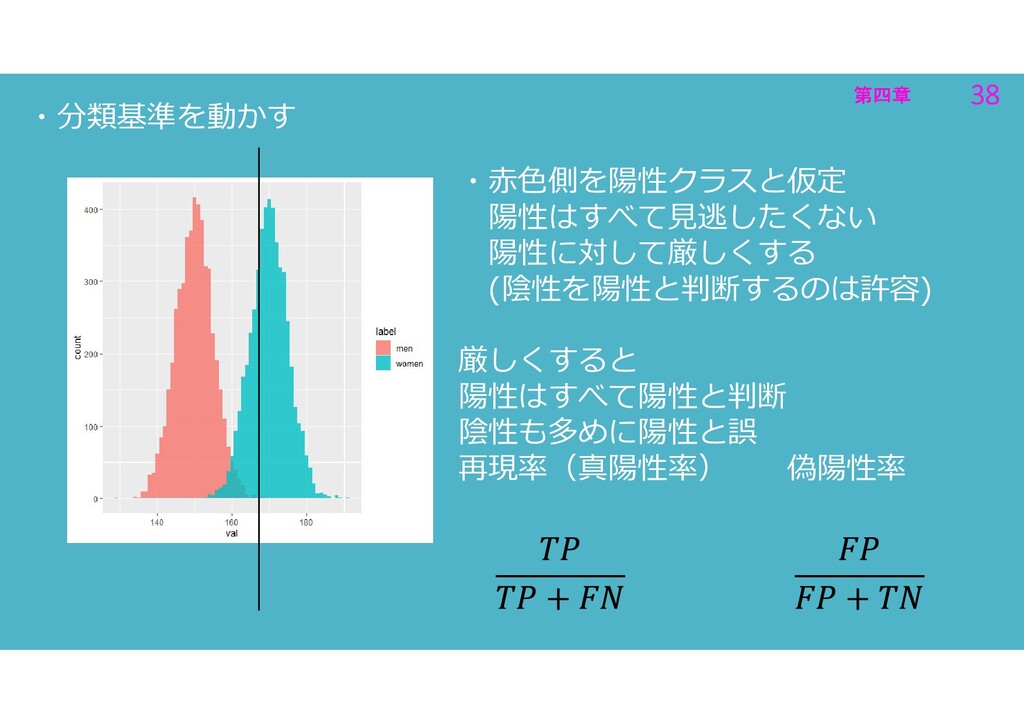
第四章 38 第四章 38 ・分類基準を動かす ・赤色側を陽性クラスと仮定 陽性はすべて見逃したくない 陽性に対して厳しくする (陰性を陽性と判断するのは許容) 厳しくすると
陽性はすべて陽性と判断 陰性も多めに陽性と誤 再現率(真陽性率) 偽陽性率
第四章 39 第四章 39 ・分類基準を動かす ただし、偽陽性率は当然増える (閾値をずらして陽性を許容するから) 閾値をずらしていった時の 「偽陽性率」と「真陽性率」をplotする
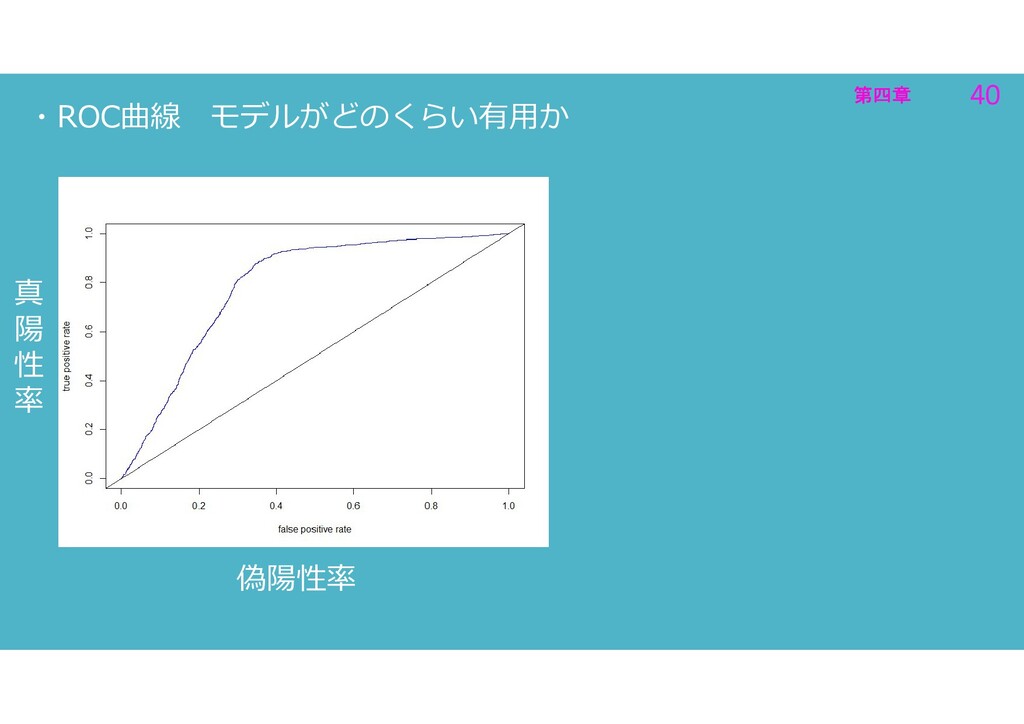
第四章 40 第四章 40 ・ROC曲線 モデルがどのくらい有用か 偽陽性率 真 陽 性
率
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}