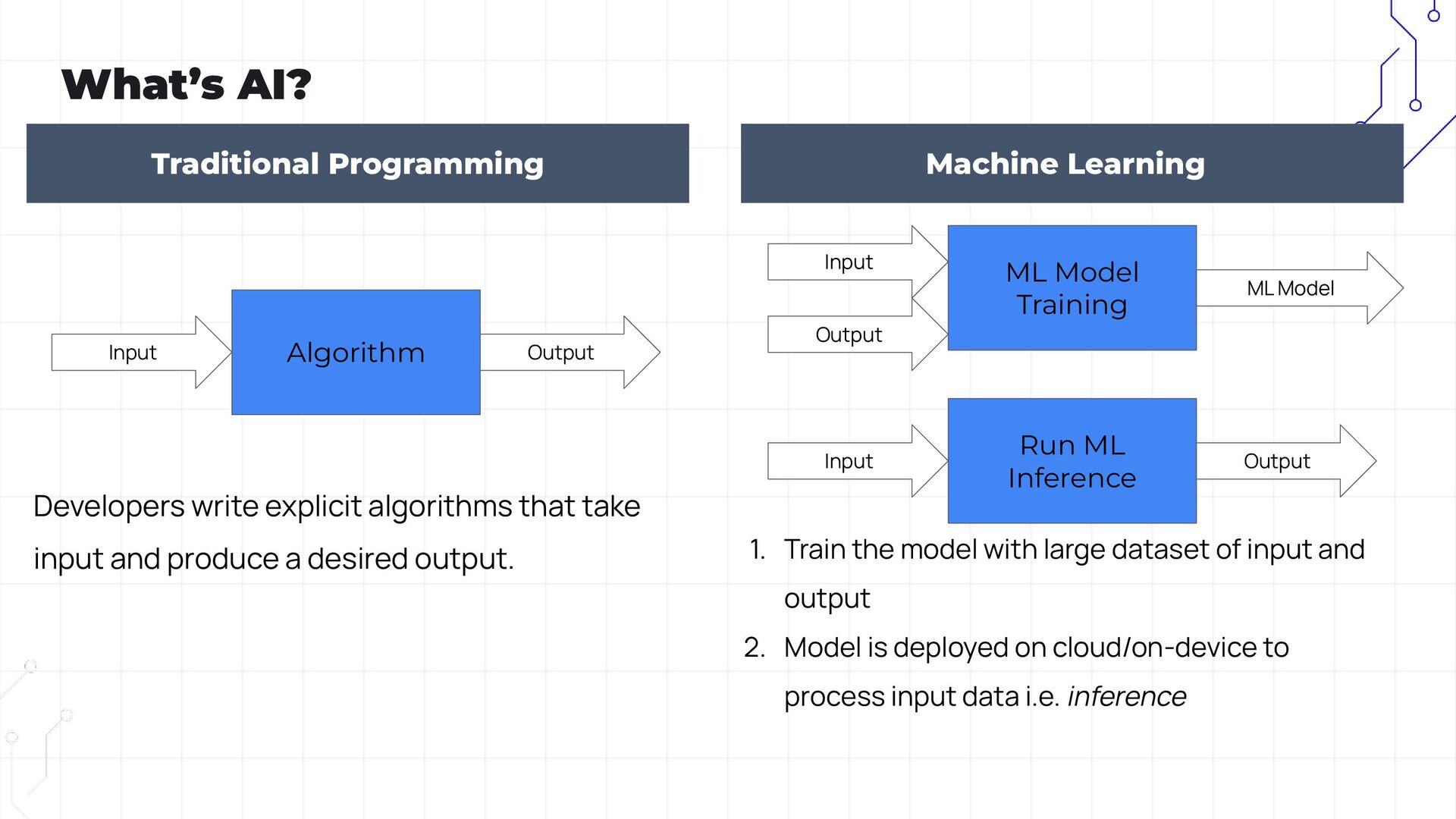
In an era where generative AI is rapidly evolving and cross-platform development is on the rise, Kotlin Multiplatform (KMP) offers a unique way to blend on-device and API-driven AI experiences. Our session will explore how to leverage these technologies to create a dynamic story generator app.
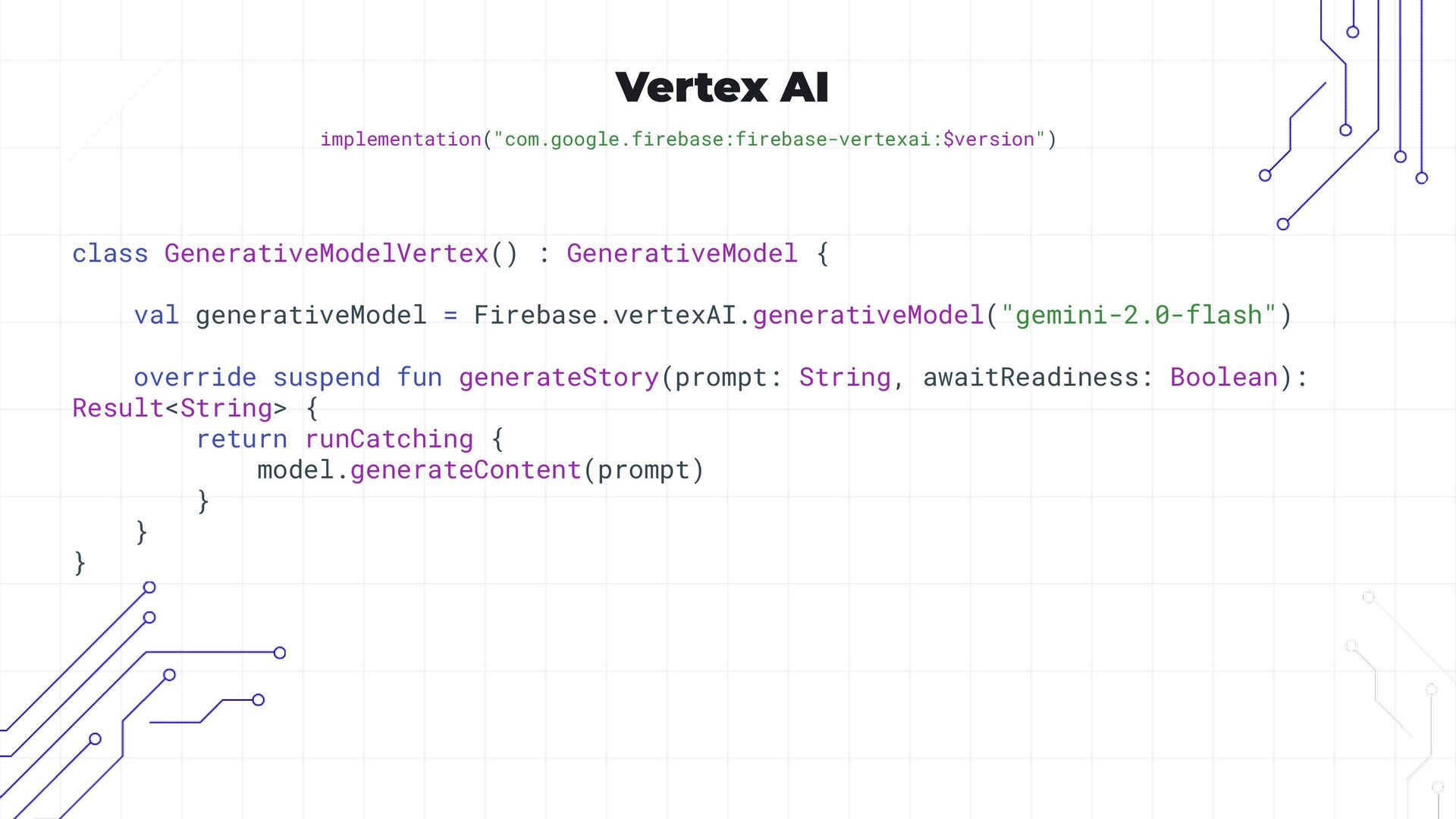
In this session, we’ll explore how to create a dynamic story generator using Google’s Kotlin Multiplatform (KMP) framework and the Gemma on-device language model. We’ll start by using the Gemini API to generate initial stories and then transition to on-device story generation with the Gemma model. Attendees will see how to move from a cloud-based model to an on-device solution, progressively refining the output through prompt tuning and adapter-based fine-tuning.
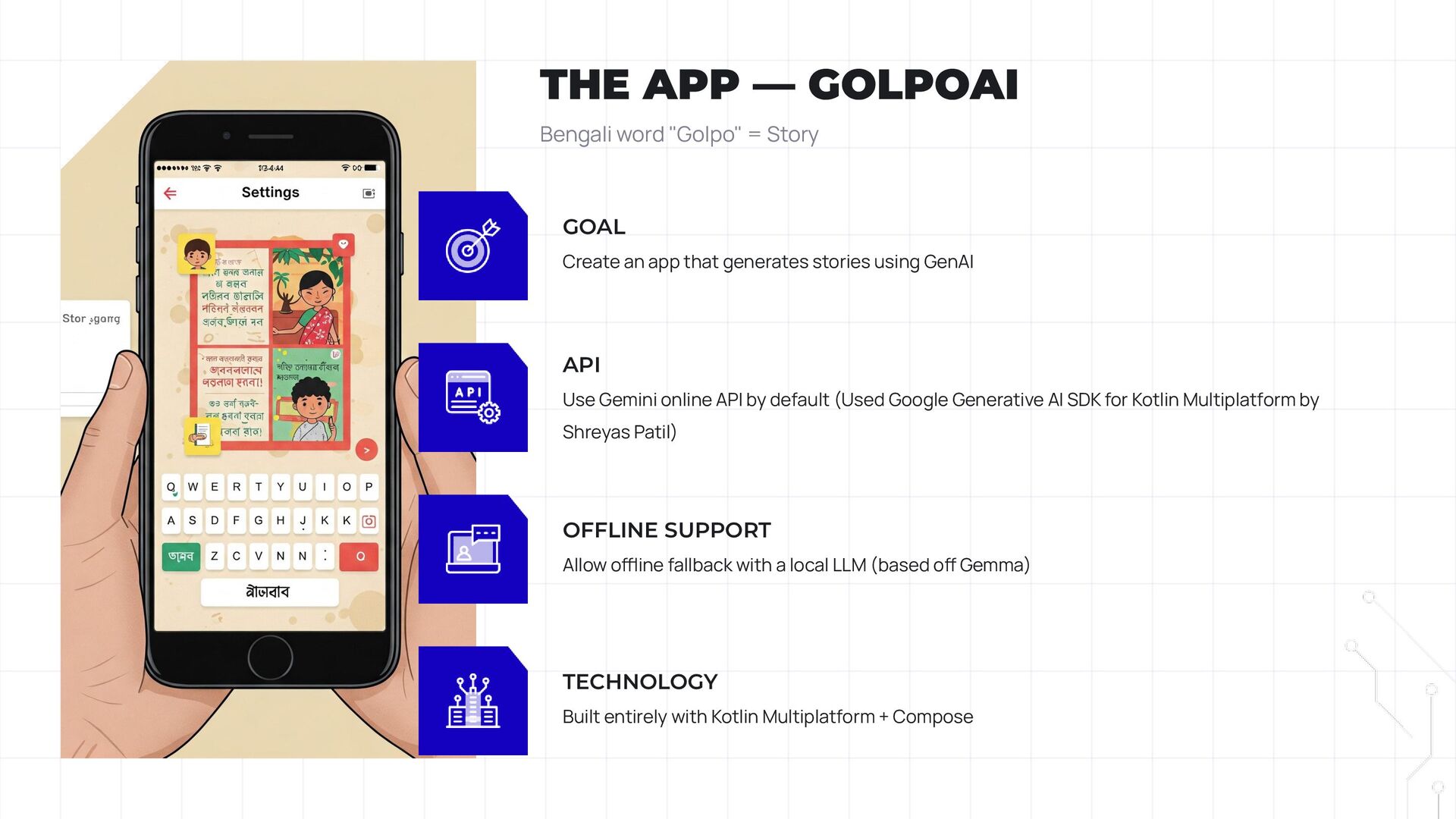
In essence, the app is a story generator, and the demo highlights how different model variations can enrich the storytelling experience. This abstract approach will give attendees a clear picture of how we’re blending API-based and on-device techniques to craft dynamic stories.
What the Session Covers:
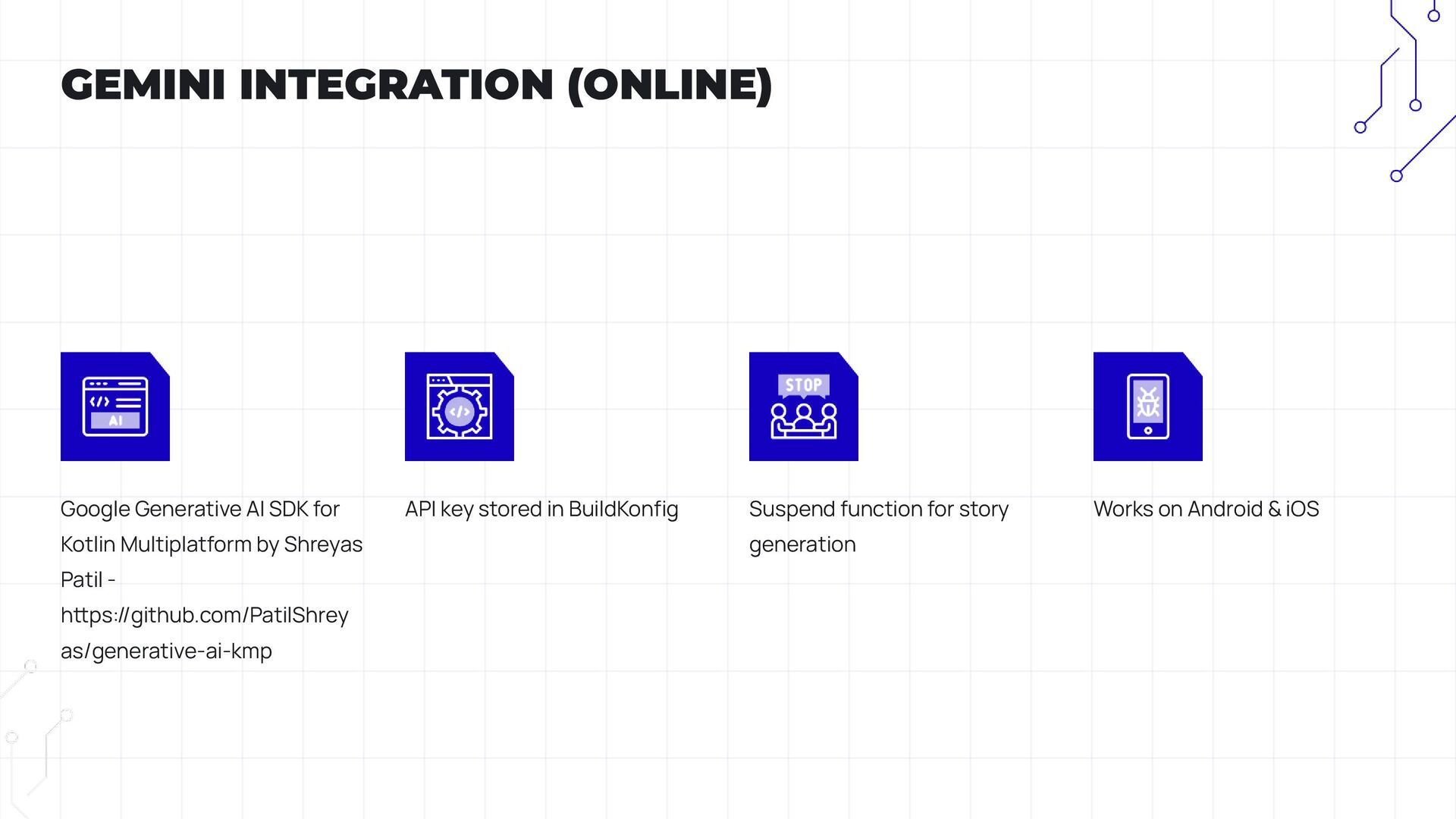
• How to kickstart story generation using the Gemini API.
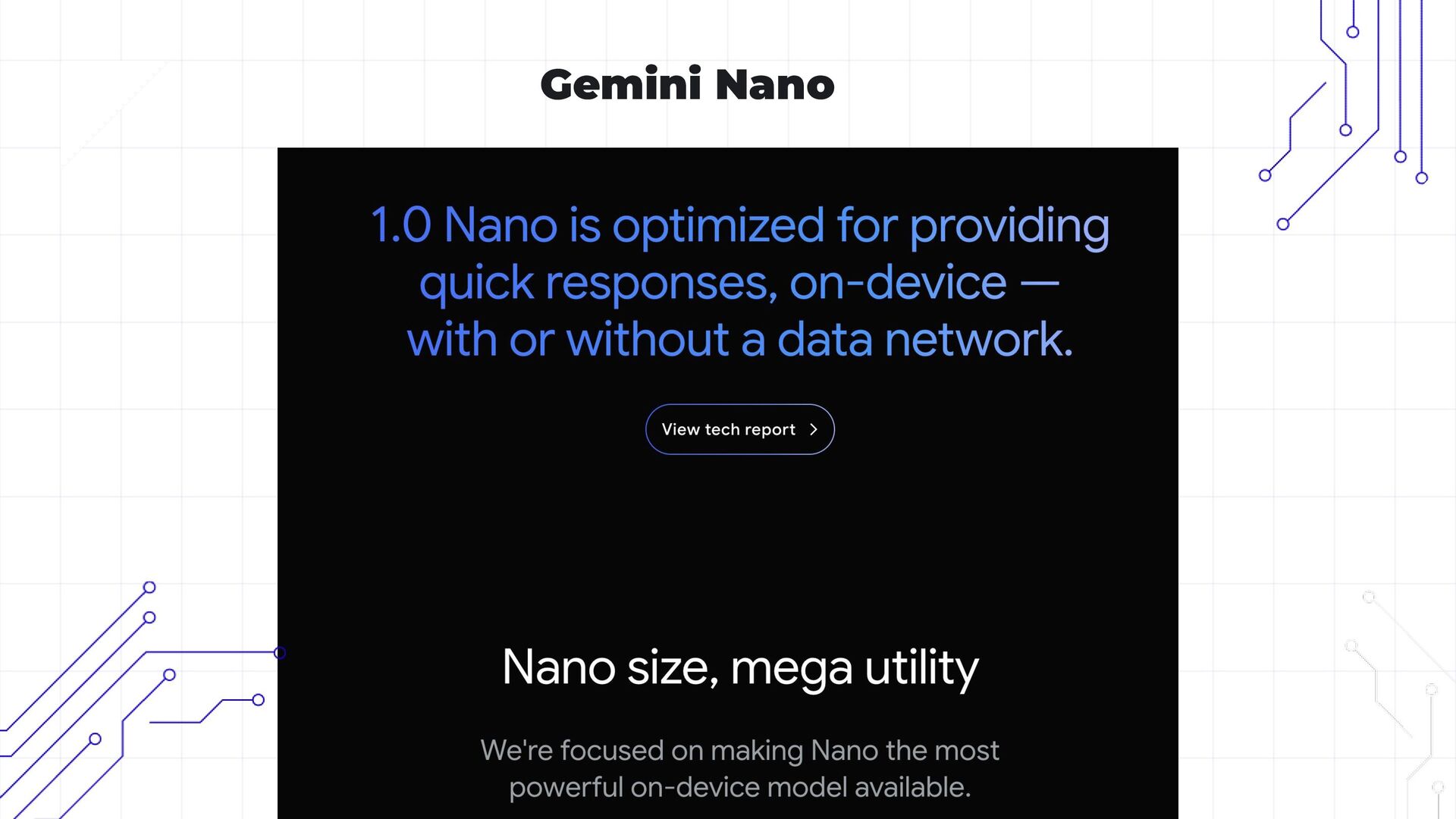
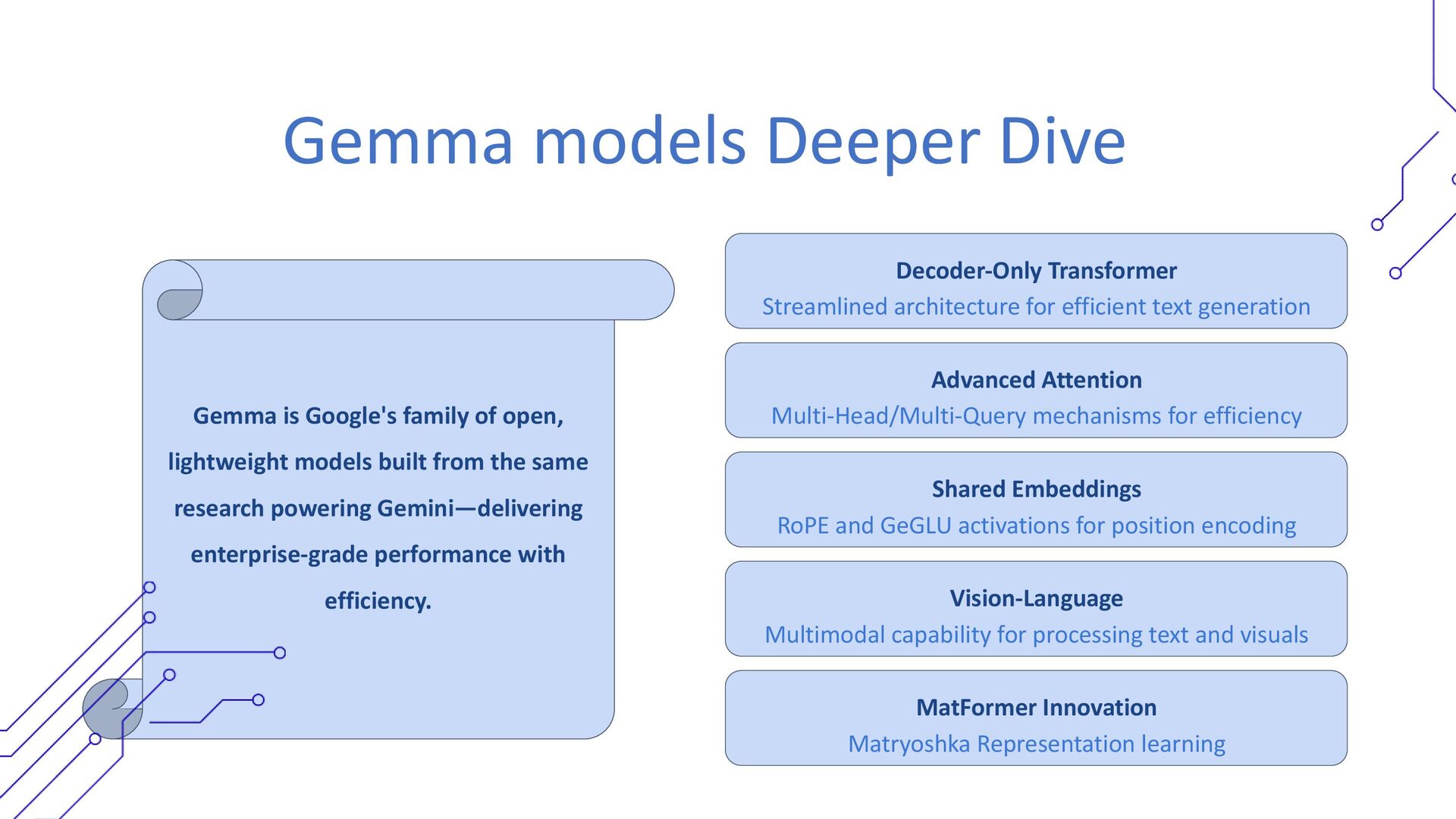
• Transitioning to Google’s Gemma model for offline personalization.
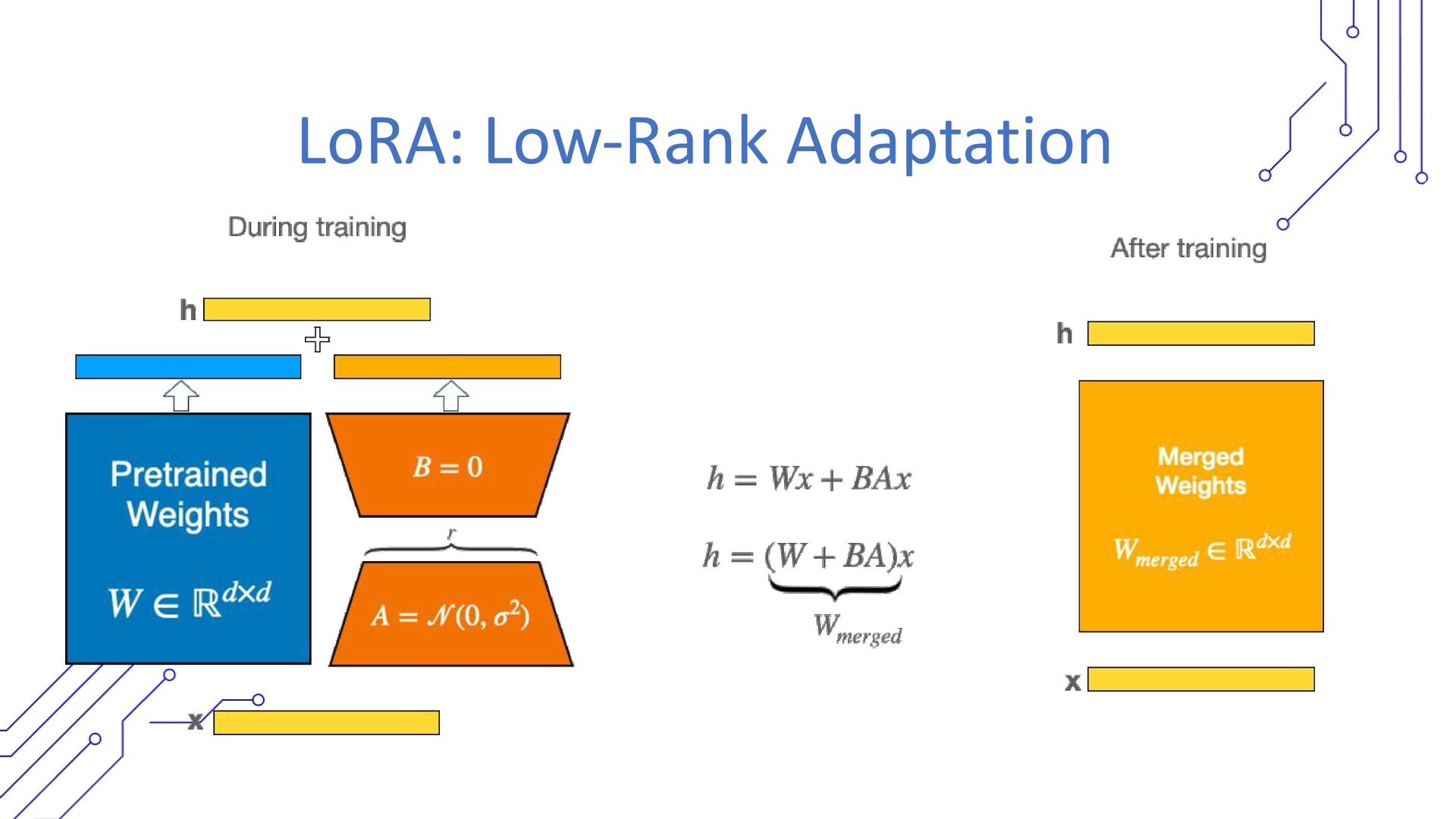
• Applying prompt tuning and fine-tuning to enhance on-device story quality.
• Evaluation methods to compare the different stages of model refinement.
Session Highlights:
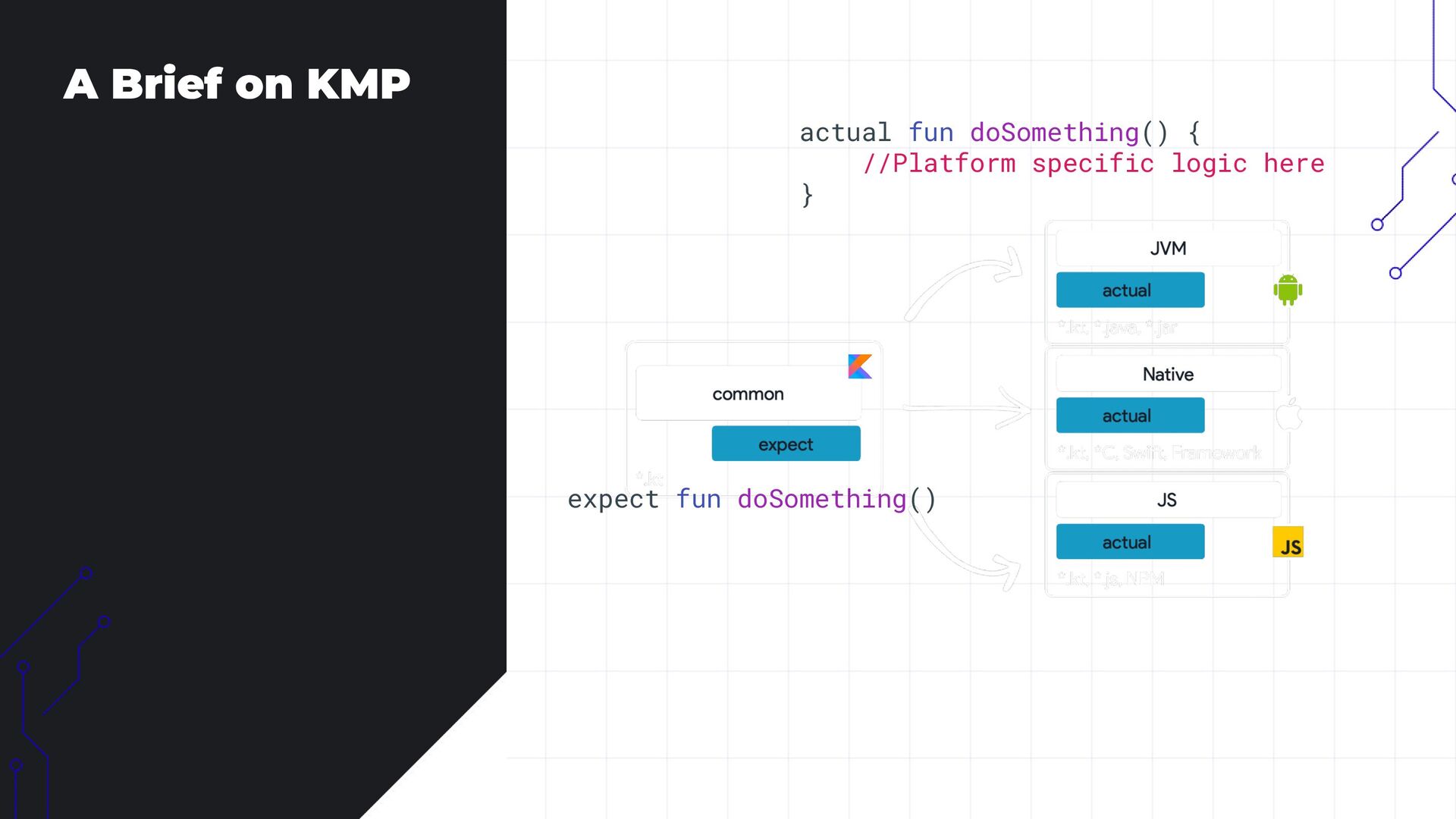
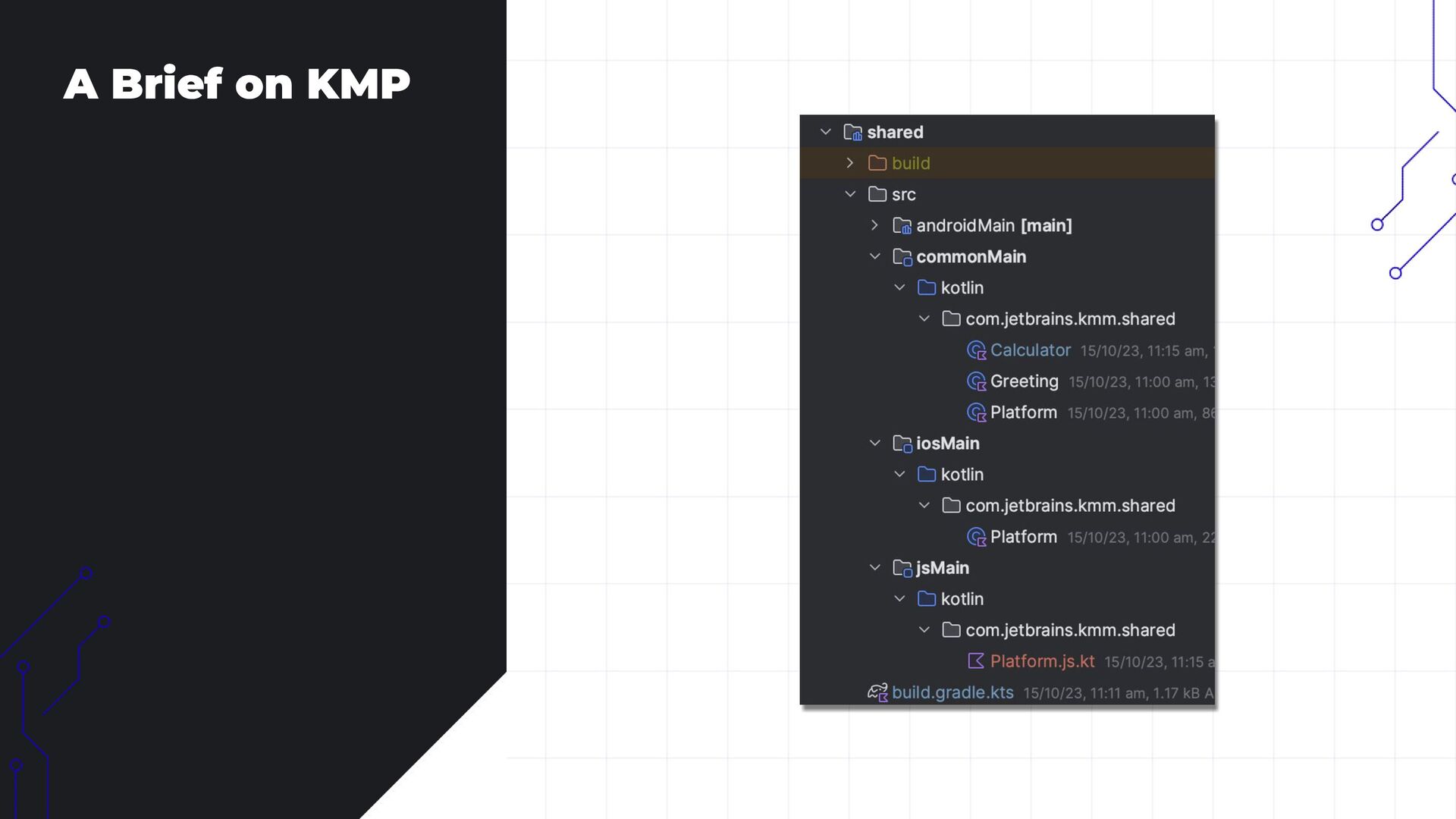
• Cross-Platform AI Integration: How KMP enables seamless use of both API-based and on-device models.
• Story Generation Techniques: Comparing base, prompt-tuned, and fine-tuned model outputs to show how each step refines the storytelling.
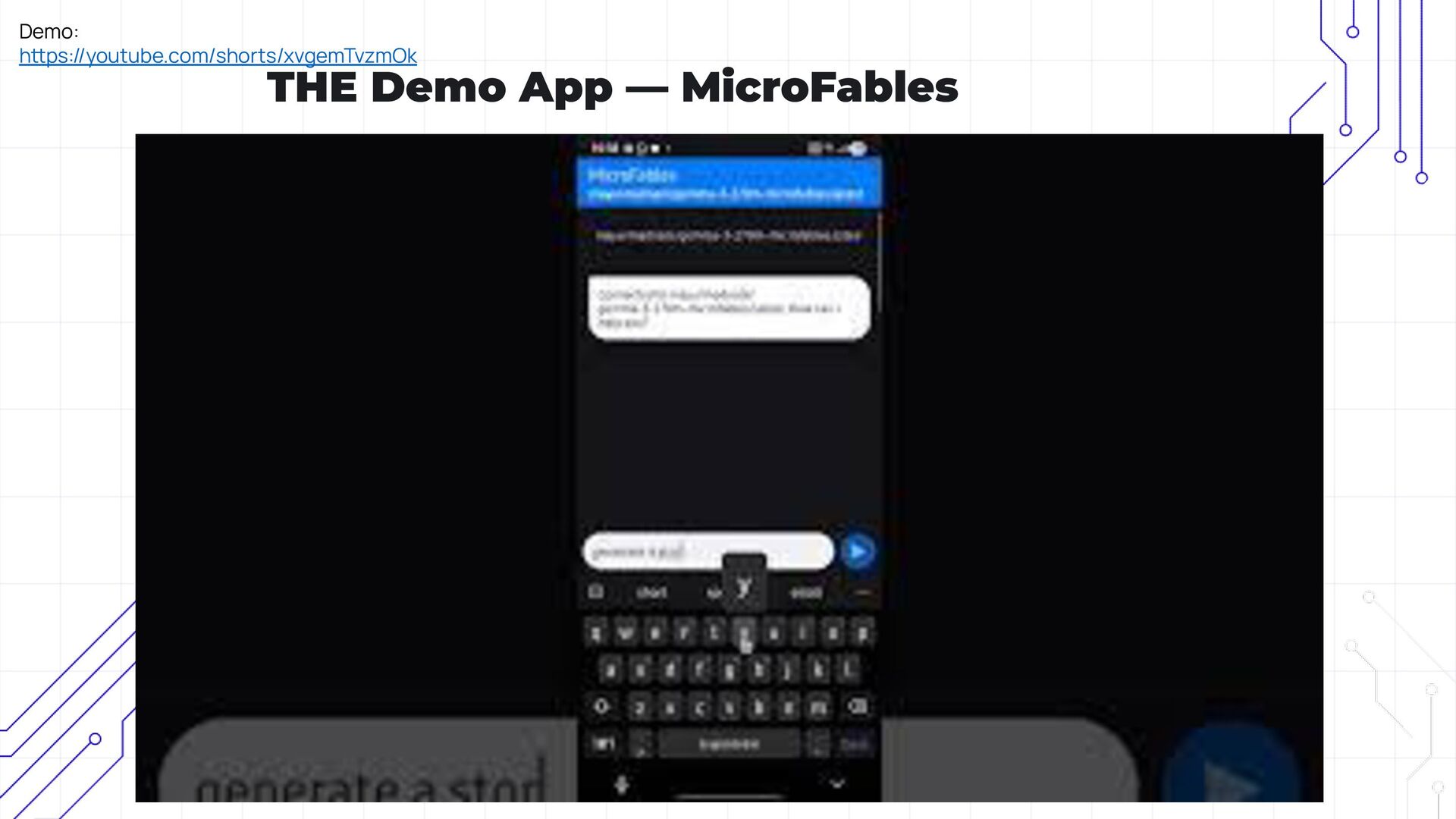
• Practical Demo: A live walk-through of how the app generates and personalizes stories in real time.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}