We introduce RL concepts, methods, and applications. We look at tools and frameworks for posing and solving RL problems, including OpenAI gym. We then more closely examine Q learning and Deep Q Networks, a popular contemporary deep reinforcement algorithm. We aim to share the best insights from the top researchers in a lucid and entertaining way. We assume only basic knowledge of machine learning and math.
Robin Chauhan has a longstanding interest in AI and machine learning theory and practice. He has applied AI to venture capital, fintech fraud, transportation, and environmental engineering. He holds a BASc in Computer Engineering from University of Waterloo.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Deep Q-Networks and Friends Robin Ranjit Singh Chauhan [email protected] Pathway](https://files.speakerdeck.com/presentations/5b99d11a967648e4a9fcad41c9dac1e1/slide_84.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
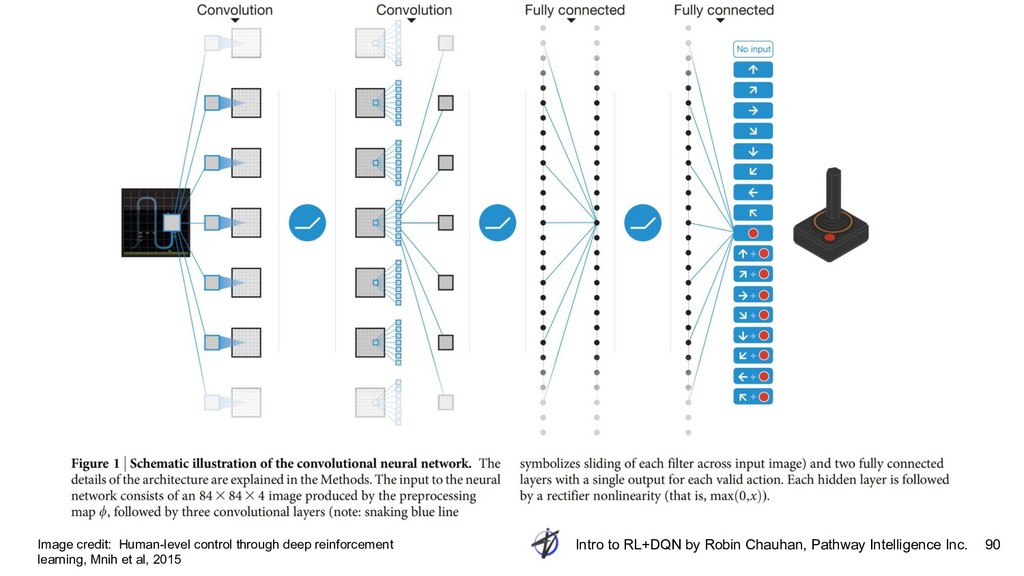{kind=link}
{kind=link}
{kind=link}
{kind=link}
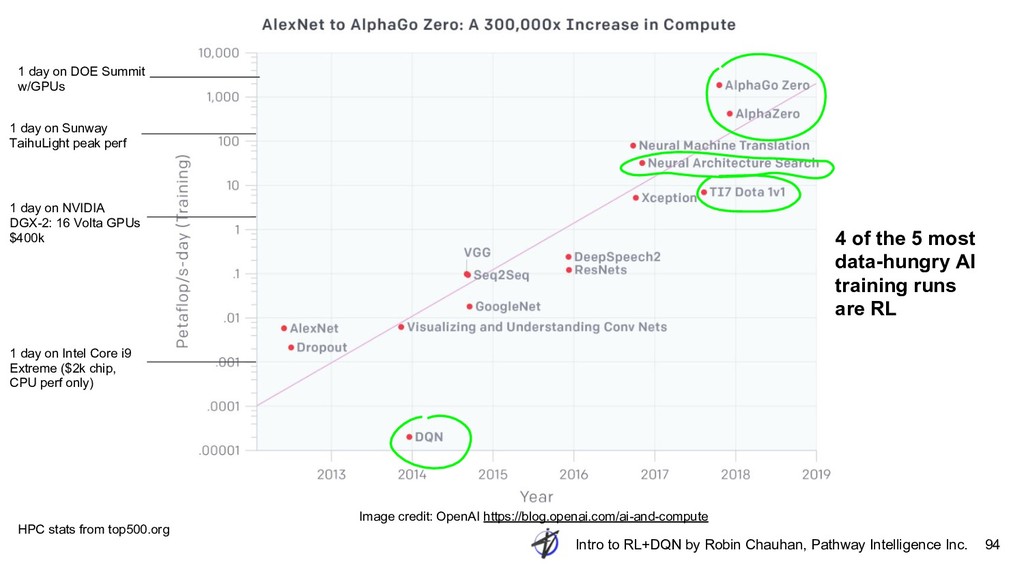{kind=link}
{kind=link}
{kind=link}
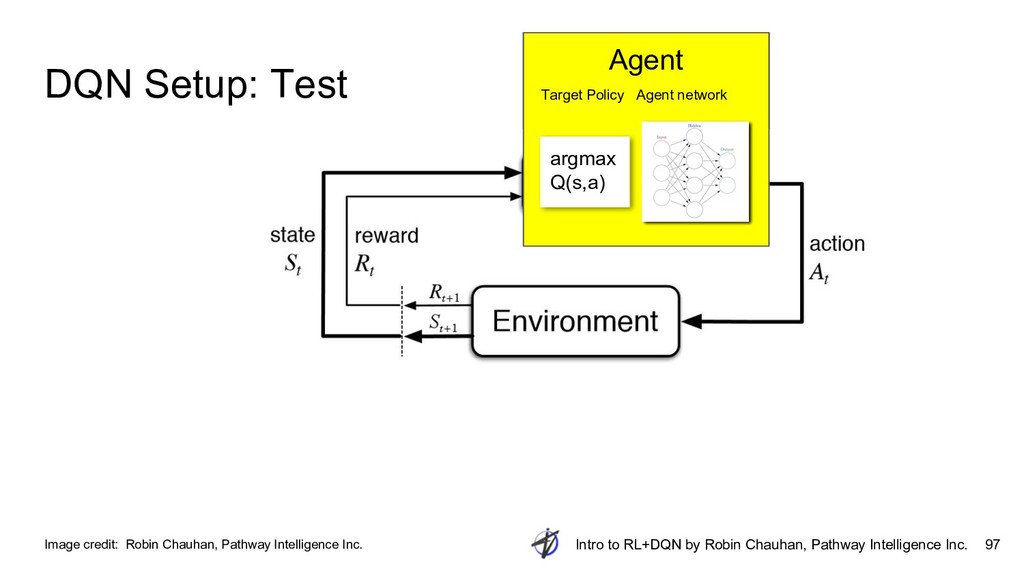{kind=link}
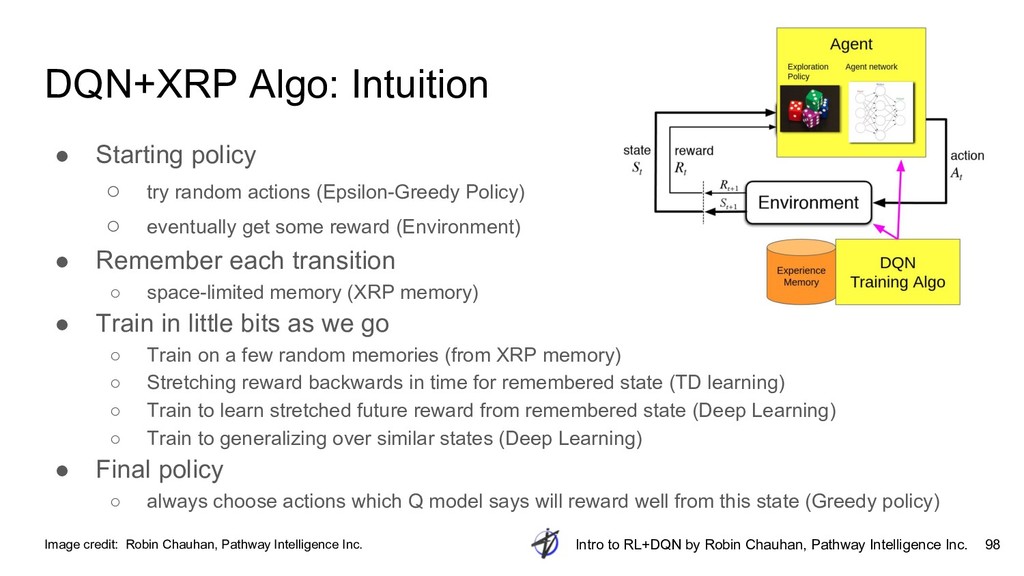{kind=link}
{kind=link}
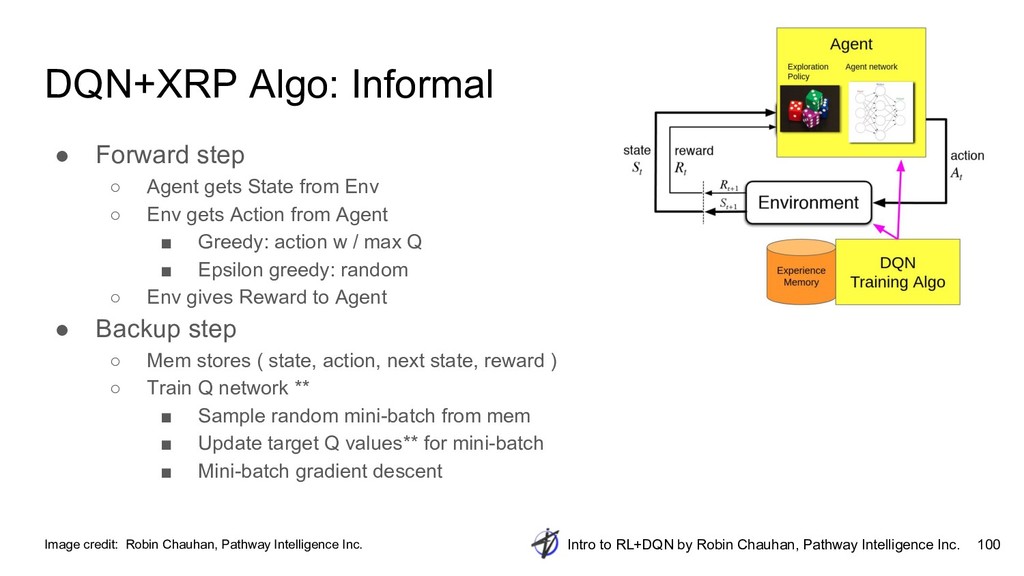{kind=link}
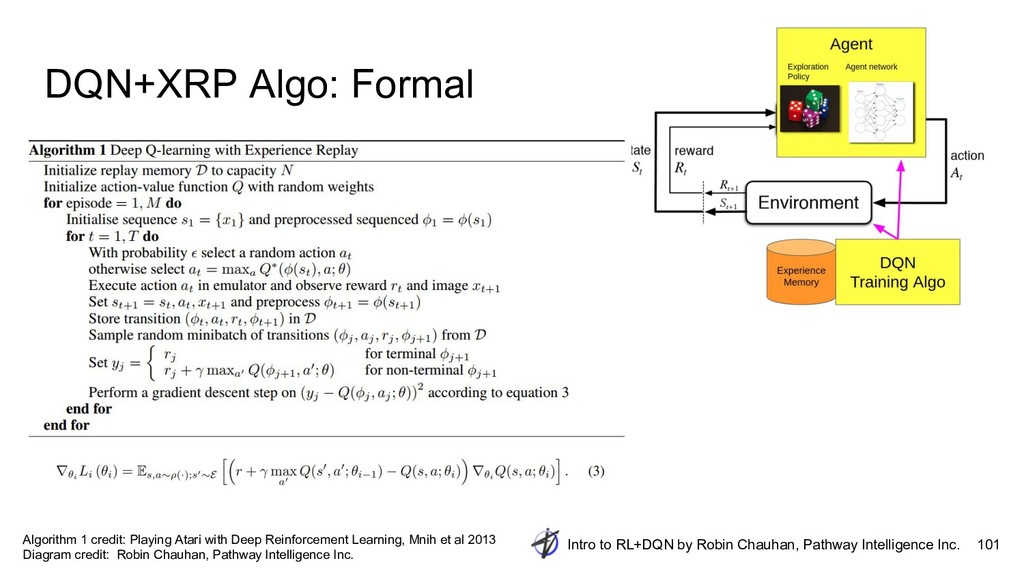{kind=link}
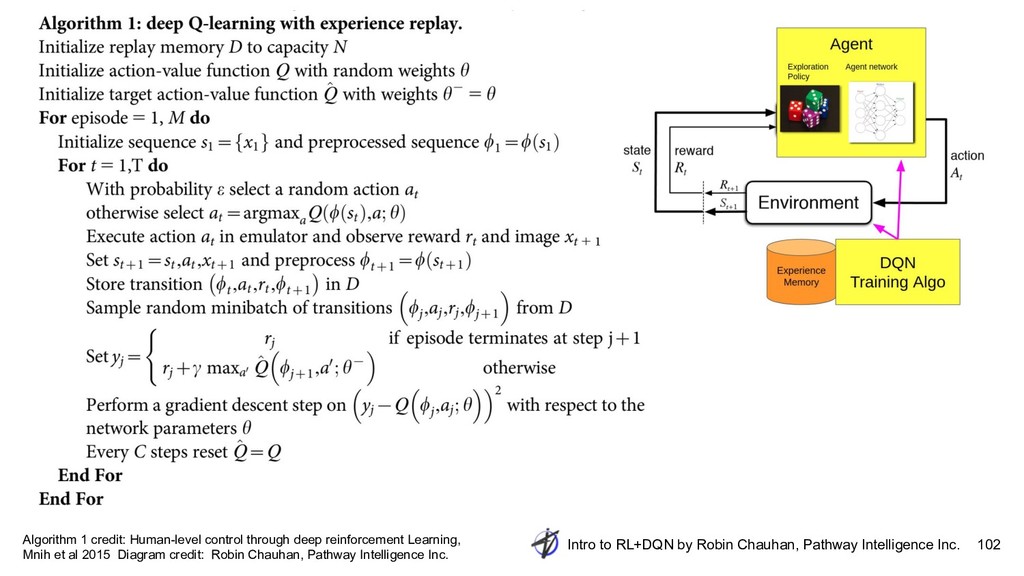{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
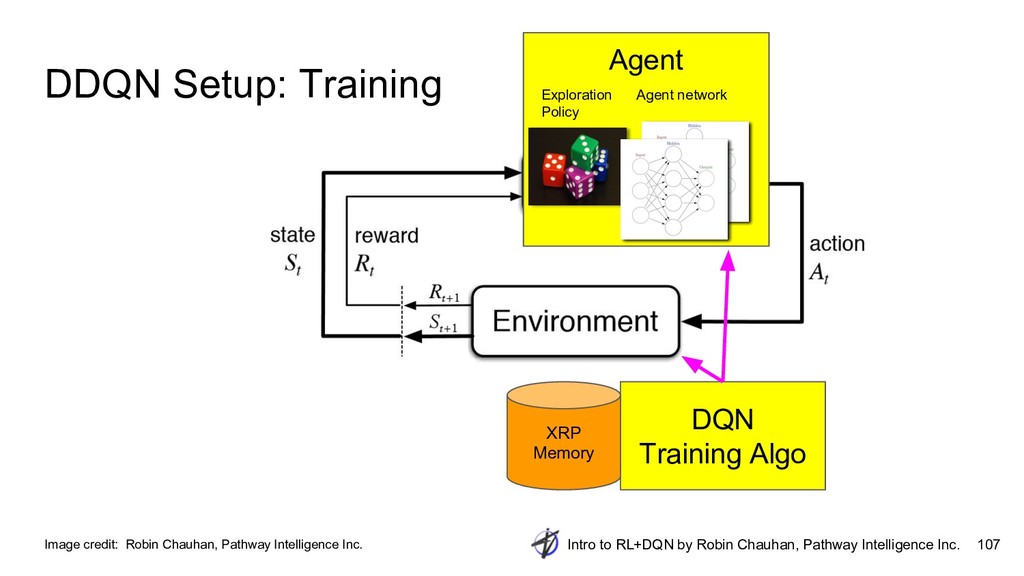{kind=link}
{kind=link}
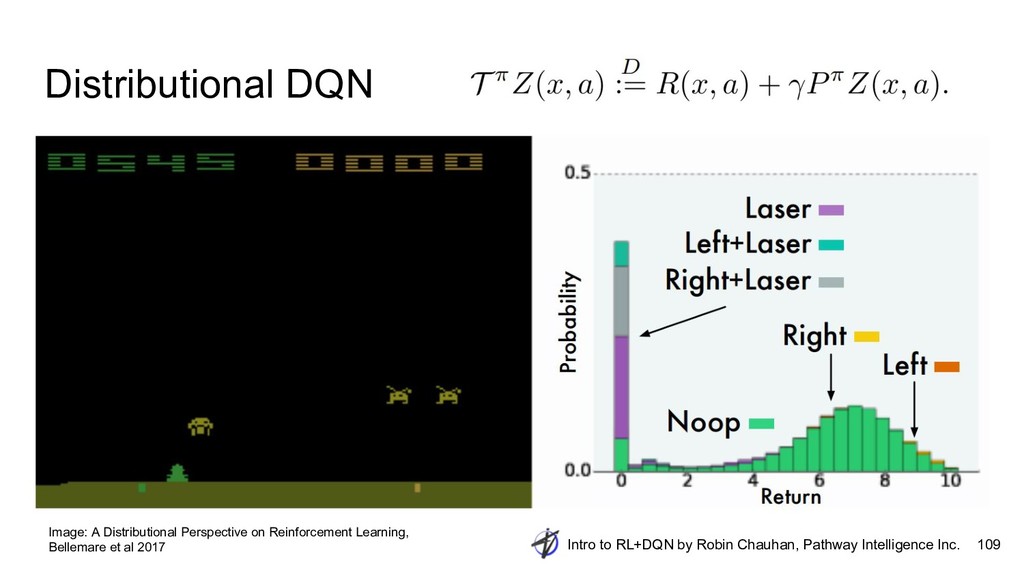{kind=link}
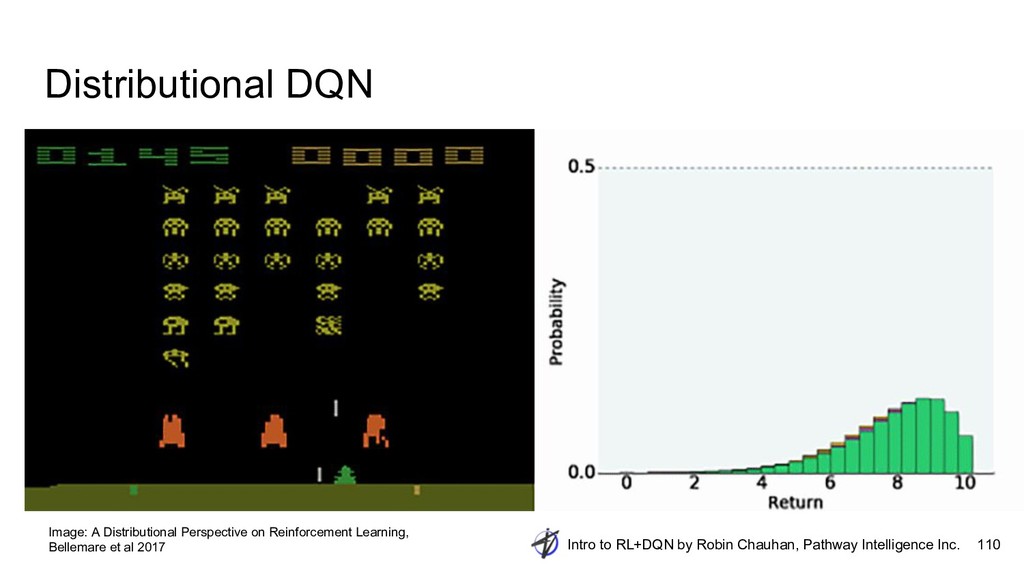{kind=link}
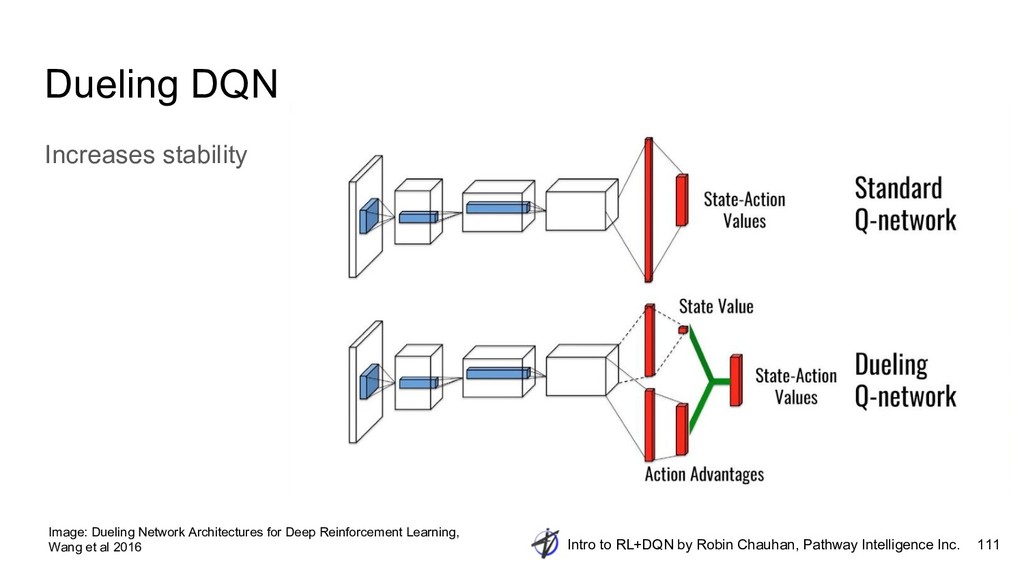{kind=link}
{kind=link}
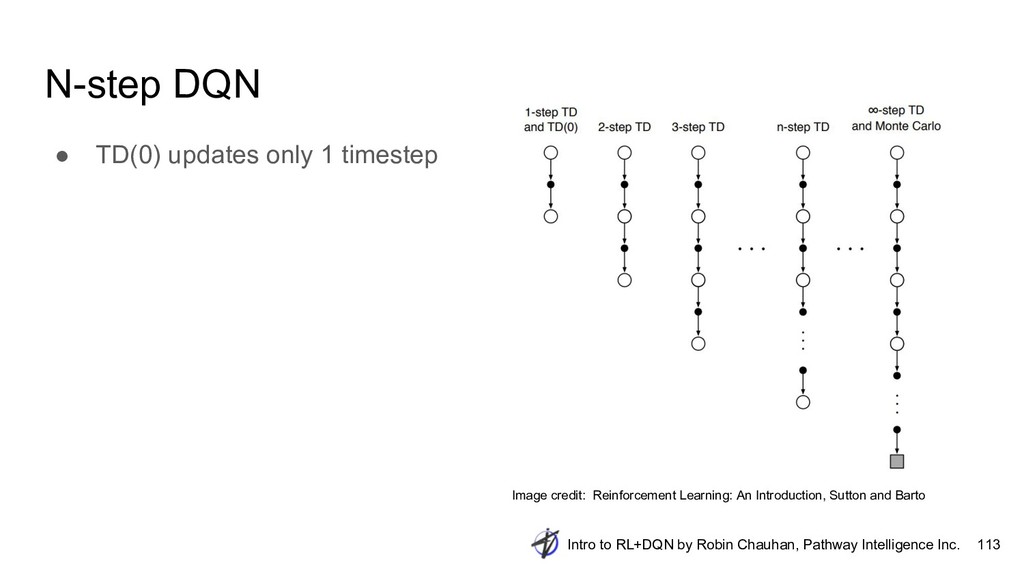{kind=link}
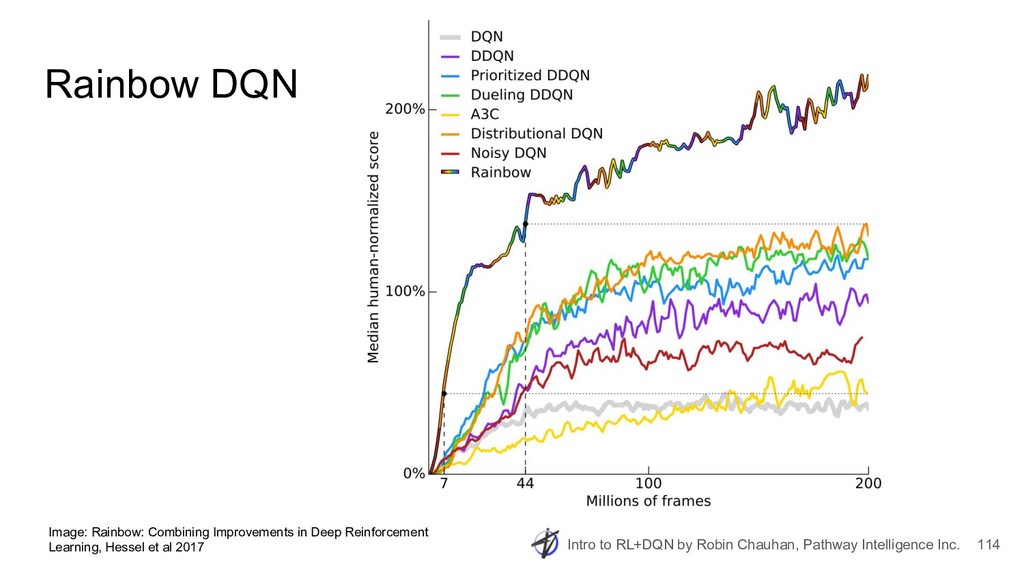{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Robin Ranjit Singh Chauhan [email protected] https://github.com/pathway https://ca.linkedin.com/in/robinc https://pathway.com/aiml](https://files.speakerdeck.com/presentations/5b99d11a967648e4a9fcad41c9dac1e1/slide_123.jpg){kind=link}
{kind=link}
{kind=link}