usaba filtros grandes y asim´ etricos (11x11, 5x5). GoogLeNet (2014): Introdujo m´ odulos complejos y manuales (Inception) para optimizar el c´ omputo. La Pregunta de VGG (2014): ¿Es posible mejorar la precisi´ on simplemente aumentando la profundidad utilizando una arquitectura extremadamente simple y uniforme? La Respuesta: VGGNet El Visual Geometry Group (Oxford) demostr´ o que la profundidad, combinada con filtros peque˜ nos y una secuencia cl´ asica repetitiva, es la clave del ´ exito. 3 / 13
diferencia de las arquitecturas con ”m´ odulos especiales”(como Inception), el paradigma cl´ asico de VGG se basa en la uniformidad estricta: 1 Filtros Peque˜ nos: Uso exclusivo de convoluciones 3x3 (y 1x1 en capas finales). 2 Secuencia Repetitiva: Bloques id´ enticos de (Conv 3x3 → ReLU → MaxPool). 3 Reducci´ on Progresiva: El tama˜ no espacial se reduce a la mitad (stride 2) mientras la profundidad (canales) se duplica (64 → 128 → 256 → 512). 4 Clasificador Est´ andar: Transici´ on de caracter´ ısticas a un clasificador de Capas Totalmente Conectadas (FC). 4 / 13
y equilibrada de la familia VGG. Desglose de las 16 Capas de Peso 13 Capas Convolucionales: Distribuidas en 5 bloques. Extraen caracter´ ısticas jer´ arquicas (bordes → texturas → objetos). 3 Capas Totalmente Conectadas (FC): FC1, FC2 y FC3. Mapean las caracter´ ısticas extra´ ıdas a las clases de salida. Caracter´ ısticas clave: Total de par´ ametros: ≈ 138 millones. Tama˜ no del modelo: ≈ 528 MB (en float32). 6 / 13
profunda dise˜ nada para evaluar el l´ ımite del paradigma de profundidad. Desglose de las 19 Capas de Peso 16 Capas Convolucionales: A˜ nade 3 capas convolucionales extra en los bloques m´ as profundos (bloques 3, 4 y 5) en comparaci´ on con VGG16. 3 Capas Totalmente Conectadas (FC): Id´ enticas a VGG16 (FC1, FC2, FC3). Caracter´ ısticas clave: Total de par´ ametros: ≈ 144 millones. Nota: A pesar de ser m´ as profunda, la mejora en precisi´ on respecto a VGG16 es marginal, pero el coste computacional aumenta. 7 / 13
3x3 es el pilar fundamental del paradigma de secuencia cl´ asico. 1. Campo Receptivo Equivalente Dos capas 3x3 apiladas = Campo receptivo de un filtro 5x5. Tres capas 3x3 apiladas = Campo receptivo de un filtro 7x7. 2. Menos Par´ ametros Un filtro 7x7 tiene 49 par´ ametros. Tres filtros 3x3 tienen 3 × 9 = 27 par´ ametros. Reducci´ on del 45 % en par´ ametros. 3. M´ as No-Linealidad Al usar tres capas 3x3 en lugar de una 7x7, se aplican tres funciones de activaci´ on ReLU en lugar de una. Esto hace que la funci´ on de decisi´ on sea m´ as discriminativa y mejore el aprendizaje. 8 / 13
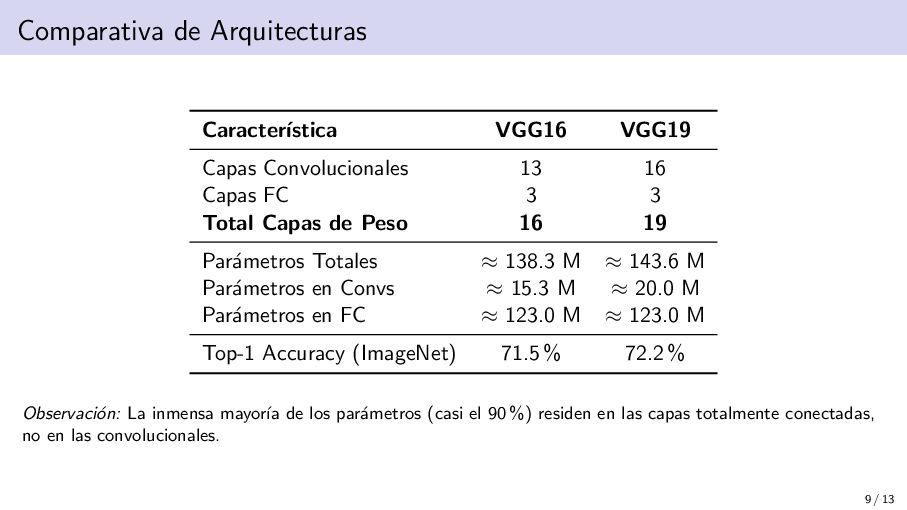
16 Capas FC 3 3 Total Capas de Peso 16 19 Par´ ametros Totales ≈ 138.3 M ≈ 143.6 M Par´ ametros en Convs ≈ 15.3 M ≈ 20.0 M Par´ ametros en FC ≈ 123.0 M ≈ 123.0 M Top-1 Accuracy (ImageNet) 71.5 % 72.2 % Observaci´ on: La inmensa mayor´ ıa de los par´ ametros (casi el 90 %) residen en las capas totalmente conectadas, no en las convolucionales. 9 / 13
y depurar. Extractor de Caracter´ ısticas: Excelente para tareas de visi´ on por computadora (detecci´ on, segmentaci´ on). Transfer Learning: Sus pesos preentrenados son un est´ andar de oro para inicializar otras redes. Desventajas Peso Masivo: Requiere mucha memoria RAM/VRAM. Inferencia Lenta: Alto coste computacional en producci´ on. Desvanecimiento del Gradiente: Al ser muy profunda sin conexiones residuales, sufre en el entrenamiento desde cero. 10 / 13
Profundidad: VGG demostr´ o que ”m´ as profundo es mejor”(hasta cierto punto), cambiando el foco de la comunidad desde el dise˜ no de m´ odulos complejos hacia el aumento de profundidad. El Puente hacia ResNet: Los problemas de desvanecimiento del gradiente en VGG19 motivaron directamente la creaci´ on de las Skip Connections (Conexiones Residuales) en ResNet (2015). Uso Actual: Aunque ha sido superada en eficiencia, VGG16 sigue siendo ampliamente utilizada como backbone en modelos de estilo art´ ıstico (Neural Style Transfer) y como extractor de caracter´ ısticas en modelos de dos etapas. 11 / 13
prioriza la simplicidad, la uniformidad y la profundidad mediante filtros peque˜ nos (3x3). 2 VGG16 (16 capas de peso) ofrece el mejor equilibrio entre precisi´ on y coste computacional, convirti´ endose en un est´ andar de la industria. 3 VGG19 (19 capas de peso) explora los l´ ımites de la profundidad, demostrando mejoras marginales a costa de mayor complejidad. 4 La innovaci´ on de los filtros 3x3 apilados redujo par´ ametros y aument´ o la no-linealidad, sentando las bases para las CNNs modernas. 12 / 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}