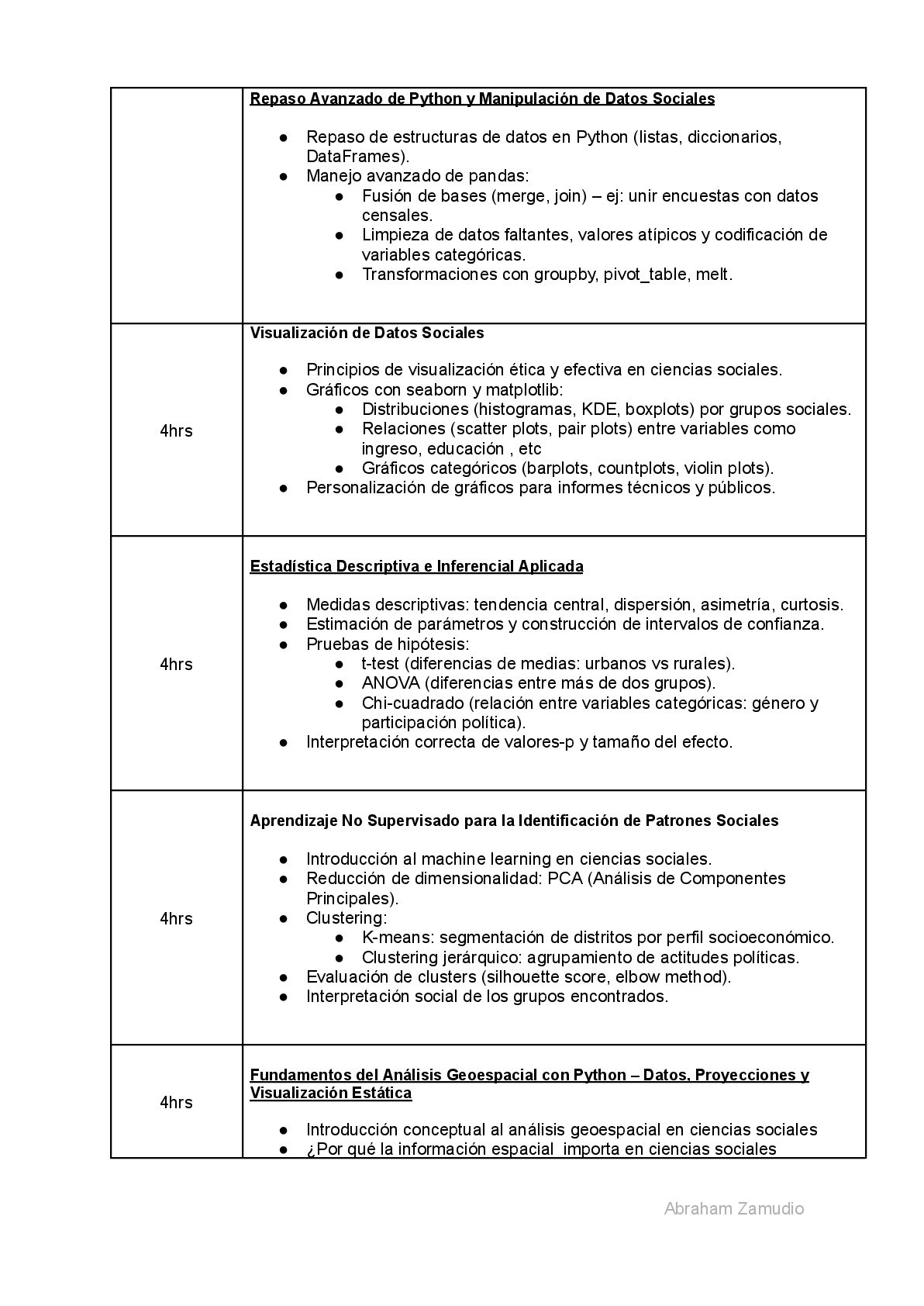
a un nivel profesional, aplicado específicamente a problemas sociales, políticos y culturales. La estructura del curso, dividido en clases de cuatro horas cada una, está diseñada para ser progresiva, práctica y contextualizada. Cada sesión no solo enseña una herramienta técnica, sino que la vincula con un caso de estudio real planteado por el profesor, una pregunta de investigación social o un desafío de política pública. El enfoque es proyect-based learning (PBL), lo que significa que los participantes no solo aprenden haciendo, sino que construyen un portafolio de análisis aplicados que pueden utilizar en su vida profesional. Este curso, por lo tanto, no solo responde a una necesidad técnica, sino a una necesidad estratégica del campo de las ciencias sociales. En un contexto donde los gobiernos, las empresas y las organizaciones internacionales toman decisiones basadas en datos, es fundamental que los profesionales de las ciencias sociales no queden al margen. No se trata de adoptar ciegamente las herramientas que provee el ecosistema de Python, sino de apropiarse críticamente de las oportunidades que genera este conocimiento tecnico, usando su poder analítico para visibilizar injusticias, evaluar políticas y fortalecer la democracia. Además, el curso está alineado con las tendencias globales en investigación social. Organismos como el World Bank, UNDP, OECD y Latinobarómetro ya publican sus datos en formatos abiertos y estructurados, muchos de ellos accesibles mediante APIs. La capacidad de acceder, procesar y analizar estos datos en tiempo real es una ventaja competitiva para cualquier investigador o gestor público. Como bien se mostró en el primer curso el uso de Python, como lenguaje abierto, gratuito y de código abierto, también promueve la reproducibilidad y la transparencia científica, dos pilares del método científico que son especialmente relevantes en un contexto de desinformación y polarización. Un análisis hecho en Google Colab puede ser compartido, revisado y replicado por otros, fortaleciendo así la credibilidad del conocimiento social. En resumen, este curso no es un simple entrenamiento en programación. Es una propuesta de modernización del campo de las ciencias sociales, que busca equipar a sus profesionales con las herramientas del siglo XXI, sin sacrificar su compromiso ético, crítico y transformador. Es un llamado a no temer a los datos, sino a dominarlos, interpretarlos y usarlos para construir sociedades más justas, equitativas y democráticas. Los egresados y profesionales de las ciencias sociales no deben limitarse a interpretar el mundo; deben tener las herramientas para transformarlo con evidencia. Y para transformarlo con evidencia, necesitan dominar el lenguaje de los datos : LA MATEMÁTICA. Este curso es un paso decisivo en esa dirección. 3.Objetivo general del curso Capacitar a profesionales de ciencias sociales en el uso avanzado de Python para la exploración, análisis y visualización de datos sociales, integrando técnicas de estadística descriptiva, inferencial, aprendizaje automático, con el fin de fortalecer su capacidad crítica, analítica e interventora en contextos públicos, académicos y sociales. Abraham Zamudio
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}