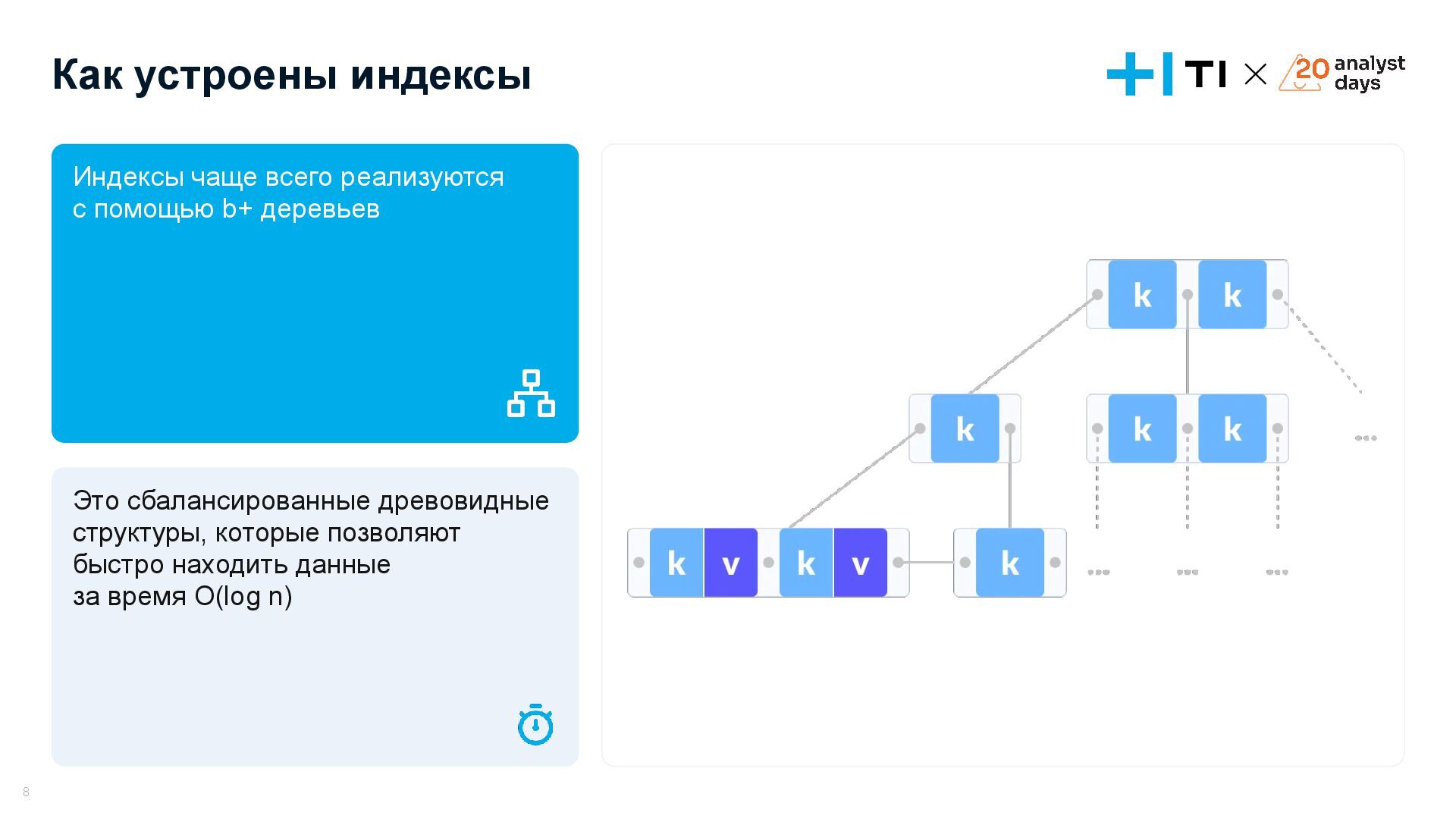
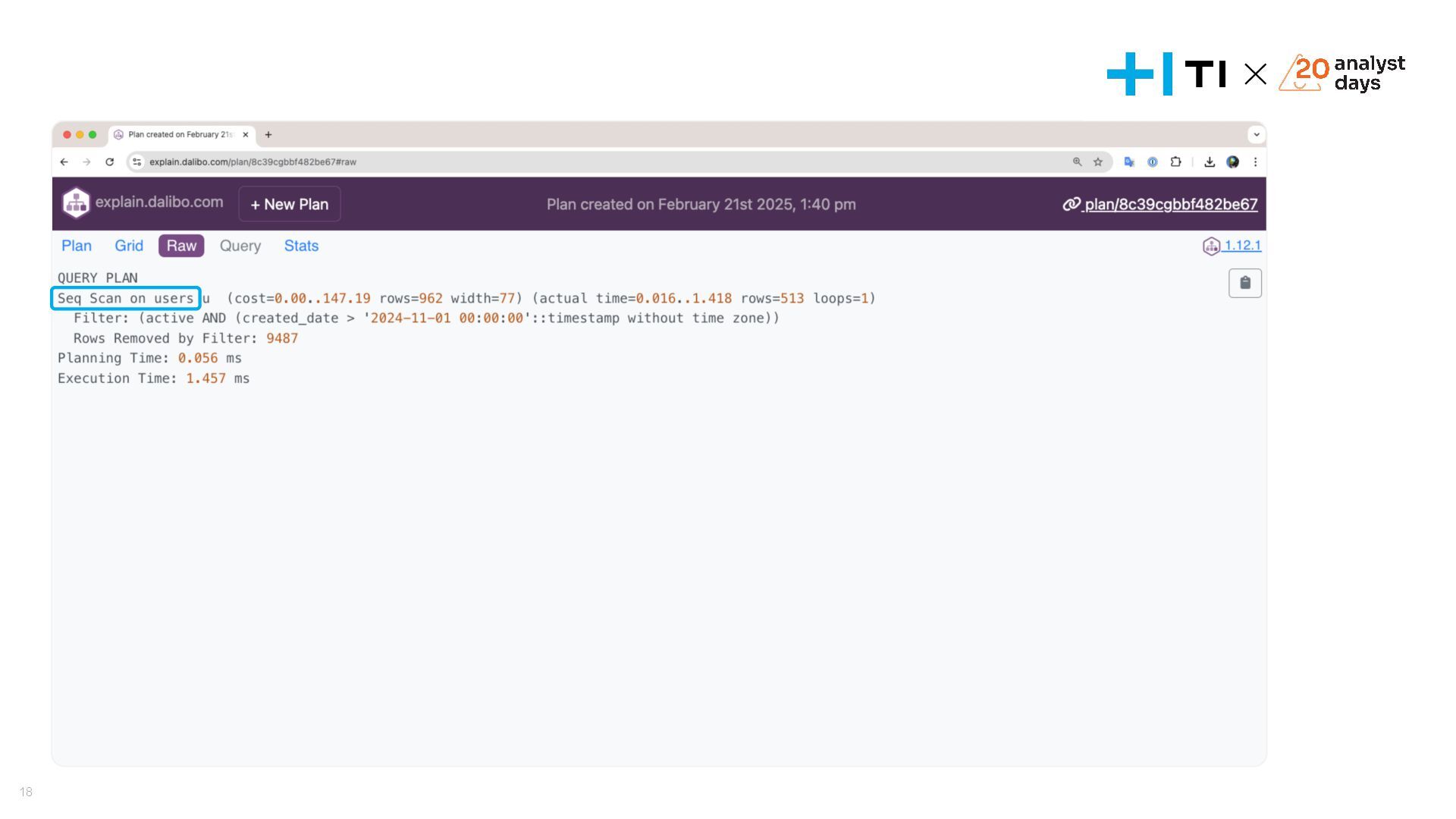
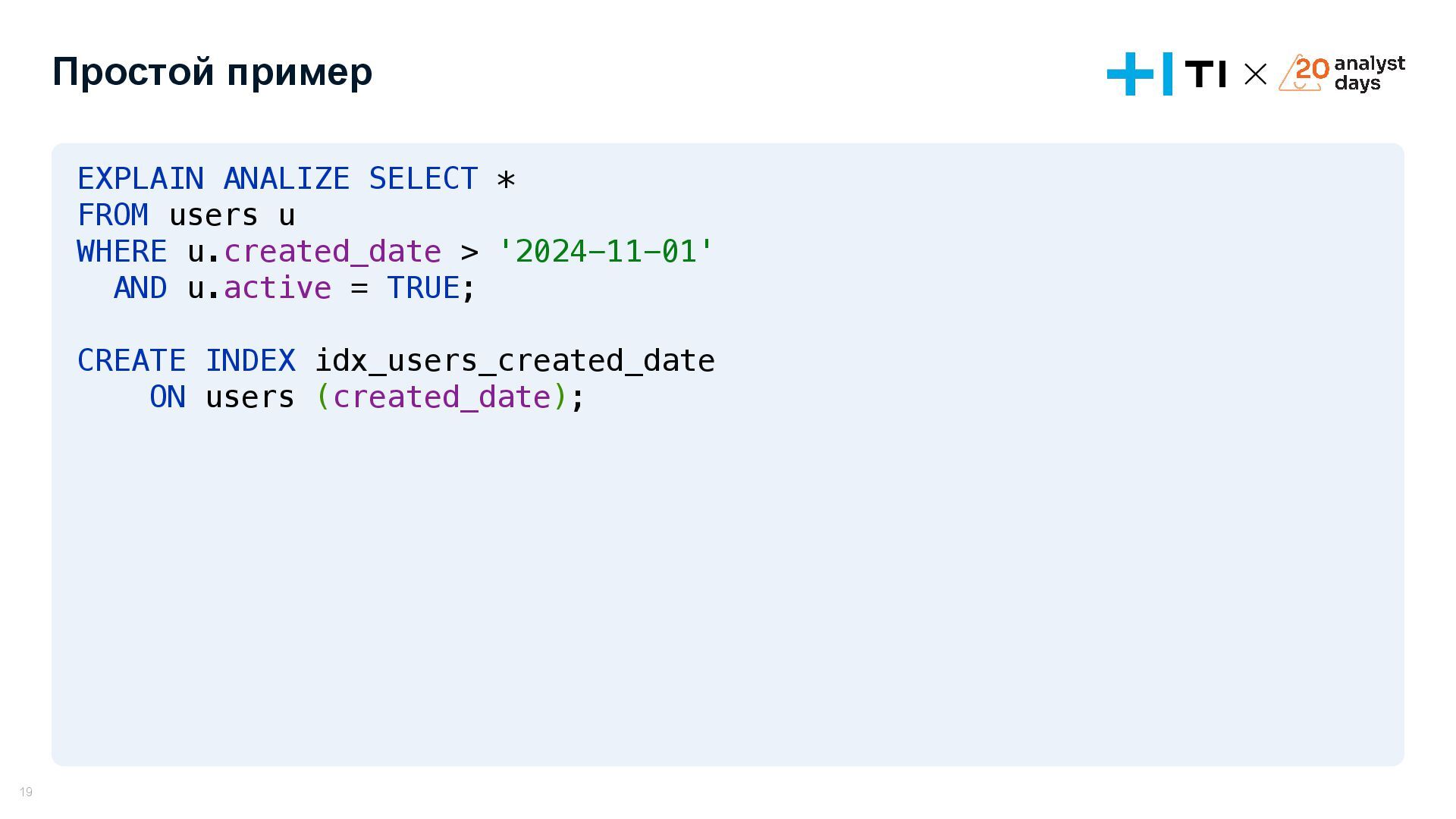
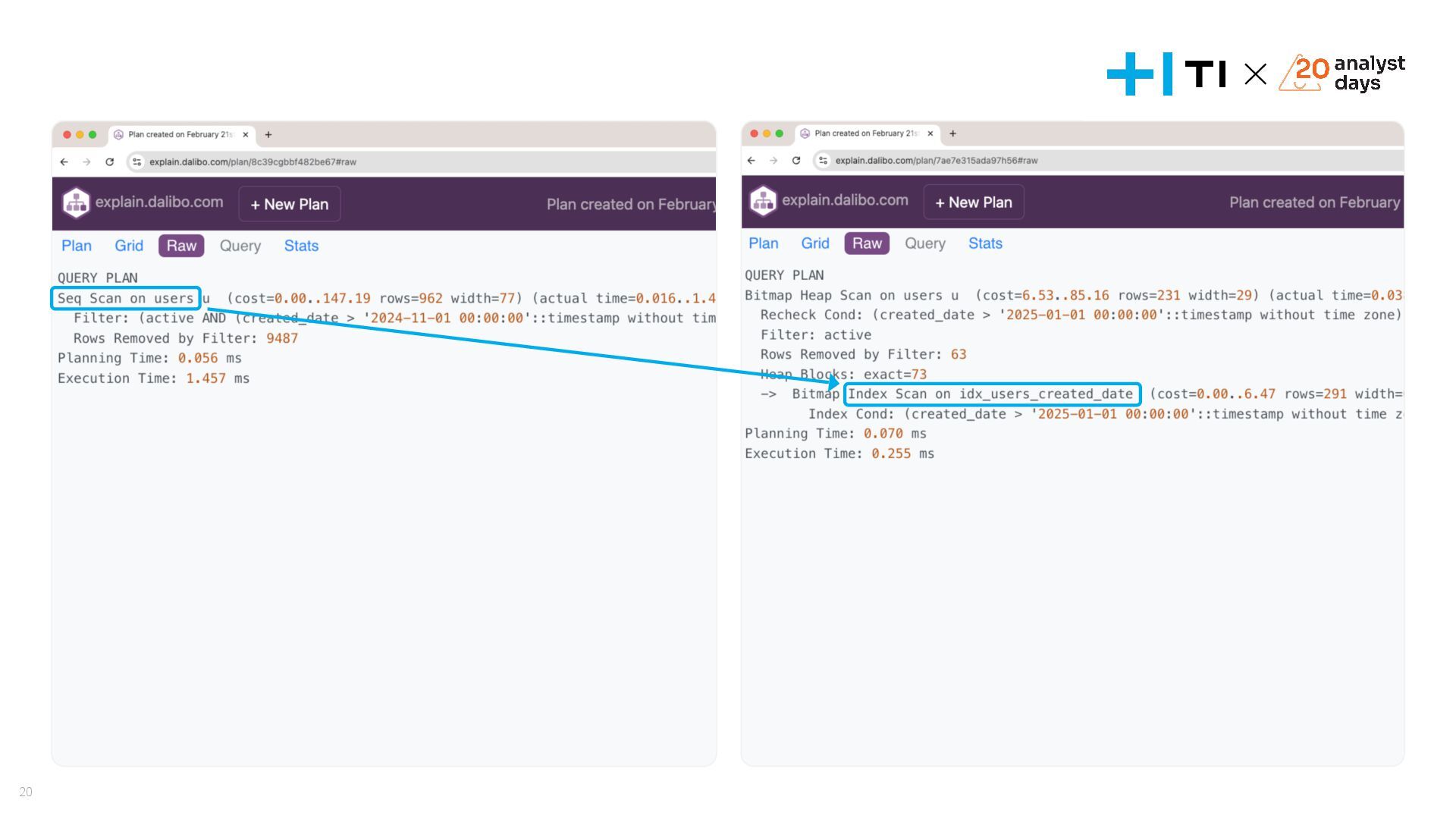
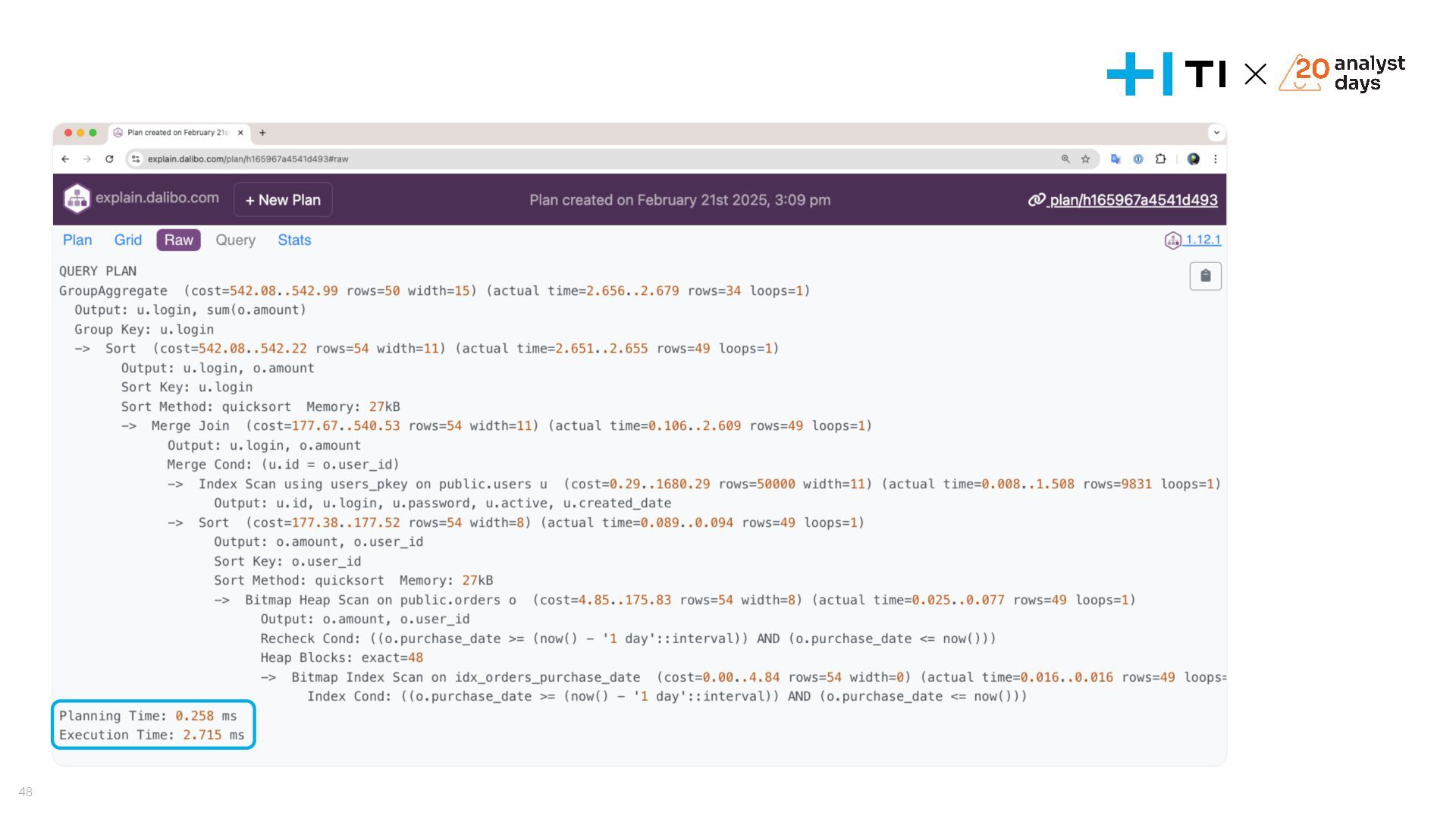
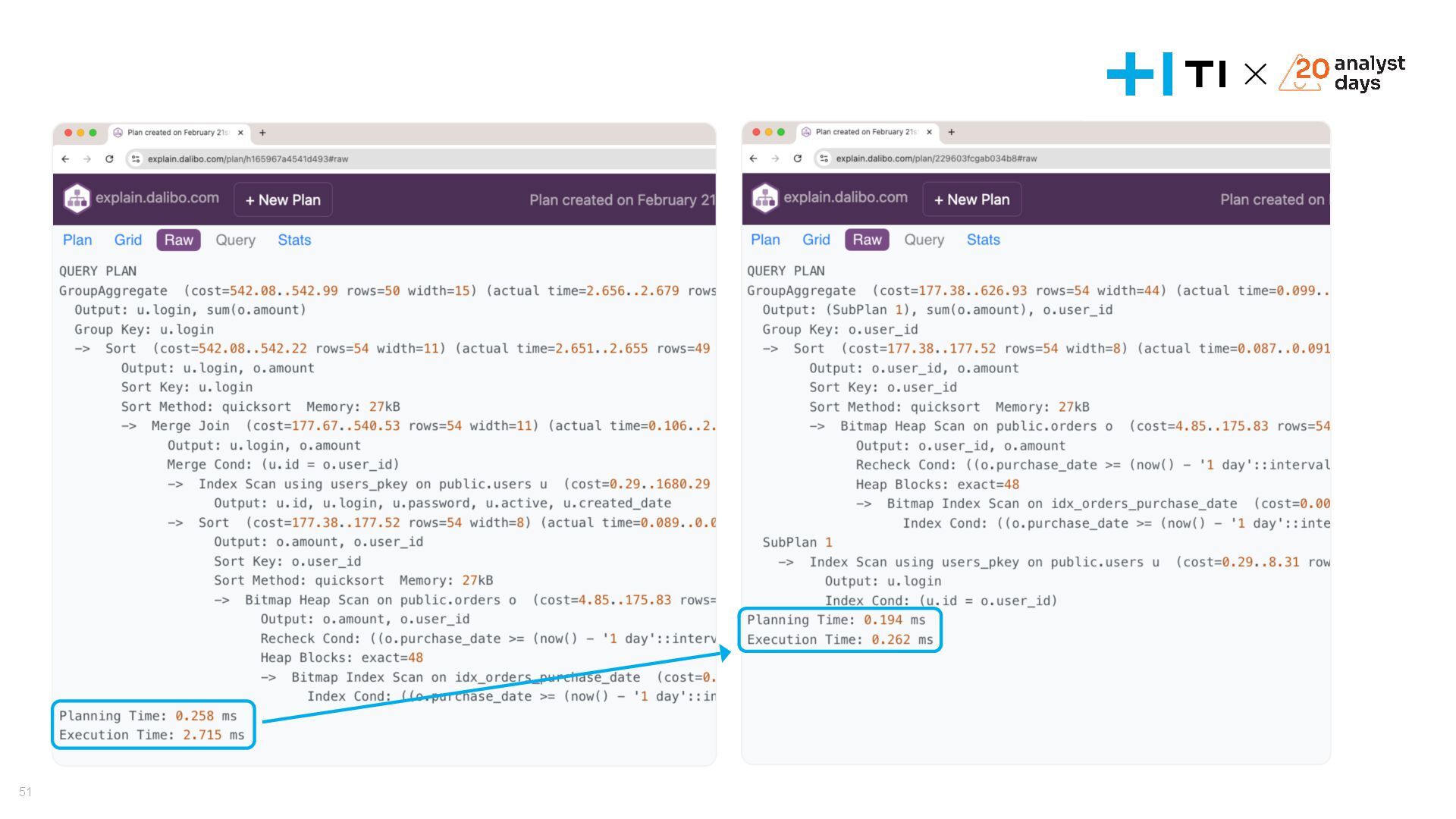
Доклад посвящен оптимизации запросов в базах данных и эффективному использованию индексов. Мы разберем, что делать, если запросы начинают тормозить, научимся анализировать планы выполнения запросов с помощью команд EXPLAIN и EXPLAIN ANALYZE, и выясним, как индексы влияют на производительность. На простых и сложных примерах рассмотрим, как улучшить работу запросов, понять селективность индексов и избежать ошибок, ухудшающих производительность. В завершении обсудим, когда действительно стоит использовать индексы и как они могут стать вашим инструментом для оптимизации.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
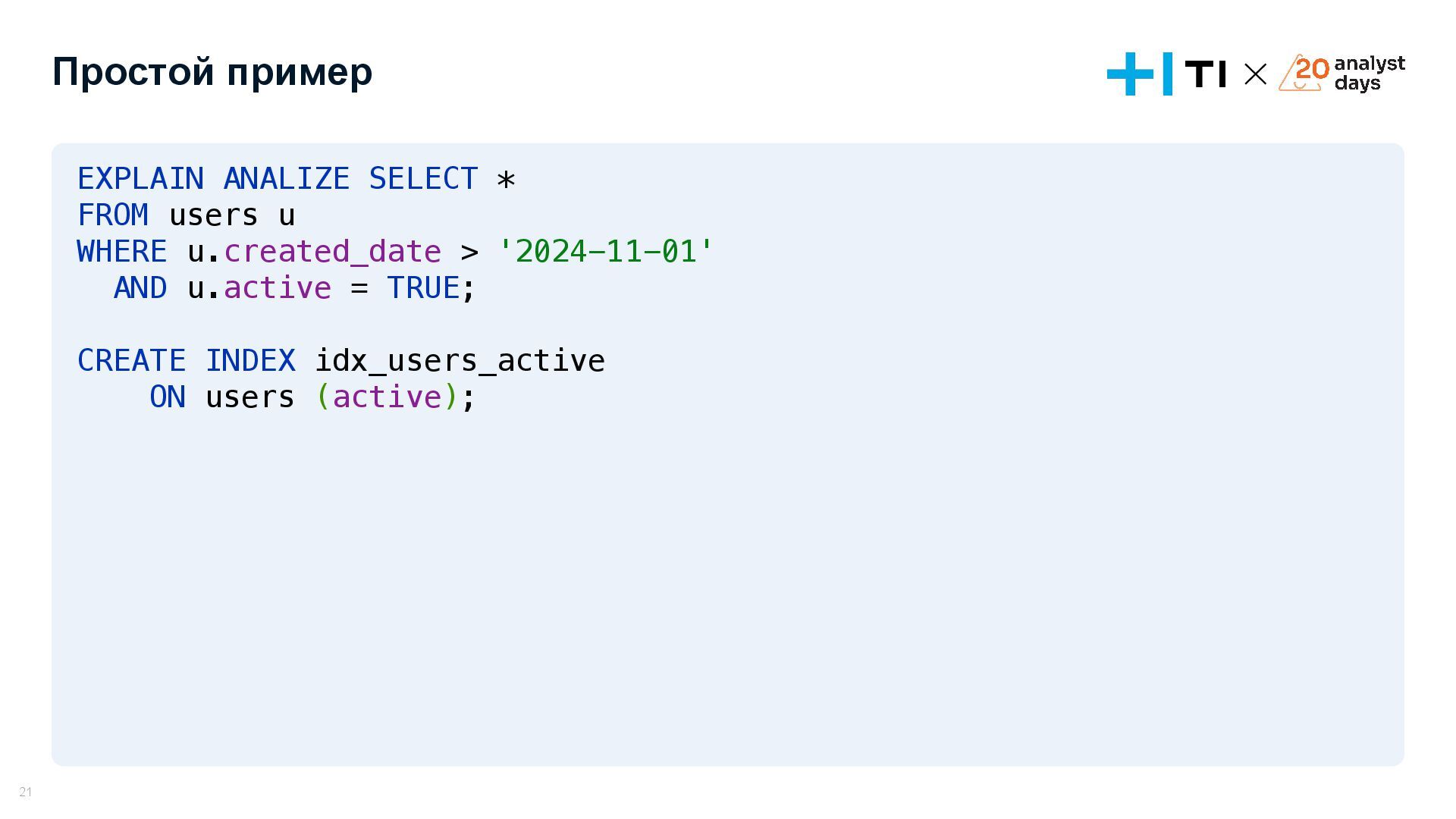{kind=link}
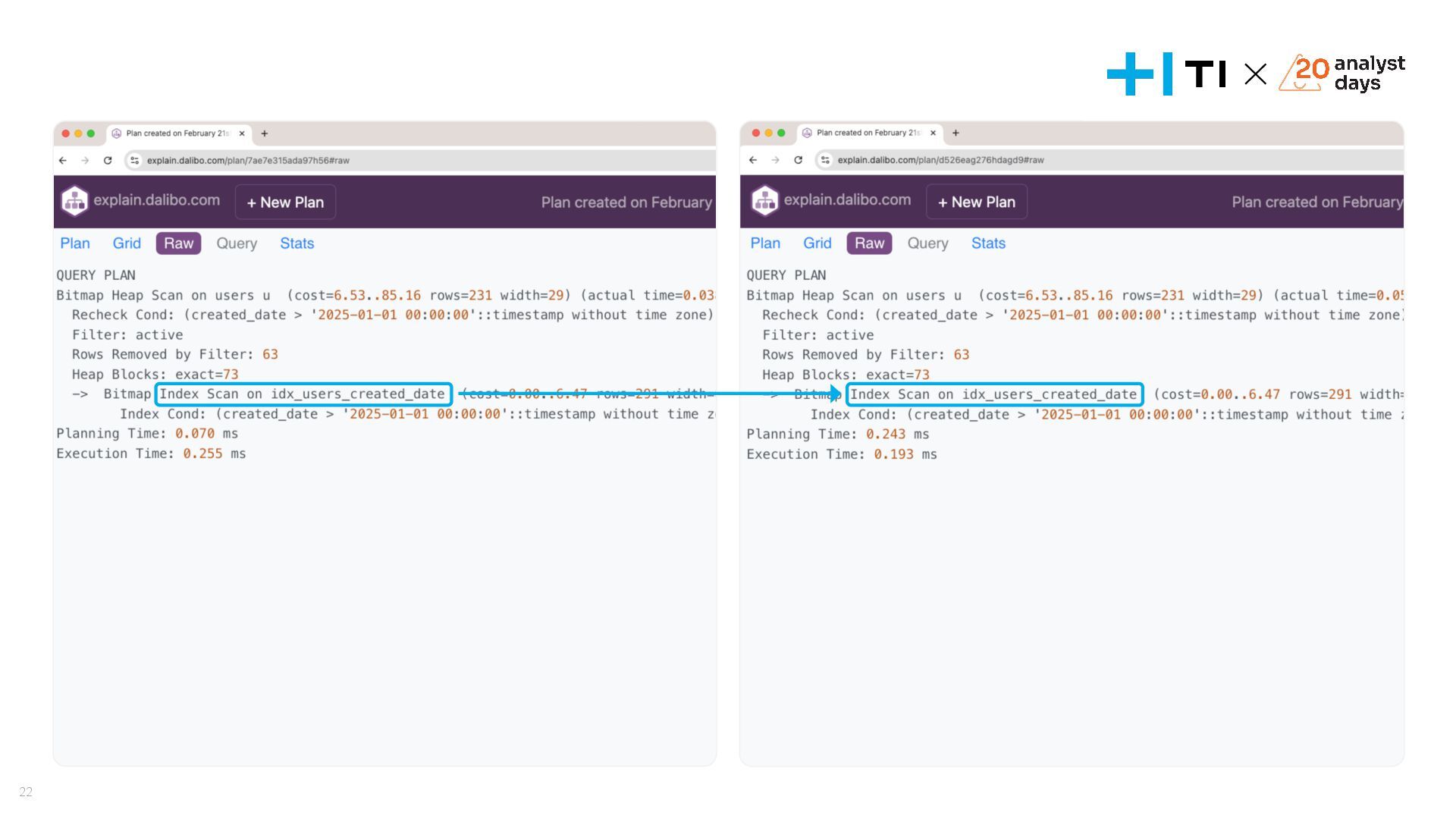{kind=link}
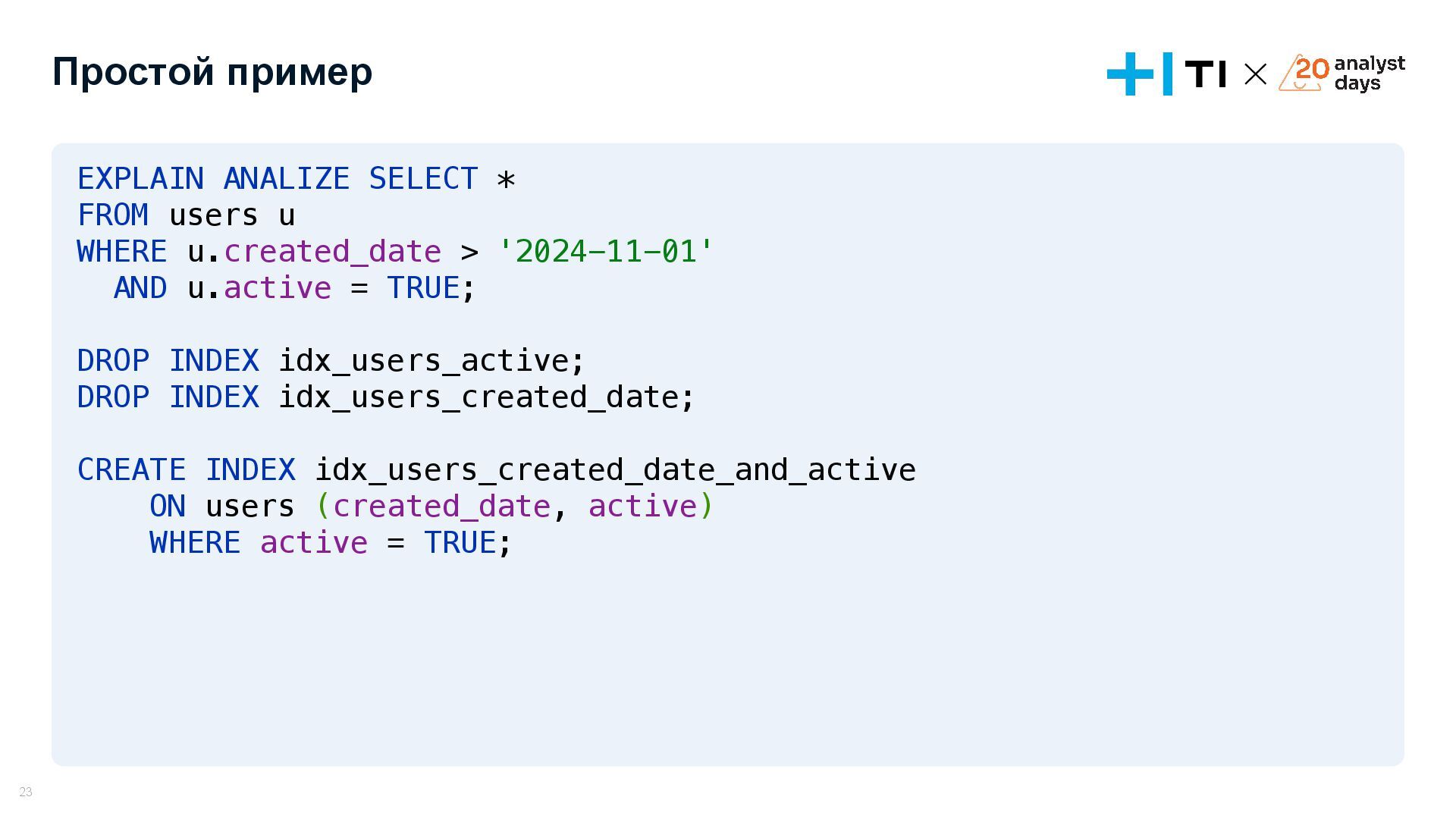{kind=link}
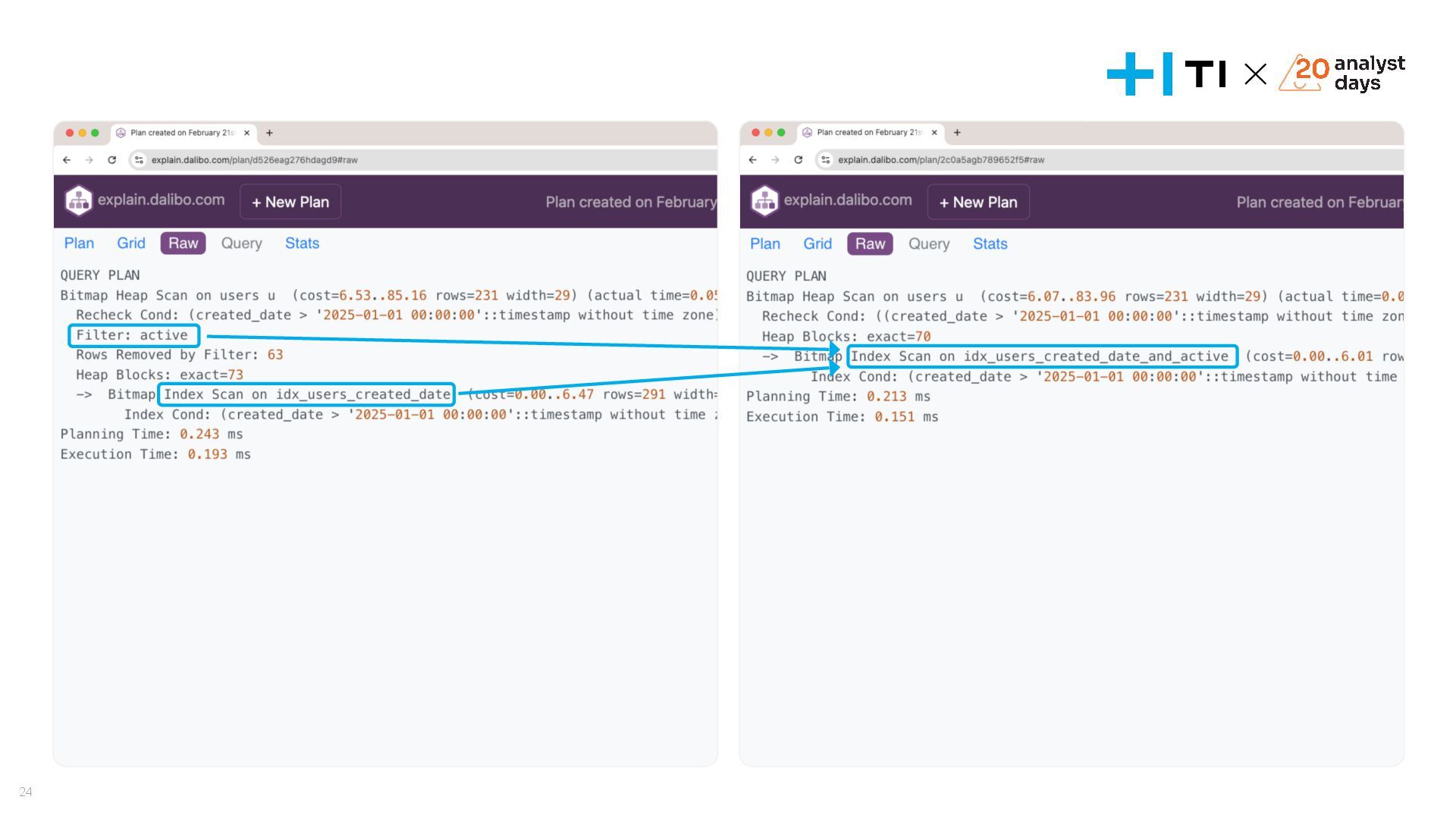{kind=link}
{kind=link}
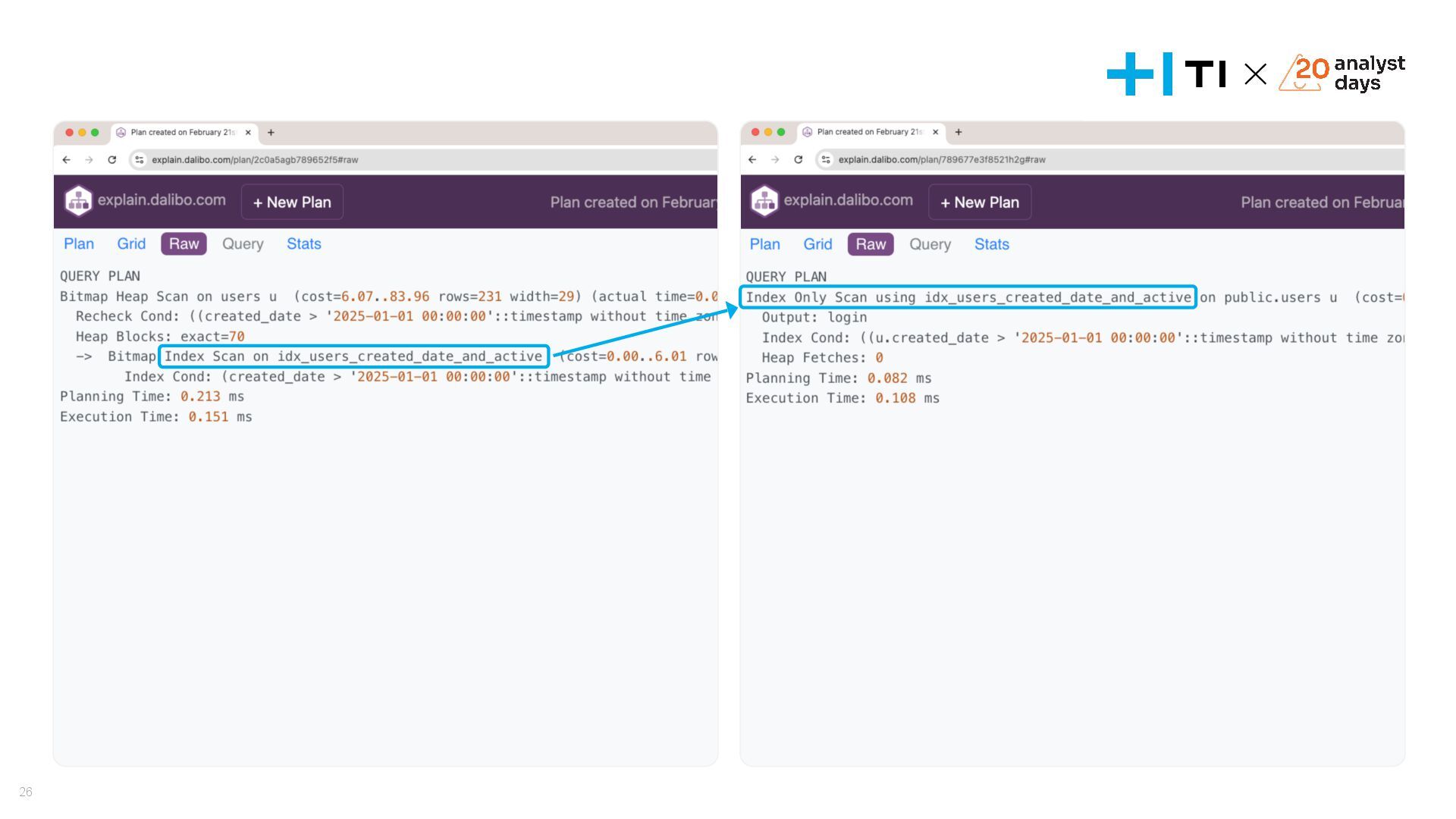{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
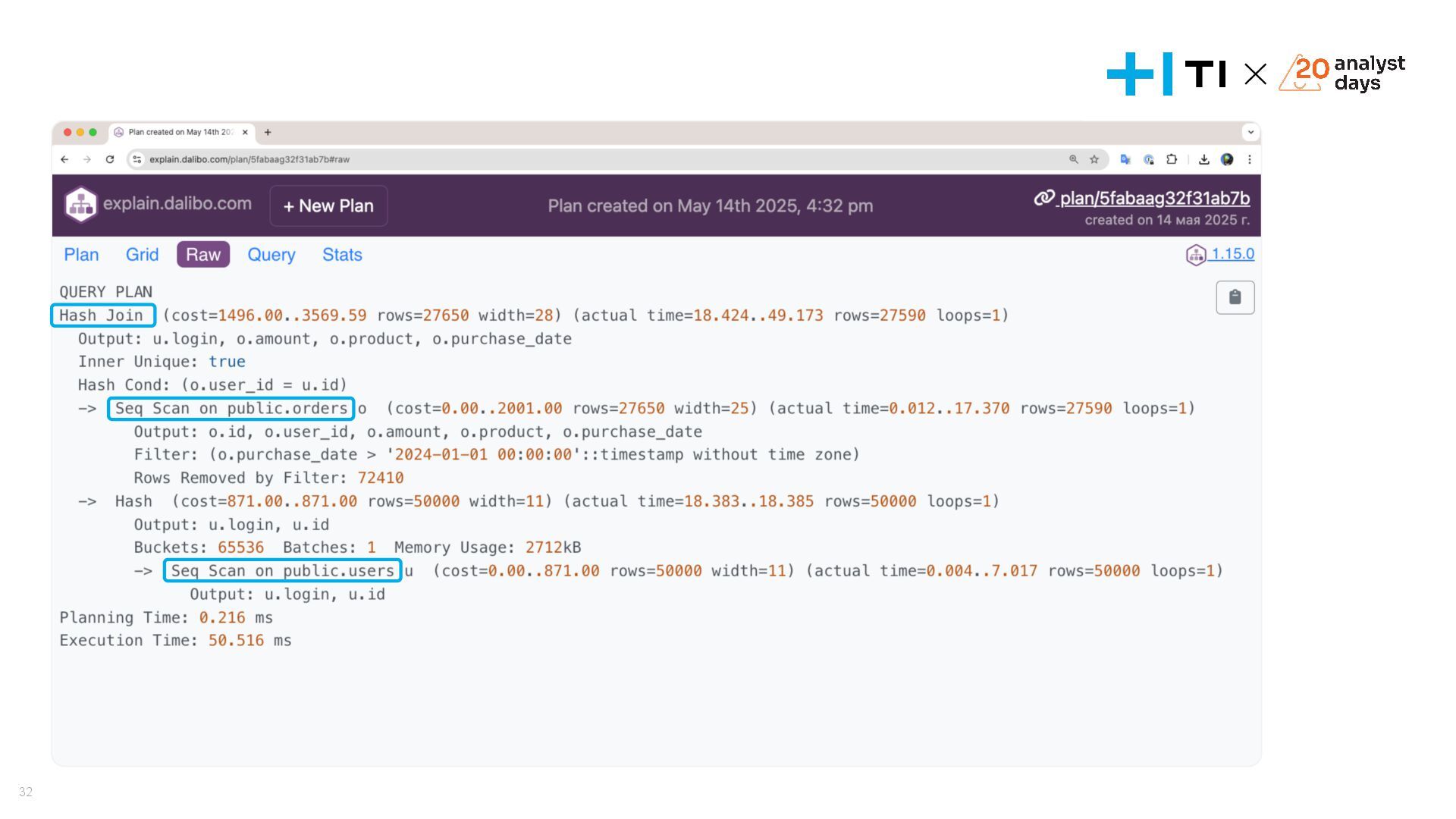{kind=link}
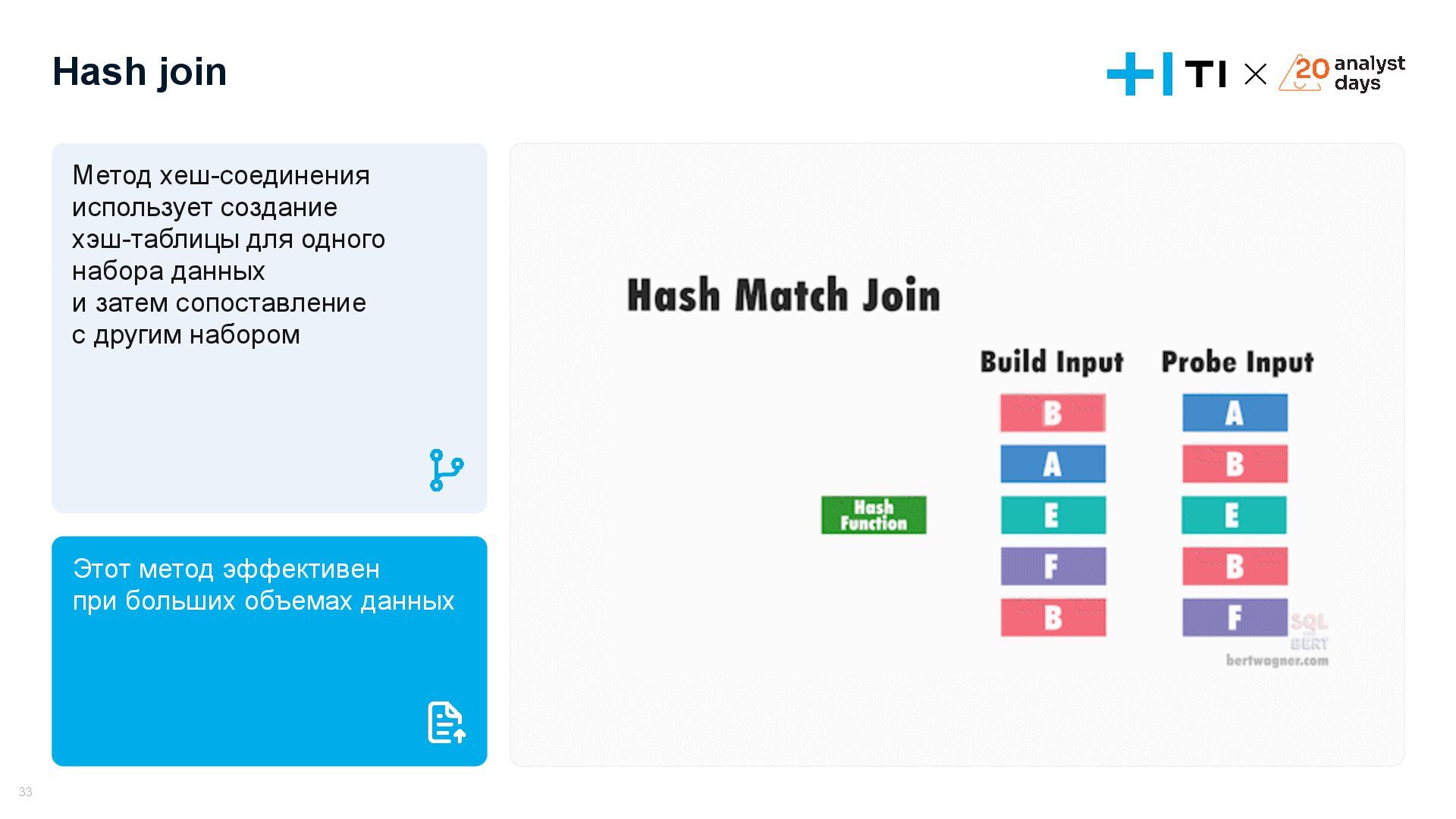{kind=link}
{kind=link}
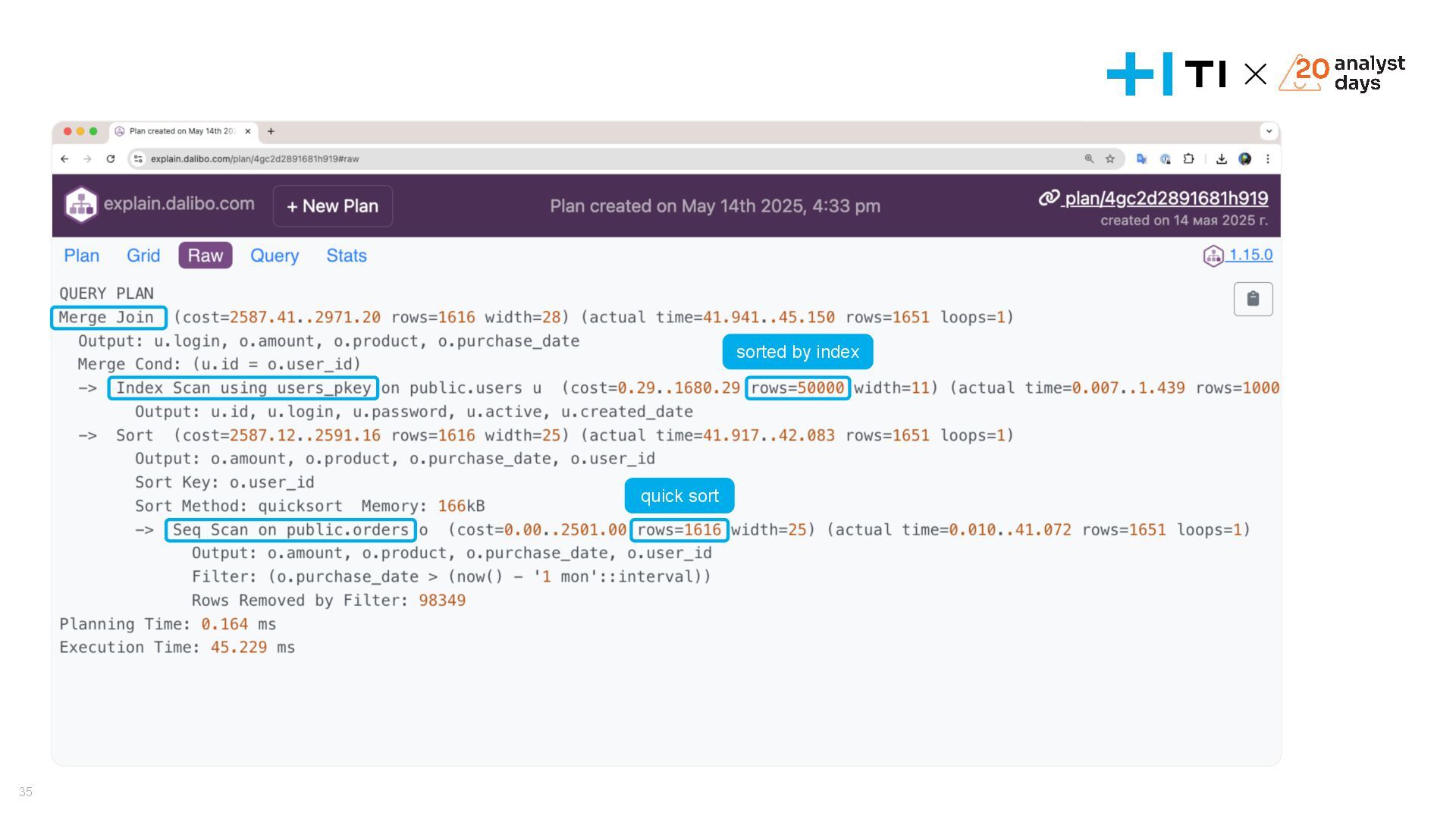{kind=link}
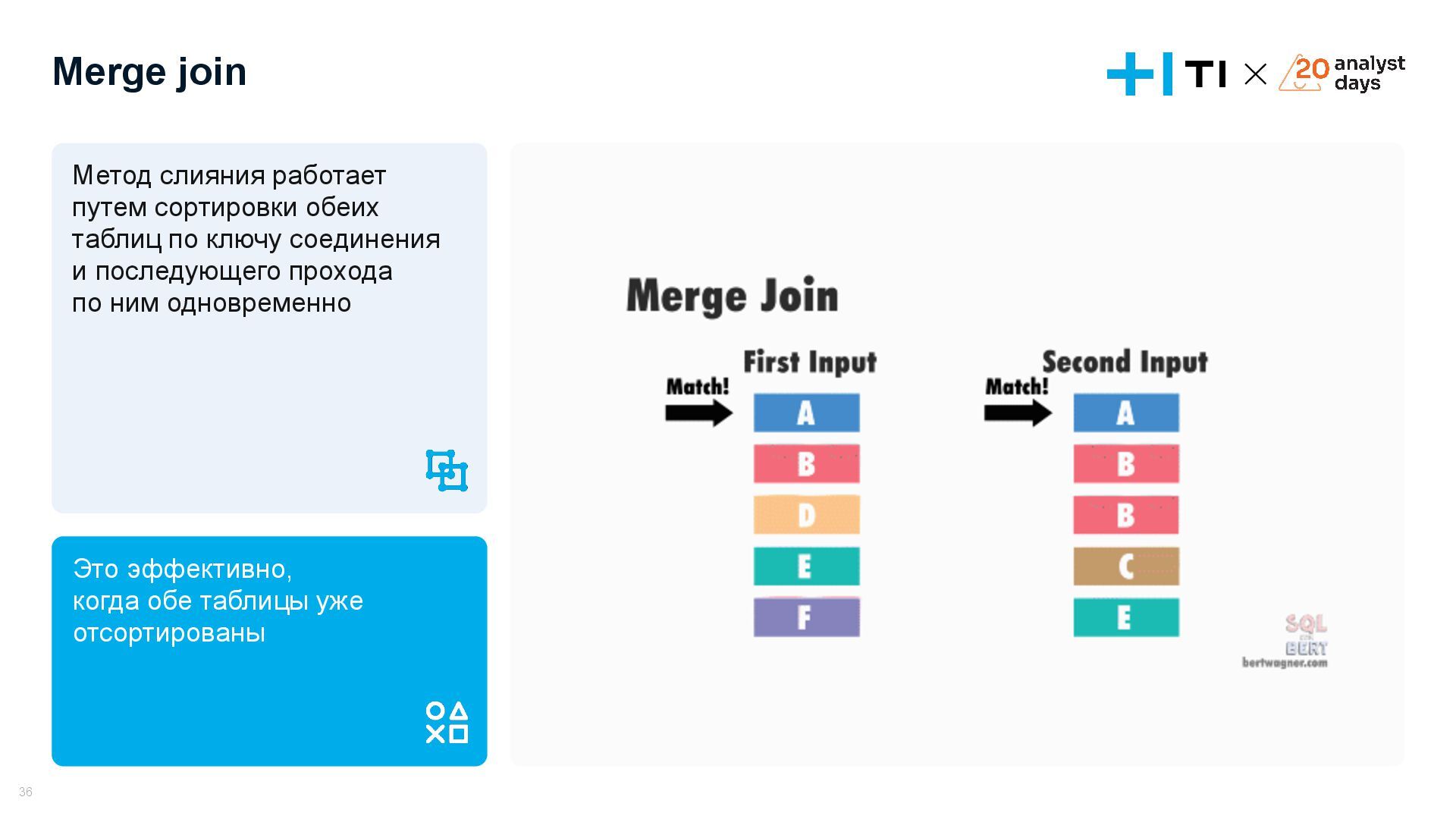{kind=link}
{kind=link}
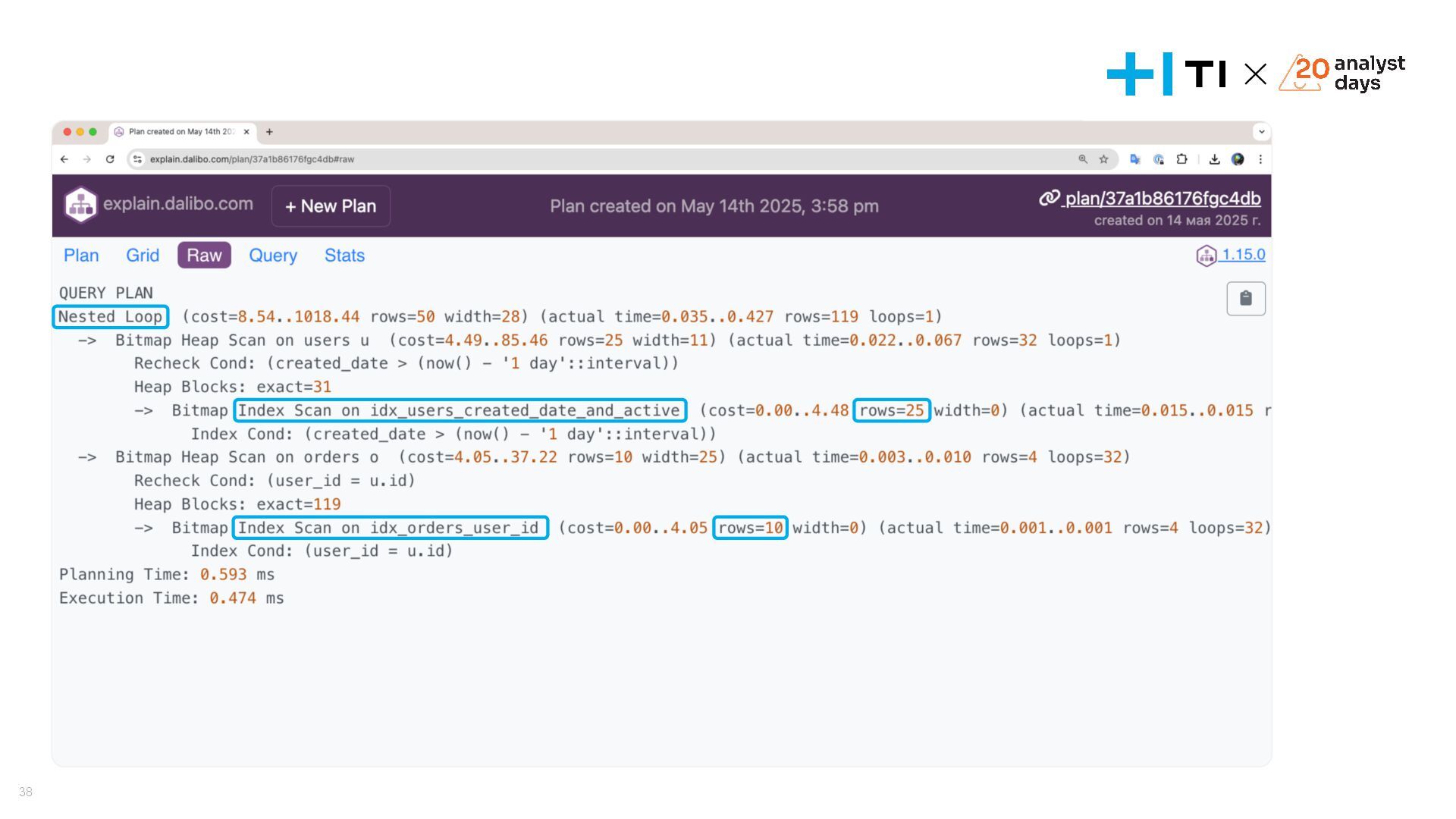{kind=link}
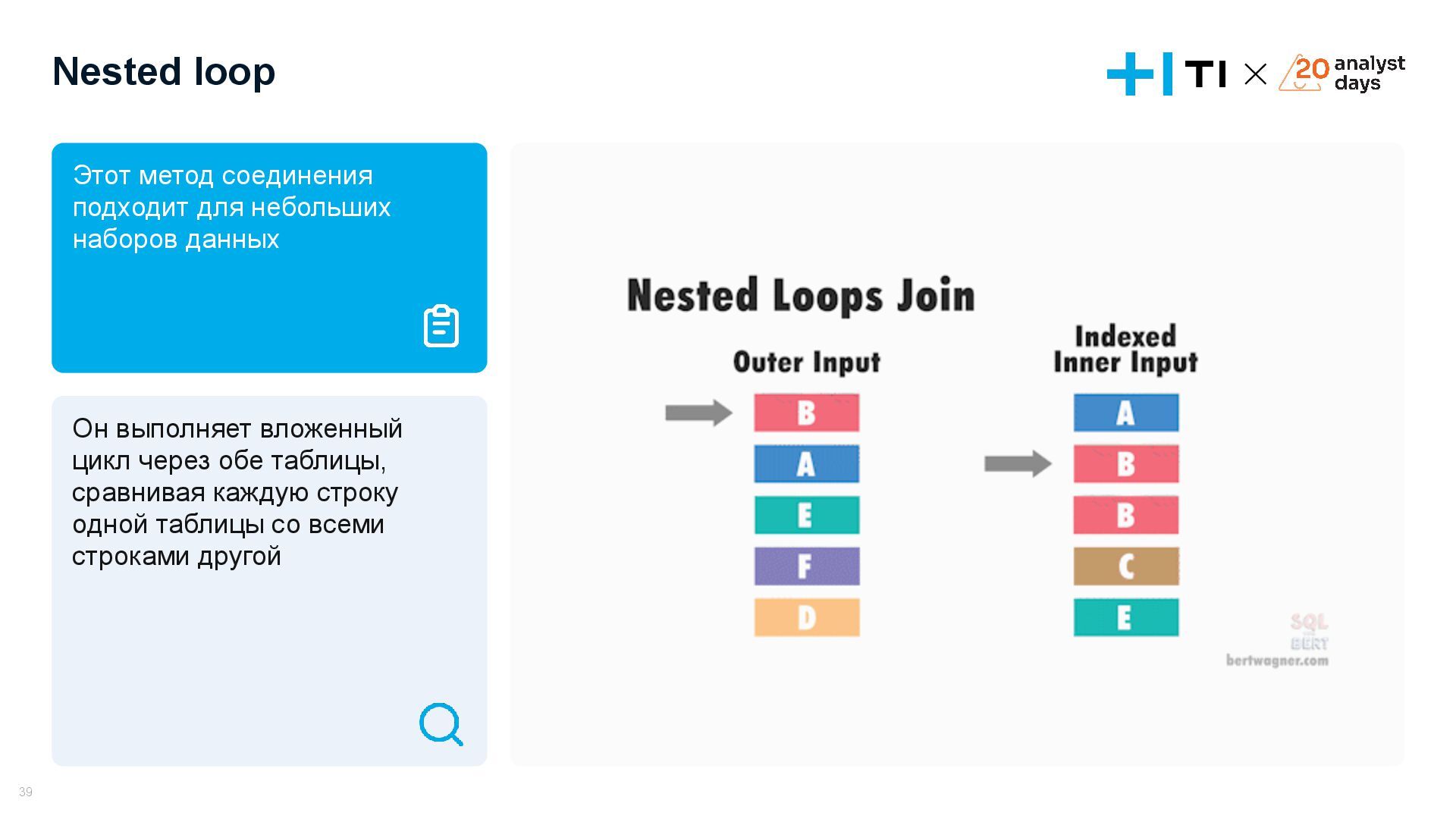{kind=link}
{kind=link}
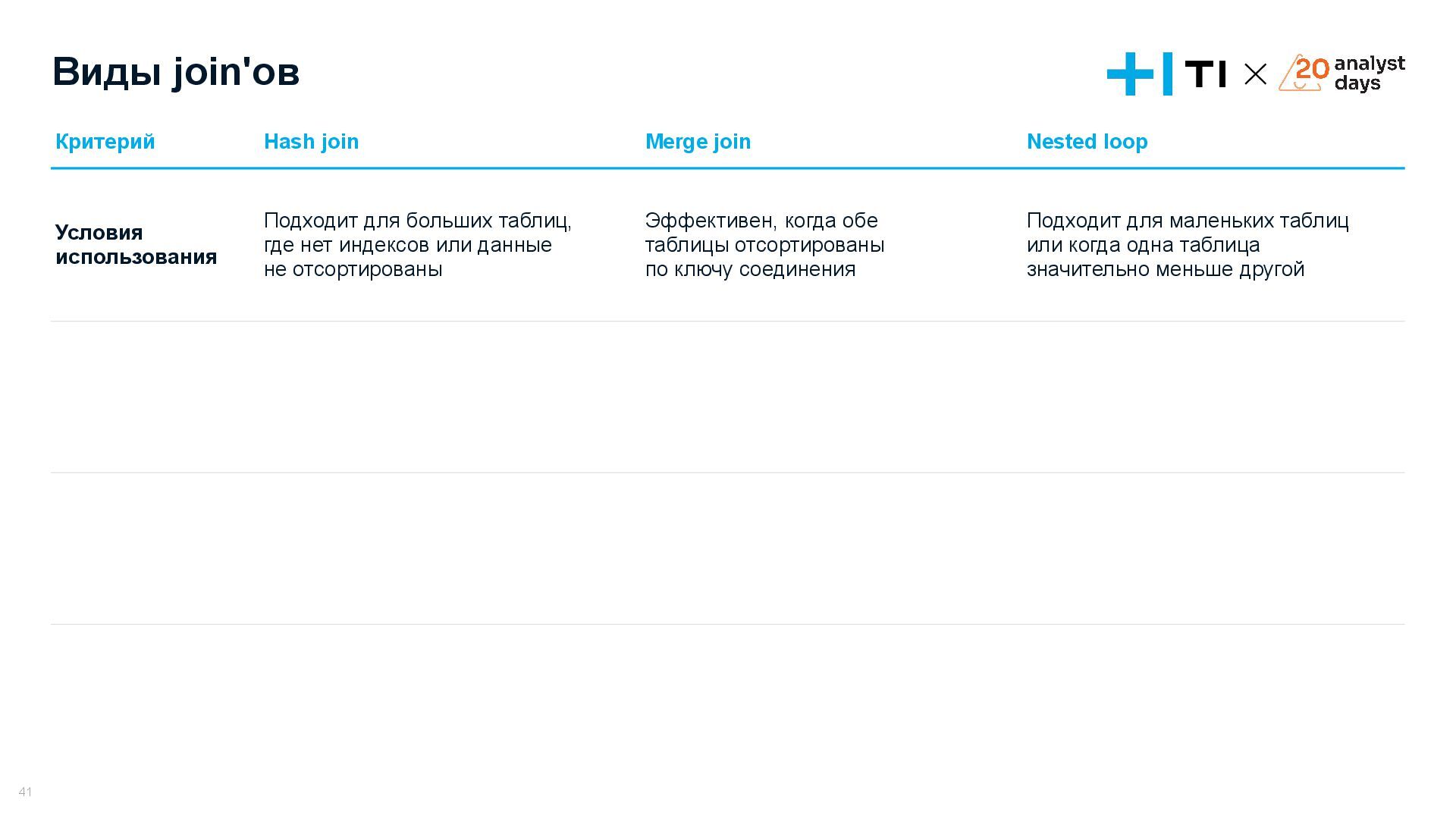{kind=link}
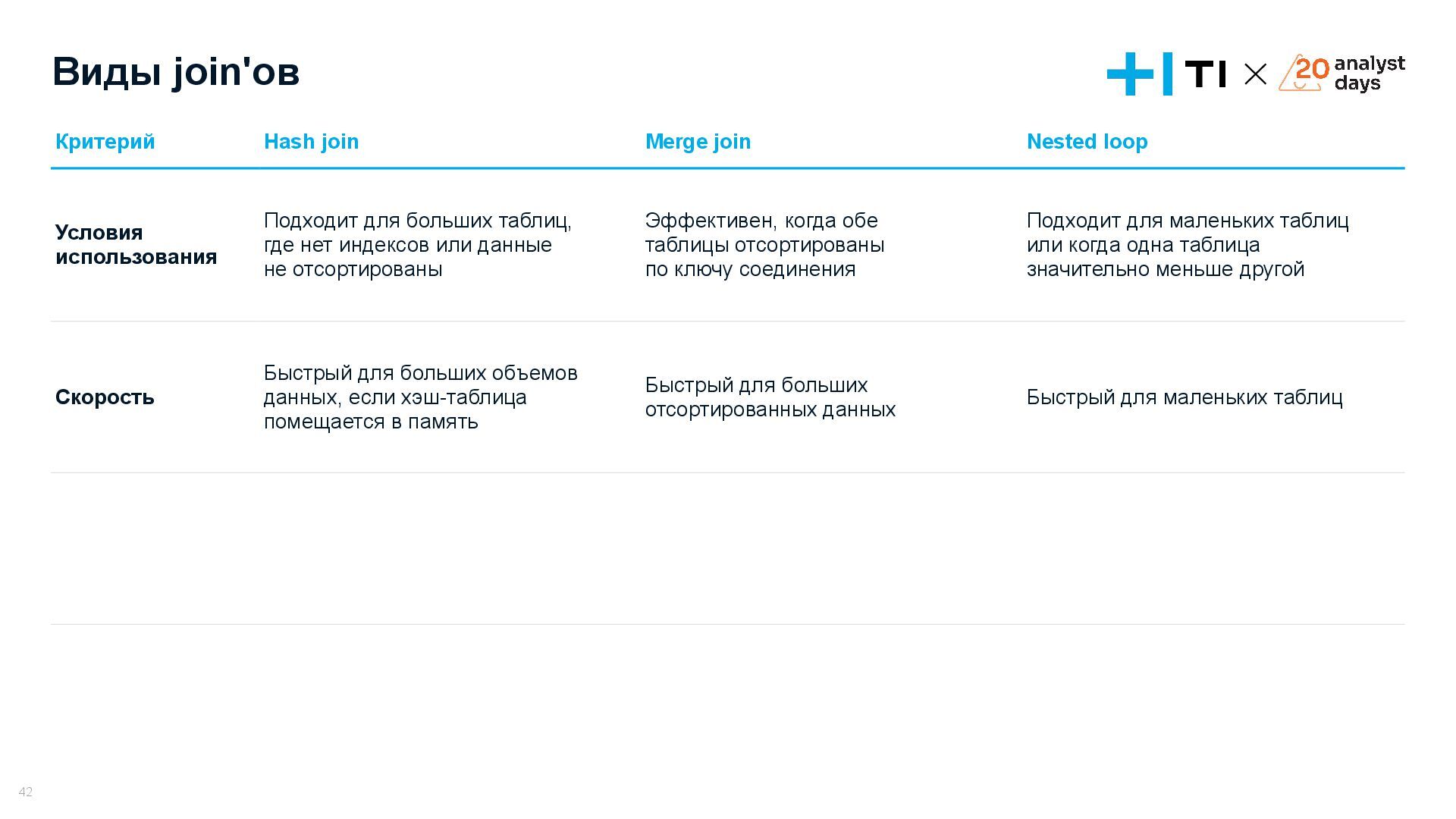{kind=link}
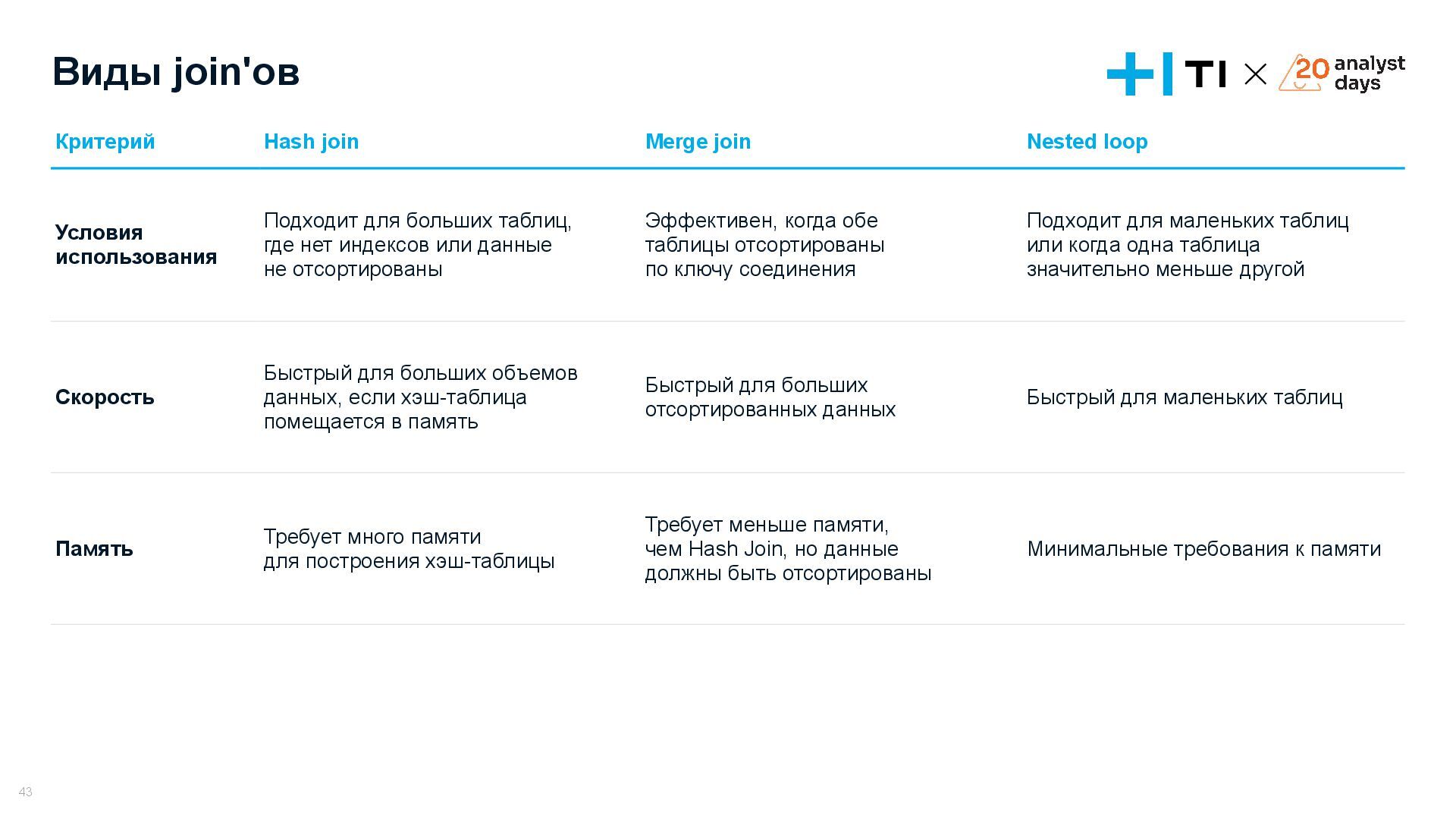{kind=link}
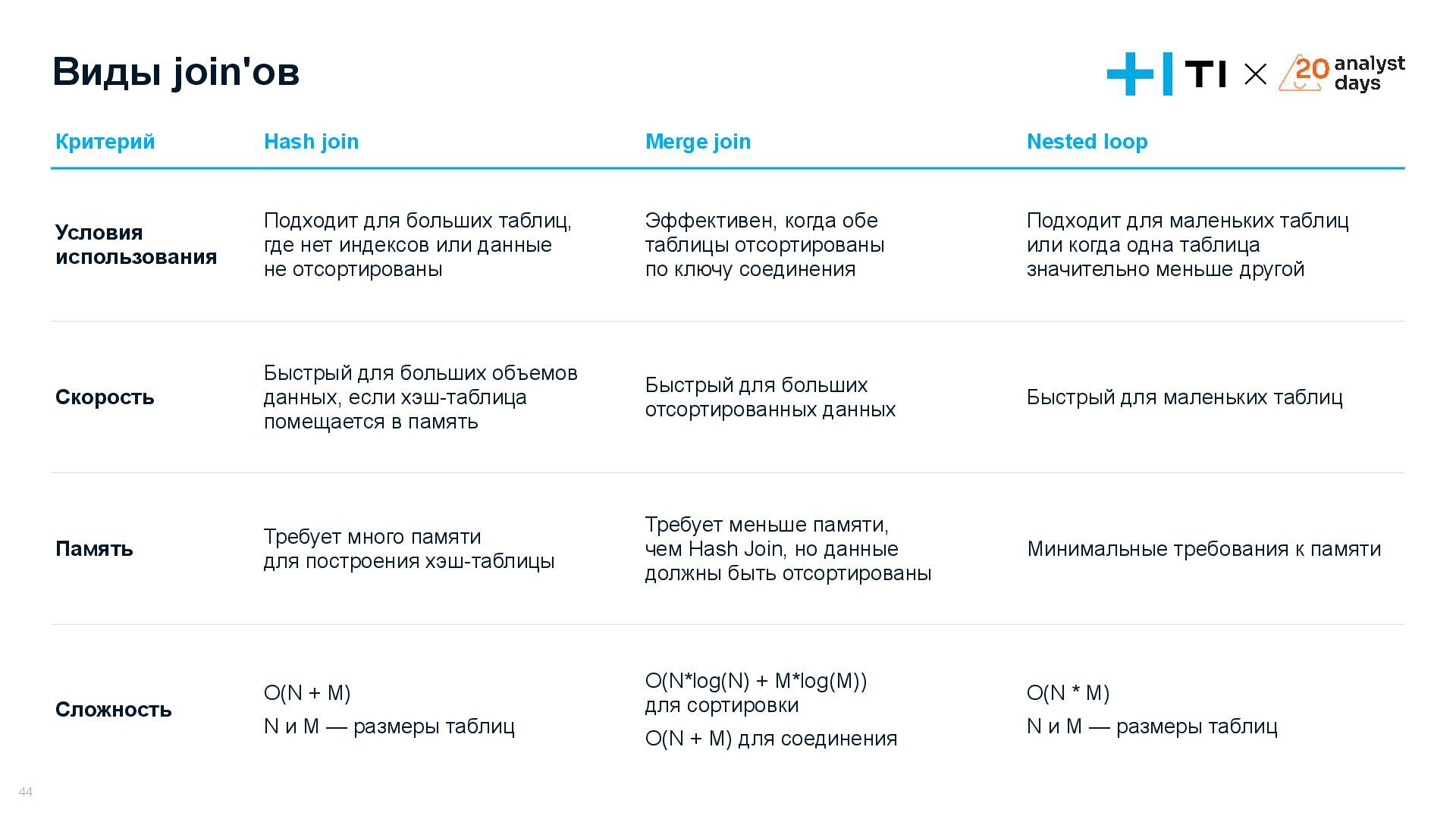{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}