of data has gone down • By 2015, 3B people will be online, pushing data volume created to 8 zettabytes • More data = More insights = Better decisions • Ease and cost of processing is falling thanks to cloud platforms
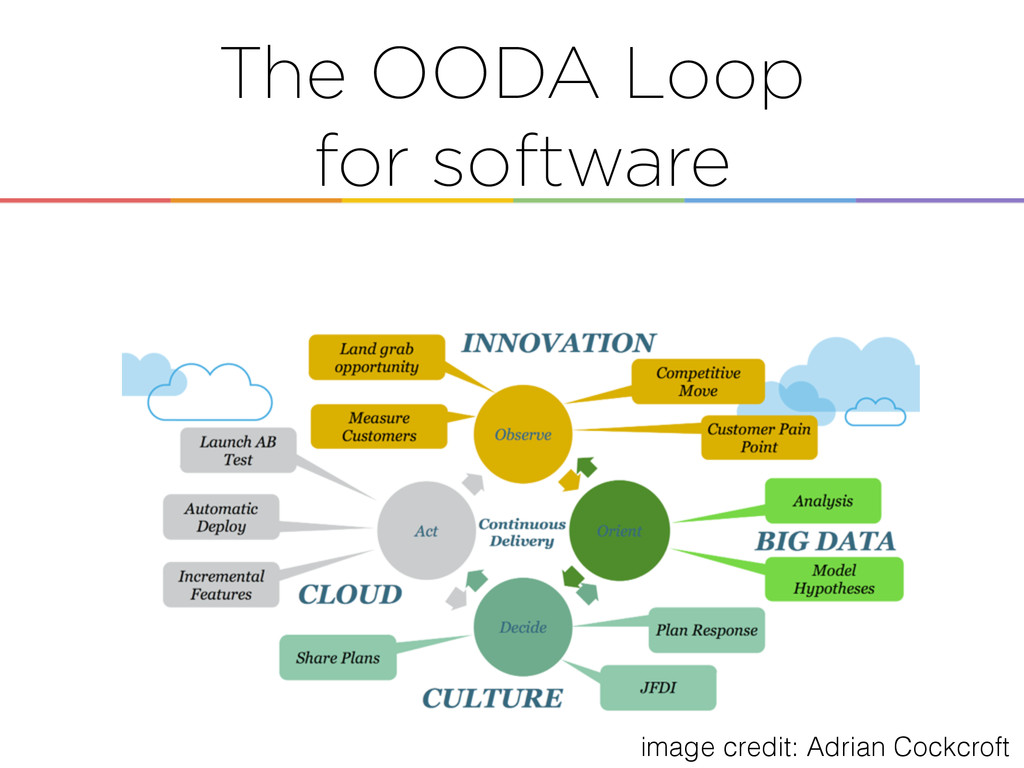
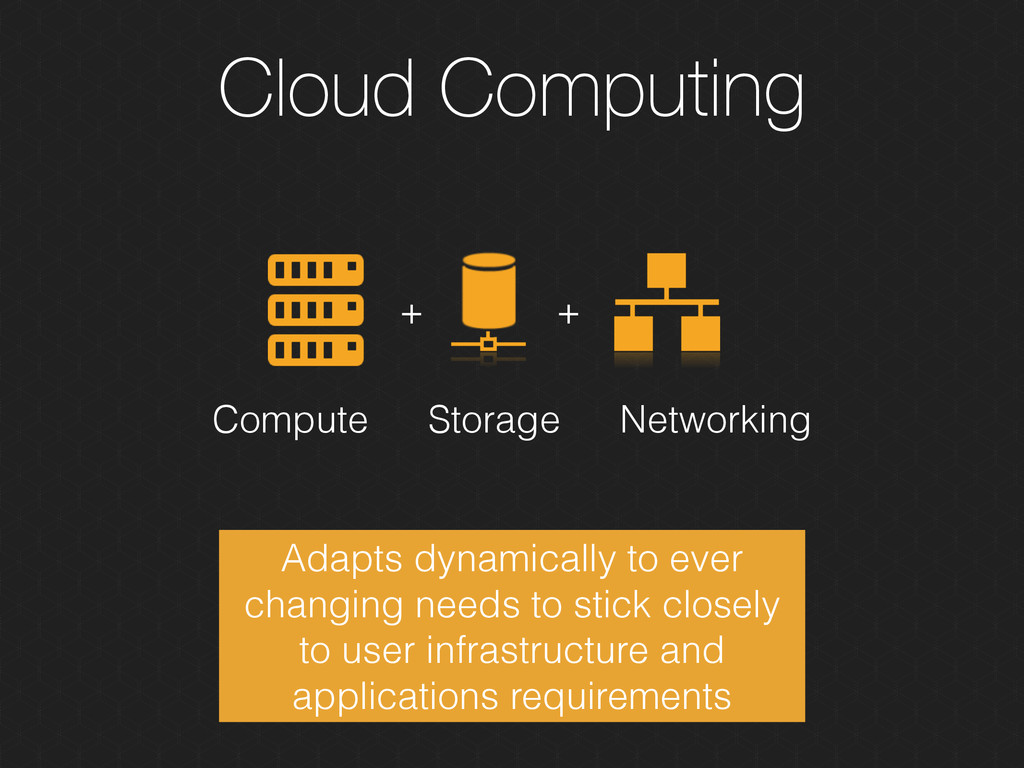
on the ingesting, storing, and processing layer and adapts closely to demands. • Provides a collection of integrated tools to adapt to the 3 V’s of Big Data • Unlimited capacity of storage and processing power fits well to changing data storage and analysis requirements.
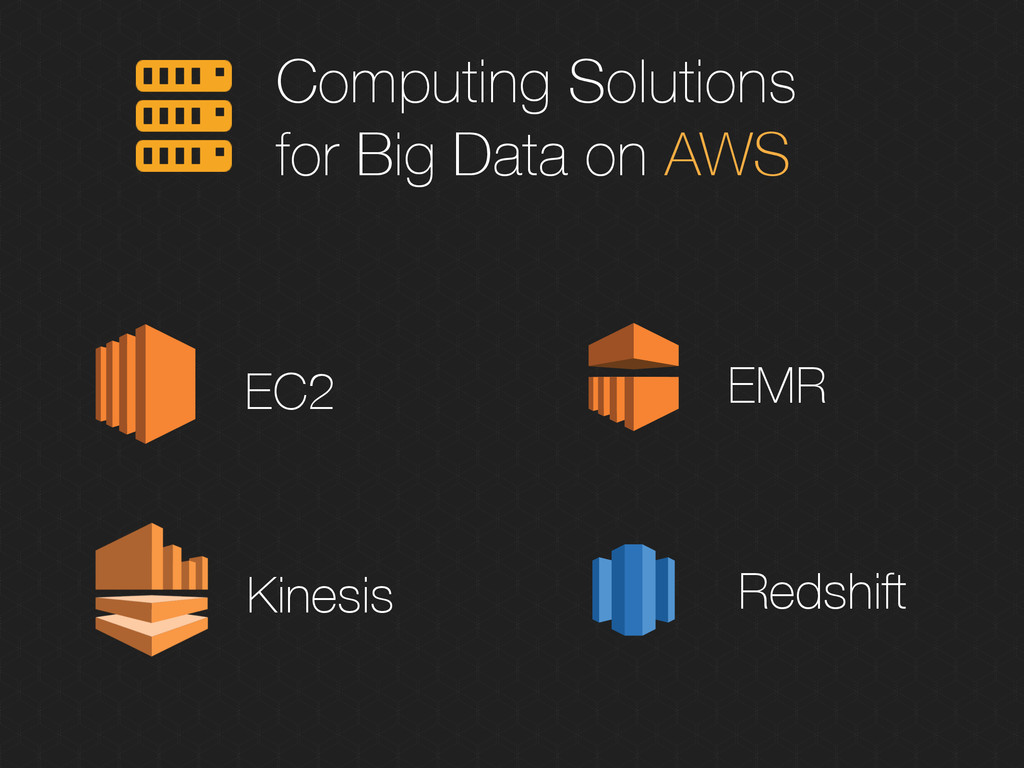
instances. Dynamic Provisioning and resizing Let you scale your infrastructure at low cost Use Case: Well suited for running custom or proprietary application (ex: SAP Hana, Tableau…)
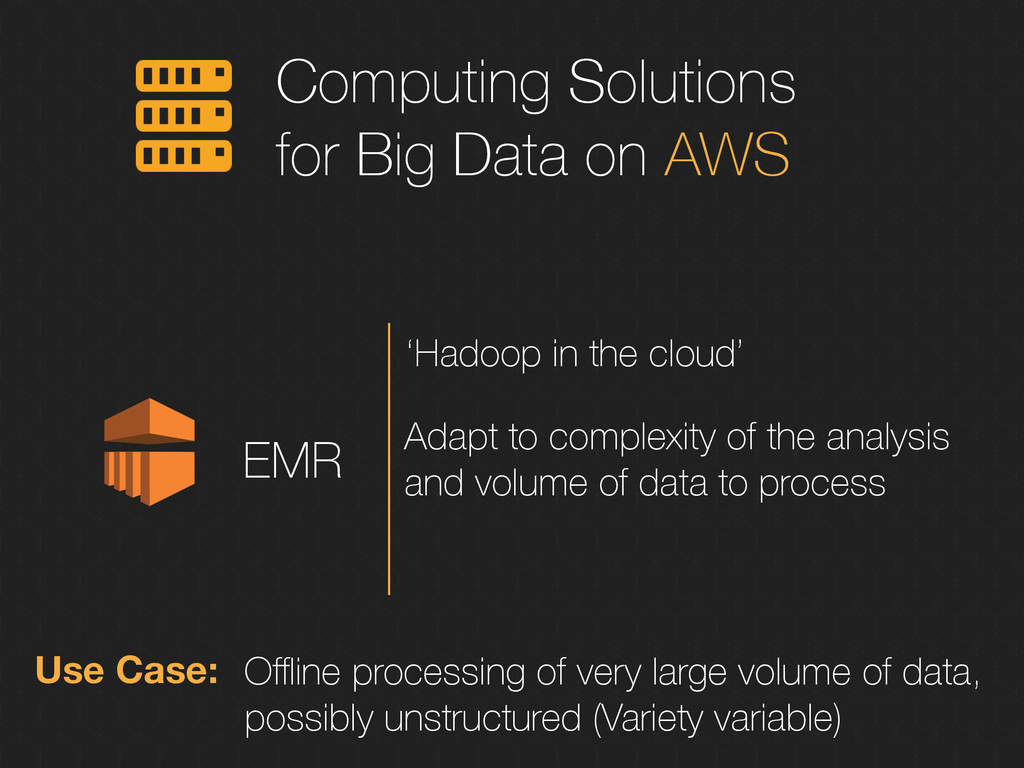
the cloud’ Adapt to complexity of the analysis and volume of data to process Use Case: Offline processing of very large volume of data, possibly unstructured (Variety variable)
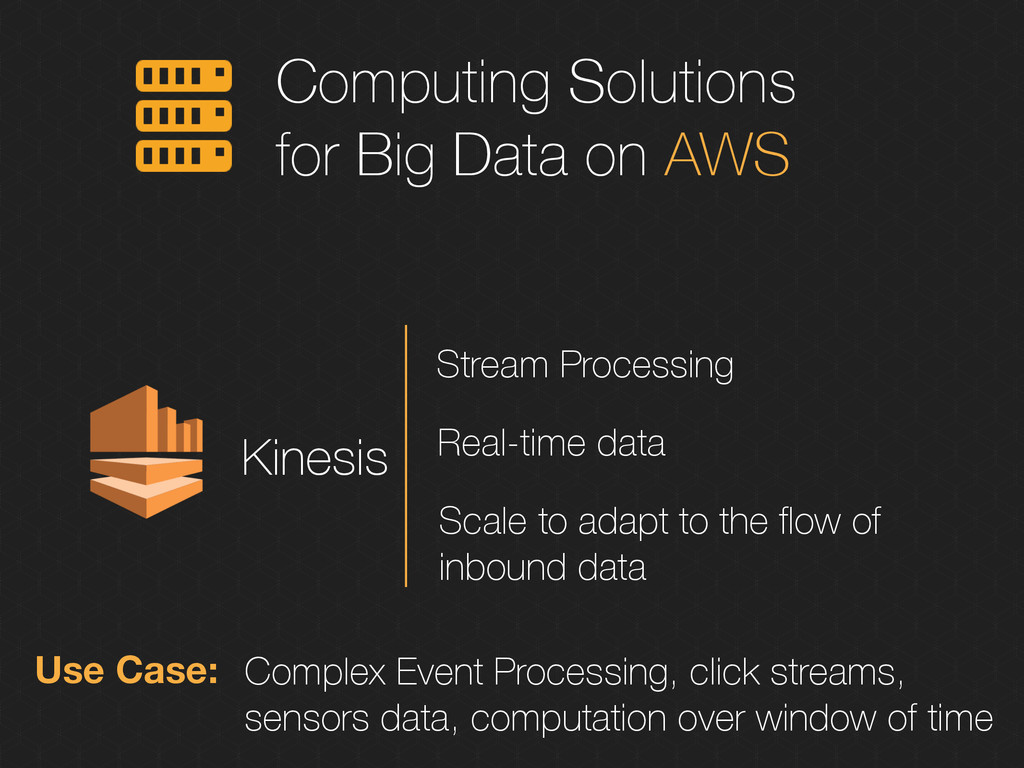
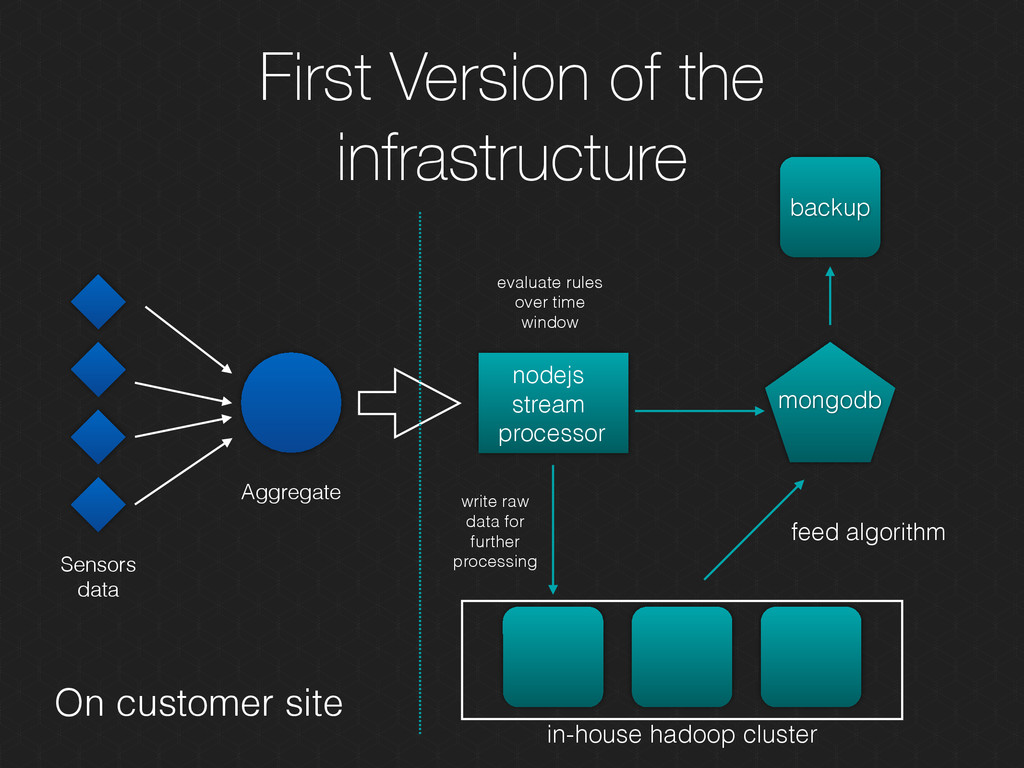
Real-time data Scale to adapt to the flow of inbound data Use Case: Complex Event Processing, click streams, sensors data, computation over window of time
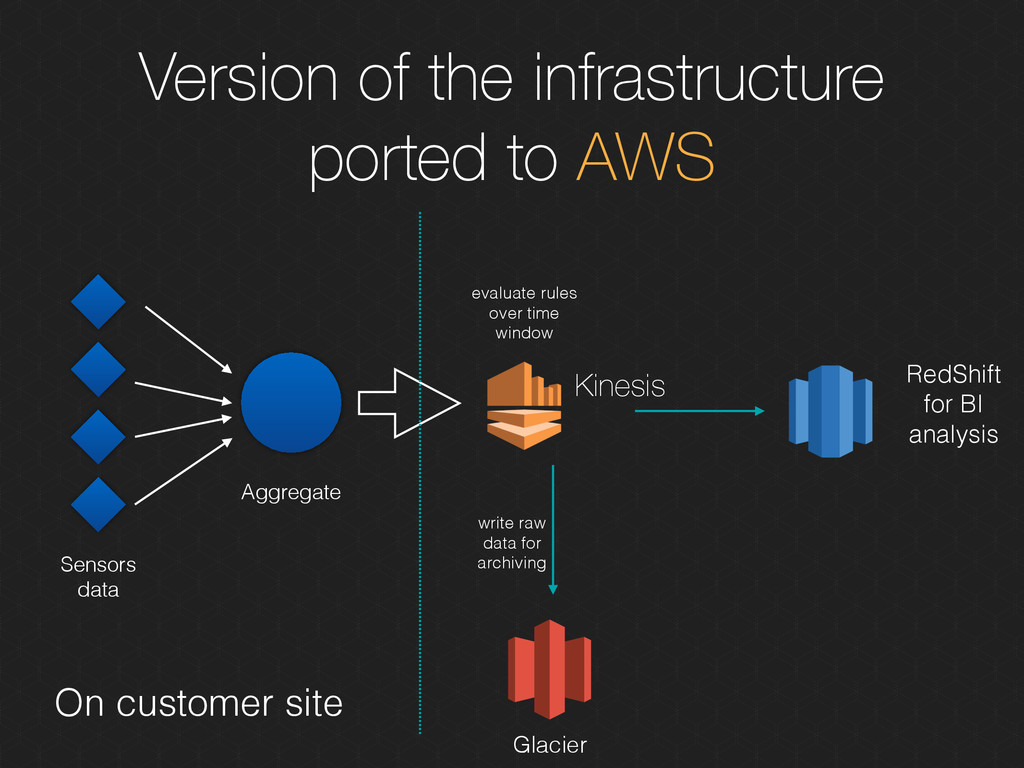
in the cloud Scales to Petabytes Supports SQL Querying Start small for just $0.25/h Use Case: BI Analysis, Use of ODBC/JDBC legacy software to analyze or visualize data
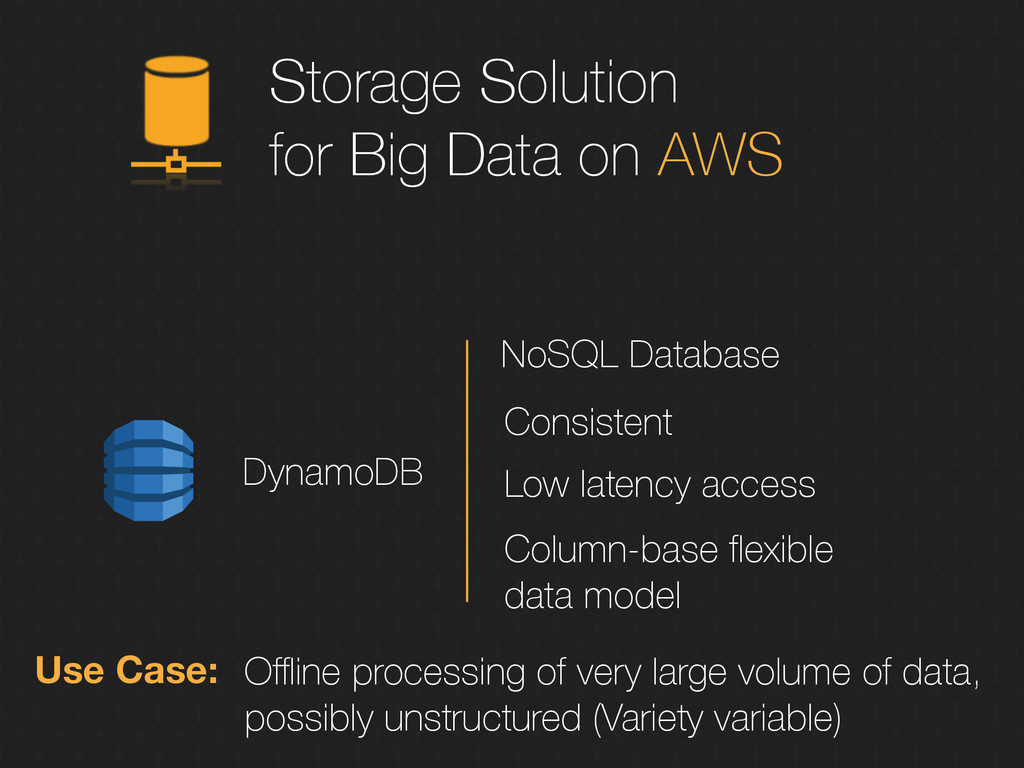
Consistent Low latency access Column-base flexible data model Use Case: Offline processing of very large volume of data, possibly unstructured (Variety variable)
Storing raw logs of data. Storing media archives. Magnetic tape replacement Archive storage of cold data Extremely low-cost optimized for data infrequently accessed
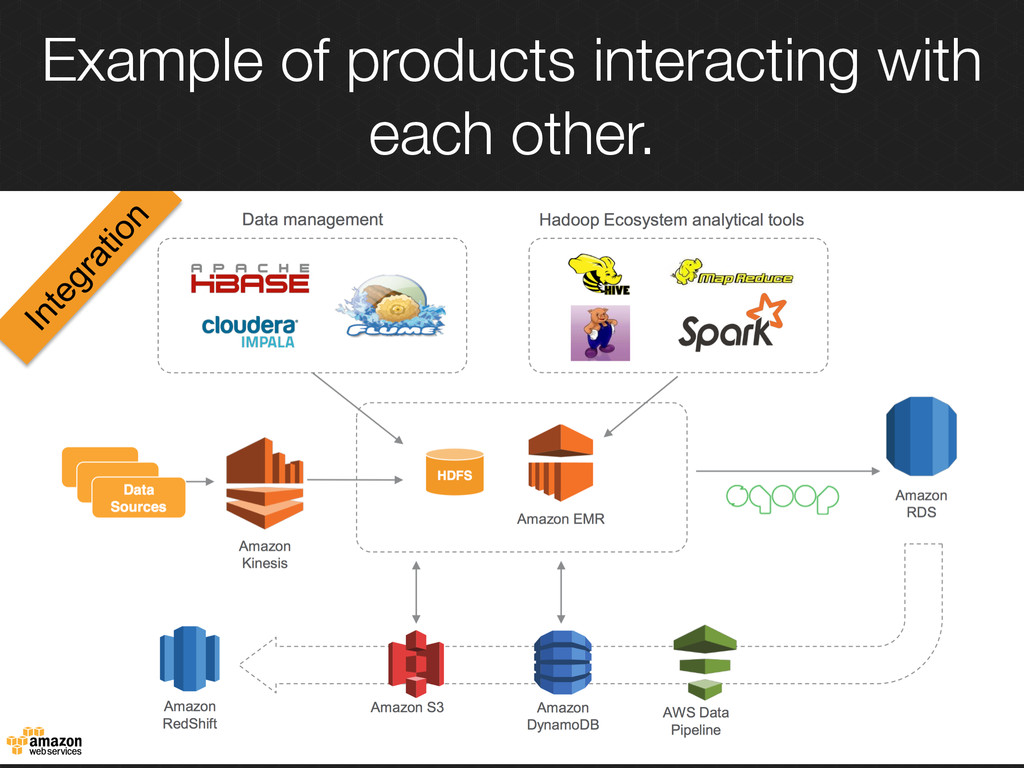
the time needed for your data processing and storage. Integrated Environment for Big Data AWS Big Data solutions comes integrated with each others already AWS Big Data solutions also integrate with the whole AWS ecosystem (Security, Identity Management, Logging, Backups, Management Console…)
and Energy management Use Case: Real-time IOT Analytics Gathering data in real time from sensors deployed in factory and send them for immediate processing
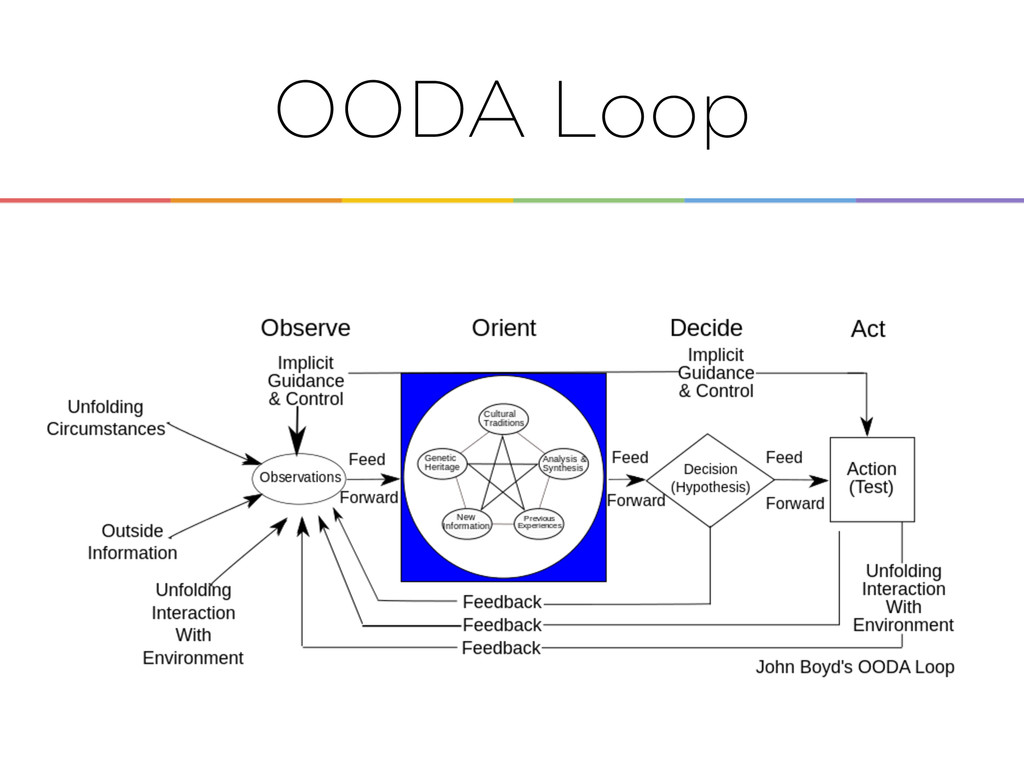
• Lots of back and forth due to bugs and the necessity to test app all over each time • Chain of command too long • Feeling no power in the process • Low trust
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You follow me: @romefort [email protected]](https://files.speakerdeck.com/presentations/1c88aa9ce2374294a4f7341bfbc4685d/slide_68.jpg){kind=link}