Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
190821 不均衡 データとの戦い方(前処理編) うっちーさん
Search
RPACommunity
August 21, 2019
Technology
580
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
190821 不均衡 データとの戦い方(前処理編) うっちーさん
RPACommunity
August 21, 2019
More Decks by RPACommunity
See All by RPACommunity
201023 Automation Anywhere「A2019」を触ってみた Ayy
rpabank
0
1.1k
201023 DX Suiteを触ってみた Ayy
rpabank
0
1.1k
201023 RPA超初心者がWinActorにチャレンジしてみた ユーコさん
rpabank
0
670
201023 PowerPlatform はじめの一歩 みさみささん
rpabank
0
670
201023 アシロボで実際に沼ってみた たまいさん
rpabank
0
730
201018 RPAの本質とトレンド Mitz
rpabank
0
550
201006 僕がいまRPAで伝えたいことのすべて いろはまるさん
rpabank
0
510
201006 UiPath MVP 2019-2020 はなっち!さん
rpabank
0
500
201006 今からでも間に合う!UiPathトーク一気に振り返り たまいさん
rpabank
0
450
Other Decks in Technology
See All in Technology
なぜMIXIはゼロトラスト基盤として クラウドフレアを選んだのか - Cloudflare Peer Point SASE User Voices
mixi_engineers
PRO
2
120
StepFunctionsとGraphRAGを活用した暗黙知活用のためのRAG基盤
yakumo
0
180
数値で見る Microsoft MVP 〜Spec Kit と GitHub Copilot Agent で作るデータ可視化ダッシュボード〜
yutakaosada
0
160
人とエージェントが高め合う協業設計
kintotechdev
0
1k
AIQAのナレッジ構築について
qatonchan
1
110
AI研修(Day2)【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
1.3k
BigQuery を検索ソースとした AI Agent の作り方って 〇〇 通りあんねん
satohjohn
0
130
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
1.5k
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
410
NYC Summit 2026 における Amazon Bedrock AgentCore のアップデート
ren8k
1
240
現場をAIで動かす「フィジカル AI」の組み込み設計の考え方【SORACOM Discovery 2026】
soracom
PRO
0
140
システム監視を 「システムを監視するだけ」で 終わらせないために
seiud
0
140
Featured
See All Featured
Design in an AI World
tapps
1
270
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
530
Building Adaptive Systems
keathley
44
3.1k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
190
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
Building an army of robots
kneath
306
46k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
360
Prompt Engineering for Job Search
mfonobong
0
380
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Ruling the World: When Life Gets Gamed
codingconduct
0
290
Transcript
不均衡データとの戦い方 (前処理編) うっちー@マクニカ 1
自己紹介 福岡県出身、学生時代を福岡で過ごす。 2008年 大学院を修了、専攻は応用数学。 その後、東京のソフトウェア会社に就職。 2017年 マクニカネットワーク株式会社に転職。
2019年3月まで「Splunk」Pre Sales 技術担当。 2019年4月より、現在の部署でAI関連の業務に勤しむ。 2019年7月G検定合格。 特技・趣味 お酒大好き。九州男児。 幼少期子役としてCM、舞台等に出演。 将棋好き。某将棋アプリで三段です。 Facebook: /masakatsu.uchida.5 2
いつもの 本資料の内容と発表での発言は個人の見解であり、 所属する組織の公式見解ではありません。 3
Agenda 不均衡データ 考え方編 不均衡データ 実践編 まとめ 4
不均衡データ 考え方編 5
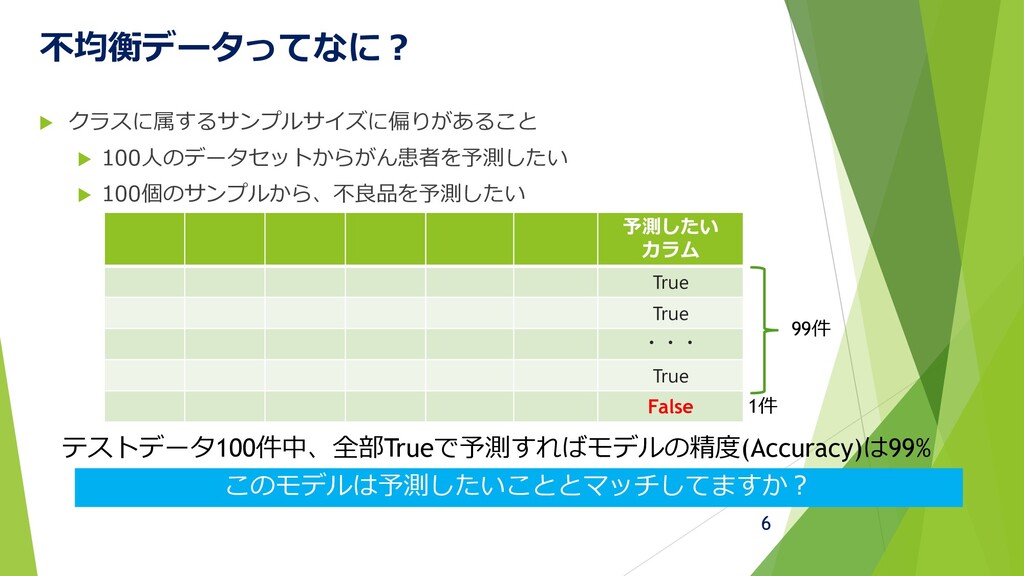
不均衡データってなに? クラスに属するサンプルサイズに偏りがあること 100人のデータセットからがん患者を予測したい 100個のサンプルから、不良品を予測したい 予測したい カラム True
True ・・・ True False 99件 1件 テストデータ100件中、全部Trueで予測すればモデルの精度(Accuracy)は99% このモデルは予測したいこととマッチしてますか? 6
本日のテーマ サンプルサイズが偏って いる事がわかったけど、 そう頻繁に起きるわけ じゃないし、困ったなあ 今あるデータだけを使って、モデルの改善を試みる方法をご紹介します 7
前提条件 今回のLTでは、教師あり学習の2値分類問題を対象とします。 データセットはテーブルデータを対象とします。 8
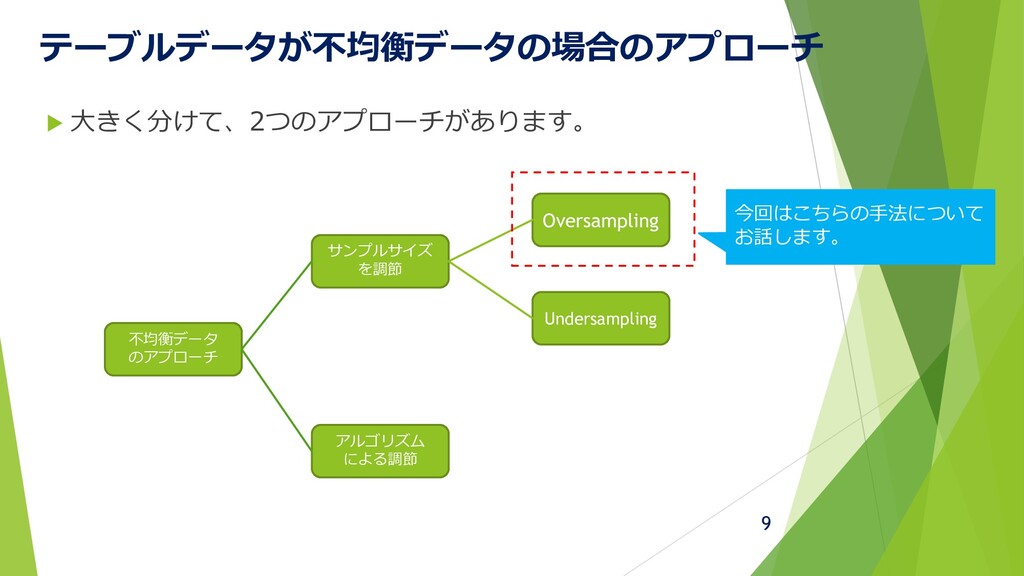
テーブルデータが不均衡データの場合のアプローチ 大きく分けて、2つのアプローチがあります。 不均衡データ のアプローチ サンプルサイズ を調節 アルゴリズム による調節 Oversampling
Undersampling 今回はこちらの手法について お話します。 9
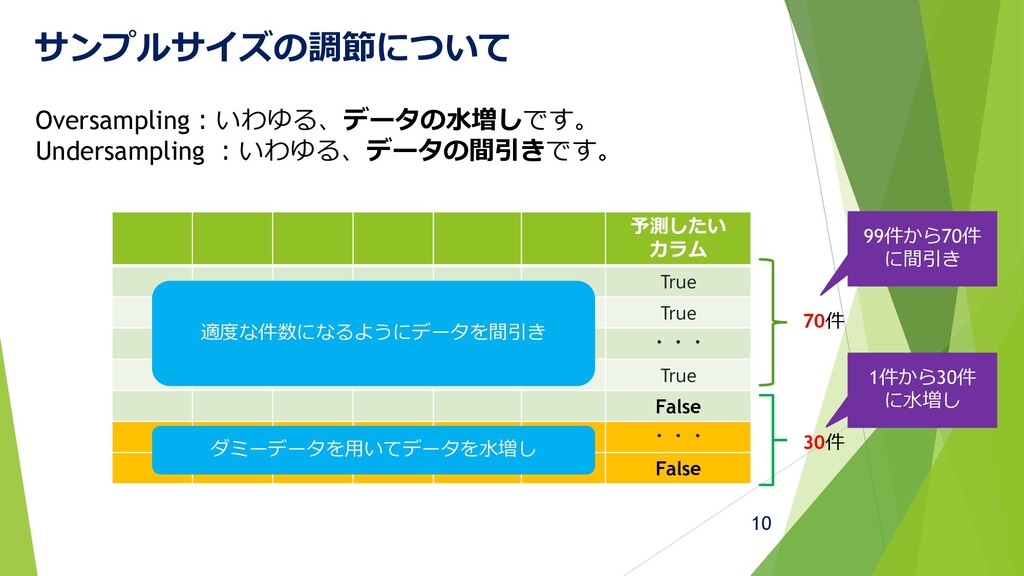
サンプルサイズの調節について Oversampling:いわゆる、データの水増しです。 Undersampling :いわゆる、データの間引きです。 予測したい カラム True True ・・・ True
False ・・・ False 70件 30件 ダミーデータを用いてデータを水増し 適度な件数になるようにデータを間引き 99件から70件 に間引き 1件から30件 に水増し 10
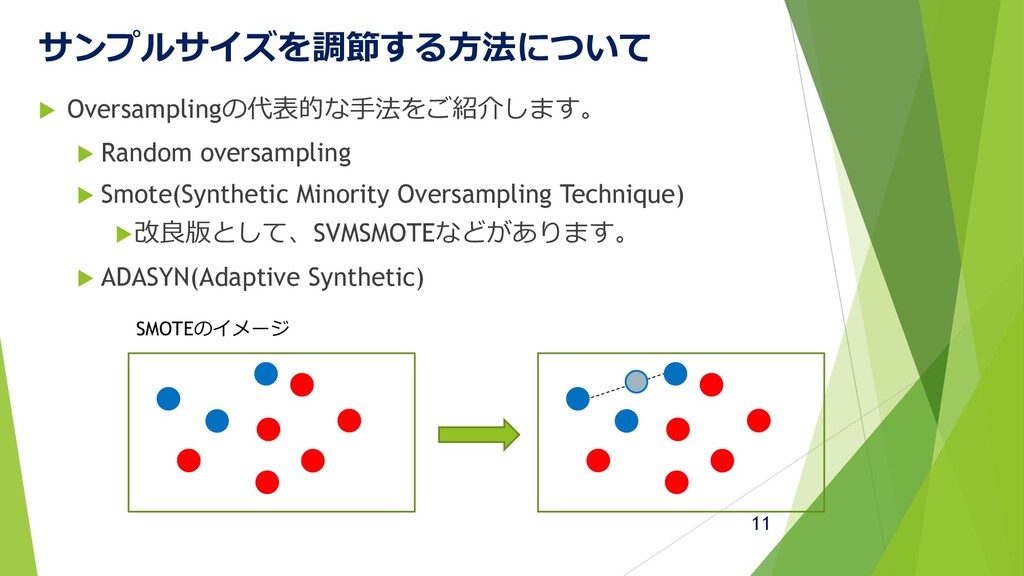
サンプルサイズを調節する方法について Oversamplingの代表的な手法をご紹介します。 Random oversampling Smote(Synthetic Minority Oversampling
Technique) 改良版として、SVMSMOTEなどがあります。 ADASYN(Adaptive Synthetic) SMOTEのイメージ 11
サンプルサイズを調節する際の注意事項について 1. Oversamplingによって過学習が発生する可能性がある問題 データ量が増えたことにより、過学習してしまうことがあります。 2. 精度があがるとは限らない問題 サンプルサイズを調整しても、モデル精度が改善しない場合があります。 12
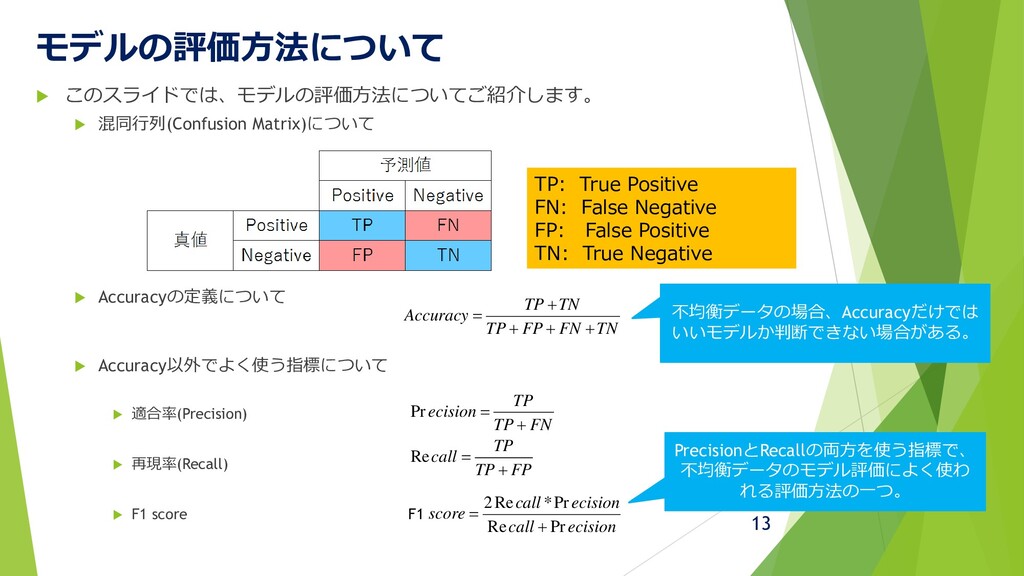
モデルの評価方法について このスライドでは、モデルの評価方法についてご紹介します。 混同行列(Confusion Matrix)について Accuracyの定義について Accuracy以外でよく使う指標について
適合率(Precision) 再現率(Recall) F1 score FP TP TP call + = Re ecision call ecision call score Pr Re Pr * Re 2 + = FN TP TP ecision + = Pr 13 TP: True Positive FN: False Negative FP: False Positive TN: True Negative TN FN FP TP TN TP Accuracy + + + + = F1 PrecisionとRecallの両方を使う指標で、 不均衡データのモデル評価によく使わ れる評価方法の一つ。 不均衡データの場合、Accuracyだけでは いいモデルか判断できない場合がある。
不均衡データ 実践編 14
この章の概要 不均衡データのデータセットを使って、下記パターンのモデルを作成し、 精度を比較することで、Oversamplingの効果について確認します。 Oversamplingを適用しない場合 Oversamplingを適用した場合 評価指標はAccuracy
と F1 scoreを利用します。 15
Datasetの説明 下記データセットをいます。 「Default of Credit Card Clients Dataset」
https://www.kaggle.com/uciml/default-of-credit-card-clients-dataset/version/1# 台湾の2005/4月~2005/9月の貸付データ カラム数25個 × レコード数3万件 翌月デフォルトした件数は6,636件 (約21.6%) 16
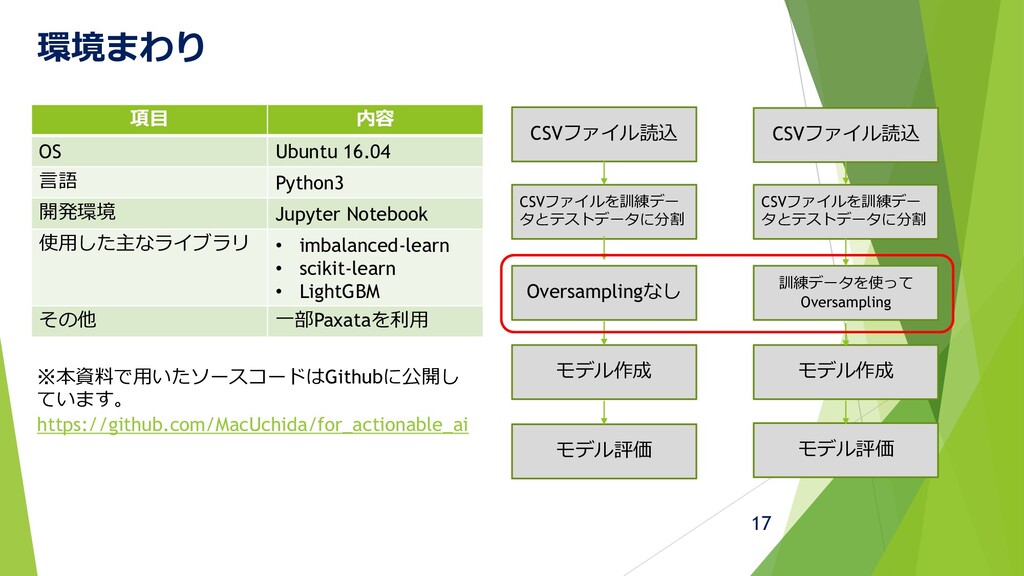
環境まわり CSVファイル読込 モデル作成 モデル作成 モデル評価 CSVファイルを訓練デー タとテストデータに分割 モデル評価 Oversamplingなし 訓練データを使って
Oversampling CSVファイル読込 CSVファイルを訓練デー タとテストデータに分割 ※本資料で用いたソースコードはGithubに公開し ています。 https://github.com/MacUchida/for_actionable_ai 17 項目 内容 OS Ubuntu 16.04 言語 Python3 開発環境 Jupyter Notebook 使用した主なライブラリ • imbalanced-learn • scikit-learn • LightGBM その他 一部Paxataを利用
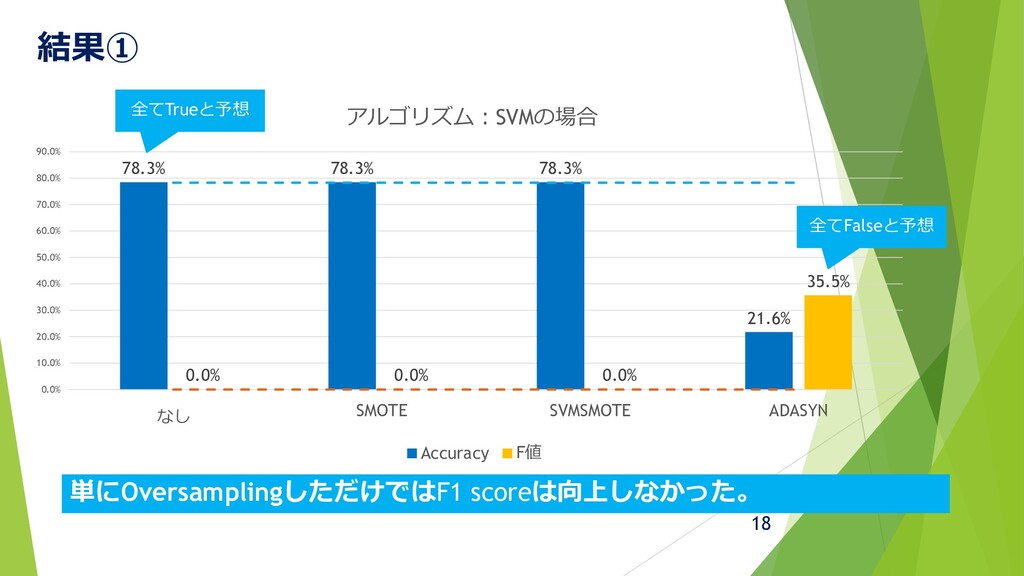
結果① 18 78.3% 78.3% 78.3% 21.6% 0.0% 0.0% 0.0% 35.5%
0.0% 10.0% 20.0% 30.0% 40.0% 50.0% 60.0% 70.0% 80.0% 90.0% なし SMOTE SVMSMOTE ADASYN アルゴリズム:SVMの場合 Accuracy F値 単にOversamplingしただけではF1 scoreは向上しなかった。 全てFalseと予想 全てTrueと予想
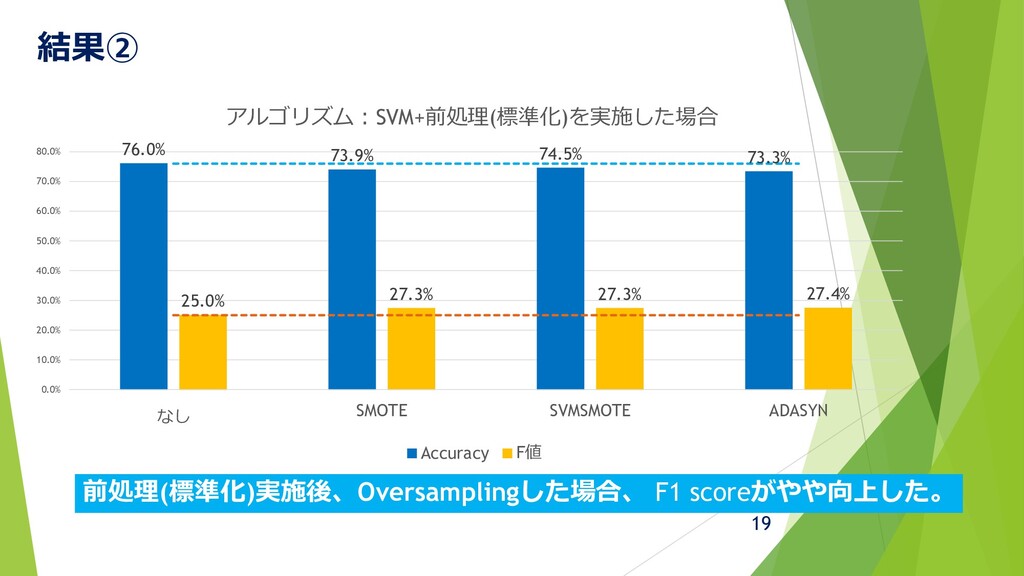
結果② 19 前処理(標準化)実施後、Oversamplingした場合、 F1 scoreがやや向上した。 76.0% 73.9% 74.5% 73.3% 25.0%
27.3% 27.3% 27.4% 0.0% 10.0% 20.0% 30.0% 40.0% 50.0% 60.0% 70.0% 80.0% なし SMOTE SVMSMOTE ADASYN アルゴリズム:SVM+前処理(標準化)を実施した場合 Accuracy F値
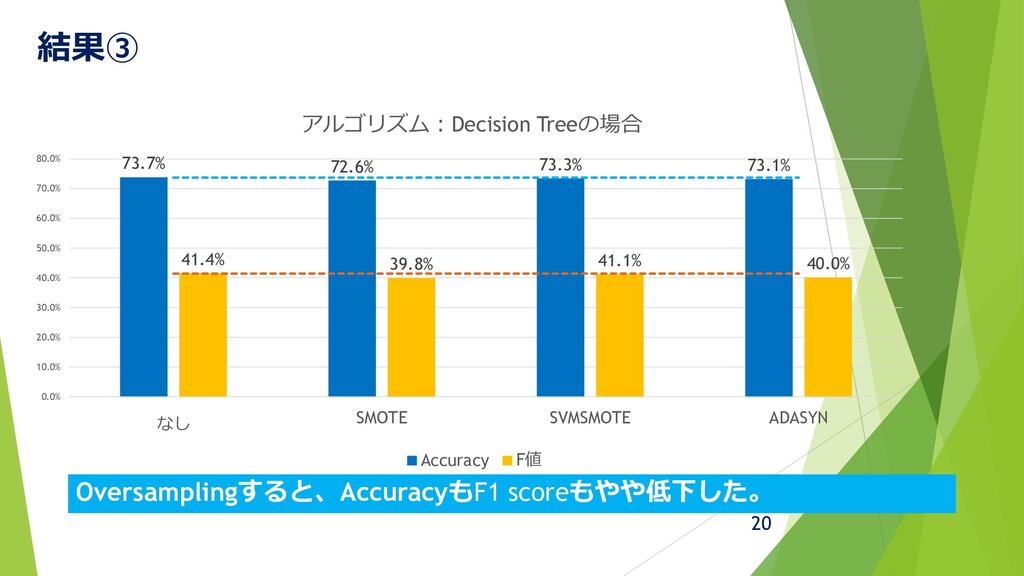
結果③ 20 73.7% 72.6% 73.3% 73.1% 41.4% 39.8% 41.1% 40.0%
0.0% 10.0% 20.0% 30.0% 40.0% 50.0% 60.0% 70.0% 80.0% なし SMOTE SVMSMOTE ADASYN アルゴリズム:Decision Treeの場合 Accuracy F値 Oversamplingすると、AccuracyもF1 scoreもやや低下した。
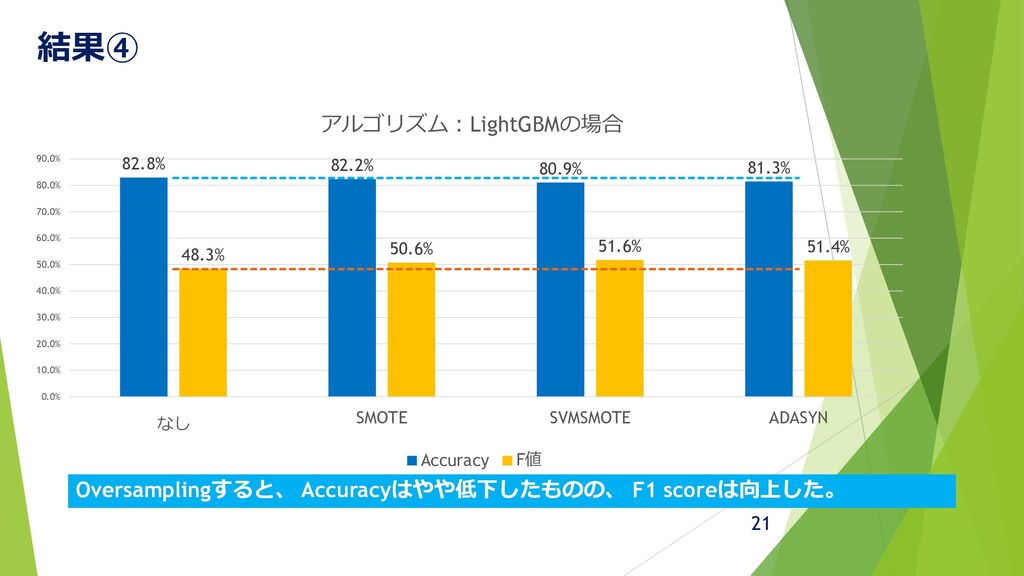
結果④ 21 82.8% 82.2% 80.9% 81.3% 48.3% 50.6% 51.6% 51.4%
0.0% 10.0% 20.0% 30.0% 40.0% 50.0% 60.0% 70.0% 80.0% 90.0% なし SMOTE SVMSMOTE ADASYN アルゴリズム:LightGBMの場合 Accuracy F値 Oversamplingすると、 Accuracyはやや低下したものの、 F1 scoreは向上した。
不均衡データ まとめ編 22
まとめ データセットが不均衡データになってしまった場合でも、あきらめないで。 サンプルサイズを調節する手法として、「Oversampling」をご紹介しました。 実際に「Default of Credit Card
Clients Dataset」というデータセットを使って、サンプル サイズを調節する手法にて効果があるか確認しました。 今回紹介できませんでしたが、他にもアルゴリズムレベルでチューニングする方法もあり ます。 モデルの評価指標も検討しましょう。 23
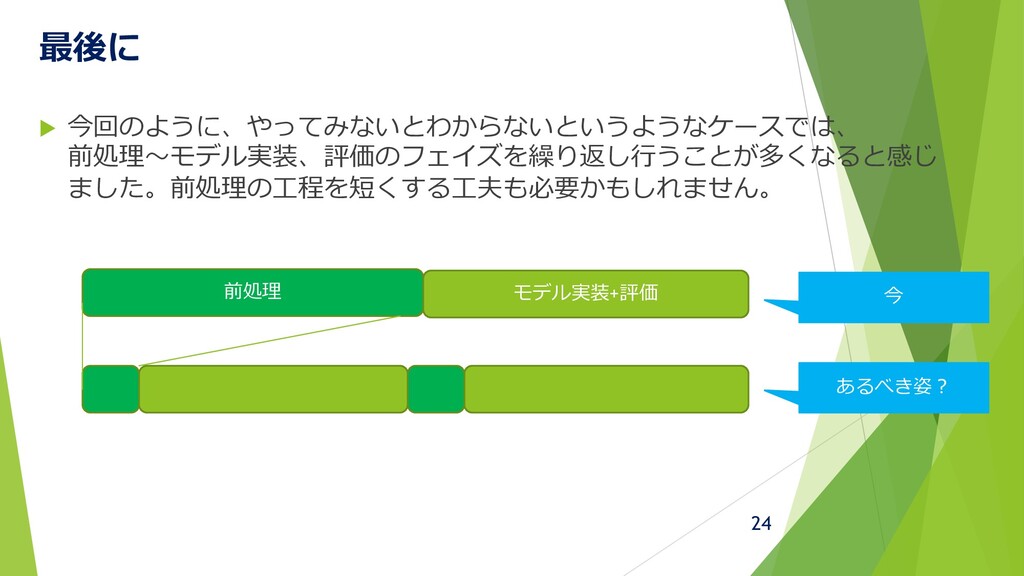
最後に 今回のように、やってみないとわからないというようなケースでは、 前処理~モデル実装、評価のフェイズを繰り返し行うことが多くなると感じ ました。前処理の工程を短くする工夫も必要かもしれません。 前処理 モデル実装+評価 今 あるべき姿? 24
25
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}