distribution assumptions on the derived latent class trajectories Dr Hannah Lennon, Dr Matthew Sperrin, Prof Andrew G Renehan 3rd July 2017 [email protected] @HannahLennon Statistical Analysis of Multi-Outcome Data (SAM) 2017
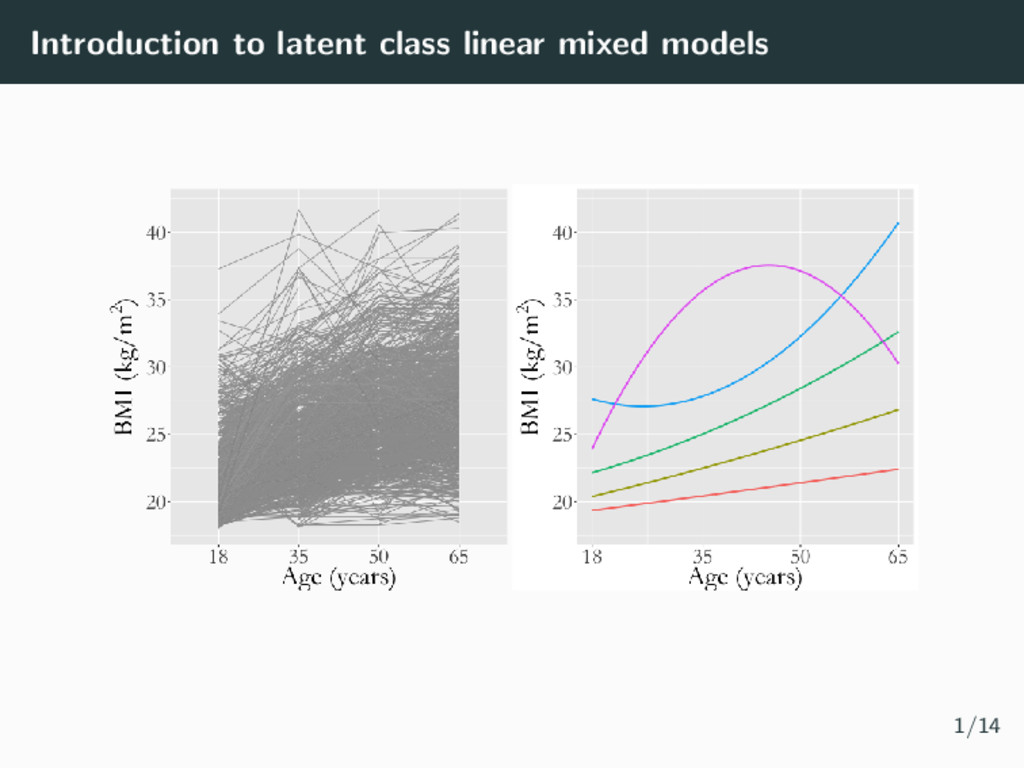
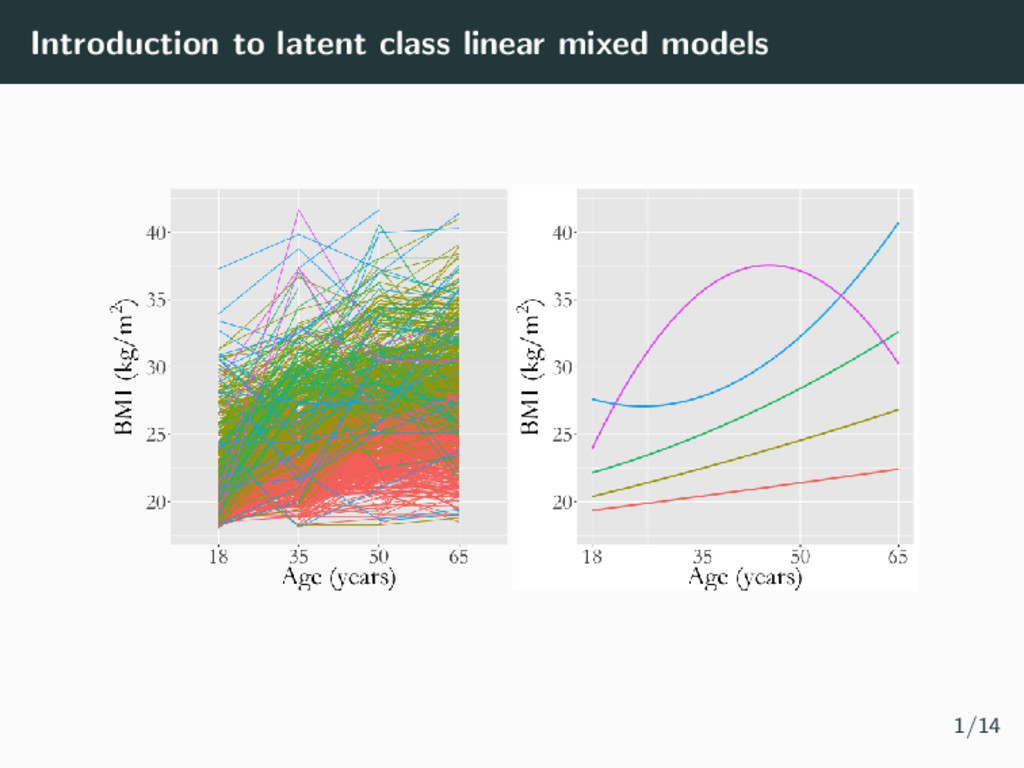
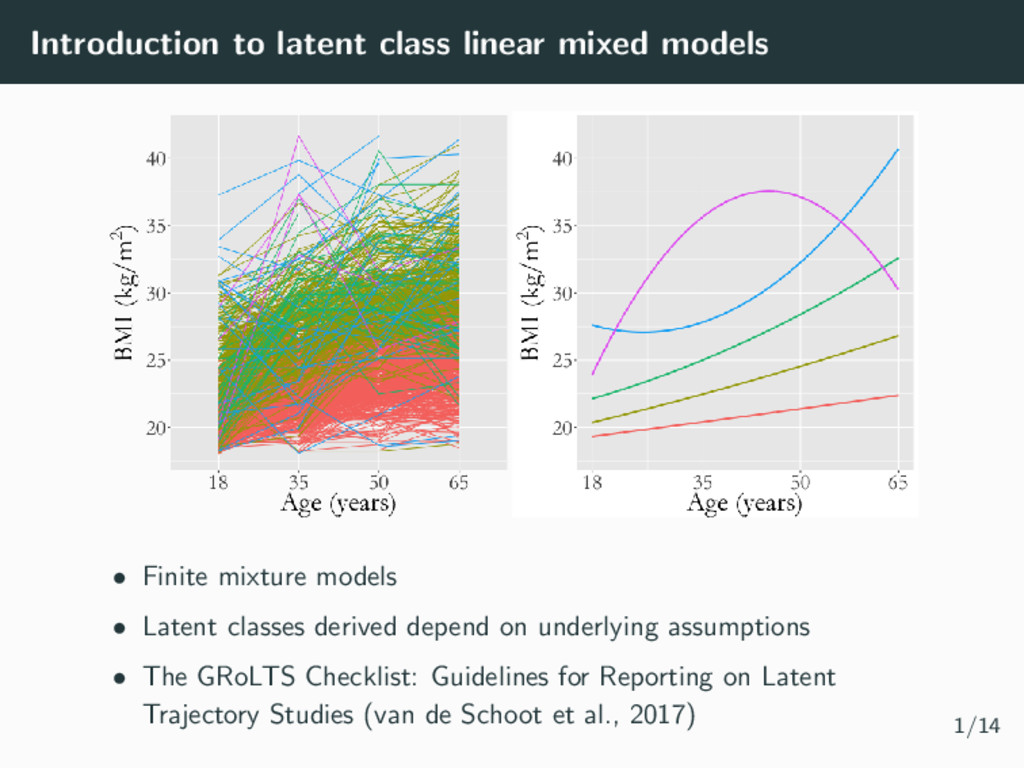
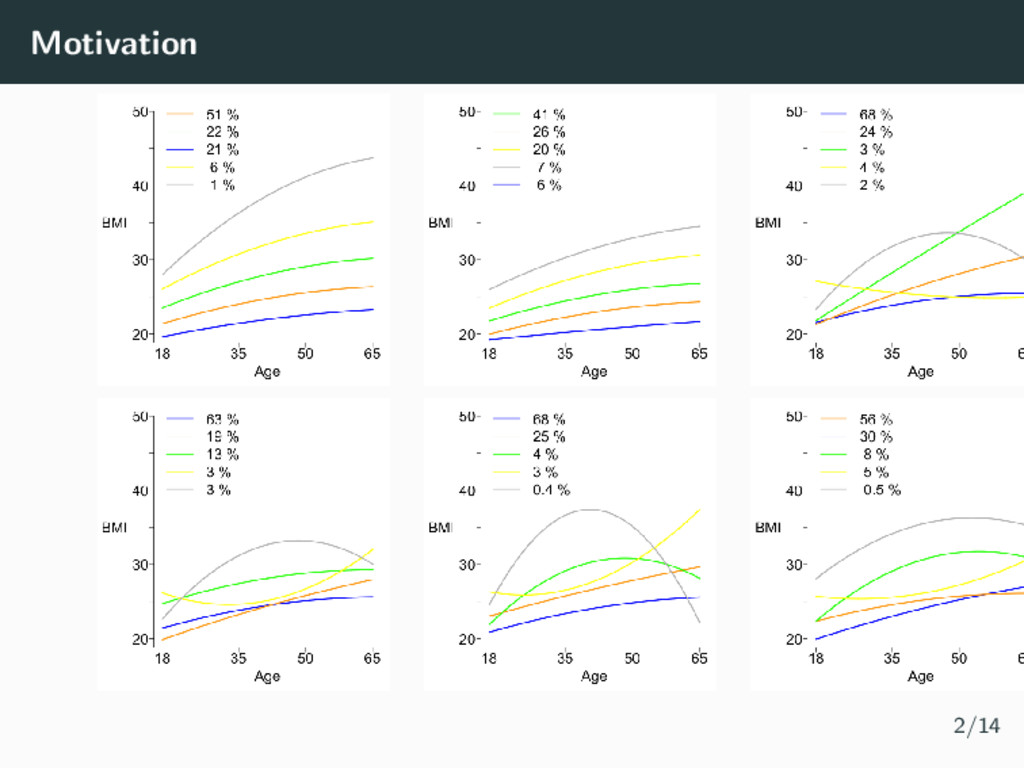
models • Latent classes derived depend on underlying assumptions • The GRoLTS Checklist: Guidelines for Reporting on Latent Trajectory Studies (van de Schoot et al., 2017) 1/14
Methods A simulation study under various variance-covariance matrix scenarios Simulation Study I Varying DGP (sample sizes and class proportions) under one model fit Simulation Study II Varying models: under one DGP Take Home Messages 3/14
extension of the linear mixed model of Laird & Ware (1982) for individuals i = 1, . . . , N at times j = 1, . . . , T, for k = 1, . . . , K classes Yij|ci =k = Xi (tij )βk + Zik (tij )uik + wk (tij ) + εijk , (1) εij iid ∼ N(0, R). where both the fixed effects and the distribution of the random effects can be class-specific. 4/14
extension of the linear mixed model of Laird & Ware (1982) for individuals i = 1, . . . , N at times j = 1, . . . , T, for k = 1, . . . , K classes Yij|ci =k = Xi (tij )βk + Zik (tij )uik + wk (tij ) + εijk , (1) εij iid ∼ N(0, R). where both the fixed effects and the distribution of the random effects can be class-specific. 4/14
extension of the linear mixed model of Laird & Ware (1982) for individuals i = 1, . . . , N at times j = 1, . . . , T, for k = 1, . . . , K classes Yij|ci =k = Xi (tij )βk + Zik (tij )uik + wk (tij ) + εijk , (1) εij iid ∼ N(0, R). where both the fixed effects and the distribution of the random effects can be class-specific. 4/14
extension of the linear mixed model of Laird & Ware (1982) for individuals i = 1, . . . , N at times j = 1, . . . , T, for k = 1, . . . , K classes Yij|ci =k = Xi (tij )βk + Zik (tij )uik + wk (tij ) + εijk , (1) εij iid ∼ N(0, R). where both the fixed effects and the distribution of the random effects can be class-specific. Each subject is allowed to vary about the mean trajectory of its class. 4/14
extension of the linear mixed model of Laird & Ware (1982) for individuals i = 1, . . . , N at times j = 1, . . . , T, for k = 1, . . . , K classes Yij|ci =k = Xi (tij )βk + Zik (tij )uik + wk (tij ) + εijk , (1) εij iid ∼ N(0, R). where both the fixed effects and the distribution of the random effects can be class-specific. Each subject is allowed to vary about the mean trajectory of its class. We let the discrete random variable ci follow a multinomial logistic model according to covariates Xi , Pr(ci = k|Xi ) = exp(ξ0k + Xi ξk ) K l=1 exp(ξ0l + X i ξl ) . (2) 4/14
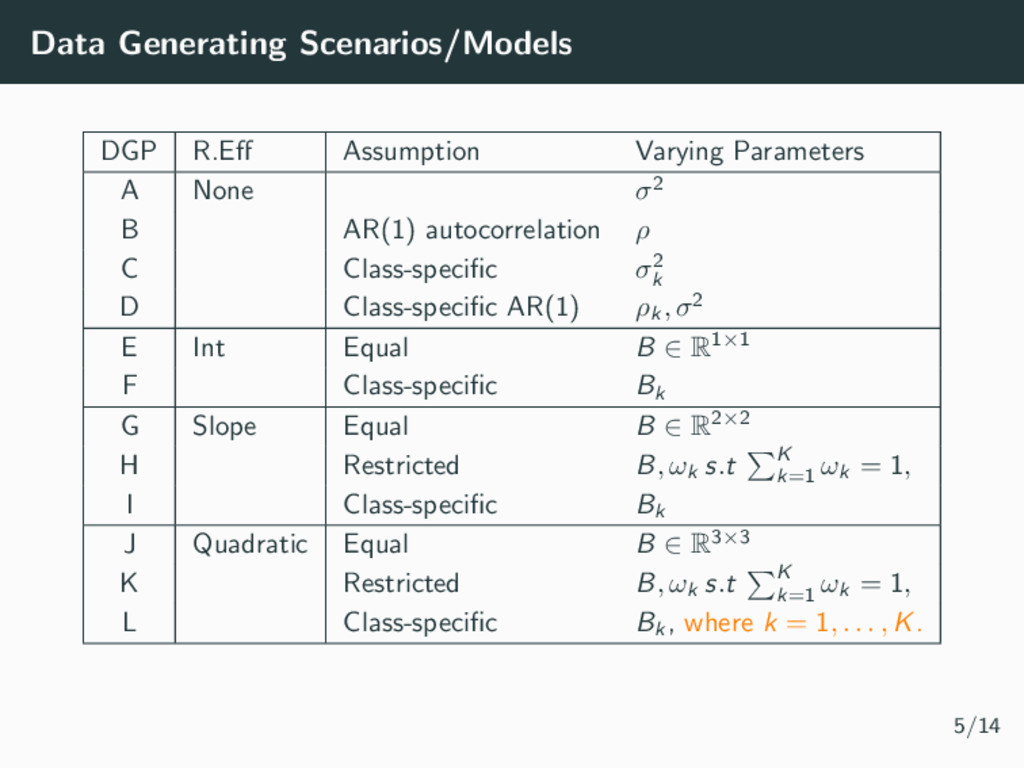
σ2 B AR(1) autocorrelation ρ C Class-specific σ2 k D Class-specific AR(1) ρk , σ2 E Int Equal B ∈ R1×1 F Class-specific Bk G Slope Equal B ∈ R2×2 H Restricted B, ωk s.t K k=1 ωk = 1, I Class-specific Bk J Quadratic Equal B ∈ R3×3 K Restricted B, ωk s.t K k=1 ωk = 1, L Class-specific Bk , where k = 1, . . . , K. 5/14
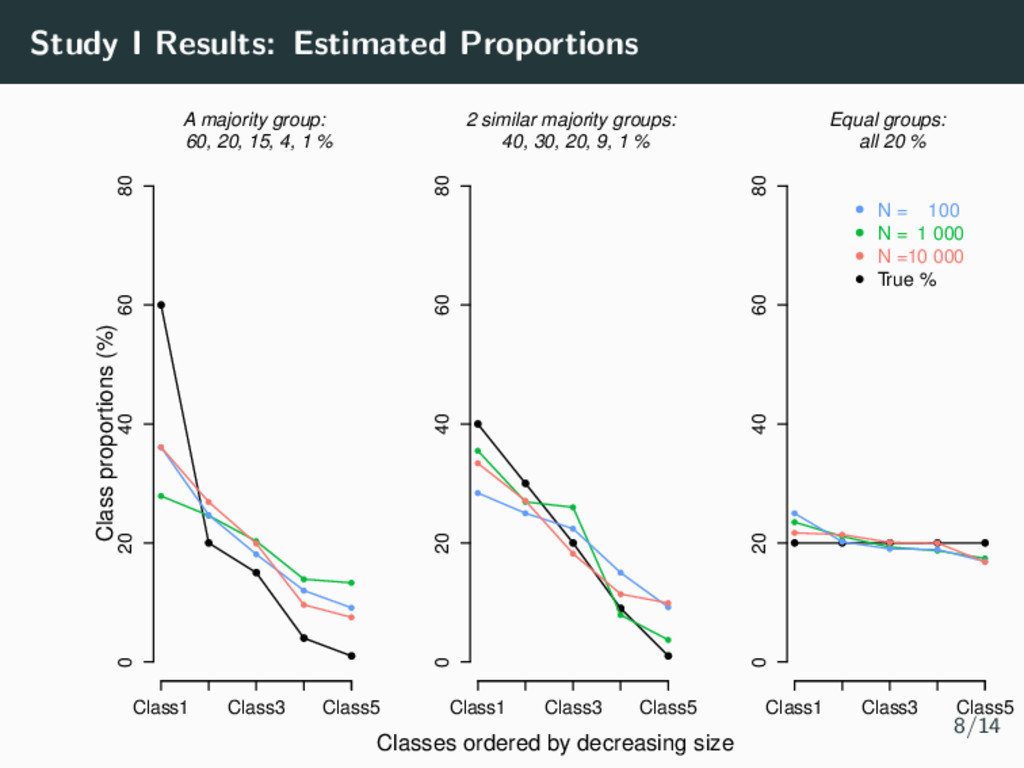
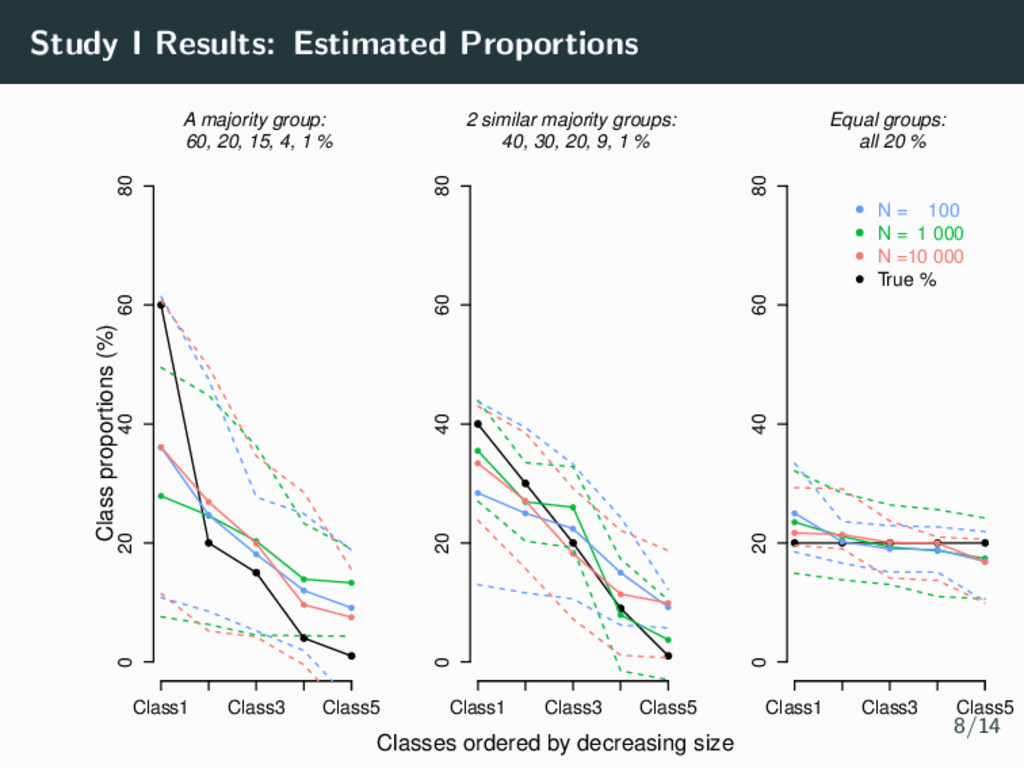
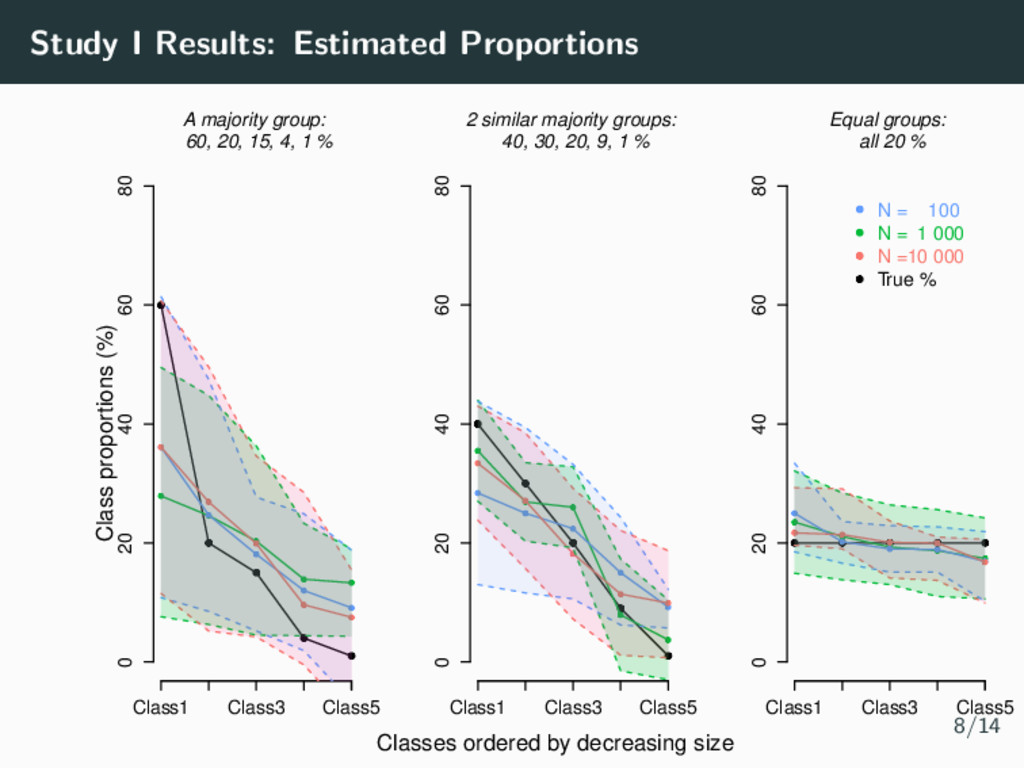
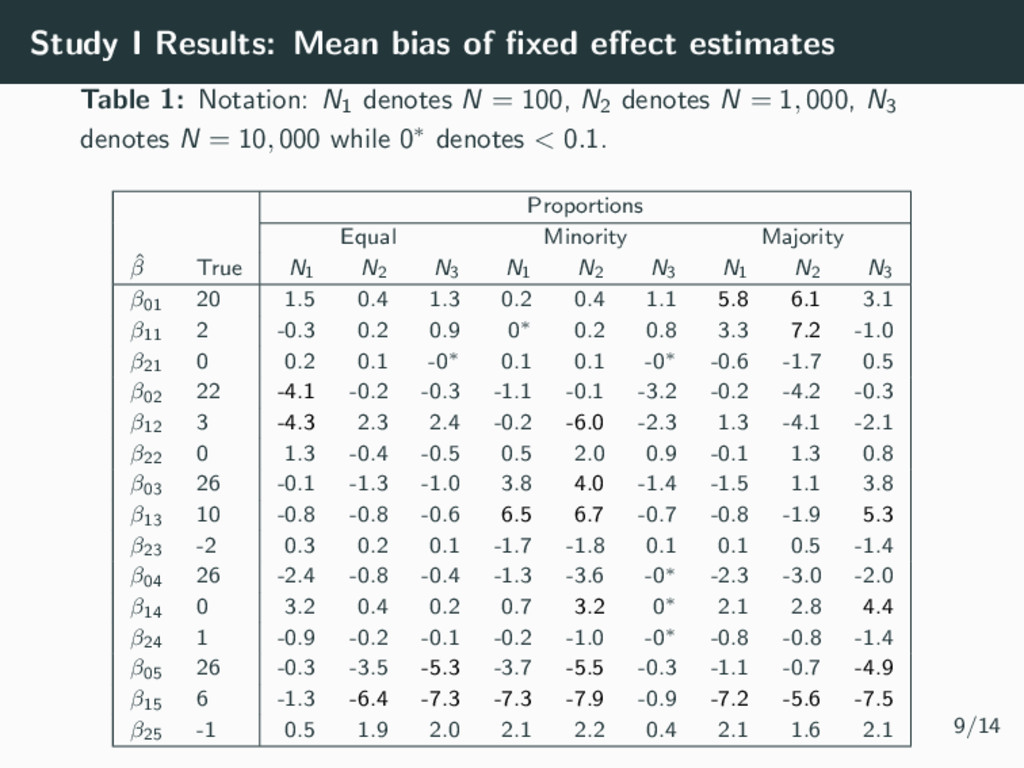
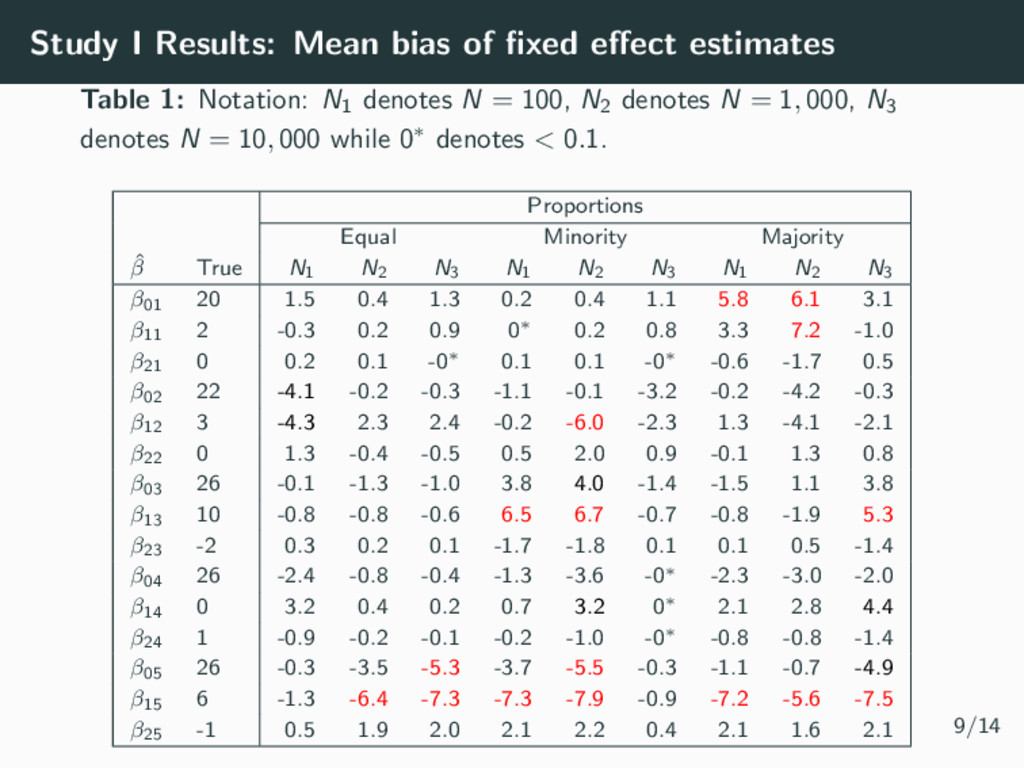
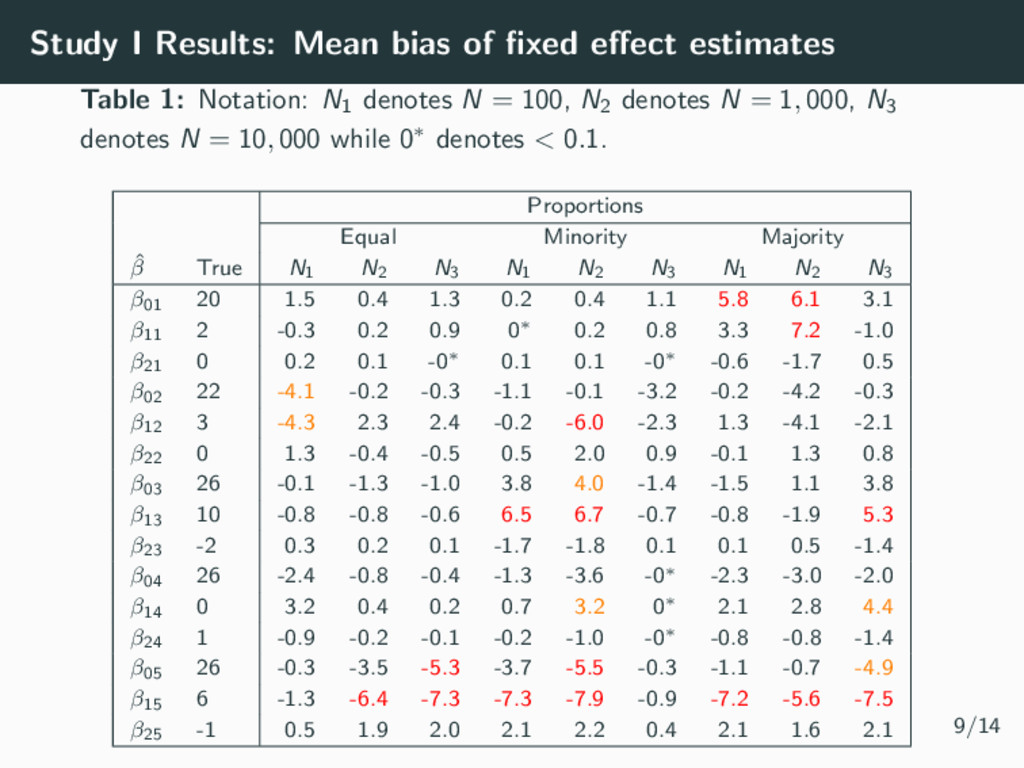
parameters (Magnitude & shapes of classes) • 4 time points per individual • Residual variance σ2 = 0.5 • Number of Samples m = 1000 Simulation Parameters: Study I • Sample Size N = 100, N = 1000, N = 10 000 • Class Proportions • Equality (All 20%) • 2 similar majority groups (40%, 30%, 20%, 9%, 1%) • A clear majority group (60%, 20%, 15%, 4%, 1%) 7/14
parameters (Magnitude & shapes of classes) • 4 time points per individual • Residual variance σ2 = 0.5 • Number of Samples m = 1000 Simulation Parameters: Study II Fix • Sample Size N = 10000 • Class Proportions (60%, 20%, 15%, 4%, 1%) Vary • Fit Models A to Models L 7/14
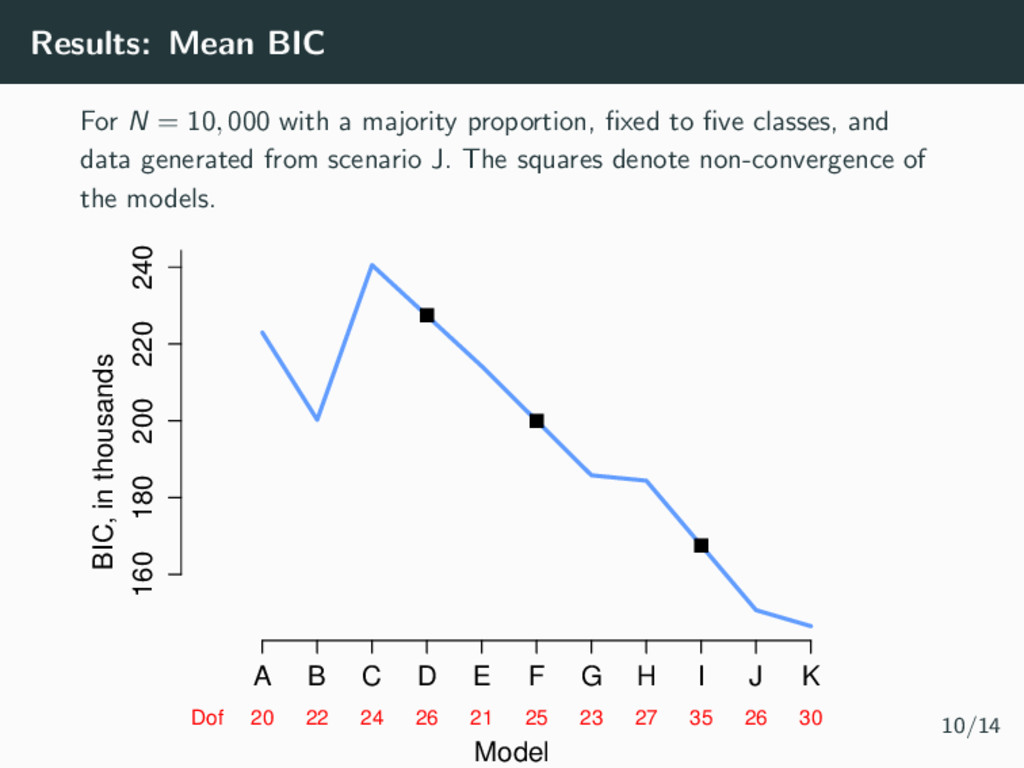
majority proportion, fixed to five classes, and data generated from scenario J. The squares denote non-convergence of the models. Model Dof 20 22 24 26 21 25 23 27 35 26 30 160 180 200 220 240 A B C D E F G H I J K BIC, in thousands 10/14
be used to simplify complex longitudinal data into relatively homogeneous sub-populations • Easy to implement in many software packages (R, Stata, SAS, MPlus, LatentGold, etc) and becoming more popular in epidemiology studies 13/14
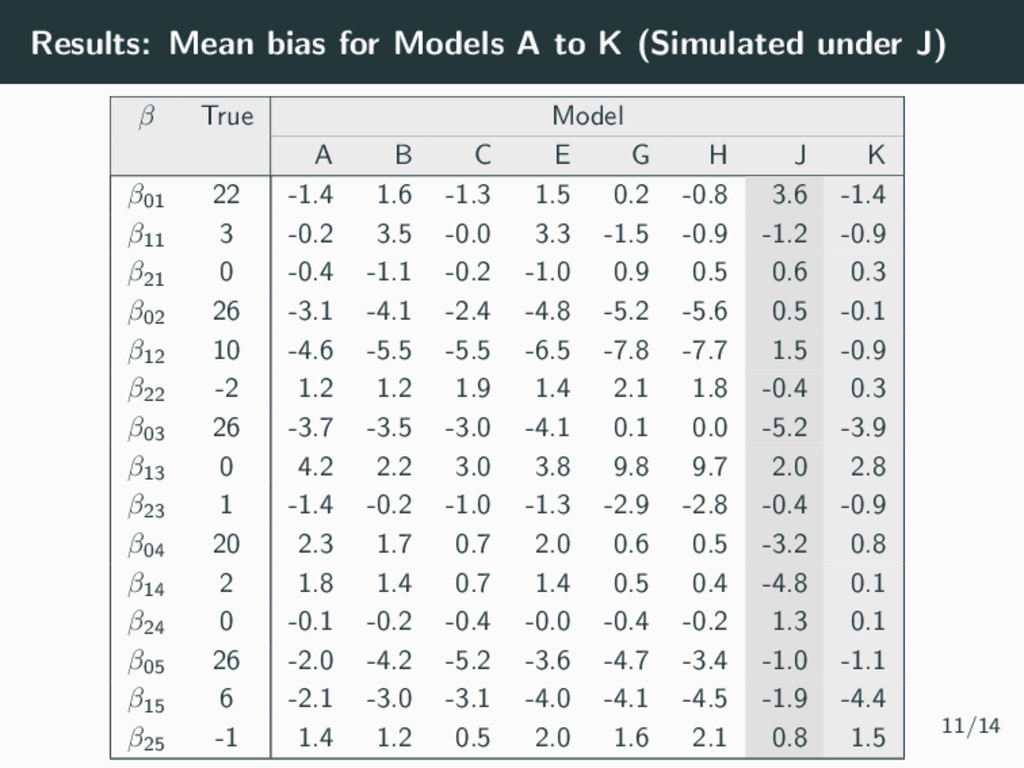
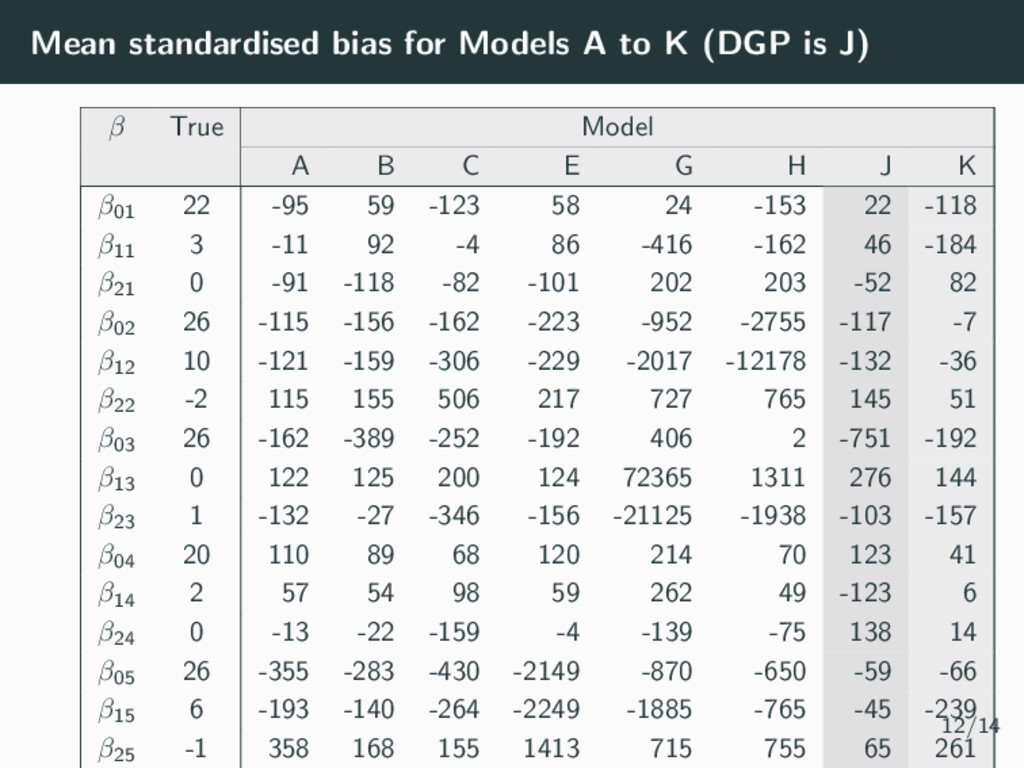
be used to simplify complex longitudinal data into relatively homogeneous sub-populations • Easy to implement in many software packages (R, Stata, SAS, MPlus, LatentGold, etc) and becoming more popular in epidemiology studies • However, the class proportions can be underestimated, affecting the fixed effect estimates and hence the magnitude and size of the trajectories recovered. • The GRoLTS Checklist (2017) can be used to improve reporting standards. • Let’s look deeper into the SEM literature which has already studied many of the emerging questions from epidemiological studies. 13/14
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}