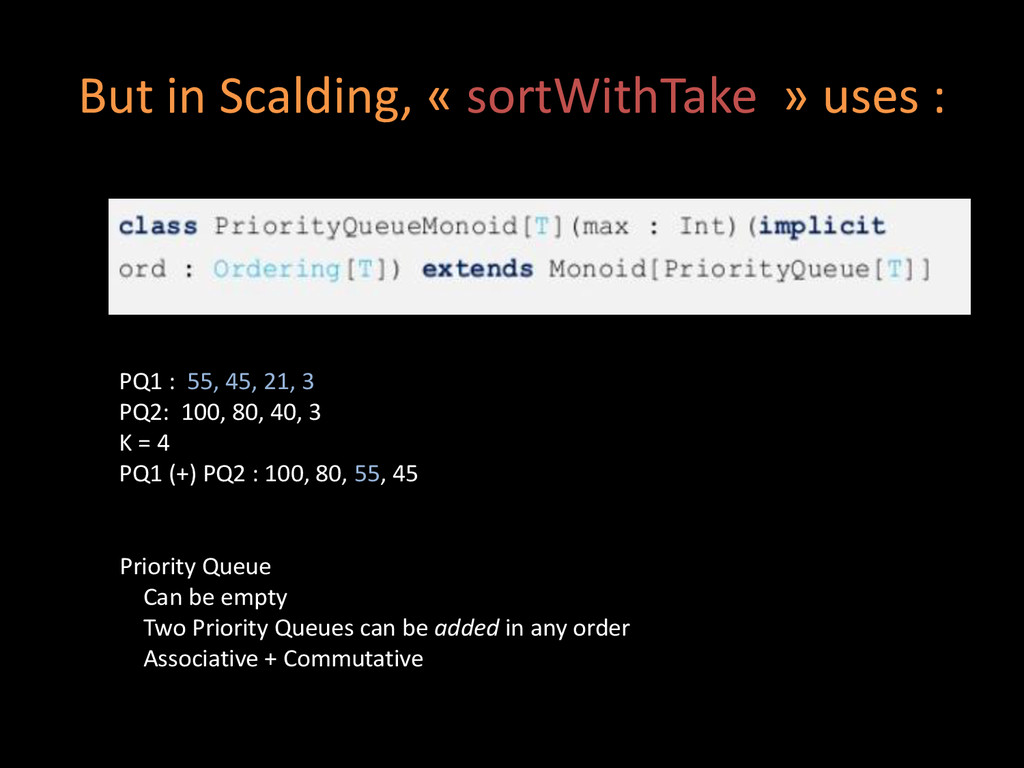
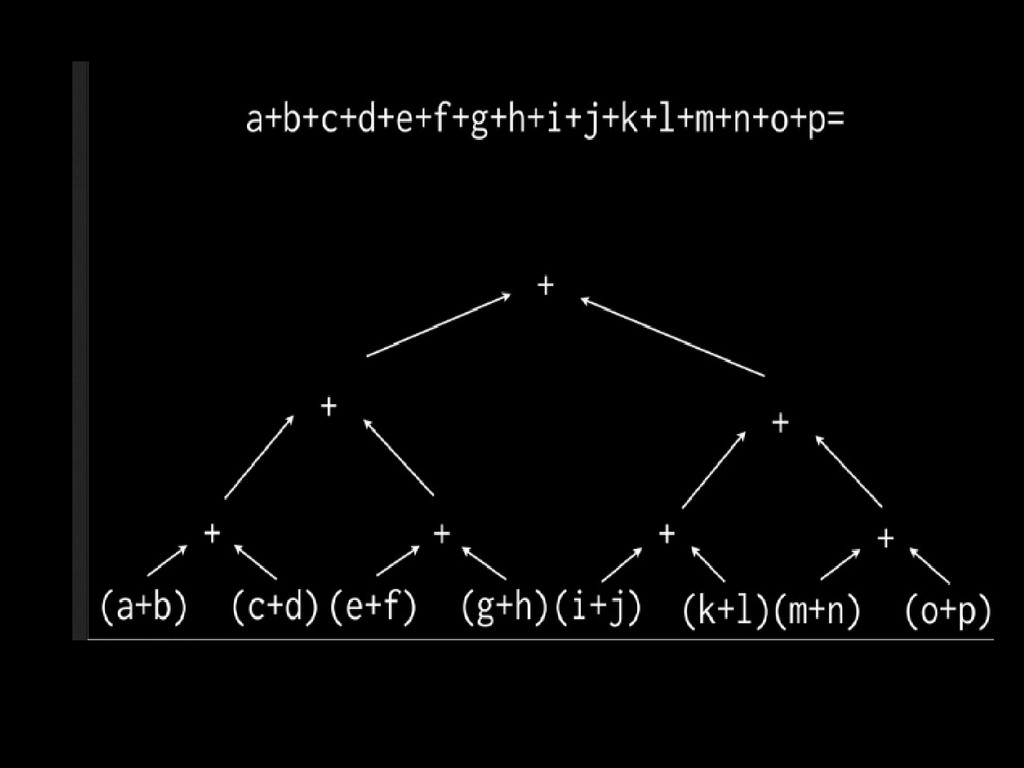
Can be empty Two Priority Queues can be added in any order Associative + Commutative PQ1 : 55, 45, 21, 3 PQ2: 100, 80, 40, 3 K = 4 PQ1 (+) PQ2 : 100, 80, 55, 45
Can be empty Two Priority Queues can be added in any order Associative + Commutative PQ1 : 55, 45, 21, 3 PQ2: 100, 80, 40, 3 K = 4 PQ1 (+) PQ2 : 100, 80, 55, 45 In a single Pass
of data and in fixed memory. • Stream subsampling • Adaptive sliding windows : build decision trees on these windows, e.g Hoeffding Trees • Use time series analysis methods … • Etc
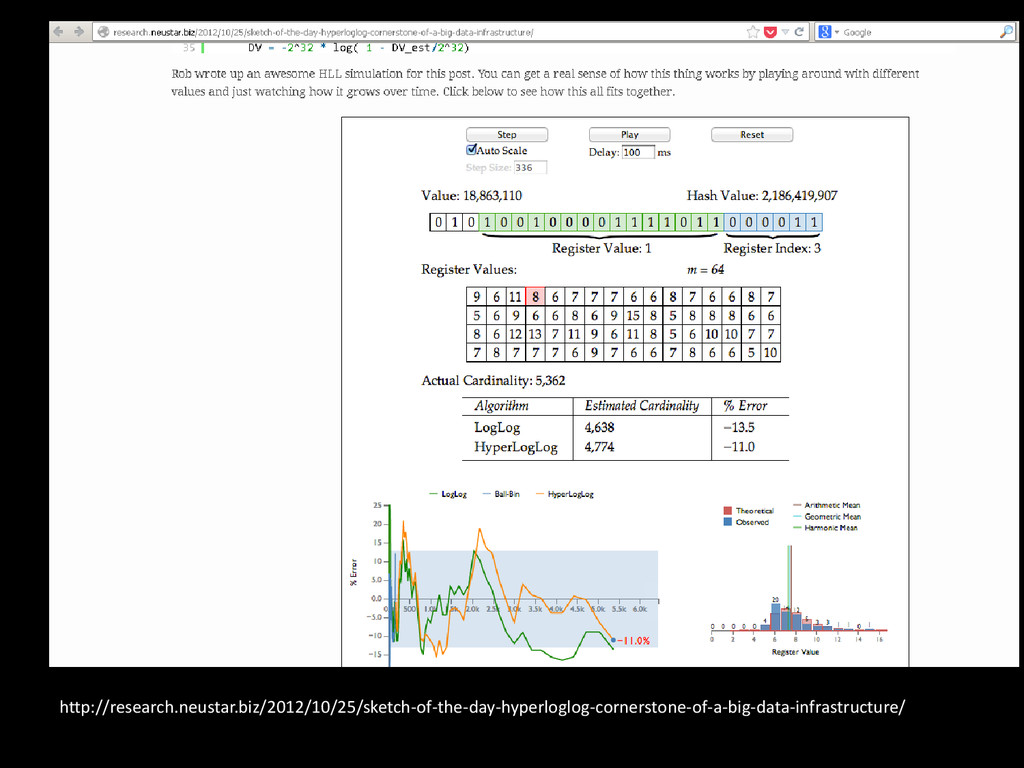
bits chain are rare • But the more bit chains you look at, the more likely you are to find a long one • The longest run of trailing 0-bits seen can be an estimator of the number of unique bit chains observed.
in a continuous stream of data. - Many exist : Q-Tree, Q-Digest, T-Digest - All of those are associative. - Another neat thing : types your data uniformaly.
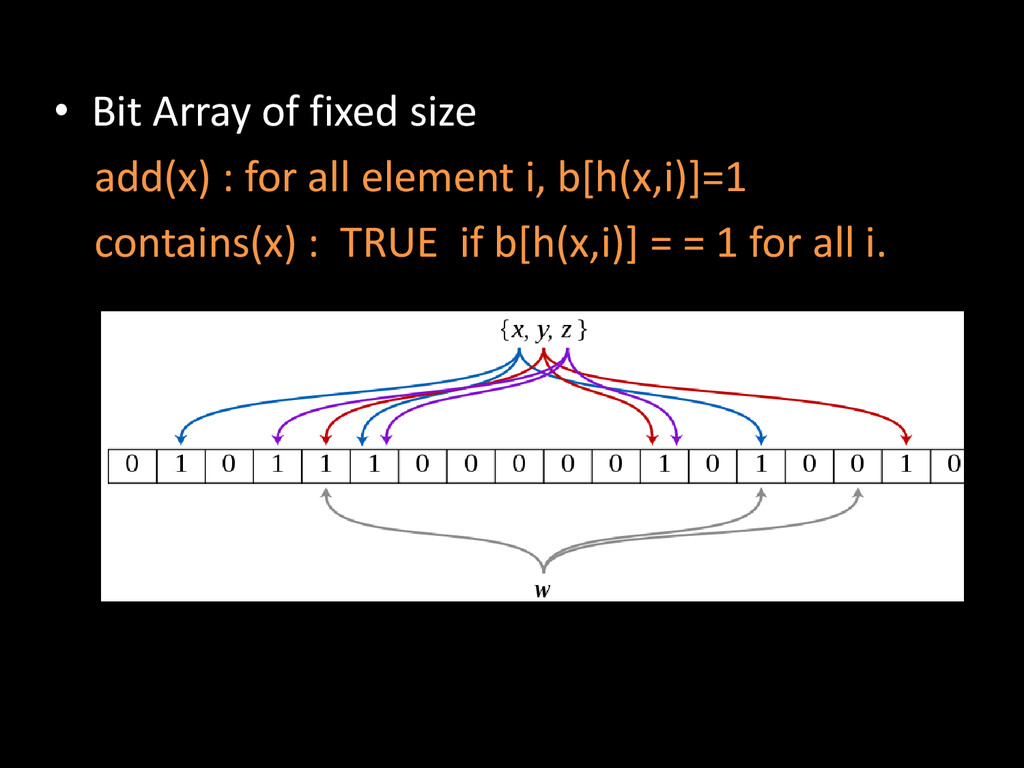
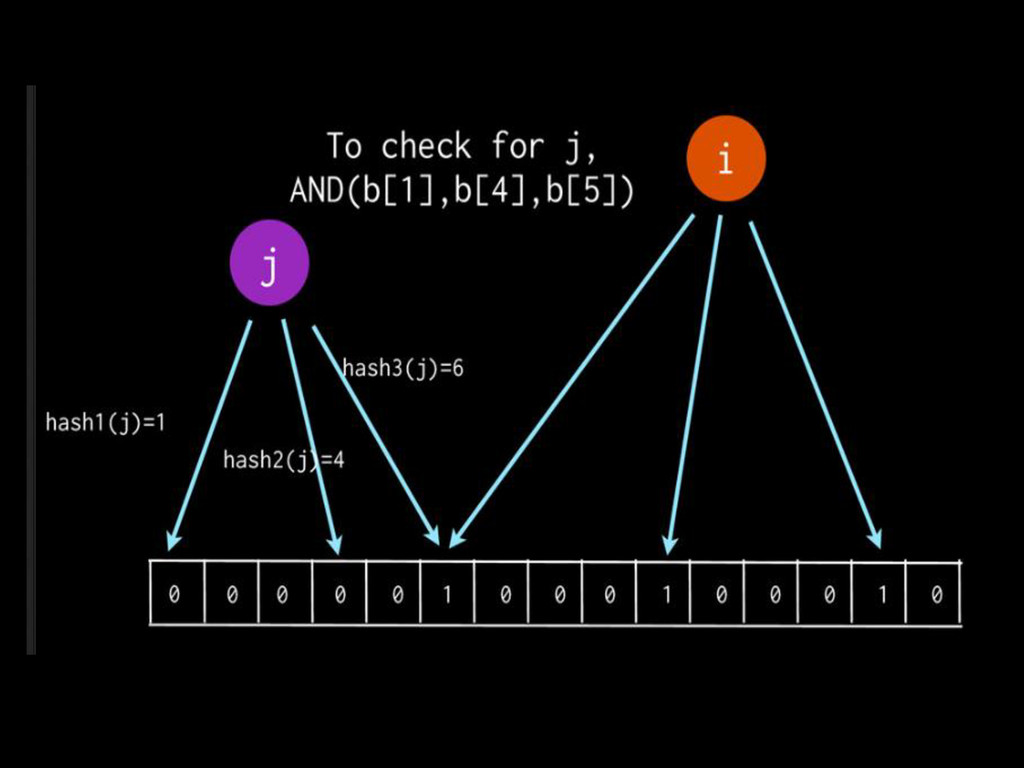
data structures like Set, Map, etc which are easier to reason about as developers • As data size grows, sampling becomes painful, hashing provide better cost effective solution • Abstract algebra with skecthed data is a no brainer, and garantees less error and better scalability of analytics systems. http://speakerdeck.com/samklr
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![HyperLogLog • Popular sketch for cardinality estimation HLL.size = Approx[Number]](https://files.speakerdeck.com/presentations/a74e1360429a0132ac71027560023fad/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}