A bunch of preprocessors munge the input text. 2. A BlockParser parses the high-level structural elements of the pre-processed text into an ElementTree object. 3. A bunch of treeprocessors are run against the ElementTree object. One such treeprocessor (markdown.treeprocessors.InlineProcessor) runs inlinepatterns against the ElementTree object, parsing inline markup. 4. Some postprocessors are run against the text after the ElementTree object has been serialized into text. 5. The output is returned as a string.
def parseBlocks(self, parent: etree.Element, blocks: list[str]) -> None: """ Process blocks of Markdown text and attach to given `etree` node. ... """ while blocks: for processor in self.blockprocessors: if processor.test(parent, blocks[0]): if processor.run(parent, blocks) is not False: # run returns True or None break
etree """Lightweight XML support for Python. XML is an inherently hierarchical data format, and the most natural way to represent it is with a tree. This module has two classes for this purpose: 1. ElementTree represents the whole XML document as a tree and 2. Element represents a single node in this tree.
{kind=link}
{kind=link}
{kind=link}
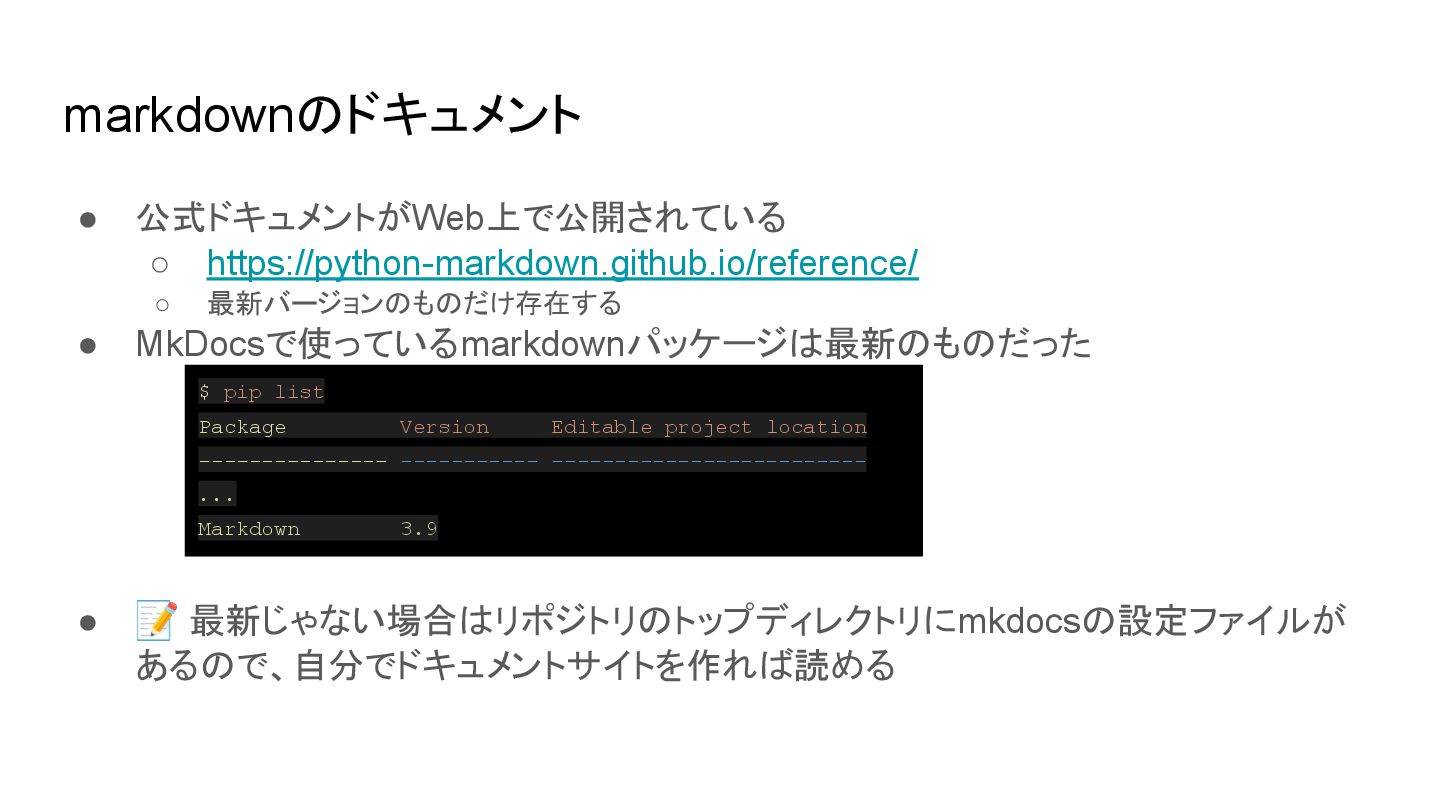{kind=link}
{kind=link}
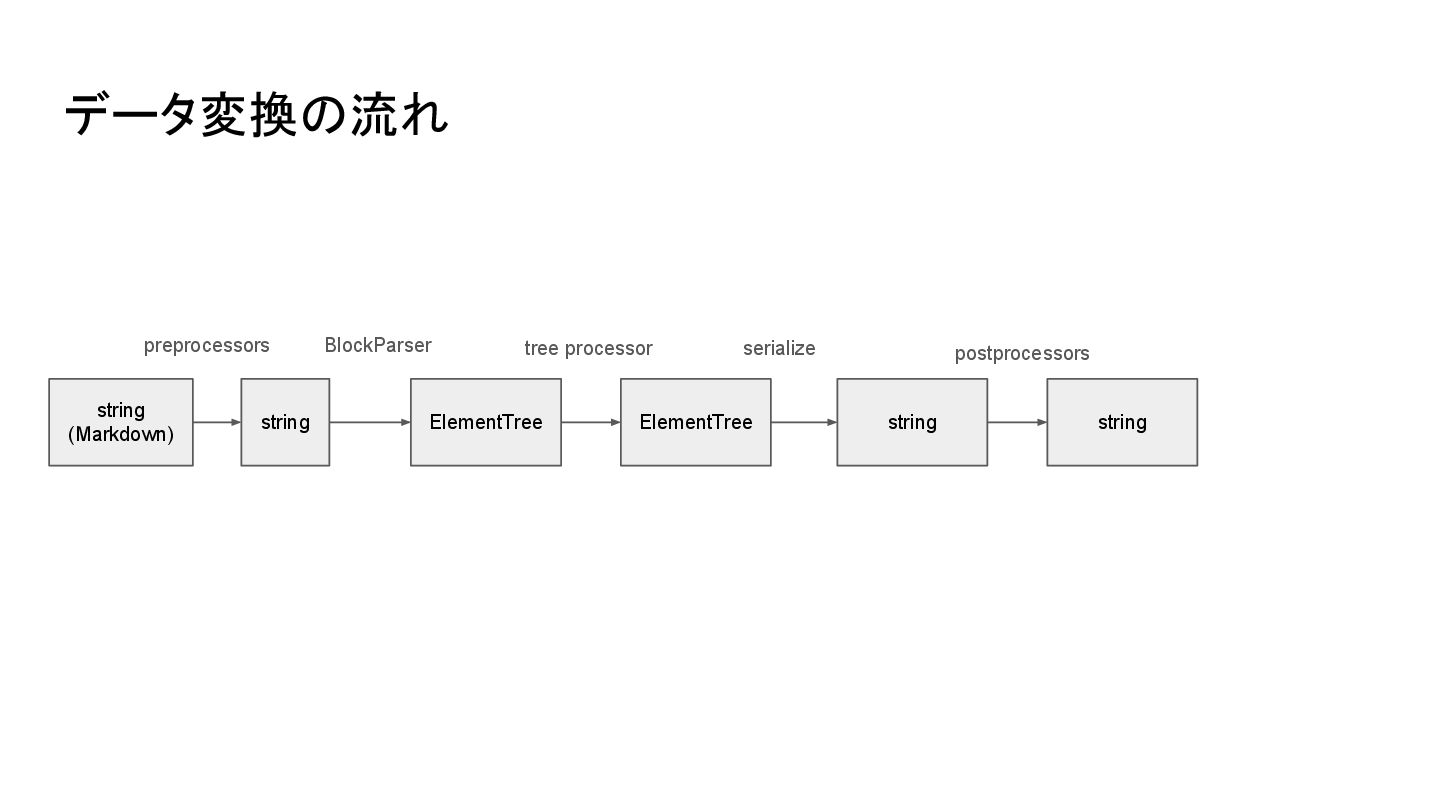{kind=link}
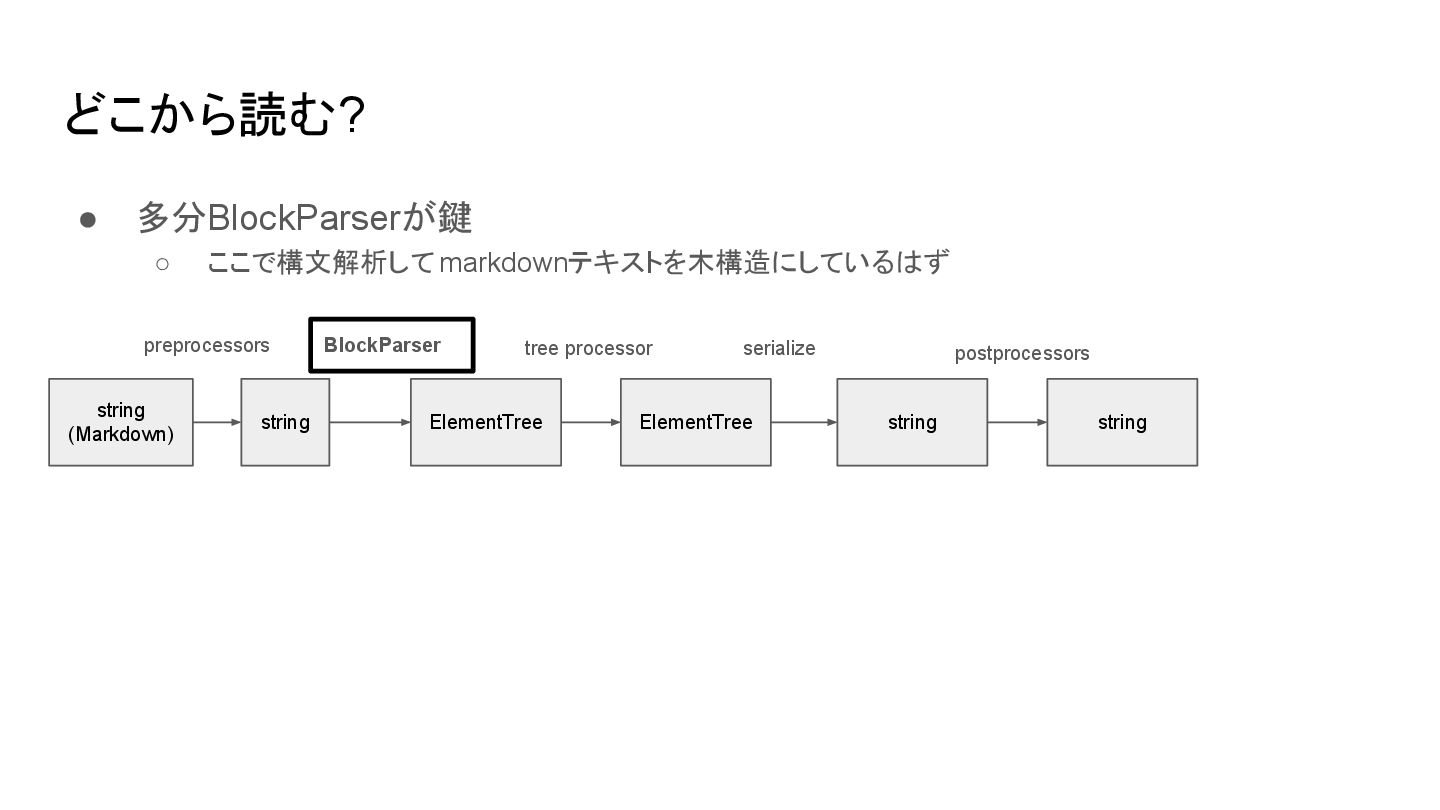{kind=link}
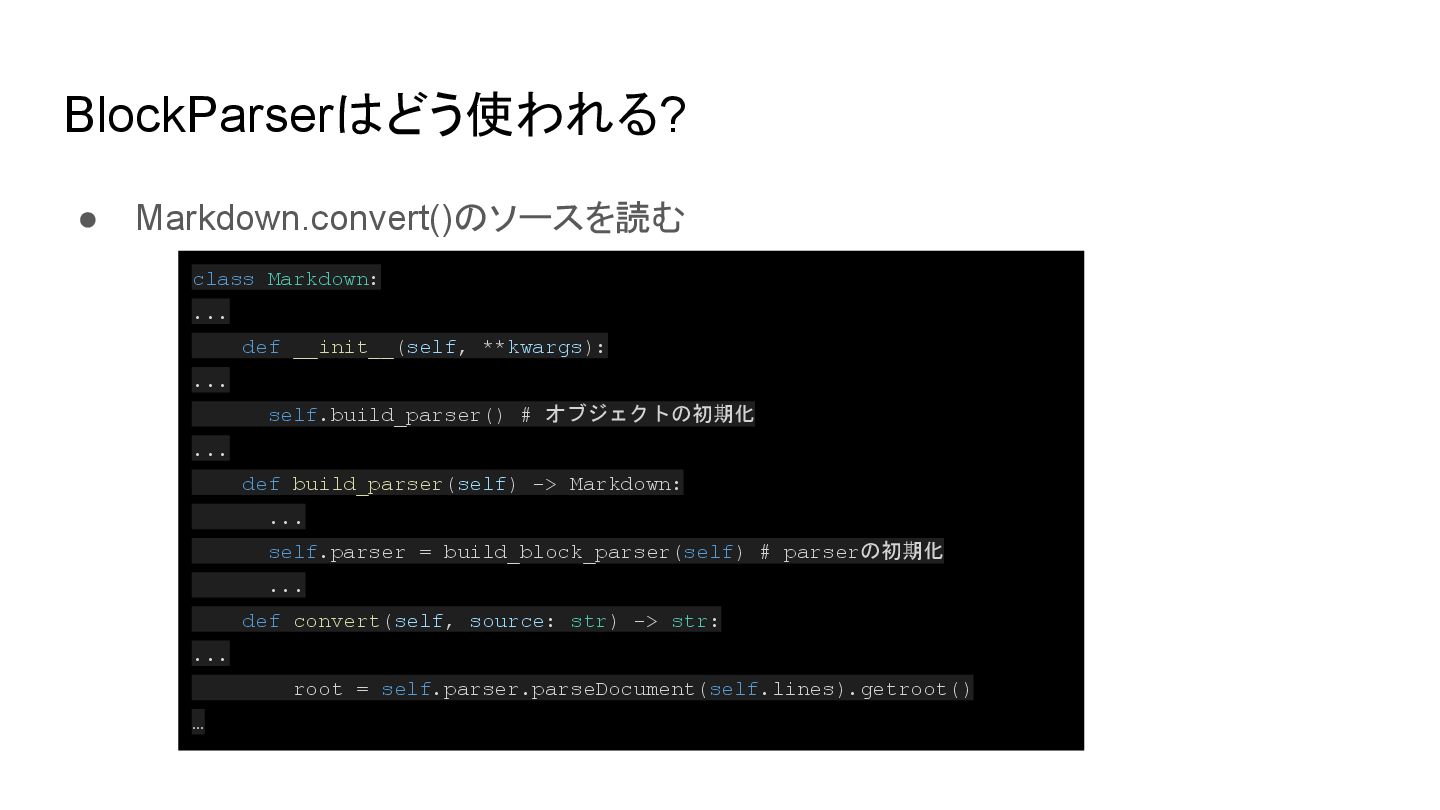{kind=link}
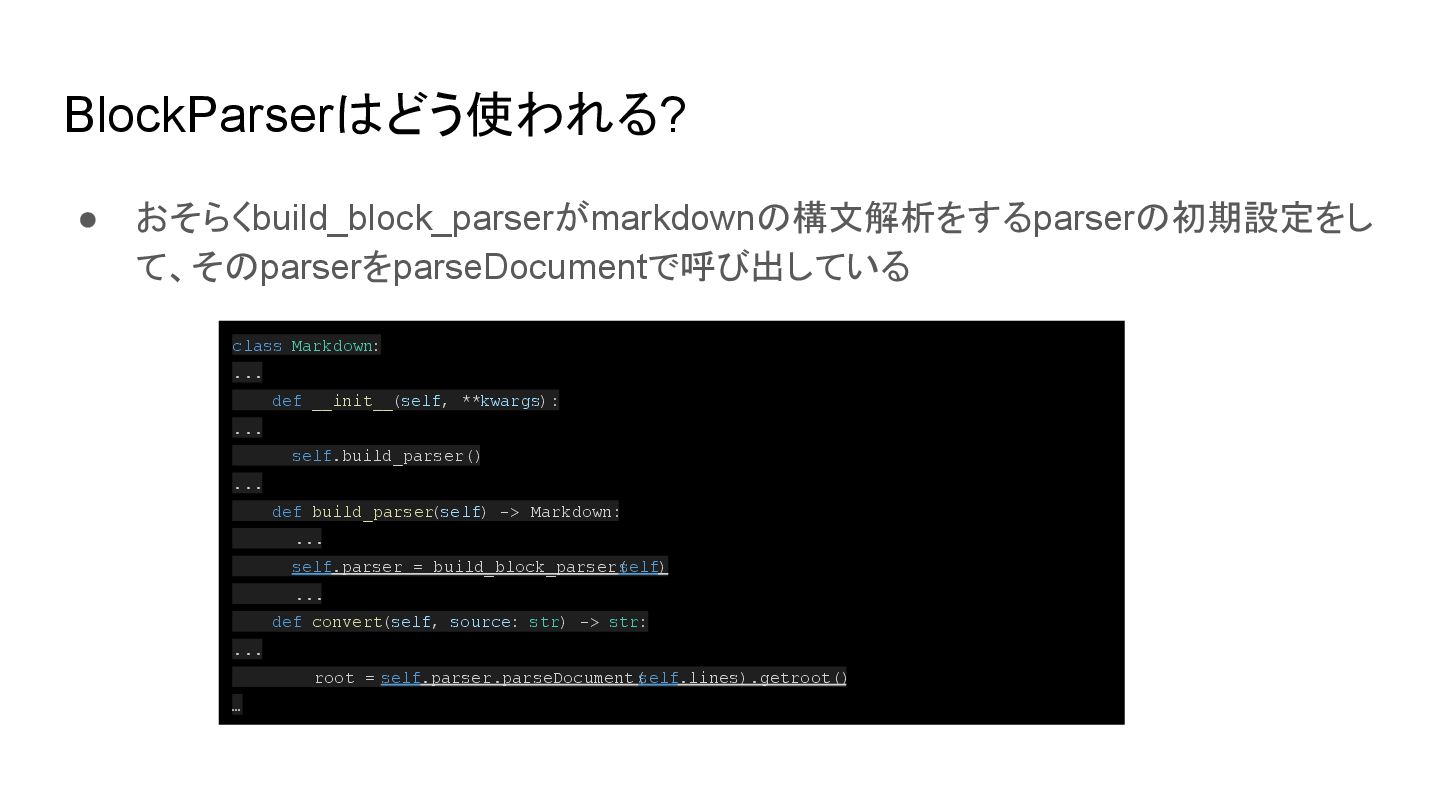{kind=link}
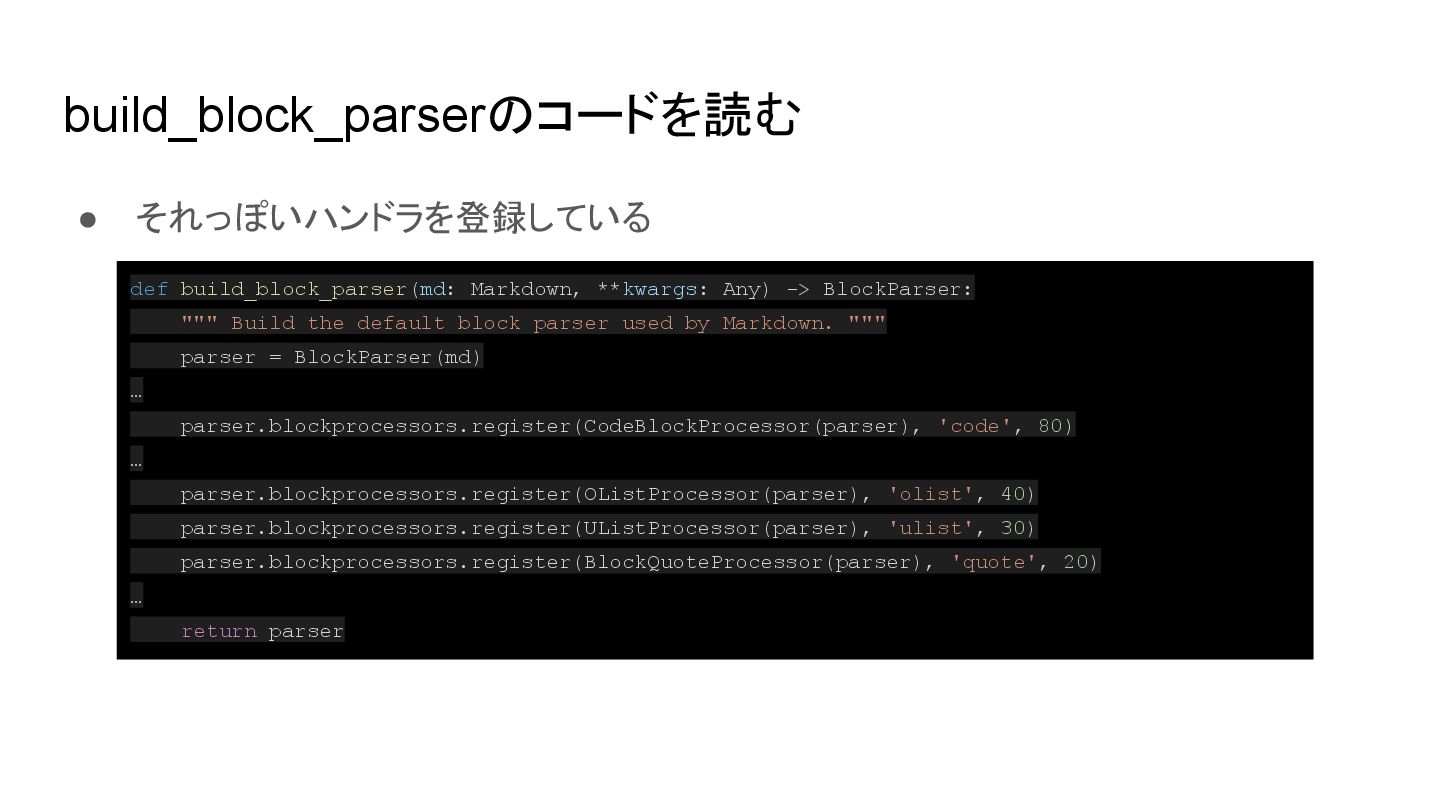{kind=link}
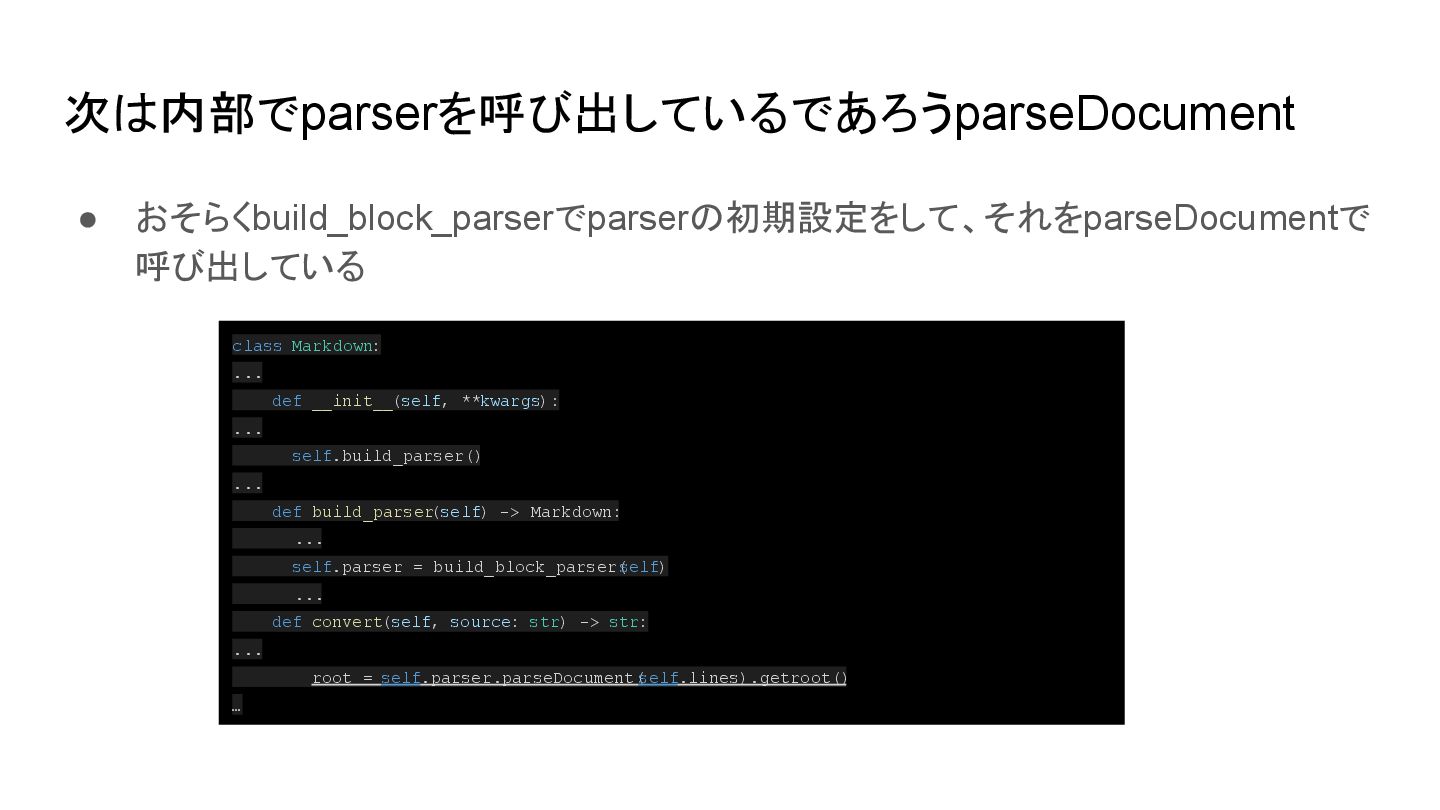{kind=link}
{kind=link}
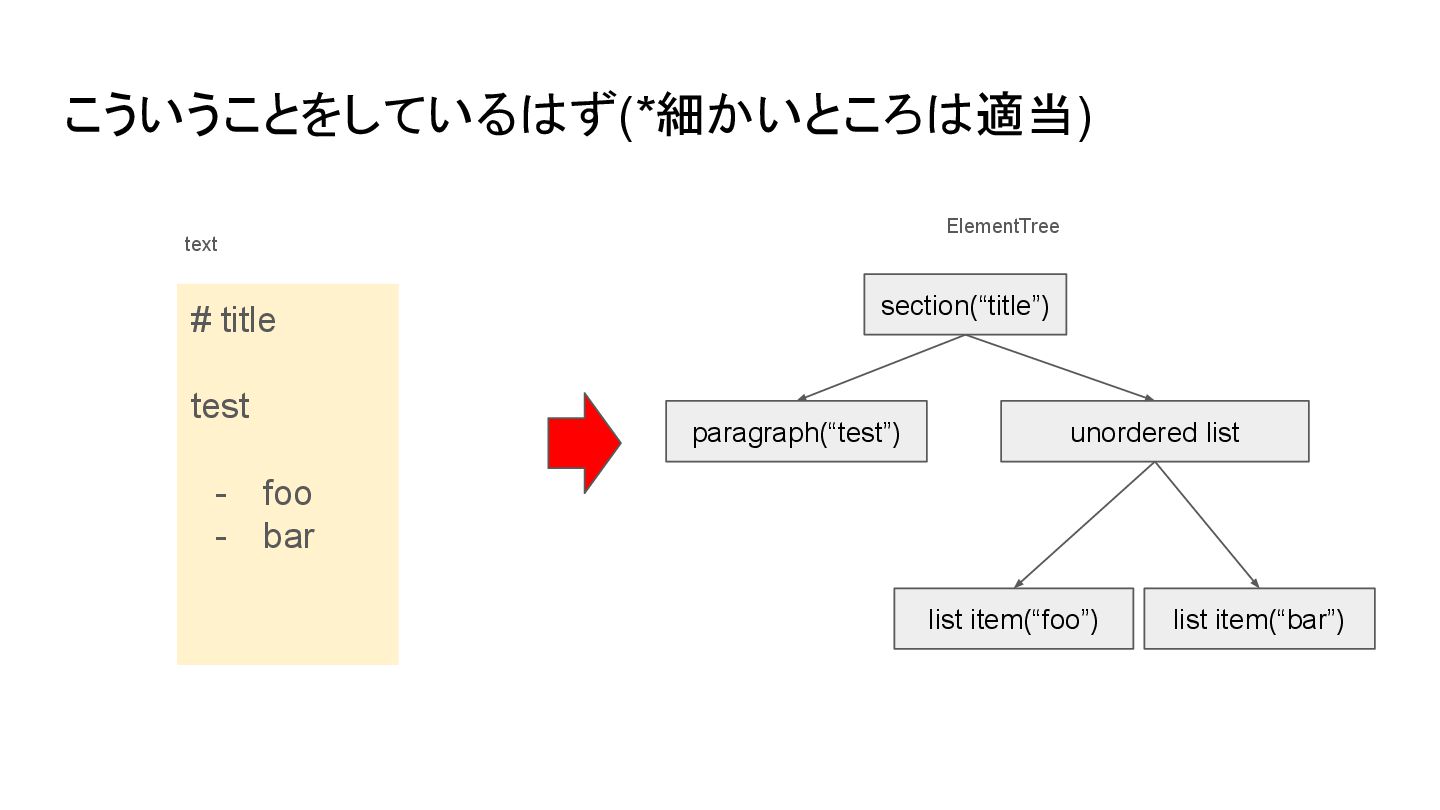{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}