Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
シングルチャネルマルチトーカー音声認識の進展
Search
Ryo Masumura
June 08, 2026
Research
190
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
シングルチャネルマルチトーカー音声認識の進展
Ryo Masumura
June 08, 2026
More Decks by Ryo Masumura
See All by Ryo Masumura
クロスモーダル表現学習の研究動向: 音声関連を中心として
ryomasumura
3
1.3k
MediaGnosis IEEE ICIP2023 Industry Seminar
ryomasumura
0
540
複数人会話データを活用した音声言語処理とアプリケーション(slud研究会招待講演)
ryomasumura
0
1k
2002_Interspeech報告.pdf
ryomasumura
0
550
1907_ICASSP報告.pdf
ryomasumura
0
220
対話コンテキストを扱うターン交替点検出の検討
ryomasumura
0
610
階層再帰型Encoder-Decoderに基づく談話コンテキストEnd-to-End音声認識
ryomasumura
0
800
学会に発表者として継続的に参加するためのセルフマネージメント
ryomasumura
11
8.5k
対話コンテキストを考慮したニューラル通話シーン分割
ryomasumura
1
450
Other Decks in Research
See All in Research
データサイエンティストの就労意識~2015 → 2026 一般(個人)会員アンケートより
datascientistsociety
PRO
0
230
Fukui Shibiten 39 - AI Art
butchi
0
150
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
250
Apache Gravitinoで実現する Icebergカタログ統合とアクセスの一元化
matsumooon
0
350
Cross-Media Information Spaces and Architectures
signer
PRO
0
310
JICA QUEST 共創×革新プログラム Impact Report(海ノ向こうコーヒー)
ontheslope
0
200
nlp2026 In-Context Learningに基づく経路案内のための地理的知識の活用方法に関する検討
takashiinui
0
110
非試合日の野球場を楽しむためのARホームランボールキャッチ体験システムの開発 / EC79-miyazaki
yumulab
0
310
Unified Audio Source Separation (Defense Slides)
kohei_1979
1
630
セマンティック通信勉強会 6Gに向けたデバイス間効率的な通信の技術紹介・課題・今後展望
satai
3
230
Sleuthcon Keynote - How Cybercriminals (ab)use AI
fr0gger
0
250
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
520
Featured
See All Featured
The Mindset for Success: Future Career Progression
greggifford
PRO
0
420
Evolving SEO for Evolving Search Engines
ryanjones
0
240
Thoughts on Productivity
jonyablonski
76
5.2k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
280
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
390
Six Lessons from altMBA
skipperchong
29
4.3k
The SEO identity crisis: Don't let AI make you average
varn
0
520
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
460
Transcript
© NTT, Inc. 2025 シングルチャネル マルチトーカー音声認識の進展 増村 亮 NTT株式会社 人間情報研究所
1 © NTT, Inc. 2026 ◼ 増村 亮 (Ryo Masumura)
⚫ 経歴 • 2011/4: 日本電信電話株式会社入社 • 2016/9: 東北大学大学院 工学研究科 博士後期課程 修了 • 現在: NTT株式会社 人間情報研究所 特別研究員 ⚫ 主な研究分野: マルチメディア処理×人工知能 (機械学習) • 音声音響処理全般 (2009~) • 自然言語処理全般 (2011~) • 画像映像処理全般 (2019~) この「広さ」を深めることで はじめて実現可能な 研究開発を目指す • 音声認識(言語モデル、音響モデル、End2End音声認識)、属性推定、感情推定、 話者推定・ダイアライゼーション、音声区間検出、ターン交代点検出、言語・方言識別、音声合成、etc. • 2011/3:東北大学大学院 工学研究科 博士前期課程 修了 • クロスタスク・クロスモーダルな統合モデリング (2017~) 自己紹介
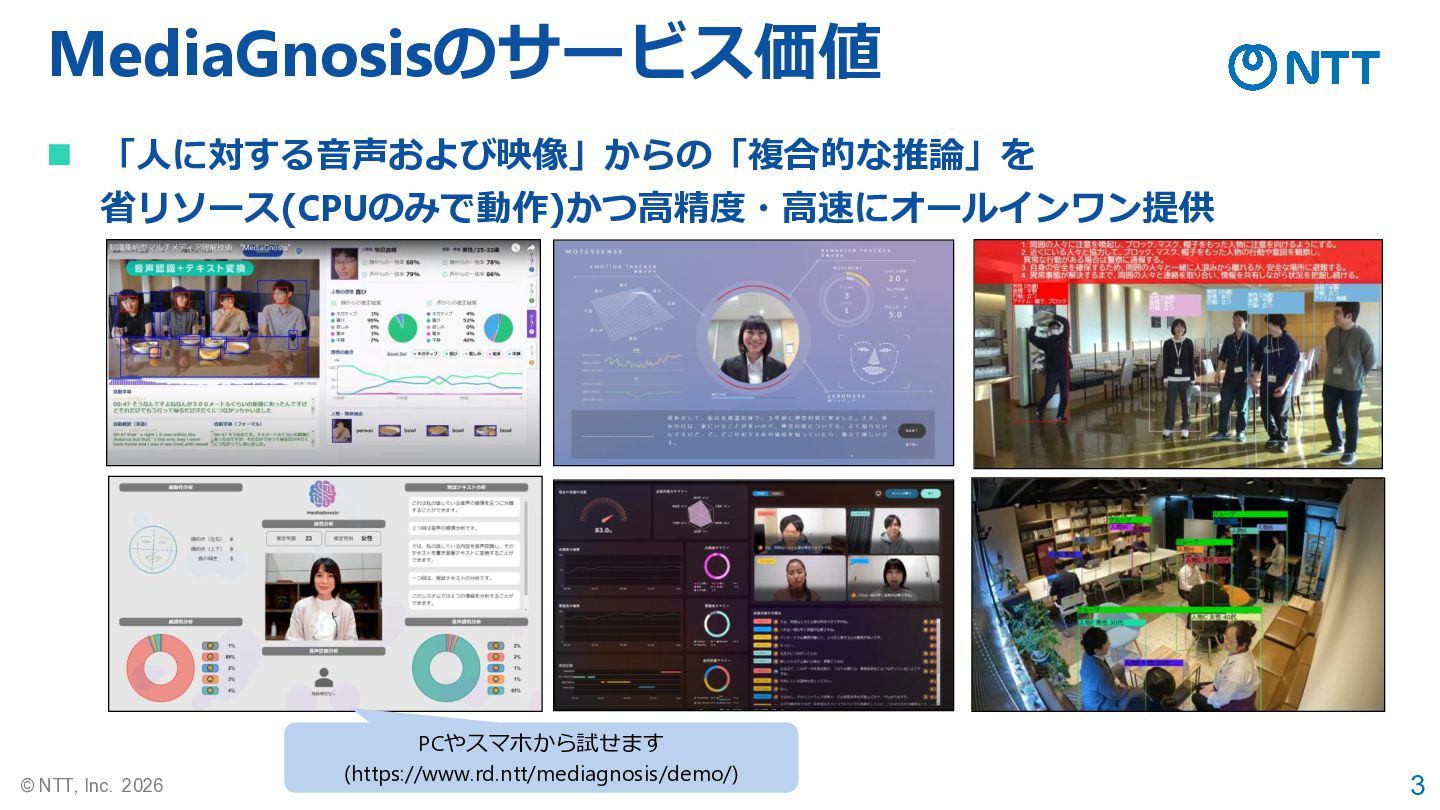
2 © NTT, Inc. 2026 ◼ 「人を音声・映像から理解する」ことを主眼とした、クロスタスク・ クロスモーダルでの知識統合によるマルチモーダル基盤モデルの実現 ⚫ NTTにて「MediaGnosis」という名前で研究開発
(https://www.rd.ntt/mediagnosis/) メインで取り組んでいる研究テーマ ⚫ 「クロスモーダルでの知識統合」 に関する部分は、ASJ2024Sにて 機会を頂いた際の私の講演にて解説
3 © NTT, Inc. 2026 ◼ 「人に対する音声および映像」からの「複合的な推論」を 省リソース(CPUのみで動作)かつ高精度・高速にオールインワン提供 MediaGnosisのサービス価値 PCやスマホから試せます
(https://www.rd.ntt/mediagnosis/demo/)
4 © NTT, Inc. 2026 MediaGnosisに基づく商用サービス基盤 ◼ NTTテクノクロスの「SpeechRec」という商用サービス基盤などを通して、 NTTグループの様々な事業領域からBtoB、BtoCに展開 ⚫
SpeechRec: 「音声認識」や「音声感情認識」「表情認識」等のモジュールレベルの 利用から、音声+映像の系を含めた複合的な系まで広く機能を利用可能
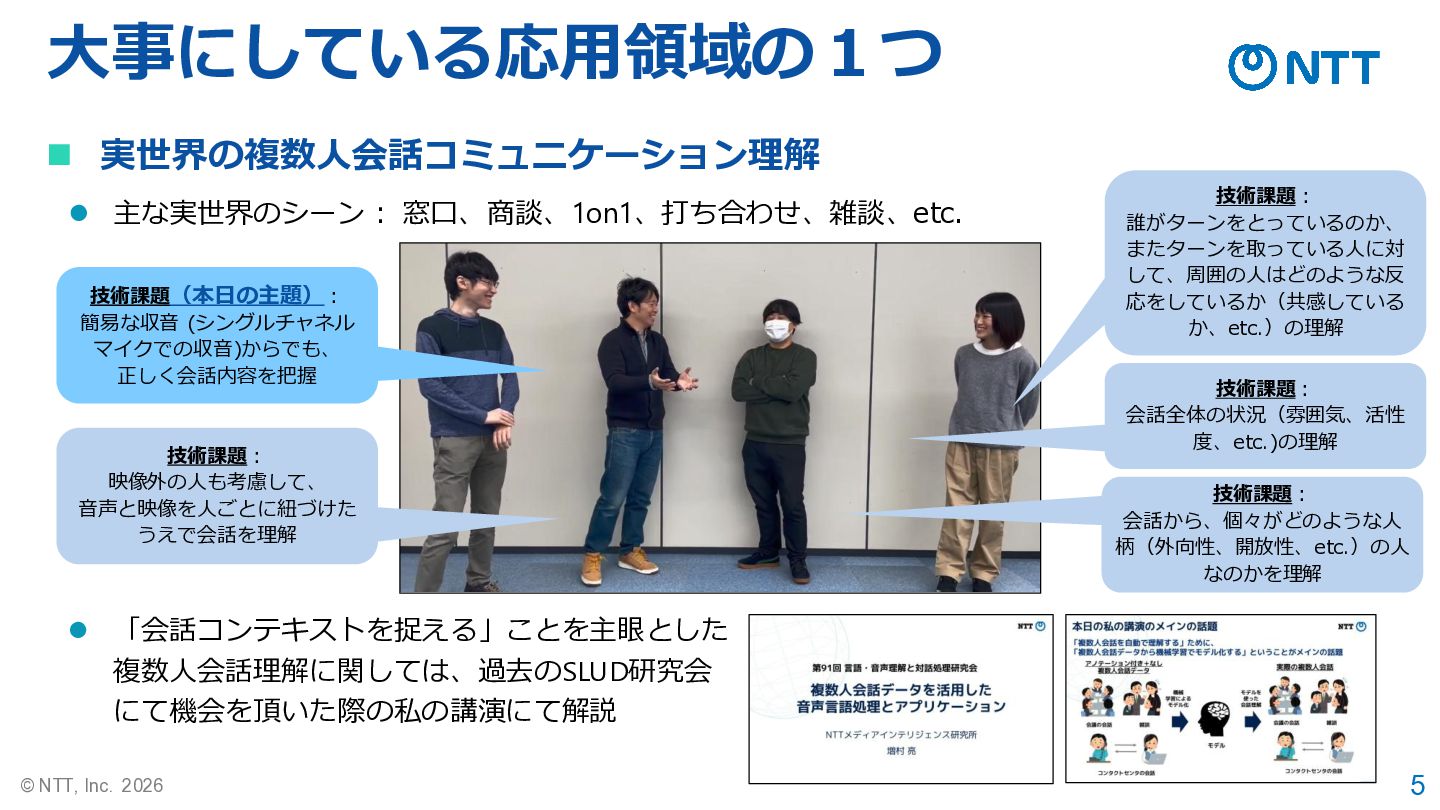
5 © NTT, Inc. 2026 ◼ 実世界の複数人会話コミュニケーション理解 ⚫ 「会話コンテキストを捉える」ことを主眼とした 複数人会話理解に関しては、過去のSLUD研究会
にて機会を頂いた際の私の講演にて解説 技術課題(本日の主題): 簡易な収音 (シングルチャネル マイクでの収音)からでも、 正しく会話内容を把握 技術課題: 誰がターンをとっているのか、 またターンを取っている人に対 して、周囲の人はどのような反 応をしているか(共感している か、etc.)の理解 技術課題: 映像外の人も考慮して、 音声と映像を人ごとに紐づけた うえで会話を理解 ⚫ 主な実世界のシーン: 窓口、商談、1on1、打ち合わせ、雑談、etc. 技術課題: 会話全体の状況(雰囲気、活性 度、etc.)の理解 技術課題: 会話から、個々がどのような人 柄(外向性、開放性、etc.)の人 なのかを理解 大事にしている応用領域の1つ
6 © NTT, Inc. 2026 本日の内容 ◼ End-to-End型のシングルチャネルマルチトーカー音声認識の進展について、 我々の取り組みも絡めながら、研究動向を概説 1.
自己紹介と前置き 2. マルチトーカー音声認識の基礎とEnd-to-End型の登場 3. End-to-Endマルチトーカー音声認識の研究動向 4. おわりに マルチチャネルマルチトーカー音声認識 もあるが本日は基本的に省略、 以降、シングルチャネルのものを、 「マルチトーカー音声認識」と呼ぶ
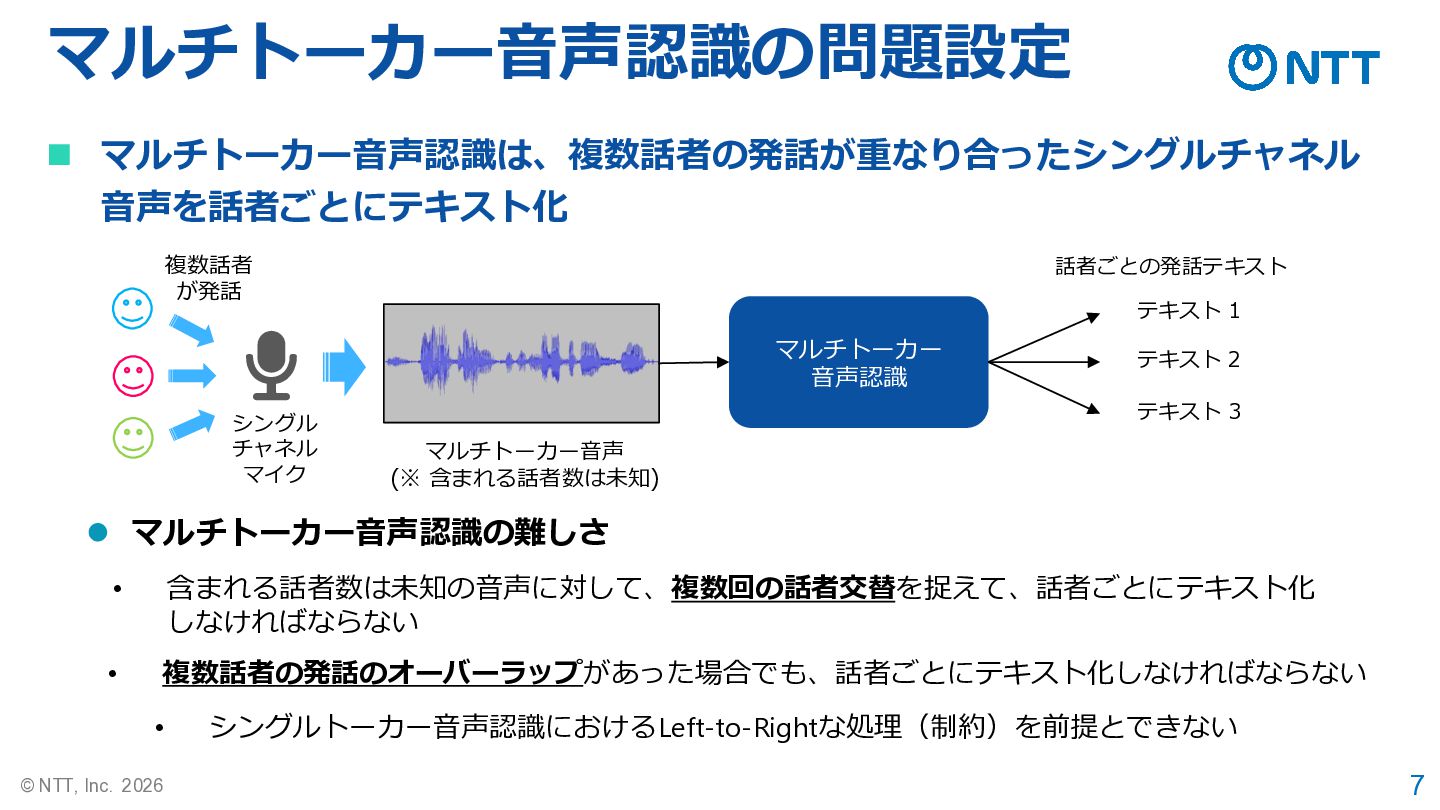
7 © NTT, Inc. 2026 マルチトーカー音声認識の問題設定 ◼ マルチトーカー音声認識は、複数話者の発話が重なり合ったシングルチャネル 音声を話者ごとにテキスト化 シングル
チャネル マイク マルチトーカー音声 (※ 含まれる話者数は未知) 複数話者 が発話 ⚫ マルチトーカー音声認識の難しさ • 含まれる話者数は未知の音声に対して、複数回の話者交替を捉えて、話者ごとにテキスト化 しなければならない • 複数話者の発話のオーバーラップがあった場合でも、話者ごとにテキスト化しなければならない 話者ごとの発話テキスト テキスト 1 テキスト 2 テキスト 3 マルチトーカー 音声認識 • シングルトーカー音声認識におけるLeft-to-Rightな処理(制約)を前提とできない
8 © NTT, Inc. 2026 音声例と我々の実用向けモデルの結果 ※ LLMで使うBillionオーダーで書くと、約0.03Bのモデルでの動作 Spk1: 0.0-12:00s
まおっしゃっていましてーなのでちょっとは いこの後ちょっとA社さんとの打ち合わせもあるのでーちょっと進 め方について山田課長にアドバイスいただきたいっていうのと Spk1: 13.5-27s そうですねーでなんかそもそもこういうまーな んか認識の齟齬っていうのがー来てしまったのももう課題だと思う のでーなんかそのそれについて防ぐためのアドバイスっていうのも あのー頂きたいなっていうふうに思っています Spk1: 28.5-29.0s はい Spk1: 31.0-31.5s はい Spk1: 34.0-34.5s はい Spk1: 35.0-35.5s はい Spk1: 36.0-36.5s そうです Spk1: 37.5-38.0s はい Spk1: 43.0-43.5s はい Spk1: 44.5-45.0s はい Spk1: 45.5-46.0s はい Spk1: 49.5-52.0s そうですそうですそういうことですはい ◼ 1モデルのEnd-to-Endマルチトーカー音声認識による1on1会話への処理結果 Spk2: 0.5-1.0s うん Spk2: 1.5-3.0s ほーほーほー Spk2: 5.5-6.5s うんうん Spk2: 7.0-7.5s うん Spk2: 11.5-13.5s なーるほどね Spk2: 14.5-15.0s うんうん Spk2: 18.5-19.0s うーん Spk2: 21.5-22.5s うーんうんうんうん Spk2: 25.0-25.1s うんうんうんうう Spk2: 27.0-51.0s あなるほどでも認識の底があったっ ていうことはあのー鈴木さん自身がもうなんか今自覚して るっていうふうに感じるんだけどそれはそうなのあそうか そうかまあれかじゃあ言った鈴木さんはあの百個以上じゃ ないと値引きできないって言ったつもりだけど向こう的に はそのーA社的には九十でも値引きしてくれよって言って るっていうことだよね Spk2: 52.0-55.0s なるほどねー ※ 改行2回連続は、スライド上での見やすさのために私が手動で挿入 グレーは認識誤り ※ ここは「齟齬」
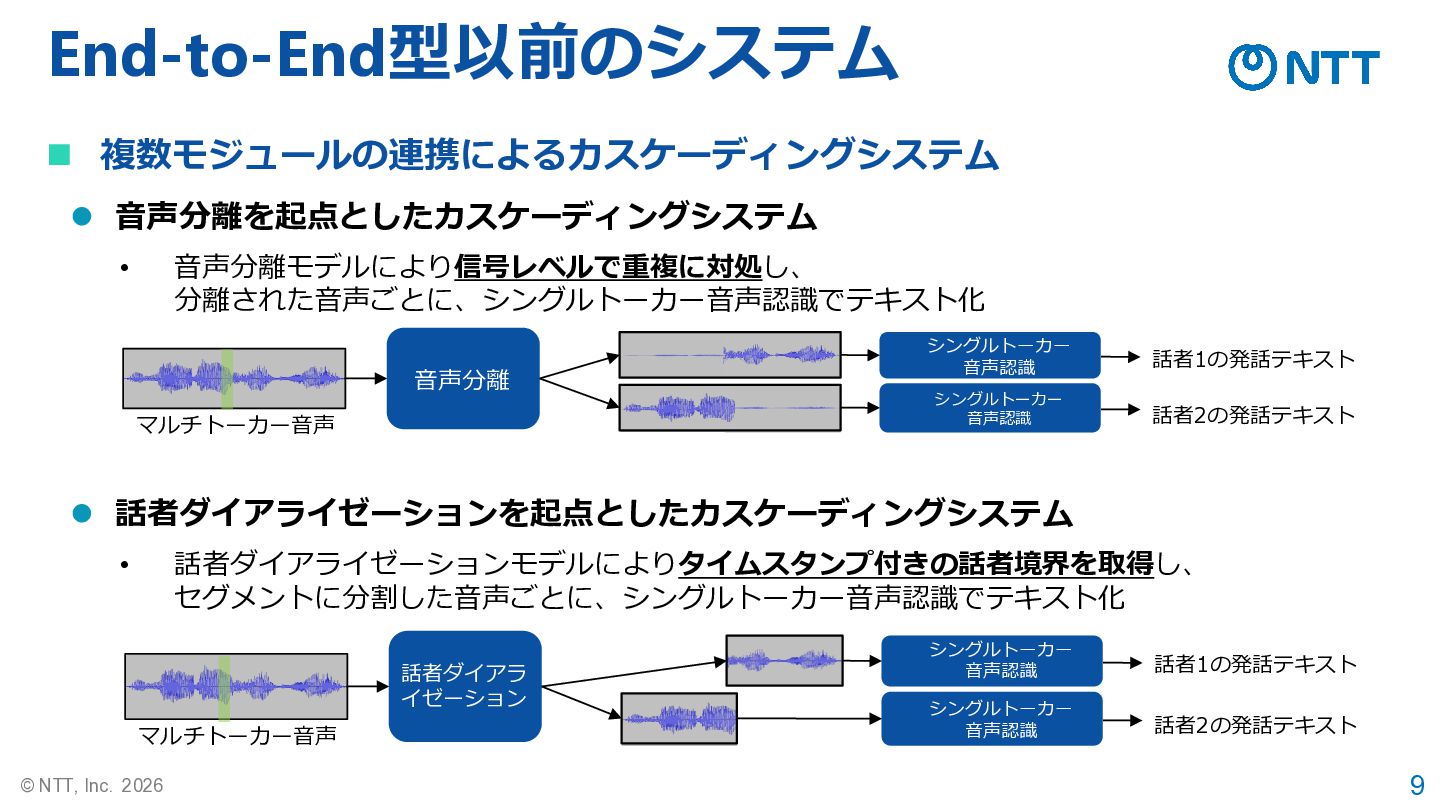
9 © NTT, Inc. 2026 End-to-End型以前のシステム ◼ 複数モジュールの連携によるカスケーディングシステム ⚫ 音声分離を起点としたカスケーディングシステム
⚫ 話者ダイアライゼーションを起点としたカスケーディングシステム • 音声分離モデルにより信号レベルで重複に対処し、 分離された音声ごとに、シングルトーカー音声認識でテキスト化 • 話者ダイアライゼーションモデルによりタイムスタンプ付きの話者境界を取得し、 セグメントに分割した音声ごとに、シングルトーカー音声認識でテキスト化 音声分離 シングルトーカー 音声認識 シングルトーカー 音声認識 話者1の発話テキスト 話者2の発話テキスト マルチトーカー音声 話者ダイアラ イゼーション シングルトーカー 音声認識 シングルトーカー 音声認識 話者1の発話テキスト 話者2の発話テキスト マルチトーカー音声
10 © NTT, Inc. 2026 2010年代後半の音声分離 ◼ 未知の話者同士のオーバーラップを分離できる方式が確立されるとともに、 End-to-Endな最適化も実現できるようになった ⚫
Deep Clusteringに戻づく音声分離 [Hershey 2016] • 時間周波数領域で、同じ音源(同じ話者)に由来する ビンが同じ特徴量となるように、異なる話者に由来す るビンが異なる特徴量になるように、学習されたモデ ルを使い、類似した特徴ごとに分離 ⚫ Permutation Invariant Training (PIT) に基づくEnd-to-End音声分離 [Yu+ 2016] • 音声分離をEnd-to-Endでモデル化する際に直面する複 数の割り当てパターンの可能性がある問題 (Permutation問題)に対して、あらゆる可能性を考慮し たうえで、割り当てが最もマッチするように学習 John R. Hershey, Zhuo Chen, Jonathan Le Roux, Shinji Watanabe, "Deep clustering: Discriminative embeddings for segmentation and separation", ICASSP 2016. Dong Yu, Morten Kolbæk, Zheng-Hua Tan, Jesper Jensen, "Permutation invariant training of deep models for speaker-independent multi-talker speech separation", ICASSP 2017. PITでは割り当てが最も マッチするように学習 時間周波数ビンごとに埋め込み ベクトル化して、クラスタリング
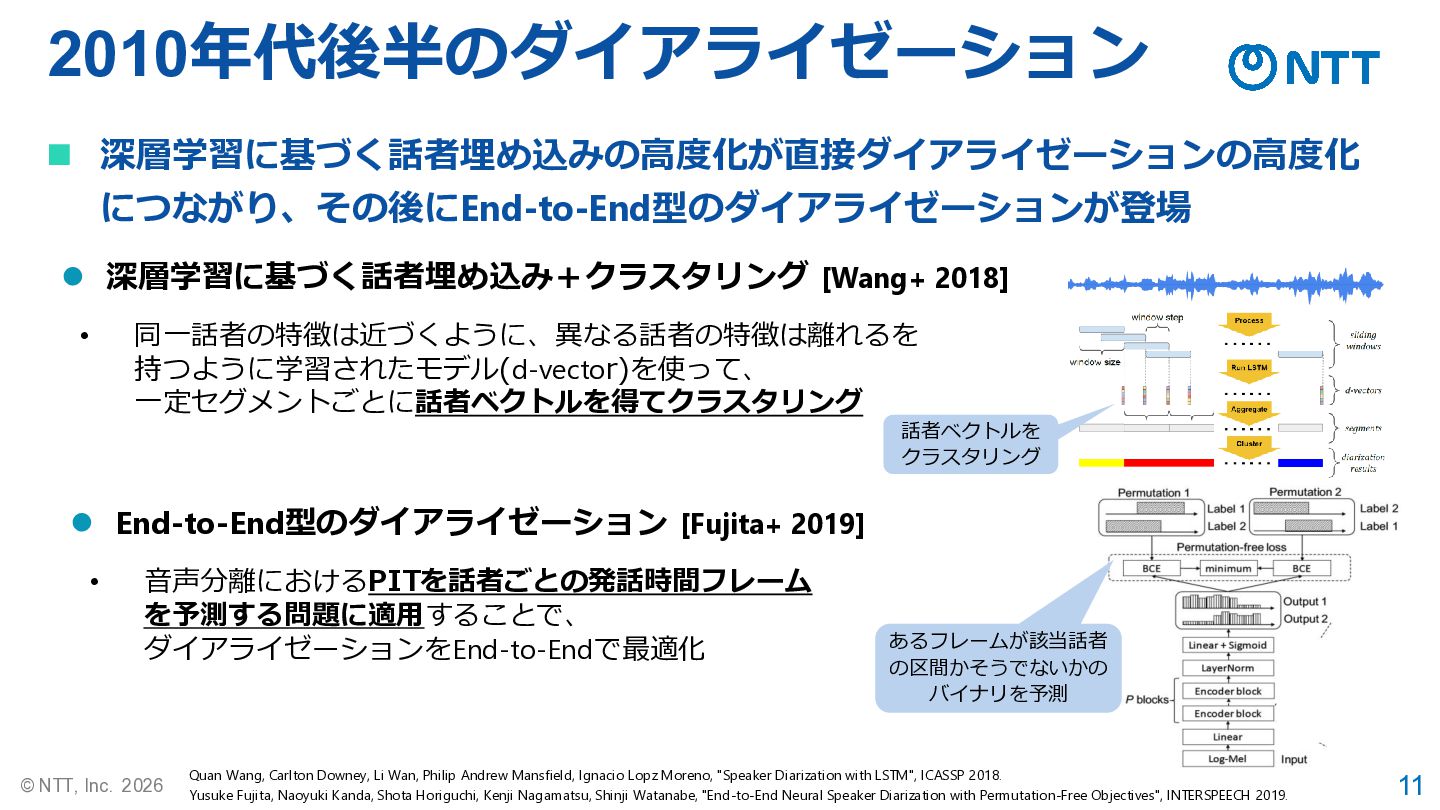
11 © NTT, Inc. 2026 2010年代後半のダイアライゼーション Quan Wang, Carlton Downey,
Li Wan, Philip Andrew Mansfield, Ignacio Lopz Moreno, "Speaker Diarization with LSTM", ICASSP 2018. Yusuke Fujita, Naoyuki Kanda, Shota Horiguchi, Kenji Nagamatsu, Shinji Watanabe, "End-to-End Neural Speaker Diarization with Permutation-Free Objectives", INTERSPEECH 2019. ⚫ 深層学習に基づく話者埋め込み+クラスタリング [Wang+ 2018] ⚫ End-to-End型のダイアライゼーション [Fujita+ 2019] • 音声分離におけるPITを話者ごとの発話時間フレーム を予測する問題に適用することで、 ダイアライゼーションをEnd-to-Endで最適化 • 同一話者の特徴は近づくように、異なる話者の特徴は離れるを 持つように学習されたモデル(d-vector)を使って、 一定セグメントごとに話者ベクトルを得てクラスタリング ◼ 深層学習に基づく話者埋め込みの高度化が直接ダイアライゼーションの高度化 につながり、その後にEnd-to-End型のダイアライゼーションが登場 話者ベクトルを クラスタリング あるフレームが該当話者 の区間かそうでないかの バイナリを予測
12 © NTT, Inc. 2026 カスケーディングシステムの課題 ◼ 複数人の音声をテキスト化することに対して最適化されたシステムではない ⚫ 音声分離を起点としたカスケーディングシステムの課題
⚫ 話者ダイアライゼーションを起点とした カスケーディングシステムの課題 • 音声分離モデルは通常、音声認識性能に対してではなく信号レベルの分離を最適化するため、 音声認識に対しては適していない • 特に過剰に削られた音声(アーティファクトを含む音声)は、音声認識には悪影響 • 音声分離時点でエラーが起きると、音声認識にエラーが伝搬して大幅に性能劣化 • 複数話者がオーバーラップする部分があると、ダイアライゼーション後のセグメントにも 依然としてオーバーラップ音声が残り、後段の音声認識ではうまく扱えない • 話者ダイアライゼーション時点でエラーが起きると、音声認識にエラーが伝搬して大幅に性能劣化
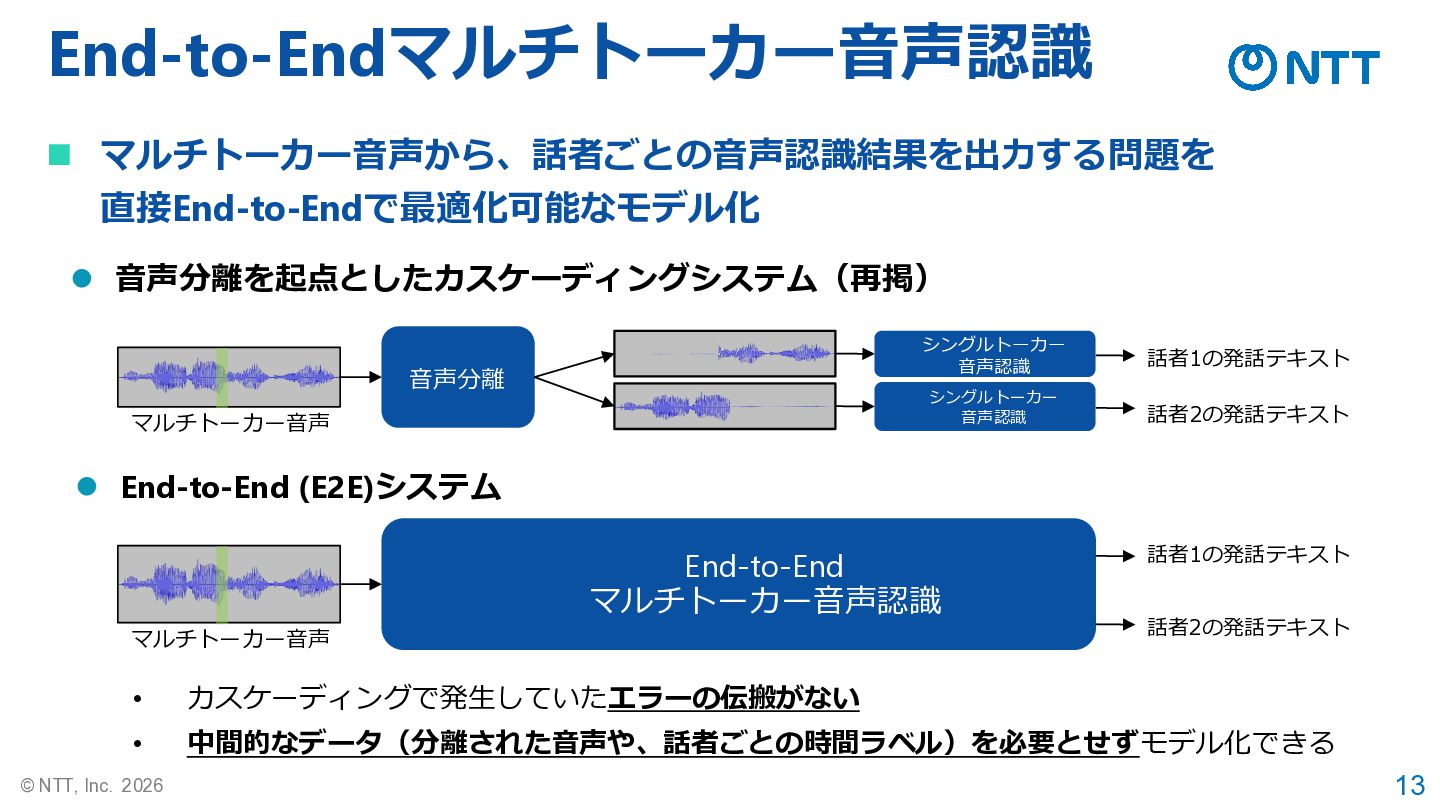
13 © NTT, Inc. 2026 End-to-Endマルチトーカー音声認識 ◼ マルチトーカー音声から、話者ごとの音声認識結果を出力する問題を 直接End-to-Endで最適化可能なモデル化 End-to-End
マルチトーカー音声認識 話者1の発話テキスト 話者2の発話テキスト マルチトーカー音声 音声分離 シングルトーカー 音声認識 シングルトーカー 音声認識 話者1の発話テキスト 話者2の発話テキスト マルチトーカー音声 ⚫ 音声分離を起点としたカスケーディングシステム(再掲) ⚫ End-to-End (E2E)システム • カスケーディングで発生していたエラーの伝搬がない • 中間的なデータ(分離された音声や、話者ごとの時間ラベル)を必要とせずモデル化できる
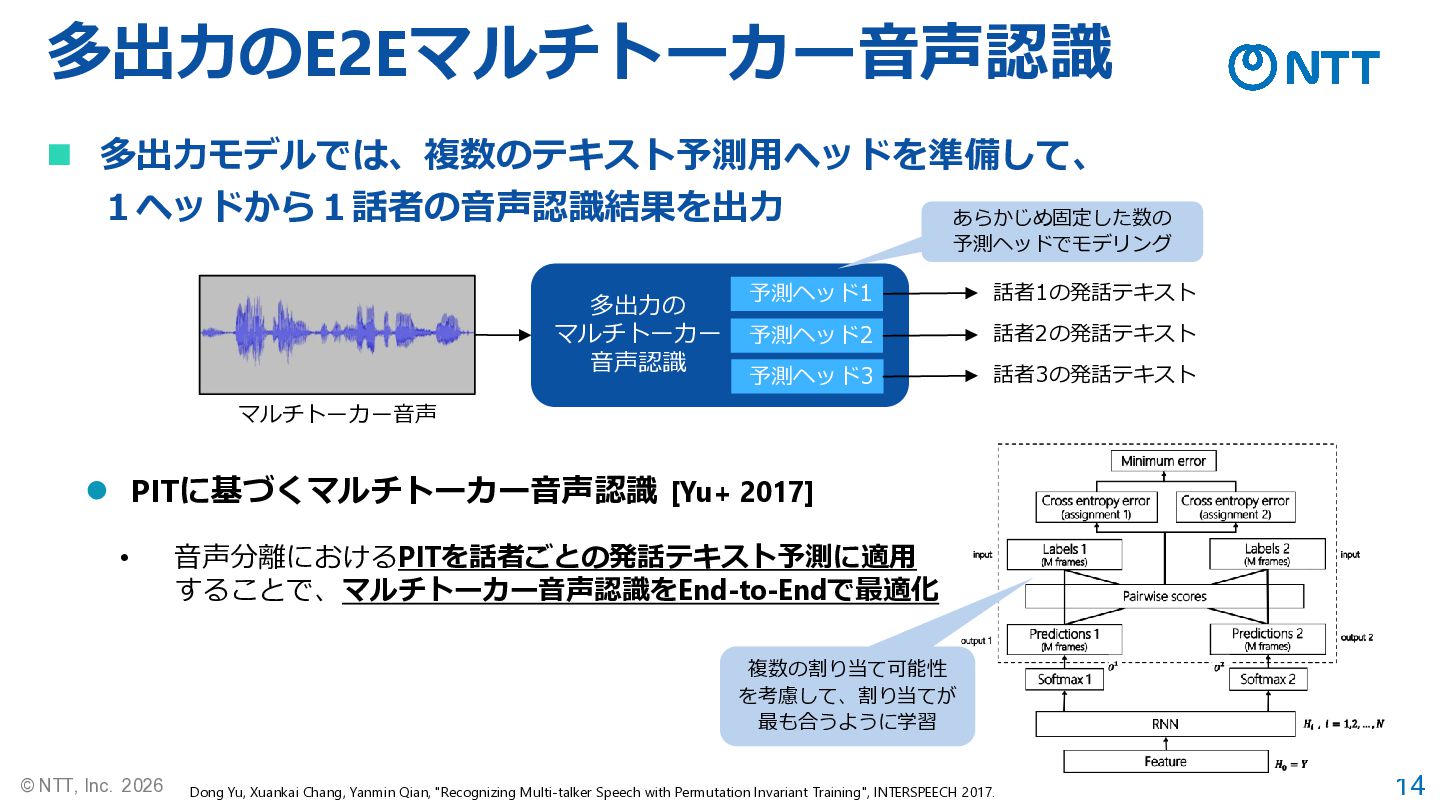
14 © NTT, Inc. 2026 多出力のE2Eマルチトーカー音声認識 ◼ 多出力モデルでは、複数のテキスト予測用ヘッドを準備して、 1ヘッドから1話者の音声認識結果を出力 マルチトーカー音声
多出力の マルチトーカー 音声認識 ⚫ PITに基づくマルチトーカー音声認識 [Yu+ 2017] Dong Yu, Xuankai Chang, Yanmin Qian, "Recognizing Multi-talker Speech with Permutation Invariant Training", INTERSPEECH 2017. 予測ヘッド1 予測ヘッド2 予測ヘッド3 話者1の発話テキスト 話者2の発話テキスト 話者3の発話テキスト • 音声分離におけるPITを話者ごとの発話テキスト予測に適用 することで、マルチトーカー音声認識をEnd-to-Endで最適化 あらかじめ固定した数の 予測ヘッドでモデリング 複数の割り当て可能性 を考慮して、割り当てが 最も合うように学習
15 © NTT, Inc. 2026 多出力型の強みと弱み ◼ 多出力型は音声分離と同様の強みを引き継いでいる一方、柔軟性は低い ⚫ 強み
• 高密度なオーバーラップに強い: 話者が完全に同時の発話開始タイミングでかつ、 完全にオーバーラップしているような発話に対して分離しやすい ⚫ 弱み • 話者数の限界: 事前に設定した予測ヘッド数より多い人数が登場すると、原理的に認識不可能 • ヘッド数より少ない話者数に弱い: 予測ヘッド数(最大話者数)未満の場合、 いくつかの予測ヘッドからブランク(何も出さない)を出力するように学習するが、 推論時に何かしら出力してしまうことがしばしば • 入力話者数が2者や3者とあらかじめ固定できる場合に強い:明示的に予測ヘッドのブ ランチを設けているので、マッチした想定ができる場合はモデリングしやすい
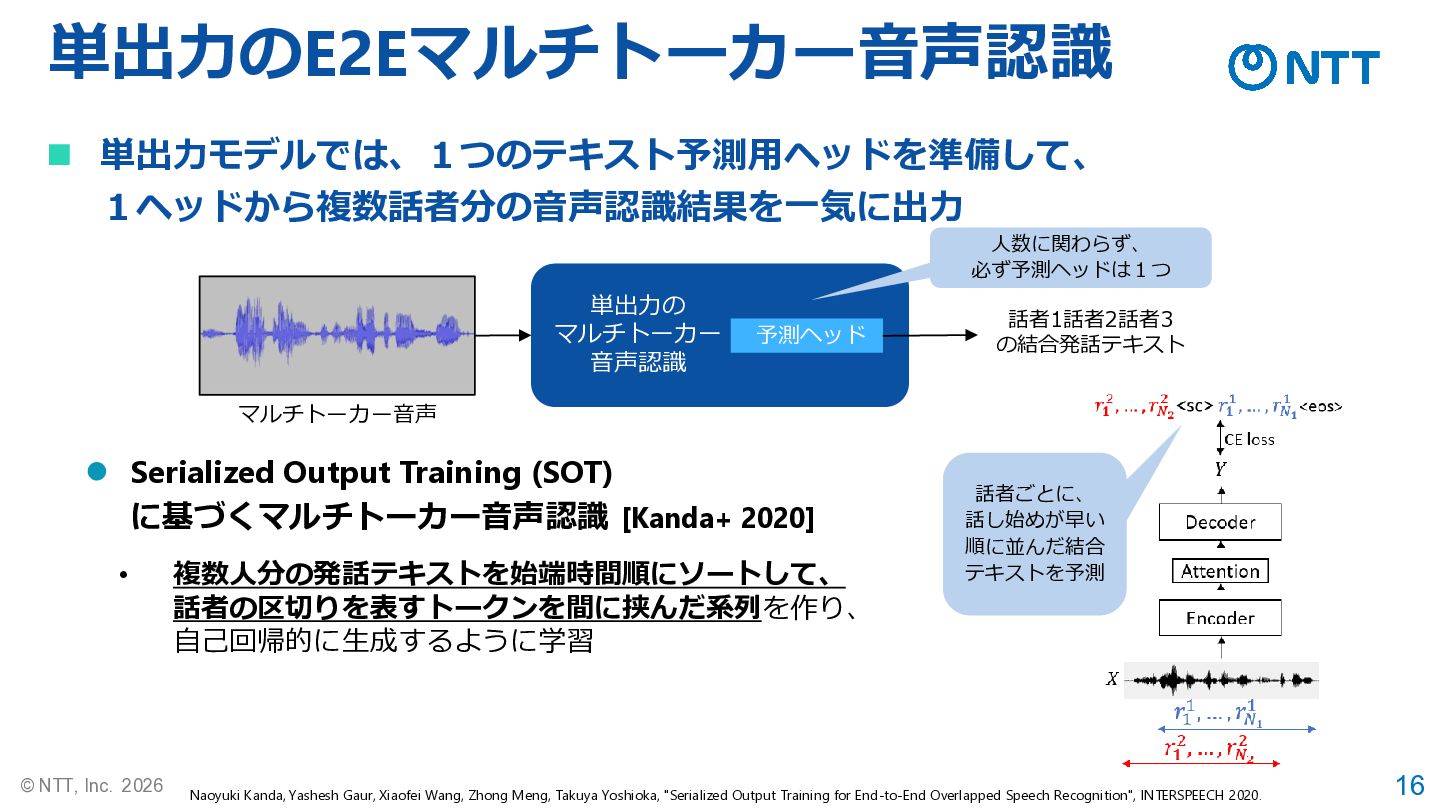
16 © NTT, Inc. 2026 単出力のE2Eマルチトーカー音声認識 ◼ 単出力モデルでは、1つのテキスト予測用ヘッドを準備して、 1ヘッドから複数話者分の音声認識結果を一気に出力 マルチトーカー音声
単出力の マルチトーカー 音声認識 ⚫ Serialized Output Training (SOT) に基づくマルチトーカー音声認識 [Kanda+ 2020] Naoyuki Kanda, Yashesh Gaur, Xiaofei Wang, Zhong Meng, Takuya Yoshioka, "Serialized Output Training for End-to-End Overlapped Speech Recognition", INTERSPEECH 2020. 予測ヘッド 話者1話者2話者3 の結合発話テキスト • 複数人分の発話テキストを始端時間順にソートして、 話者の区切りを表すトークンを間に挟んだ系列を作り、 自己回帰的に生成するように学習 人数に関わらず、 必ず予測ヘッドは1つ 話者ごとに、 話し始めが早い 順に並んだ結合 テキストを予測
17 © NTT, Inc. 2026 単出力型の強みと弱み ⚫ 強み • 言語コンテキストを利用しやすい:
1つの予測ヘッドから自己回帰的に複数話者のテキストを 予測するため、話者間の発話内容の話題等の会話コンテキストのつながりをとらえやすい • 話者数の柔軟性:事前に話者数を固定する必要がないため、 モデル構造を変更することなく、複数人のモデリングが可能 ⚫ 弱み • 完全な同時発話に適さない: 話者の発話開始時間がずれることを想定しており、 「発話開始が完全に同時、話し終わりも完全に同時」、といった場合には、 どちらを先にデコードすべきかの合間性が生じ、欠落などが発生しやすい ◼ 単出力モデルでは、1つのテキスト(トークン系列)予測用ヘッドを準備して、 1ヘッドから複数話者分の音声認識結果を一気に出力 • 自己回帰モデルの技術理論と相性が良い: エンコーダ-自己回帰デコーダ型の音声認識や機械翻訳、 や大規模言語モデル(LLM)など、自己回帰モデルに基づく各分野の知見・考え方が大いに活きる
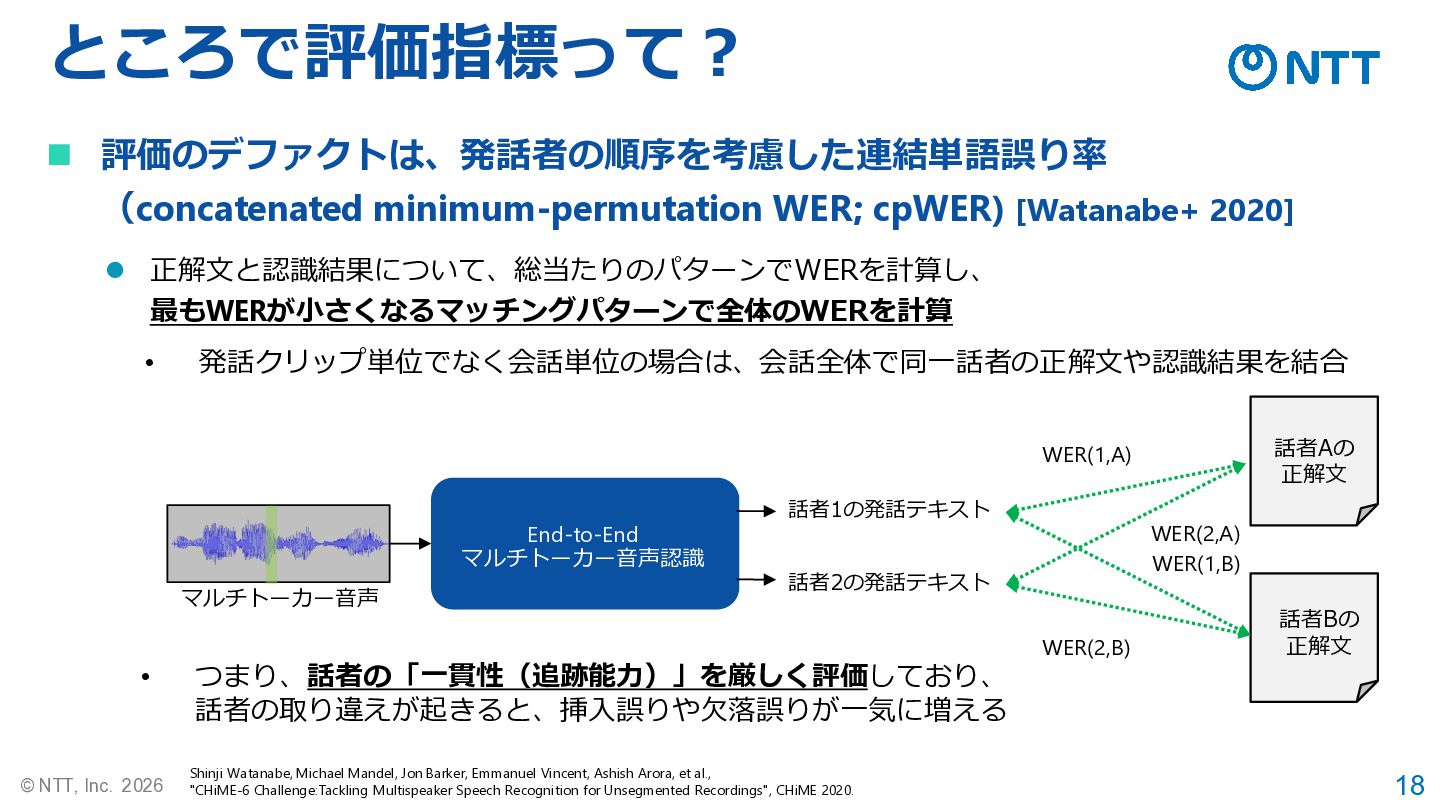
18 © NTT, Inc. 2026 ところで評価指標って? ◼ 評価のデファクトは、発話者の順序を考慮した連結単語誤り率 (concatenated minimum-permutation
WER; cpWER) [Watanabe+ 2020] 話者Aの 正解文 話者Bの 正解文 End-to-End マルチトーカー音声認識 話者1の発話テキスト 話者2の発話テキスト マルチトーカー音声 WER(1,A) WER(1,B) WER(2,B) WER(2,A) ⚫ 正解文と認識結果について、総当たりのパターンでWERを計算し、 最もWERが小さくなるマッチングパターンで全体のWERを計算 • つまり、話者の「一貫性(追跡能力)」を厳しく評価しており、 話者の取り違えが起きると、挿入誤りや欠落誤りが一気に増える Shinji Watanabe, Michael Mandel, Jon Barker, Emmanuel Vincent, Ashish Arora, et al., "CHiME-6 Challenge:Tackling Multispeaker Speech Recognition for Unsegmented Recordings", CHiME 2020. • 発話クリップ単位でなく会話単位の場合は、会話全体で同一話者の正解文や認識結果を結合
19 © NTT, Inc. 2026 代表的なベンチマークデータ ◼ 英語にて、代表的なベンチマークセットアップが存在しており、 その他の言語では各々がセットアップを汲んで評価することが多い ⚫
LibriMix (Libri2Mix/Libri3Mix) [Cosentino+ 2020] • 音声分離の評価をメインとして、 基本的に大部分にわたってオーバーラップがあるシュミレーションデータ ⚫ LibriSpeechMix [Kanda+ 2020] • マルチトーカー音声認識の評価をメインとして、 実際の会話に近い部分的なオーバーラップがあるシュミレーションデータ Joris Cosentino, Manuel Pariente, Samuele Cornell, Antoine Deleforge, Emmanuel Vincent, "LibriMix: An Open-Source Dataset for Generalizable Speech Separation", arXiv 2005.11262 Naoyuki Kanda, Yashesh Gaur, Xiaofei Wang, Zhong Meng, Takuya Yoshioka, "Serialized Output Training for End-to-End Overlapped Speech Recognition", INTERSPEECH 2020. ⚫ AMI meeting corpus [Carletta+ 2005] Jean Carletta, Simone Ashby, Sebastien Bourban, et. al, "The AMI Meeting Corpus: A Pre-announcement", MLMI 2005. • 完全なリアル会議データであり、話者ごとのヘッドセット収録を シングルチャネル化した音声や遠隔マイクによる収録音声のデータ
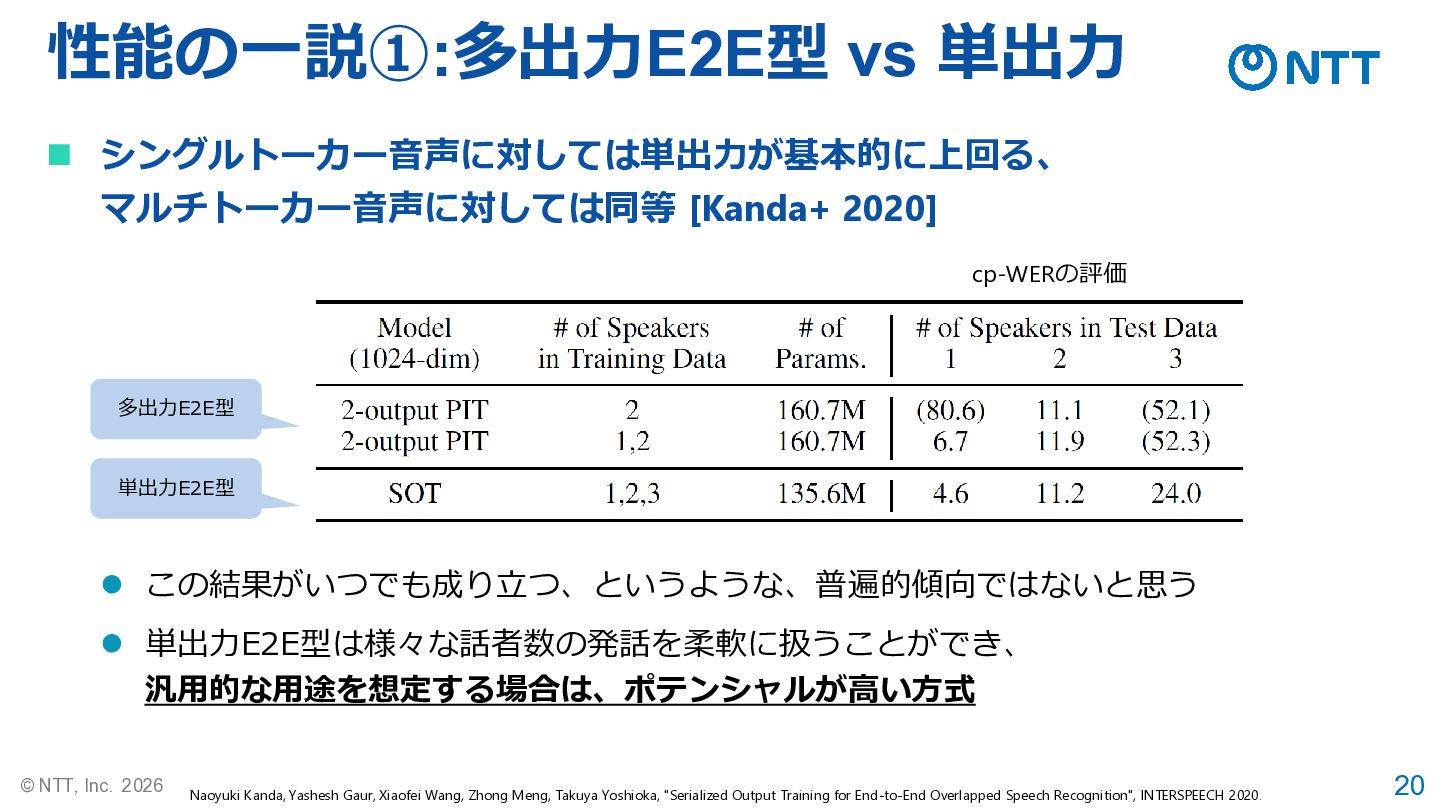
20 © NTT, Inc. 2026 性能の一説①:多出力E2E型 vs 単出力 ◼ シングルトーカー音声に対しては単出力が基本的に上回る、
マルチトーカー音声に対しては同等 [Kanda+ 2020] Naoyuki Kanda, Yashesh Gaur, Xiaofei Wang, Zhong Meng, Takuya Yoshioka, "Serialized Output Training for End-to-End Overlapped Speech Recognition", INTERSPEECH 2020. 単出力E2E型 多出力E2E型 cp-WERの評価 ⚫ 単出力E2E型は様々な話者数の発話を柔軟に扱うことができ、 汎用的な用途を想定する場合は、ポテンシャルが高い方式 ⚫ この結果がいつでも成り立つ、というような、普遍的傾向ではないと思う
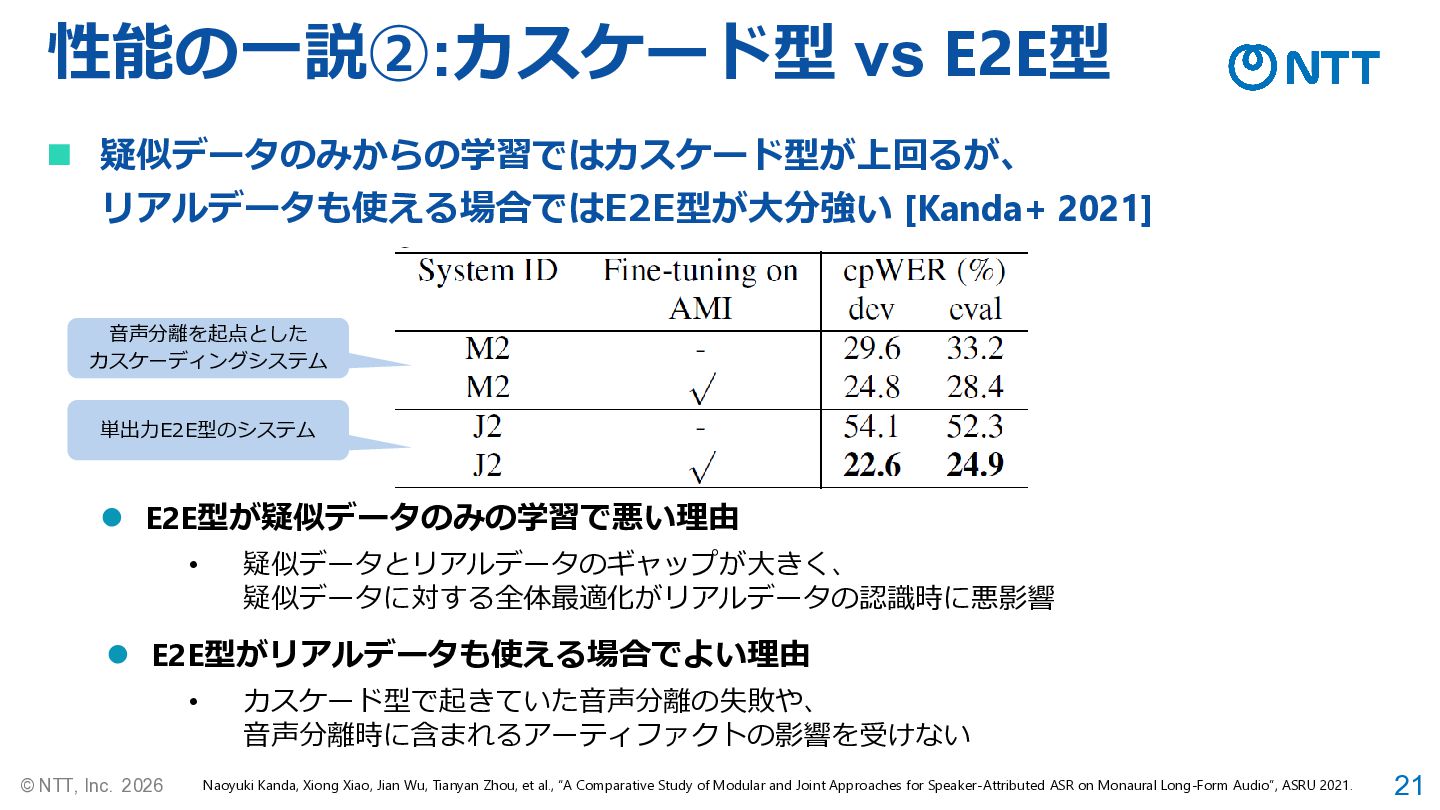
21 © NTT, Inc. 2026 性能の一説②:カスケード型 vs E2E型 Naoyuki Kanda,
Xiong Xiao, Jian Wu, Tianyan Zhou, et al., “A Comparative Study of Modular and Joint Approaches for Speaker-Attributed ASR on Monaural Long-Form Audio”, ASRU 2021. ◼ 疑似データのみからの学習ではカスケード型が上回るが、 リアルデータも使える場合ではE2E型が大分強い [Kanda+ 2021] ⚫ E2E型が疑似データのみの学習で悪い理由 ⚫ E2E型がリアルデータも使える場合でよい理由 • 疑似データとリアルデータのギャップが大きく、 疑似データに対する全体最適化がリアルデータの認識時に悪影響 • カスケード型で起きていた音声分離の失敗や、 音声分離時に含まれるアーティファクトの影響を受けない 音声分離を起点とした カスケーディングシステム 単出力E2E型のシステム
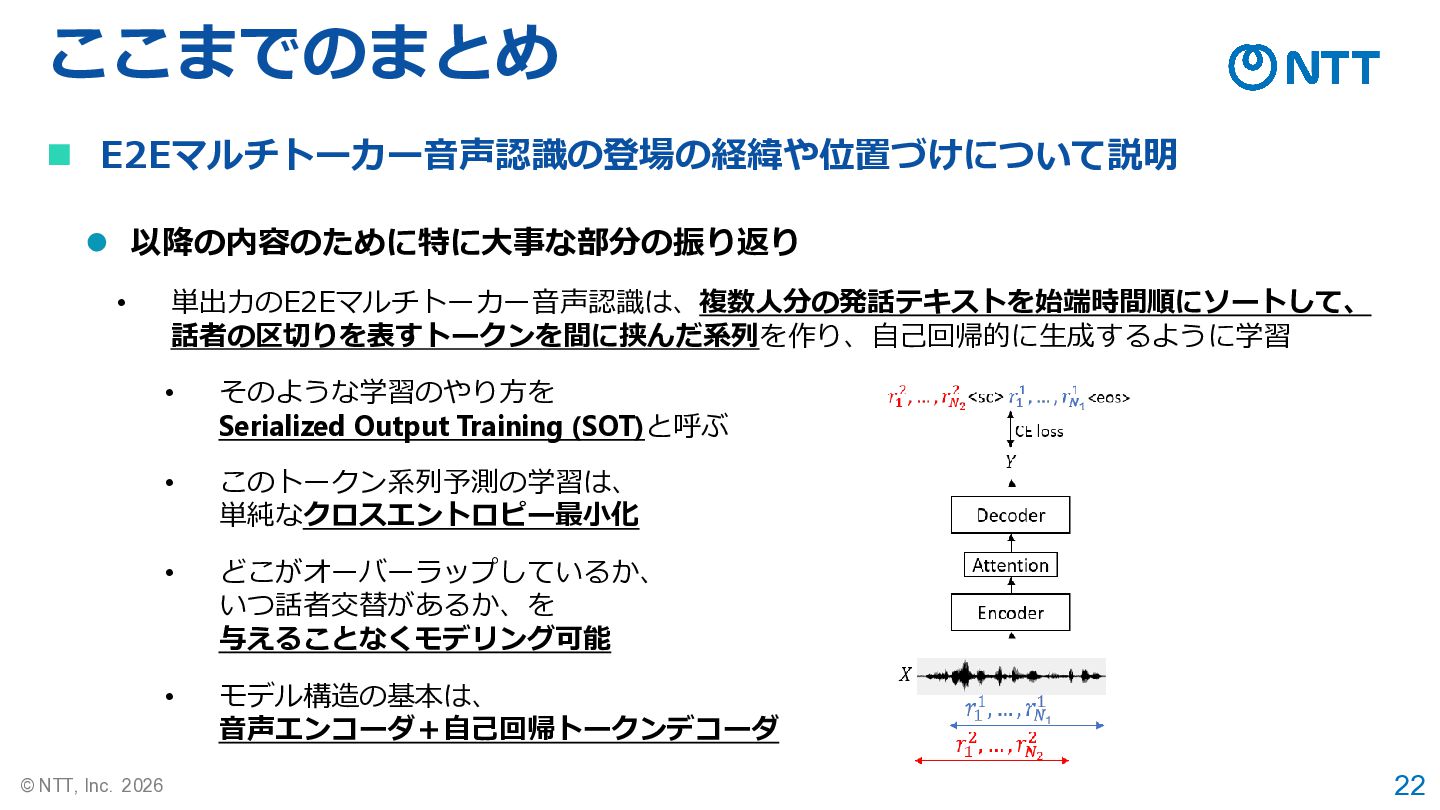
22 © NTT, Inc. 2026 ここまでのまとめ ◼ E2Eマルチトーカー音声認識の登場の経緯や位置づけについて説明 ⚫ 以降の内容のために特に大事な部分の振り返り
• 単出力のE2Eマルチトーカー音声認識は、複数人分の発話テキストを始端時間順にソートして、 話者の区切りを表すトークンを間に挟んだ系列を作り、自己回帰的に生成するように学習 • そのような学習のやり方を Serialized Output Training (SOT)と呼ぶ • このトークン系列予測の学習は、 単純なクロスエントロピー最小化 • どこがオーバーラップしているか、 いつ話者交替があるか、を 与えることなくモデリング可能 • モデル構造の基本は、 音声エンコーダ+自己回帰トークンデコーダ
23 © NTT, Inc. 2026 本日の内容 ◼ End-to-End型のシングルチャネルマルチトーカー音声認識の進展について、 我々の取り組みも絡めながら、研究動向を概説 1.
自己紹介と前置き 2. マルチトーカー音声認識の基礎とEnd-to-End型の登場 3. End-to-Endマルチトーカー音声認識の研究動向 4. おわりに
24 © NTT, Inc. 2026 E2Eマルチトーカー音声認識の研究動向 ◼ 特にE2Eの単出力モデリングに関して、「基本性能を高めるため」や、 「できることを拡張するため」の検討が進んでいる ⚫
基本性能を高めるための検討 • 事前学習された知識(自己教師あり学習モデルや大規模基盤モデル等)の活用 • 補助的な学習基準の導入 ⚫ できることを拡張するための検討 (と同時に、基本性能を高めるための検討) • 事前話者登録の考慮 • 様々な情報の同時認識 • 長時間音声への対応 • マルチトーカータスク複数統合 • 映像情報の考慮
25 © NTT, Inc. 2026 研究動向:補助的な学習基準の導入 ◼ 複数話者のオーバーラップ音声を扱う難しさを緩和するための 補助的な学習基準が検討されている ⚫
一般的な学習基準:複数人分の発話テキストを始端時間順にソートして、 話者の区切りを表すトークンを間に挟んだ系列を作り、自己回帰的に 生成するように学習 • 課題: 話者交替が頻繁に起こる会話や発話のオーバーラップが激 しいシーンでは、デコーダ出力にてテキストのコンテキストに引 きずられ、発話の欠落や発話交替の見逃しが発生 ⚫ 求められる補助的な学習基準: 話者交替やオーバーラップに対する気づき を高められるような基準 • テキストトークンも話者の区切りを表すトークンも等価に扱う これらを予測するだけでは、 入力音声に対して、いつ話 者交替やオーバーラップが 起きたか意識でない
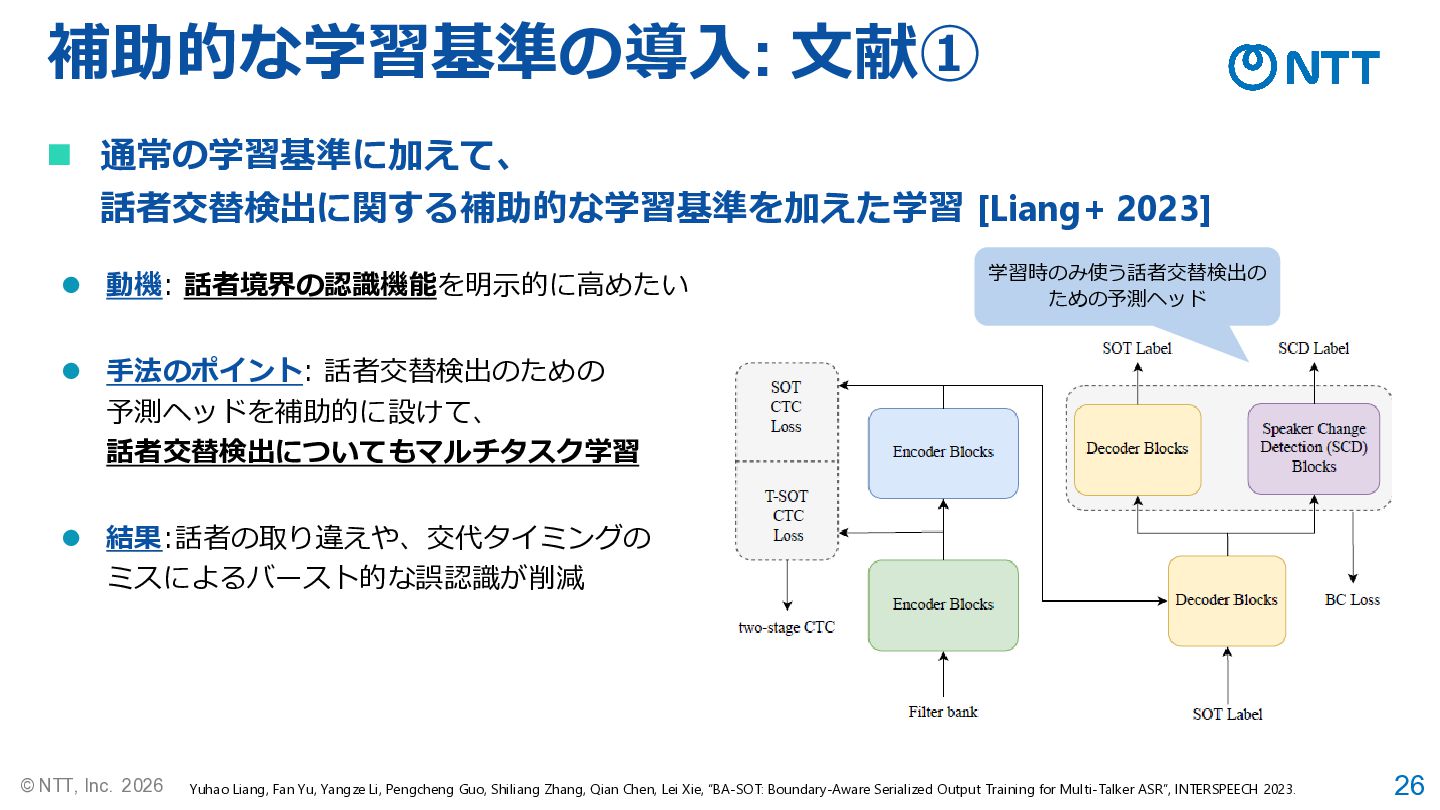
26 © NTT, Inc. 2026 補助的な学習基準の導入: 文献① Yuhao Liang, Fan
Yu, Yangze Li, Pengcheng Guo, Shiliang Zhang, Qian Chen, Lei Xie, “BA-SOT: Boundary-Aware Serialized Output Training for Multi-Talker ASR”, INTERSPEECH 2023. ◼ 通常の学習基準に加えて、 話者交替検出に関する補助的な学習基準を加えた学習 [Liang+ 2023] ⚫ 動機: 話者境界の認識機能を明示的に高めたい ⚫ 手法のポイント: 話者交替検出のための 予測ヘッドを補助的に設けて、 話者交替検出についてもマルチタスク学習 ⚫ 結果:話者の取り違えや、交代タイミングの ミスによるバースト的な誤認識が削減 学習時のみ使う話者交替検出の ための予測ヘッド
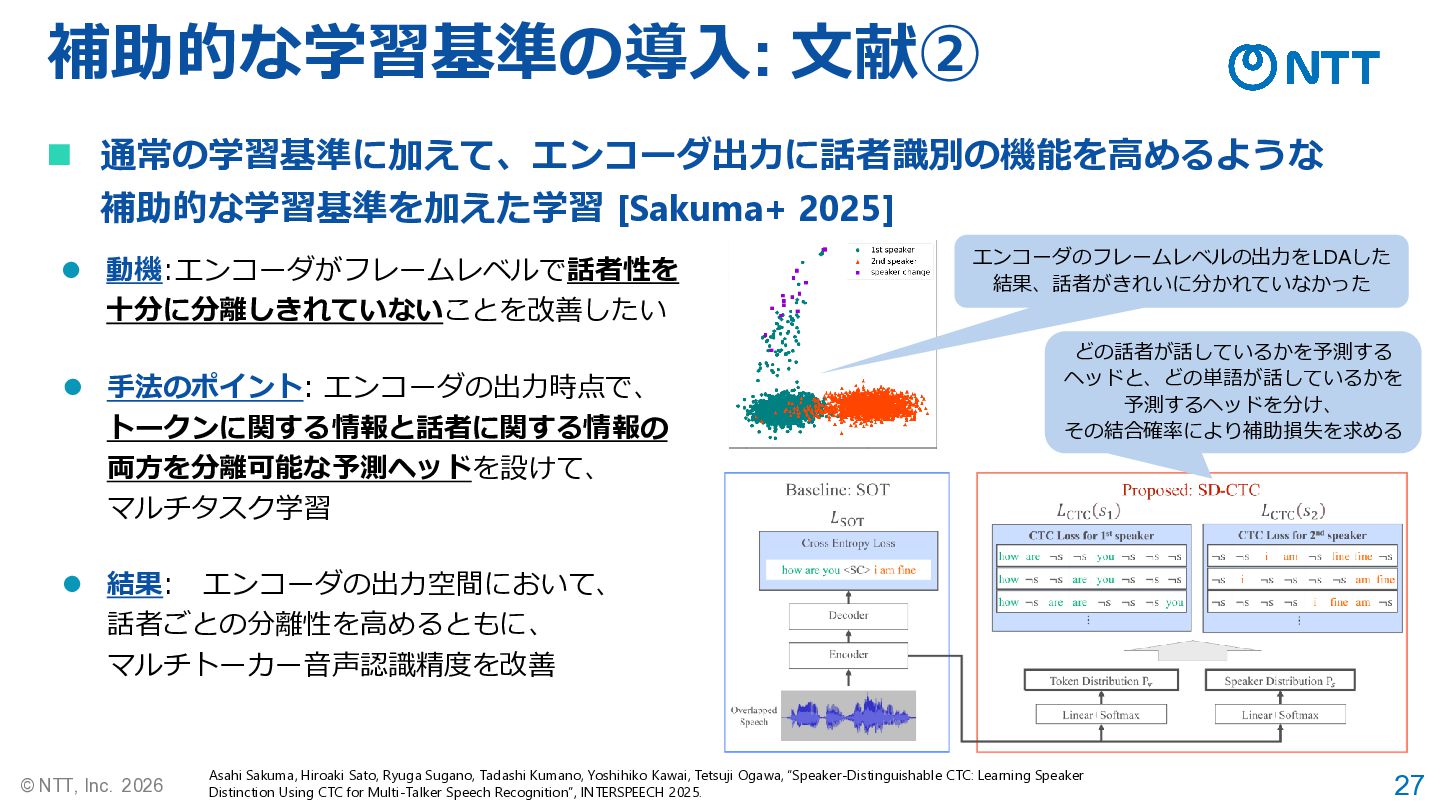
27 © NTT, Inc. 2026 補助的な学習基準の導入: 文献② Asahi Sakuma, Hiroaki
Sato, Ryuga Sugano, Tadashi Kumano, Yoshihiko Kawai, Tetsuji Ogawa, “Speaker-Distinguishable CTC: Learning Speaker Distinction Using CTC for Multi-Talker Speech Recognition”, INTERSPEECH 2025. ◼ 通常の学習基準に加えて、エンコーダ出力に話者識別の機能を高めるような 補助的な学習基準を加えた学習 [Sakuma+ 2025] ⚫ 動機:エンコーダがフレームレベルで話者性を 十分に分離しきれていないことを改善したい ⚫ 手法のポイント: エンコーダの出力時点で、 トークンに関する情報と話者に関する情報の 両方を分離可能な予測ヘッドを設けて、 マルチタスク学習 ⚫ 結果: エンコーダの出力空間において、 話者ごとの分離性を高めるともに、 マルチトーカー音声認識精度を改善 エンコーダのフレームレベルの出力をLDAした 結果、話者がきれいに分かれていなかった どの話者が話しているかを予測する ヘッドと、どの単語が話しているかを 予測するヘッドを分け、 その結合確率により補助損失を求める
28 © NTT, Inc. 2026 事前学習された知識の活用 ◼ Whisper等の大規模な音声基盤モデルや大規模言語モデルの活用、 また、マルチトーカー音声認識に特化した事前学習が検討されている ⚫
プリミティブな学習: モデルパラメータをランダム初期化してから マルチトーカー音声認識タスクについて学習 • 課題: マルチトーカー音声について、正確なテキスト書き起こしや話 者ラベルが付与されたデータは収集コストが高く、言語的にも音響的 にも汎化性能を十分高められるだけの学習データを準備できない ⚫ 求められる学習: モデルパラメータとして、事前学習済みの パラメータを活用したうえで、マルチトーカー音声認識タス クにファインチューニング わずかなマルチトーカーデータ のみから、この問題を広く頑健 に扱うようになることは困難
29 © NTT, Inc. 2026 事前学習された知識の活用: 文献① Weiqing Wang, Kunal
Dhawan, Taejin Park, Krishna C. Puvvada, Ivan Medennikov; Somshubra Majumdar, “Resource-Efficient Adaptation of Speech Foundation Models for Multi-Speaker ASR”, SLT 2024. ◼ 基盤音声認識モデルの音響的・言語的な知識を事前知識とした状態で、 少量データからマルチトーカー音声認識をモデリング [Wang+ 2024] ⚫ 動機: 一般的な基盤音声認識モデルはマルチトーカー音声 に対応できないが、シングルトーカータスクで得た豊富 な知識が入っているのでそれを活かしたい ⚫ 手法のポイント: 基盤音声認識モデル(Canary-1B)の知 識を活かしたうえで、アダプタ(LoRA)ベースの軽量な モデル適応によりマルチトーカー音声に対応 ⚫ 結果: 電話の2者間会話だけで学習しただけでも、 会議会話に対して高い性能を達成 エンコーダやデコーダのパラメータは 凍結した状態で、アダプタ部分のみを マルチトーカー音声認識向けに適応
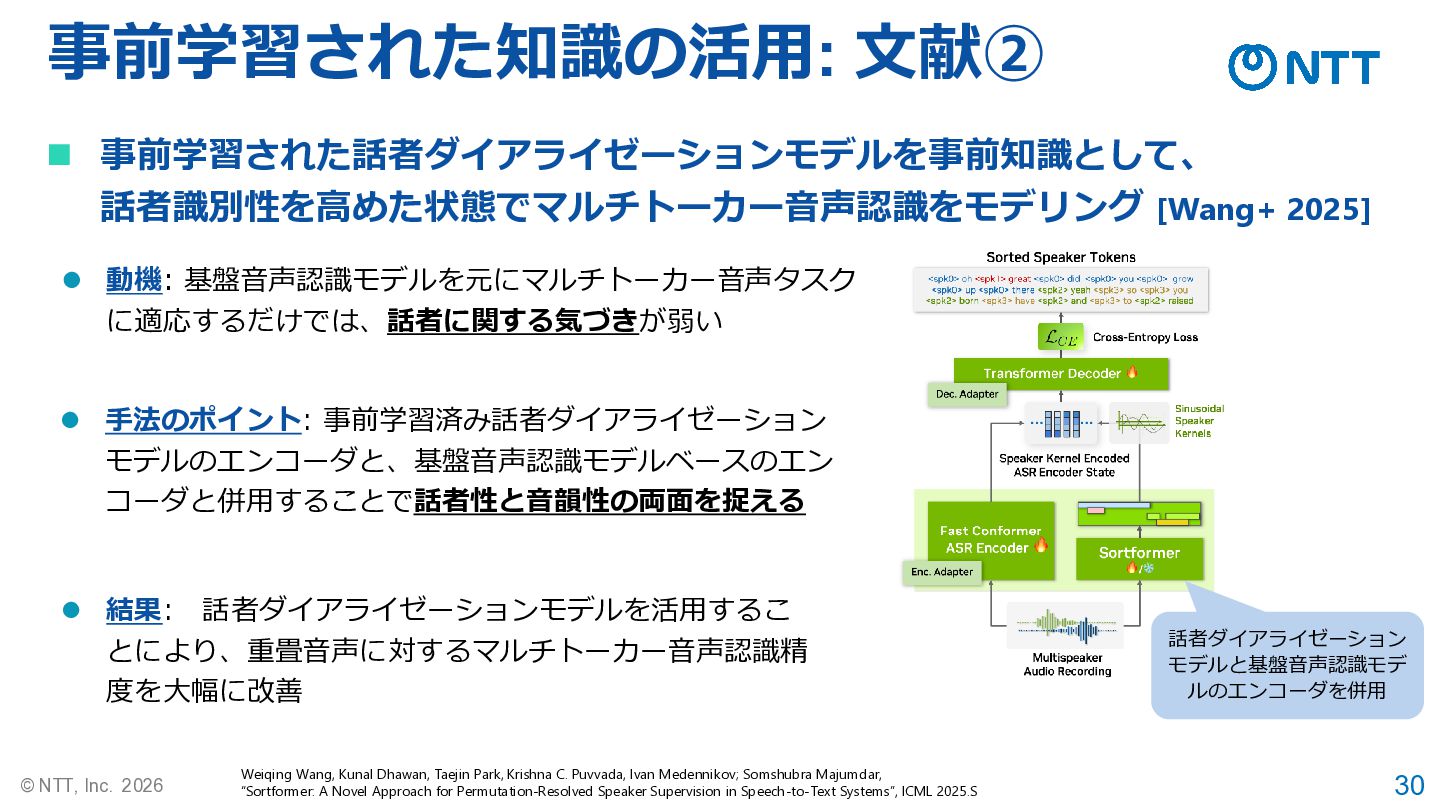
30 © NTT, Inc. 2026 事前学習された知識の活用: 文献② ◼ 事前学習された話者ダイアライゼーションモデルを事前知識として、 話者識別性を高めた状態でマルチトーカー音声認識をモデリング
[Wang+ 2025] Weiqing Wang, Kunal Dhawan, Taejin Park, Krishna C. Puvvada, Ivan Medennikov; Somshubra Majumdar, “Sortformer: A Novel Approach for Permutation-Resolved Speaker Supervision in Speech-to-Text Systems”, ICML 2025.S ⚫ 動機: 基盤音声認識モデルを元にマルチトーカー音声タスク に適応するだけでは、話者に関する気づきが弱い ⚫ 手法のポイント: 事前学習済み話者ダイアライゼーション モデルのエンコーダと、基盤音声認識モデルベースのエン コーダと併用することで話者性と音韻性の両面を捉える ⚫ 結果: 話者ダイアライゼーションモデルを活用するこ とにより、重畳音声に対するマルチトーカー音声認識精 度を大幅に改善 話者ダイアライゼーション モデルと基盤音声認識モデ ルのエンコーダを併用
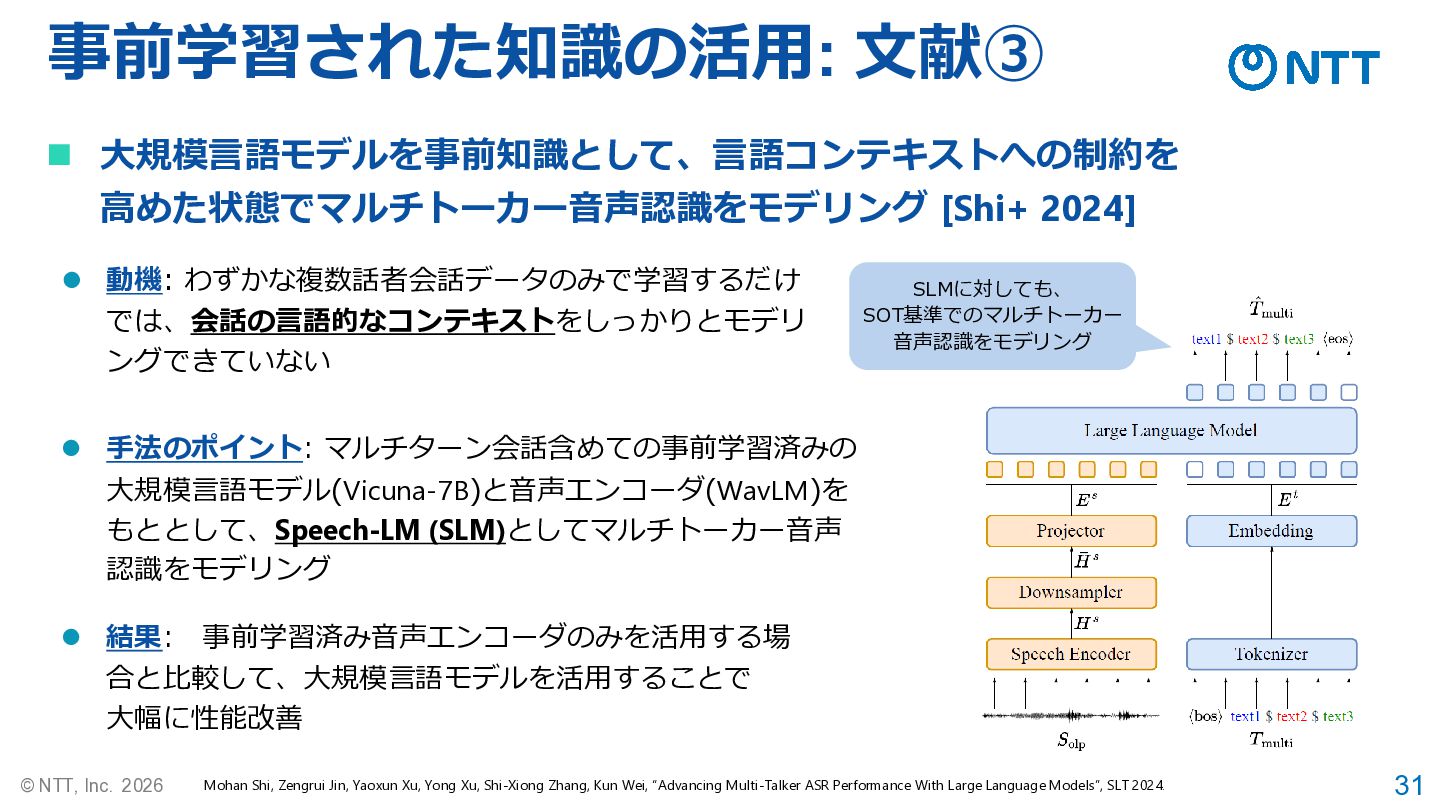
31 © NTT, Inc. 2026 事前学習された知識の活用: 文献➂ ◼ 大規模言語モデルを事前知識として、言語コンテキストへの制約を 高めた状態でマルチトーカー音声認識をモデリング
[Shi+ 2024] Mohan Shi, Zengrui Jin, Yaoxun Xu, Yong Xu, Shi-Xiong Zhang, Kun Wei, “Advancing Multi-Talker ASR Performance With Large Language Models”, SLT 2024. ⚫ 結果: 事前学習済み音声エンコーダのみを活用する場 合と比較して、大規模言語モデルを活用することで 大幅に性能改善 ⚫ 動機: わずかな複数話者会話データのみで学習するだけ では、会話の言語的なコンテキストをしっかりとモデリ ングできていない ⚫ 手法のポイント: マルチターン会話含めての事前学習済みの 大規模言語モデル(Vicuna-7B)と音声エンコーダ(WavLM)を もととして、Speech-LM (SLM)としてマルチトーカー音声 認識をモデリング SLMに対しても、 SOT基準でのマルチトーカー 音声認識をモデリング
32 © NTT, Inc. 2026 事前学習された知識の活用: 文献④ ◼ 重畳音素系列からそこに含まれる複数テキストを取り出すタスクを事前学習し、 マルチトーカー音声認識に適応
[Masumura+ 2025] ⚫ 動機: テキストのみから、言語的な制約だけでなく、 音韻的な重畳現象を見分ける力を獲得したい ⚫ 手法のポイント: 重畳音素という記号を導入して、 重畳音素系列からそこに隠れた複数のテキストを取 り出す問題を大規模な言語資源から事前学習 ⚫ 結果: 言語モデル基準の事前学習と比較して、 オーバーラップ音声に対する音声認識精度が大幅に改善 “It’s sunny today”, “Long time no see”, “Hello” をこの重畳音素系列から取り出す マルチトーカー音声認識に近い問題を、 テキストデータのみから設定 Ryo Masumura, Tomohiro Tanaka, Naoki Makishima, Mana Ihori, Shota Orihashi, Naotaka Kawata, et al., "Phoneme Overlapping-Aware Pre-Training with External Text Resources for Multi-Talker ASR“, ASRU 2025.
33 © NTT, Inc. 2026 E2Eマルチトーカー音声認識の研究動向 ◼ 特にE2Eの単出力モデリングに関して、「基本性能を高めるため」や、 「できることを拡張するため」の検討が進んでいる ⚫
基本性能を高めるための検討 • 事前学習された知識(自己教師あり学習モデルや大規模基盤モデル等)の活用 • 補助的な学習基準の導入 ⚫ できることを拡張するための検討 (と同時に、基本性能を高めるための検討) • 事前話者登録の考慮 • 様々な情報の同時認識 • 長時間音声への対応 • マルチトーカータスク複数統合 • 映像情報の考慮
34 © NTT, Inc. 2026 研究動向: 様々な情報の同時認識 ◼ 音声認識のメインである発話内容のテキスト化に加えて、 その他の音声言語情報も同時認識する手法が検討されている
⚫ プリミティブなモデルの認識対象: テキストトークン、話者区切りトークン • 課題①: 他の音声言語処理で必要とされる情報を付与した い場合、マルチトーカー音声を扱う難しさを同様に被る ⚫ 追加したい認識対象: アプリケーション上、および、性能改善を目指す上 でも必要となるような音声言語処理の情報 • 課題②: 話者交替やオーバーラップに対する気づきが得づらい状態で はあるため、通常の認識対象をしっかりと捉えること自体が難しい 複数人会話を扱うアプ リケーションにおいて、 この情報で十分?
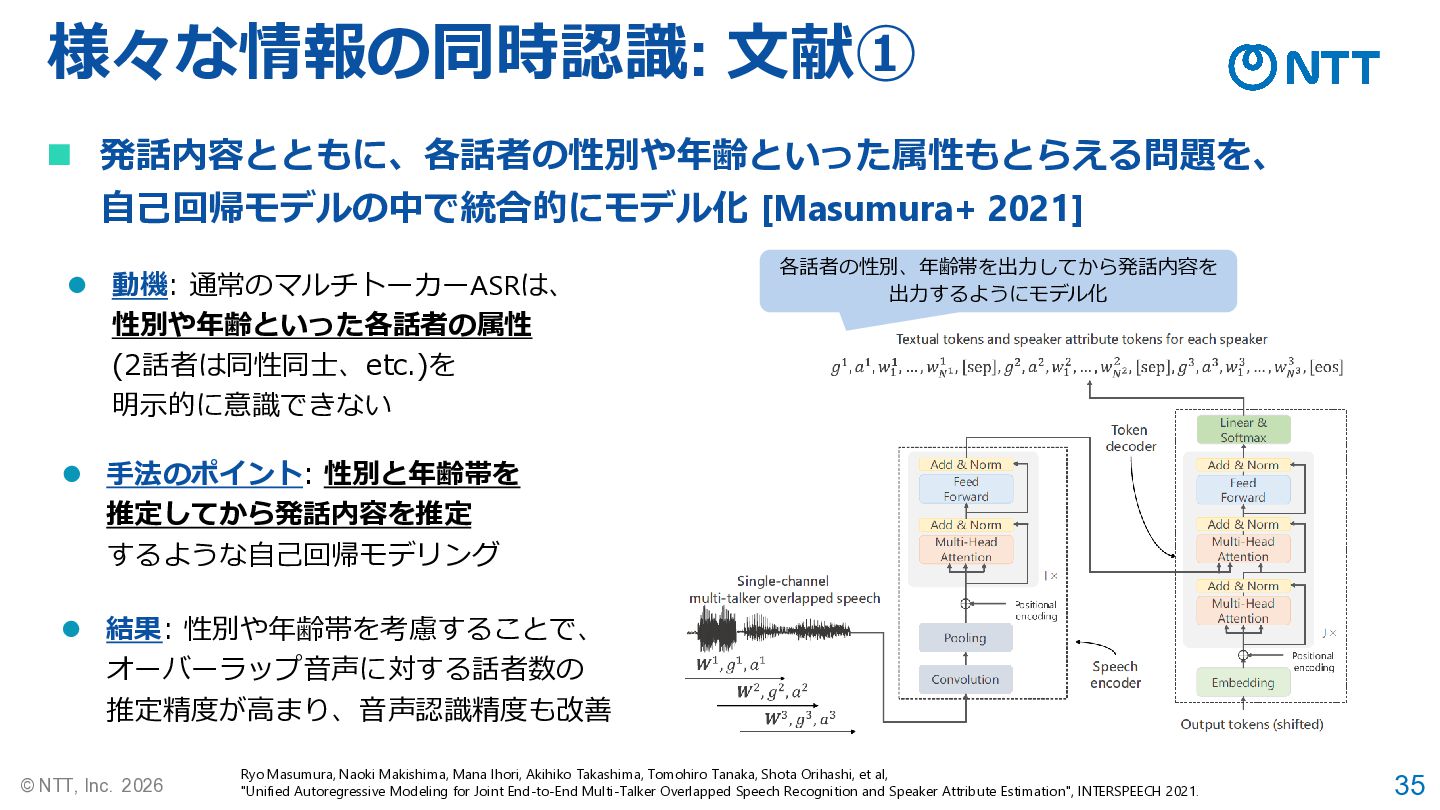
35 © NTT, Inc. 2026 様々な情報の同時認識: 文献① Ryo Masumura, Naoki
Makishima, Mana Ihori, Akihiko Takashima, Tomohiro Tanaka, Shota Orihashi, et al, "Unified Autoregressive Modeling for Joint End-to-End Multi-Talker Overlapped Speech Recognition and Speaker Attribute Estimation", INTERSPEECH 2021. ◼ 発話内容とともに、各話者の性別や年齢といった属性もとらえる問題を、 自己回帰モデルの中で統合的にモデル化 [Masumura+ 2021] ⚫ 動機: 通常のマルチトーカーASRは、 性別や年齢といった各話者の属性 (2話者は同性同士、etc.)を 明示的に意識できない ⚫ 手法のポイント: 性別と年齢帯を 推定してから発話内容を推定 するような自己回帰モデリング ⚫ 結果: 性別や年齢帯を考慮することで、 オーバーラップ音声に対する話者数の 推定精度が高まり、音声認識精度も改善 各話者の性別、年齢帯を出力してから発話内容を 出力するようにモデル化
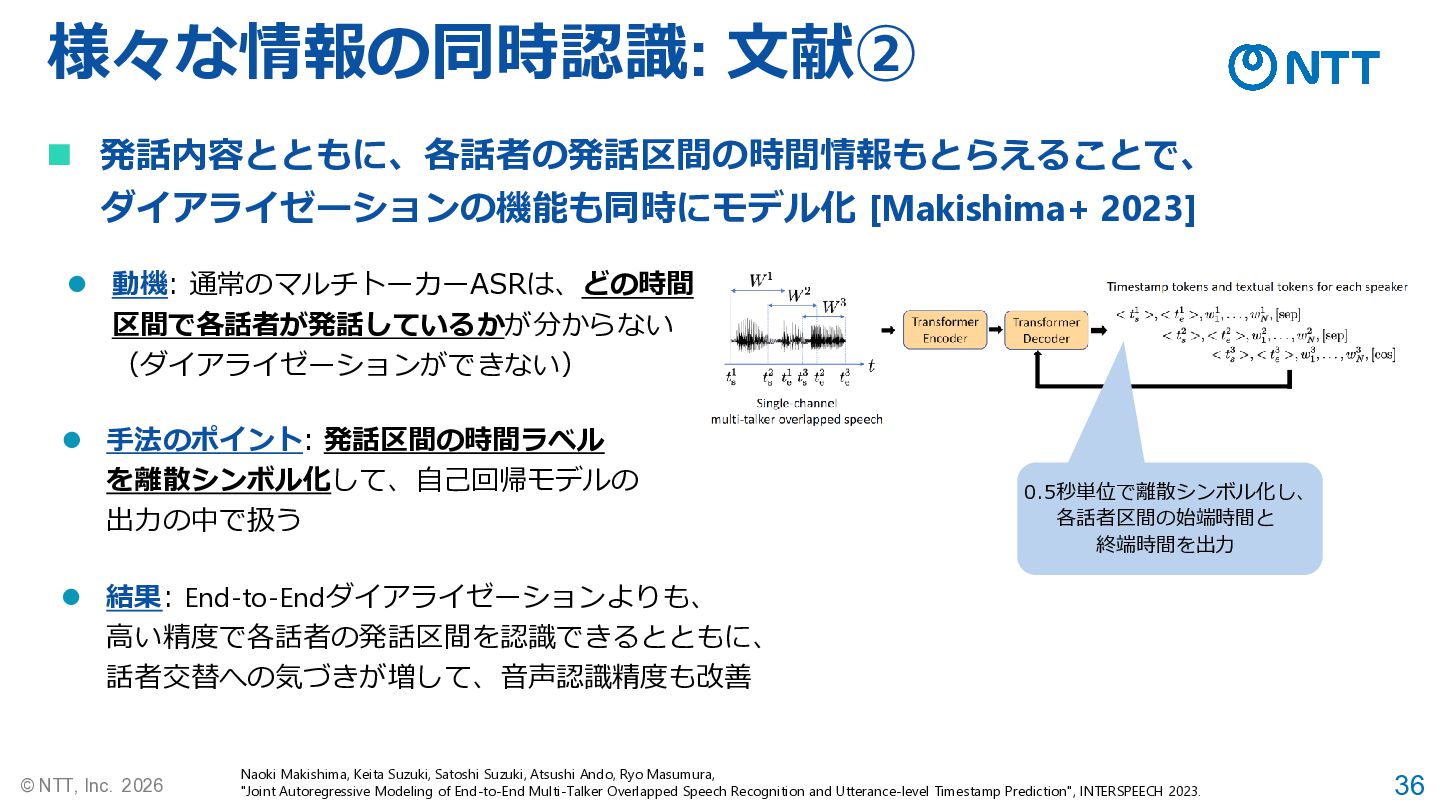
36 © NTT, Inc. 2026 様々な情報の同時認識: 文献② Naoki Makishima, Keita
Suzuki, Satoshi Suzuki, Atsushi Ando, Ryo Masumura, "Joint Autoregressive Modeling of End-to-End Multi-Talker Overlapped Speech Recognition and Utterance-level Timestamp Prediction", INTERSPEECH 2023. ◼ 発話内容とともに、各話者の発話区間の時間情報もとらえることで、 ダイアライゼーションの機能も同時にモデル化 [Makishima+ 2023] ⚫ 動機: 通常のマルチトーカーASRは、どの時間 区間で各話者が発話しているかが分からない (ダイアライゼーションができない) ⚫ 手法のポイント: 発話区間の時間ラベル を離散シンボル化して、自己回帰モデルの 出力の中で扱う ⚫ 結果: End-to-Endダイアライゼーションよりも、 高い精度で各話者の発話区間を認識できるとともに、 話者交替への気づきが増して、音声認識精度も改善 0.5秒単位で離散シンボル化し、 各話者区間の始端時間と 終端時間を出力
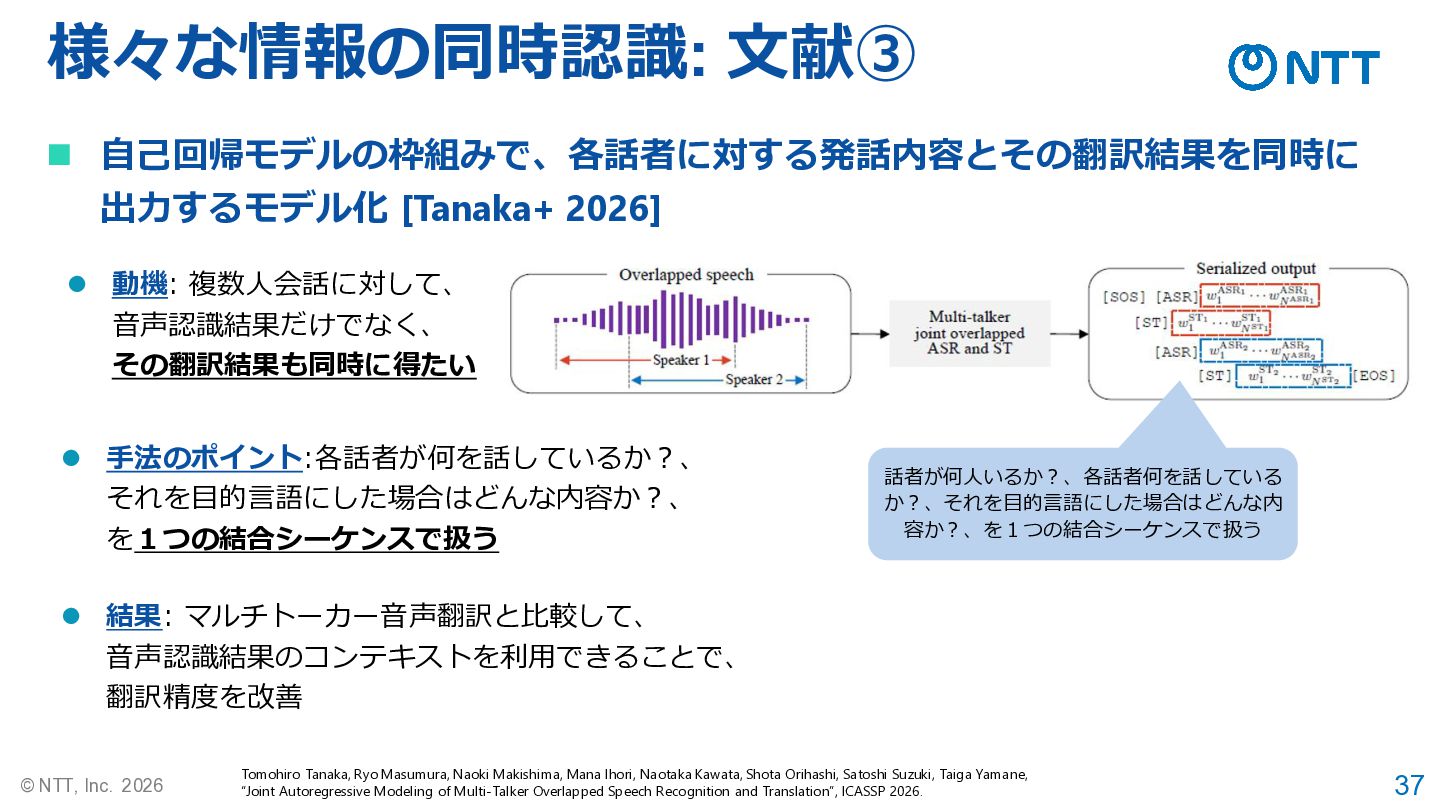
37 © NTT, Inc. 2026 様々な情報の同時認識: 文献➂ Tomohiro Tanaka, Ryo
Masumura, Naoki Makishima, Mana Ihori, Naotaka Kawata, Shota Orihashi, Satoshi Suzuki, Taiga Yamane, “Joint Autoregressive Modeling of Multi-Talker Overlapped Speech Recognition and Translation”, ICASSP 2026. ◼ 自己回帰モデルの枠組みで、各話者に対する発話内容とその翻訳結果を同時に 出力するモデル化 [Tanaka+ 2026] ⚫ 動機: 複数人会話に対して、 音声認識結果だけでなく、 その翻訳結果も同時に得たい ⚫ 手法のポイント:各話者が何を話しているか?、 それを目的言語にした場合はどんな内容か?、 を1つの結合シーケンスで扱う ⚫ 結果: マルチトーカー音声翻訳と比較して、 音声認識結果のコンテキストを利用できることで、 翻訳精度を改善 話者が何人いるか?、各話者何を話している か?、それを目的言語にした場合はどんな内 容か?、を1つの結合シーケンスで扱う
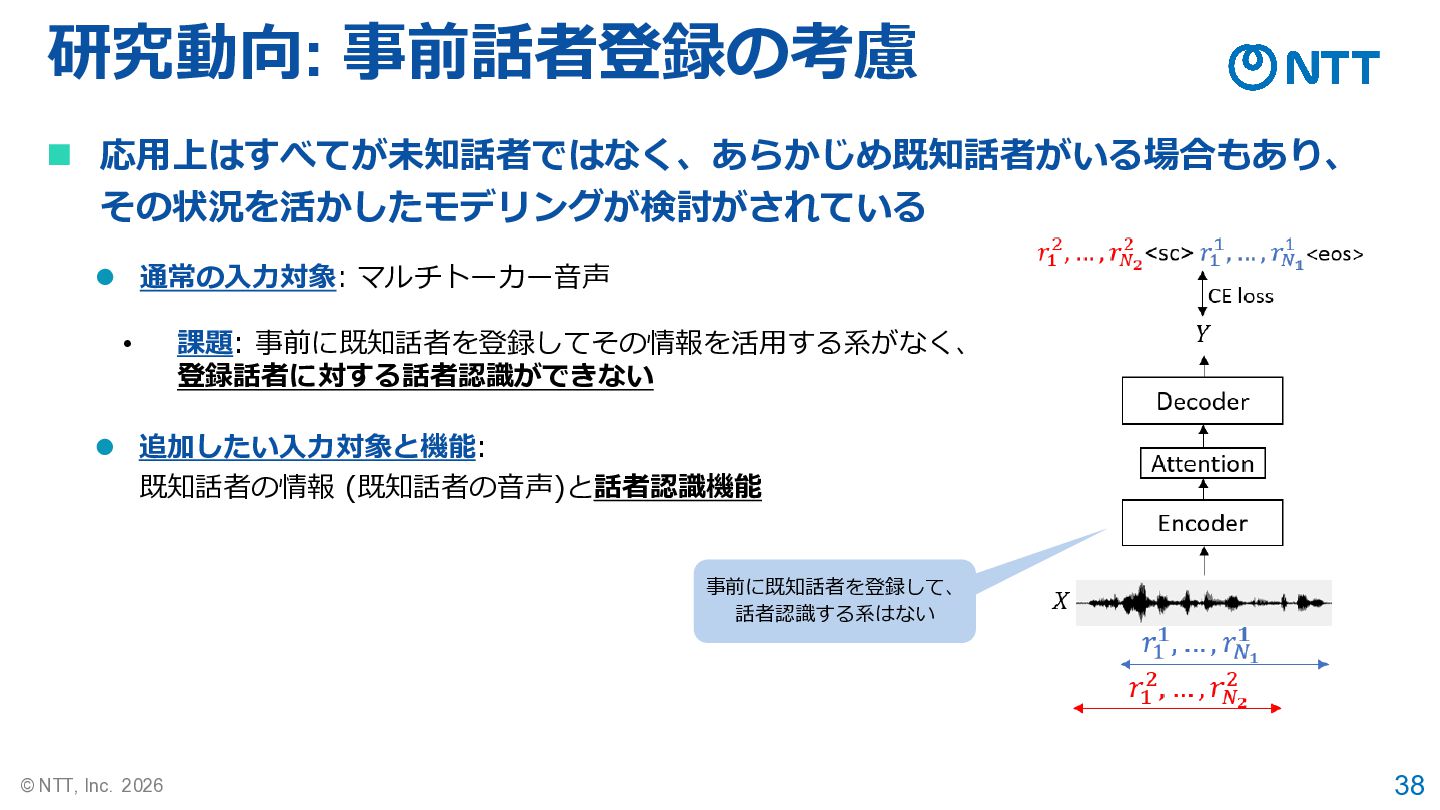
38 © NTT, Inc. 2026 研究動向: 事前話者登録の考慮 ◼ 応用上はすべてが未知話者ではなく、あらかじめ既知話者がいる場合もあり、 その状況を活かしたモデリングが検討がされている
⚫ 通常の入力対象: マルチトーカー音声 • 課題: 事前に既知話者を登録してその情報を活用する系がなく、 登録話者に対する話者認識ができない ⚫ 追加したい入力対象と機能: 既知話者の情報 (既知話者の音声)と話者認識機能 事前に既知話者を登録して、 話者認識する系はない
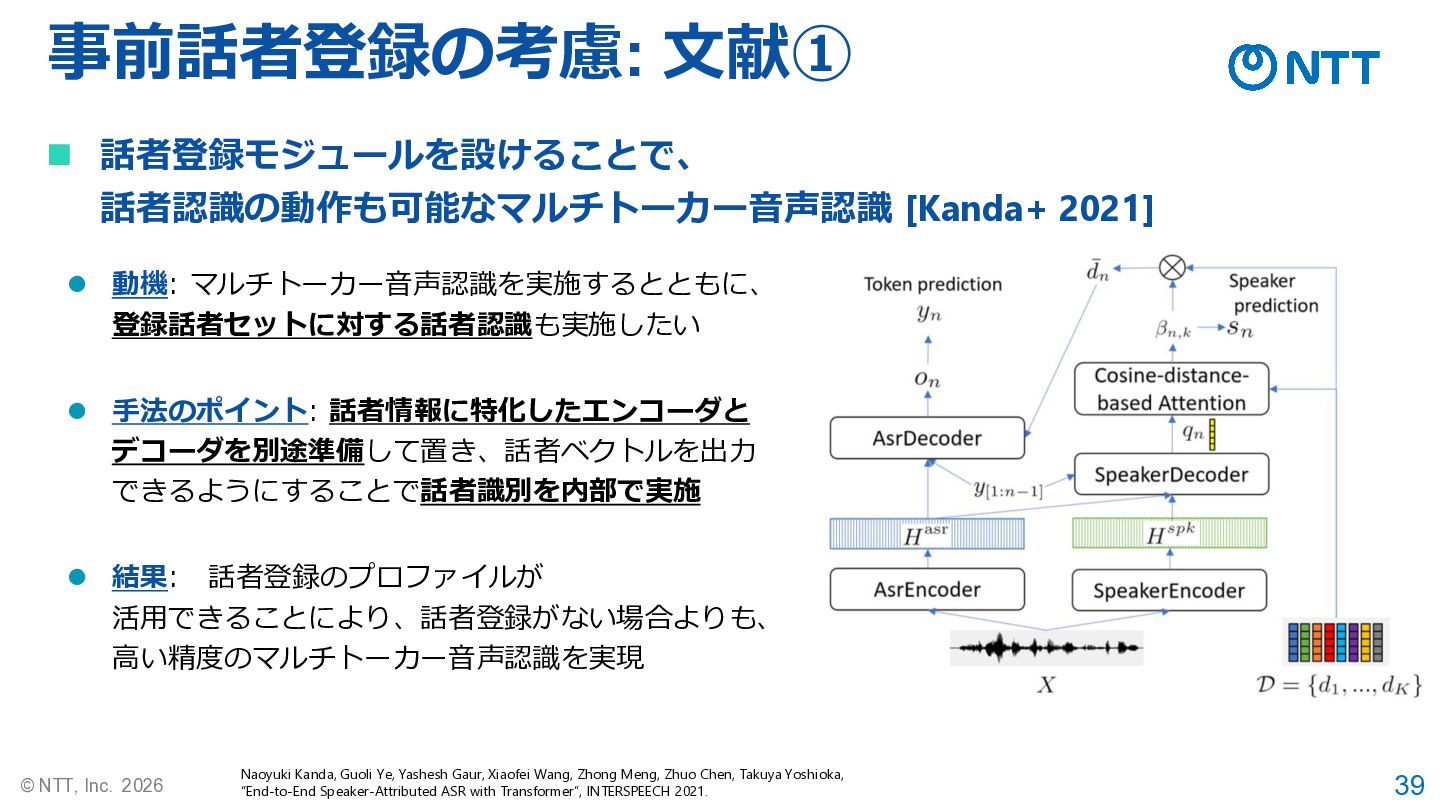
39 © NTT, Inc. 2026 事前話者登録の考慮: 文献① ◼ 話者登録モジュールを設けることで、 話者認識の動作も可能なマルチトーカー音声認識
[Kanda+ 2021] Naoyuki Kanda, Guoli Ye, Yashesh Gaur, Xiaofei Wang, Zhong Meng, Zhuo Chen, Takuya Yoshioka, “End-to-End Speaker-Attributed ASR with Transformer”, INTERSPEECH 2021. ⚫ 動機: マルチトーカー音声認識を実施するとともに、 登録話者セットに対する話者認識も実施したい ⚫ 手法のポイント: 話者情報に特化したエンコーダと デコーダを別途準備して置き、話者ベクトルを出力 できるようにすることで話者識別を内部で実施 ⚫ 結果: 話者登録のプロファイルが 活用できることにより、話者登録がない場合よりも、 高い精度のマルチトーカー音声認識を実現
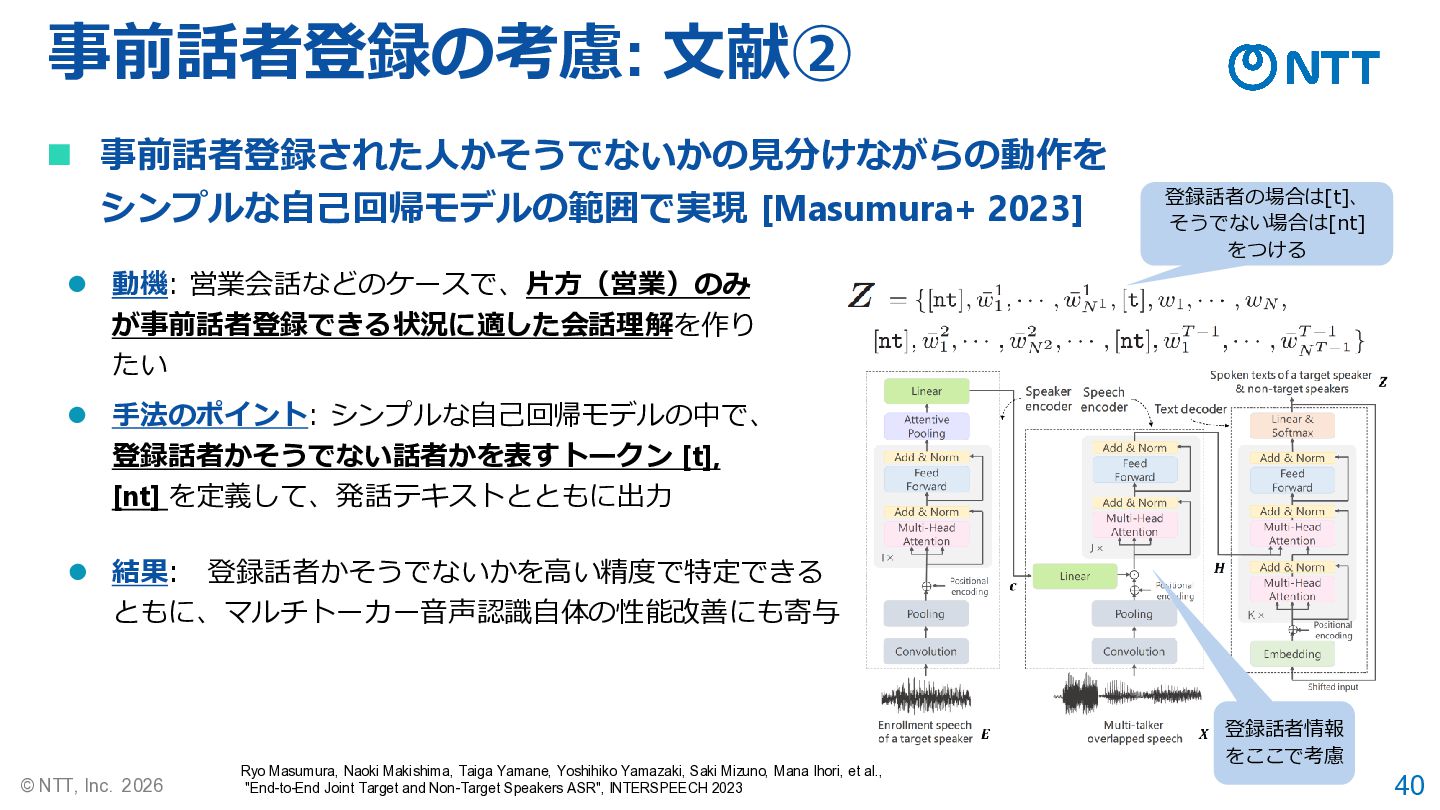
40 © NTT, Inc. 2026 事前話者登録の考慮: 文献② Ryo Masumura, Naoki
Makishima, Taiga Yamane, Yoshihiko Yamazaki, Saki Mizuno, Mana Ihori, et al., "End-to-End Joint Target and Non-Target Speakers ASR", INTERSPEECH 2023 ◼ 事前話者登録された人かそうでないかの見分けながらの動作を シンプルな自己回帰モデルの範囲で実現 [Masumura+ 2023] ⚫ 動機: 営業会話などのケースで、片方(営業)のみ が事前話者登録できる状況に適した会話理解を作り たい ⚫ 手法のポイント: シンプルな自己回帰モデルの中で、 登録話者かそうでない話者かを表すトークン [t], [nt] を定義して、発話テキストとともに出力 ⚫ 結果: 登録話者かそうでないかを高い精度で特定できる ともに、マルチトーカー音声認識自体の性能改善にも寄与 登録話者情報 をここで考慮 登録話者の場合は[t]、 そうでない場合は[nt] をつける
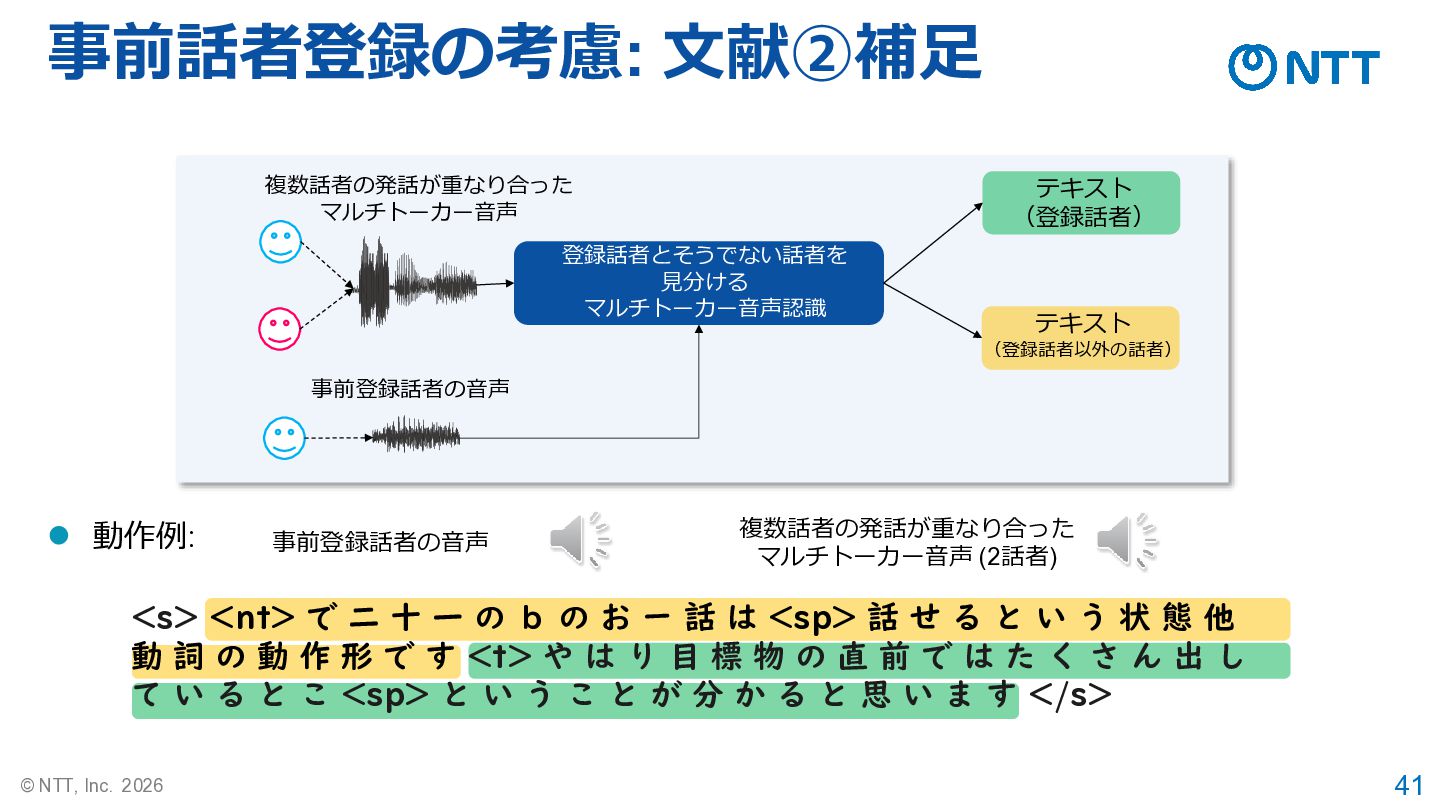
41 © NTT, Inc. 2026 事前話者登録の考慮: 文献②補足 ⚫ 動作例: 登録話者とそうでない話者を
見分ける マルチトーカー音声認識 テキスト (登録話者以外の話者) テキスト (登録話者) 複数話者の発話が重なり合った マルチトーカー音声 事前登録話者の音声 事前登録話者の音声 複数話者の発話が重なり合った マルチトーカー音声 (2話者) <s> <nt> で 二 十 一 の b の お ー 話 は <sp> 話 せ る と い う 状 態 他 動 詞 の 動 作 形 で す <t> や は り 目 標 物 の 直 前 で は た く さ ん 出 し て い る と こ <sp> と い う こ と が 分 か る と 思 い ま す </s>
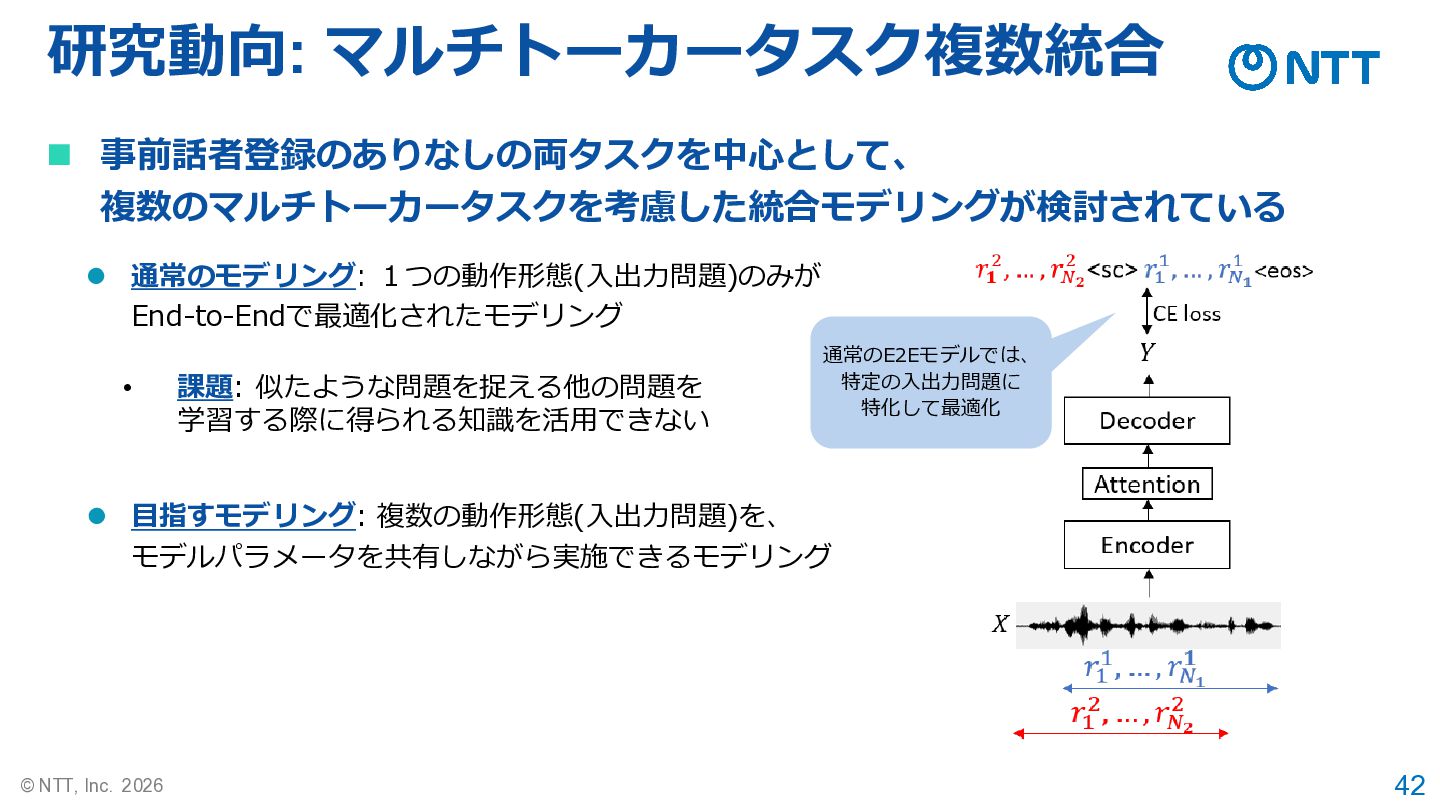
42 © NTT, Inc. 2026 研究動向: マルチトーカータスク複数統合 ◼ 事前話者登録のありなしの両タスクを中心として、 複数のマルチトーカータスクを考慮した統合モデリングが検討されている
⚫ 通常のモデリング: 1つの動作形態(入出力問題)のみが End-to-Endで最適化されたモデリング ⚫ 目指すモデリング: 複数の動作形態(入出力問題)を、 モデルパラメータを共有しながら実施できるモデリング 通常のE2Eモデルでは、 特定の入出力問題に 特化して最適化 • 課題: 似たような問題を捉える他の問題を 学習する際に得られる知識を活用できない
43 © NTT, Inc. 2026 マルチトーカータスク複数統合: 文献① Ryo Masumura, Naoki
Makishima, Tomohiro Tanaka, Mana Ihori, Naotaka Kawata, Shota Orihashi, et al., "Unified Multi-Talker ASR with and without Target-speaker Enrollment", INTERSPEECH 2024. ◼ 通常のマルチトーカー音声認識と、事前の話者登録により目的話者音声のみを 認識する系を1つの自己回帰モデルで統合的に扱う [Masumura+ 2024] ⚫ 動機: 話者登録を前提としたモデルと、そうでないモデル を別々に作ることが非効率的であることを解決したい ⚫ 手法のポイント: 音声エンコーダ、自己回帰デコーダを完全 に共有できる形で、話者登録モジュールをつけるかつけない かを切り替えられるようにモデリング ⚫ 結果: 1つの自己回帰モデルで両方のタスクがあつかえ るとともに、一方のタスクのみでモデリングする場合よ りも音声認識精度を改善 「登録話者がいない」を ゼロベクトル に割り当てることで実現
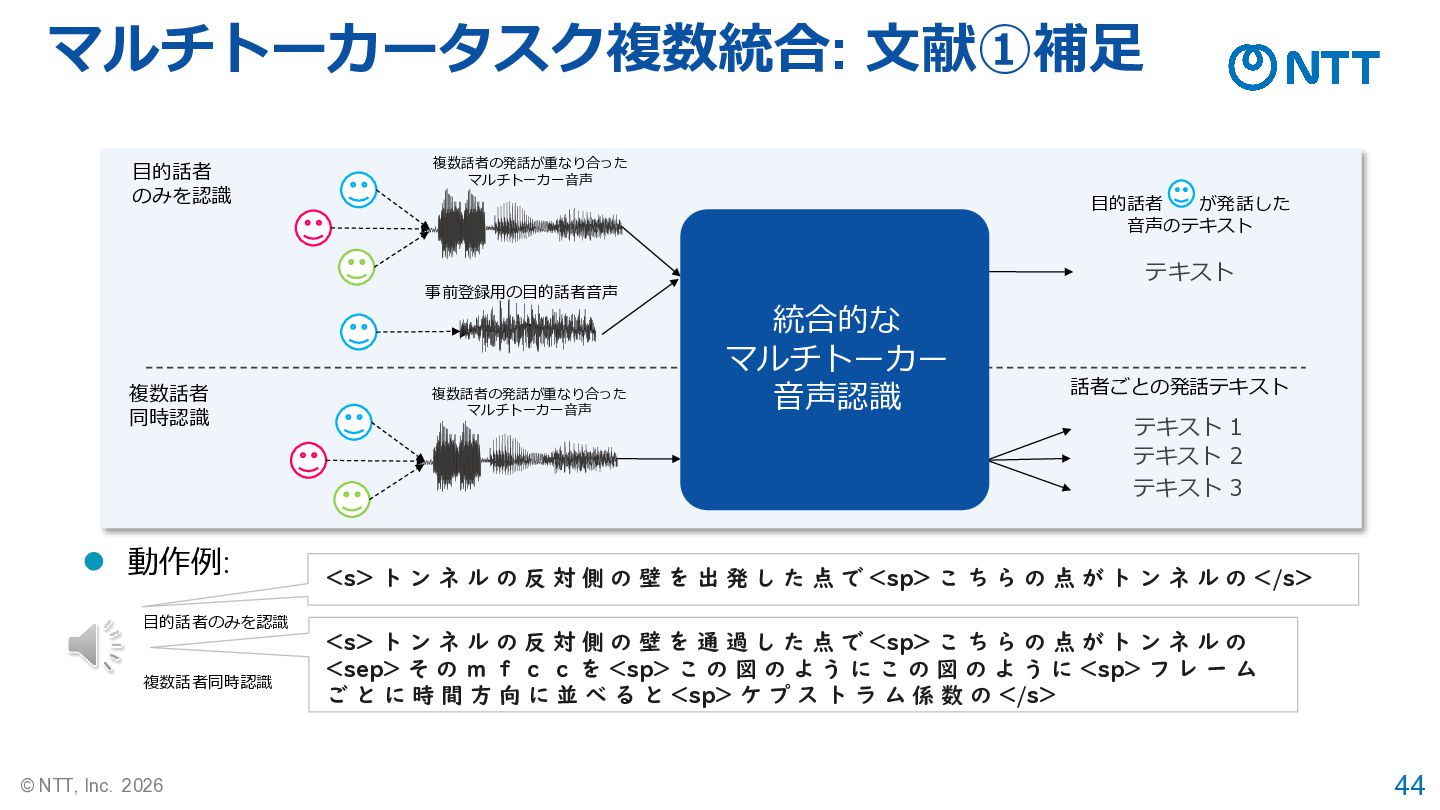
44 © NTT, Inc. 2026 テキスト テキスト 1 テキスト 2
テキスト 3 統合的な マルチトーカー 音声認識 複数話者 同時認識 目的話者 のみを認識 複数話者の発話が重なり合った マルチトーカー音声 複数話者の発話が重なり合った マルチトーカー音声 話者ごとの発話テキスト 目的話者 が発話した 音声のテキスト 事前登録用の目的話者音声 <s> ト ン ネ ル の 反 対 側 の 壁 を 通 過 し た 点 で <sp> こ ち ら の 点 が ト ン ネ ル の <sep> そ の m f c c を <sp> こ の 図 の よ う に こ の 図 の よ う に <sp> フ レ ー ム ご と に 時 間 方 向 に 並 べ る と <sp> ケ プ ス ト ラ ム 係 数 の </s> <s> ト ン ネ ル の 反 対 側 の 壁 を 出 発 し た 点 で <sp> こ ち ら の 点 が ト ン ネ ル の </s> ⚫ 動作例: 目的話者のみを認識 複数話者同時認識 マルチトーカータスク複数統合: 文献①補足
45 © NTT, Inc. 2026 Lingwei Meng, Shujie Hu, Jiawen
Kang, Zhaoqing Li, Yuejiao Wang, Wenxuan Wu, “Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions”, ICASSP 2025. ◼ SLM型の中で、マルチトーカー音声認識や目的話者の認識など、 各タスクに指示文を割り当てて統合的にモデリング [Meng+ 2025] マルチトーカータスク複数統合: 文献② ⚫ 動機: SLMが発展してきているものの、 マルチトーカー音声を扱う複数のタスク が扱えるか明らかではない ⚫ 手法のポイント: 複数のマルチトーカータスクを準備 して、各タスクに指示文を割り当てて、 全タスクのデータを使ってSLMを学習 ⚫ 結果: 指示文で動作を切り替えることが可能で、 複数タスクを同時に学習することでマルチトーカー 音声認識の精度もわずかに改善 「男性」や「3番目に話し始めた人」など、 のマルチトーカータスクも作り、それらも含めて一括学習 典型的なSLMを使い、 マルチトーカータスクを 指示文で切り替える
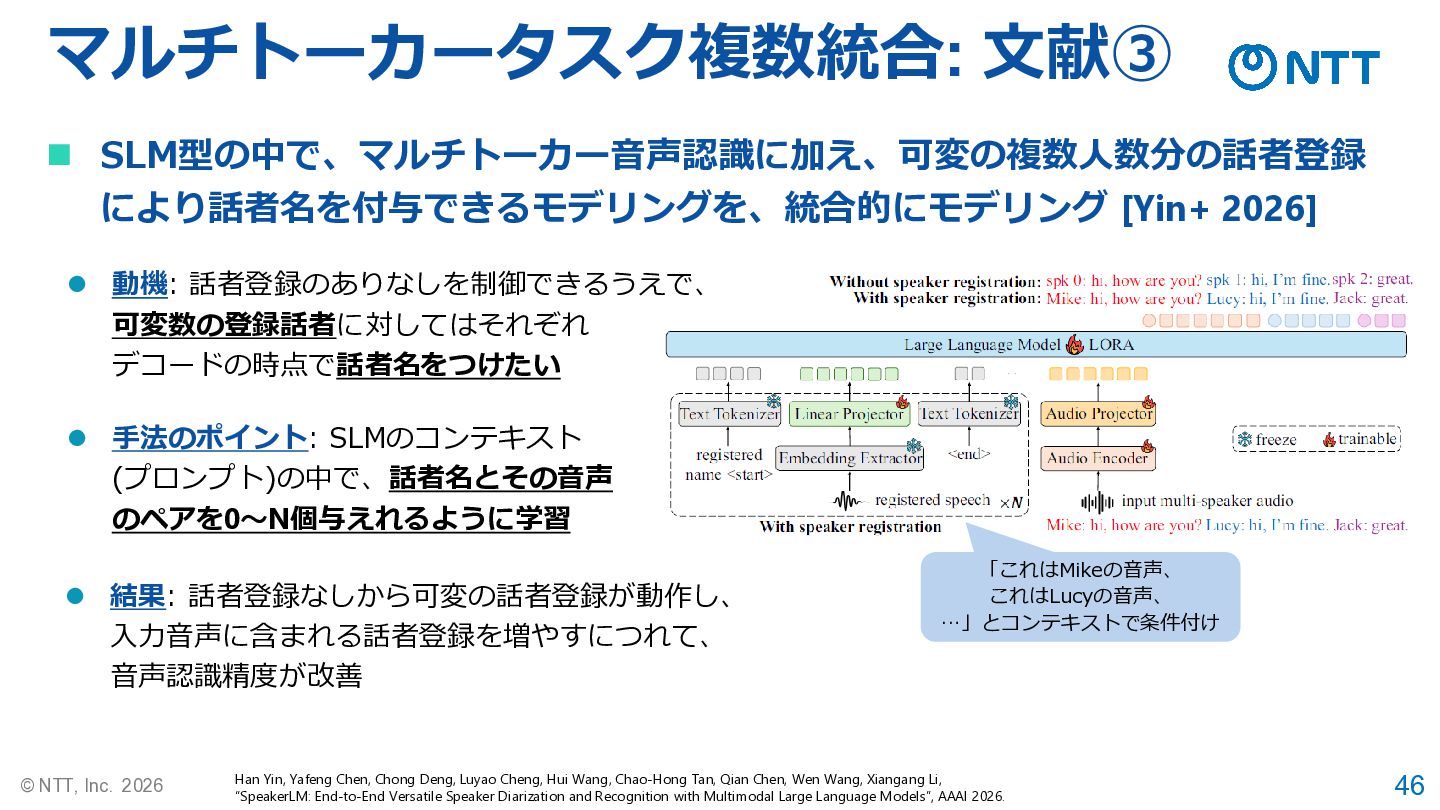
46 © NTT, Inc. 2026 マルチトーカータスク複数統合: 文献➂ Han Yin, Yafeng
Chen, Chong Deng, Luyao Cheng, Hui Wang, Chao-Hong Tan, Qian Chen, Wen Wang, Xiangang Li, “SpeakerLM: End-to-End Versatile Speaker Diarization and Recognition with Multimodal Large Language Models”, AAAI 2026. ◼ SLM型の中で、マルチトーカー音声認識に加え、可変の複数人数分の話者登録 により話者名を付与できるモデリングを、統合的にモデリング [Yin+ 2026] ⚫ 動機: 話者登録のありなしを制御できるうえで、 可変数の登録話者に対してはそれぞれ デコードの時点で話者名をつけたい ⚫ 手法のポイント: SLMのコンテキスト (プロンプト)の中で、話者名とその音声 のペアを0~N個与えれるように学習 ⚫ 結果: 話者登録なしから可変の話者登録が動作し、 入力音声に含まれる話者登録を増やすにつれて、 音声認識精度が改善 「これはMikeの音声、 これはLucyの音声、 …」とコンテキストで条件付け
47 © NTT, Inc. 2026 研究動向: 長時間音声への対応 ◼ E2Eマルチトーカー音声認識は発話クリップ単位(VAD区切り、30-60秒区切り) であるが、実会話に対しては発話境界を越えた対応づけが必要
⚫ ナイーブなアプローチ: マルチトーカー音声認識と並行して、 ダイアライゼーションや話者ベクトル抽出等の 複数モデルを使って、システムカスケーディング ⚫ 検討が進んでいるアプローチ: マルチトーカー音声認識とダイアライゼー ションや話者ベクトル抽出を統合的に扱うことが可能なモデリング E2Eマルチトーカー音声認識は、30-60秒程度 の長さのクリップとなっていること前提 とすることが多い • 課題: 全体最適とはならず、ダイアライゼーションや 話者ベクトル抽出とマルチトーカー音声認識の結果の マッチングで不整合が発生、エラーの伝搬も被る
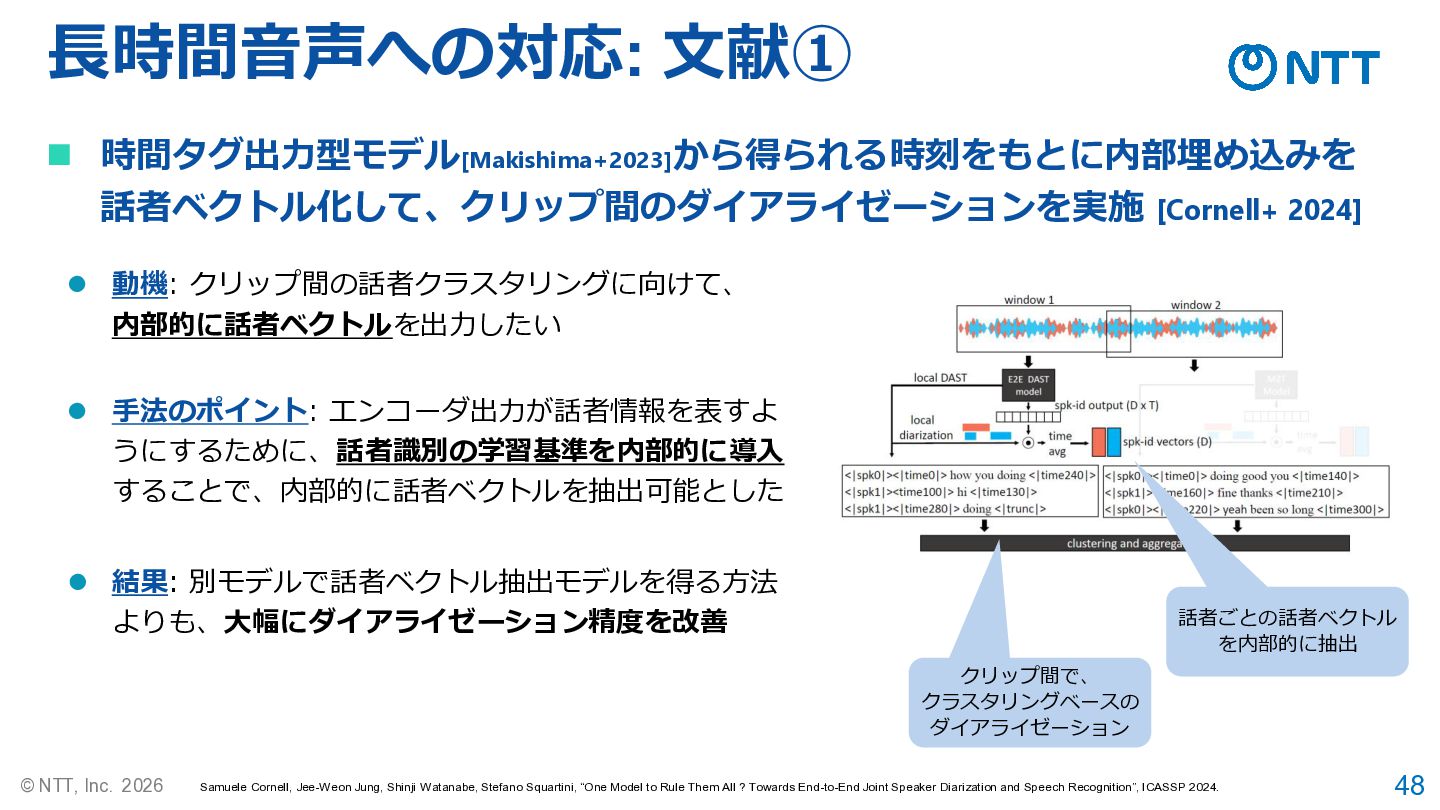
48 © NTT, Inc. 2026 Samuele Cornell, Jee-Weon Jung, Shinji
Watanabe, Stefano Squartini, “One Model to Rule Them All ? Towards End-to-End Joint Speaker Diarization and Speech Recognition”, ICASSP 2024. 長時間音声への対応: 文献① ◼ 時間タグ出力型モデル[Makishima+2023] から得られる時刻をもとに内部埋め込みを 話者ベクトル化して、クリップ間のダイアライゼーションを実施 [Cornell+ 2024] ⚫ 動機: クリップ間の話者クラスタリングに向けて、 内部的に話者ベクトルを出力したい ⚫ 手法のポイント: エンコーダ出力が話者情報を表すよ うにするために、話者識別の学習基準を内部的に導入 することで、内部的に話者ベクトルを抽出可能とした ⚫ 結果: 別モデルで話者ベクトル抽出モデルを得る方法 よりも、大幅にダイアライゼーション精度を改善 話者ごとの話者ベクトル を内部的に抽出 クリップ間で、 クラスタリングベースの ダイアライゼーション
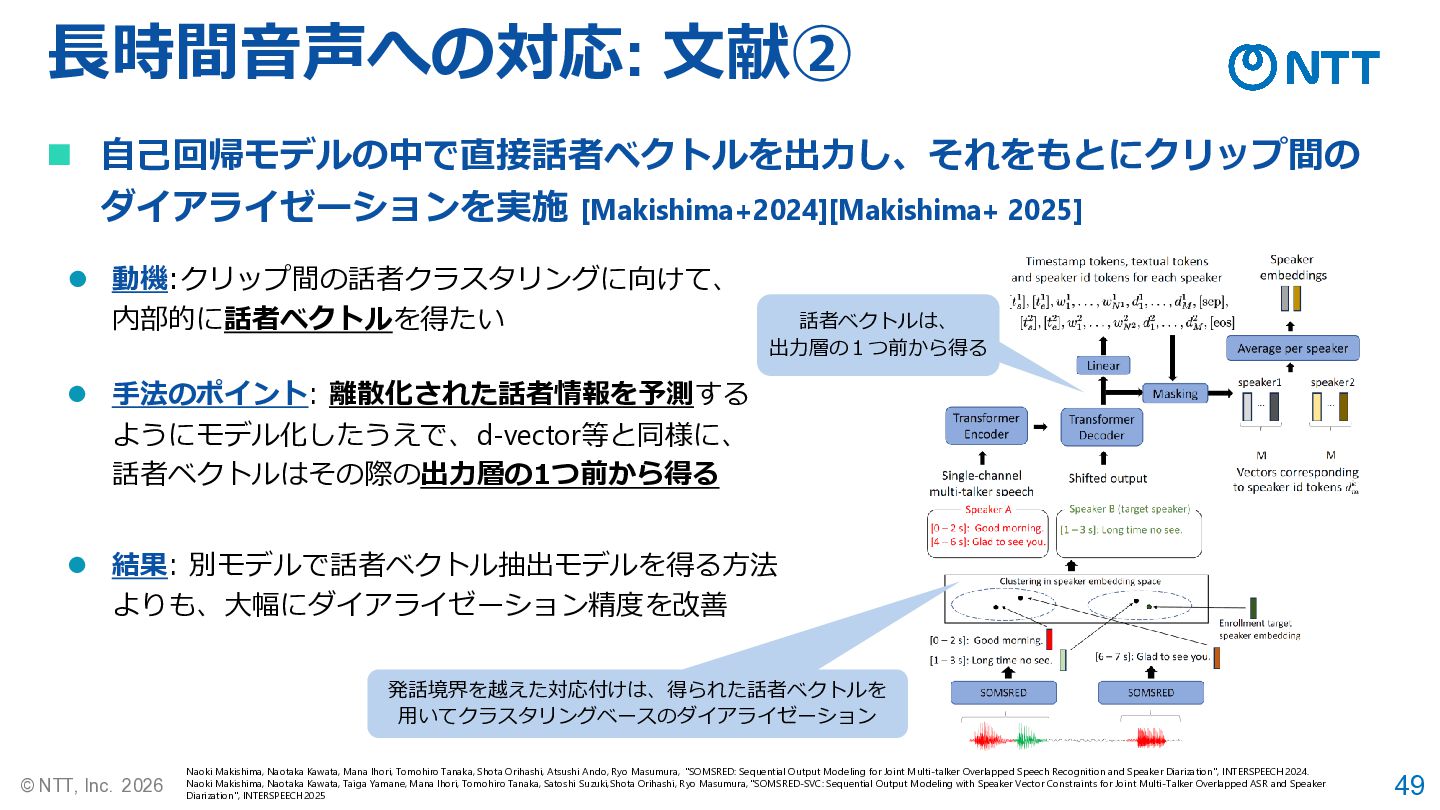
49 © NTT, Inc. 2026 長時間音声への対応: 文献② Naoki Makishima, Naotaka
Kawata, Mana Ihori, Tomohiro Tanaka, Shota Orihashi, Atsushi Ando, Ryo Masumura, "SOMSRED: Sequential Output Modeling for Joint Multi-talker Overlapped Speech Recognition and Speaker Diarization", INTERSPEECH 2024. Naoki Makishima, Naotaka Kawata, Taiga Yamane, Mana Ihori, Tomohiro Tanaka, Satoshi Suzuki,Shota Orihashi, Ryo Masumura, "SOMSRED-SVC: Sequential Output Modeling with Speaker Vector Constraints for Joint Multi-Talker Overlapped ASR and Speaker Diarization", INTERSPEECH2025 ◼ 自己回帰モデルの中で直接話者ベクトルを出力し、それをもとにクリップ間の ダイアライゼーションを実施 [Makishima+2024][Makishima+ 2025] ⚫ 動機:クリップ間の話者クラスタリングに向けて、 内部的に話者ベクトルを得たい 発話境界を越えた対応付けは、得られた話者ベクトルを 用いてクラスタリングベースのダイアライゼーション 話者ベクトルは、 出力層の1つ前から得る ⚫ 手法のポイント: 離散化された話者情報を予測する ようにモデル化したうえで、d-vector等と同様に、 話者ベクトルはその際の出力層の1つ前から得る ⚫ 結果: 別モデルで話者ベクトル抽出モデルを得る方法 よりも、大幅にダイアライゼーション精度を改善
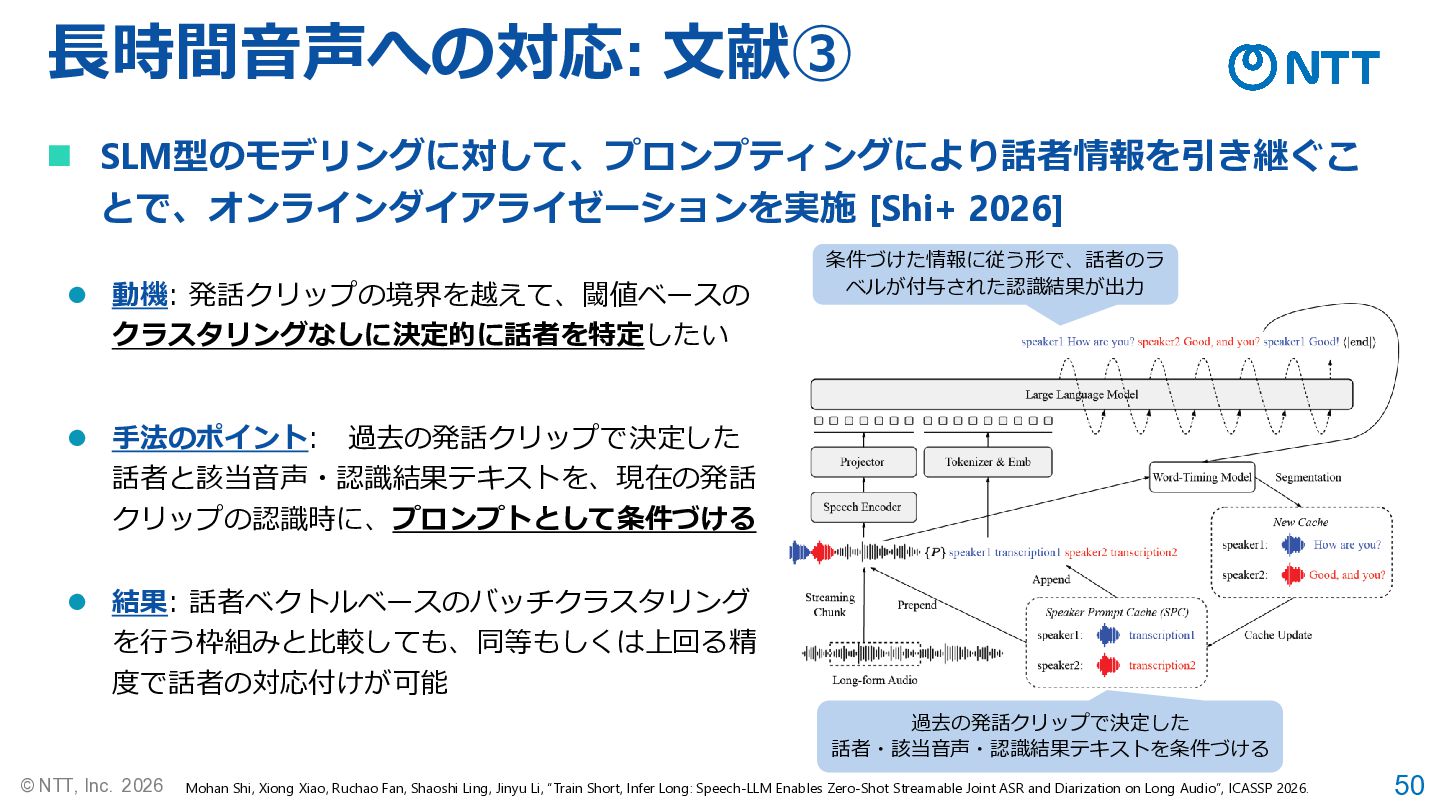
50 © NTT, Inc. 2026 長時間音声への対応: 文献➂ Mohan Shi, Xiong
Xiao, Ruchao Fan, Shaoshi Ling, Jinyu Li, “Train Short, Infer Long: Speech-LLM Enables Zero-Shot Streamable Joint ASR and Diarization on Long Audio”, ICASSP 2026. ◼ SLM型のモデリングに対して、プロンプティングにより話者情報を引き継ぐこ とで、オンラインダイアライゼーションを実施 [Shi+ 2026] ⚫ 手法のポイント: 過去の発話クリップで決定した 話者と該当音声・認識結果テキストを、現在の発話 クリップの認識時に、プロンプトとして条件づける ⚫ 動機: 発話クリップの境界を越えて、閾値ベースの クラスタリングなしに決定的に話者を特定したい ⚫ 結果: 話者ベクトルベースのバッチクラスタリング を行う枠組みと比較しても、同等もしくは上回る精 度で話者の対応付けが可能 過去の発話クリップで決定した 話者・該当音声・認識結果テキストを条件づける 条件づけた情報に従う形で、話者のラ ベルが付与された認識結果が出力
51 © NTT, Inc. 2026 Zhiliang Peng, Jianwei Yu, Yaoyao
Chang, ZilongWang, Li Dong, et.al., “VIBEVOICE-ASR Technical Report”, arXiv:2601.18184 ◼ 60分のマルチトーカー音声を扱えるように、ロングコンテキストを扱うことが 可能なSLMとしてEnd-to-Endにモデル化 [Peng+, 2026] 長時間音声への対応: 文献④ ⚫ 動機: 一定時間のクリップごとの処理+α、ではなく、 できることならE2Eにすべて処理してしまいたい ⚫ 手法のポイント: 60分で27,000トークン(1秒で7.5 トークン)とできる音声エンコーダを準備し、6万程 度のコンテキスト長を扱えるLLMとつないでSLM化、 長い音声を積極的に使って学習 ⚫ 結果: 長めの音声に対しても、話者を切り分けた 一貫性ある結果を出力 60分で27,000トークンとできる 音声エンコーダをつなぐ
52 © NTT, Inc. 2026 研究動向: 映像情報の考慮 ◼ 実世界の会話においては、音声情報のみならず、同時に映像情報も得られる 場合があり、映像も含めた理解が検討されている
0秒-4.5秒 すごい、大盤振る舞いすね、予算が、予算がいっぱい 1.5秒-6.5秒 なんかすごいバブリーになってきましたねうんうんうん 3.5秒-12.0秒 ちょっと、か、社長に掛け合わなきゃいけないですけど、今 年ちょっと余ってるって聞いたんで、そういうのもありかなっていうのはちょっと 僕のアイデアであるんですけどね 5.5秒-6.0秒 うんうんうんうん 8.0秒-9.5秒 へー 映像 映像と対応付けた発話内容 ⚫ 検討が進んでいるアプローチ: 音声と映像情報の同時利用によるマルチトーカー音声認識、 音声情報と映像情報の対応付けを含めたマルチトーカー音声認識のモデリング
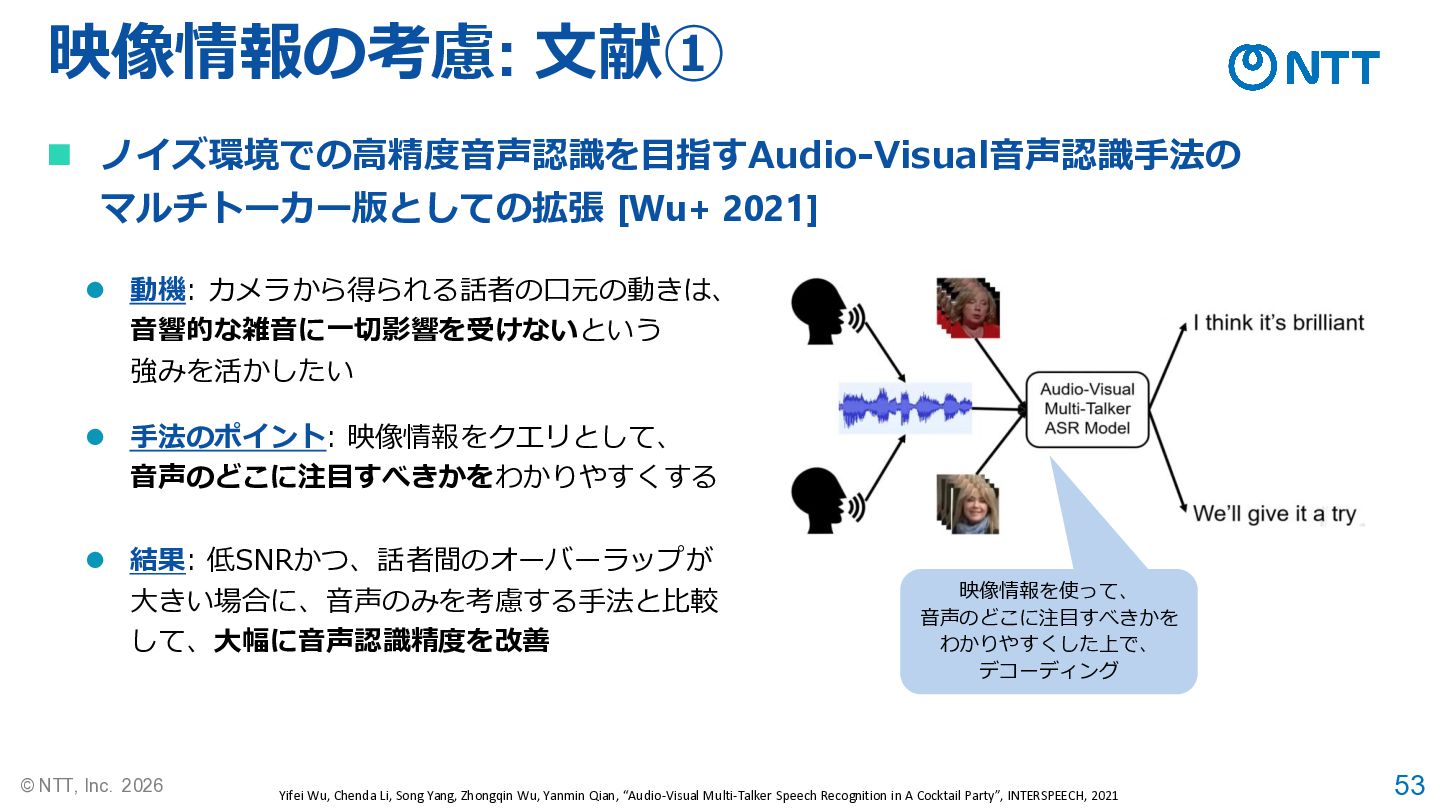
53 © NTT, Inc. 2026 映像情報の考慮: 文献① Yifei Wu, Chenda
Li, Song Yang, Zhongqin Wu, Yanmin Qian, “Audio-Visual Multi-Talker Speech Recognition in A Cocktail Party”, INTERSPEECH, 2021 ◼ ノイズ環境での高精度音声認識を目指すAudio-Visual音声認識手法の マルチトーカー版としての拡張 [Wu+ 2021] ⚫ 動機: カメラから得られる話者の口元の動きは、 音響的な雑音に一切影響を受けないという 強みを活かしたい ⚫ 結果: 低SNRかつ、話者間のオーバーラップが 大きい場合に、音声のみを考慮する手法と比較 して、大幅に音声認識精度を改善 ⚫ 手法のポイント: 映像情報をクエリとして、 音声のどこに注目すべきかをわかりやすくする 映像情報を使って、 音声のどこに注目すべきかを わかりやすくした上で、 デコーディング
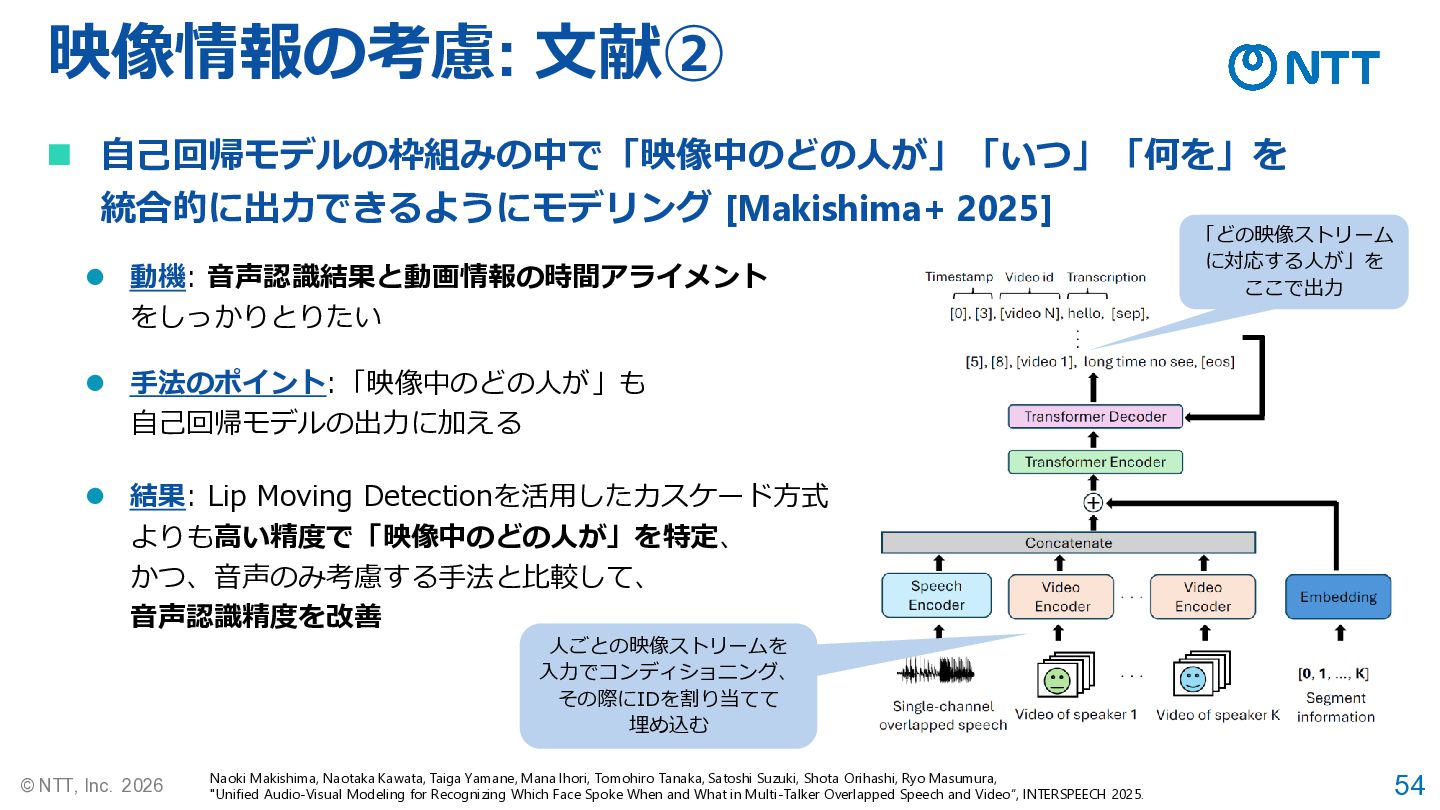
54 © NTT, Inc. 2026 映像情報の考慮: 文献② Naoki Makishima, Naotaka
Kawata, Taiga Yamane, Mana Ihori, Tomohiro Tanaka, Satoshi Suzuki, Shota Orihashi, Ryo Masumura, "Unified Audio-Visual Modeling for Recognizing Which Face Spoke When and What in Multi-Talker Overlapped Speech and Video“, INTERSPEECH 2025. ◼ 自己回帰モデルの枠組みの中で「映像中のどの人が」「いつ」「何を」を 統合的に出力できるようにモデリング [Makishima+ 2025] ⚫ 動機: 音声認識結果と動画情報の時間アライメント をしっかりとりたい 「どの映像ストリーム に対応する人が」を ここで出力 人ごとの映像ストリームを 入力でコンディショニング、 その際にIDを割り当てて 埋め込む ⚫ 結果: Lip Moving Detectionを活用したカスケード方式 よりも高い精度で「映像中のどの人が」を特定、 かつ、音声のみ考慮する手法と比較して、 音声認識精度を改善 ⚫ 手法のポイント:「映像中のどの人が」も 自己回帰モデルの出力に加える
55 © NTT, Inc. 2026 研究動向まとめ ◼ E2Eマルチトーカー音声認識は2020年当初から急激に進化している ⚫ 触れられなかったが興味深い研究動向はまだまだ…
• 各話者の発話テキストのデコーディング順序 (学習時のシリアライズ) の再考 • トークン単位の詳細なタイムスタンプの付与 • リアル会話の認識に役立つシュミレーション会話データの生成 • SLM型を活かした外部モジュール情報をコンテキストに使ったモデリング • … • ダイアライゼーション部分における言語コンテキストの明示的な利用
56 © NTT, Inc. 2026 本日の内容 ◼ End-to-End型のシングルチャネルマルチトーカー音声認識の進展について、 我々の取り組みも絡めながら、研究動向を概説 1.
自己紹介と前置き 2. マルチトーカー音声認識の基礎とEnd-to-End型の登場 3. End-to-Endマルチトーカー音声認識の研究動向 4. おわりに
57 © NTT, Inc. 2026 おわりに ◼ マルチトーカー音声認識はこの数年で大きく進歩 ⚫ 現在の技術の到達点に対する私の肌感
• 急激に実用的な技術レベルも上がり、「音声認識+ダイアライゼーション」という システムとしては、かなりの実用的なシーンで十分満足な体感を与えられるレベルに到達 ⚫ 研究動向で触れた以外で、研究分野の進む先についての私の考え • 人対人の複数人会話に介入できるFull-Duplex音声対話モデリング • 音声映像を同時に捉えるマルチモーダルLM化と、 複数人会話の内容と非言語情報を同時に捉えることが必要な深い理解 • マルチチャネルにおけるアプローチとパーティ会場レベルの人数を扱うマルチトーカー音声認識 • 遠隔マイクでの残響や話者ごとのボリュームの差異などに起因した課題はあるが、 データドリブンなアプローチで自ずと解決はしていきそう • 会話だけでなく、会話の周辺音(生活音、ペットの泣き声、楽器、etc.)を 含めた実世界としての様々な音の同時理解
58 © NTT, Inc. 2026 一緒に働いてくれる仲間を探しています、気軽に連絡ください • 人を音声・映像から理解することを主眼としたマルチモーダル基盤モデル • 実世界の複数人コミュニケーション理解
• マルチトーカー音声認識 • … • 人に対する深い内面理解・印象理解 Special Thanks: マルチトーカー音声認識を一緒に研究開発しているメンバー 田中 智大 牧島 直輝 チームメンバー 音声関連研究の仲間
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}