■AI×DevOps Study #12 の概要
2026年4月16日に開催した「AI×DevOps Study」第12回のアーカイブ動画です。
「AI×DevOps Study」は、AI駆動開発やそこに関係するマイクロサービスについて理解を深める場になります。
株式会社ScalarではAIを使ったチーム開発を進めており、参画しているメンバーや協力会社の方から、具体的なAI駆動開発を実施する方法、その中で生まれたマイクロサービスアーキテクチャを使用したAI駆動開発の事例や実際に使えるエージェントについてお話頂き、参加者の皆様と知識の共有や交換を目的としています。
(弊社製品であるScalarDBも絡んだお話も一部出てきますが、汎用的な内容となっておりますのでフラットにお楽しみいいただけます)
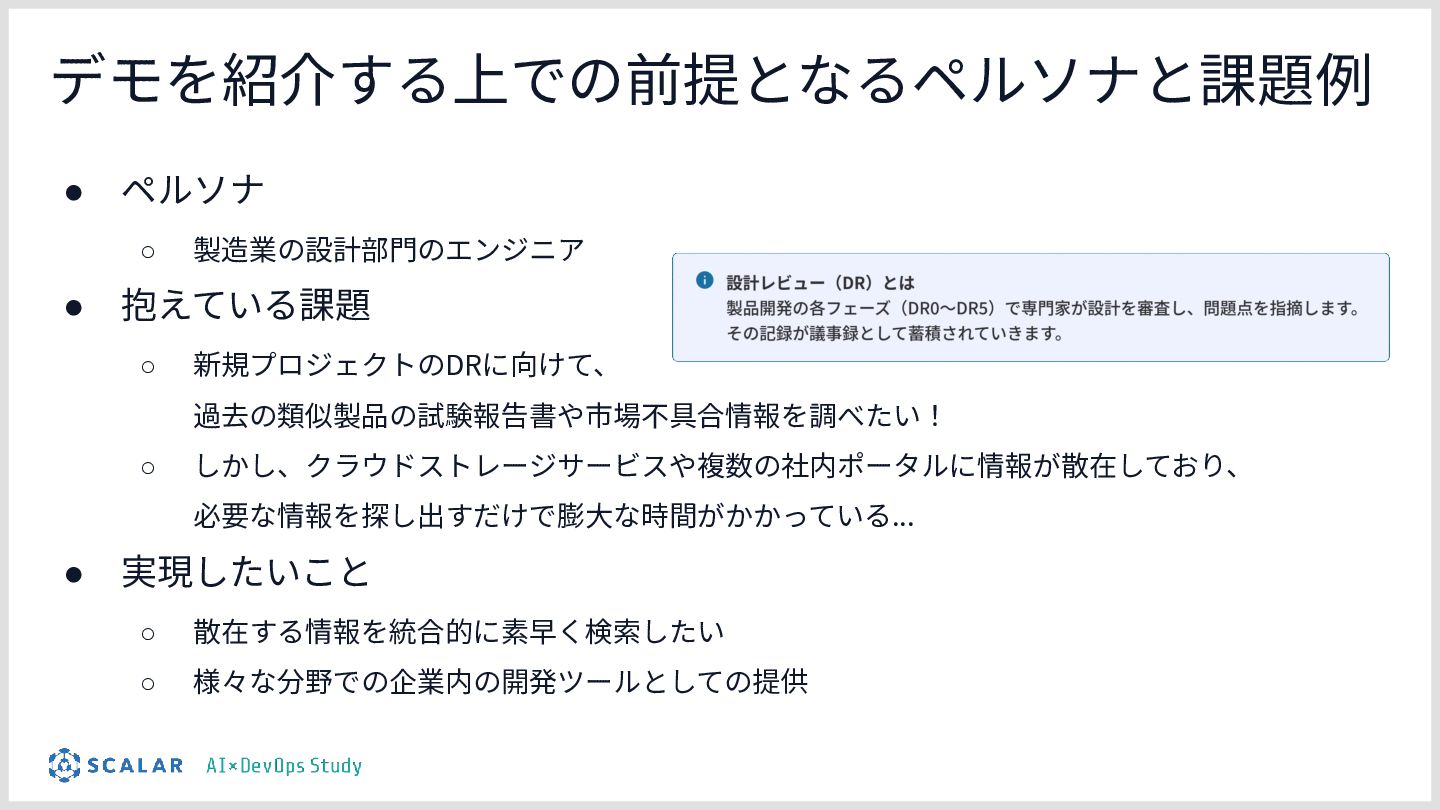
■今回のテーマ
「Claude Codeによる製造業向けのRAGとAI Agent開発」
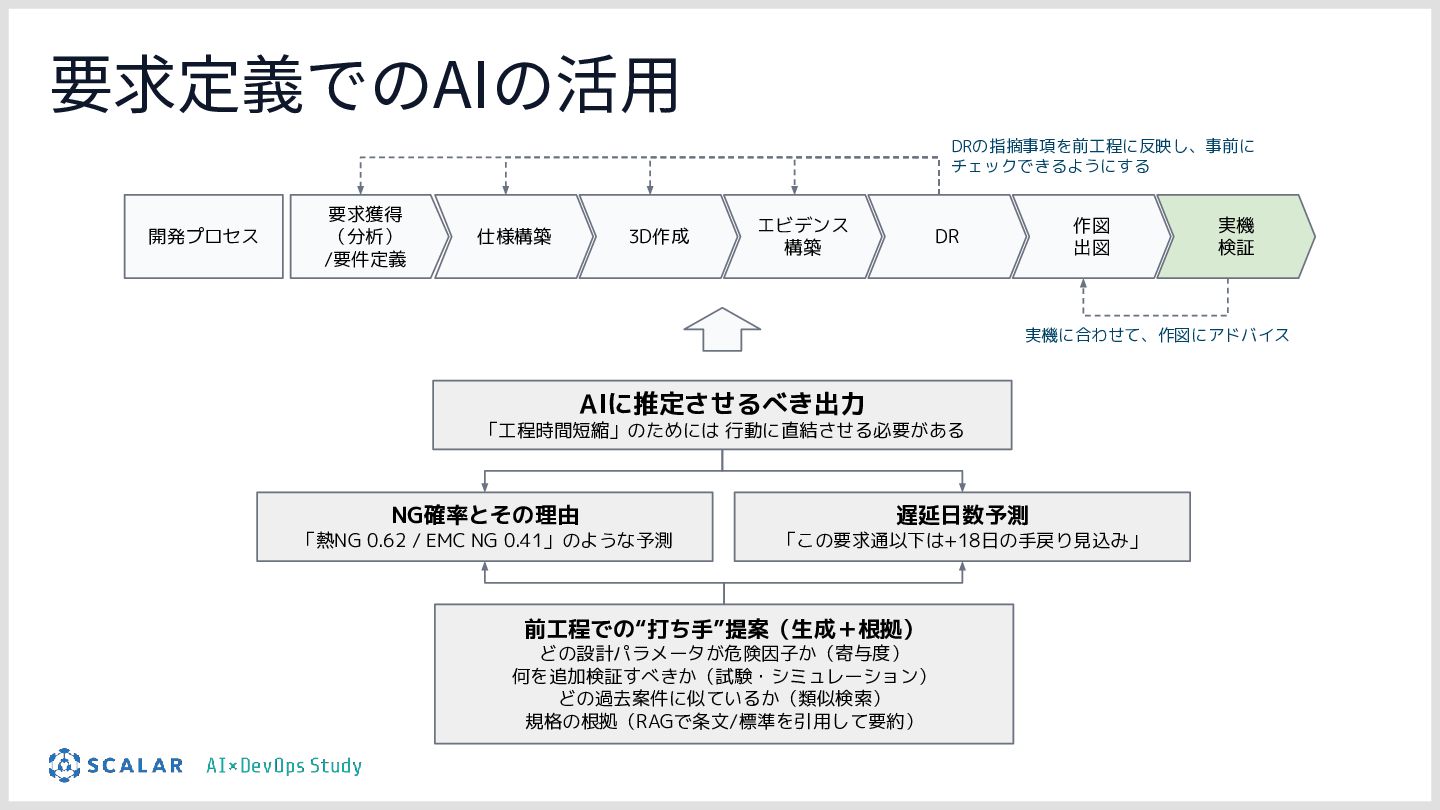
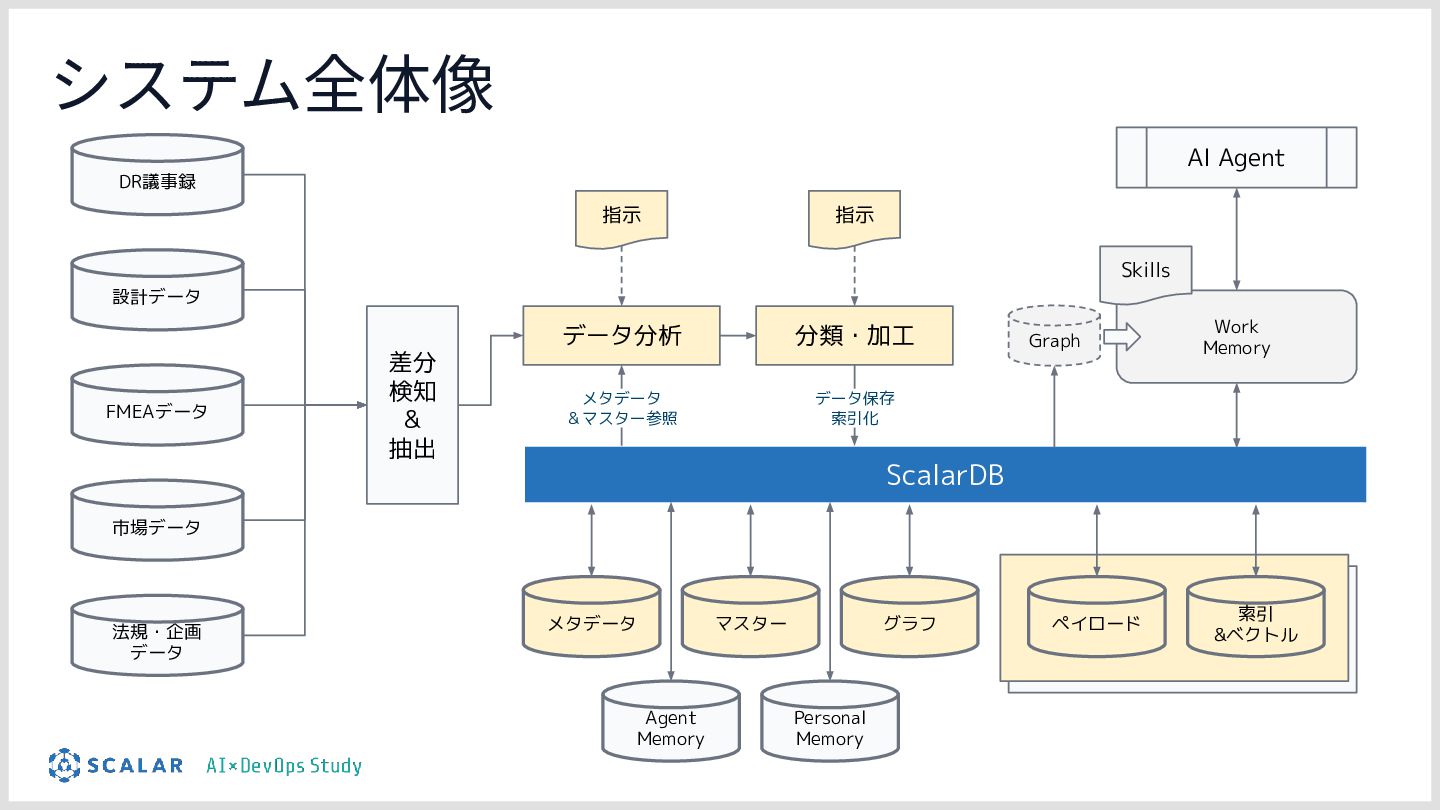
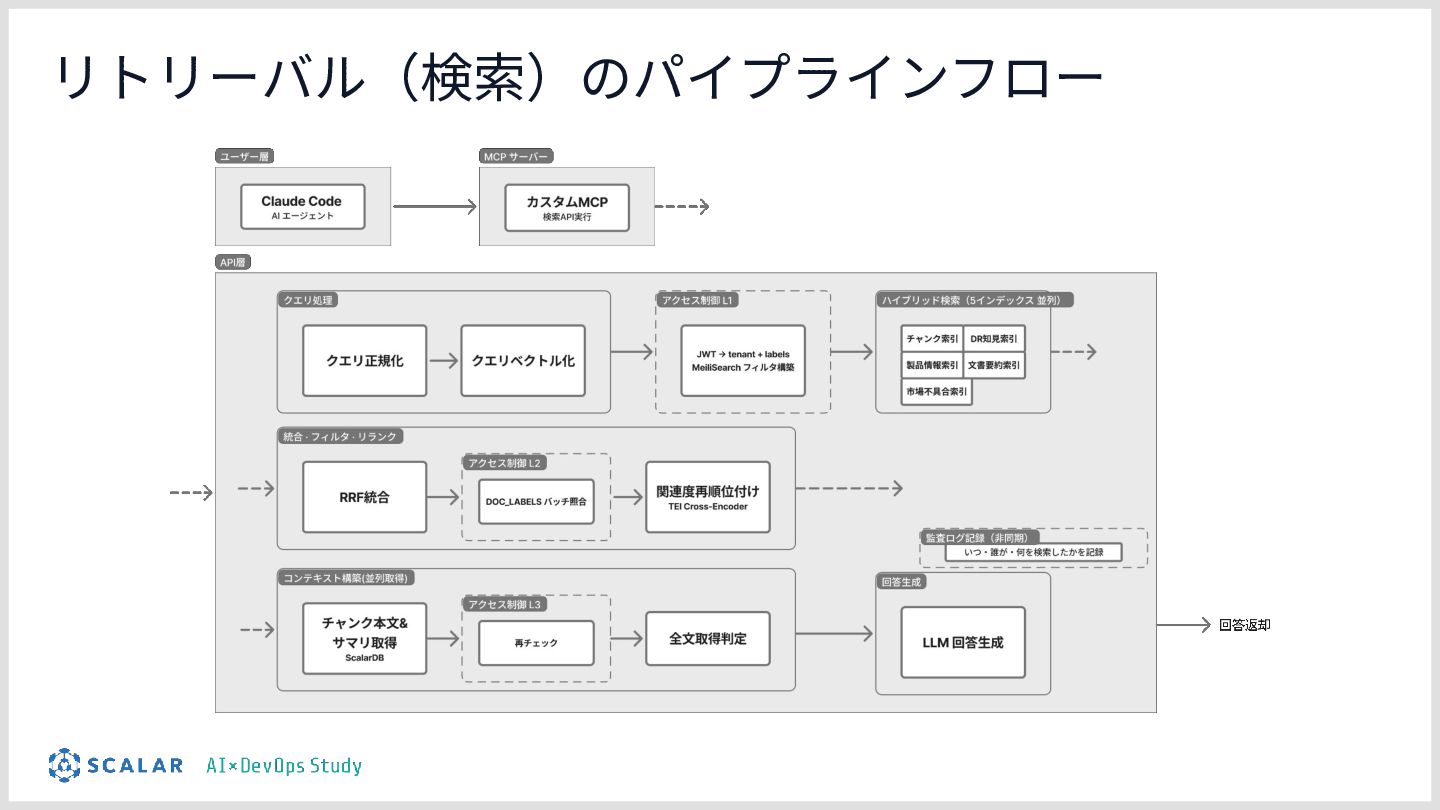
製造業における設計レビュー(Design Review)工程を短縮するための RAG基盤の構築を行いました。 マイクロRAGを構成し、ベクトル検索とキーワード検索を両立し、複数のRAGを連携してエージェントがデータを取得し、物理シュミレーションを実施するためのエージェントをどのように作っているのかをお話しします。
■登壇者情報(敬称略)
深津航
株式会社Scalar Founder & CEO。日本オラクル株式会社、決済系のスタートアップを経て、株式会社Scalarを創業。
箱崎一輝
札幌の株式会社マーベリックスで、Webエンジニア兼リーダーを務めています。 これまで社内のGoogle Workspace全社導入を推進し、組織の働きやすい環境づくりに貢献しました。 今年からはAI駆動型の開発案件に本格的にジョイン。リーダーとしてチームをまとめながら、実際の現場で「AIをどうUI/UX開発に組み込むか」、日々の実践を通じて探求しています。
■関連コンテンツ
・Youtube(過去の勉強会動画も公開中!)
www.youtube.com/@scalar-labs
・Zenn ブログ
https://zenn.dev/p/scalar_sol_blog
・イベントページ(connpass)
https://scalar.connpass.com/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
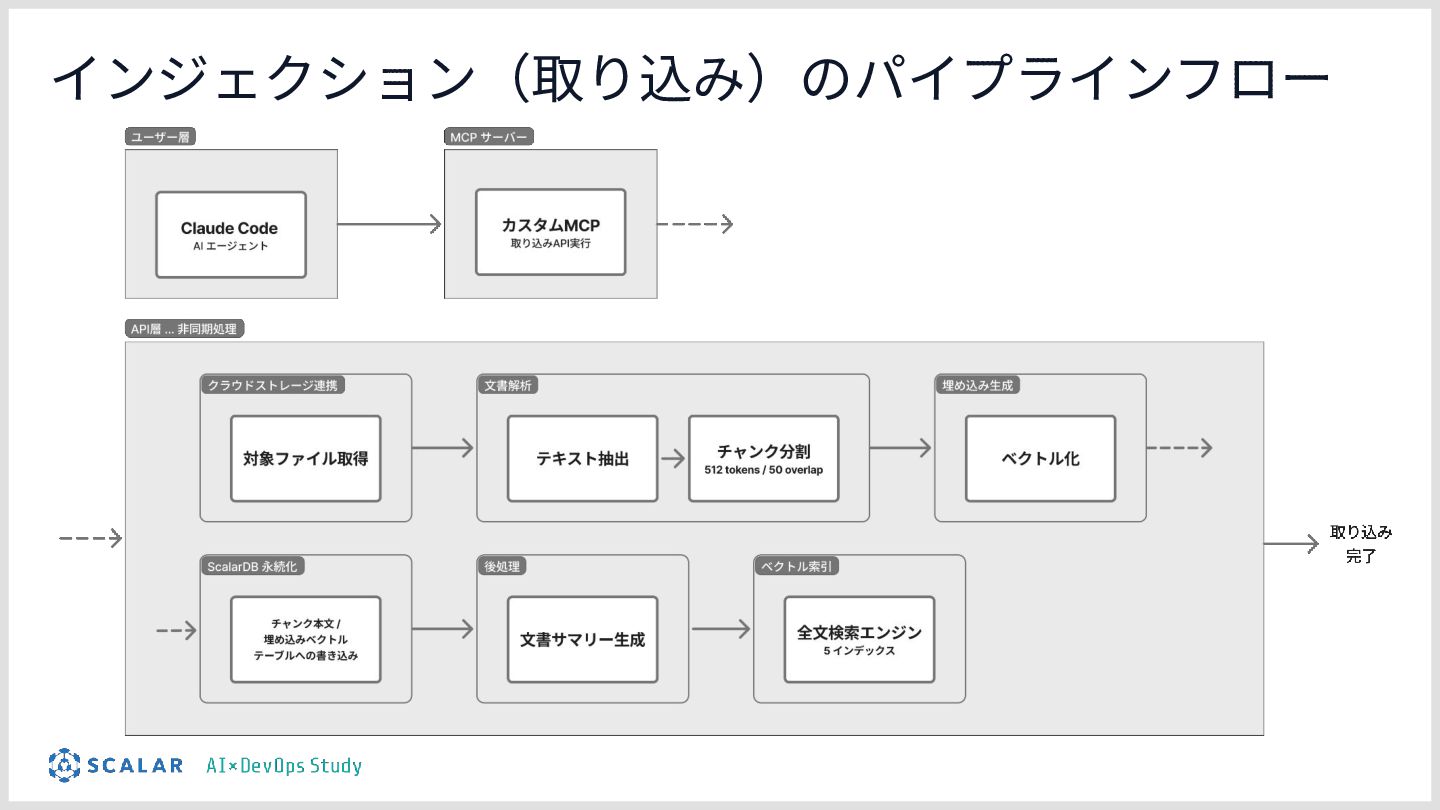
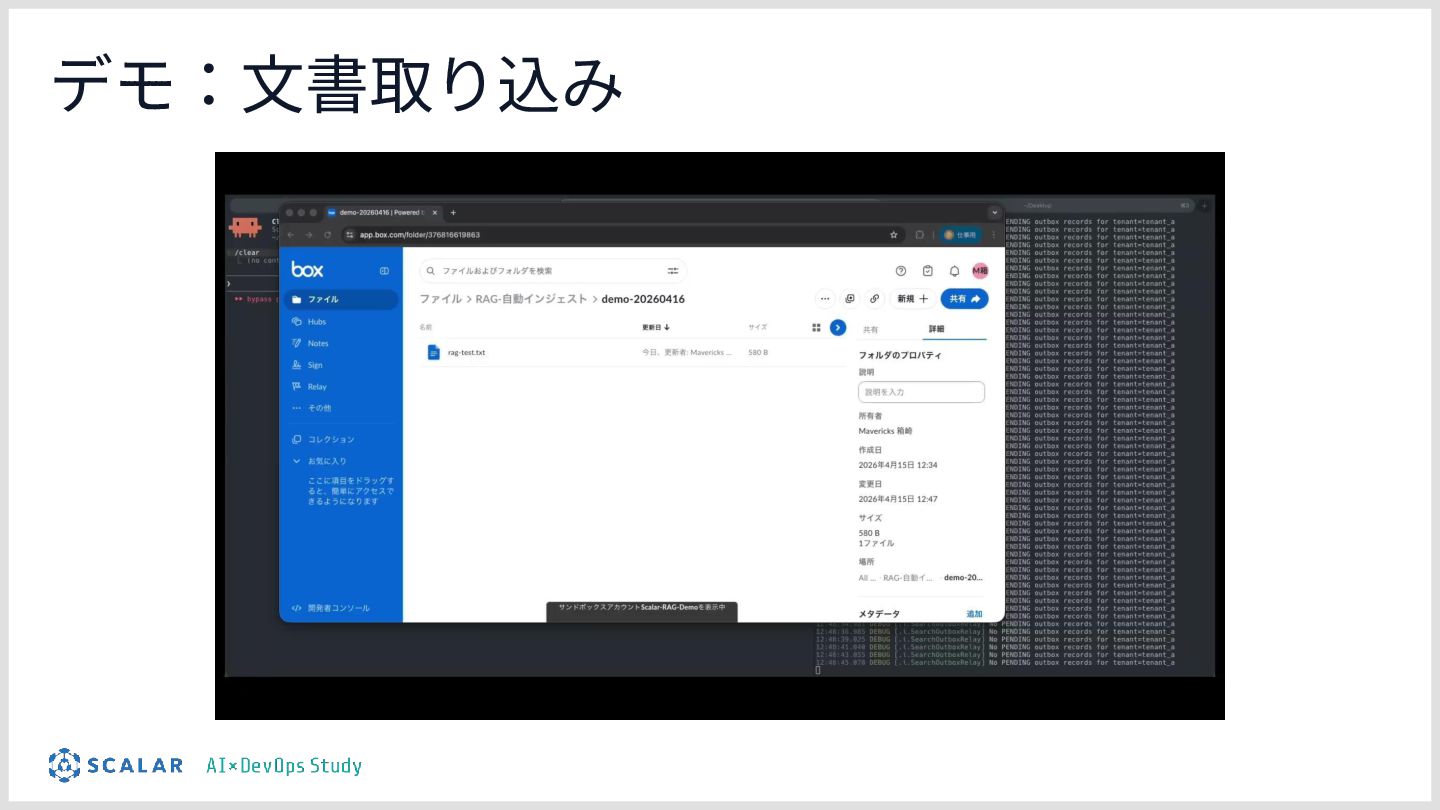
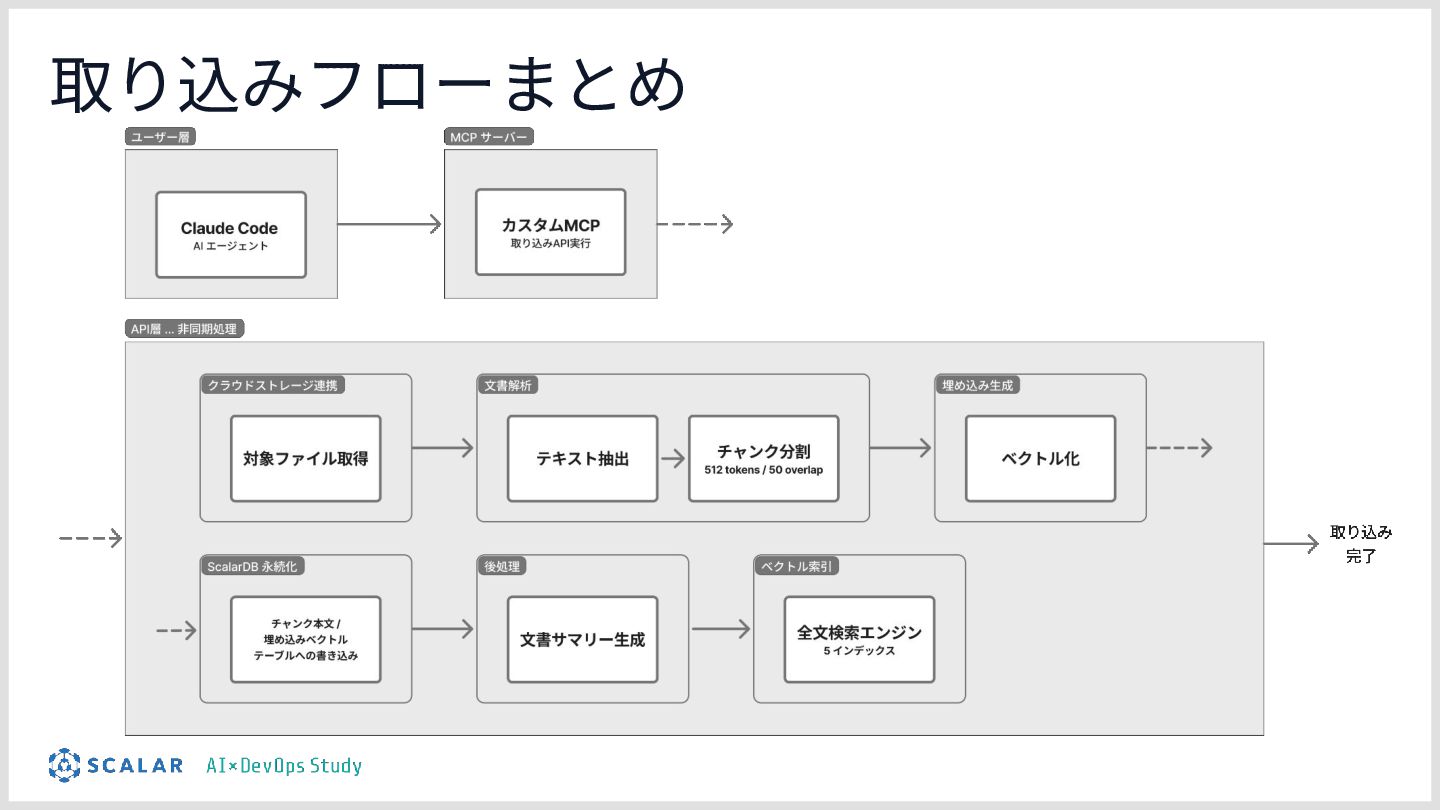
![• クラウドストレージと連携し、 サービスにファイルを追加‧更新するだけで検索に反映される • コネクタを抽象化しているため、SharePointやGoogle Driveなども統⼀APIで扱う ことができる [仕組み] • MCPへの明⽰的な取り込み指⽰や、Webhook連携フォルダ監視による検出](https://files.speakerdeck.com/presentations/e504afdb74914e968b52b6f6f5c23c20/slide_27.jpg){kind=link}
![• 担当者が取り込み時に⽂書カテゴリを⼿⼊⼒せずに分類することができる [仕組み] • ファイル名によるルールベース分類 → LLM による⾃動分類 • ファイル名で分類できない場合、LLMが⽂書の内容をもとに判定](https://files.speakerdeck.com/presentations/e504afdb74914e968b52b6f6f5c23c20/slide_28.jpg){kind=link}
{kind=link}
![製造業データ構造化抽出 • DR議事録から「どのフェーズで何件の熱系 NG があったか」を定量的に把握できる • 市場不具合とDR指摘を関連付けて過去の類似事例を検索できる [仕組み] 分類結果がDR内の不具合報告の場合、 検索エンジンへの反映とは別処理として構造化処理を実施](https://files.speakerdeck.com/presentations/e504afdb74914e968b52b6f6f5c23c20/slide_30.jpg){kind=link}
![• 全⽂取得の判断材料になる(詳しくは回答⽣成時の⼯夫で解説) • チャンクとサマリーを並⾏して検索するので、 ⽂書の概要を問う質問にヒットしやすい ◦ チャンク断⽚だけでは難しかった、”DR3 の議事録を要約して”のような俯瞰的な質問に 答えられる [仕組み]](https://files.speakerdeck.com/presentations/e504afdb74914e968b52b6f6f5c23c20/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
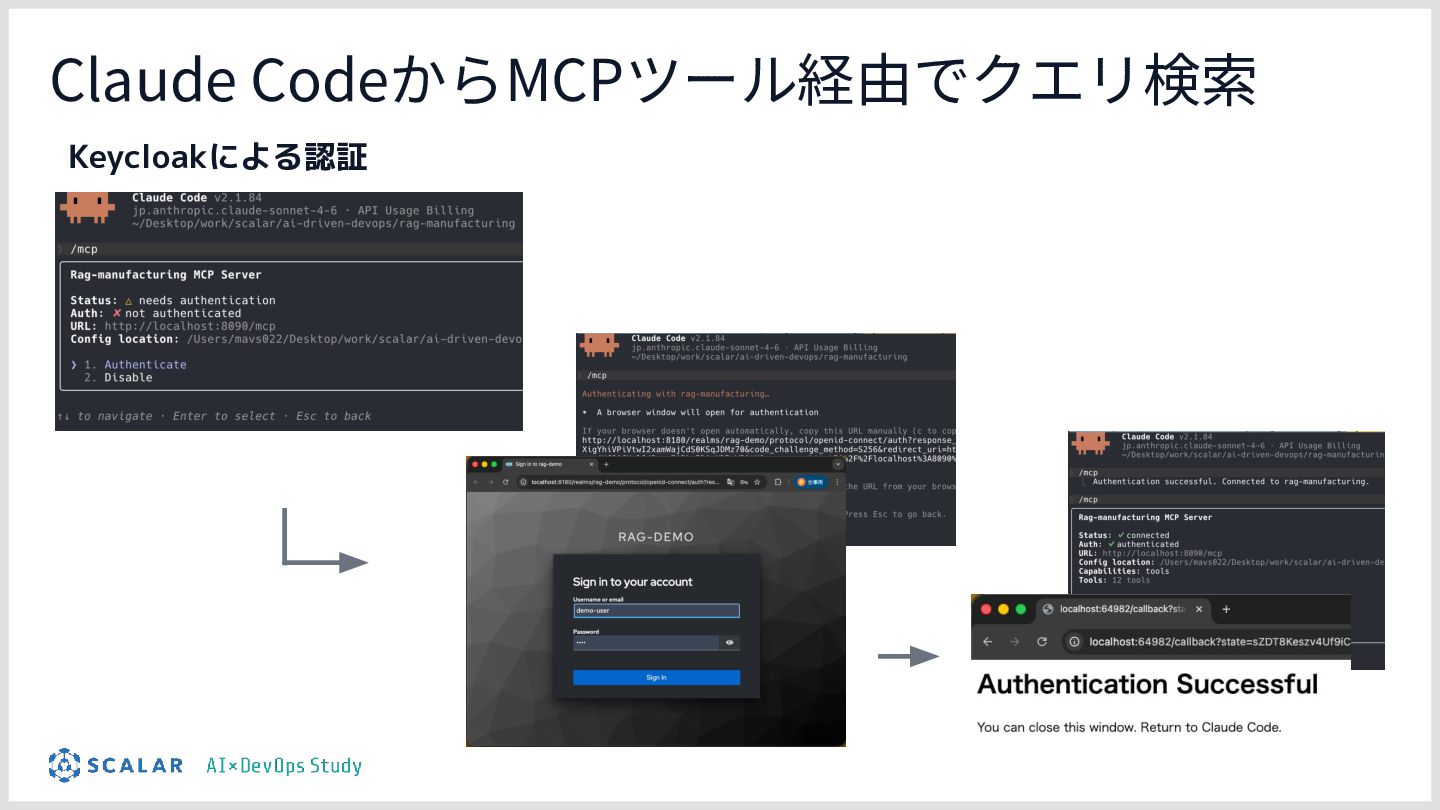
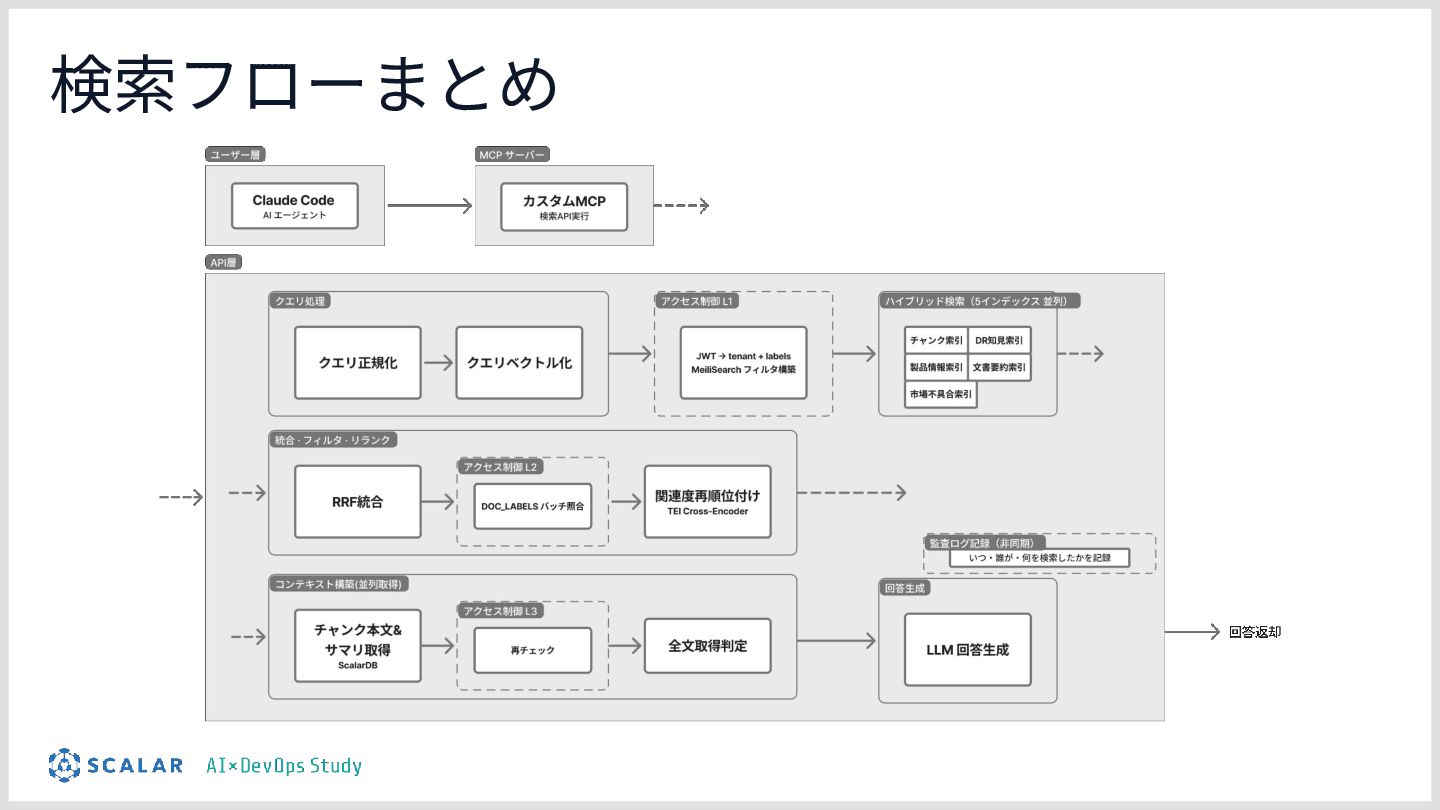
![アクセス権限の検証 ABAC(属性ベースアクセス制御)フィルタにすることで、ユーザーにとって アクセス権限のないチャンクを検索結果から⾃動的に除外する [仕組み] • Layer1:検索前に絞り込む ◦ JWT からテナントIDとユーザーラベルを取り出し、 検索エンジンのクエリに直接フィルターを埋め込む](https://files.speakerdeck.com/presentations/e504afdb74914e968b52b6f6f5c23c20/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
![ロングコンテキスト - ヒューリスティック層 ヒューリスティック … 経験や直感に基づいて “そこそこ正しい答え”を迅速に導き出す思考法(対義語:アルゴリズム) [仕組み] • クエリ内のキーワードマッチ](https://files.speakerdeck.com/presentations/e504afdb74914e968b52b6f6f5c23c20/slide_40.jpg){kind=link}
![ロングコンテキスト - LLM判断 • ヒューリスティックでは判断できなかった場合 ◦ スコアが低く、かつキーワードもない曖昧なクエリ [仕組み] • 上位](https://files.speakerdeck.com/presentations/e504afdb74914e968b52b6f6f5c23c20/slide_41.jpg){kind=link}
{kind=link}
![監査ログの付与 • 記録する内容 ◦ テナントID、セッションID、ユーザーが⼊⼒したクエリ、 返したチャンクと検索スコア、適⽤されたABACフィルタ、 ロングコンテキスト有りかどうか、記録時間 [何のために記録するのか] • いつ誰が何を検索し、何が返却されたのかを追跡する](https://files.speakerdeck.com/presentations/e504afdb74914e968b52b6f6f5c23c20/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}