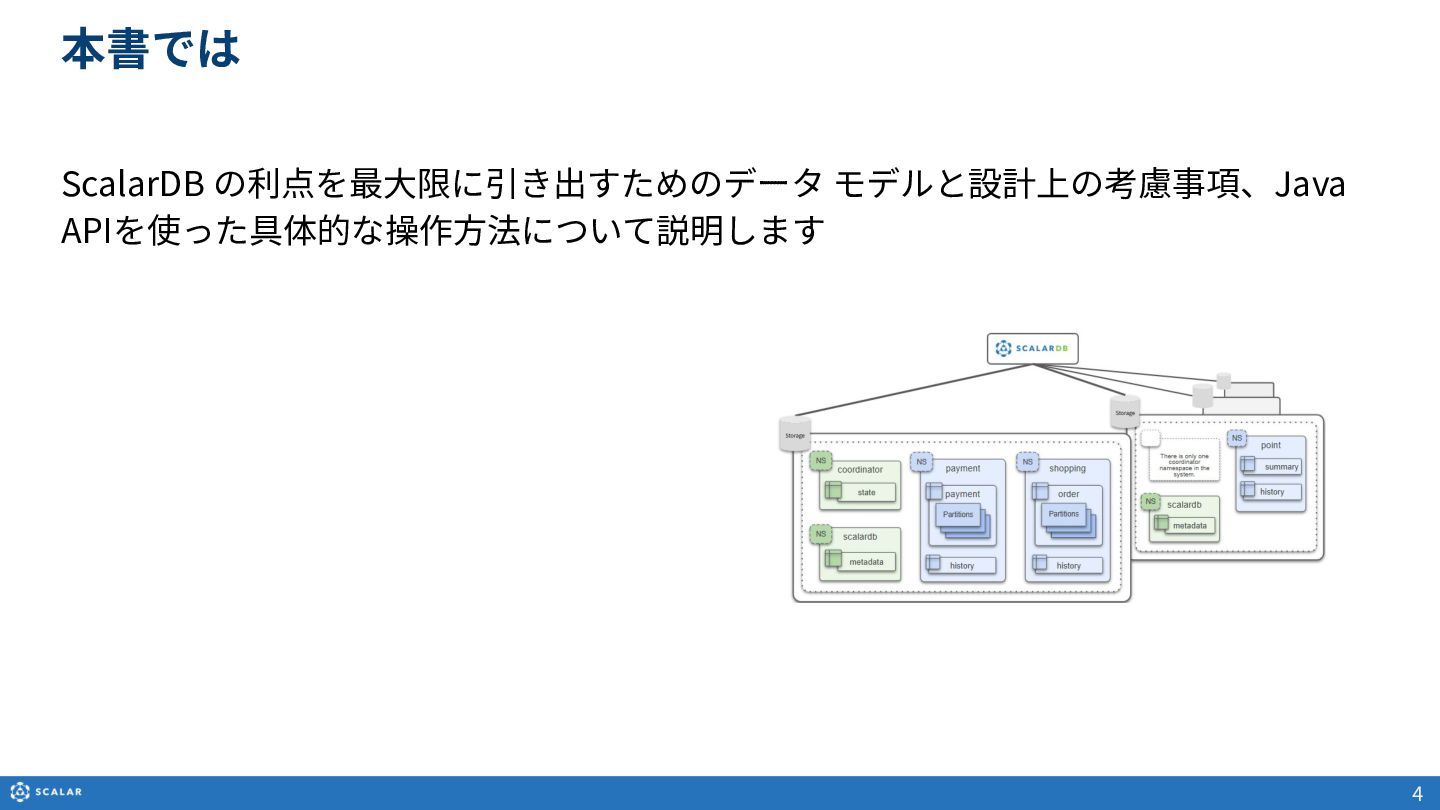
本資料は、ScalarDBの利点を最大限に引き出すためのデータモデルと設計上の考慮事項、およびJava APIを使った具体的なデータアクセス操作について解説したスライドです。
【主な内容】
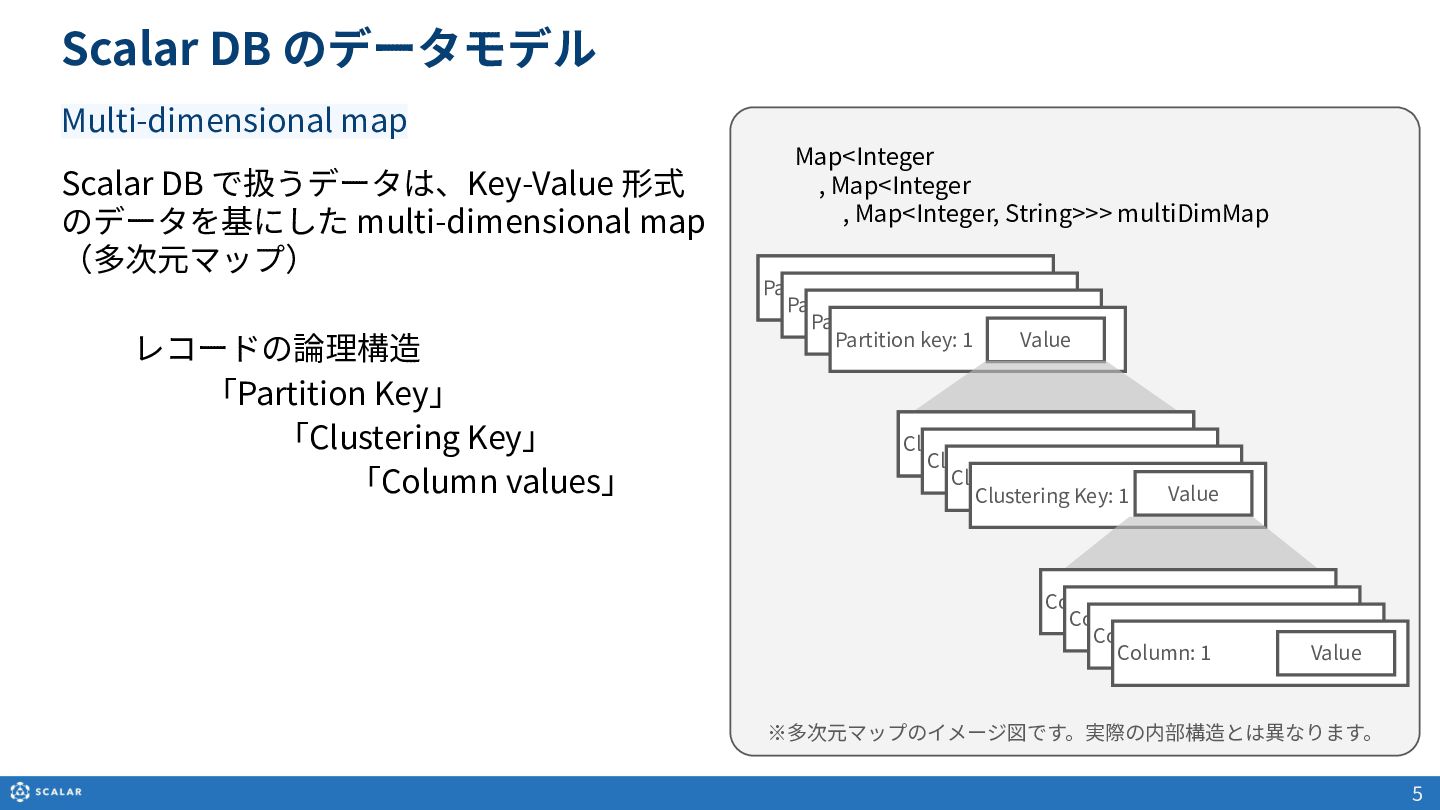
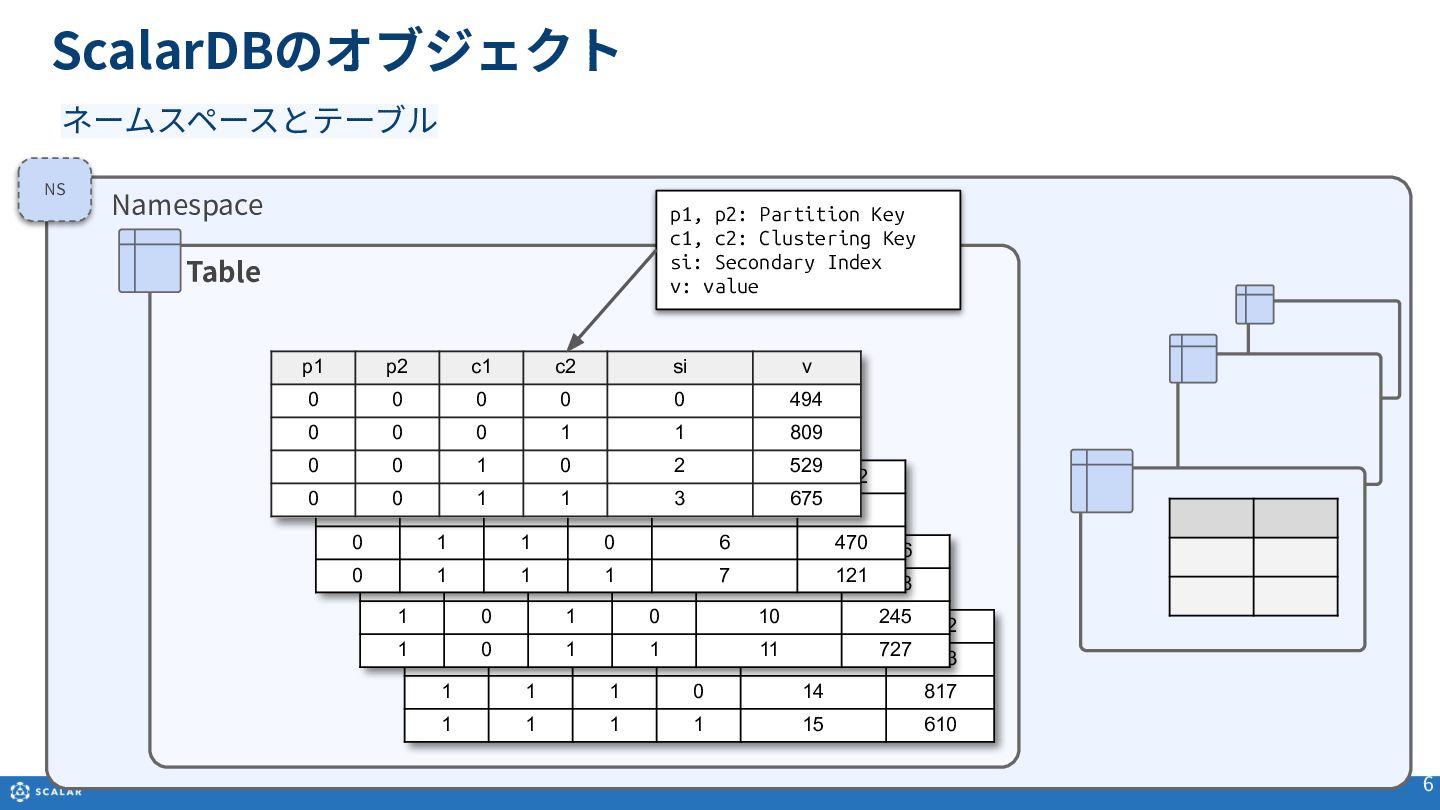
・ScalarDBのデータモデルとオブジェクト
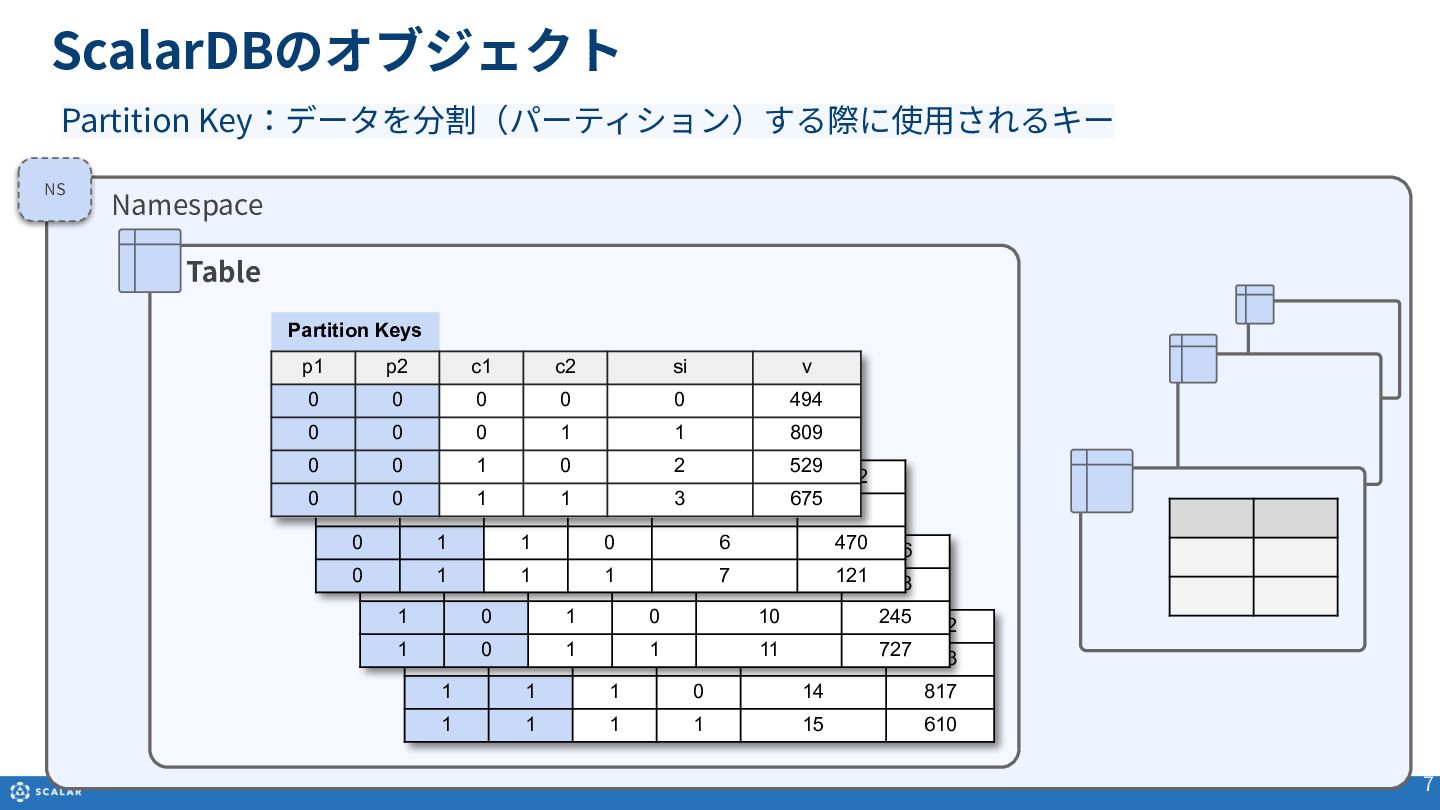
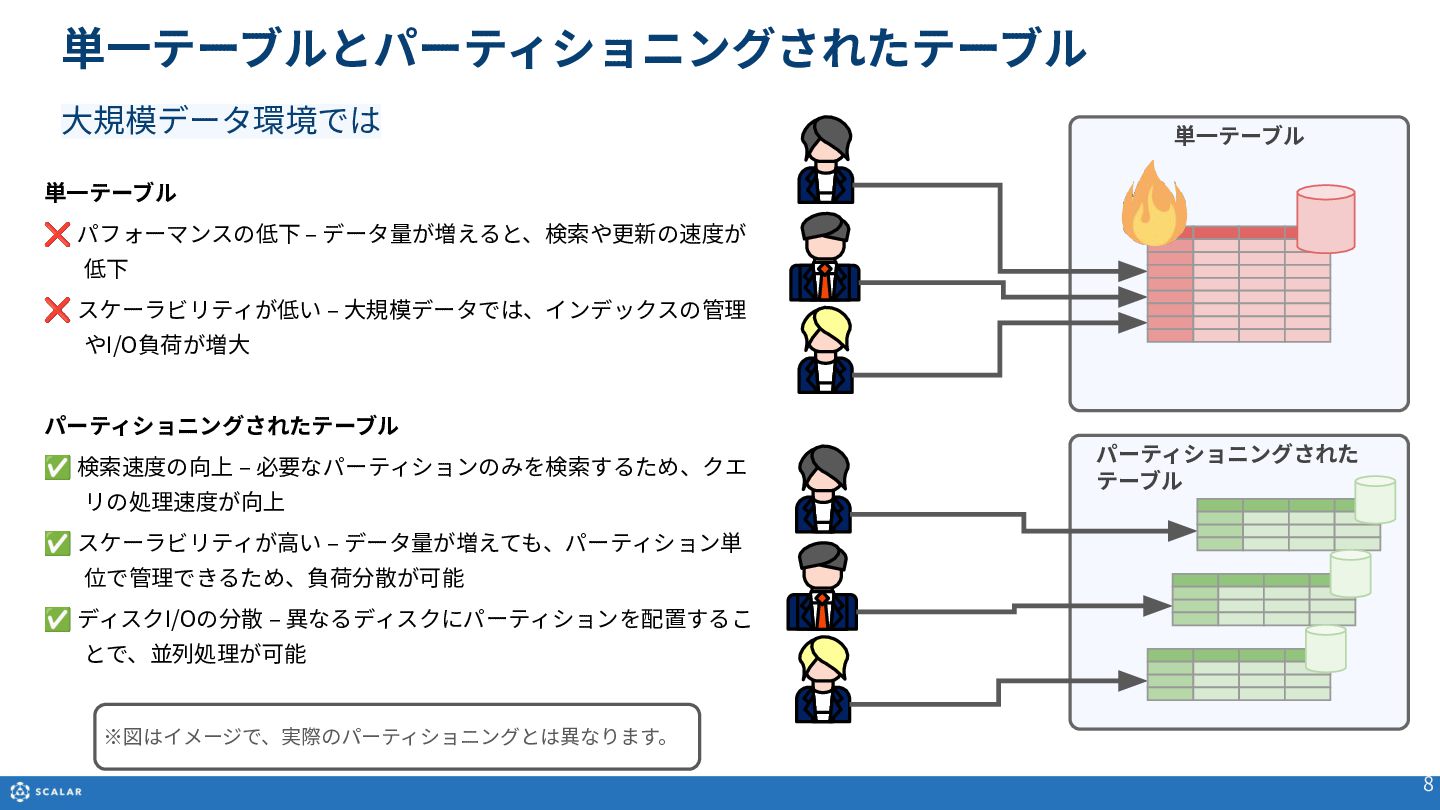
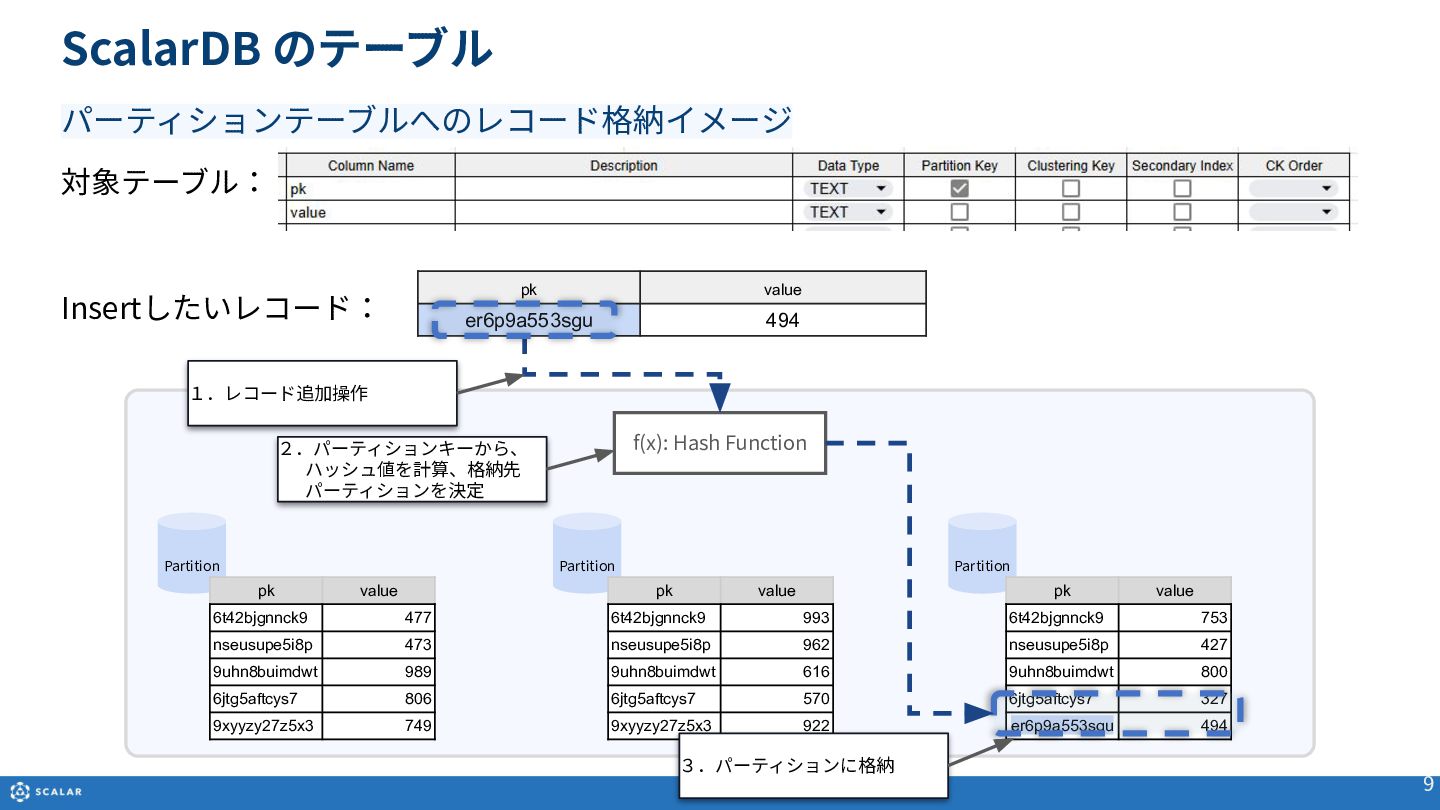
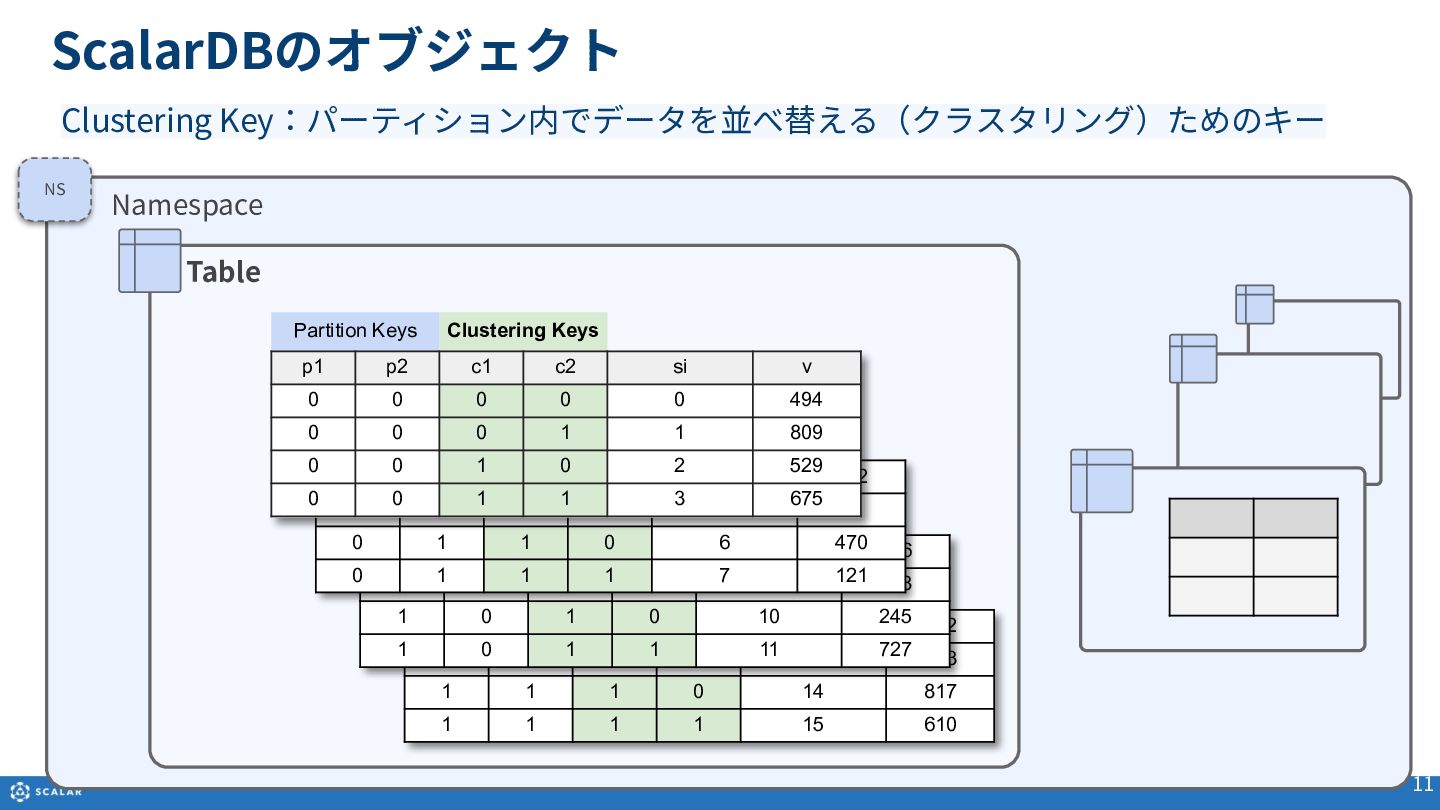
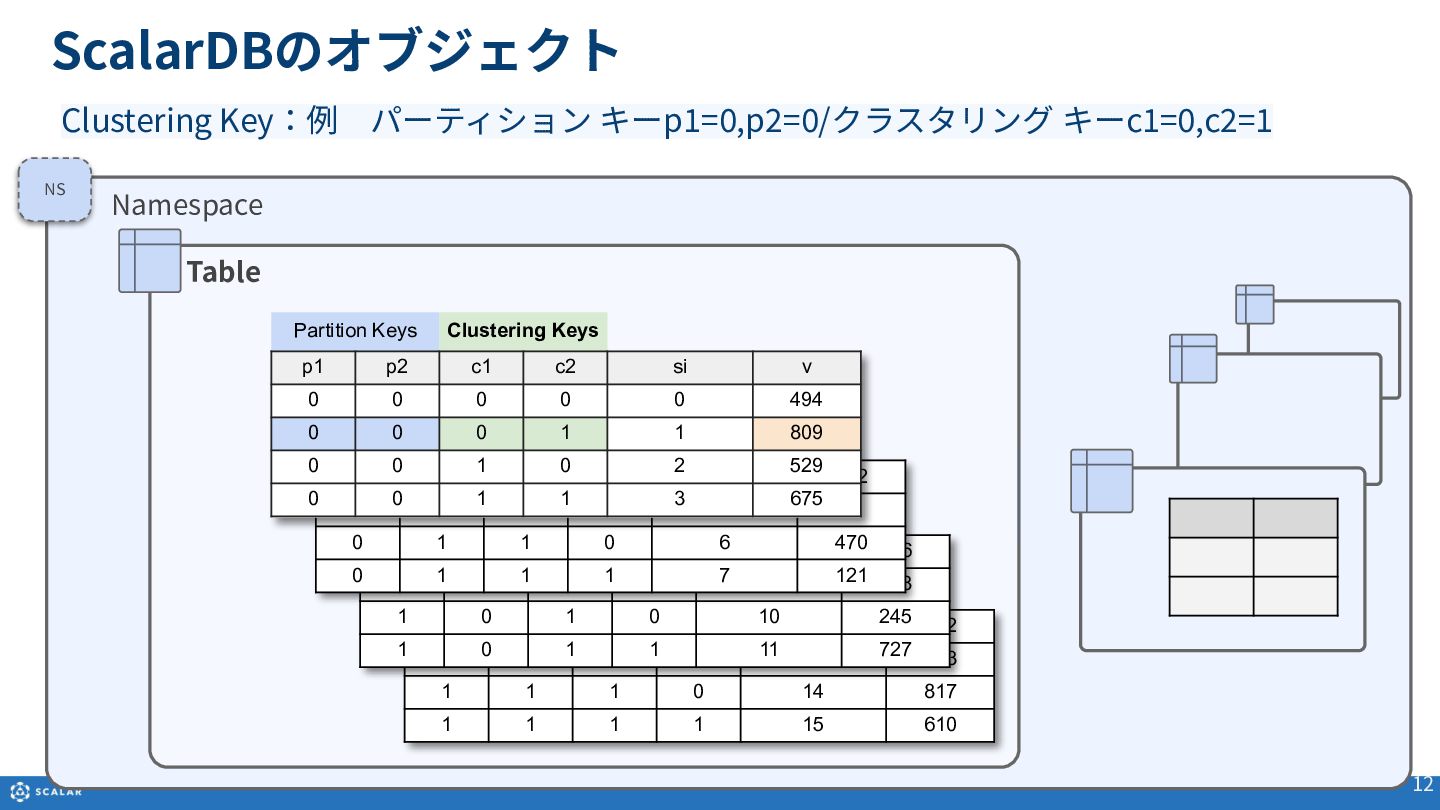
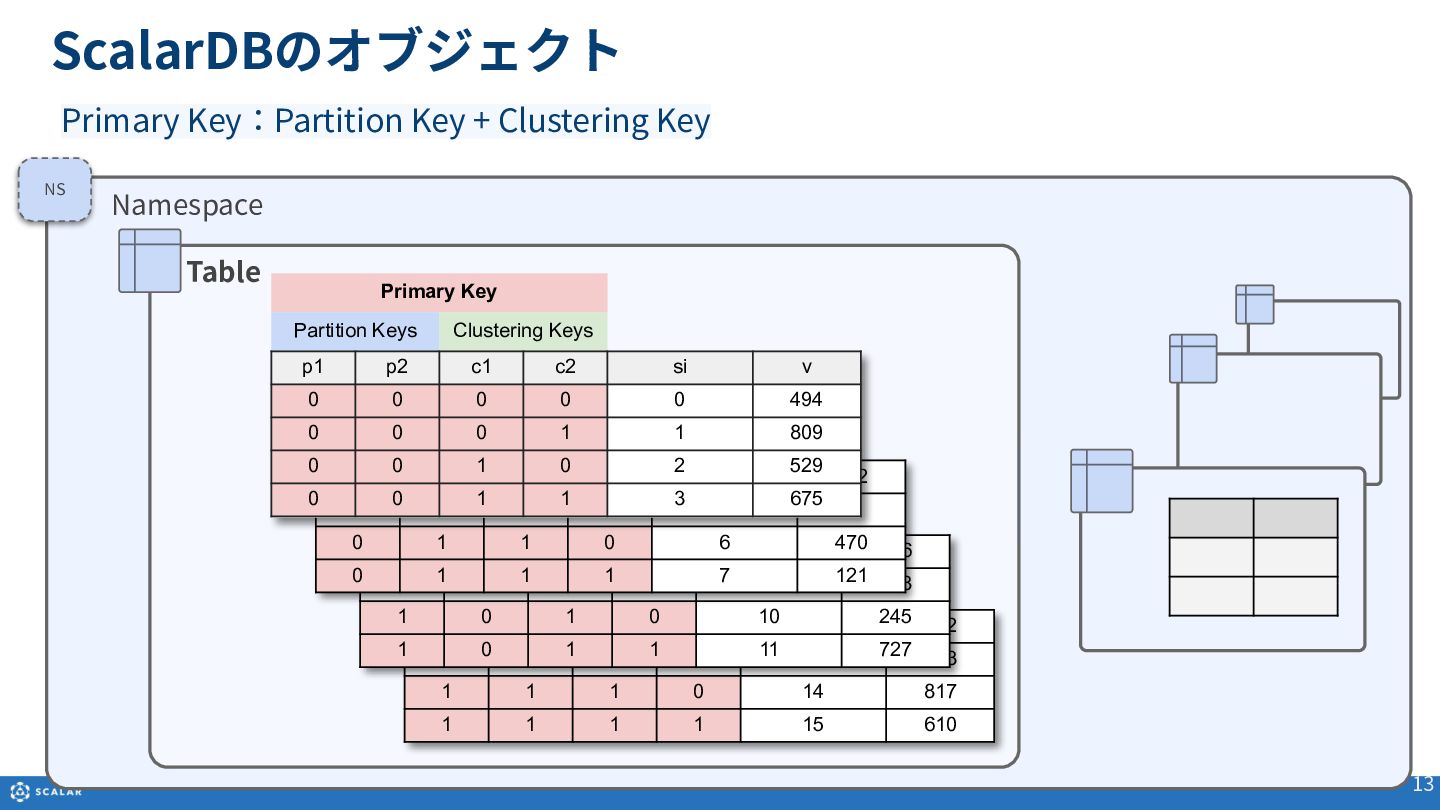
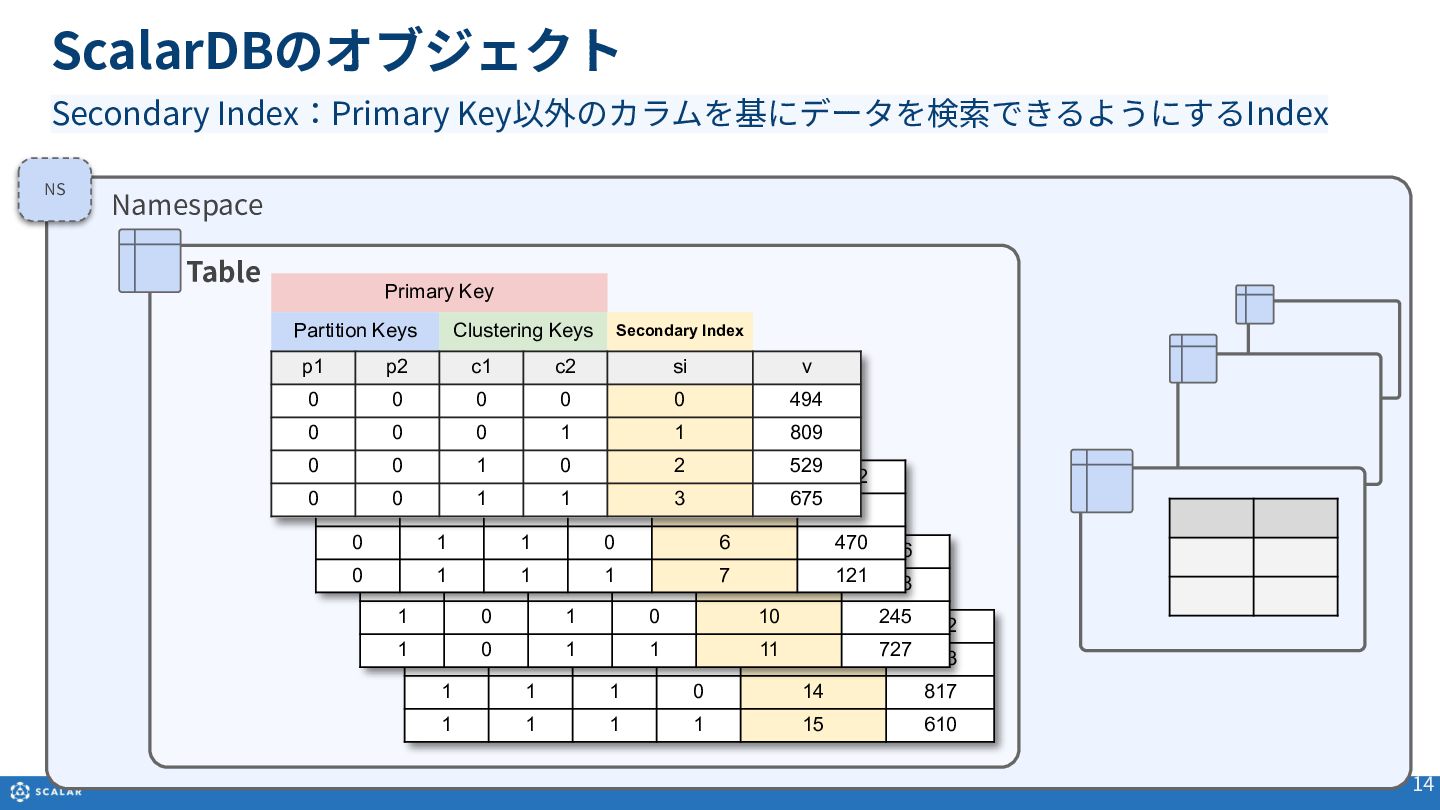
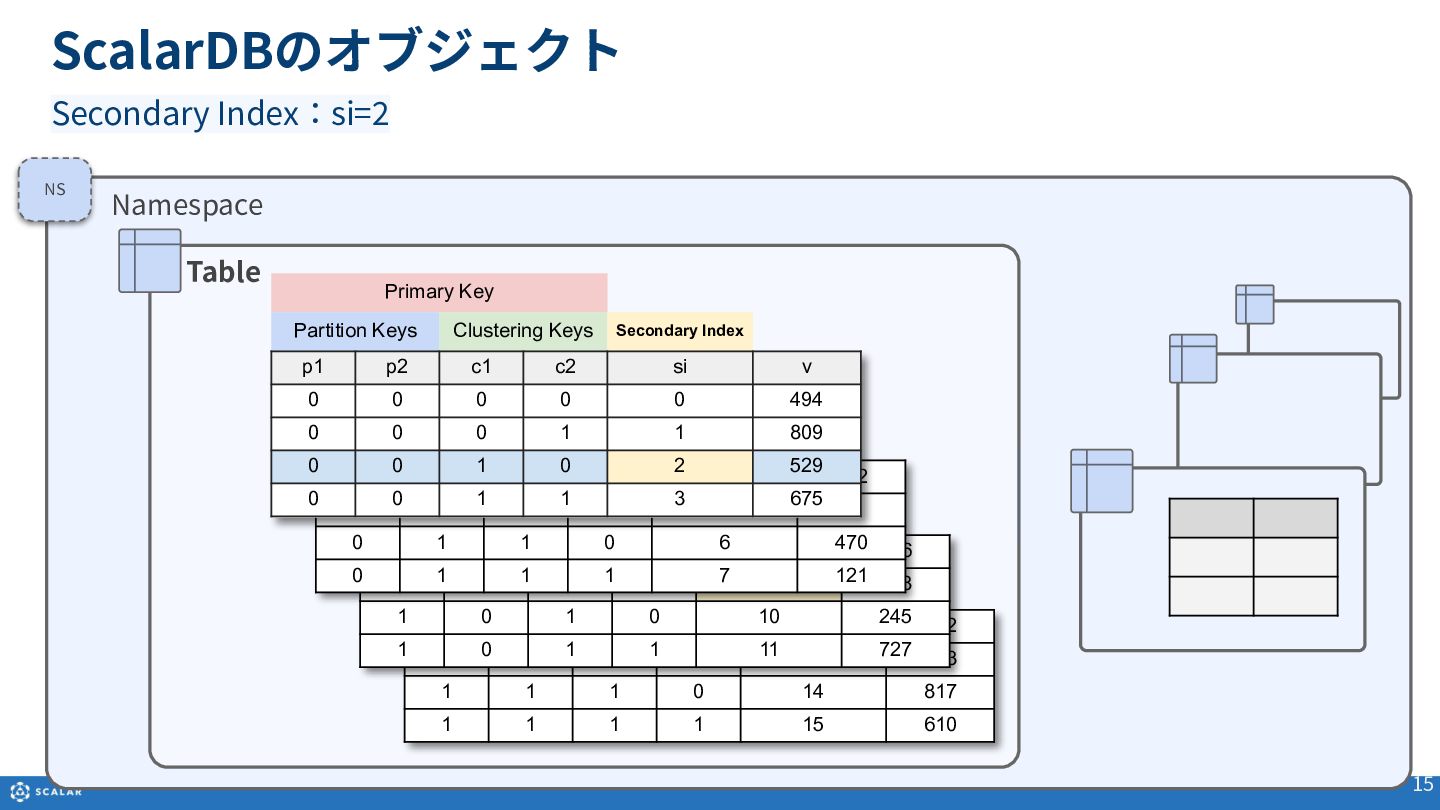
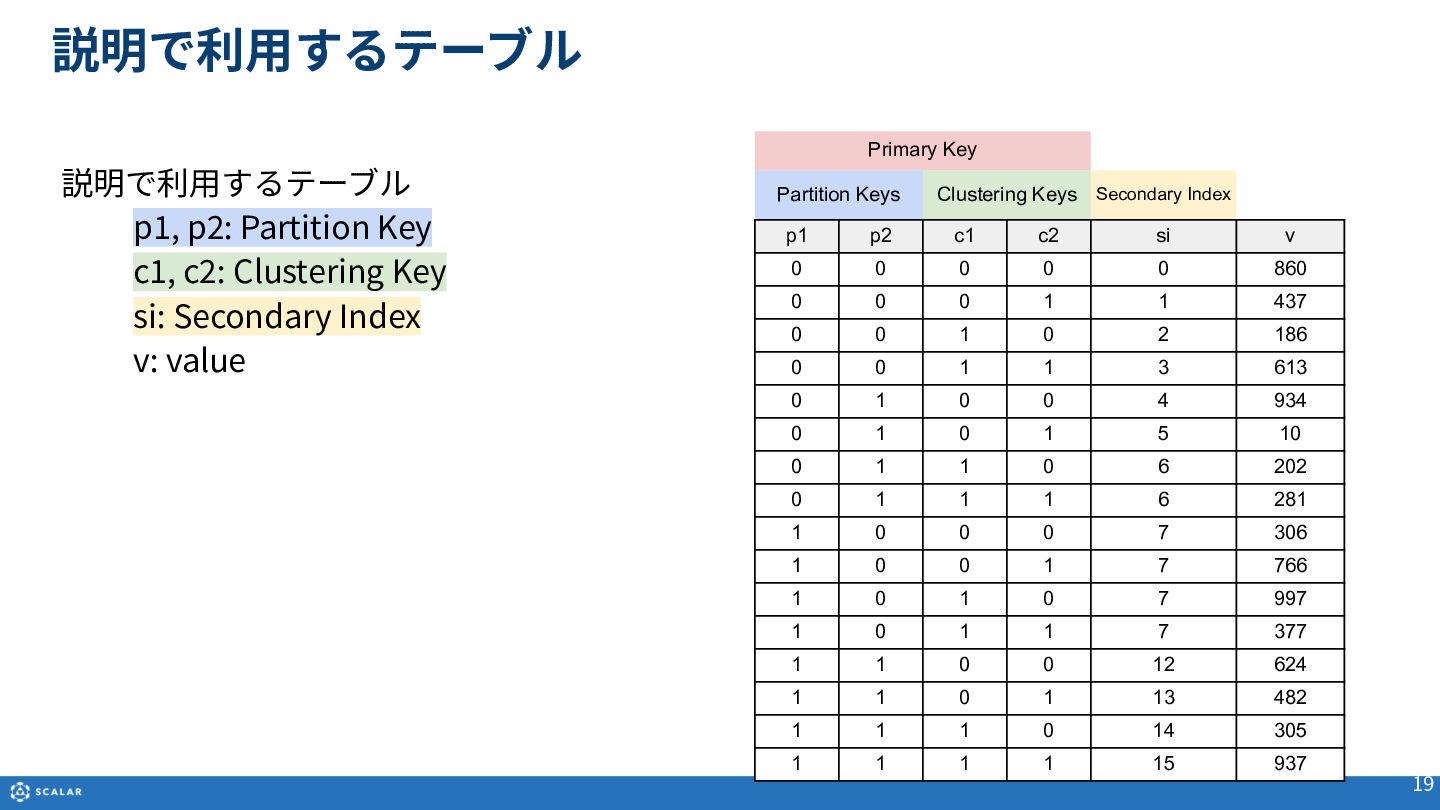
Multi-dimensional map(多次元マップ)を基にしたデータ構造や、Partition Key、Clustering Key、Secondary Indexといった各種オブジェクトの役割と構造について説明します。
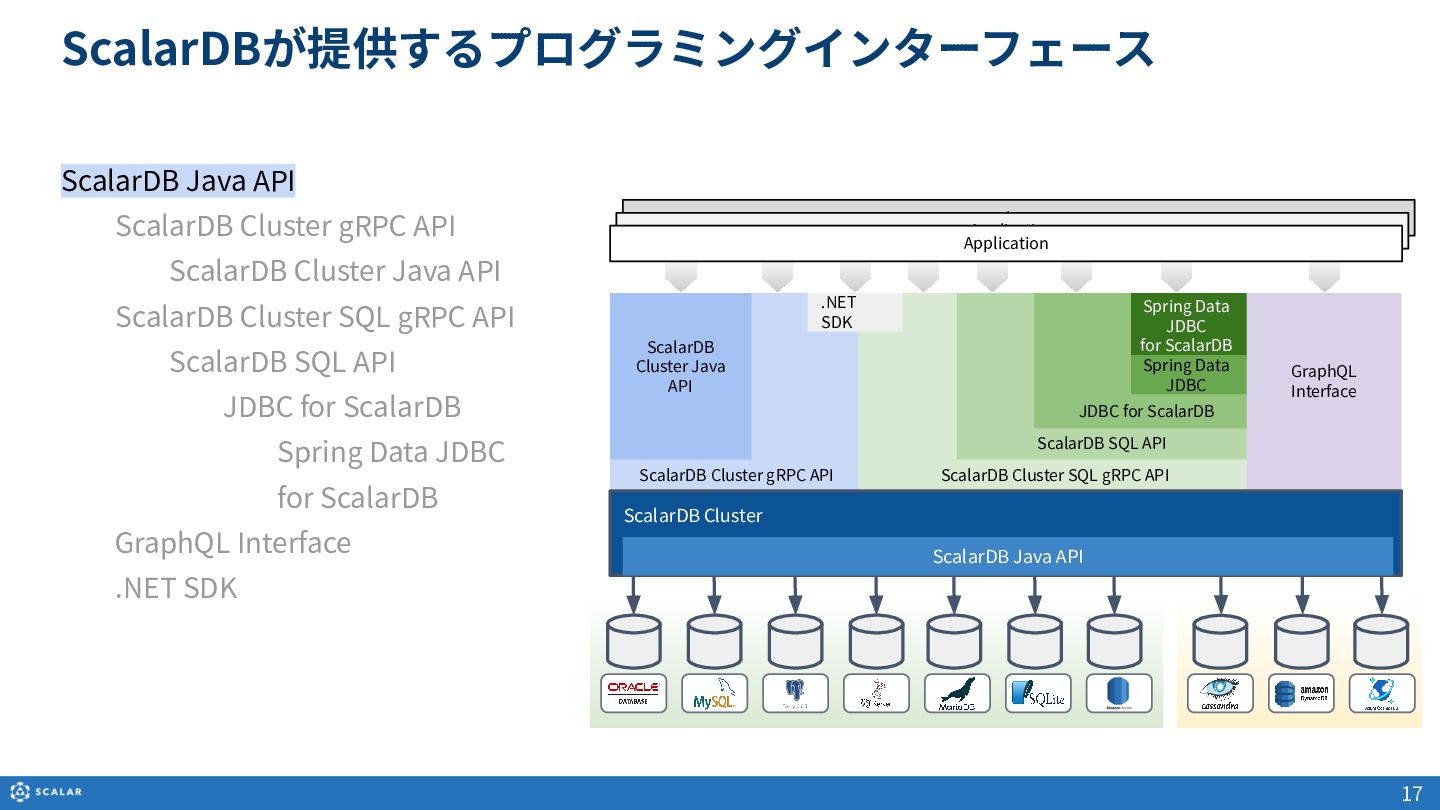
・プログラミングインターフェースとCRUD操作
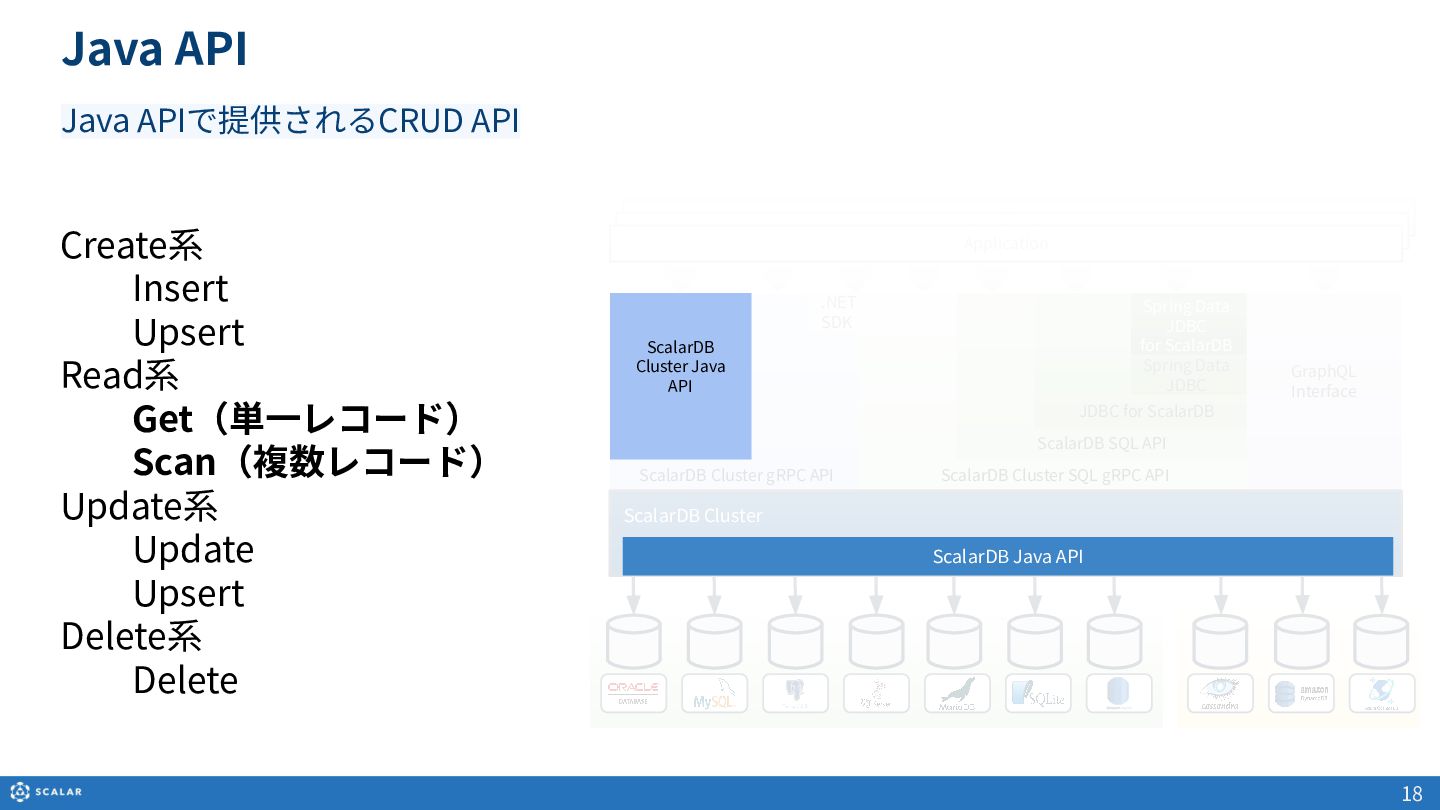
ScalarDBが提供するJava APIを利用した、データの作成(Insert/Upsert)、読み取り(Get/Scan)、更新、削除の基本概要を解説します。
・データへのアクセス方法(GetとScan)
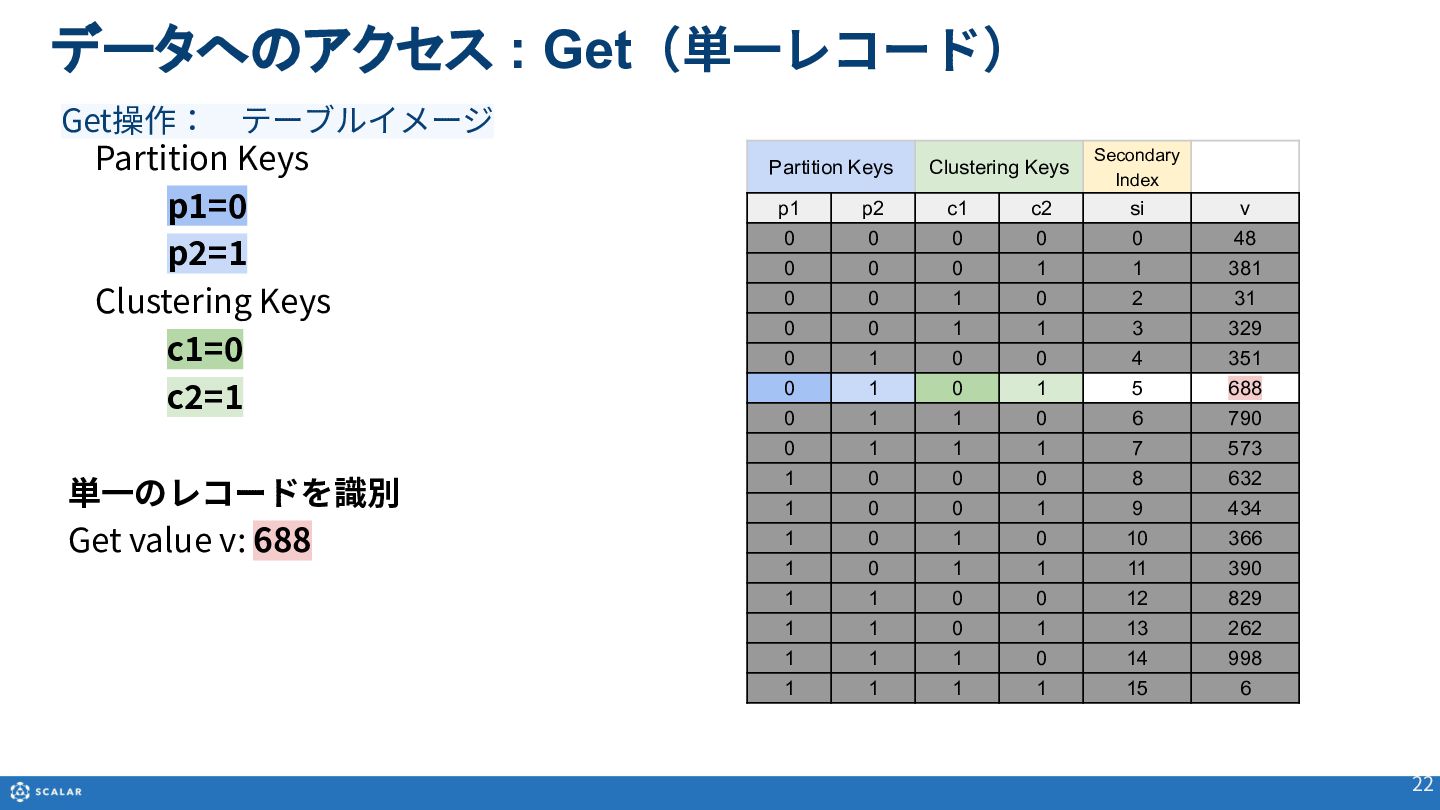
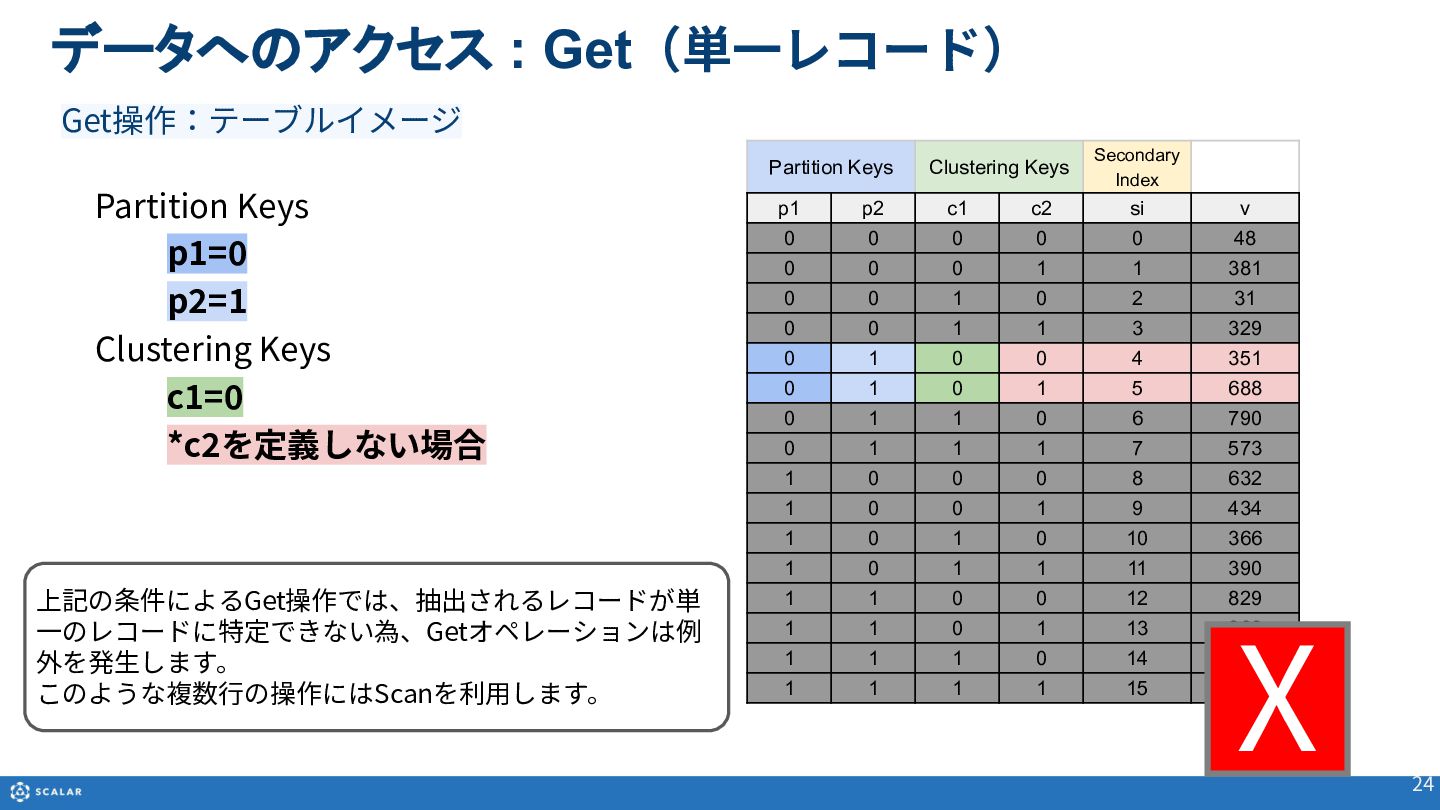
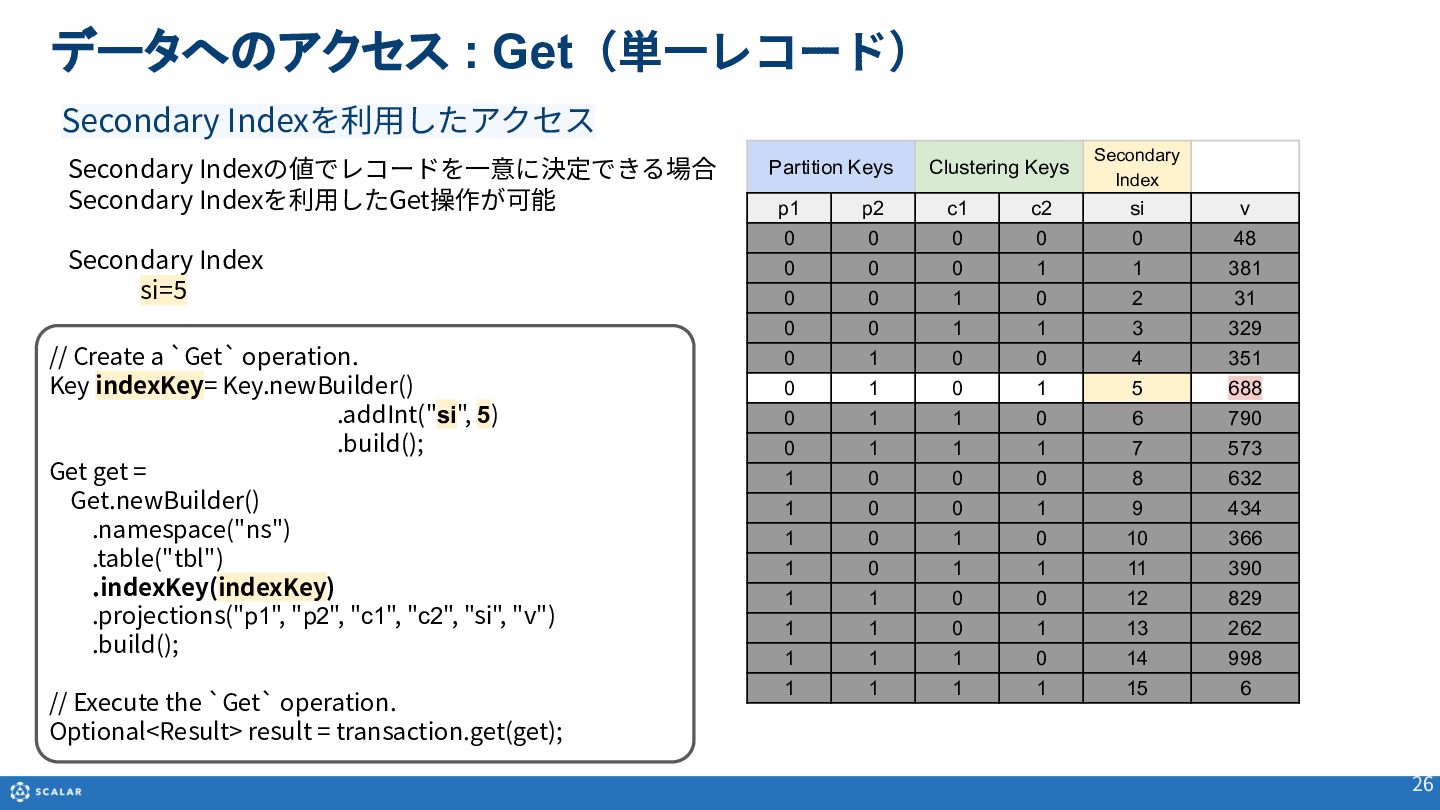
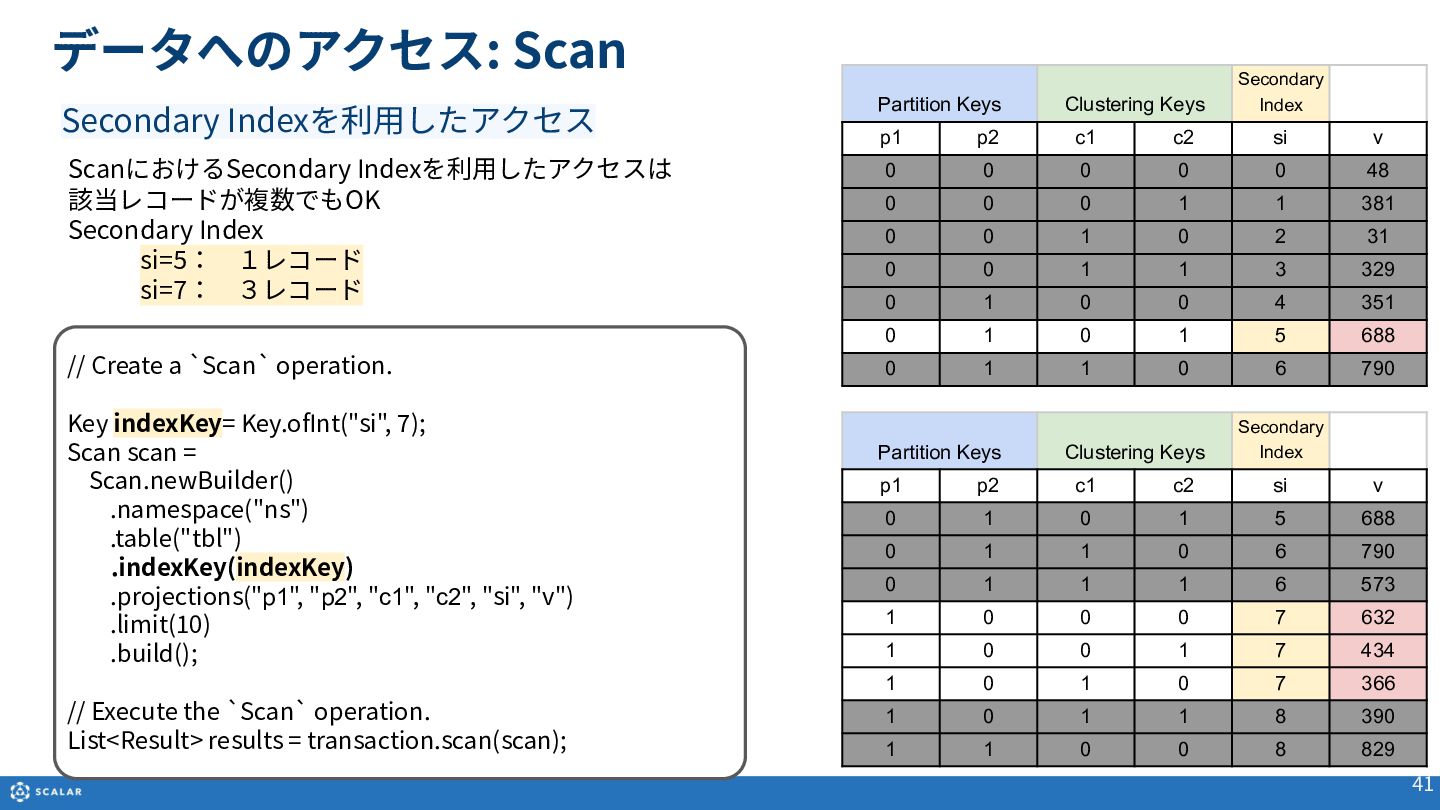
- Get(単一レコード取得):Primary Key(Partition KeyとClustering Keyの組み合わせ)やSecondary Indexを利用した、一意のレコード取得方法とサンプルコードを紹介します。
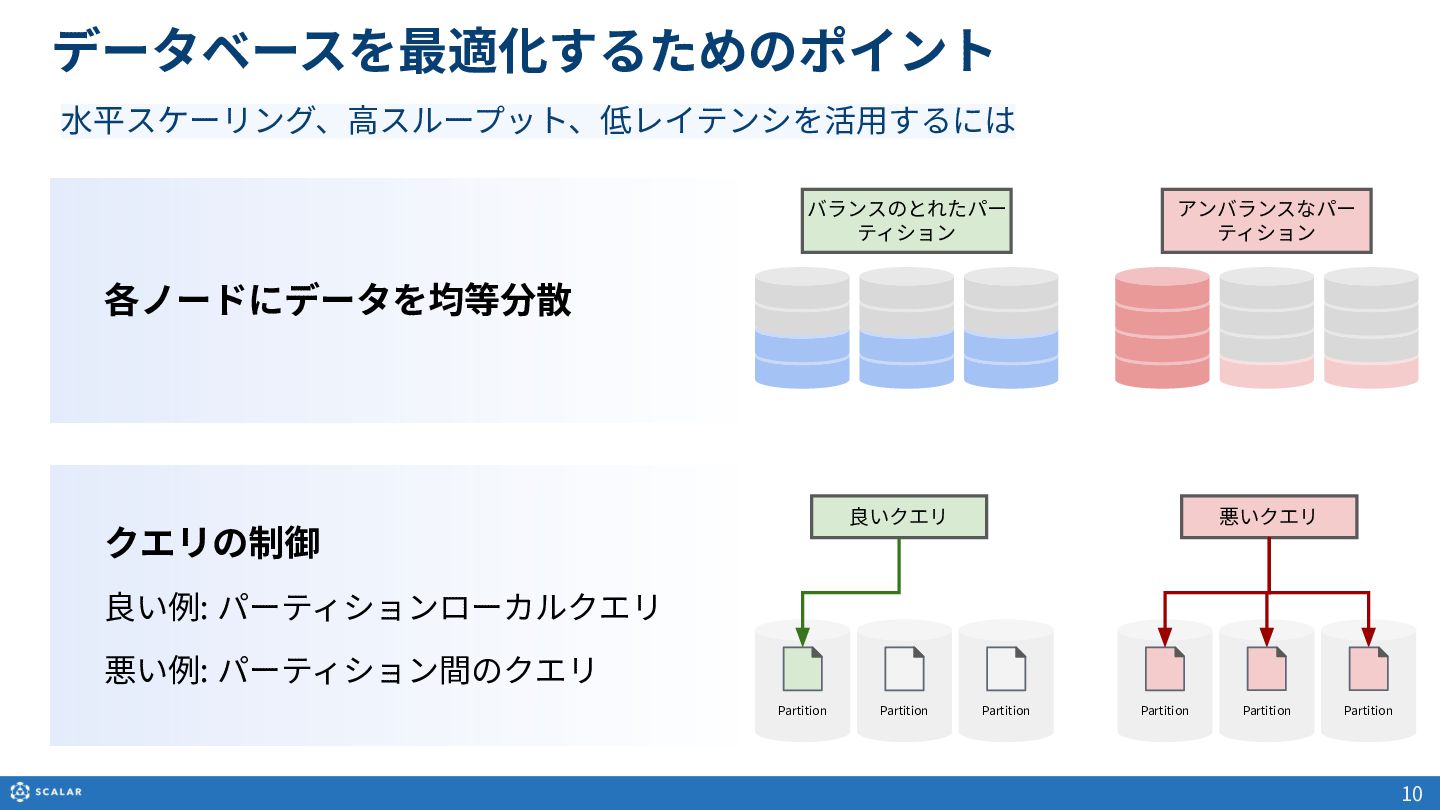
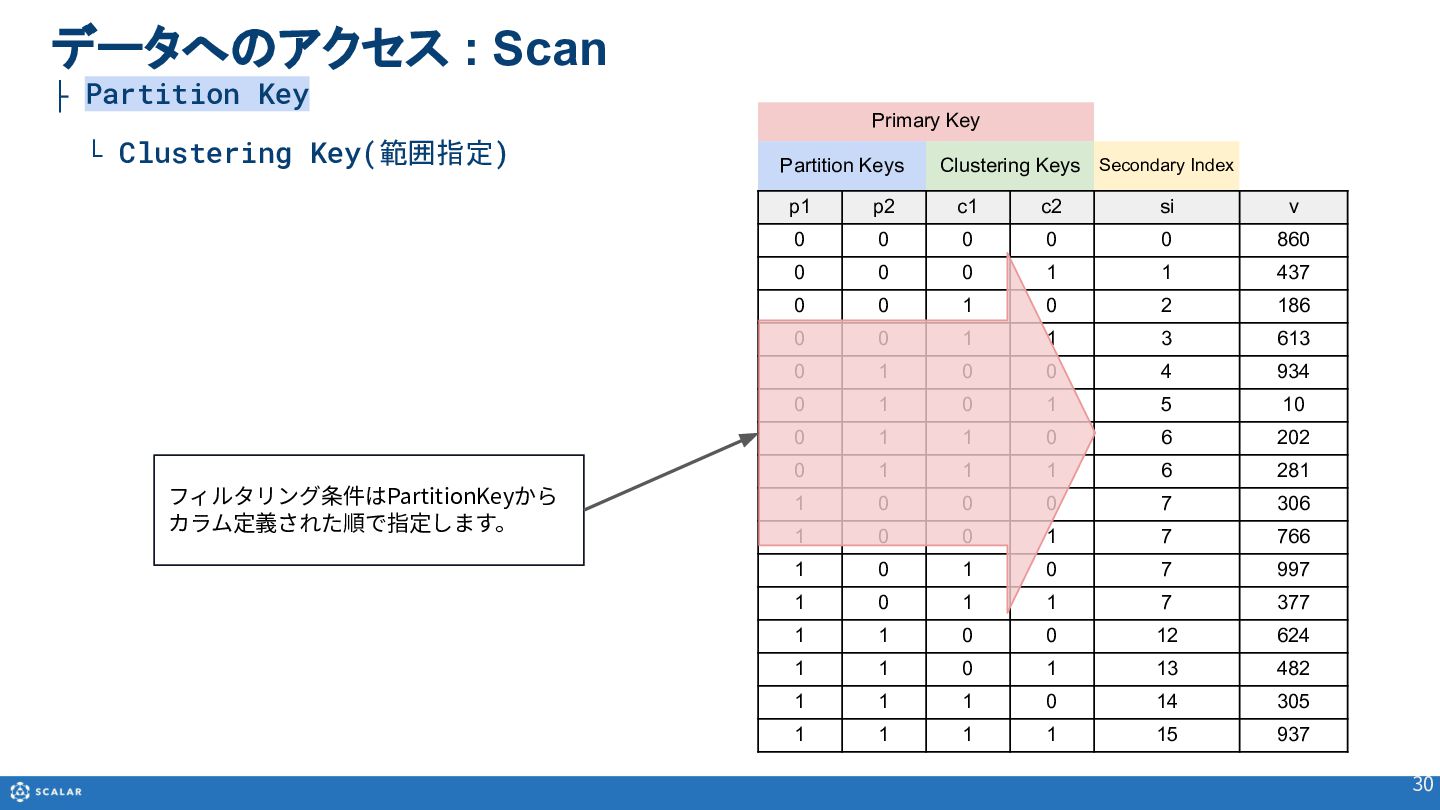
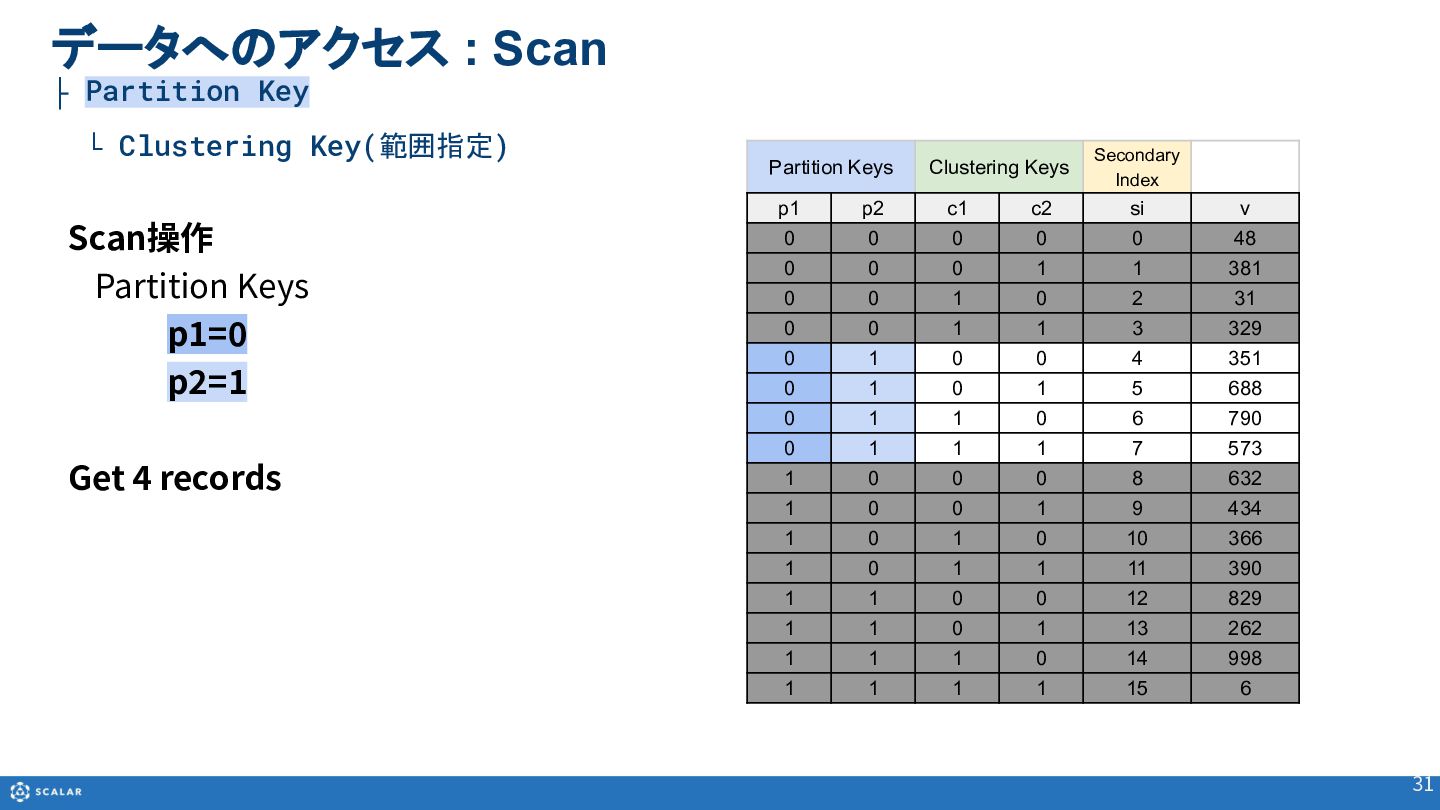
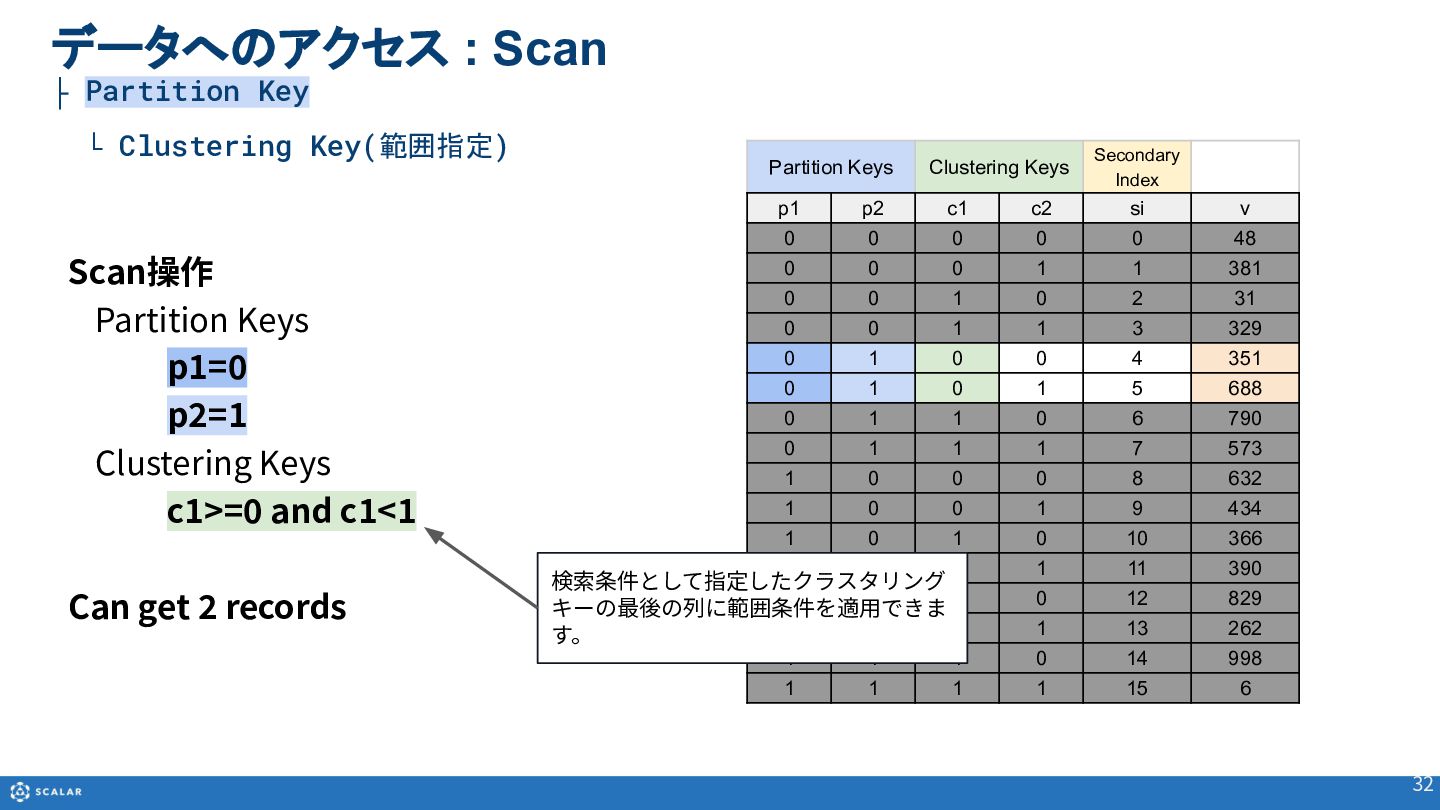
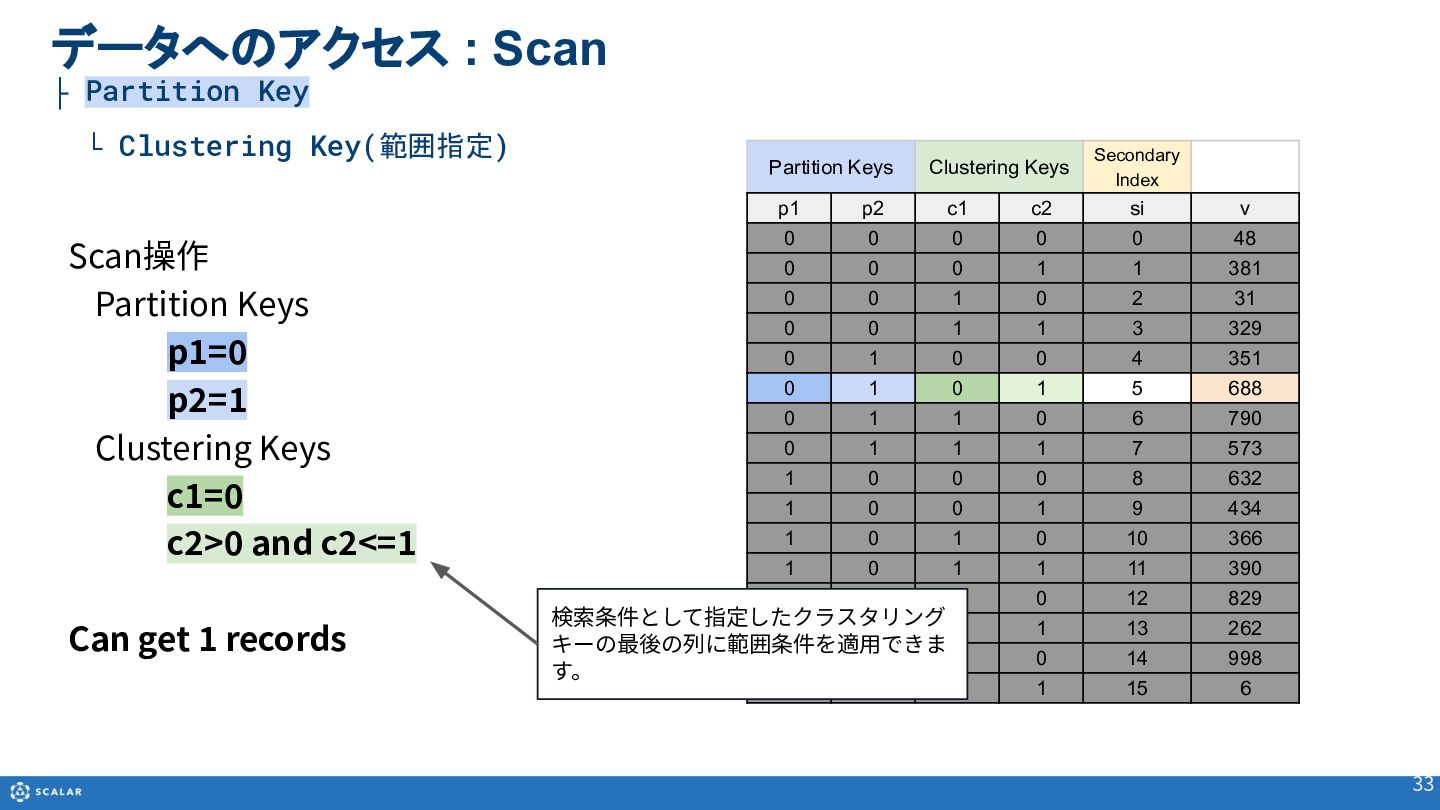
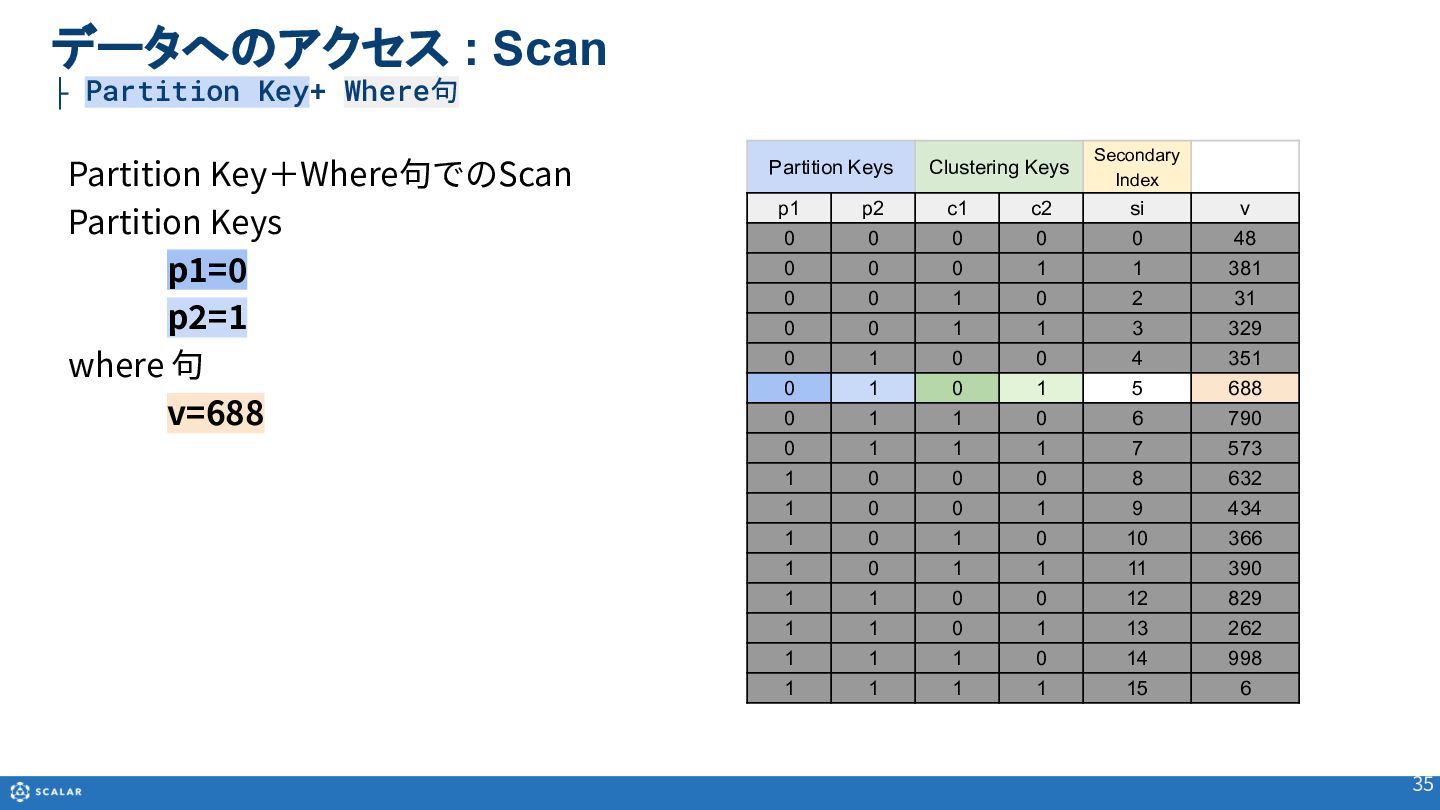
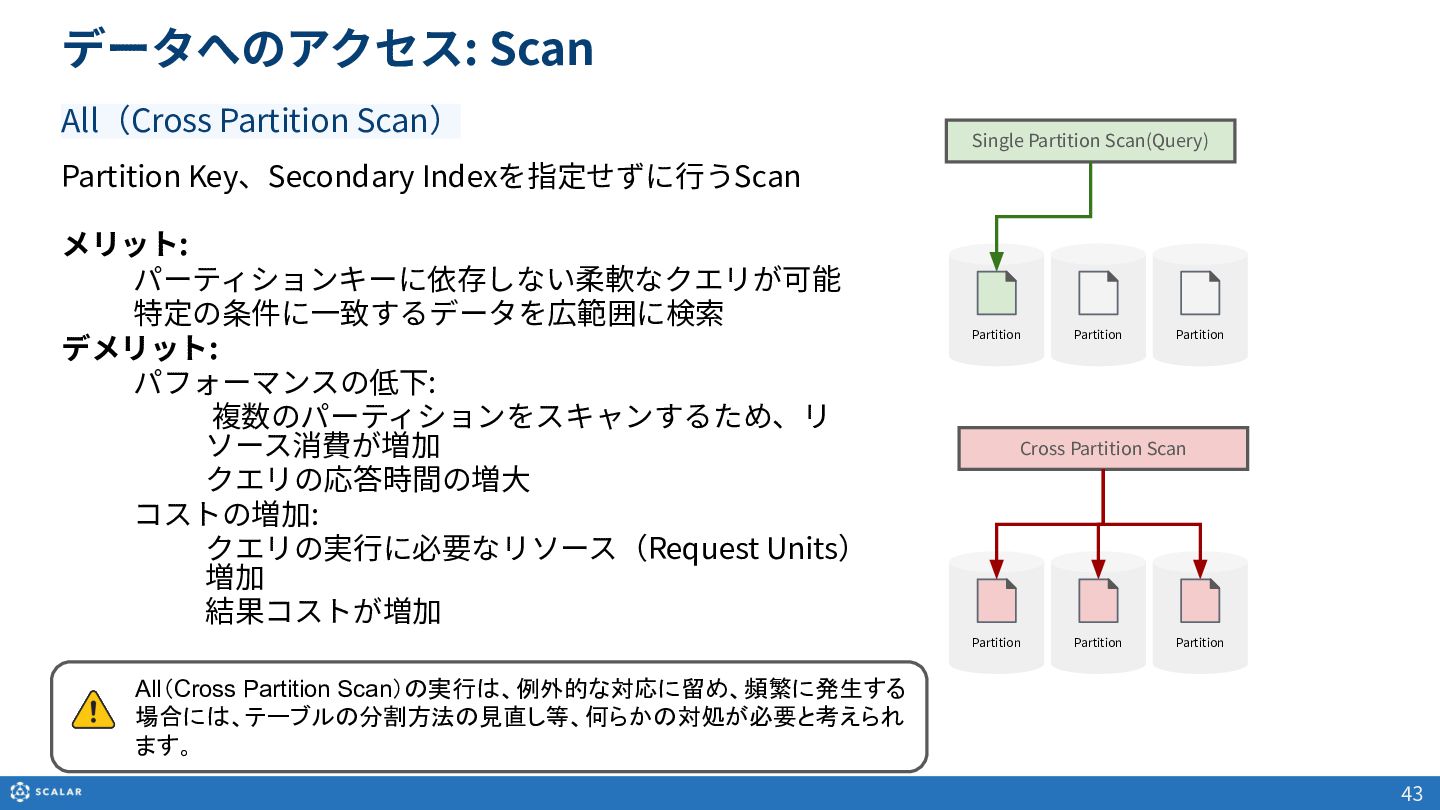
- Scan(複数レコード取得):Partition Keyのみでの検索や、Clustering Keyを使った範囲指定、Secondary Indexによる検索方法を解説します。また、Cross Partition Scan(全件スキャン)の利用方法とパフォーマンス上の注意点についても触れています。
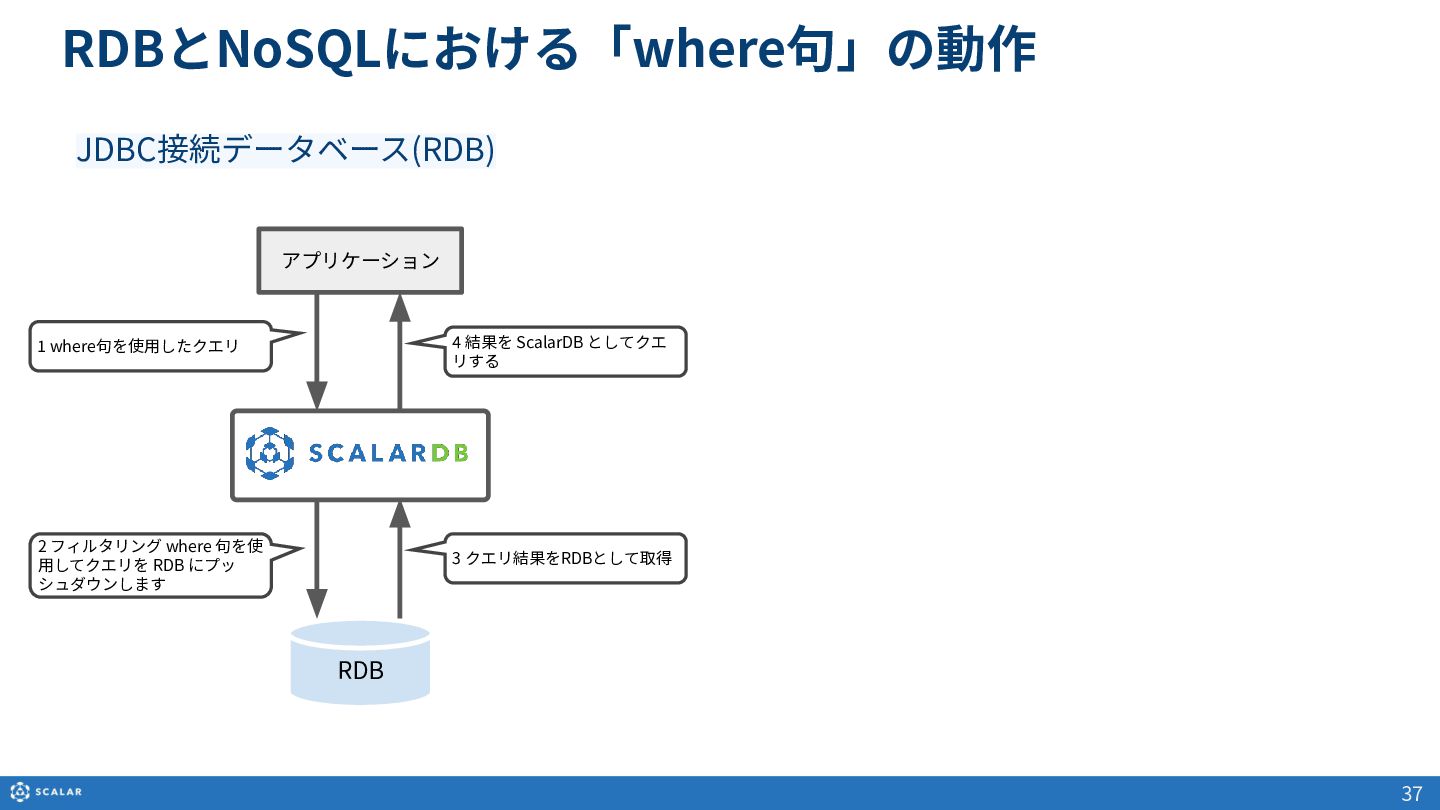
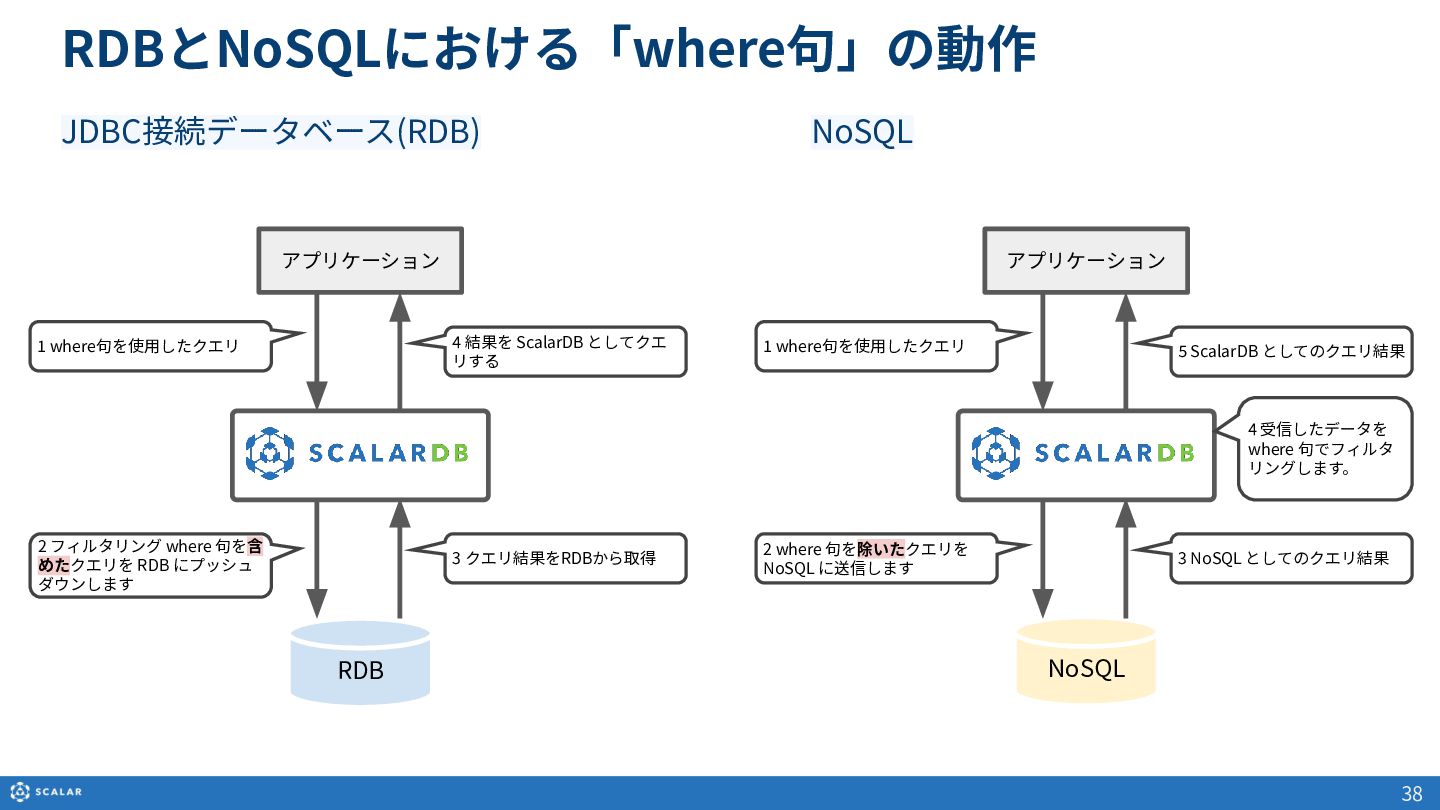
- クエリの制御:RDBとNoSQLにおける「where句」の動作の違いなど、バックエンドデータベースの特性を考慮したフィルタリングの仕組みを解説します。
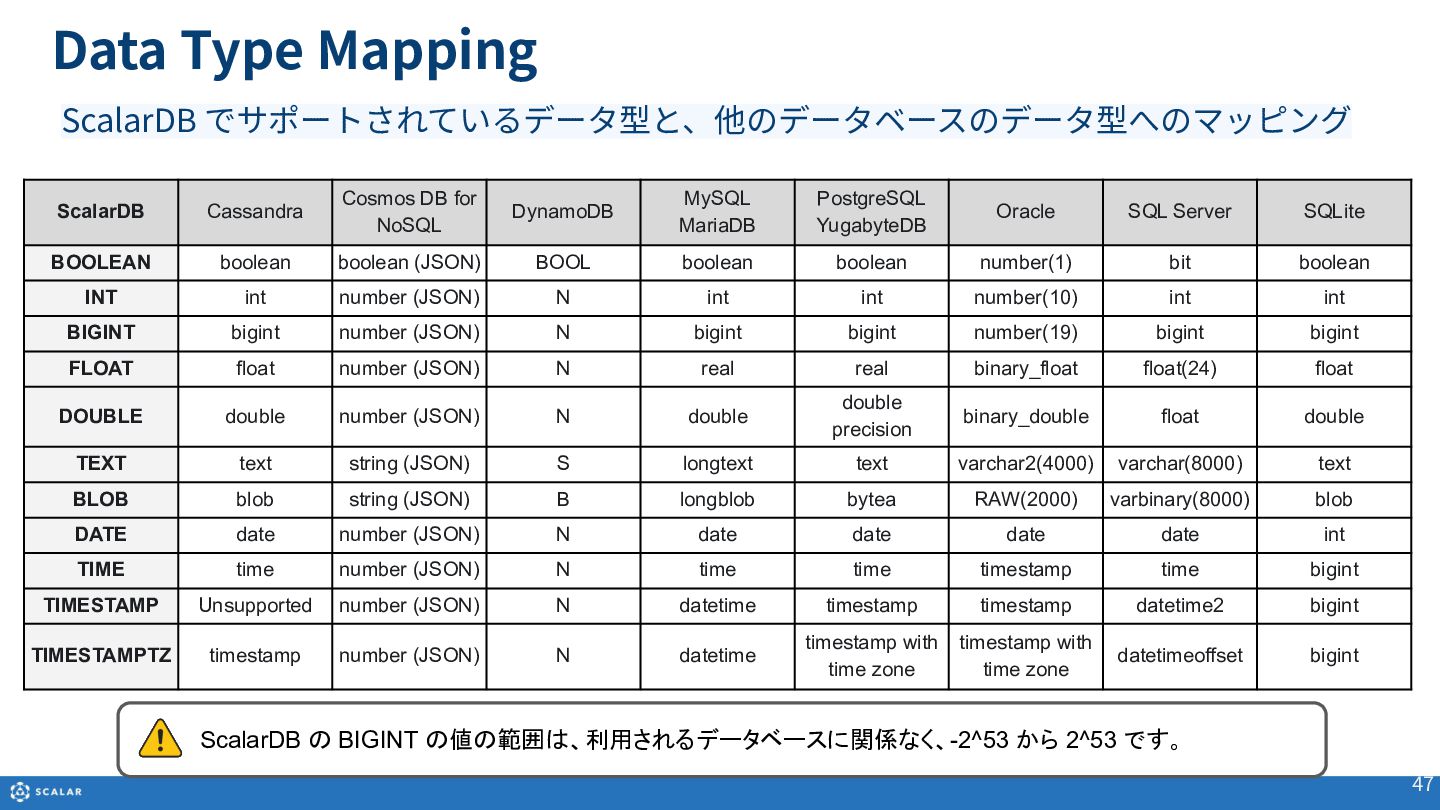
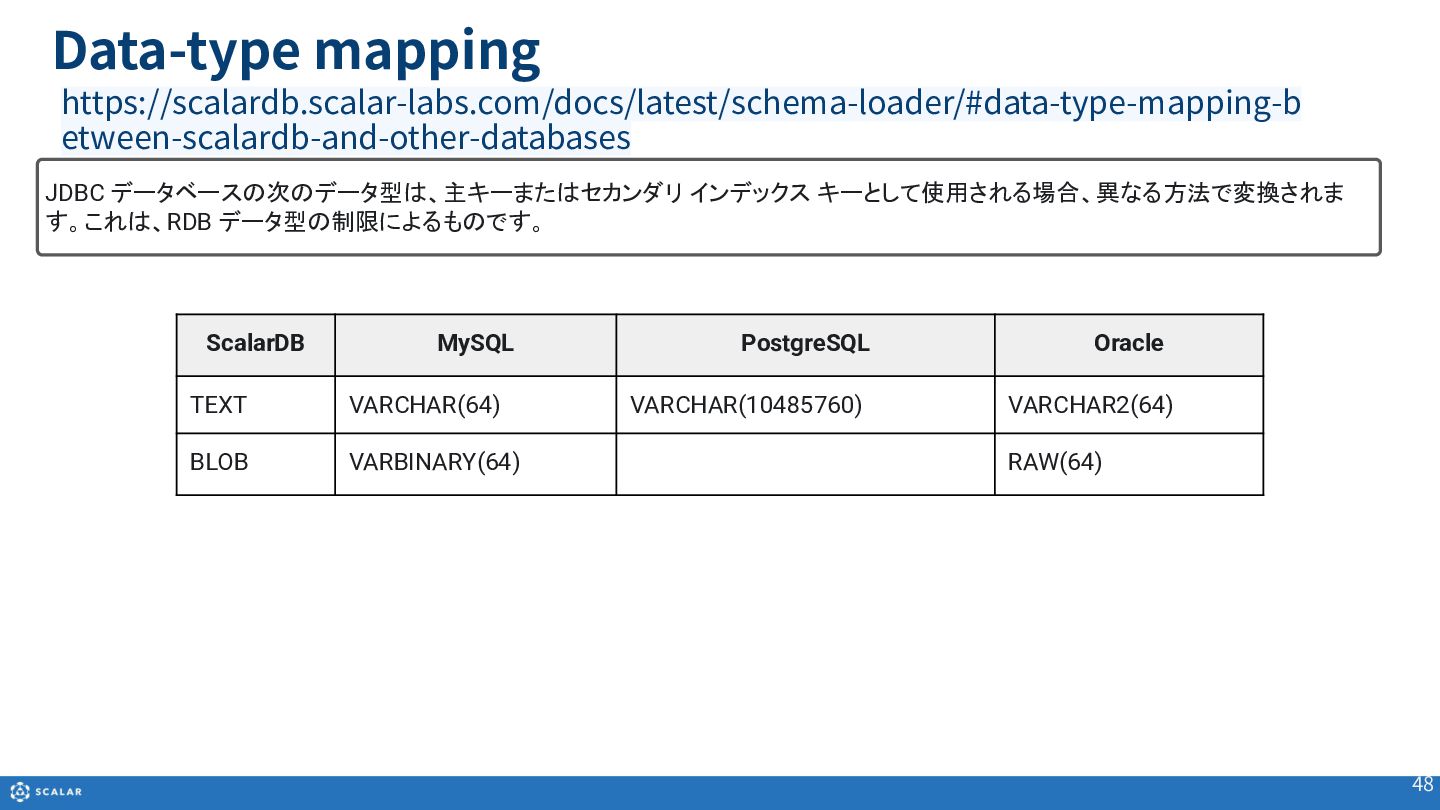
・データ型のマッピング
ScalarDBでサポートされるデータ型(INT、TEXT、BLOB、TIMESTAMPなど)と、Cassandra、MySQL、PostgreSQL、Oracleなど、基盤となる他のデータベースのデータ型とのマッピングルールについて紹介します。
ScalarDBを利用したアプリケーション開発を始める方や、スケーラビリティを高めるための適切なデータ分割・クエリ設計を学びたいエンジニアの方におすすめの資料です。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}