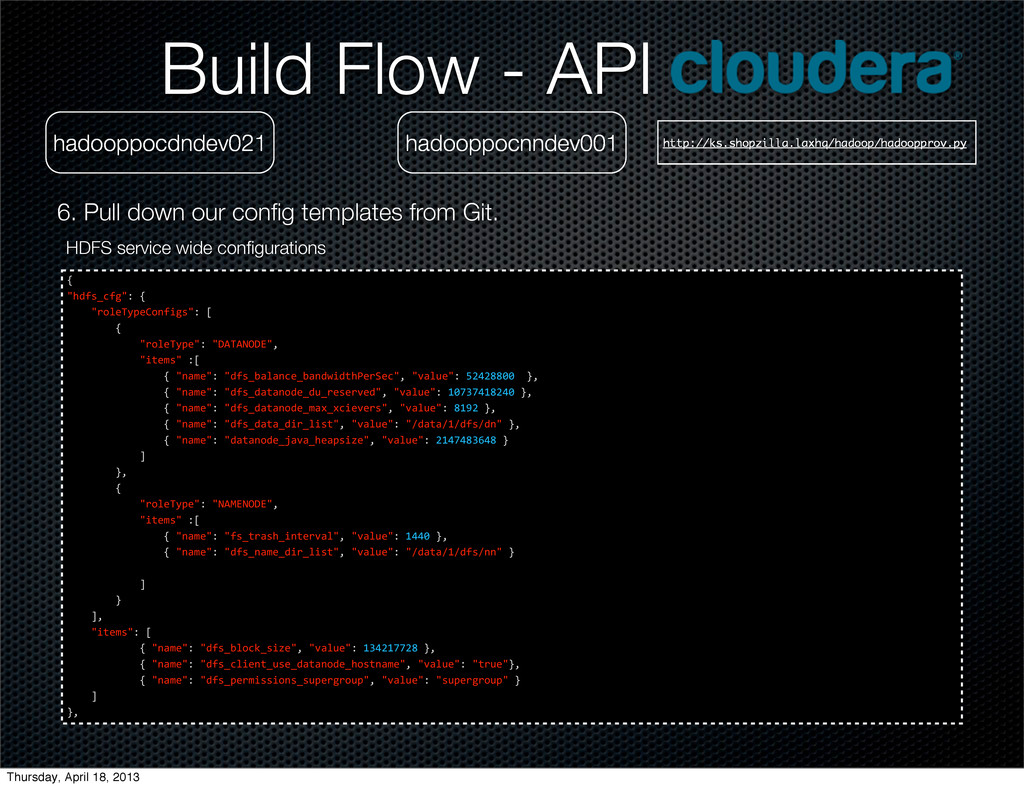
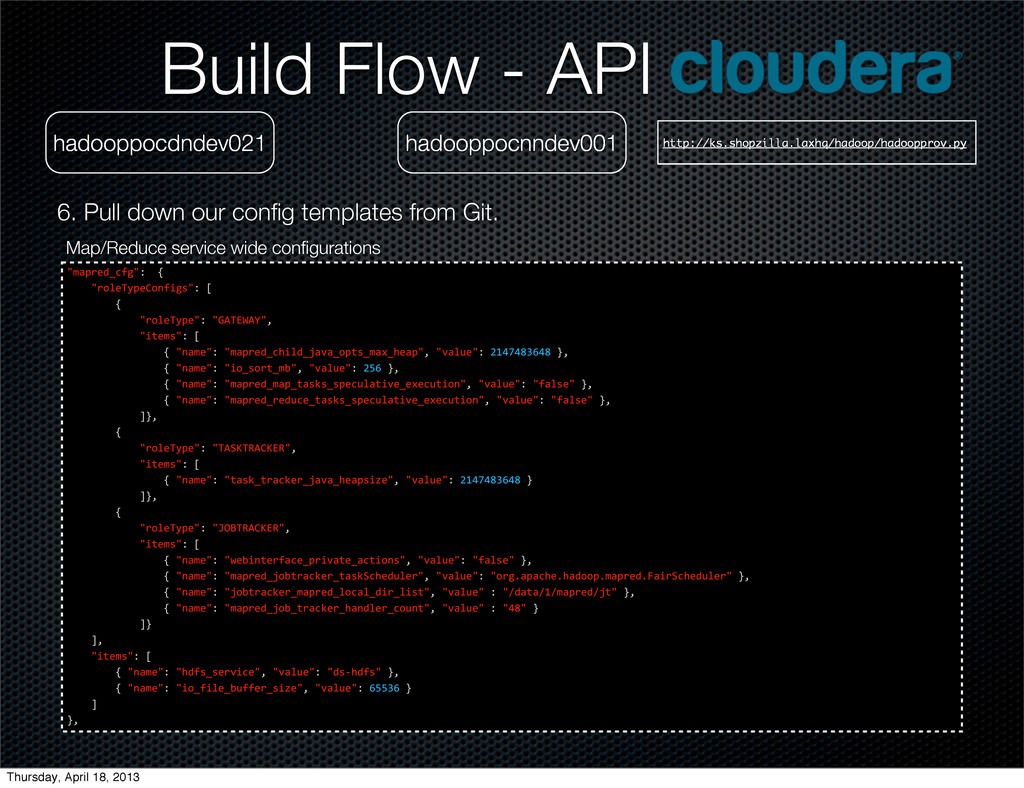
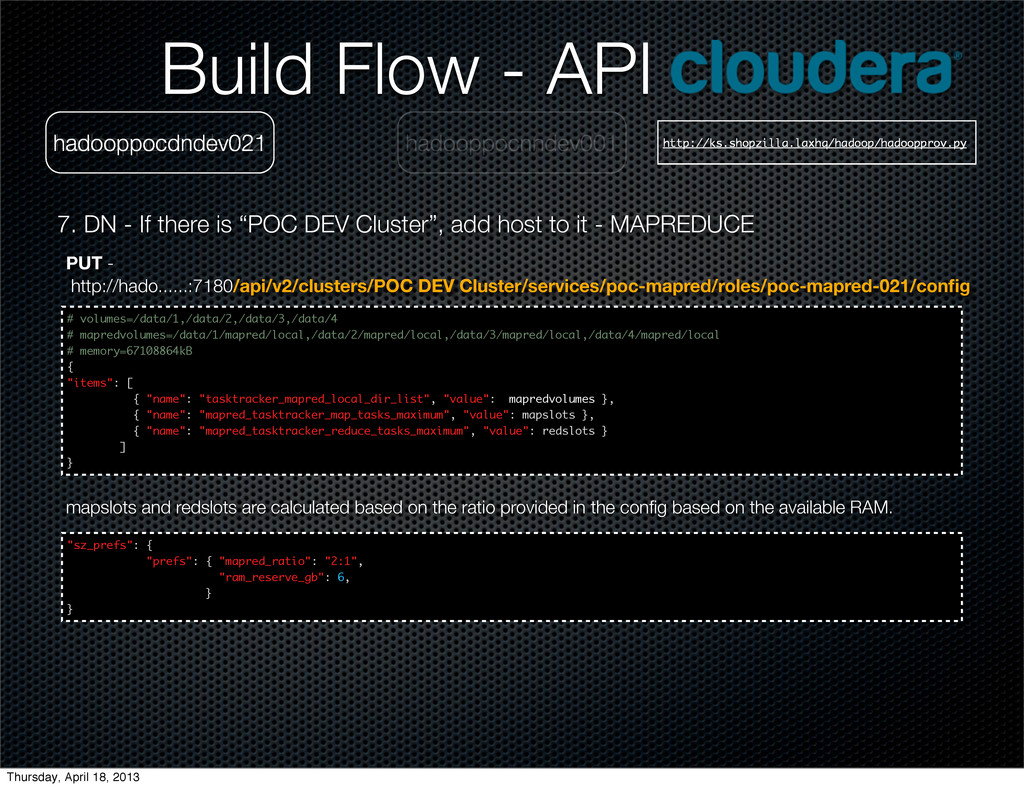
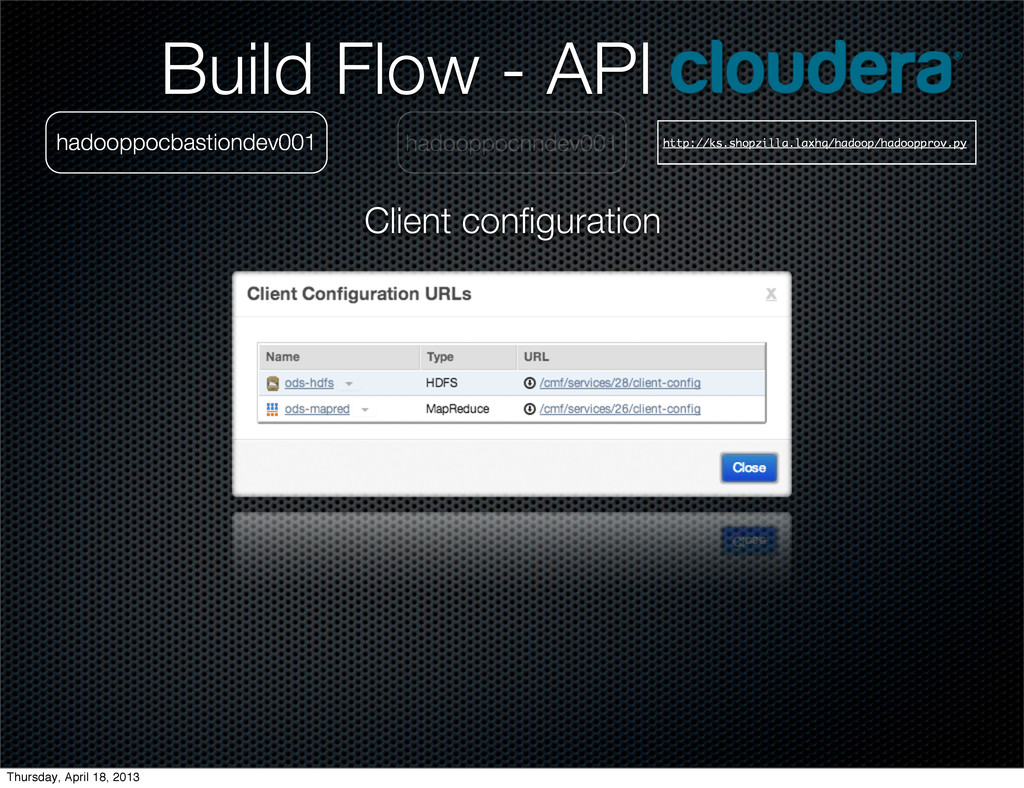
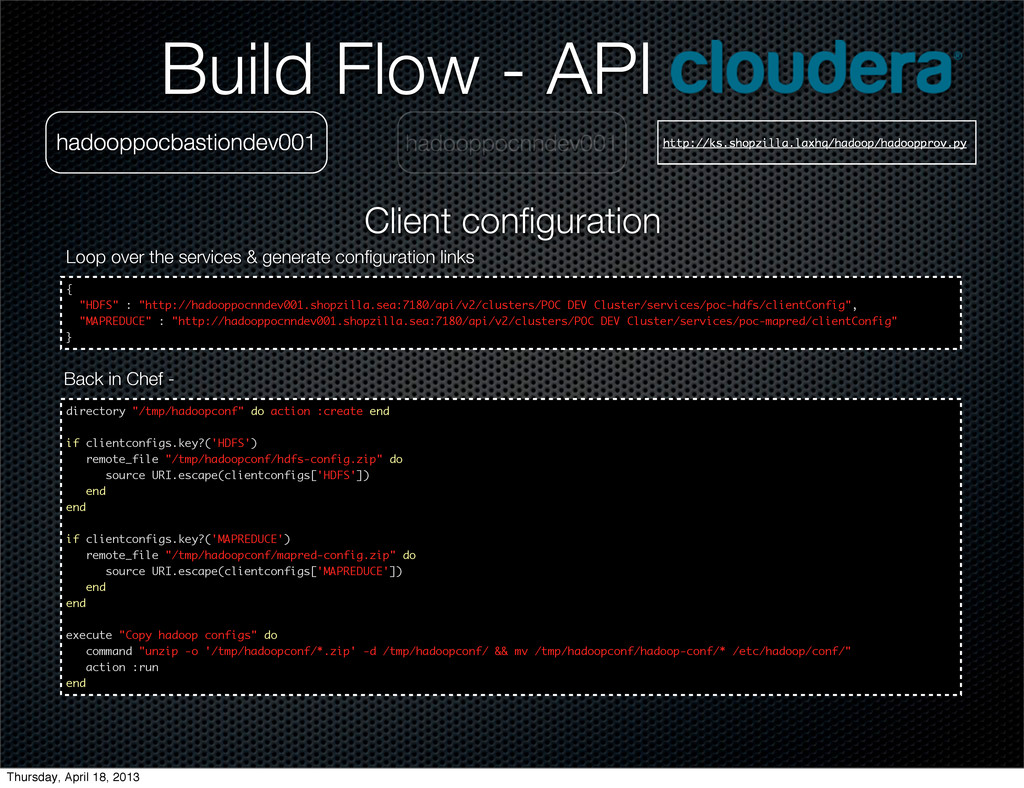
Git. hadooppocdndev021 ">?2,/$'(%)"*++! ++++",-./012/3-4%5)&"*+6 ++++++++! ++++++++++++",-./012/"*+"X80;Y8Z"< ++++++++++++"5=/>&"*+6 ++++++++++++++++!+"4?>/"*+">?2,/$'(#5.$'R?D?'-2=&'>?O'#/?2"<+"D?.E/"*+GLHMHINTHI+K< ++++++++++++++++!+"4?>/"*+"5-'&-,='>@"<+"D?.E/"*+GFT+K< ++++++++++++++++!+"4?>/"*+">?2,/$'>?2'=?&W&'&2/(E.?=5D/'/O/(E=5-4"<+"D?.E/"*+"%?.&/"+K< ++++++++++++++++!+"4?>/"*+">?2,/$',/$E(/'=?&W&'&2/(E.?=5D/'/O/(E=5-4"<+"D?.E/"*+"%?.&/"+K< ++++++++++++UK< ++++++++! ++++++++++++",-./012/"*+"08C[0\83[;\"< ++++++++++++"5=/>&"*+6 ++++++++++++++++!+"4?>/"*+"=?&W'=,?(W/,'R?D?'#/?2&5S/"<+"D?.E/"*+GLHMHINTHI+K ++++++++++++UK< ++++++++! ++++++++++++",-./012/"*+"]:^0\83[;\"< ++++++++++++"5=/>&"*+6 ++++++++++++++++!+"4?>/"*+"A/@54=/,%?(/'2,5D?=/'?(=5-4&"<+"D?.E/"*+"%?.&/"+K< ++++++++++++++++!+"4?>/"*+">?2,/$'R-@=,?(W/,'=?&WC(#/$E./,"<+"D?.E/"*+"-,)_?2?(#/_#?$--2_>?2,/$_`?5,C(#/$E./,"+K< ++++++++++++++++!+"4?>/"*+"R-@=,?(W/,'>?2,/$'.-(?.'$5,'.5&="<+"D?.E/"+*+"Q$?=?QLQ>?2,/$QR="+K< ++++++++++++++++!+"4?>/"*+">?2,/$'R-@'=,?(W/,'#?4$./,'(-E4="<+"D?.E/"+*+"HI"+K ++++++++++++UK ++++U< ++++"5=/>&"*+6 ++++++++!+"4?>/"*+"#$%&'&/,D5(/"<+"D?.E/"*+"$&a#$%&"+K< ++++++++!+"4?>/"*+"5-'%5./'@E%%/,'&5S/"<+"D?.E/"*+TFFNT+K ++++U++ K< Build Flow - API Map/Reduce service wide configurations Thursday, April 18, 2013
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Build Flow - Chef hadooppocdndev021 if node.name.match(/^hadoop.*(dn|nn|jt|bastion).*[0-9]../) hostptrn = node.hostname.gsub(/^hadoop/,"")](https://files.speakerdeck.com/presentations/25477b3009c60131167e1a94ecd7685c/slide_33.jpg){kind=link}
![Build Flow - Chef hadooppocdndev021 if node.name.match(/^hadoop.*(dn|nn|jt|bastion).*[0-9]../) hostptrn = node.hostname.gsub(/^hadoop/,"")](https://files.speakerdeck.com/presentations/25477b3009c60131167e1a94ecd7685c/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
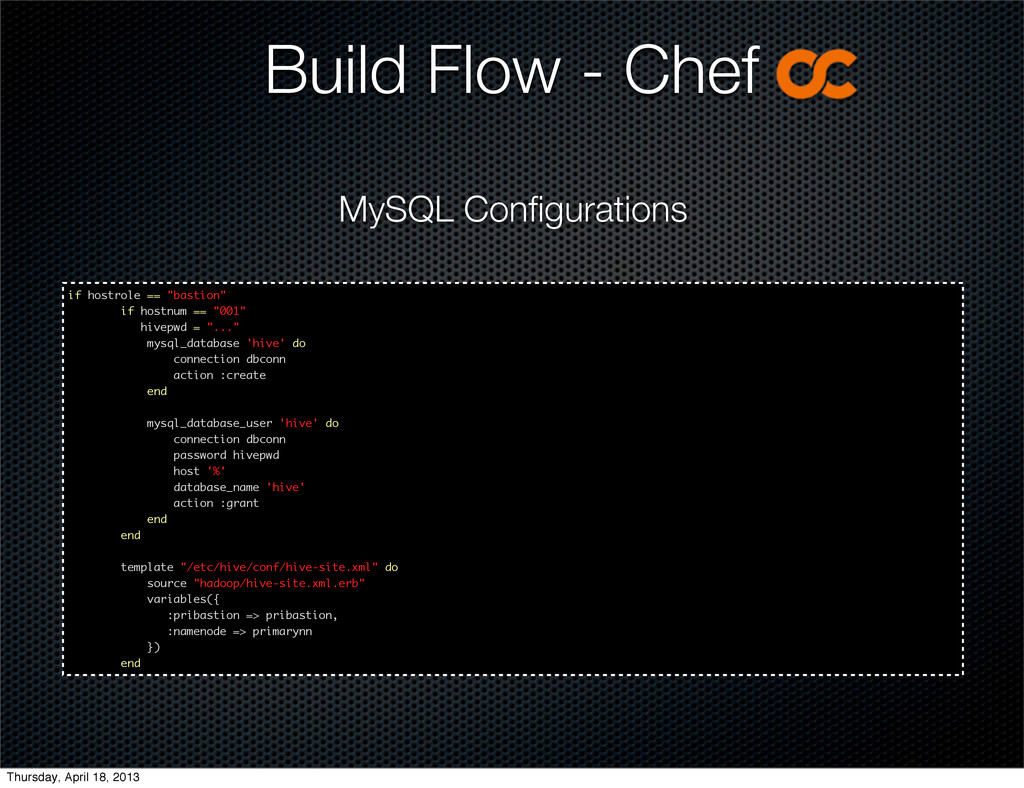
![node['mysql']['server_debian_password'] = "..." node['mysql']['server_repl_password'] = "..." node['mysql']['server_root_password'] = "..." ###](https://files.speakerdeck.com/presentations/25477b3009c60131167e1a94ecd7685c/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
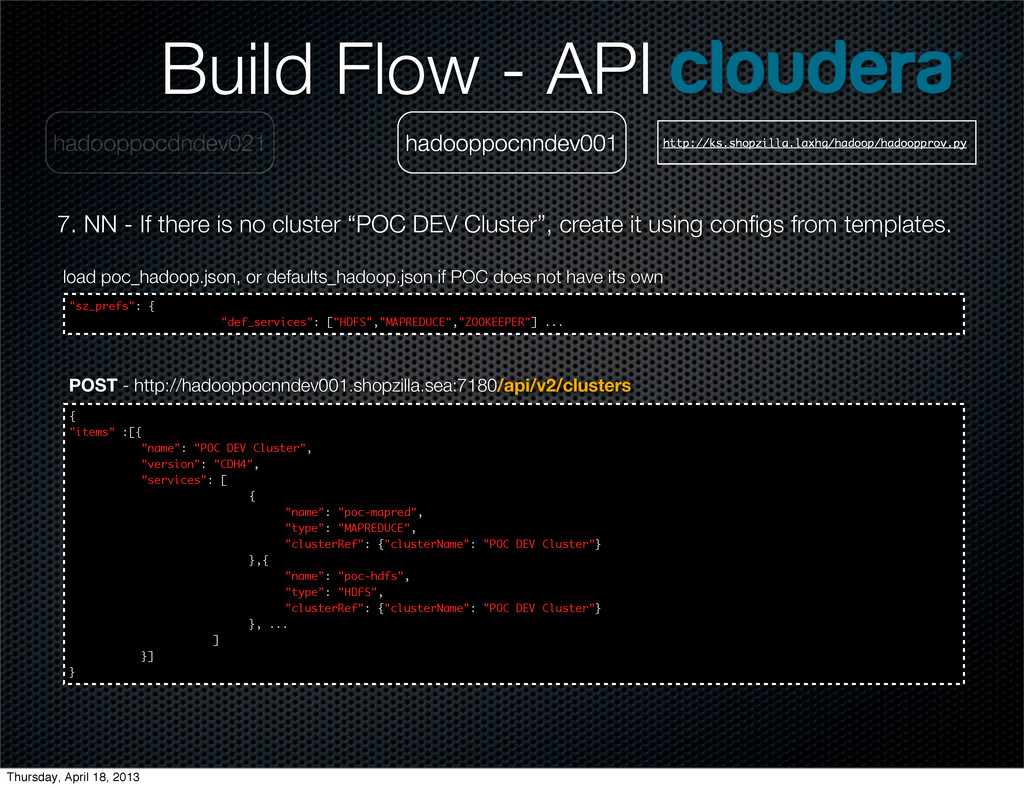{kind=link}
{kind=link}
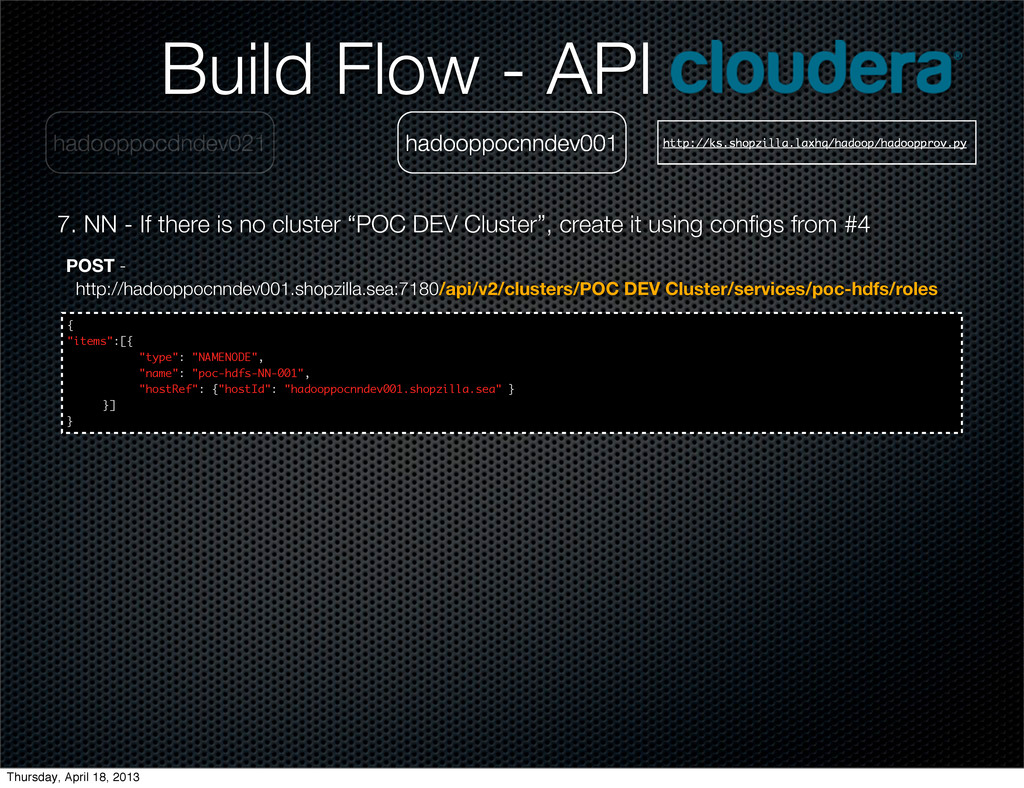{kind=link}
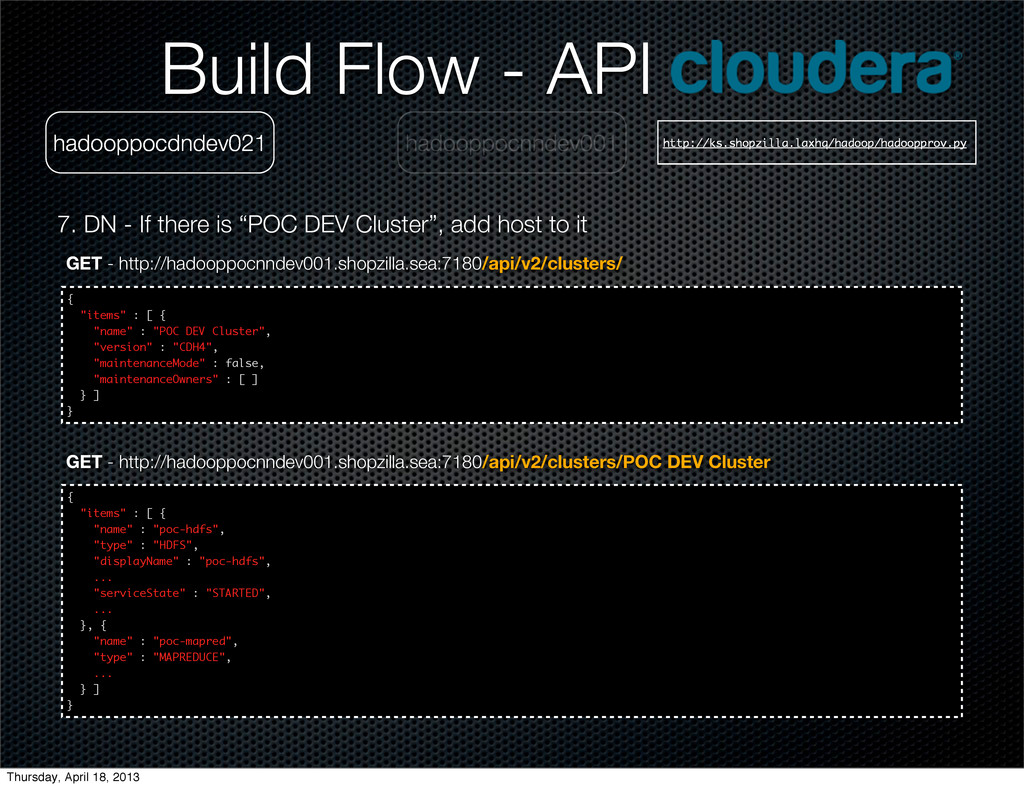{kind=link}
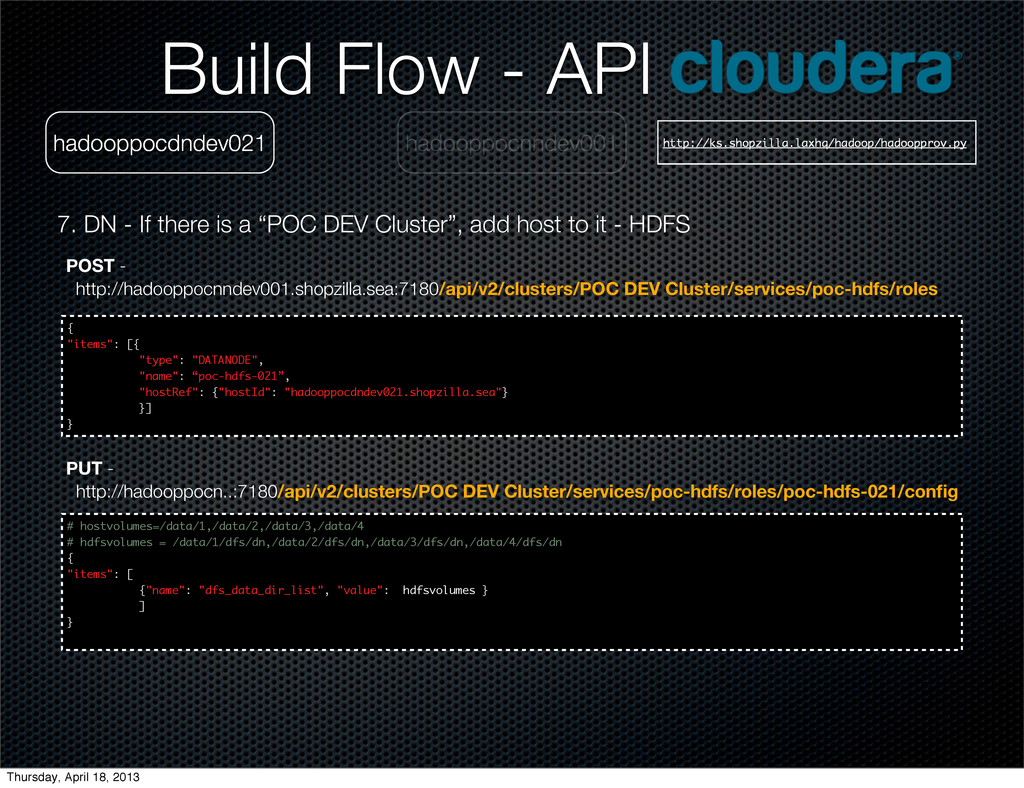{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}