An Introduction to Apache Hadoop MapReduce, what is it and how does
it work ? What is the map reduce cycle and how are jobs managed. Why should it be used and who are big users and providers ?
Hadoop • Developers create Map and Reduce jobs • Used for big data batch processing • Parallel processing of huge data volumes • Fault tolerant • Scalable
Terabyte / Petabyte range • You have huge I/O • Hadoop framework takes care of – Job and task management – Failures – Storage – Replication • You just write Map and Reduce jobs
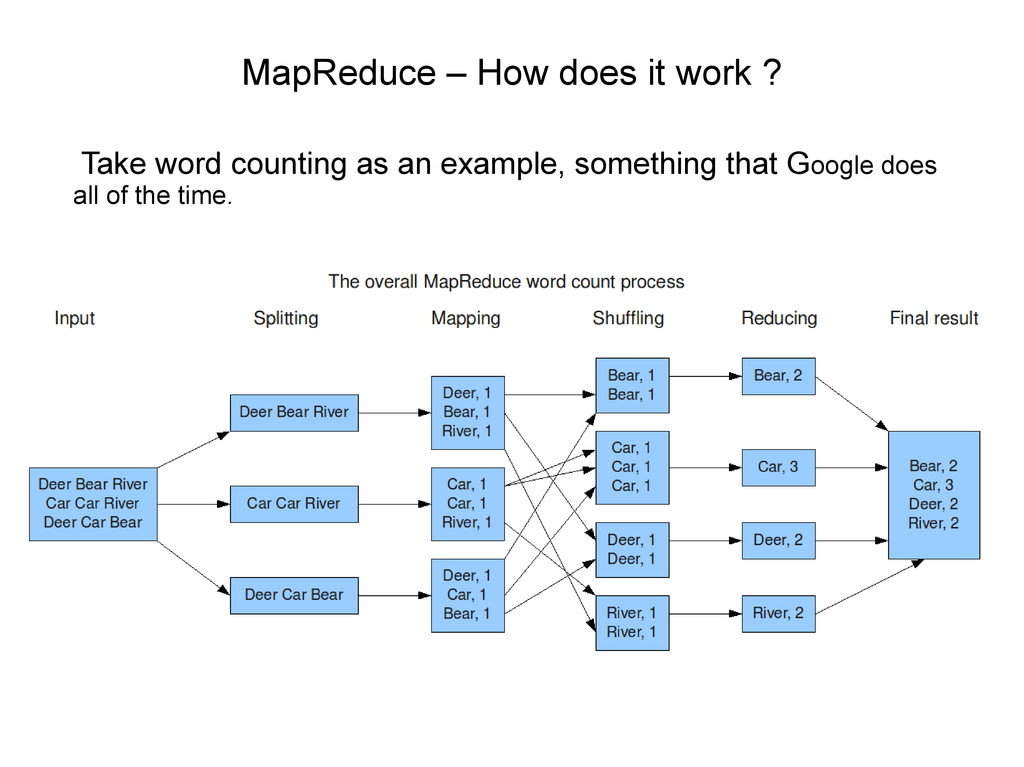
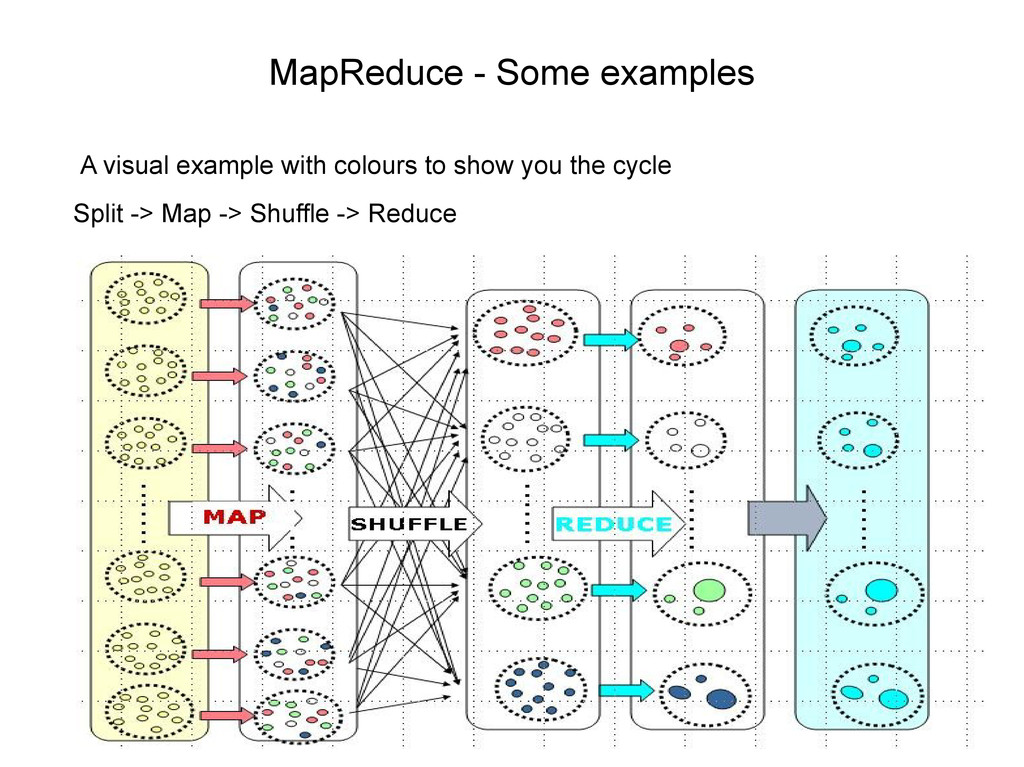
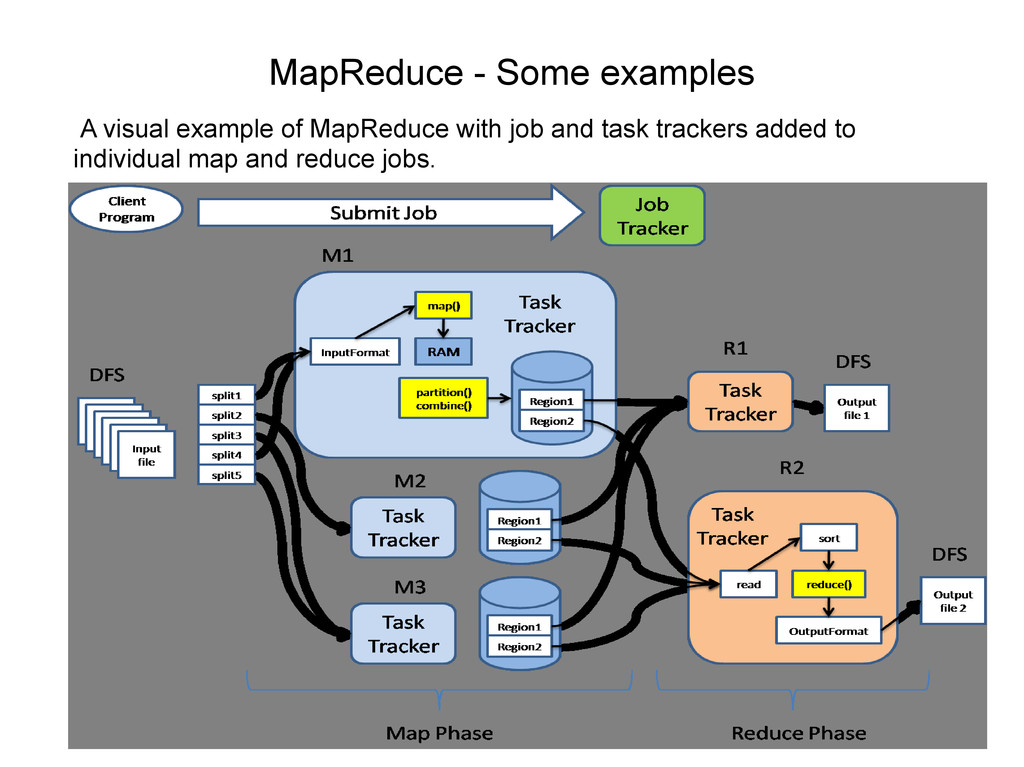
split into shards • Split data mapped to key,value pairs i.e. Bear,1 • Mapped data shuffled/sorted by key i.e. Bear • Sorted data reduced i.e. Bear, 2 • Final data stored on HDFS • There might be extra map layer before shuffle • JobTracker controls all tasks in job • TaskTracker controls map and reduce
www.semtech-solutions.co.nz – [email protected] • We offer IT project consultancy • We are happy to hear about your problems • You can just pay for those hours that you need • To solve your problems
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}