#155 Pavel Senin [email protected] Jessica Lin Xing Wang {jessica,xwang24}@gmu.edu Tim Oates Sunil Gandhi* {Oates,sunilga1}@cs.umbc.edu Arnold Boedihardjo Crystal Chen Susan Frankenstein {arnold.p.boedihardjo, crystal.chen, susan.frankenstein}@usace.army.mil 3/26/2015 Time series anomaly discovery with grammar-based compression 1
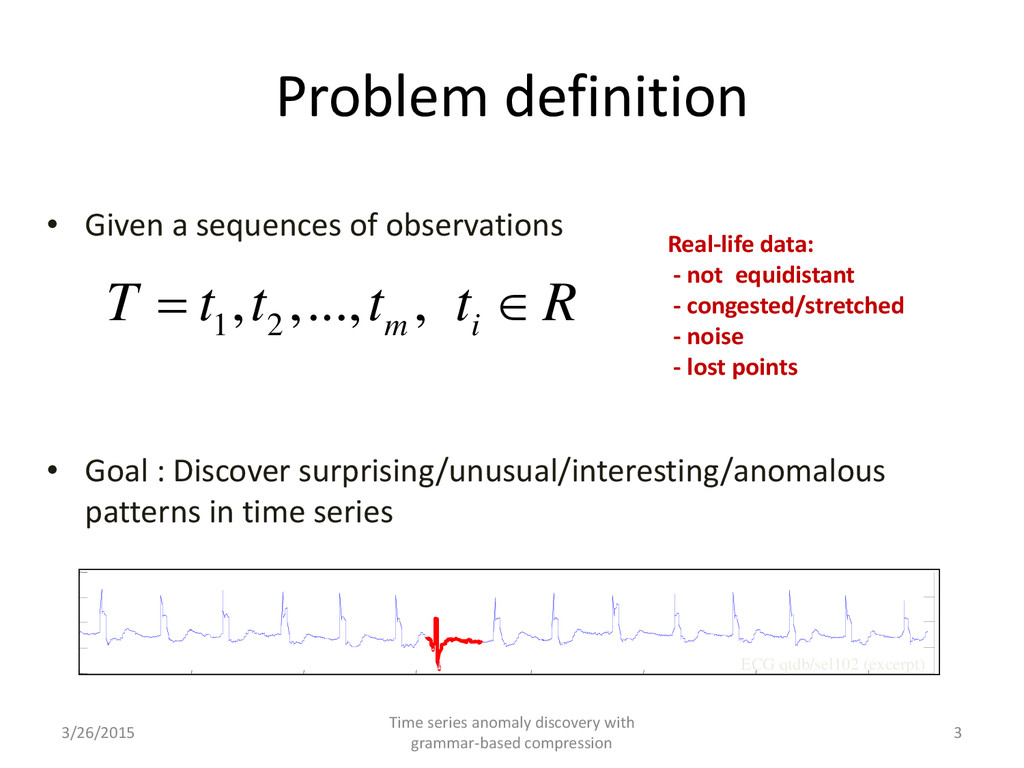
: Discover surprising/unusual/interesting/anomalous patterns in time series 1 2 , ,..., , m i T t t t t R ∈ Real-life data: - not equidistant - congested/stretched - noise - lost points ECG qtdb/sel102 (excerpt) 3/26/2015 Time series anomaly discovery with grammar-based compression 3
– Compute distribution – Make a decision base on likelihood • Complex statistics – HMM • Transformation into a feature space, such as DFT, DWT, etc. 3/26/2015 Time series anomaly discovery with grammar-based compression 4
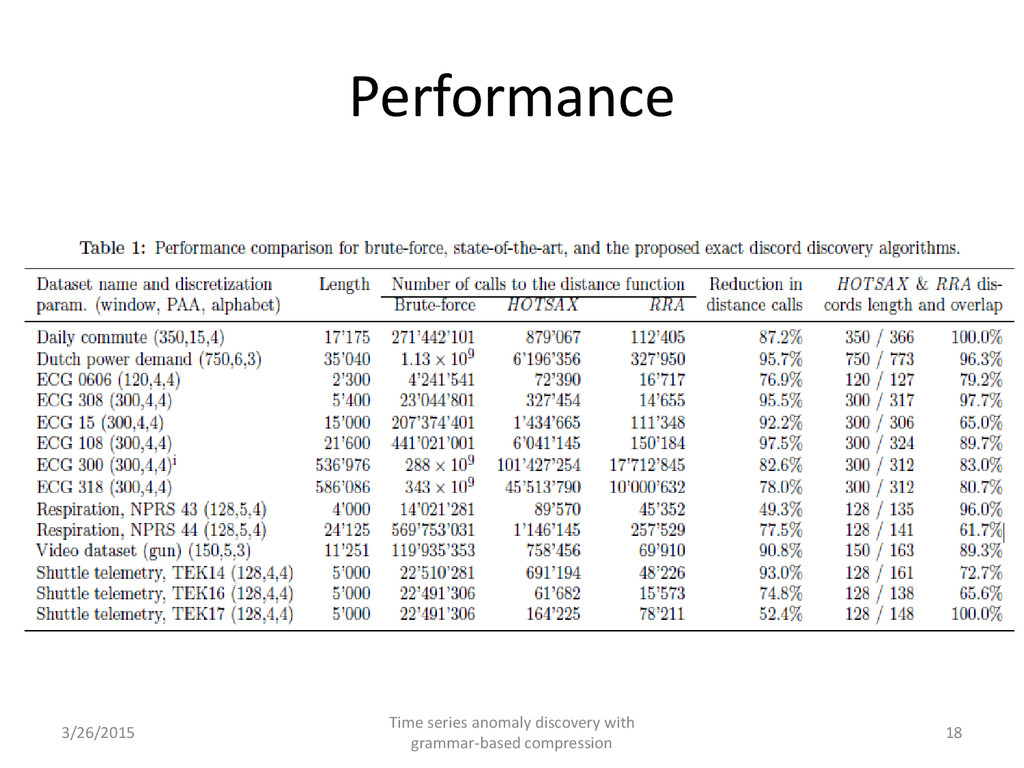
capture anomaly 2. Computational complexity 1. Scan over the data estimating a model, scan to find anomalies 2. Distance computation (reported to be ~99% of runtime*) 3. Input parameters, i.e. a need for an apriori knowledge 1. Length of the potential anomalous or recurrent pattern 2. Threshold of divergence, etc. What if there is a complex distribution? 4. Limited interpretability of the feature space * Eamonn Keogh, Jessica Lin, Ada Fu, HOT SAX: Finding the Most Unusual Time Series Subsequence: Algorithms and Applications, ICDM05 3/26/2015 5
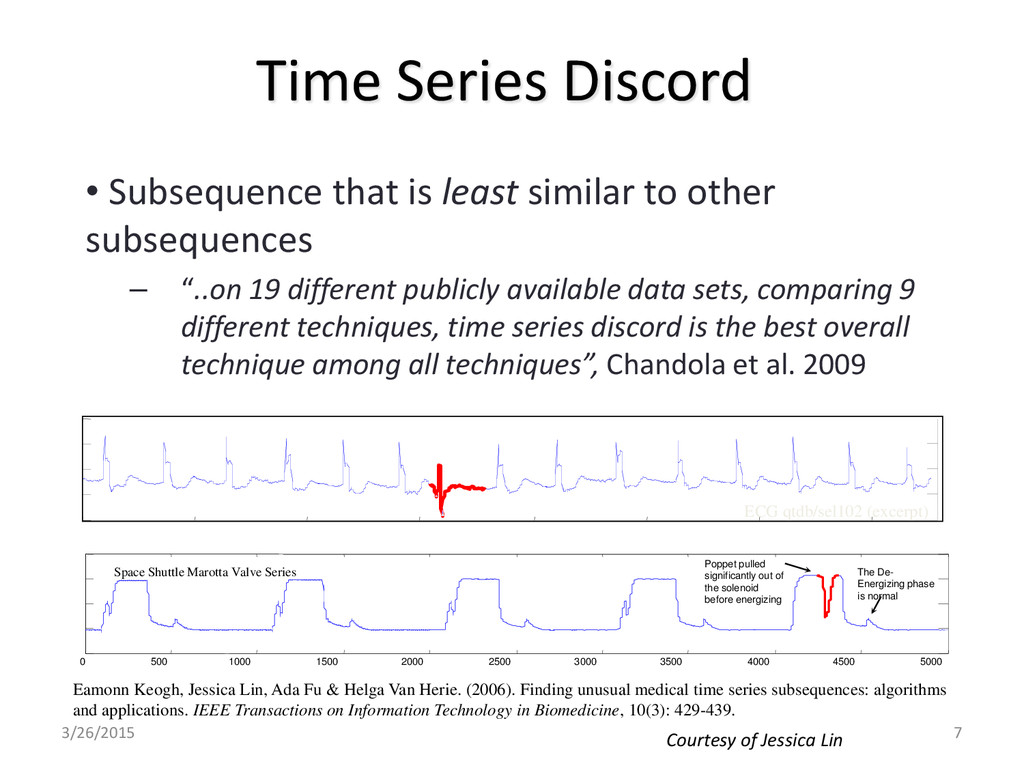
number t (i.e., threshold) and subsequences C and M, if Dist(C, M) ≤ t then subsequence M is a match to C • Non-self match: Given a subsequence C of length n starting at position p of time series T, the subsequence M beginning at q is a non-self match to C at distance Dist(C, M) if |p − q| ≥ n • Time Series Discord: Given a time series T, the time series subsequence C ∈ T is called the discord if it has the largest Euclidean distance to its nearest non-self match 3/26/2015 Time series anomaly discovery with grammar-based compression 6
“..on 19 different publicly available data sets, comparing 9 different techniques, time series discord is the best overall technique among all techniques”, Chandola et al. 2009 ECG qtdb/sel102 (excerpt) Eamonn Keogh, Jessica Lin, Ada Fu & Helga Van Herie. (2006). Finding unusual medical time series subsequences: algorithms and applications. IEEE Transactions on Information Technology in Biomedicine, 10(3): 429-439. Time Series Discord 0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000 Poppet pulled significantly out of the solenoid before energizing The De- Energizing phase is normal Space Shuttle Marotta Valve Series 3/26/2015 7 Courtesy of Jessica Lin
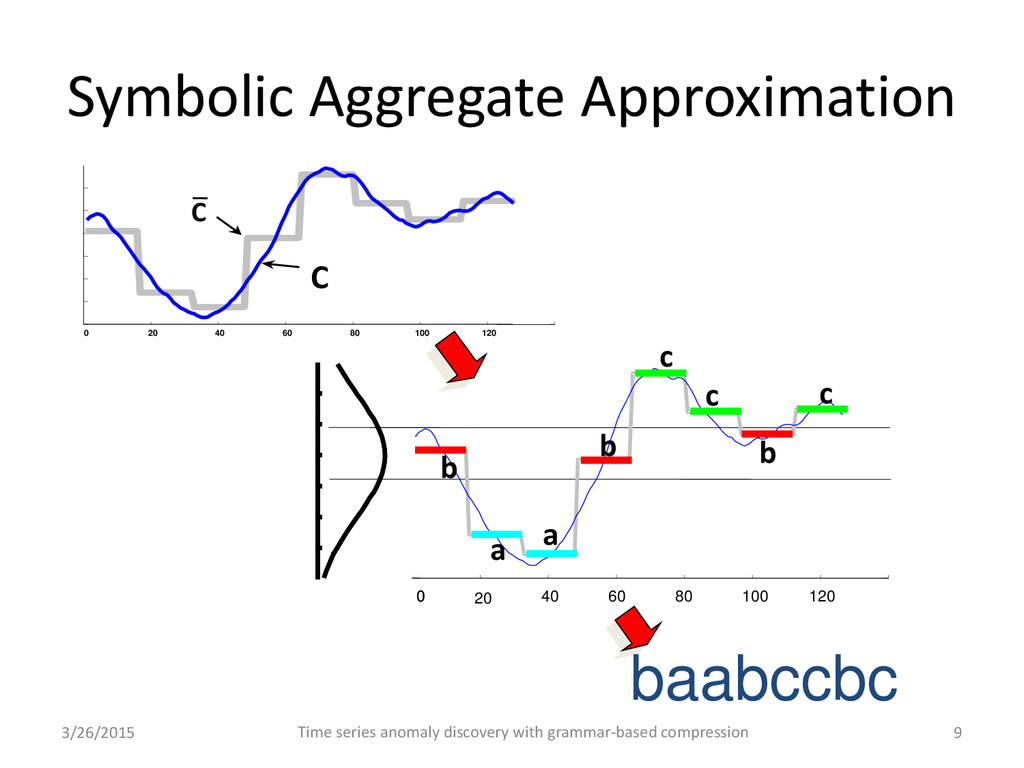
• Guarantees to find the discord through an exhaustive, exact search. • At the first step decomposes the input time series into a map of key and values – words are keys – occurrence indices are values • Intuitively, rare subsequences are good discord candidates – search is ordered (heuristics #1) • Similar subsequences map to the same word – compares them first (heuristics #2) 3/26/2015 Time series anomaly discovery with grammar-based compression 8
Output grammar: Observation: The pattern “XXX” never appears in grammar rules except for the topmost rule (the original string). Approach: For each pattern, just count how many rules it appears in, e.g. “abc” appears in 3 rules. “XXX” appears in none. Advantage: Fast; No prior knowledge on discord length is needed. 3/26/2015 11 Courtesy of Jessica Lin
based on HOT-SAX: guarantees to find the discord through a nearly exhaustive, exact search. • Uses grammar induction to transform the list of SAX words into a context-free grammar – Terminal symbols and rule correspond subsequences for the search • Intuitively, terminal symbols and rare grammar rules are good discord candidates – search is ordered (new heuristics #1) • Similar subsequences map to the same terminal or grammar rule – compares them first (the same heuristics #2) 3/26/2015 Time series anomaly discovery with grammar-based compression 12
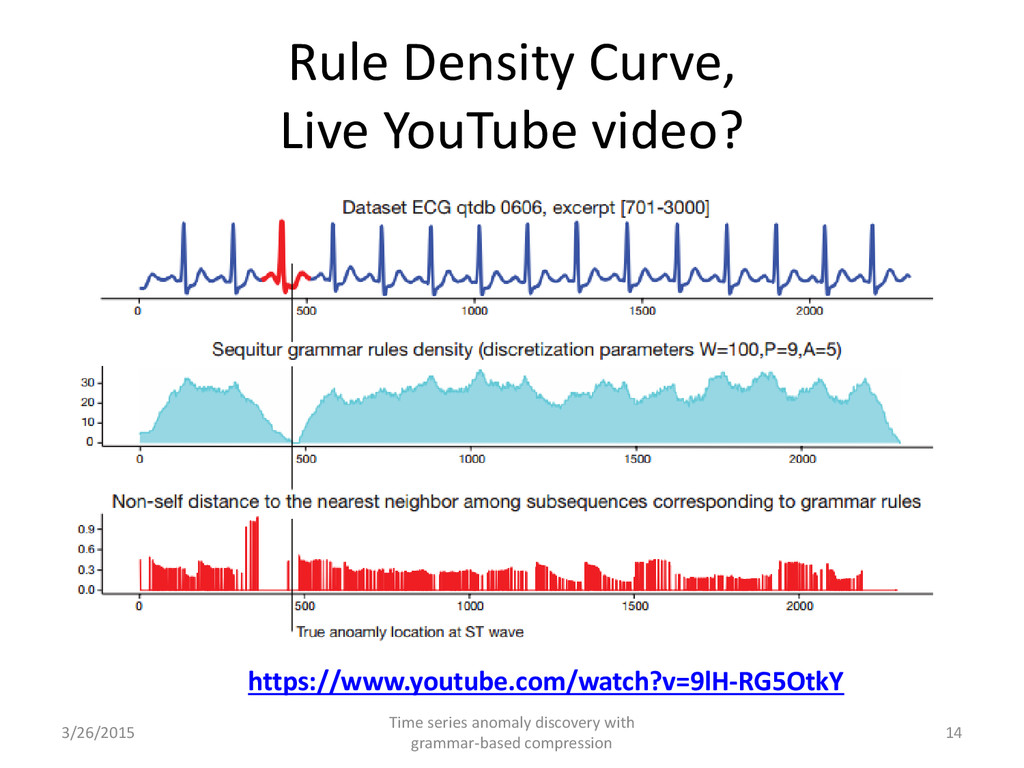
digests new terminals, it continuously changes the grammar: – Creates new rules – Removes obsolete ones • Many rules are overlapping, reflecting the grammar’ hierarchical structure and the correlation between terminal symbol-corresponding subsequences • We account for the rules covering each point of the input time series building a rule density curve 3/26/2015 Time series anomaly discovery with grammar-based compression 13
rare patterns • Kolmogorov Complexity – Size of smallest Turing machine that describes s. 3/26/2015 Time series anomaly discovery with grammar-based compression 15 aaaaaaaaaaaa abbaababab More Structured Less Structured KC(s) less KC(s) more
rare patterns • Kolmogorov Complexity – Size of smallest Turing machine that describes s. 3/26/2015 Time series anomaly discovery with grammar-based compression 16 abcabcabcXXXabcabc
rare patterns • Kolmogorov Complexity – Size of smallest Turing machine that describes s. 3/26/2015 Time series anomaly discovery with grammar-based compression 17
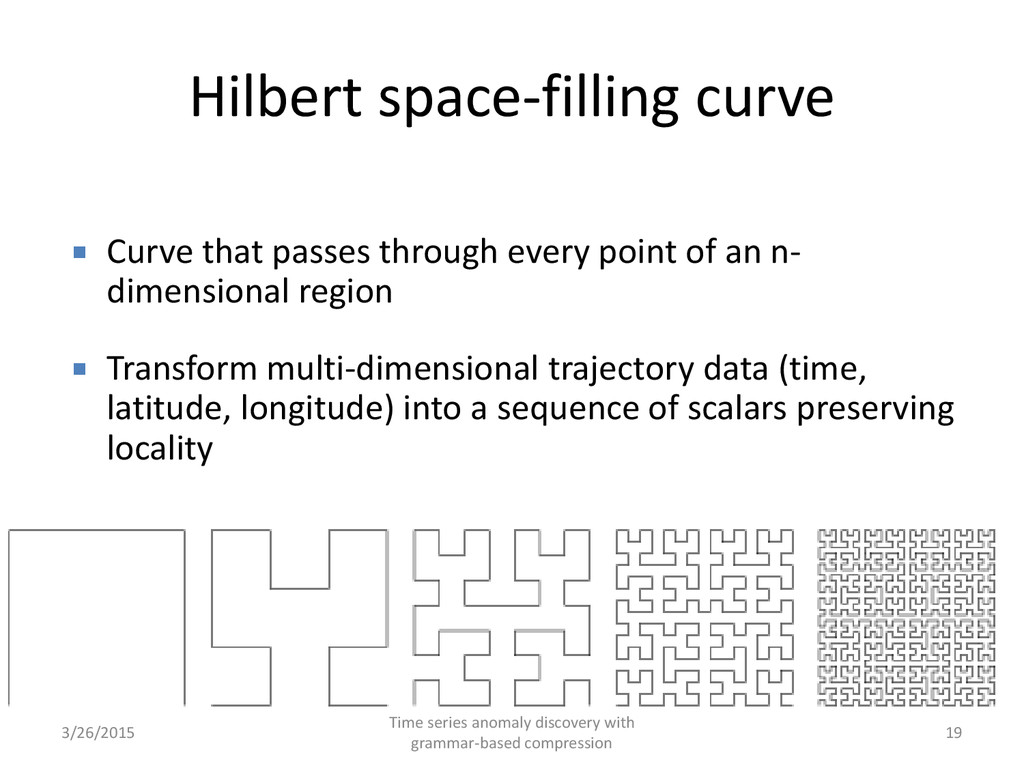
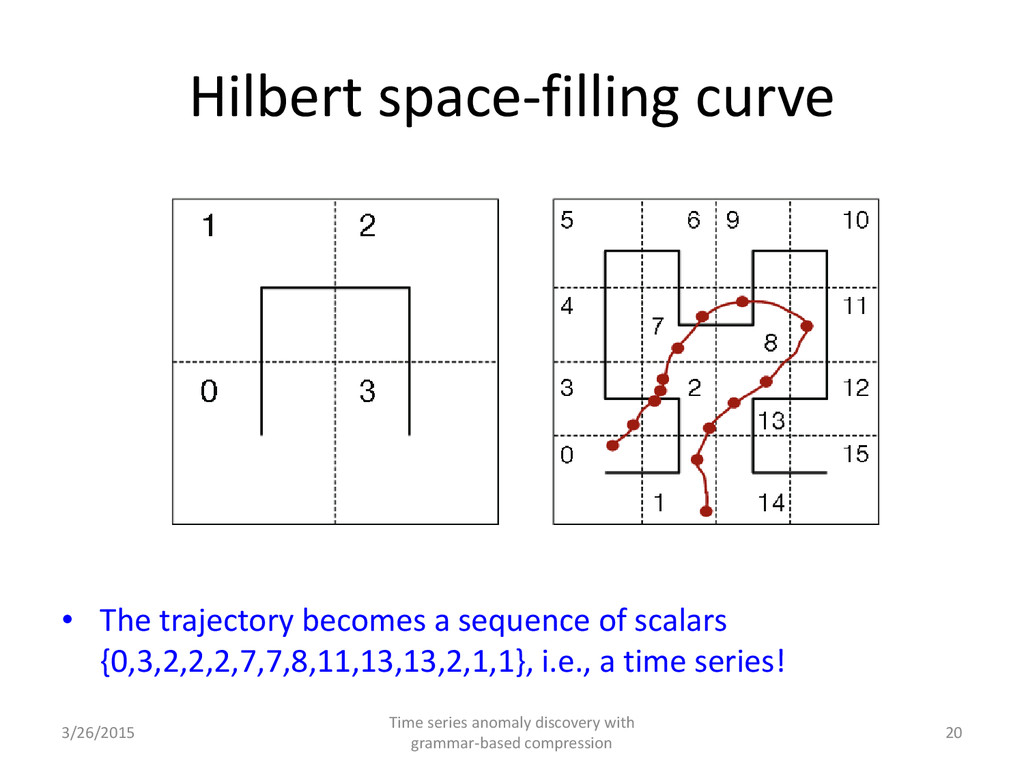
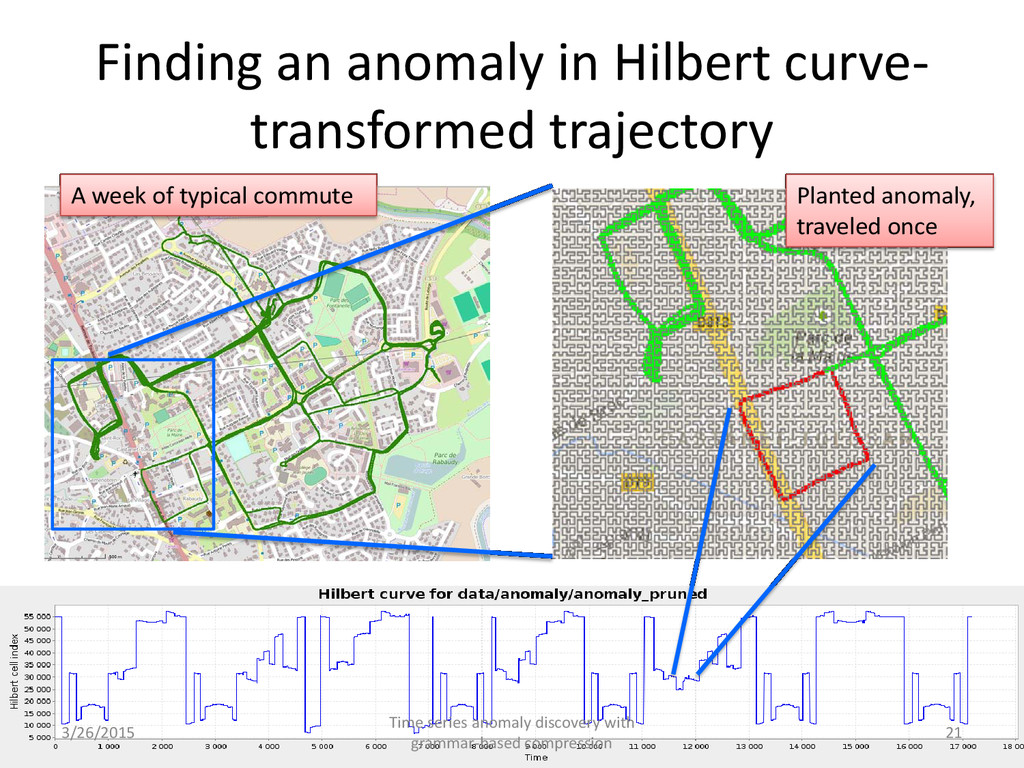
of an n- dimensional region Transform multi-dimensional trajectory data (time, latitude, longitude) into a sequence of scalars preserving locality 3/26/2015 Time series anomaly discovery with grammar-based compression 19
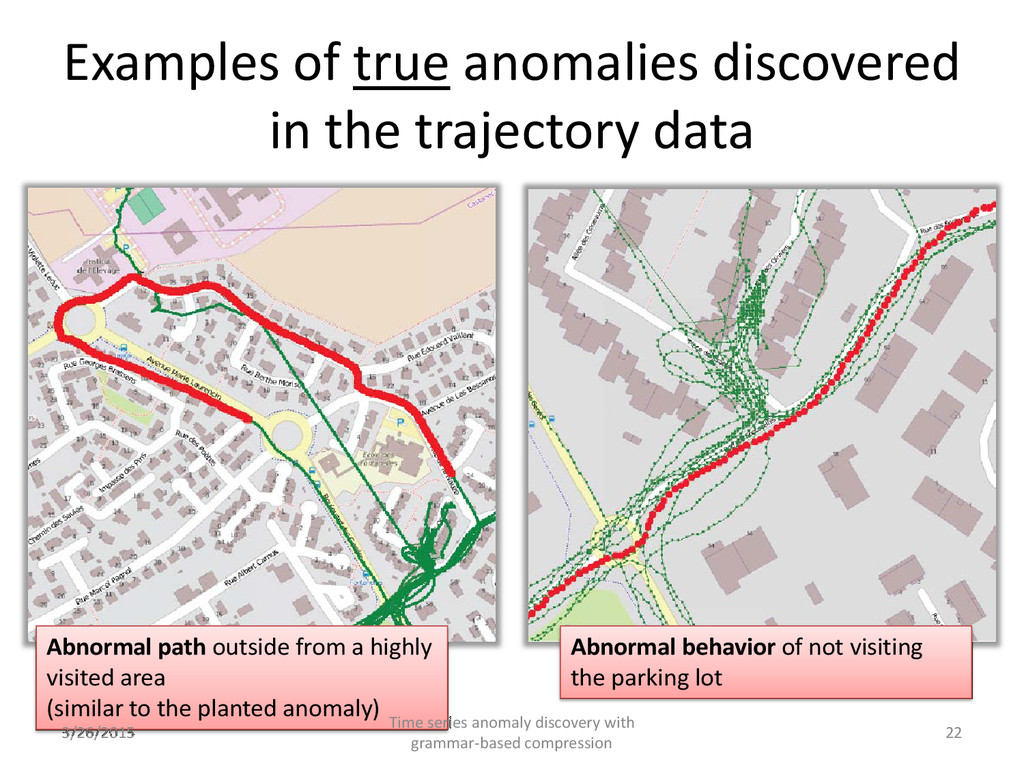
behavior of not visiting the parking lot Abnormal path outside from a highly visited area (similar to the planted anomaly) 3/26/2015 Time series anomaly discovery with grammar-based compression 22
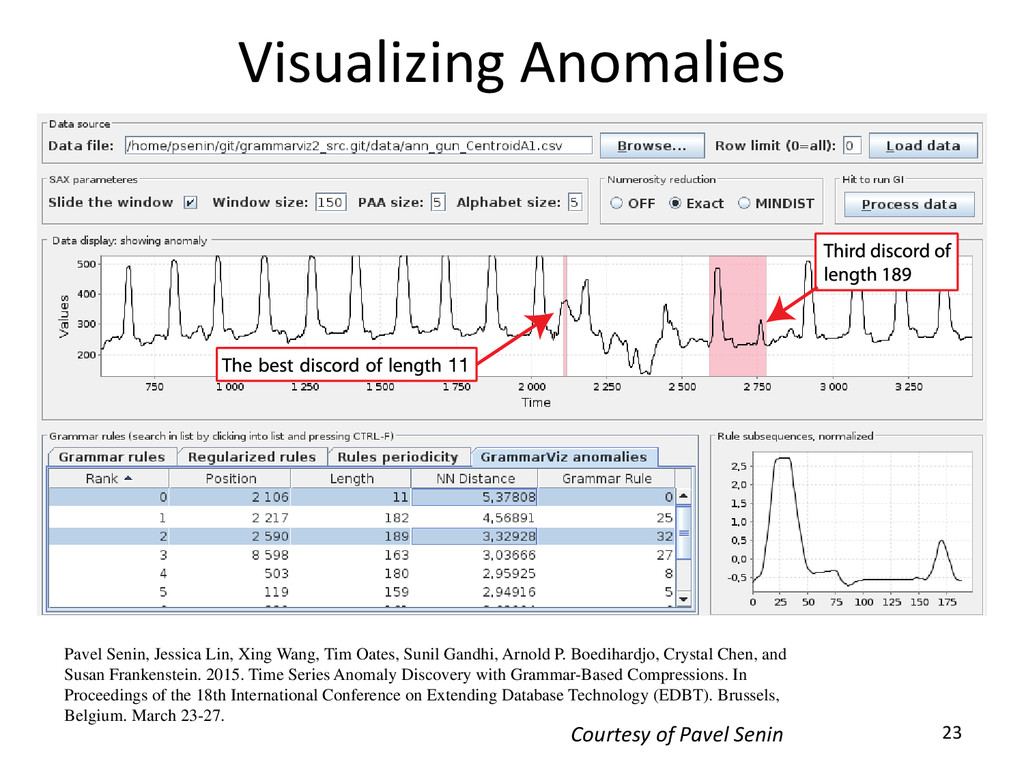
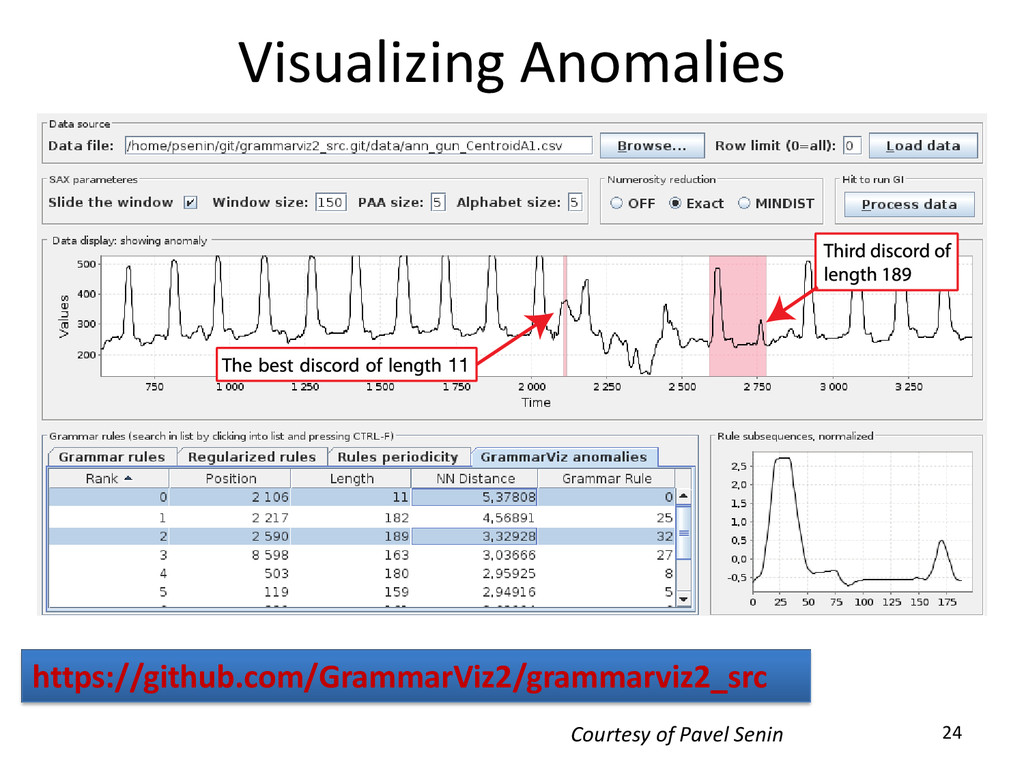
Gandhi, Arnold P. Boedihardjo, Crystal Chen, and Susan Frankenstein. 2015. Time Series Anomaly Discovery with Grammar-Based Compressions. In Proceedings of the 18th International Conference on Extending Database Technology (EDBT). Brussels, Belgium. March 23-27. Visualizing Anomalies Courtesy of Pavel Senin
for discovering short- and long-term correlations in the input string, approximating its Kolmogorov complexity – Sequitur enables streaming data mining • SAX discretization and its numerosity reduction trick enable a significant numerosity reduction of the input data and enable variable-length patterns discovery • GrammarViz 2.0 implements the both proposed algorithms: RRA and Rule Density curve enabling interactive parameters tuning via GUI 3/26/2015 Time series anomaly discovery with grammar-based compression 25
ICS, Collaborative Software Development Laboratory • Jessica Lin, Xing Wang, George Mason University, Department of Computer Science • Tim Oates, Sunil Gandhi, University of Maryland, Baltimore County, Department of Computer Science • Arnold P. Boedihardjo, Crystal Chen, Susan Frankenstein, U.S. Army Corps of Engineers, Engineer Research and Development Center 3/26/2015 Time series anomaly discovery with grammar-based compression 27
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}