Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ML Productivity
Search
Beomjun Shin
January 17, 2018
Research
85
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ML Productivity
short talks on productivity of machine learning
Beomjun Shin
January 17, 2018
More Decks by Beomjun Shin
See All by Beomjun Shin
Convolution Transpose by yourself
shastakr
0
84
스마트폰 위의 딥러닝
shastakr
0
280
Design your CNN: historical inspirations
shastakr
0
39
"진짜 되는" 투자 전략 찾기: 금융전략과 통계적 검정
shastakr
0
86
Other Decks in Research
See All in Research
Vector Map as Language: Toward Unified Remote Sensing Vector Mapping
satai
3
120
Apache Gravitinoで実現する Icebergカタログ統合とアクセスの一元化
matsumooon
0
350
シングルチャネルマルチトーカー音声認識の進展
ryomasumura
0
200
医療LLMの現在地〜最新研究から社会実装までを考える〜
kento1109
1
1.6k
2025年度秋葉原ウォーカブルプロジェクト調査報告 「アキバらしいウォーカブル」とは何か
izumiyama_lab
1
110
明日から使える!研究効率化ツール入門
matsui_528
13
7.5k
羽田新ルート運用6年の検証
1manken
0
180
「AIとWhyを深堀る」をAIと深堀る
iflection
0
530
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
450
東京大学工学部計数工学科、計数工学特別講義の説明資料
kikuzo
0
570
COMETAを用いたデータ民主化運動の歴史
sazimai
0
130
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
150
Featured
See All Featured
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Building AI with AI
inesmontani
PRO
1
1.1k
WENDY [Excerpt]
tessaabrams
11
39k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.5k
We Are The Robots
honzajavorek
0
280
Making the Leap to Tech Lead
cromwellryan
135
10k
First, design no harm
axbom
PRO
2
1.2k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Mind Mapping
helmedeiros
PRO
1
290
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
Writing Fast Ruby
sferik
630
63k
Transcript
ML Productivity Ben (Beomjun Shin) 2018-01-17 (Wed) © Beomjun Shin
Productivity is about not waiting © Beomjun Shin
Time Scales © Beomjun Shin
• Immediate: less than 60 seconds. • Bathroom break: less
than 5 minutes. • Lunch break: less than 1 hour. • Overnight: less than 12 hours. WE MUST ESTIMATE TIME BEFORE RUNNING! © Beomjun Shin
Productivity == Iteration © Beomjun Shin
© Beomjun Shin
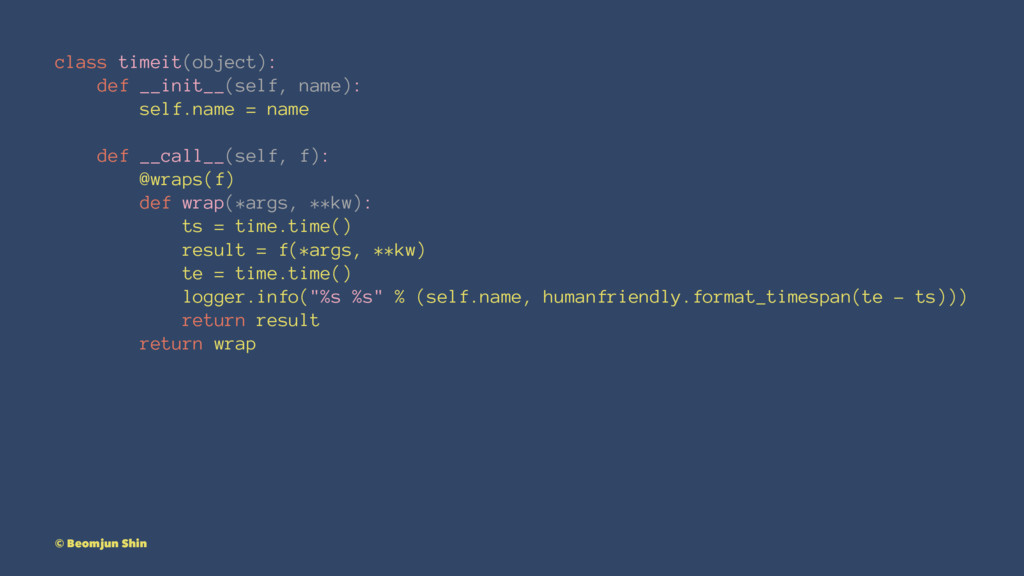
class timeit(object): def __init__(self, name): self.name = name def __call__(self,
f): @wraps(f) def wrap(*args, **kw): ts = time.time() result = f(*args, **kw) te = time.time() logger.info("%s %s" % (self.name, humanfriendly.format_timespan(te - ts))) return result return wrap © Beomjun Shin
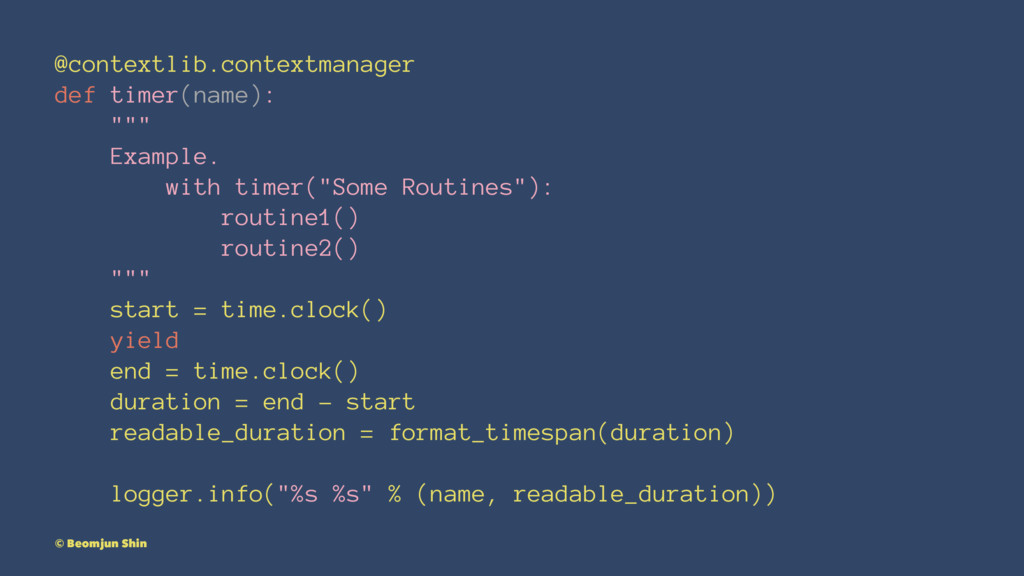
@contextlib.contextmanager def timer(name): """ Example. with timer("Some Routines"): routine1() routine2()
""" start = time.clock() yield end = time.clock() duration = end - start readable_duration = format_timespan(duration) logger.info("%s %s" % (name, readable_duration)) © Beomjun Shin
Use Less Data • Sampled data • Various data •
Synthesis data to validate hypothesis © Beomjun Shin
Sublinear Debugging • Prefer pre-trained model to training from scratch
• Prefer "proven(open-sourced)" code to coding from scratch • Prefer "SGD" to "complex" optimization algorithm © Beomjun Shin
Sublinear Debugging • Logging as many as possible: • First
N step BatchNorm Mean/Variance tracking • Scale of Logit, Activation • Rigorous validation of data quality, preprocessing, augmentation • 2 days of validation is worth enough • Insert assertions as many as possible © Beomjun Shin
Linear Feature Engineering engineering features for a linear model and
then switching to a more complicated model on the same representation © Beomjun Shin
Flexible Code • We can sacrifice "Code Efficiency" for "Flexibility"
• Exchange "raw" data between models and preprocessing by code • Unlike API server, in machine learning task so many assumption can be changed • We should always be prepare to build whole pipeline from scratch © Beomjun Shin
Reproducible preprocessing • Every data preprocessing will be fail in
first iteration • let's fall in love with shell © Beomjun Shin
Shell commands © Beomjun Shin
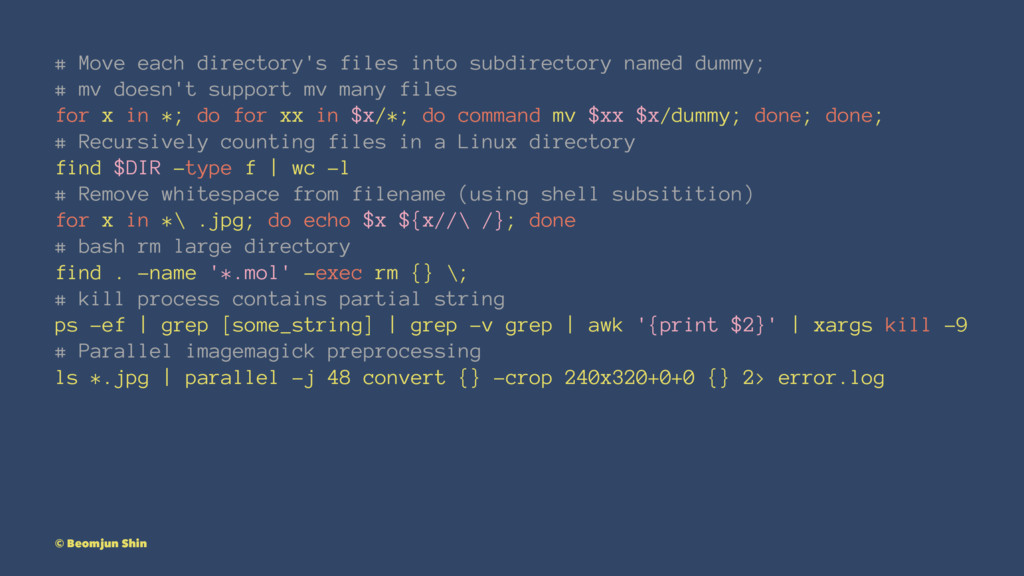
# Move each directory's files into subdirectory named dummy; #
mv doesn't support mv many files for x in *; do for xx in $x/*; do command mv $xx $x/dummy; done; done; # Recursively counting files in a Linux directory find $DIR -type f | wc -l # Remove whitespace from filename (using shell subsitition) for x in *\ .jpg; do echo $x ${x//\ /}; done # bash rm large directory find . -name '*.mol' -exec rm {} \; # kill process contains partial string ps -ef | grep [some_string] | grep -v grep | awk '{print $2}' | xargs kill -9 # Parallel imagemagick preprocessing ls *.jpg | parallel -j 48 convert {} -crop 240x320+0+0 {} 2> error.log © Beomjun Shin
How many commands are you familiar? • echo, touch, awk,
sed, cat, cut, grep, xargs, find • wait, background(&), redirect(>) • ps, netstat • for, if, function • parallel, imagemagick(convert) © Beomjun Shin
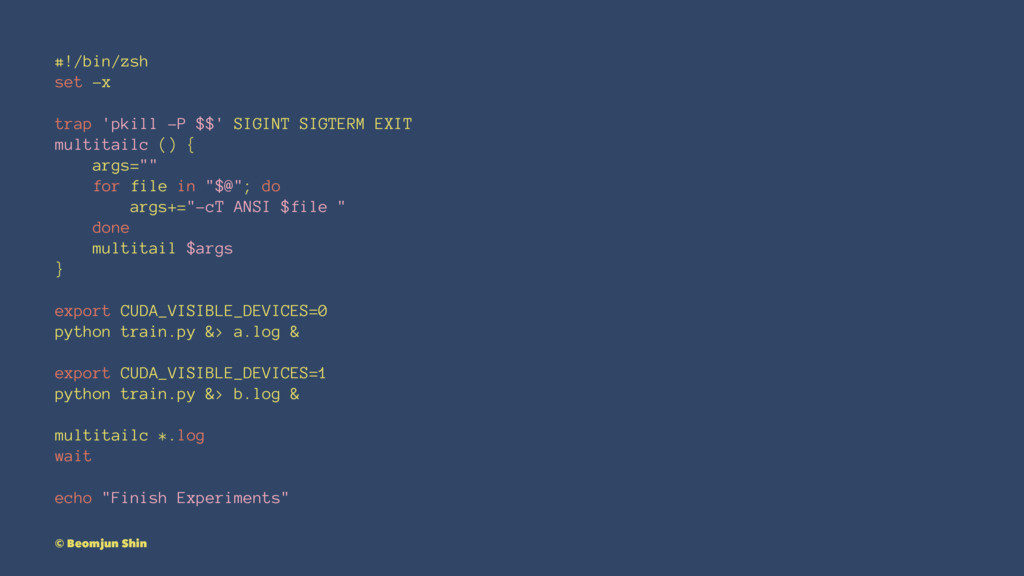
#!/bin/zsh set -x trap 'pkill -P $$' SIGINT SIGTERM EXIT
multitailc () { args="" for file in "$@"; do args+="-cT ANSI $file " done multitail $args } export CUDA_VISIBLE_DEVICES=0 python train.py &> a.log & export CUDA_VISIBLE_DEVICES=1 python train.py &> b.log & multitailc *.log wait echo "Finish Experiments" © Beomjun Shin
Working Process 1. Prepare "proven" data, model or idea 2.
Data validation 3. Setup evaluation metrics (at least two) • one is for model comparison, the other is for human 4. Code and test whether it is "well" trained or not 5. Model improvement (iteration) © Beomjun Shin
Build our best practice • datawrapper - model - trainer
• data/ folder in project root • experiment management © Beomjun Shin
Be aware of ML's technical debt • Recommend to read
Machine Learning: The High- Interest Credit Card of Technical Debt from Google © Beomjun Shin
References • Productivity is about not waiting • Machine Learning:
The High-Interest Credit Card of Technical Debt • Patterns for Research in Machine Learning • Development workflows for Data Scientists © Beomjun Shin
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}