Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Design your CNN: historical inspirations
Search
Beomjun Shin
October 21, 2017
Research
39
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Design your CNN: historical inspirations
talks at MLDS study
Beomjun Shin
October 21, 2017
More Decks by Beomjun Shin
See All by Beomjun Shin
Convolution Transpose by yourself
shastakr
0
84
ML Productivity
shastakr
1
85
스마트폰 위의 딥러닝
shastakr
0
280
"진짜 되는" 투자 전략 찾기: 금융전략과 통계적 검정
shastakr
0
86
Other Decks in Research
See All in Research
JICA QUEST 共創×革新プログラム Impact Report(海ノ向こうコーヒー)
ontheslope
0
240
[Fishers] DIVER OSINT CTF 2026 特化AIエージェントハーネスで挑戦するOSINT CTF
analokmaus
0
200
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
340
Cross-Media Human-Information Interaction
signer
PRO
0
130
研究室単位での自律的 IPv6接続性確立に向けたAS共同運用モデルの提案と実証
reokashiwa
PRO
0
160
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
250
HAKARI-Bench - 実運用視点での情報検索モデル評価ベンチマーク
hotchpotch
0
110
データセンター事業者を取り巻く近年の状況とその中での研究開発動向、テストベッドへの貢献の可能性
kikuzo
1
270
Unified Audio Source Separation (Defense Slides)
kohei_1979
1
630
Φ-Sat-2のAutoEncoderによる情報圧縮系論文
satai
4
870
データサイエンティストの就労意識~2015 → 2026 一般(個人)会員アンケートより
datascientistsociety
PRO
0
450
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
450
Featured
See All Featured
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
190
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
Paper Plane
katiecoart
PRO
2
52k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
270
Designing Powerful Visuals for Engaging Learning
tmiket
1
460
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
160
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.7k
The browser strikes back
jonoalderson
0
1.4k
Transcript
Design your CNN: historical inspirations Ben (Beomjun Shin) October 21,
2017 © Beomjun Shin, October 31, 2017
Disclaimer • Some papers are skipped: I haven't read them,
or they are not famous • Papers are selected using my own perspective • Test phase details omitted: Multi-Crop, Ensemble, average the scores at multiple scales • Data Augmentation details skipped: Scaling, Aspect ratio, translation, flipping • Mobile SOTA results will be discussed on Naver Tech Talk (!) © Beomjun Shin, October 31, 2017
Classification © Beomjun Shin, October 31, 2017
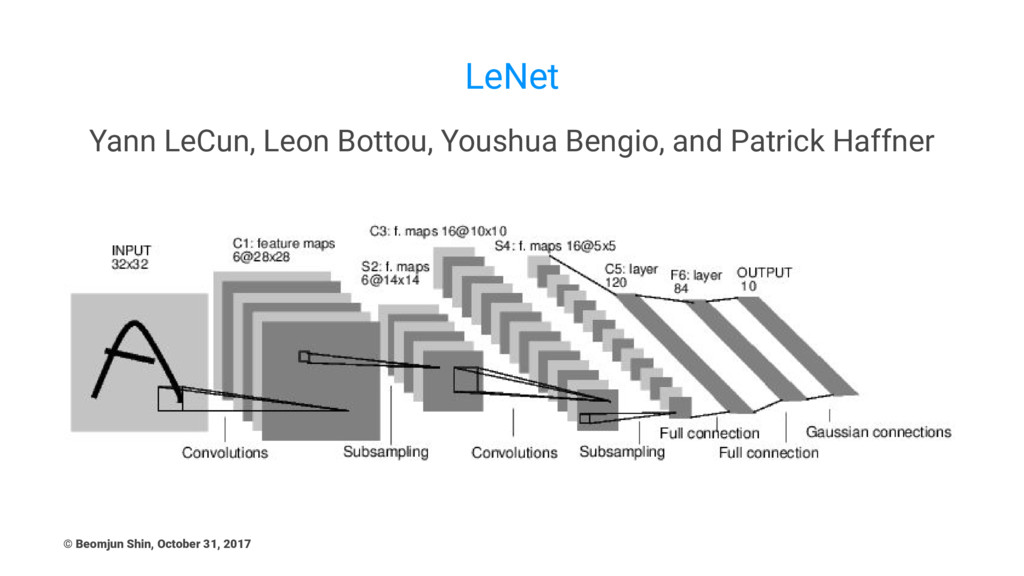
LeNet Yann LeCun, Leon Bottou, Youshua Bengio, and Patrick Haffner
© Beomjun Shin, October 31, 2017
Main Points • Two full connected layers in last two
layers (out-of-fashion) • Mainly uses 5x5 convolution layers • Downsampling only with max_pool stride = 2 Thoughts • Only stride 1 for convolution layer • 224x224, batch_size: 32 -> Memory? 8500MB (Big!) © Beomjun Shin, October 31, 2017
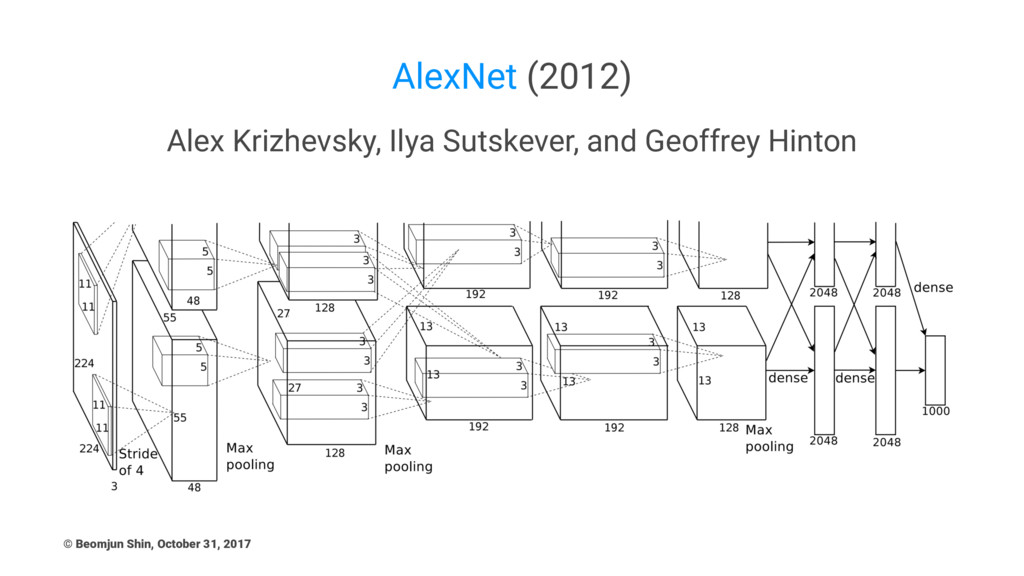
AlexNet (2012) Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton ©
Beomjun Shin, October 31, 2017
AlexNet Main Points - 1 • Techniques still used today,
such as ReLU, Dropout, Data Augmentation techniques • Many paper cite AlexNet's data augmentation techniques ! • Out-of-fashion techniques: Local Response Normalization, Multi-GPU training, Group convolution, Overlapping Pooling (stride < kernel_size), Three FC layers • Data Augmentation: (1) image translation, horizontal reflection (2) altering the intensities of the RGB channels in training images. © Beomjun Shin, October 31, 2017
AlexNet Main Points - 2 • Trained on two GTX
580 GPUs for five to six days • Model Parallelism: Multi-GPU structure: Read AlexNetV2 • CONV1, CONV2, CONV4, CONV5: Connections only with feature maps on same GPU • CONV3, FC6, FC7, FC8: Connections with all feature maps in preceding layer, communication across GPUs © Beomjun Shin, October 31, 2017
Thoughts about AlexNet • In Multi-GPU training, it can be
seen as "grouped convolution" and it has side-effects: • SIDE EFFECT: Outputs from a certain channel are only derived from a small fraction of input • Because of patch extraction for data augmentation, AlexNet firstly suggests 224x224 image size (256x256 -> 224x224) • First use of RELU (maybe not) • A kind of early downsampling by stride = 4 © Beomjun Shin, October 31, 2017
ZFNet: Fine-tuning of AlexNet Developed a visualization technique named Deconvolutional
Network, which helps to examine different feature activations and their relation to the input space. © Beomjun Shin, October 31, 2017
VGG © Beomjun Shin, October 31, 2017
© Beomjun Shin, October 31, 2017
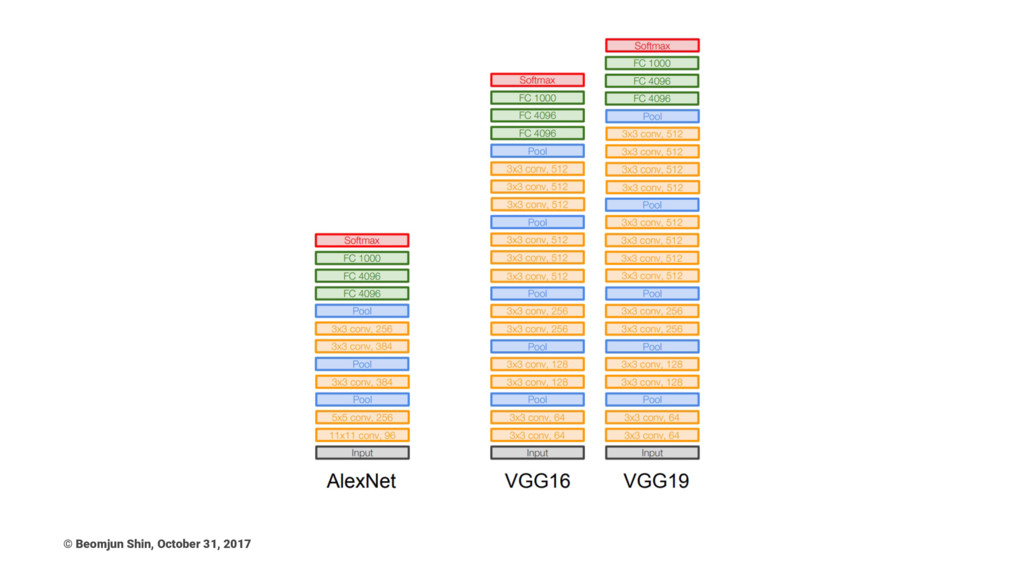
VGG Main Points - 1 • Stack of three 3x3
conv (stride 1) layers has same effective receptive field as one 7x7 conv layer • two 3x3 conv has same effective receptive field of 5x5 conv • "Most memory is in early CONV, Most Parameters are in late FC" • ILSVRC’14 2nd in classification, 1st in localization • FC7 features generalize well to other tasks © Beomjun Shin, October 31, 2017
VGG Main Points - 2 • Trained on 4 Nvidia
Titan Black GPUs for two to three weeks. • Suggest two rules to ensure the computational complexity in terms of FLOPs (floating-point operations, in of multiply-adds) which are roughly the same for all blocks. 1. If producing spatial maps of the same size, the blocks share the same hyper-parameters (width and filter sizes) 2. Each time when the spatial map is downsampled by a factor of 2, the width of the blocks is multiplied by a factor of 2 © Beomjun Shin, October 31, 2017
© Beomjun Shin, October 31, 2017
Thoughts about VGG • "Effective Receptive Field(two 3x3 = 5x5,
three 3x3 = 7x7)" is important Dilated convolution, To use 1xN kernel • Depth of the network is a critical component for good performance Deeper and Deeper • Narrow down the design space and focus on a few key factors! Homogenoeous architecture • "Most memory is in early CONV, Most Parameters are in late FC" Early Downsampling & Remove FC layers © Beomjun Shin, October 31, 2017
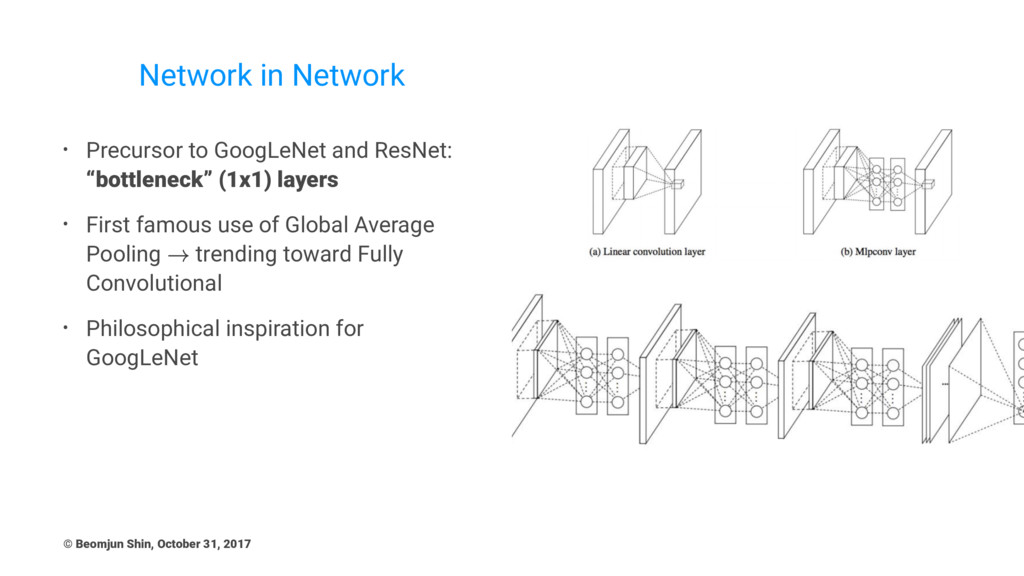
Network in Network • Precursor to GoogLeNet and ResNet: “bottleneck”
(1x1) layers • First famous use of Global Average Pooling trending toward Fully Convolutional • Philosophical inspiration for GoogLeNet © Beomjun Shin, October 31, 2017
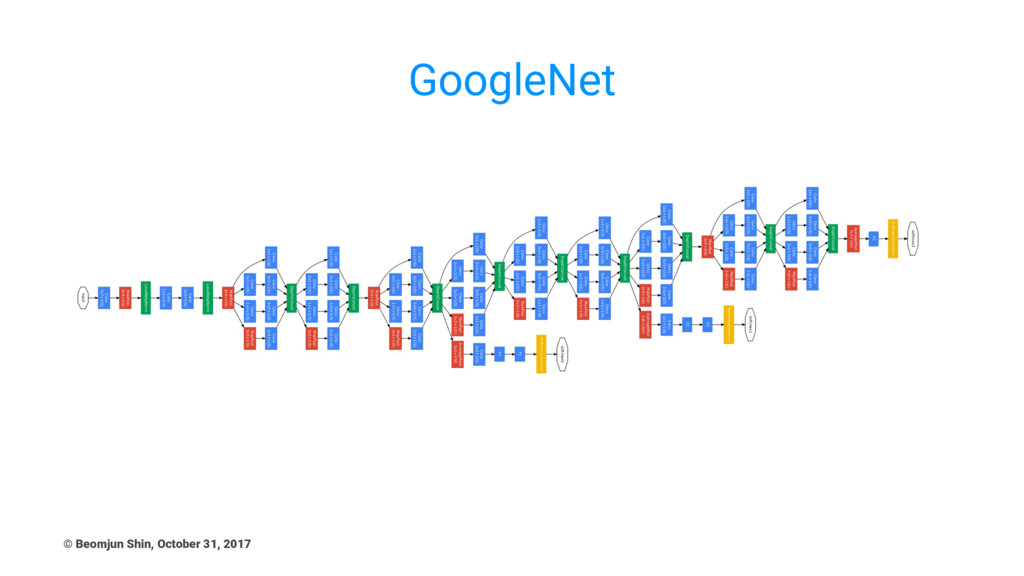
GoogleNet © Beomjun Shin, October 31, 2017
Main Points of GoogleNet(Inception) - 1 • Improved utilization of
the computing resources Uses 12x fewer parameters than AlexNet (!) • No use of fully connected layers! They use an average pooling instead, to go from a 7x7x1024 volume to a 1x1x1024 volume. This saves a huge number of parameters. • Auxiliary classification outputs to inject additional gradient at lower layers © Beomjun Shin, October 31, 2017
Main Points of GoogleNet(Inception) - 2 • split-transform-merge strategy :
the input is split into a few lower- dimensional embeddings (by 1×1 convolutions), transformed by a set of specialized filters (3×3, 5×5, etc.), and merged by concatenation Revisited by ResNext • The solution space of this architecture is a strict subspace of the solution space of a single large layer (e.g., 5×5) operating on a high- dimensional embedding. • Using 1x1 convolutions to reduce computational cost for 3x3, 5x5 • Trained on “a few high-end GPUs within a week”. © Beomjun Shin, October 31, 2017
Thoughts about GoogleNet(Inception) • It is hard to adapt inception
architectures to new datasets/tasks (too! careful design) • First popularized Multi-branch strategy & Bottleneck design • Multi-level feature extraction(1x1, 3x3, 5x5) multi-level feature? • Toward efficient network : (3x3+3x3)/ (5x5) = 72%, (1x3+1x3)/(3x3) = 66% © Beomjun Shin, October 31, 2017
Rethinking the Inception Architecture for Computer Vision • Factorizing Convolutions
with large filter size • (3x3+3x3)/(5x5) = 72%, (1x3+1x3)/(3x3) = 66% • Efficient Grid Size Reduction • Efficient way to expand channel: concat • Model Regularization via Label Smoothing • Performance on Lower Resolution Input • 299x299 vs 151x151 vs 79x79 : Almost same accuracy when training for a long-time © Beomjun Shin, October 31, 2017
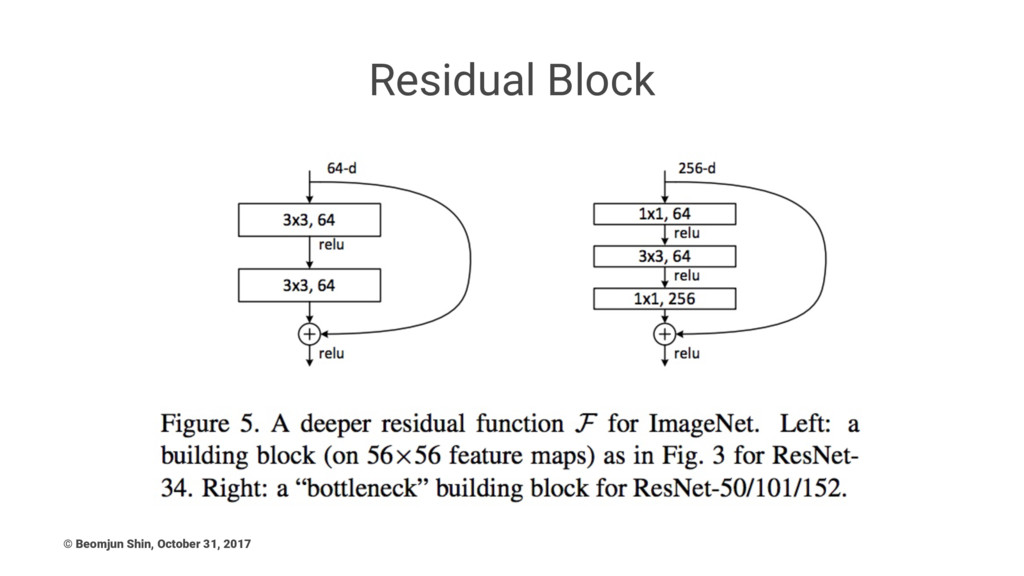
ResNet • after only the first 2 layers, the spatial
size gets compressed from an input volume of 224x224 to a 56x56 volume. Accuracy or Speed(Memory) ? • Keywords, Residual Learning (Shortcut connection), Bottleneck Design again, batch normalization • Swept 1st place in all ILSVRC and COCO 2015 competitions • First Ultra-Deep Network (shows power of depth!) • End with average pooling and then FC layer • Trained on an 8 GPU machine for two to three weeks. © Beomjun Shin, October 31, 2017
Residual Block © Beomjun Shin, October 31, 2017
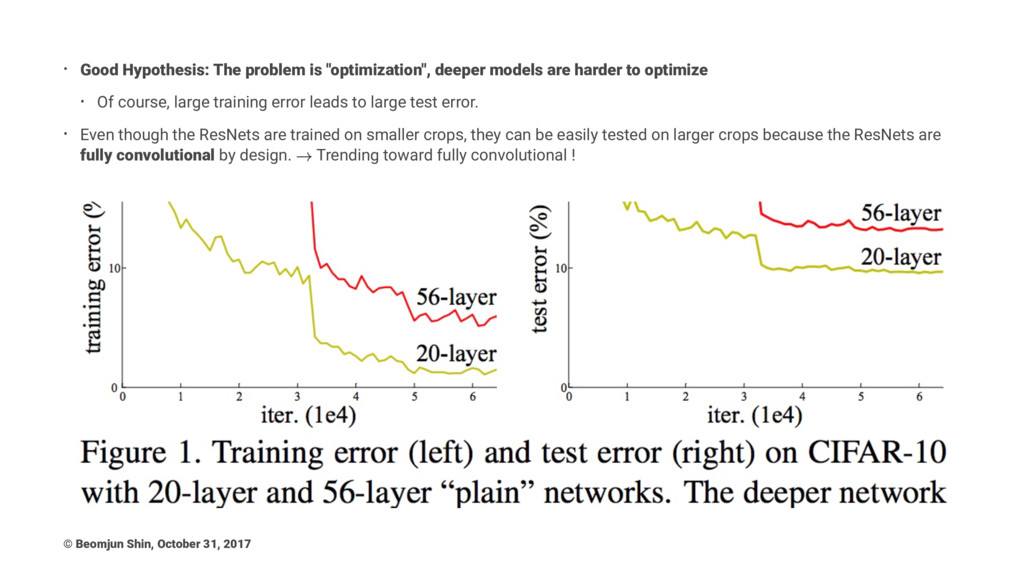
• Good Hypothesis: The problem is "optimization", deeper models are
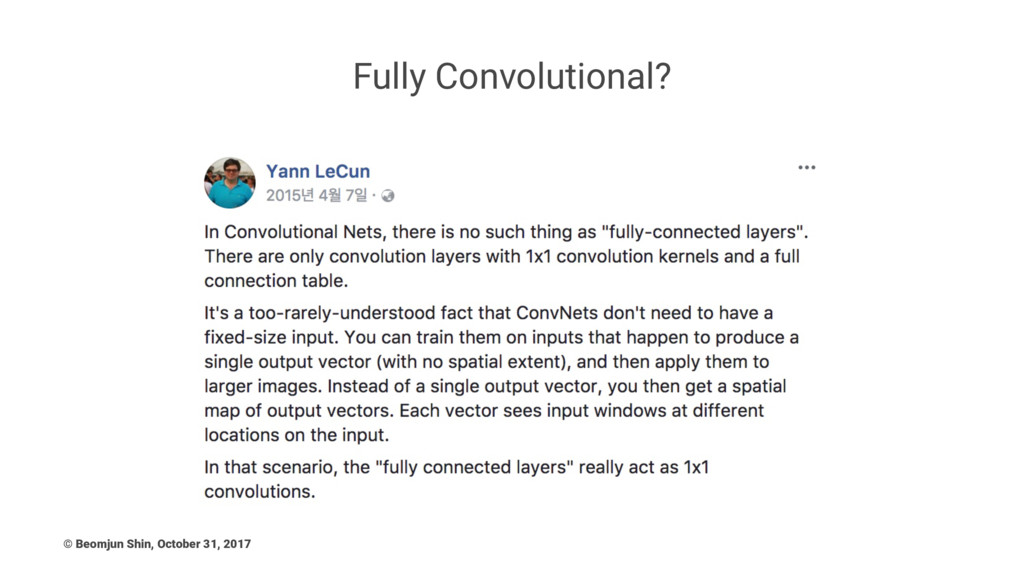
harder to optimize • Of course, large training error leads to large test error. • Even though the ResNets are trained on smaller crops, they can be easily tested on larger crops because the ResNets are fully convolutional by design. Trending toward fully convolutional ! © Beomjun Shin, October 31, 2017
Fully Convolutional? © Beomjun Shin, October 31, 2017
Identity Mappings in Deep Residual Networks (2016) Improved ResNet block
design from creators of ResNet © Beomjun Shin, October 31, 2017
Identity Mappings in Deep Residual Networks: [BN-RELU-CONV] © Beomjun Shin,
October 31, 2017
Identity Mappings in Deep Residual Networks: [BN-RELU-CONV] • Two Identity
Mappings: Remove RELU after addition & Identity skip-connection • View BN-RELU as "pre-activation" for convolution layer (not post-activation) ! • ensures that information is directly propagated back to any shallower unit © Beomjun Shin, October 31, 2017
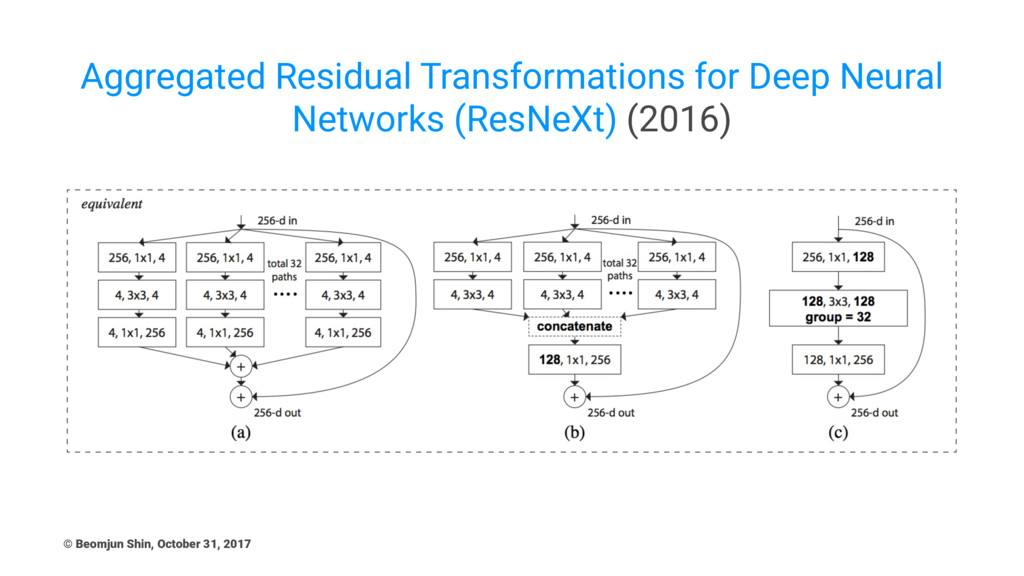
Aggregated Residual Transformations for Deep Neural Networks (ResNeXt) (2016) ©
Beomjun Shin, October 31, 2017
Main Points • Homogeneous design with Multi-branch architecture SeNet •
Inception module has a structure similar to Figure (b) • Figure (c) can be seen as AlexNet's group convolution Thoughts about ResNext • grouped convolution (channel information) & multi-branch (spatial information) revisited and reutilized © Beomjun Shin, October 31, 2017
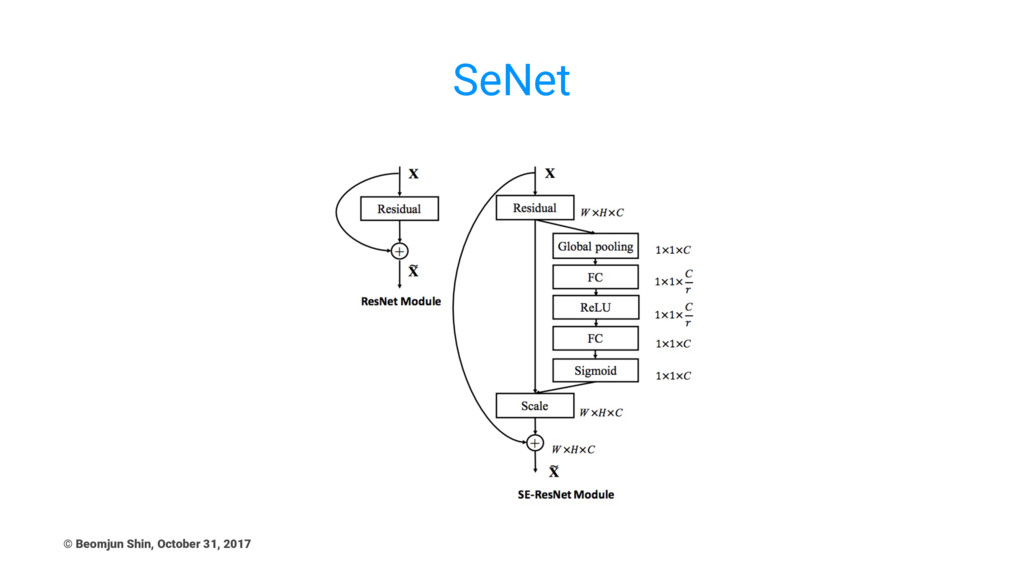
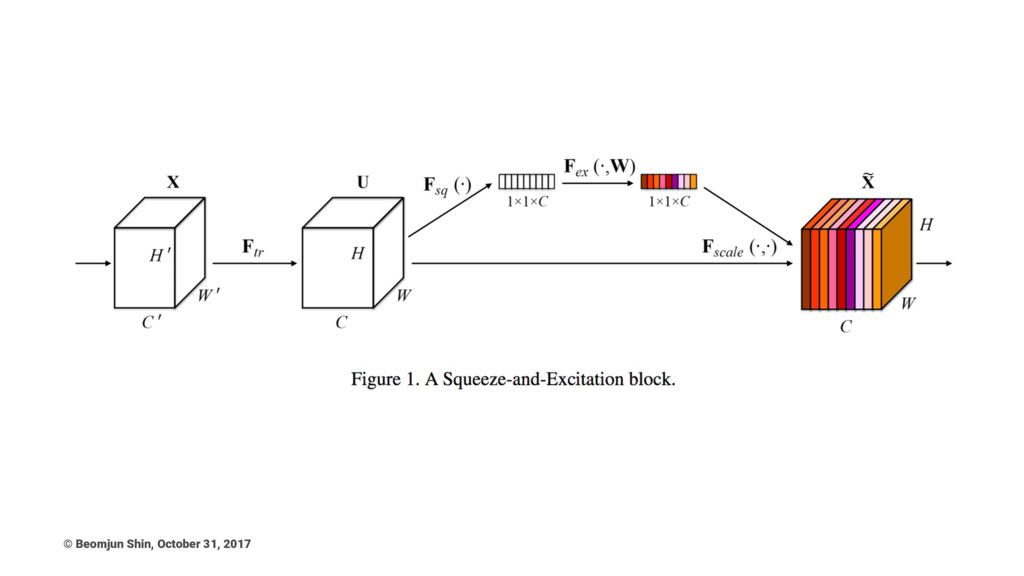
SeNet © Beomjun Shin, October 31, 2017
© Beomjun Shin, October 31, 2017
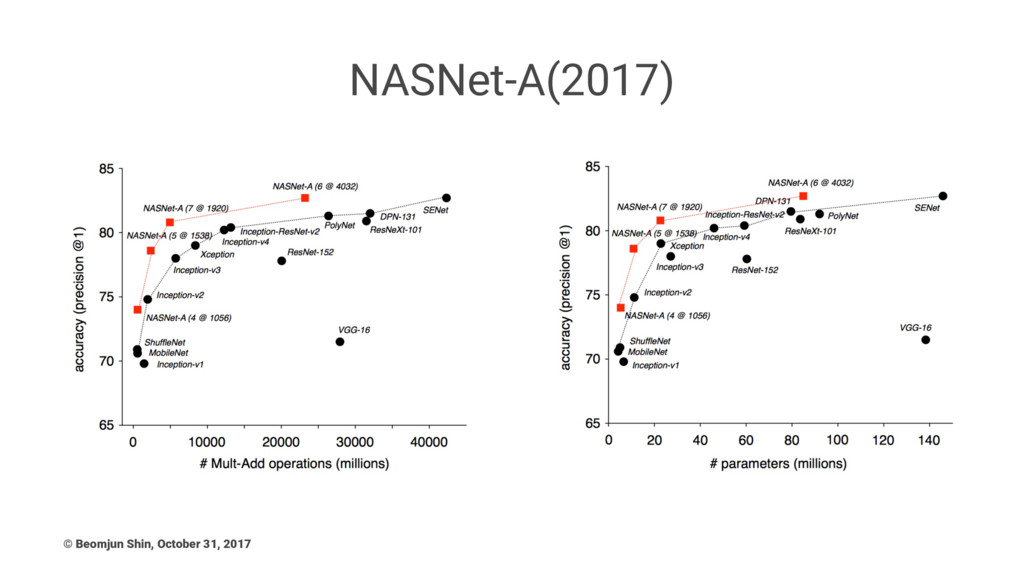
NASNet-A(2017) © Beomjun Shin, October 31, 2017
Summary 1. LeNet: [CONV-POOL-CONV-POOL-FC-FC] (5 layers) 2. AlexNet: [CONV*M-MAXPOOL]*N-FC*M-SOFTMAX (8
layers) 3. VGG: [CONV-CONV-MAXPOOL]*N-FC*M-SOFTMAX (19 layers) 4. GoogleNet: ?!?! 5. ResnetV2, ResNext: [BN-RELU-CONV]*M (152 layers) 6. DenseNet: [BN-RELU-CONV]*CONCAT! 7. ...! © Beomjun Shin, October 31, 2017
A few network design tips taken from history • Increase
depth as much as possible: Identity-based skip connection • Utilize spatial & channel information as much as possible • Use homogeneous design and focus on core factor • Ensure the same computational complexity in terms of FLOPs for all blocks (two rules) • Ends with global average pooling instead of fully connected layer • Early downsampling, but we should preserve enough spatial information © Beomjun Shin, October 31, 2017
Segmentation © Beomjun Shin, October 31, 2017
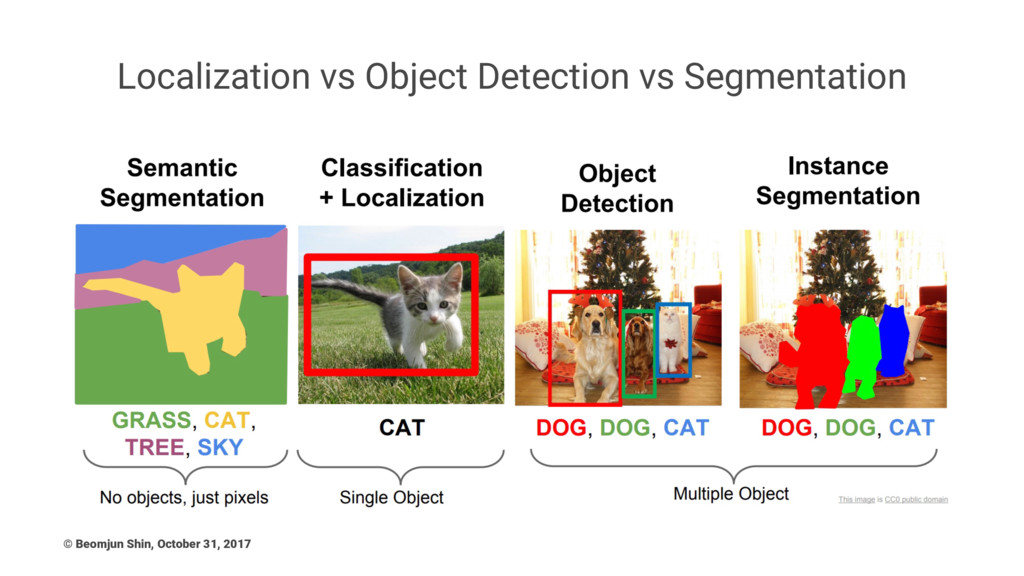
Localization vs Object Detection vs Segmentation © Beomjun Shin, October
31, 2017
Preliminary: convolution arithmetic © Beomjun Shin, October 31, 2017
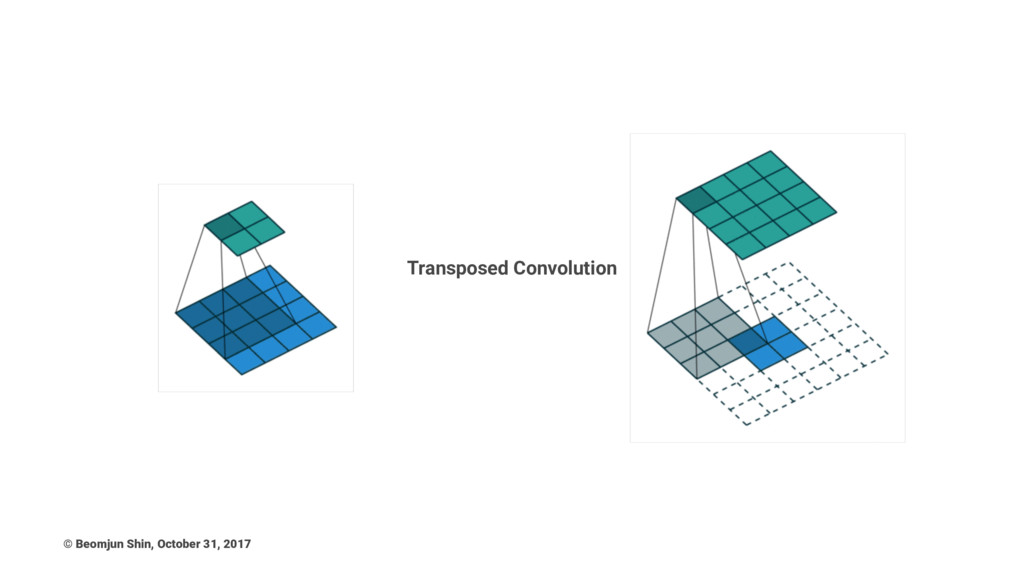
Transposed Convolution © Beomjun Shin, October 31, 2017
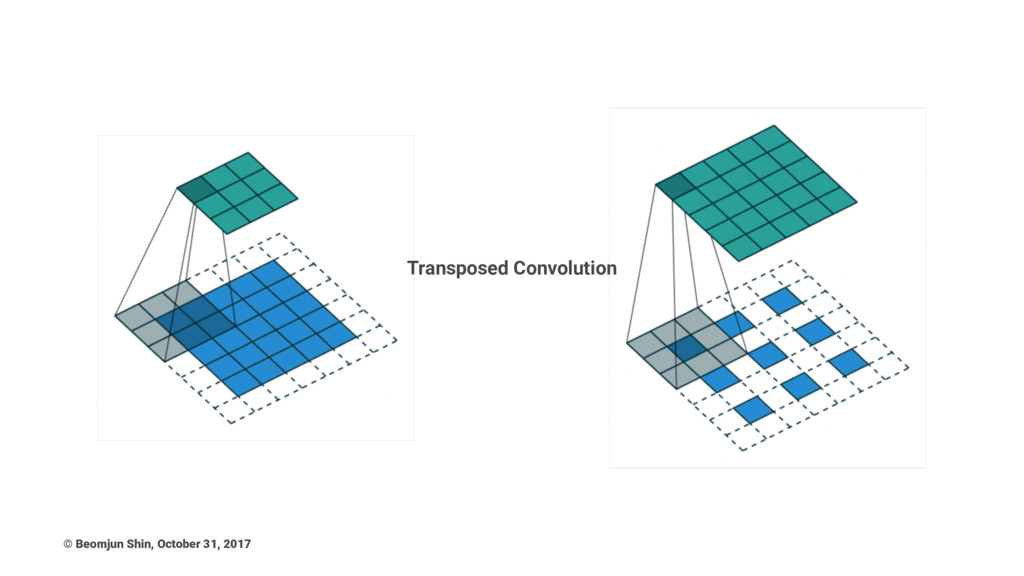
Transposed Convolution © Beomjun Shin, October 31, 2017
Transposed Convolution • Deconvolution • Upconvolution • Fractionally strided convolution
• Backward strided convolution © Beomjun Shin, October 31, 2017
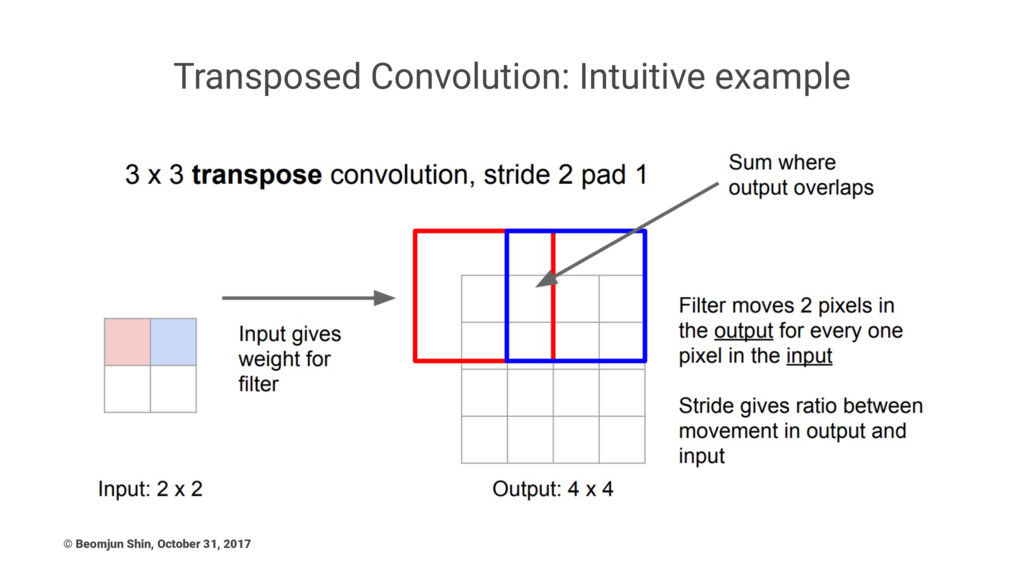
Transposed Convolution: Intuitive example © Beomjun Shin, October 31, 2017
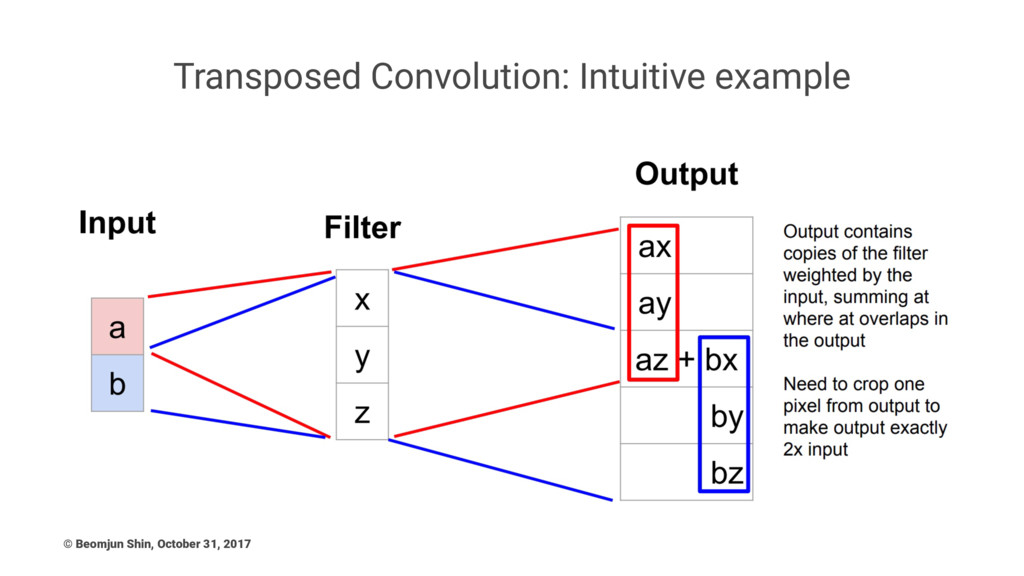
Transposed Convolution: Intuitive example © Beomjun Shin, October 31, 2017
Transposed Convolution: Intuitive example © Beomjun Shin, October 31, 2017
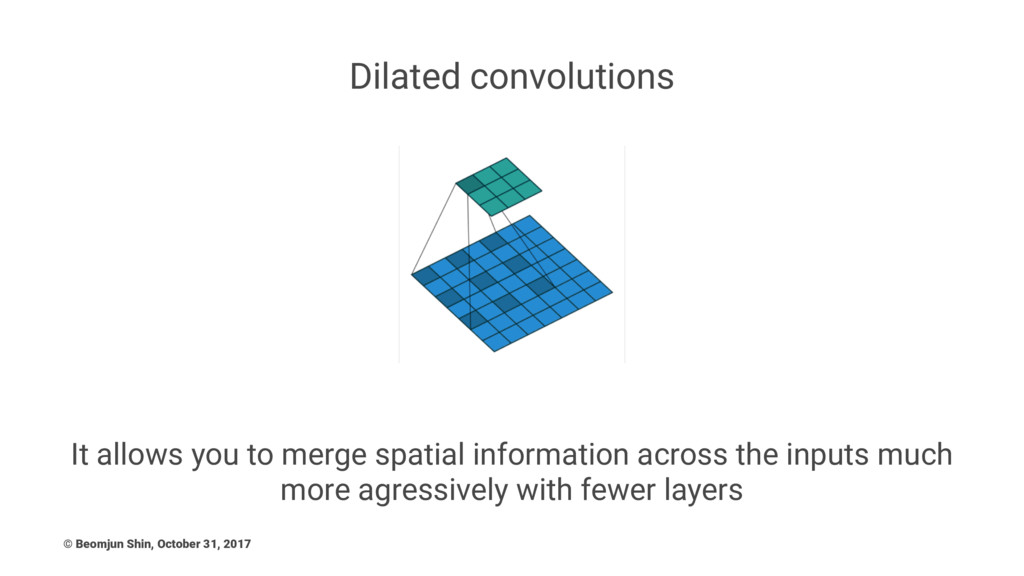
Dilated convolutions It allows you to merge spatial information across
the inputs much more agressively with fewer layers © Beomjun Shin, October 31, 2017
The simplest way to think about a transposed convolution is
by computing the output shape of the direct convolution for a given input shape first, and then inverting the input and output shapes for the transposed convolution. Note that transposed convolution can be emulated as a normal convolution via inserting zeroes between the input. (Keep in mind this is distinct from the atrous/dilated convolution where zeroes are inserted in the filters) © Beomjun Shin, October 31, 2017
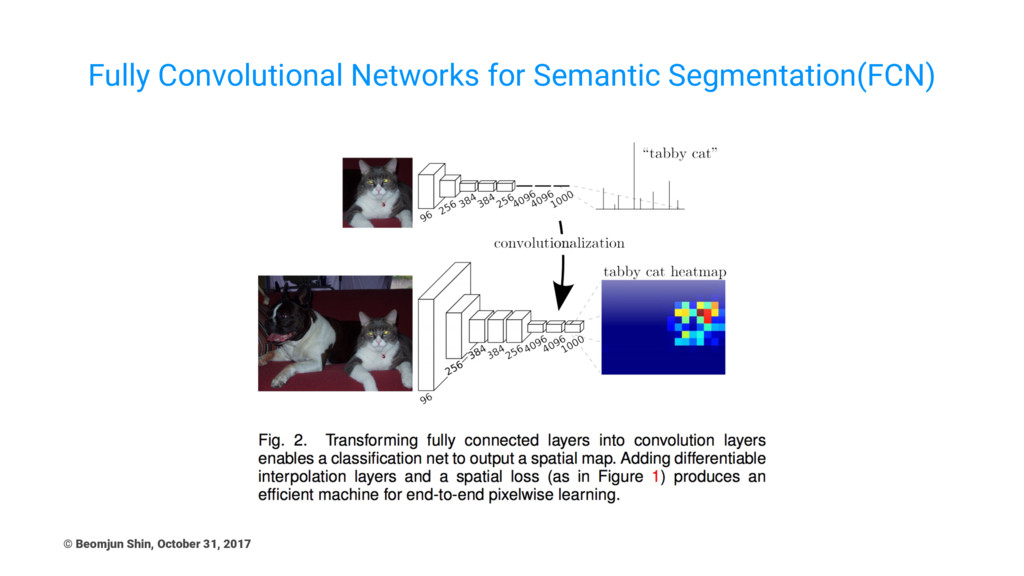
Fully Convolutional Networks for Semantic Segmentation(FCN) © Beomjun Shin, October
31, 2017
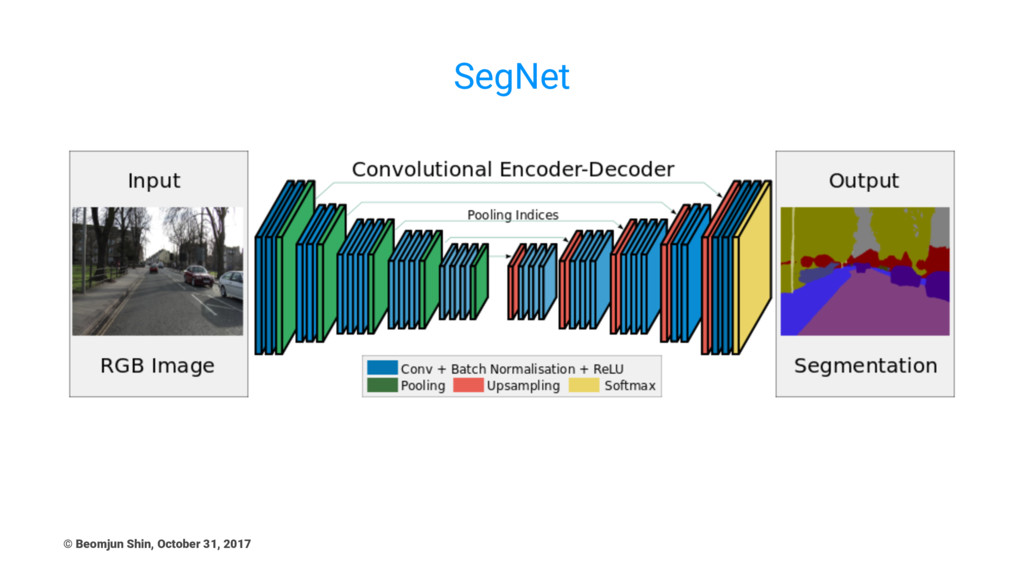
SegNet © Beomjun Shin, October 31, 2017
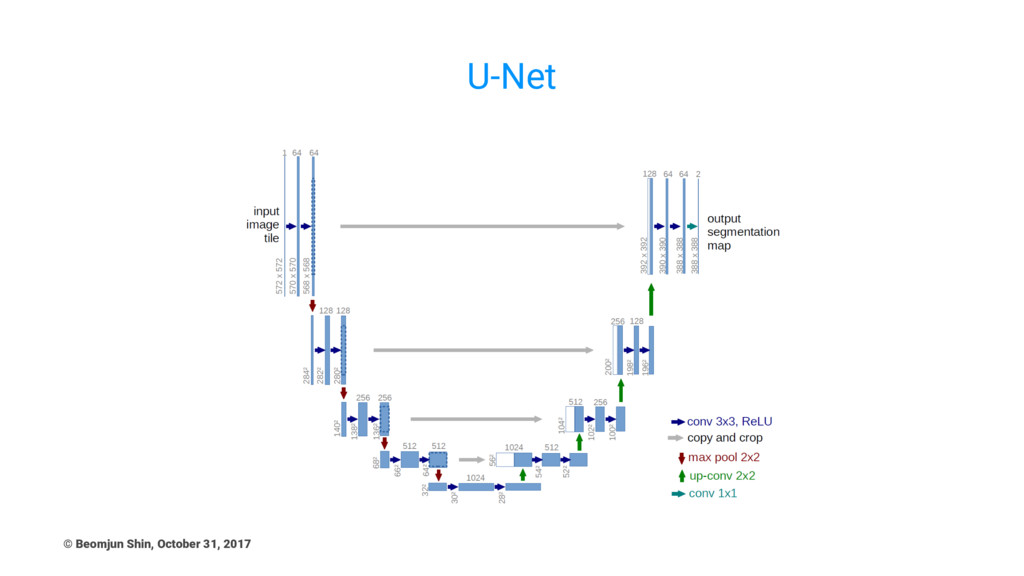
U-Net © Beomjun Shin, October 31, 2017
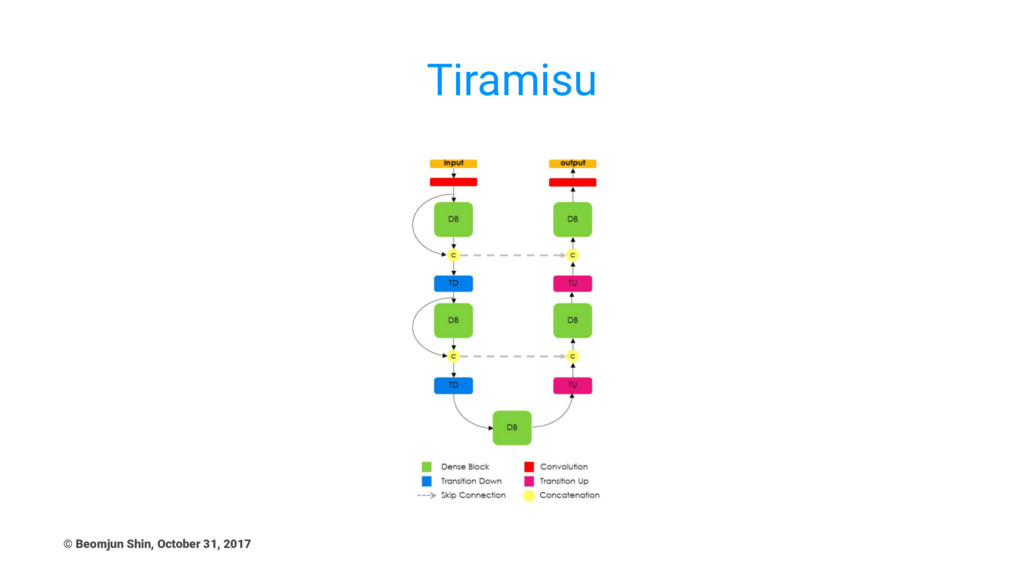
Tiramisu © Beomjun Shin, October 31, 2017
E-Net, Link-Net Good heuristics for designing segmentation networks © Beomjun
Shin, October 31, 2017
Design choices from E-Net and LinkNet • Low resolution but
bigger receptive field needed dilated convolutions • Early Downsampling, increasing from 16 -> 32 doesn't improve accuracy • Large Encoder and a small decoder • PReLU > RELU • Information-preserving dimensionality changes (same as VGG) • Factorizing filters (same as Inception) • Dilated convolutions for wide receptive field • (LinkNet) Aggressive dimenstion reduction before convolution transpose © Beomjun Shin, October 31, 2017
Recent papers about segmentation.. • 2017, Mask R-CNN • CVPR
2017, PSPNet: Pyramid Scene Parsing Network • CVPR 2017, RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation • CVPR 2017, G-FRNet: Gated Feedback Refinement Network for Dense Image Labeling © Beomjun Shin, October 31, 2017
References CNN Architectures • CS231n-2017-Lecture9 • The 9 Deep Learning
Papers You Need To Know About • What I learned from competing against a ConvNet on ImageNet(2014) • https://adeshpande3.github.io/adeshpande3.github.io/The-9- Deep-Learning-Papers-You-Need-To-Know-About.html © Beomjun Shin, October 31, 2017
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Identity Mappings in Deep Residual Networks: [BN-RELU-CONV] © Beomjun Shin,](https://files.speakerdeck.com/presentations/1aba87cad84042c2a33355ccff919587/slide_27.jpg){kind=link}
![Identity Mappings in Deep Residual Networks: [BN-RELU-CONV] • Two Identity](https://files.speakerdeck.com/presentations/1aba87cad84042c2a33355ccff919587/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Summary 1. LeNet: [CONV-POOL-CONV-POOL-FC-FC] (5 layers) 2. AlexNet: [CONV*M-MAXPOOL]*N-FC*M-SOFTMAX (8](https://files.speakerdeck.com/presentations/1aba87cad84042c2a33355ccff919587/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}