言語処理学会第27回年次大会 招待論文 発表スライド(2021年3月18日)
Presented in the invited paper session at the 27th Annual Meeting of the Association for Natural Language Processing on March 18, 2021.
Sumita1, Masao Ideuchi1,2, Yoshiaki Oida3, Yohei Sakamoto4, Isaac Okada3, Yuji Matsumoto5 1:NICT, 2:NAIST, 3:Fujitsu, 4:Redgelinez, 5:RIKEN NLP2021, Invited Paper The paper is available at https://www.jstage.jst.go.jp/article/jnlp/27/3/27_499/_article/-char/en
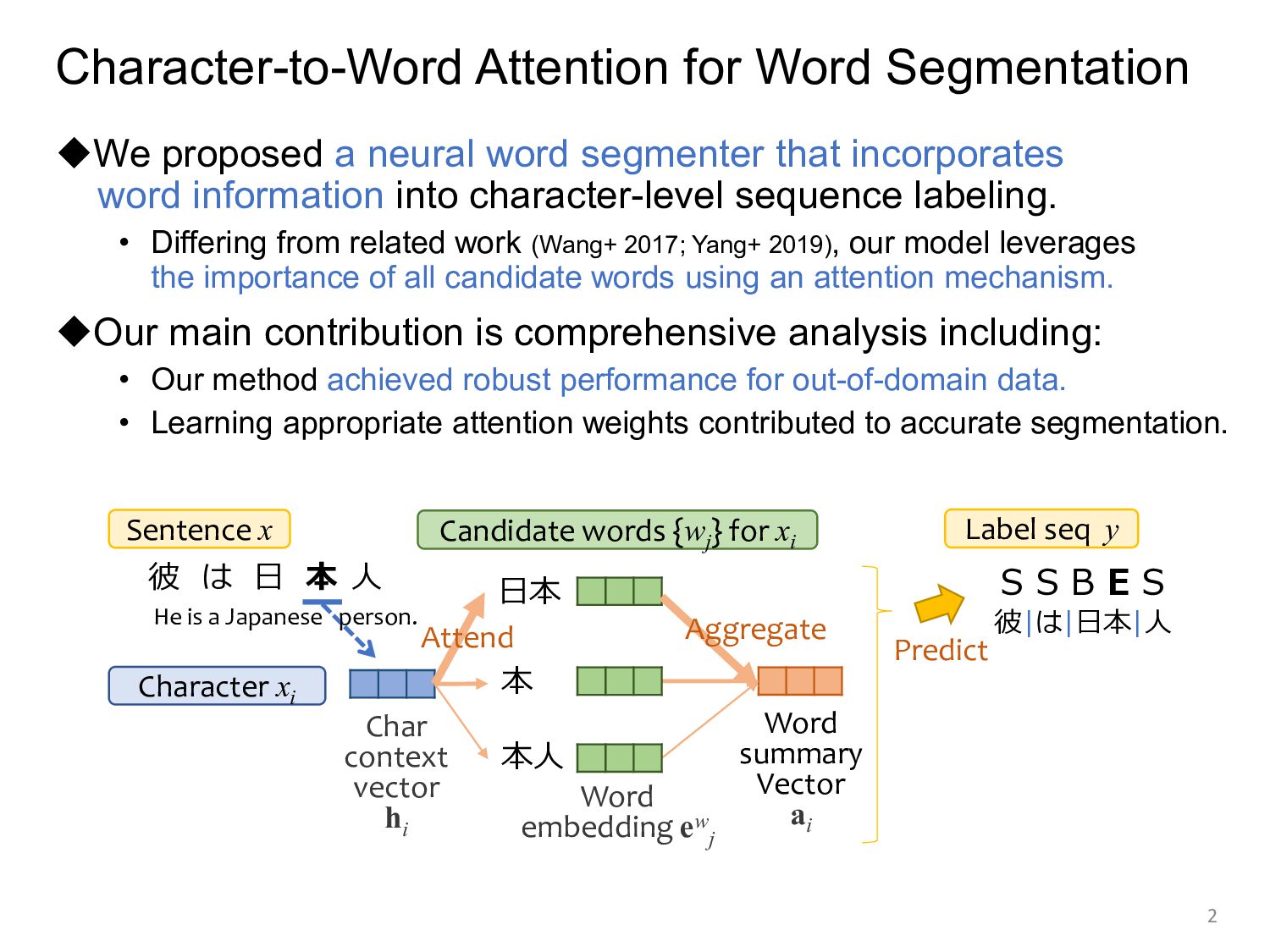
segmenter that incorporates word information into character-level sequence labeling. • Differing from related work (Wang+ 2017; Yang+ 2019), our model leverages the importance of all candidate words using an attention mechanism. ◆Our main contribution is comprehensive analysis including: • Our method achieved robust performance for out-of-domain data. • Learning appropriate attention weights contributed to accurate segmentation. 2 日本 本 本人 Character xi Candidate words {wj } for xi Char context vector hi Word summary Vector ai 彼 は 日 本 人 Sentence x Word embedding ew j Aggregate Attend He is a Japanese person. SSBES Label seq y Predict 彼|は|日本|人
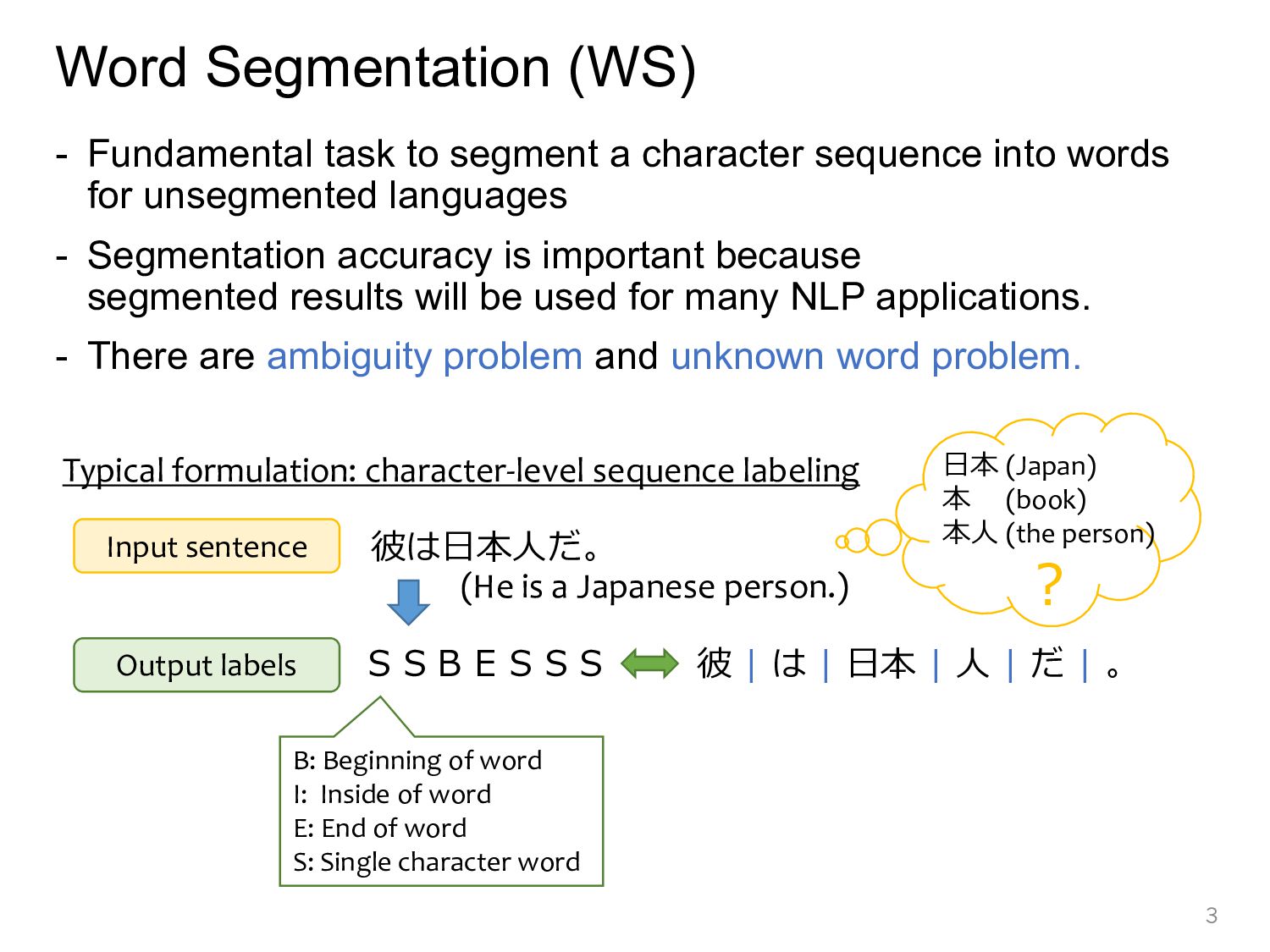
sequence into words for unsegmented languages - Segmentation accuracy is important because segmented results will be used for many NLP applications. - There are ambiguity problem and unknown word problem. 3 彼は日本人だ。 彼 | は | 日本 | 人 | だ | 。 SSBESSS Input sentence Output labels B: Beginning of word I: Inside of word E: End of word S: Single character word (He is a Japanese person.) Typical formulation: character-level sequence labeling 日本 (Japan) 本 (book) 本人 (the person) ?
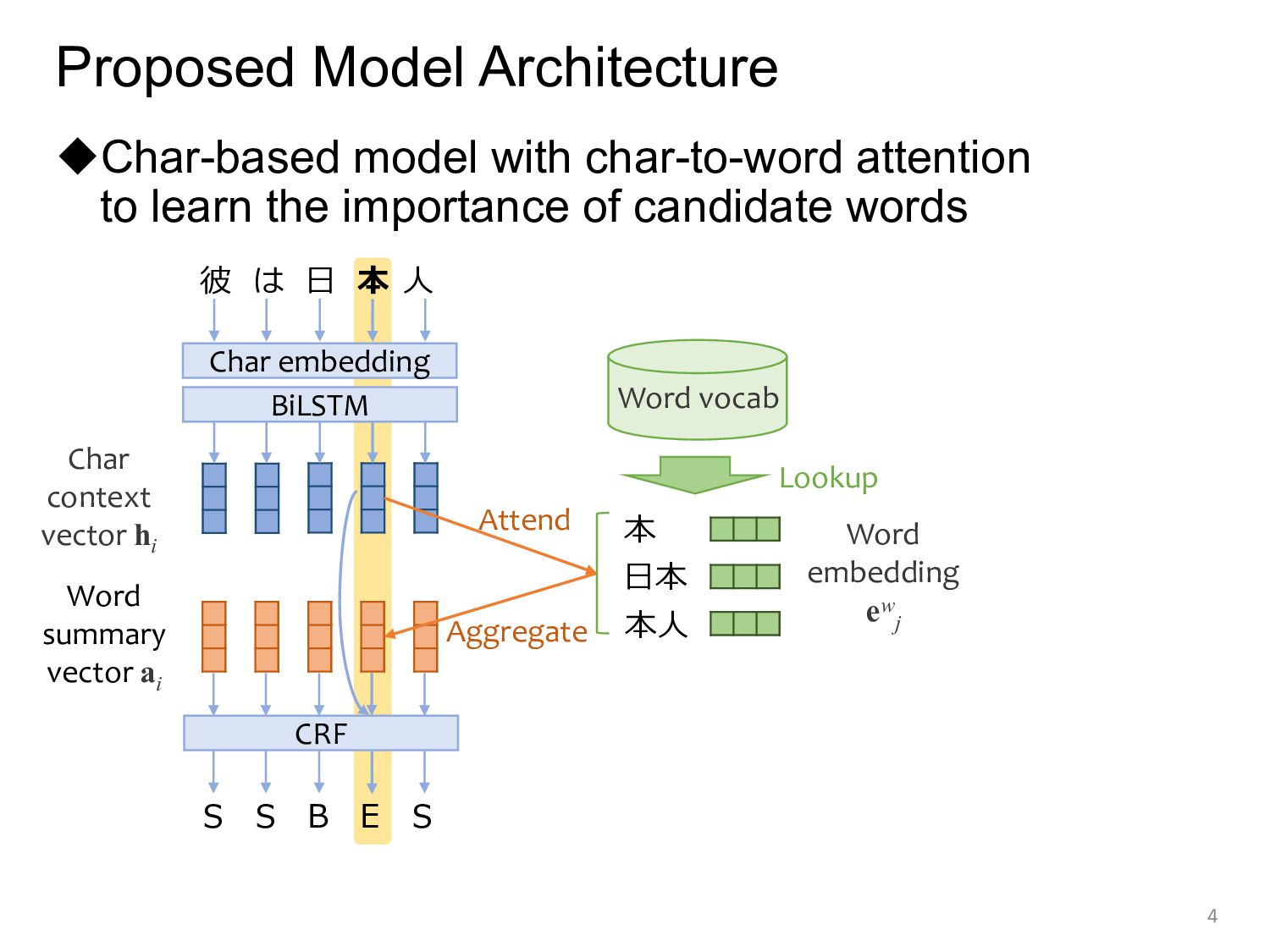
the importance of candidate words 4 本 日本 本人 S S B E S BiLSTM CRF Char context vector hi Word embedding ew j Word summary vector ai Attend Aggregate Word vocab Char embedding 彼 は 日 本 人 Lookup
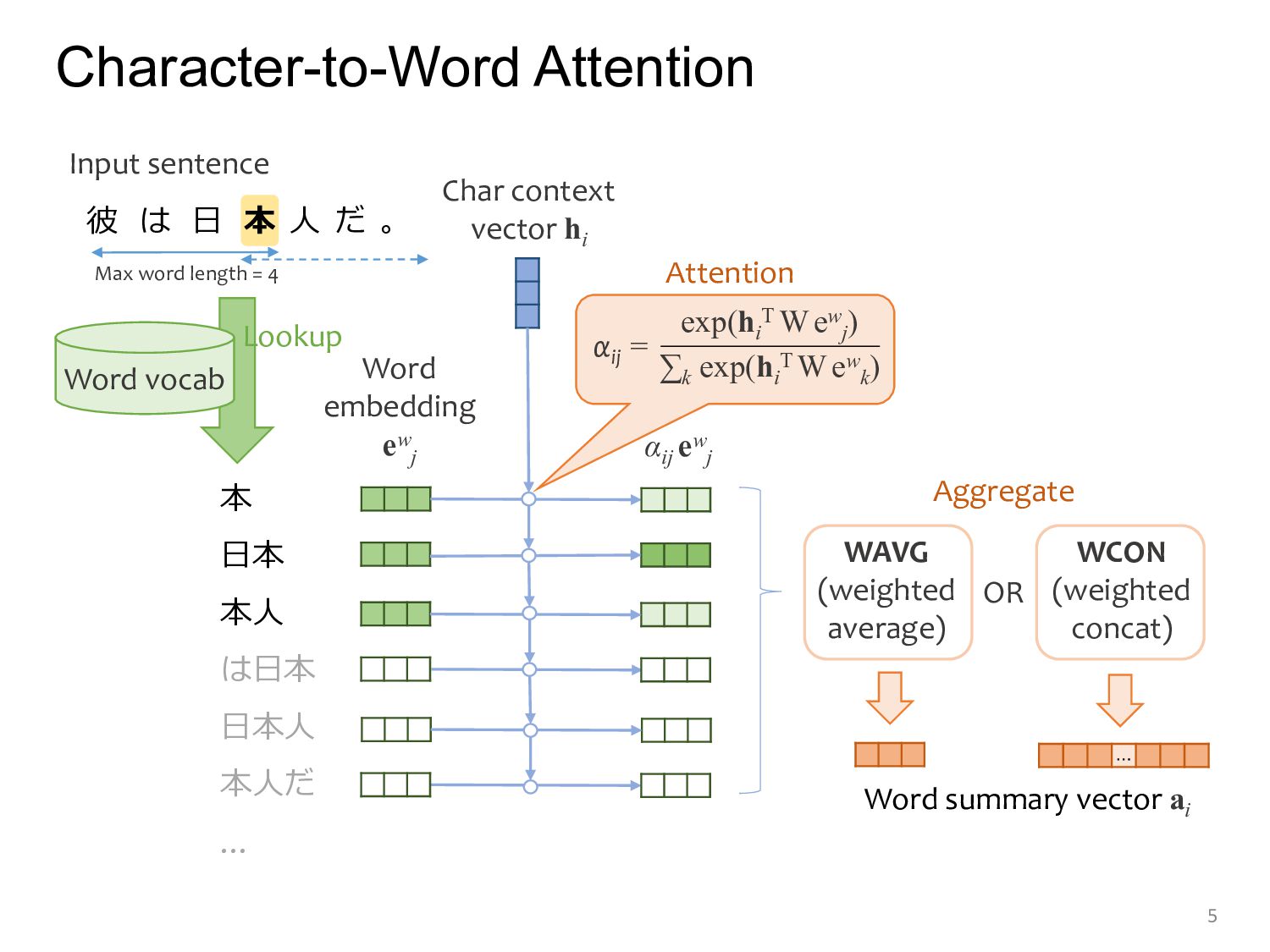
Word embedding ew j Word vocab 彼 は 日 本 人 だ 。 Char context vector hi αij ew j exp(hi T Wew j ) ∑k exp(hi T Wew k ) αij = Input sentence Lookup Attention Max word length = 4 WAVG (weighted average) WCON (weighted concat) OR Aggregate … Word summary vector ai
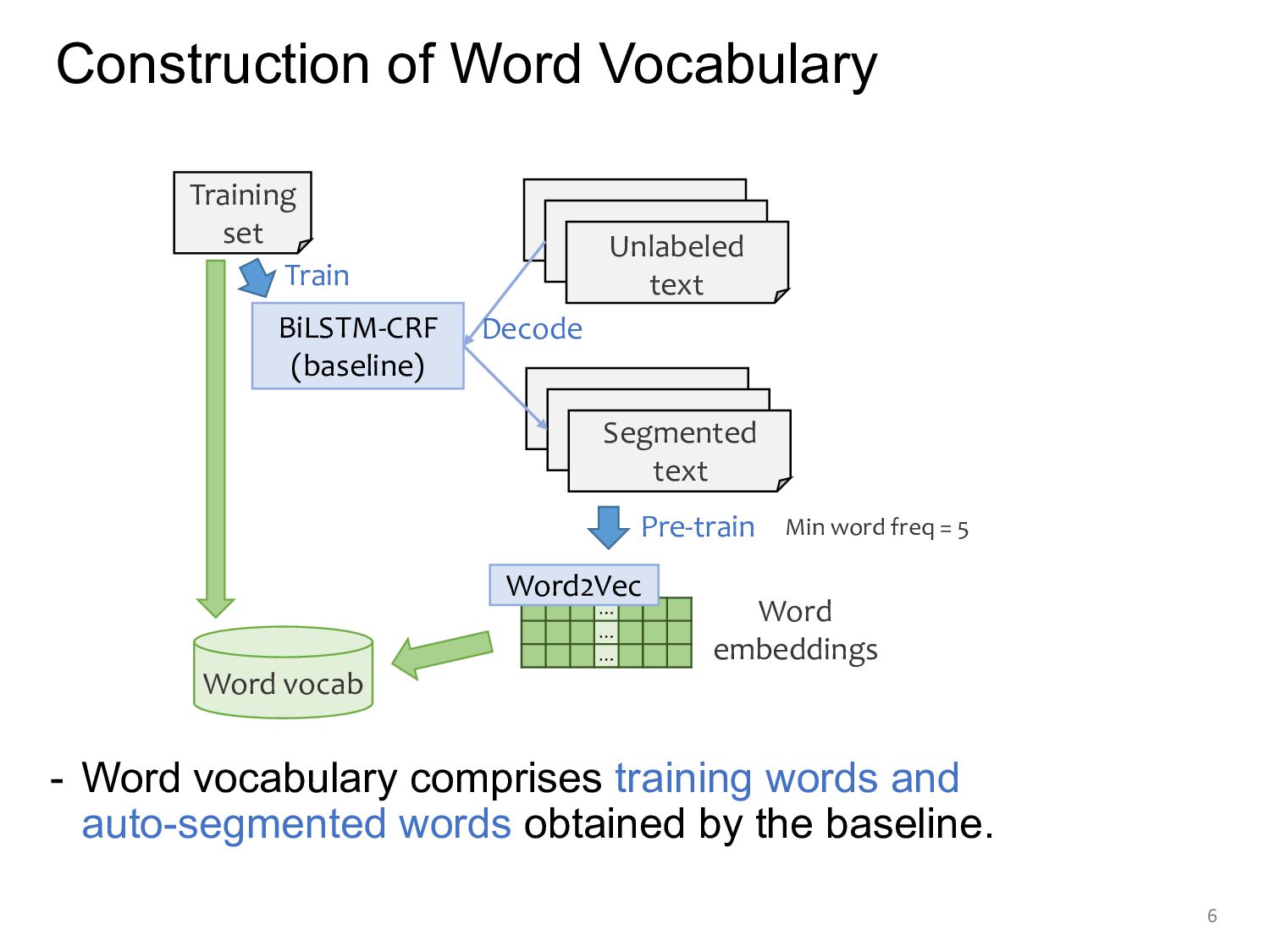
set Unlabeled text Segmented text Train Decode … … … Word embeddings Word2Vec Pre-train Min word freq = 5 - Word vocabulary comprises training words and auto-segmented words obtained by the baseline.
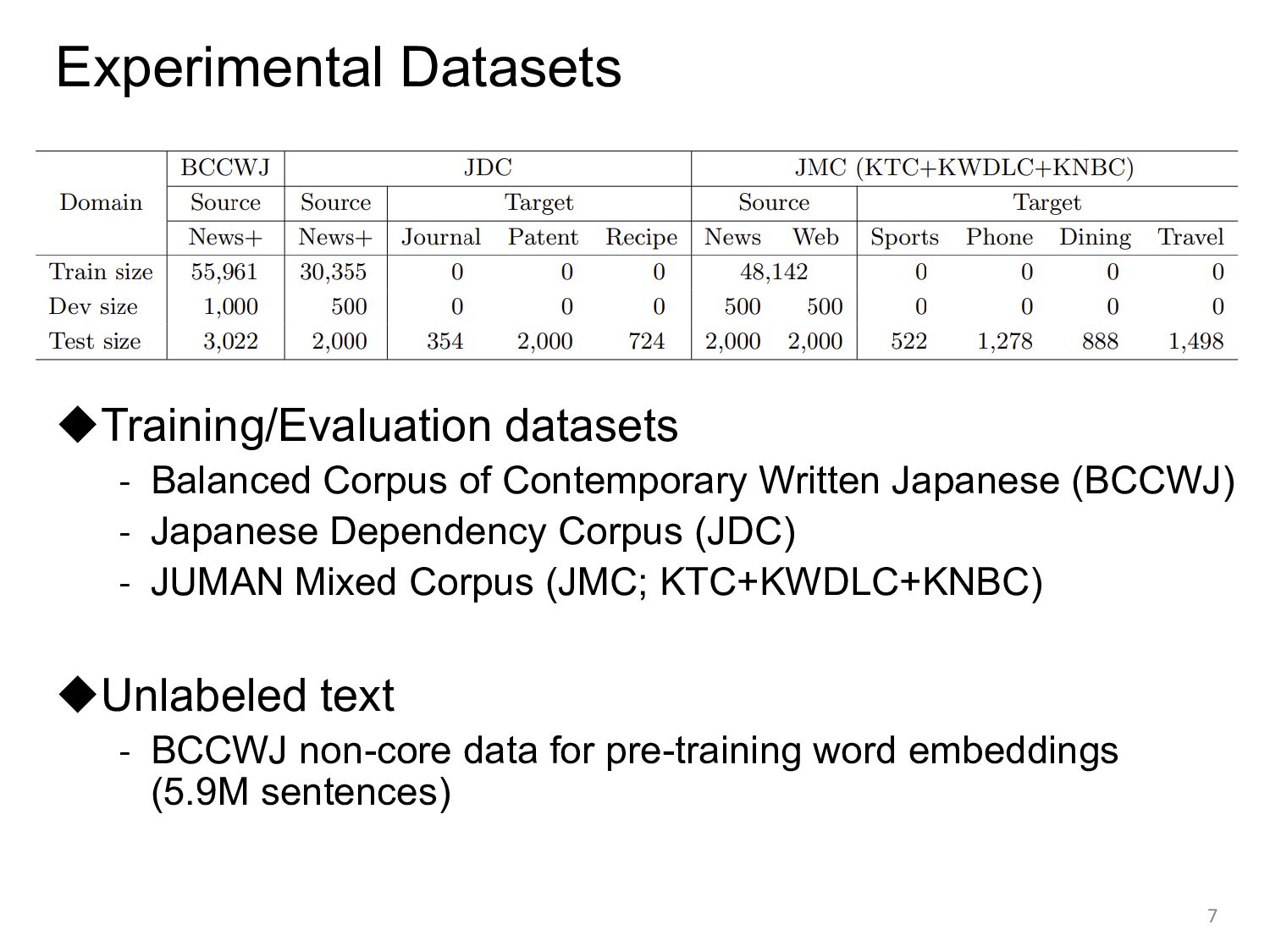
Japanese (BCCWJ) - Japanese Dependency Corpus (JDC) - JUMAN Mixed Corpus (JMC; KTC+KWDLC+KNBC) ◆Unlabeled text - BCCWJ non-core data for pre-training word embeddings (5.9M sentences) 7
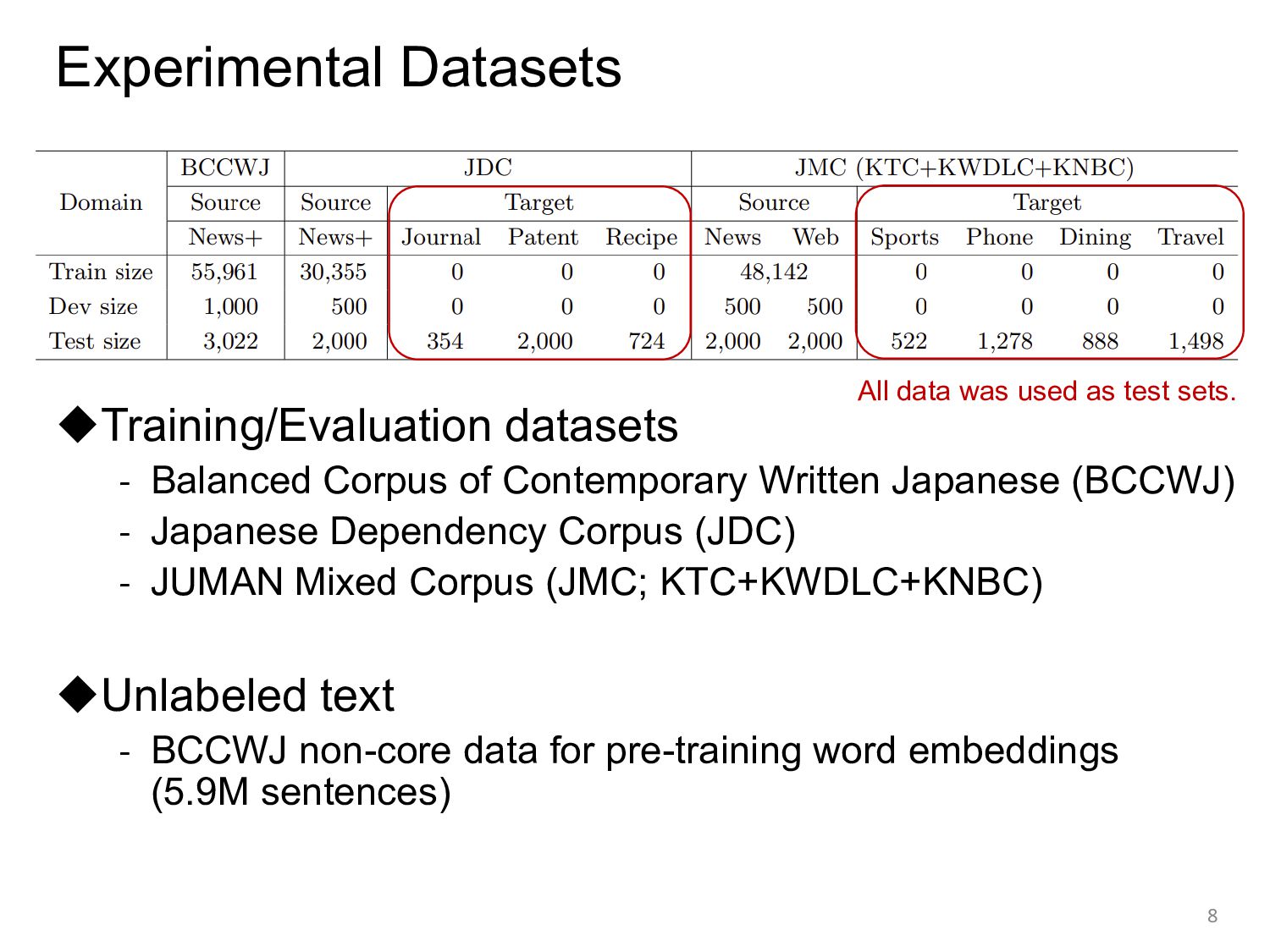
Japanese (BCCWJ) - Japanese Dependency Corpus (JDC) - JUMAN Mixed Corpus (JMC; KTC+KWDLC+KNBC) ◆Unlabeled text - BCCWJ non-core data for pre-training word embeddings (5.9M sentences) 8 All data was used as test sets.
on dev sets. - Hyperparameters • num_BiLSTM_layers=2, num_BiLSTM_units=600, char/word_emb_dim=300, RNN_dropout_rate=0.4, min_word_freq=5, max_word_length=4, etc. ◆Evaluation 1. Comparison of baseline and proposed model variants 2. Comparison with existing methods on in/cross-domain datasets 3. Effect of semi-supervised learning 4. Effect of word frequency and length 5. Effect of attention for segmentation performance 6. Analysis of segmentation examples 7. Effect of additional word embeddings from target domains 9
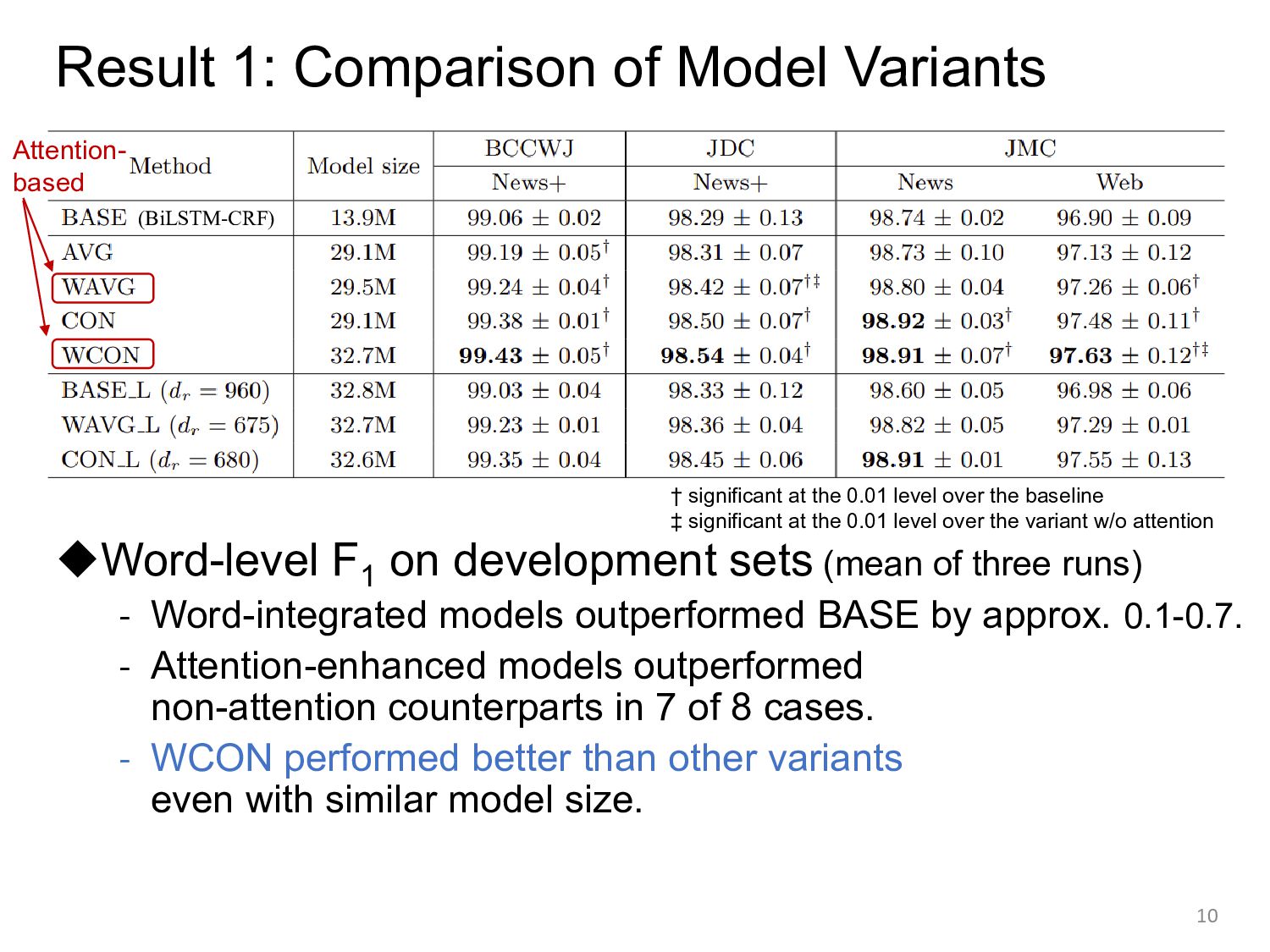
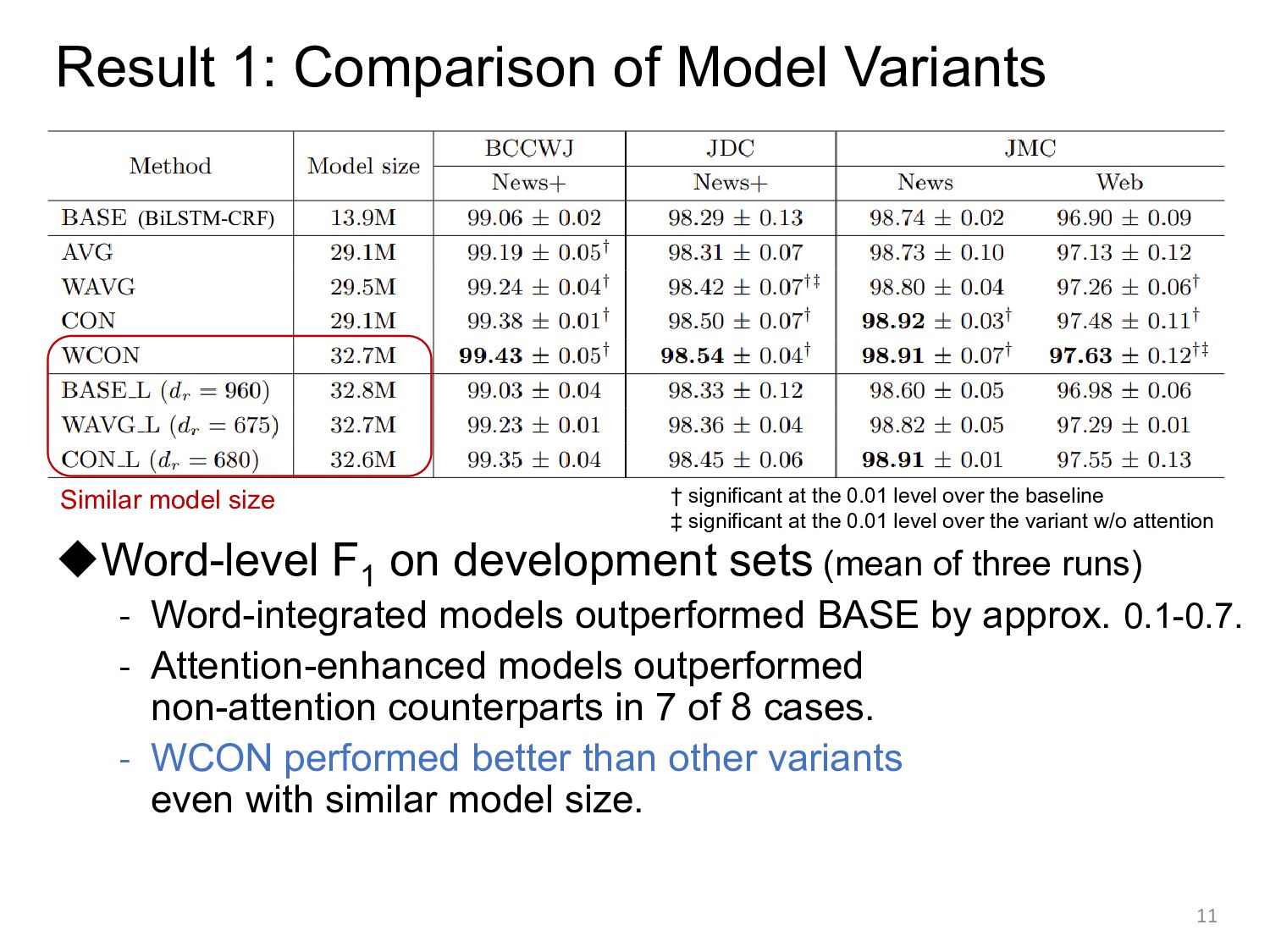
sets (mean of three runs) - Word-integrated models outperformed BASE by approx. 0.1-0.7. - Attention-enhanced models outperformed non-attention counterparts in 7 of 8 cases. - WCON performed better than other variants even with similar model size. 10 (BiLSTM-CRF) † significant at the 0.01 level over the baseline ‡ significant at the 0.01 level over the variant w/o attention Attention- based
sets (mean of three runs) - Word-integrated models outperformed BASE by approx. 0.1-0.7. - Attention-enhanced models outperformed non-attention counterparts in 7 of 8 cases. - WCON performed better than other variants even with similar model size. 11 (BiLSTM-CRF) † significant at the 0.01 level over the baseline ‡ significant at the 0.01 level over the variant w/o attention Similar model size
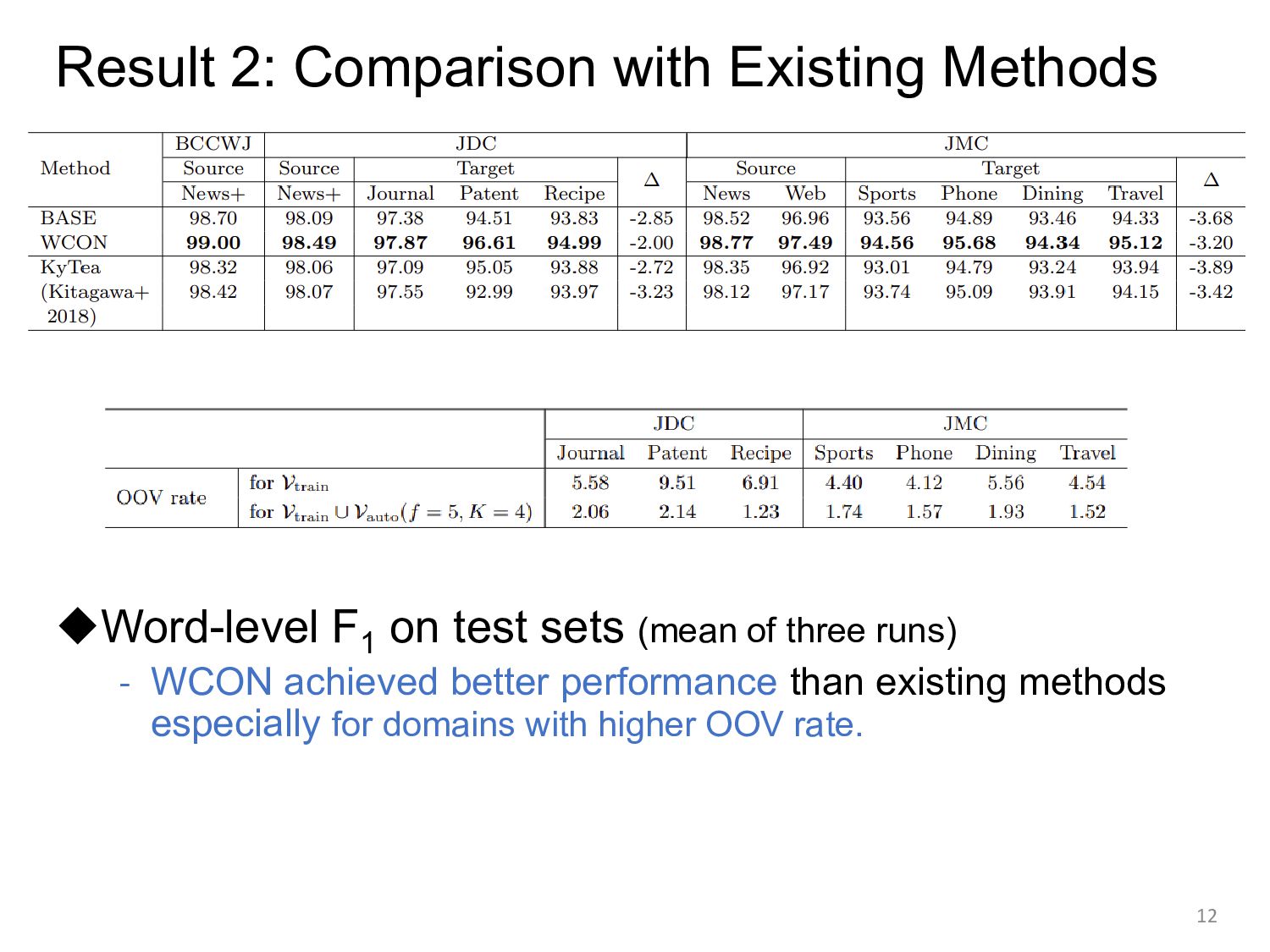
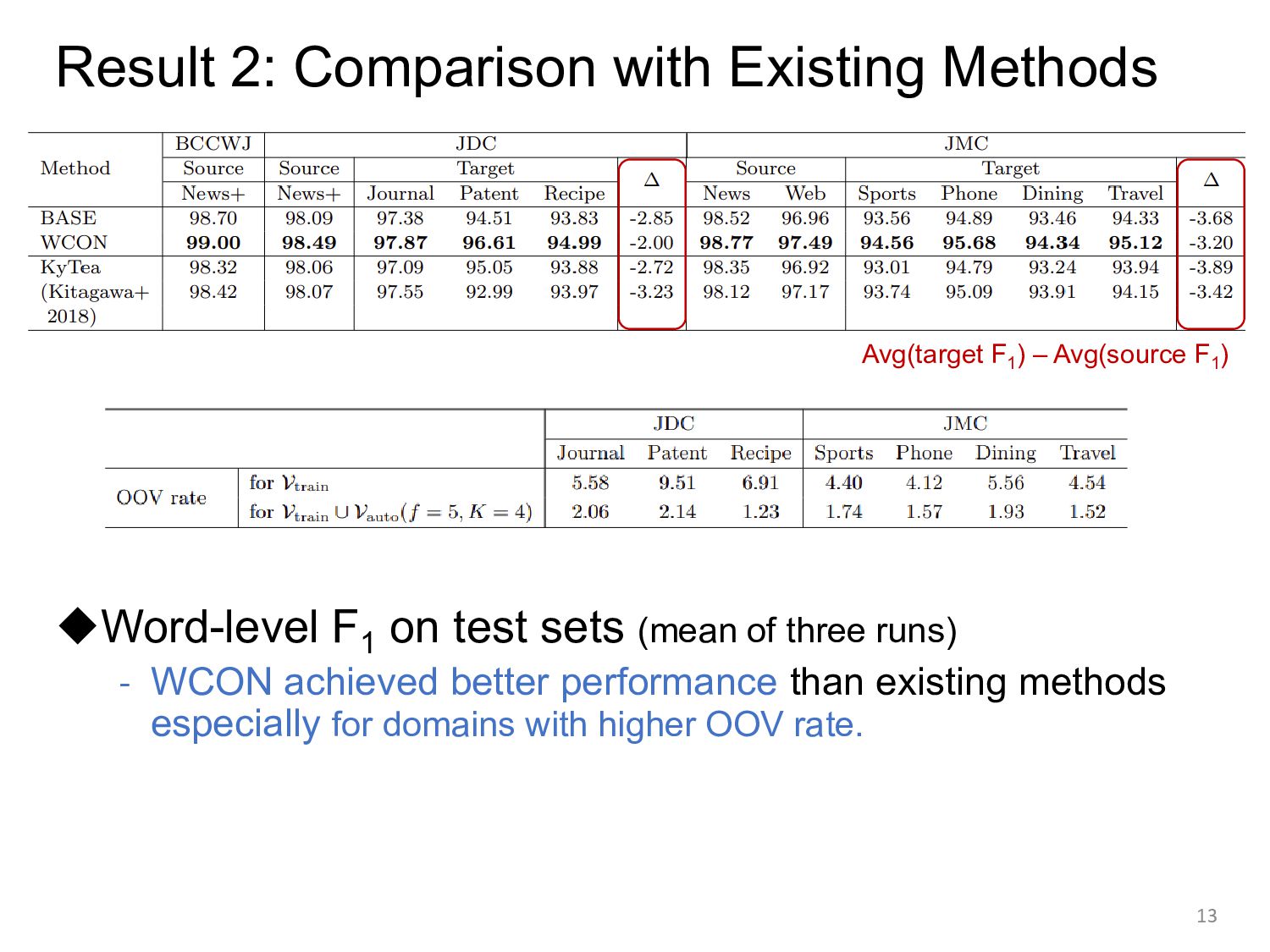
sets (mean of three runs) - WCON achieved better performance than existing methods especially for domains with higher OOV rate. 13 Avg(target F1 ) – Avg(source F1 )
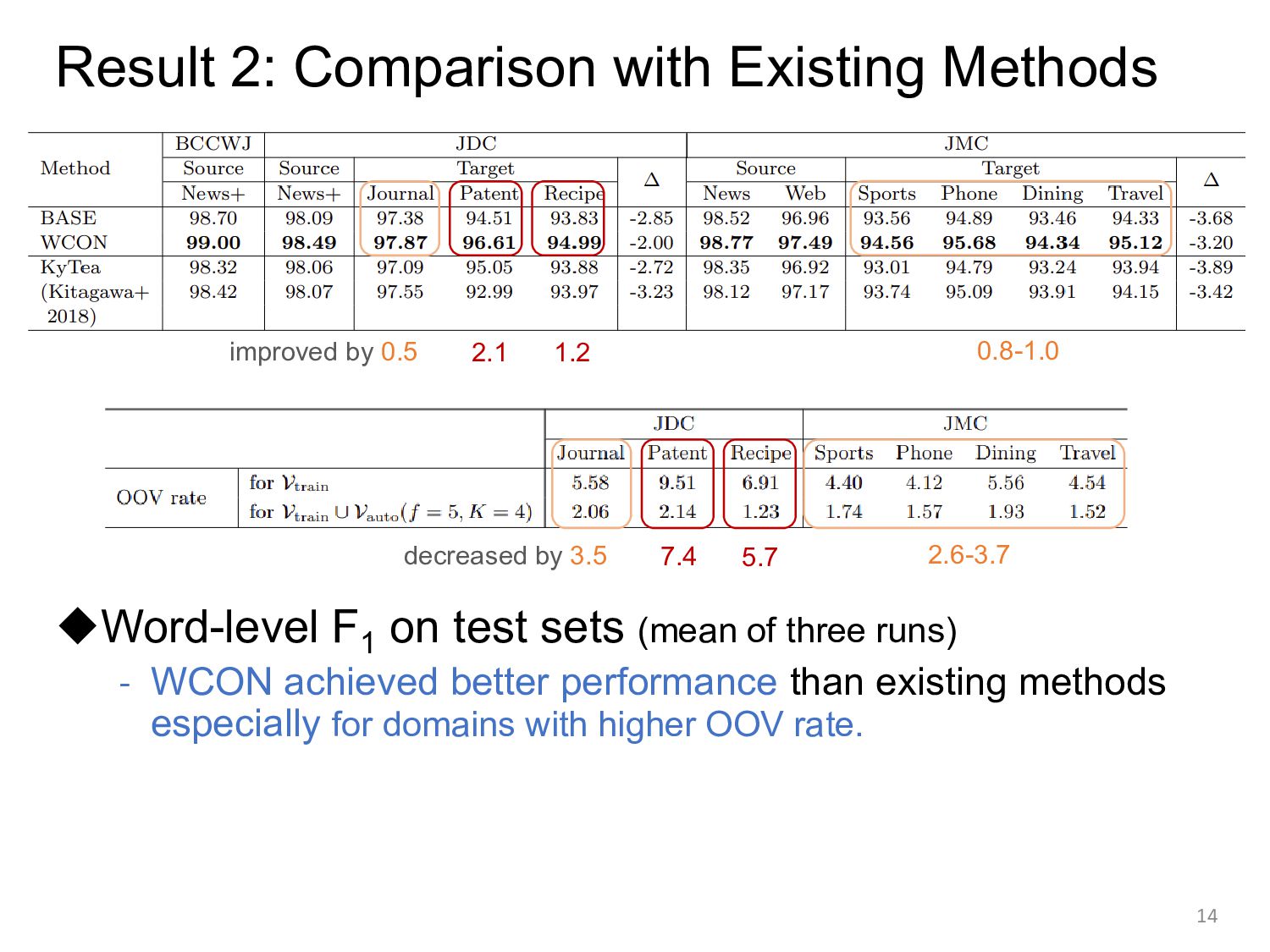
sets (mean of three runs) - WCON achieved better performance than existing methods especially for domains with higher OOV rate. 14 decreased by 3.5 7.4 5.7 2.6-3.7 improved by 0.5 2.1 1.2 0.8-1.0
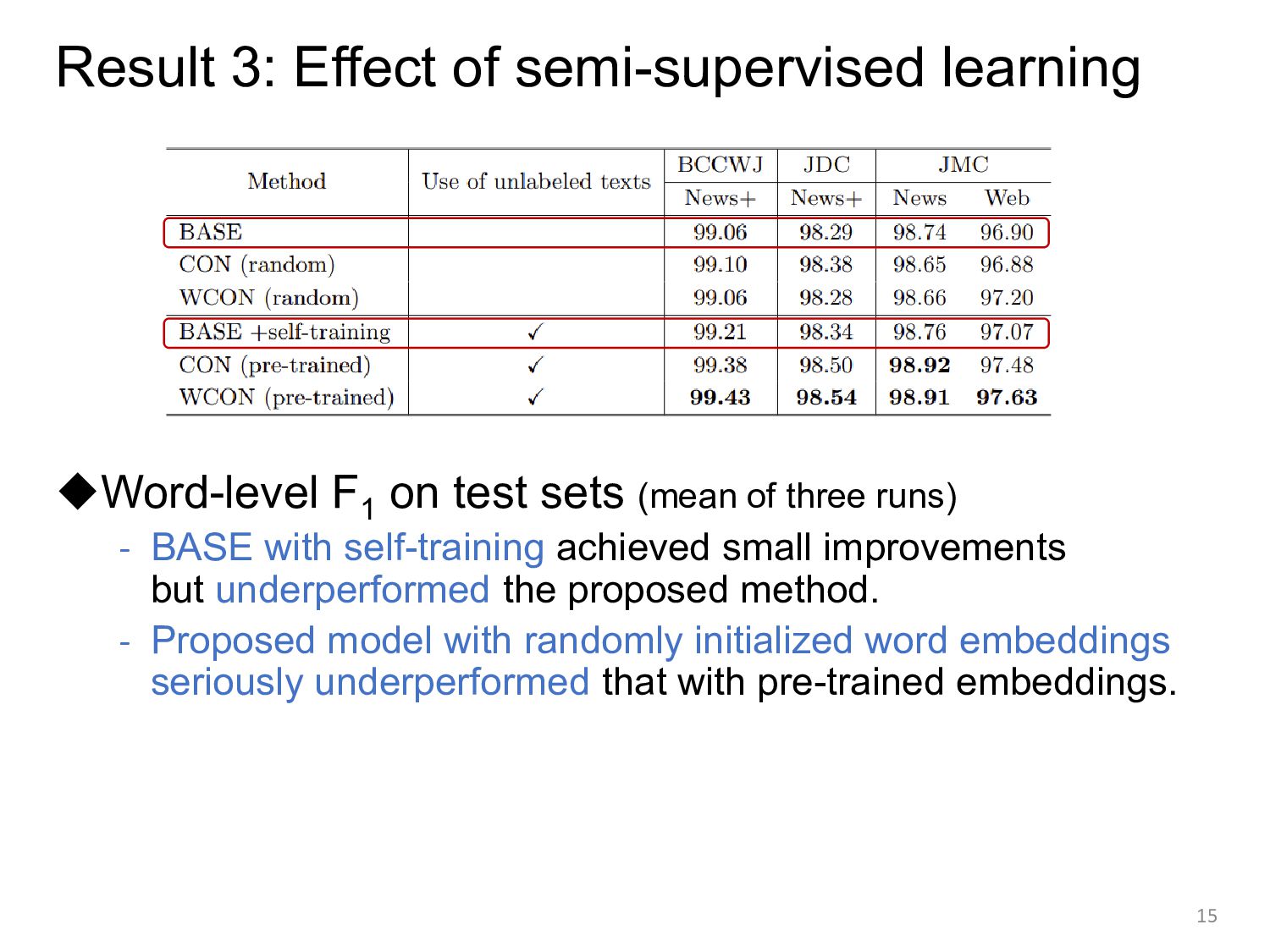
sets (mean of three runs) - BASE with self-training achieved small improvements but underperformed the proposed method. - Proposed model with randomly initialized word embeddings seriously underperformed that with pre-trained embeddings. 15
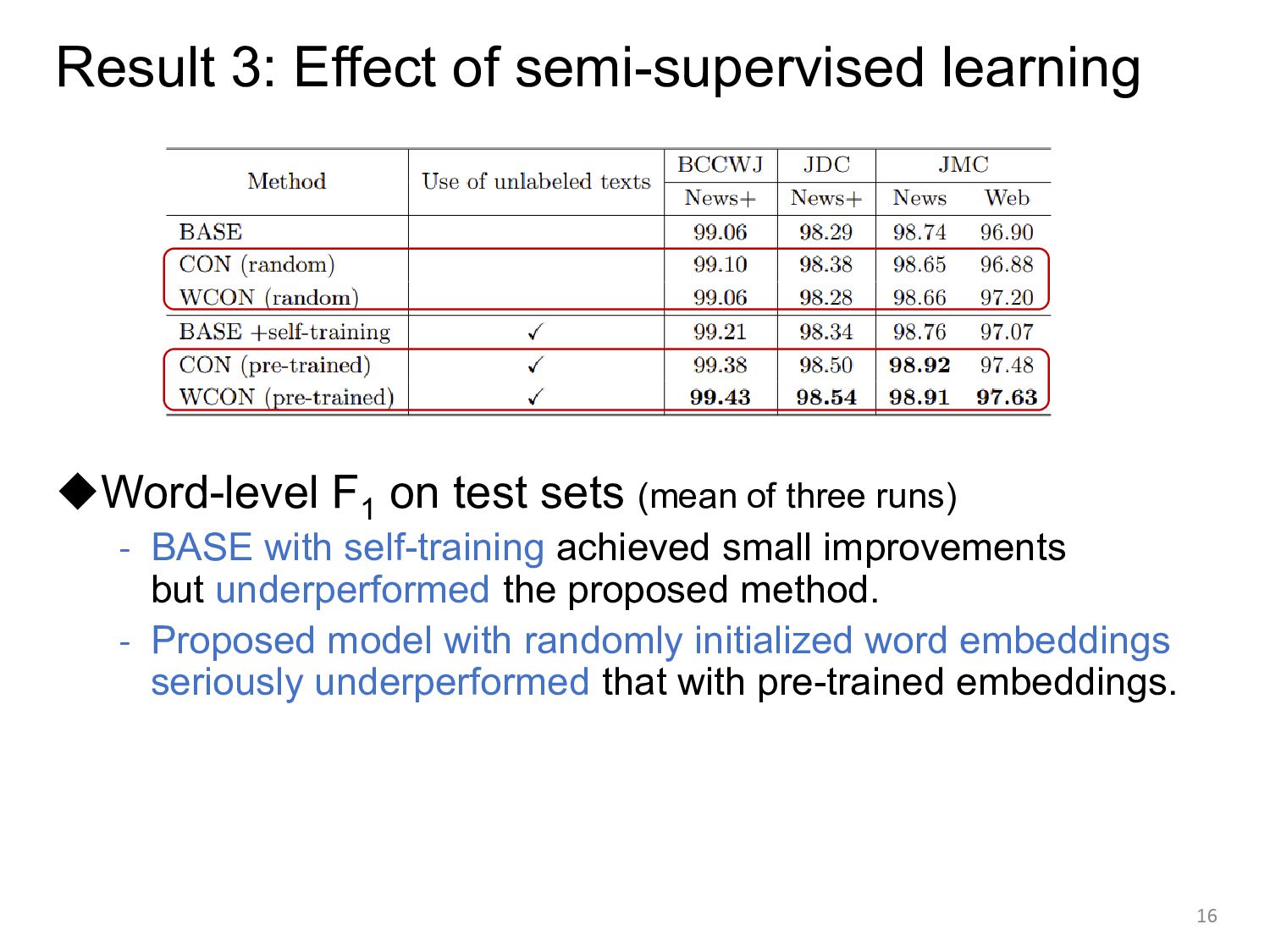
sets (mean of three runs) - BASE with self-training achieved small improvements but underperformed the proposed method. - Proposed model with randomly initialized word embeddings seriously underperformed that with pre-trained embeddings. 16
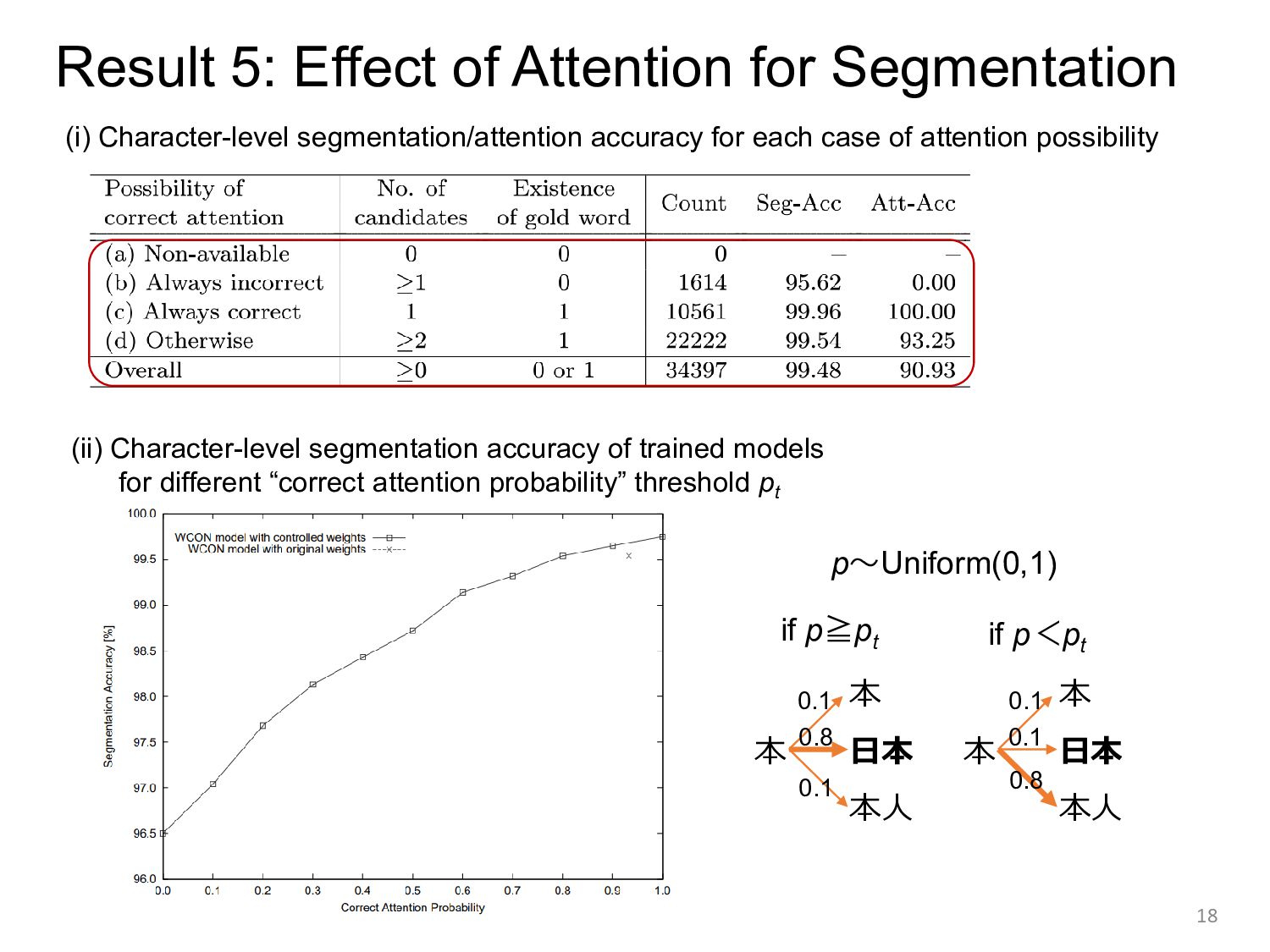
segmentation accuracy of trained models for different “correct attention probability” threshold pt 本 本 日本 本人 本 本 日本 本人 0.1 0.1 0.8 0.1 0.1 0.8 if p≧pt if p<pt p~Uniform(0,1) (i) Character-level segmentation/attention accuracy for each case of attention possibility
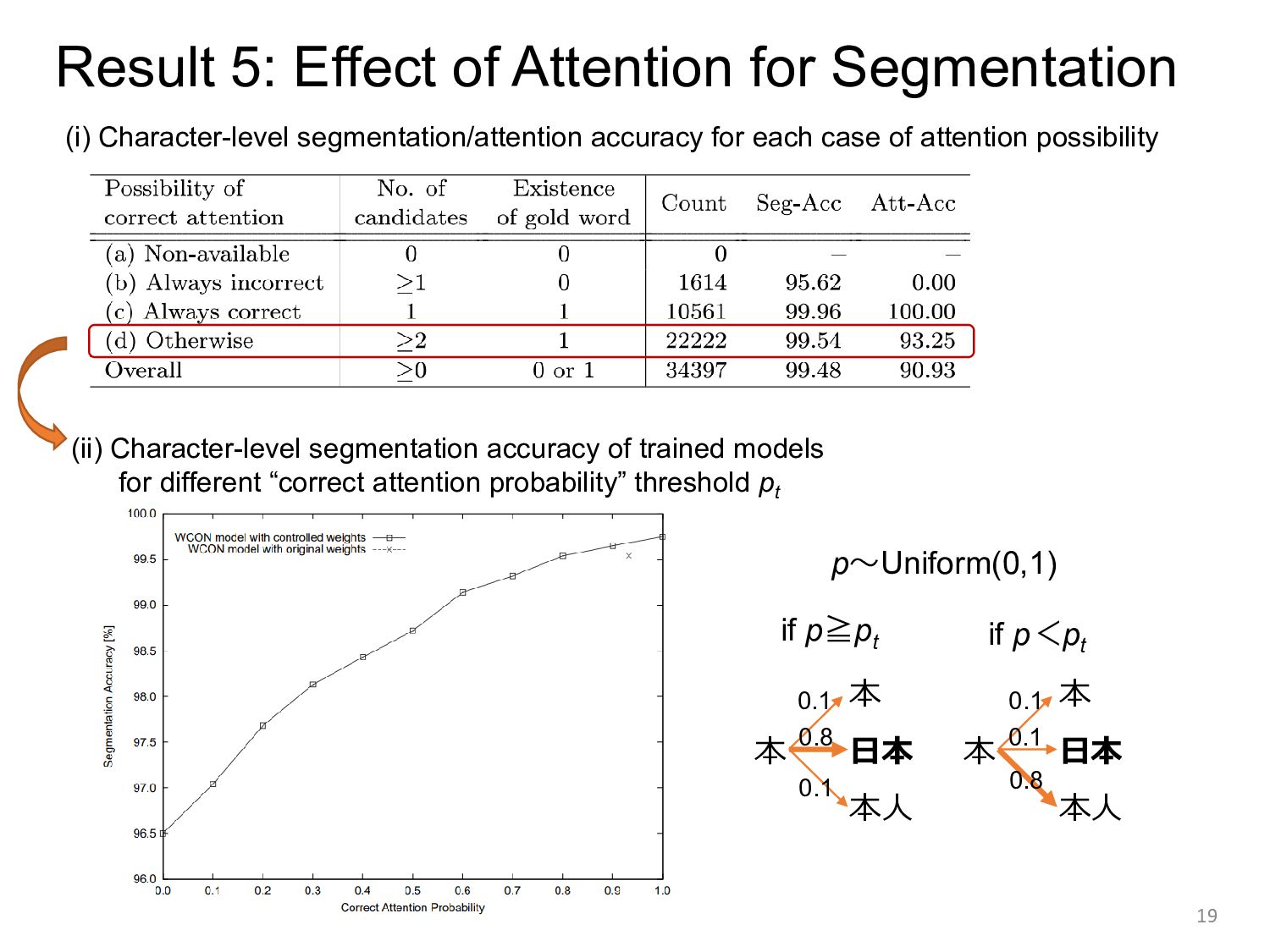
segmentation accuracy of trained models for different “correct attention probability” threshold pt 本 本 日本 本人 本 本 日本 本人 0.1 0.1 0.8 0.1 0.1 0.8 if p≧pt if p<pt p~Uniform(0,1) (i) Character-level segmentation/attention accuracy for each case of attention possibility
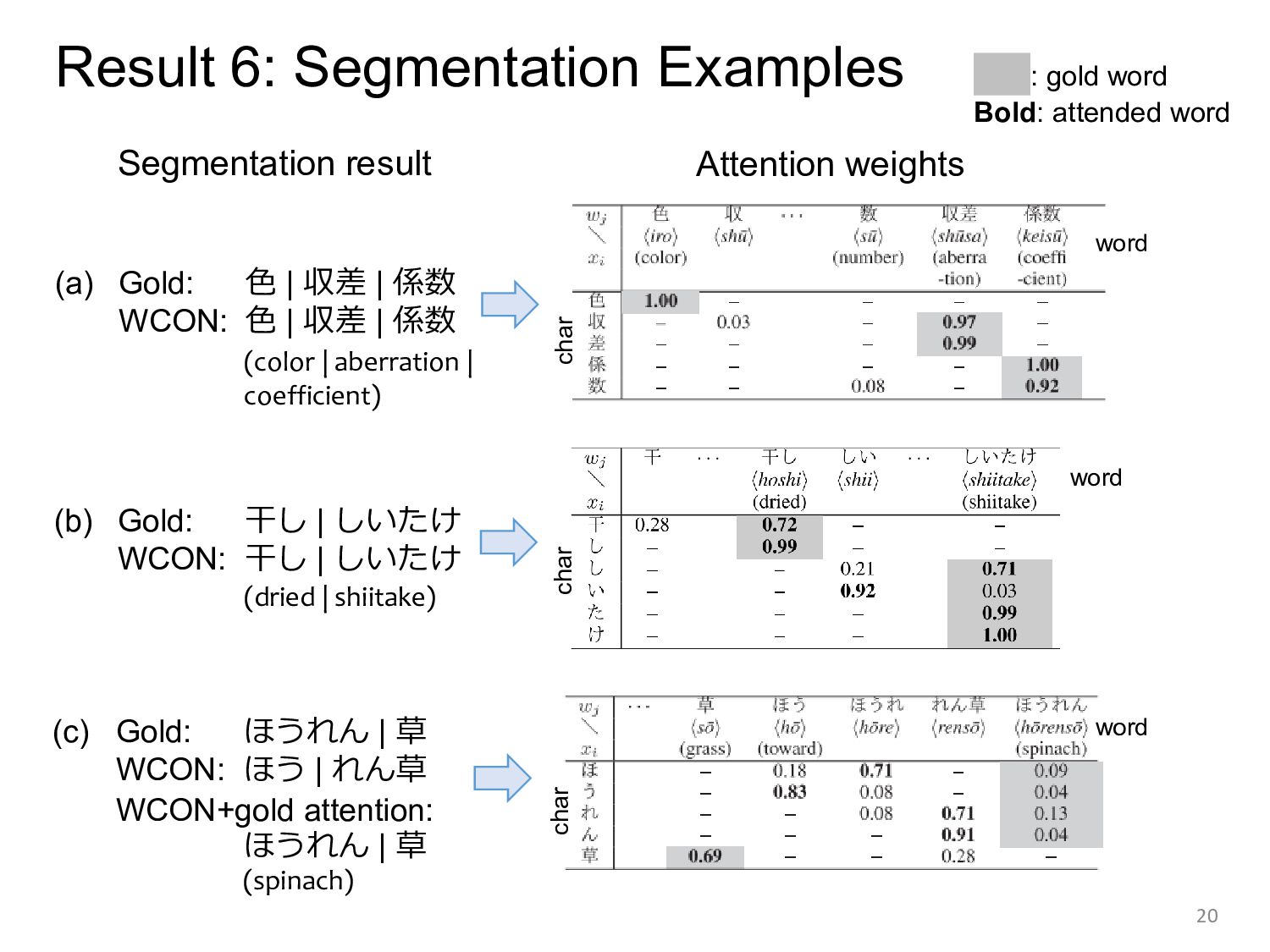
attention mechanism, which incorporates word information into a character-level sequence labeling framework. - Our analysis shows that 1. The proposed method, WCON, achieved better performance than existing methods especially for domains with higher OOV rate. 2. Learning appropriate attention weights contributed to accurate segmentation. - In future work, we will develop more robust methods for various text including user-generated text. 21 The code is available at https://github.com/shigashiyama/seikanlp
Oida, Y., Sakamoto, Y., and Okada, I. (2019). “Incorporating Word Attention into Character-Based Word Segmentation.” NAACL-HLT, pp. 2699–2709. ⁃ Kitagawa, Y. and Komachi, M. (2018). “Long Short-term Memory for Japanese Word Segmentation.” PACLIC, pp. 279–288. ⁃ Neubig, G., Nakata, Y., and Mori, S. (2011). “PointwIse Prediction for Robust, Adaptable Japanese Morphological Analysis.” ACL-HLT, pp. 529–533. ⁃ Wang, C. and Xu, B. (2017). “Convolutional Neural Network with Word Embeddings for Chinese Word Segmentation.” IJCNLP, pp. 163–172. ⁃ Yang, J., Zhang, Y., and Liang, S. (2019). “Subword Encoding in Lattice LSTM for Chinese Word Segmentation.” NAACL-HLT, pp. 2720–2725. 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}