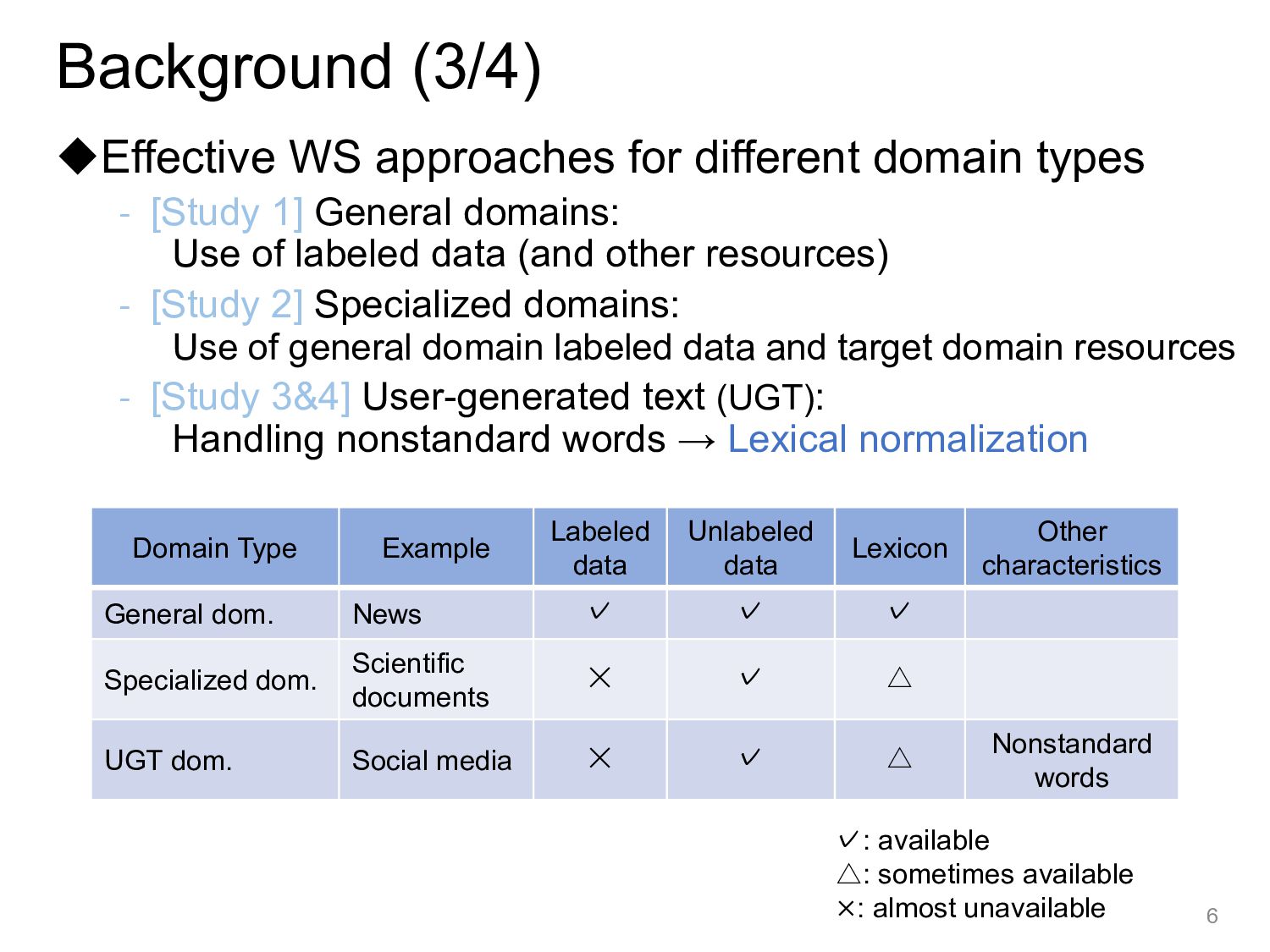
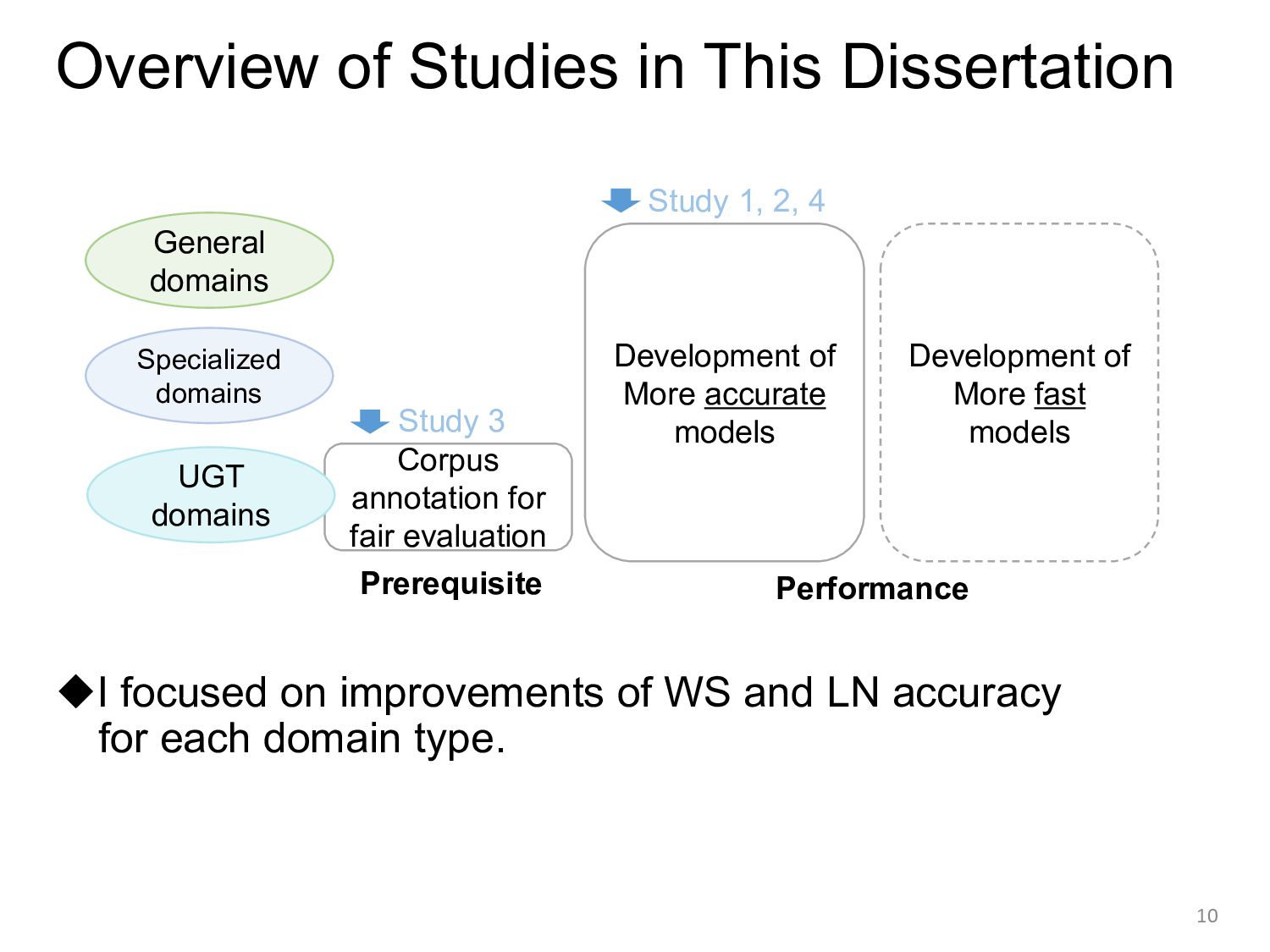
segments a sentence into tokens ◆Word - Human-understandable unit - Processing unit of traditional NLP - Mandatory unit for linguistic analysis (e.g., parsing and PAS) - Useful information as a feature or an intermediate unit of subword for application-oriented tasks (e.g., NER and MT) 4 Char ニ,ュ,ー,ラ,ル,ネ,ッ,ト,ワ,ー,ク,に,よ,る,自,然,言,語,処,理 Subword ニュー,ラル,ネット,ワーク,による,自然,言語,処理 Word ニューラル,ネットワーク,に,よる,自然,言語,処理 ニューラルネットワークによる自然言語処理 ‘Natural language processing based on neural networks’ Background (1/4)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
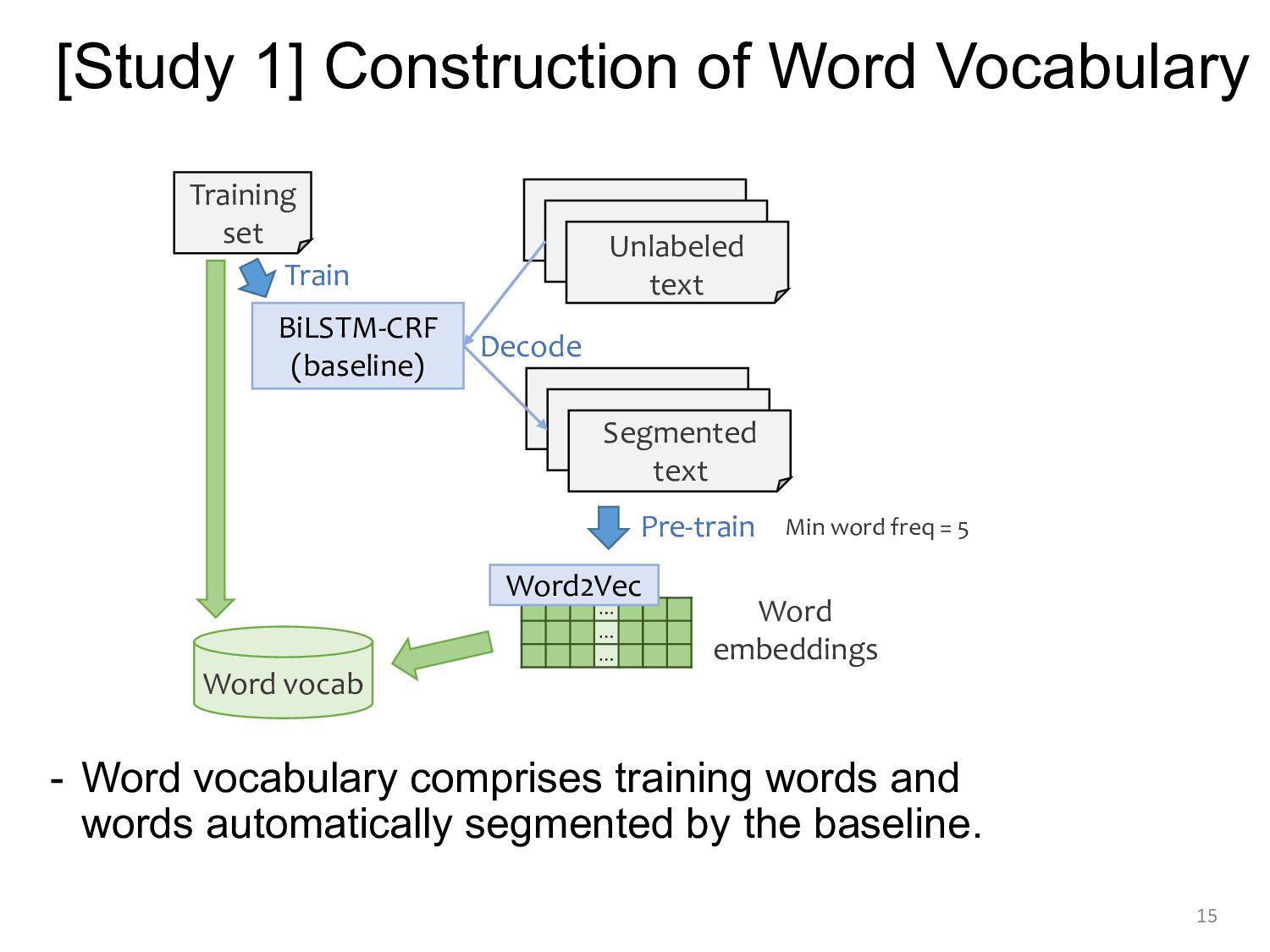
![[Study 1] Proposed Model Architecture ◆Char-based model with char-to-word attention](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_12.jpg){kind=link}
![[Study 1] Character-to-Word Attention 14 本 日本 本人 は日本 日本人](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_13.jpg){kind=link}
{kind=link}
![[Study 1] Experimental Datasets ◆Training/Test data - Chinese: 2 source](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_15.jpg){kind=link}
![[Study 1] Experimental Settings ◆Hyperparameters - num_BiLSTM_layers=2 or 3, num_BiLSTM_units=600,](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_16.jpg){kind=link}
![[Study 1] Exp 1. Comparison of Model Variants ◆F1 on](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_17.jpg){kind=link}
![[Study 1] Exp 2. Comparison with Existing Methods ◆F1 on](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_18.jpg){kind=link}
![20 [Study 1] Exp 5. Effect of Attention for Segmentation](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_19.jpg){kind=link}
![[Study 1] Conclusion - We proposed a neural word segmenter](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
![[Study 2] Cross-Domain WS with Linguistic Resources ◆Methods for Cross-Domain](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_23.jpg){kind=link}
![[Study 2] Lexicon Feature - Models cannot learn relationship b/w](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_24.jpg){kind=link}
![[Study 2] Our Lexicon Word Prediction - We introduce auxiliary](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_25.jpg){kind=link}
![[Study 2] Methods and Experimental Data ◆Linguistic resources for training](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_26.jpg){kind=link}
![[Study 2] Experimental Settings ◆Hyperparameter - num_BiLSTM_layers=2, num_BiLSTM_units=600, char_emb_dim=300, num_MLP_units=300,](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_27.jpg){kind=link}
![[Study 2] Exp 2. Cross-Domain Results ◆F1 on test sets](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_28.jpg){kind=link}
![[Study 2] Exp 3. Comparison with SOTA Methods ◆F1 on](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_29.jpg){kind=link}
![[Study 2] Exp 6. Performance for Unknown Words ◆Recall of](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_30.jpg){kind=link}
![[Study 2] Conclusion - We proposed a cross-domain WS method](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
![[Study 3] Corpus Construction Policies 1. Available and restorable -](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_34.jpg){kind=link}
![[Study 3] Example Sentence in Our Corpus 36 イイ歌ですねェ Raw](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_35.jpg){kind=link}
![[Study 3] Corpus Details ◆Word categories - 11 categories were](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_36.jpg){kind=link}
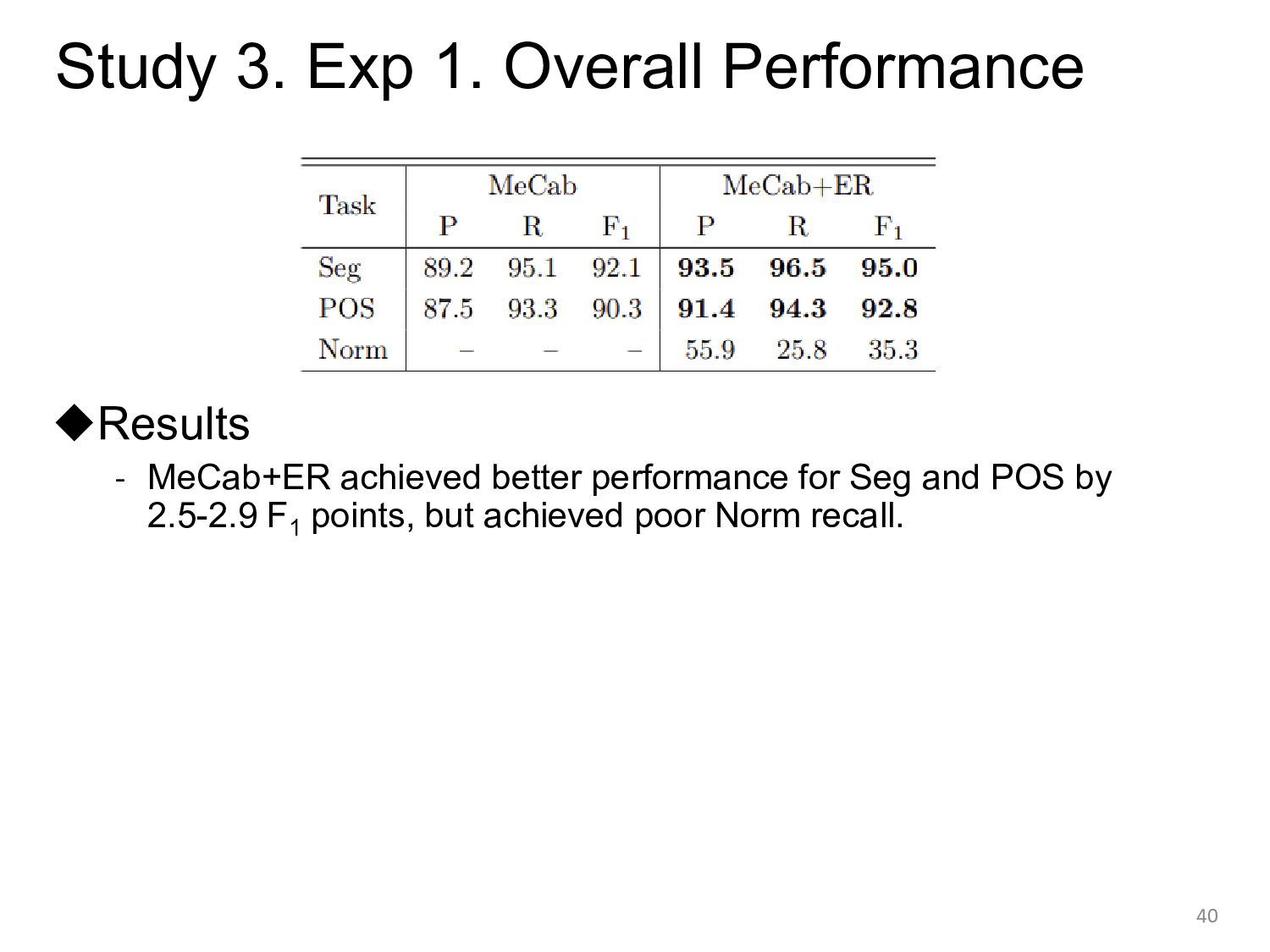
![[Study 3] Experiments Using our corpus, we evaluated two existing](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_37.jpg){kind=link}
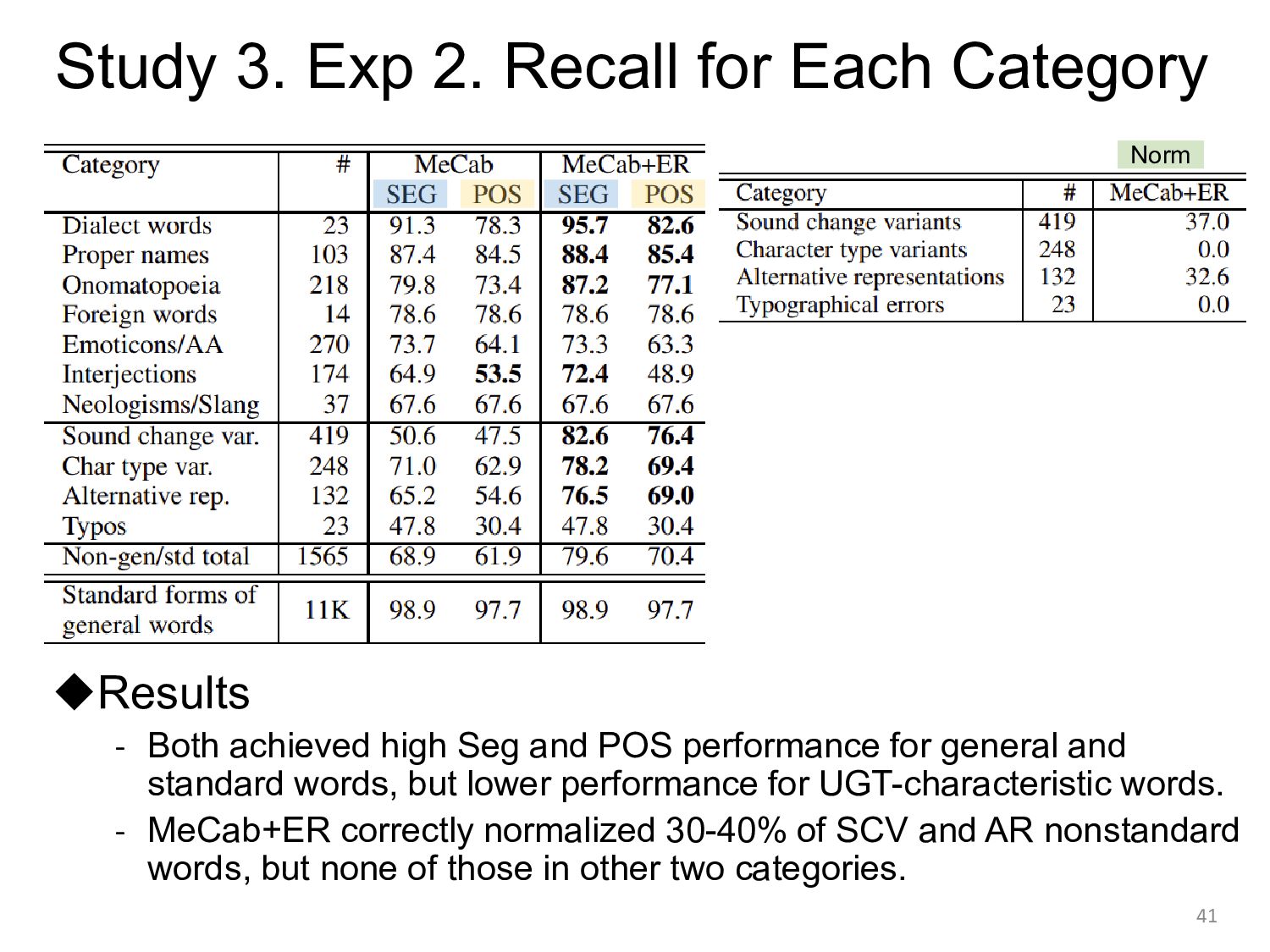
![[Study 3] Experiments ◆Evaluation 1. Overall results 2. Results for](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
![[Study 3] Conclusion - We constructed a public Japanese UGT](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
![[Study 4] Background and Motivation ◆Frameworks for text generation ◆Our](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_44.jpg){kind=link}
![[Study 4] Task Formulation ◆Formulation as multiple sequence labeling tasks](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_45.jpg){kind=link}
![[Study 4] Variant Pair Acquisition ◆Standard and nonstandard word variant](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_46.jpg){kind=link}
![[Study 4] Pseudo-labeled Data Generation ◆Input - (Auto-) segmented sentence](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_47.jpg){kind=link}
![[Study 4] Experimental Data ◆Pseudo labeled data for training (and](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_48.jpg){kind=link}
![[Study 4] Experimental Settings ◆Our model - BiLSTM + task-specific](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_49.jpg){kind=link}
![[Study 4] Exp 1. Main Results ◆Results - Our method](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_50.jpg){kind=link}
![[Study 4] Exp 5. Error Analysis ◆Detailed normalization performance -](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_51.jpg){kind=link}
![[Study 4] Conclusion - We proposed a text editing-based method](https://files.speakerdeck.com/presentations/daf374ea848c44e9bda478b907336e00/slide_52.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}