Share
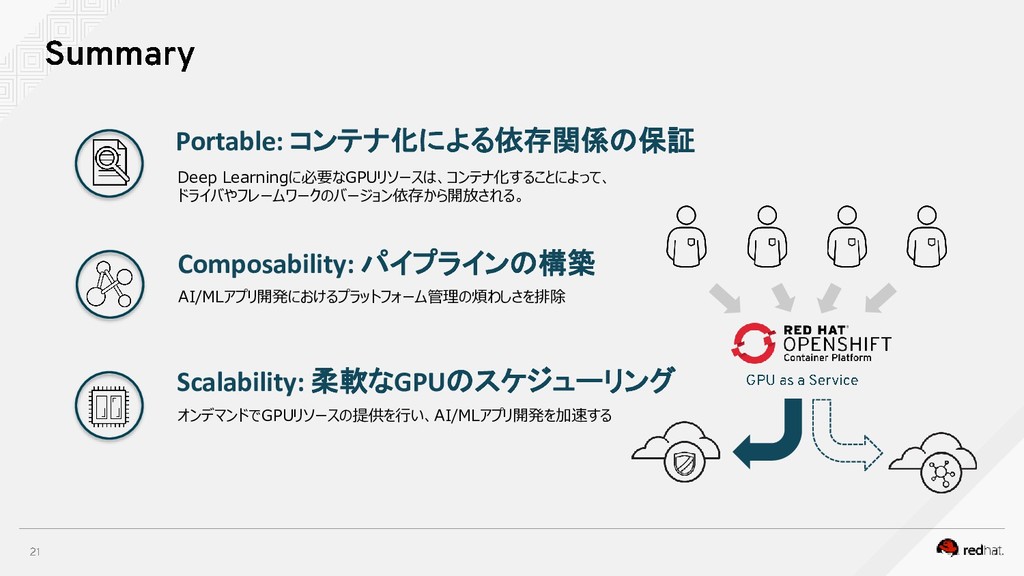
「HPE HPC & AI フォーラム 2018」で利用した資料です。 ※なお20分枠なので短縮版です。
https://h50146.www5.hpe.com/events/seminars/info/hp-cast2018.html
{kind=link}
{kind=link}
{kind=link}
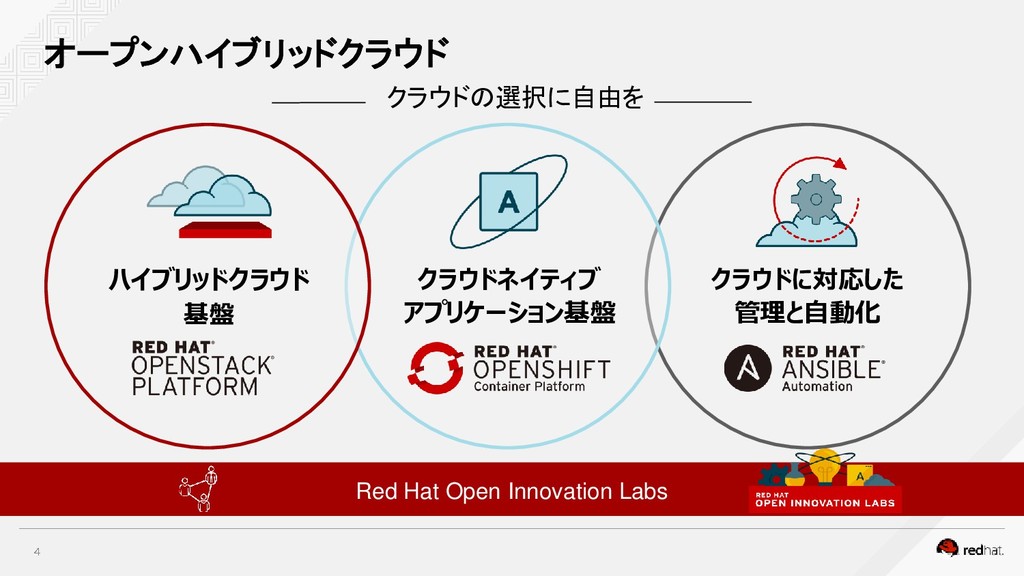{kind=link}
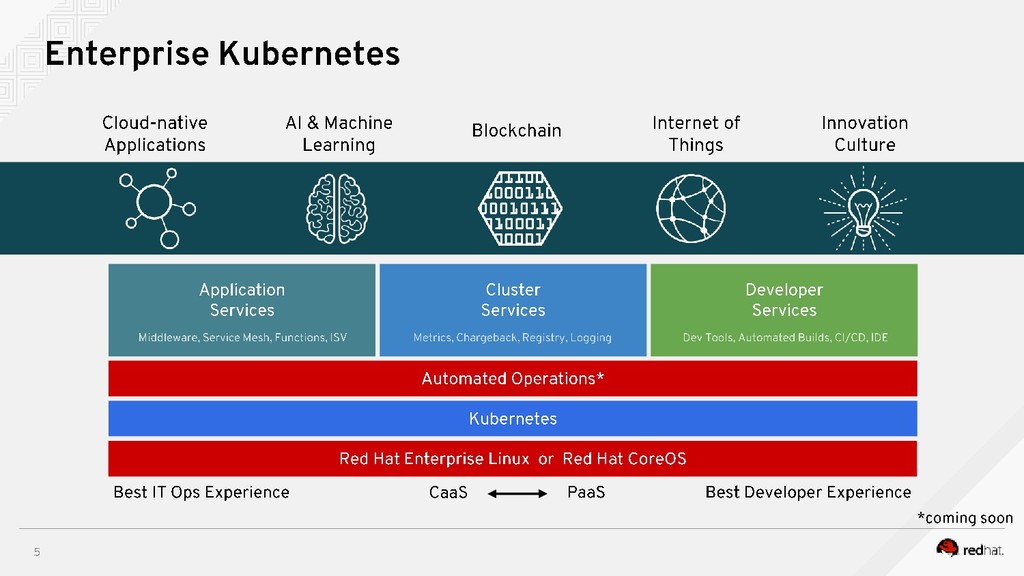{kind=link}
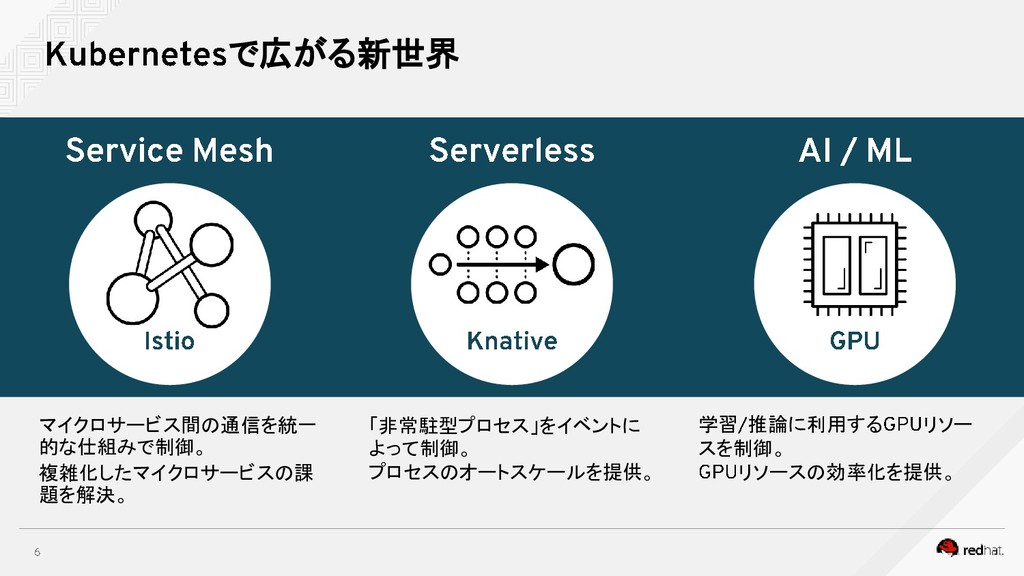{kind=link}
{kind=link}
{kind=link}
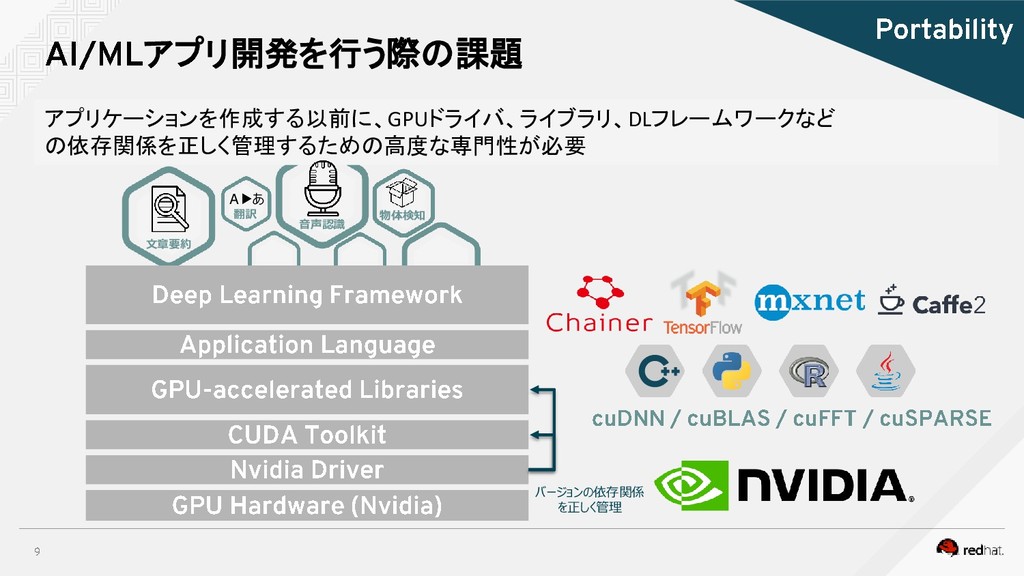{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}