Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
深層学習を用いた自然言語処理(2)
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
shu_suzuki
January 17, 2019
Technology
1
110
深層学習を用いた自然言語処理(2)
2019年1月17日 第2回B3ゼミ資料
長岡技術科学 自然言語処理研究室
16104587 鈴木脩右
shu_suzuki
January 17, 2019
Tweet
Share
More Decks by shu_suzuki
See All by shu_suzuki
文献紹介:Investigating Evaluation of Open-Domain Dialogue Systems With Human Generated Multiple References
shu_suzuki
0
200
文献紹介:Do Neural Dialog Systems Use the Conversation History Effectively? An Empirical Study
shu_suzuki
0
86
文献紹介: How to Make Context More Useful? An Empirical Study on Context-Aware Neural Conversational Models
shu_suzuki
0
360
文献紹介:Conversational Response Re-ranking Based on Event Causality and Role Factored Tensor Event Embedding
shu_suzuki
0
180
文献紹介:Modeling Semantic Relationship in Multi-turn Conversations with Hierarchical Latent Variables
shu_suzuki
0
80
文献紹介:ReCoSa: Detecting the Relevant Contexts with Self-Attention for Multi-turn Dialogue Generation
shu_suzuki
0
220
文献紹介:Better Automatic Evaluation of Open-Domain Dialogue Systems with Contextualized Embeddings
shu_suzuki
0
130
文献紹介:Why are Sequence-to-Sequence Models So Dull?
shu_suzuki
0
75
文献紹介:Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network
shu_suzuki
0
220
Other Decks in Technology
See All in Technology
スケールアップ企業でQA組織が機能し続けるための組織設計と仕組み〜ボトムアップとトップダウンを両輪としたアプローチ〜
qa
0
370
Change Calendarで今はOK?を仕組みにする
tommy0124
1
130
Oracle AI Database@Azure:サービス概要のご紹介
oracle4engineer
PRO
4
1.3k
AIにより大幅に強化された AWS Transform Customを触ってみる
0air
0
170
開発チームとQAエンジニアの新しい協業モデル -年末調整開発チームで実践する【QAリード施策】-
kaomi_wombat
0
260
私がよく使うMCPサーバー3選と社内で安全に活用する方法
kintotechdev
0
140
Even G2 クイックスタートガイド(日本語版)
vrshinobi1
0
120
TUNA Camp 2026 京都Stage ヒューリスティックアルゴリズム入門
terryu16
0
610
【社内勉強会】新年度からコーディングエージェントを使いこなす - 構造と制約で引き出すClaude Codeの実践知
nwiizo
28
14k
AI時代のIssue駆動開発のススメ
moongift
PRO
0
290
Kubernetesの「隠れメモリ消費」によるNode共倒れと、Request適正化という処方箋
g0xu
0
150
Bill One 開発エンジニア 紹介資料
sansan33
PRO
5
18k
Featured
See All Featured
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.2k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
250
Claude Code のすすめ
schroneko
67
220k
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
680
ラッコキーワード サービス紹介資料
rakko
1
2.8M
Un-Boring Meetings
codingconduct
0
240
Scaling GitHub
holman
464
140k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
420
New Earth Scene 8
popppiees
2
1.9k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Into the Great Unknown - MozCon
thekraken
40
2.3k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
66k
Transcript
深層学習を用いた 自然言語処理(2) 2019年1月17日 長岡技術科学大学 自然言語処理研究室 16104587 鈴木脩右
分散表現を得る手法 カウントベース • ある単語の周囲の単語をカウントし, そこから分散表現を得る. 推論ベース • 推測することを目標とし,副産物として分散表現を得る.
分散表現を得る手法 カウントベース • ある単語の周囲の単語をカウントし, そこから分散表現を得る. 推論ベース • 推測することを目標とし,副産物として分散表現を得る.
word2vec • 教師なし学習で,2層のニューラルネットワークで構成される • ある単語(ターゲット)と周囲の単語(コンテキスト)で推論を行う 例) 吾輩 は 猫 で
ある → に入る単語を推論する • 入出力はone-hot表現(ターゲットが1,コンテキストが0のベクトル) • 学習した入力側の重みを分散表現として獲得 ? ?
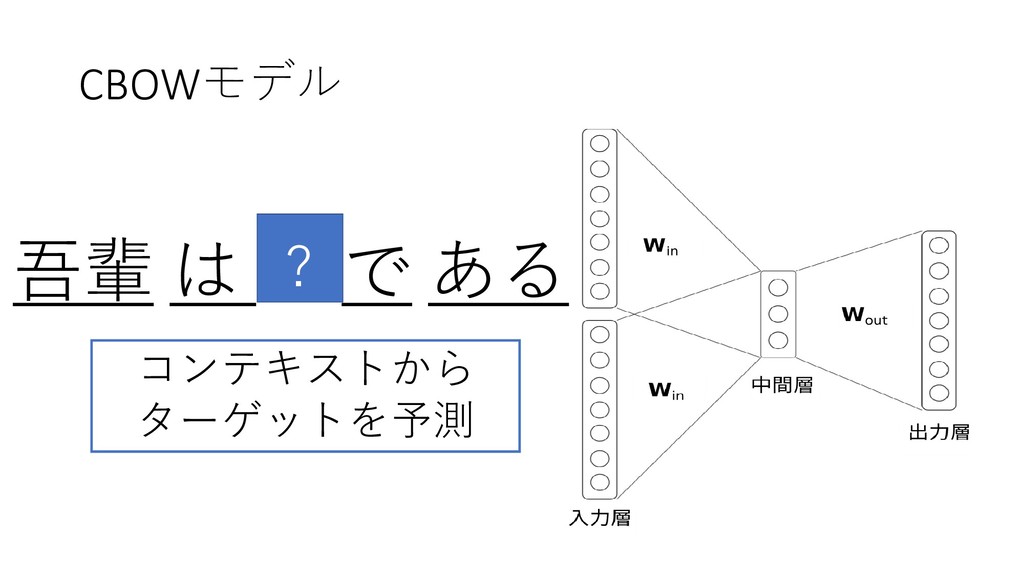
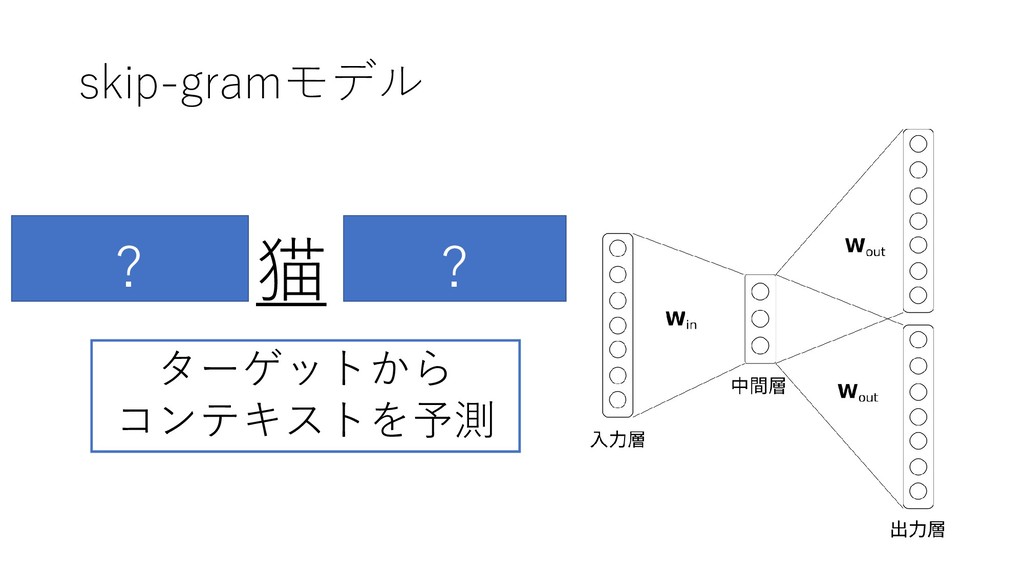
word2vecのモデル •CBOWモデル (continuous bag-of-words) •Skip-gramモデル
CBOWモデル 吾輩 は 猫 で ある ? コンテキストから ターゲットを予測
skip-gramモデル 吾輩 は 猫 で ある ターゲットから コンテキストを予測 ? ?
Negative Sampling •語彙数が多いと学習時間が長くなる →正例を与えれば短時間で学習可能 •負例も学習しないと精度が落ちる →負例をいくつかサンプリングして学習 •サンプリングには確率分布を用いる →高頻度の単語を負例として学習可能
word2vecでできること •コサイン類似度から,類似単語を見つける •類推問題をベクトルの加減算で行える 例)王様 ー 男性 + 女性 = 女王様
•転移学習に用いる (文書分類,感情分析)
word2vecの試行(1)〜学習データ作成〜 1. 学習データの作成 1.1. 「吾輩は猫である」のtxtデータから一文ずつ抽出 1.2. MeCab+NEologdで形態素解析を行い単語に分割 1.3. 各ケースに分けて学習データを作成 case1:デフォルト
case2:ストップワード(助詞など)の削除 case3:case2+動詞と形容詞を原形 ※MeCabでは形容動詞は名詞+助動詞として扱っている
word2vecの試行(2)〜学習モデル作成〜 2. 学習モデルの作成 2.1. gensimライブラリをインポート 2.2. skip-gramモデルでcase毎にモデルを作成 次元=100 サンプリング数=5 コンテキスト幅=5
学習回数=20
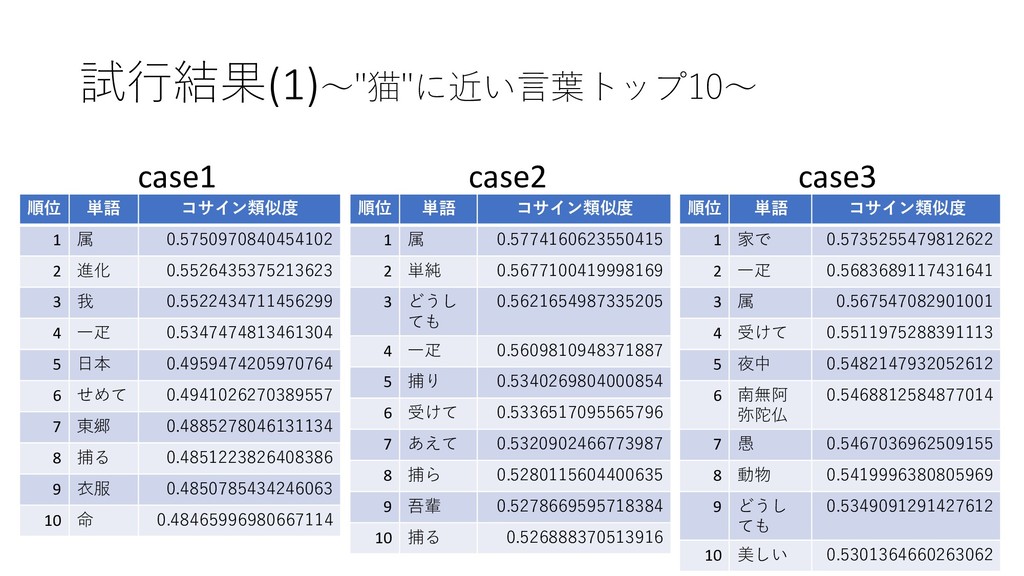
word2vecの試行(3)〜学習モデルの実行〜 3. 学習モデルの実行 3.1. "猫"と類似度が高い10単語を算出 3.2. "主人"ー"教師"+"猫"で類推問題を行う
試行結果(1)〜"猫"に近い言葉トップ10〜 case1 順位 単語 コサイン類似度 1 属 0.5750970840454102 2 進化
0.5526435375213623 3 我 0.5522434711456299 4 一疋 0.5347474813461304 5 日本 0.4959474205970764 6 せめて 0.4941026270389557 7 東郷 0.4885278046131134 8 捕る 0.4851223826408386 9 衣服 0.4850785434246063 10 命 0.48465996980667114 case2 順位 単語 コサイン類似度 1 属 0.5774160623550415 2 単純 0.5677100419998169 3 どうし ても 0.5621654987335205 4 一疋 0.5609810948371887 5 捕り 0.5340269804000854 6 受けて 0.5336517095565796 7 あえて 0.5320902466773987 8 捕ら 0.5280115604400635 9 吾輩 0.5278669595718384 10 捕る 0.526888370513916 case3 順位 単語 コサイン類似度 1 家で 0.5735255479812622 2 一疋 0.5683689117431641 3 属 0.567547082901001 4 受けて 0.5511975288391113 5 夜中 0.5482147932052612 6 南無阿 弥陀仏 0.5468812584877014 7 愚 0.5467036962509155 8 動物 0.5419996380805969 9 どうし ても 0.5349091291427612 10 美しい 0.5301364660263062
試行結果(2)〜類推問題〜 "主人"-"教師"+"猫" ="横"(0.42507898807525635) (case1) ="吾輩" (0.4937707483768463) (case2) ="吾輩 " (0.5058480501174927)
(case3)
まとめ • Word2vecはターゲットやコンテキストで推論を行い,その重みを分 散表現として得る. • CBOWモデルはコンテキストからターゲットを予測する • skip-gramモデルはターゲットからコンテキストを予測する • 学習の高速化にはNegative
samplingという手法がある • 3種類のデータクレンジング方法で試行したが大きな違いは 得られなかった.大規模なコーパスで定量的な実験を行いたい
参考文献 [1] 斎藤康毅.ゼロから作る Deep Learning②.オライリー・ジャパ ン,2018. [2] 西村陸,松本忠博.日本語単語ベクトルの精度向上のための 前処理手法の検討.言語処理学会 第23回年次大会
発表論文集, pp.613-616,2017.
おまけ〜乾・鈴木研究室配布モデル〜 順位 単語 コサイン類似度 1 犬 0.8248943090438843 2 ネコ 0.8084875345230103
3 黒猫 0.7770006060600281 4 子猫 0.7636253833770752 5 ウサギ 0.7440483570098877 6 飼い猫 0.7325707674026489 7 ねこ 0.7288334369659424 8 子犬 0.727780818939209 9 野良猫 0.7255929708480835 10 飼っ 0.7047336101531982 "すき焼き"-"日本"+"アメリカ" ="ホットドッグ "(0.564887523651123)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考文献 [1] 斎藤康毅.ゼロから作る Deep Learning②.オライリー・ジャパ ン,2018. [2] 西村陸,松本忠博.日本語単語ベクトルの精度向上のための 前処理手法の検討.言語処理学会 第23回年次大会](https://files.speakerdeck.com/presentations/4e445e6882c44d13badef19696997e63/slide_15.jpg){kind=link}
{kind=link}