Automatic Dance Video Segmentation for Understanding Choreography
Koki Endo*, Shuhei Tsuchida*, Tsukasa Fukusato, Takeo Igarashi (* = authors contributed equally)
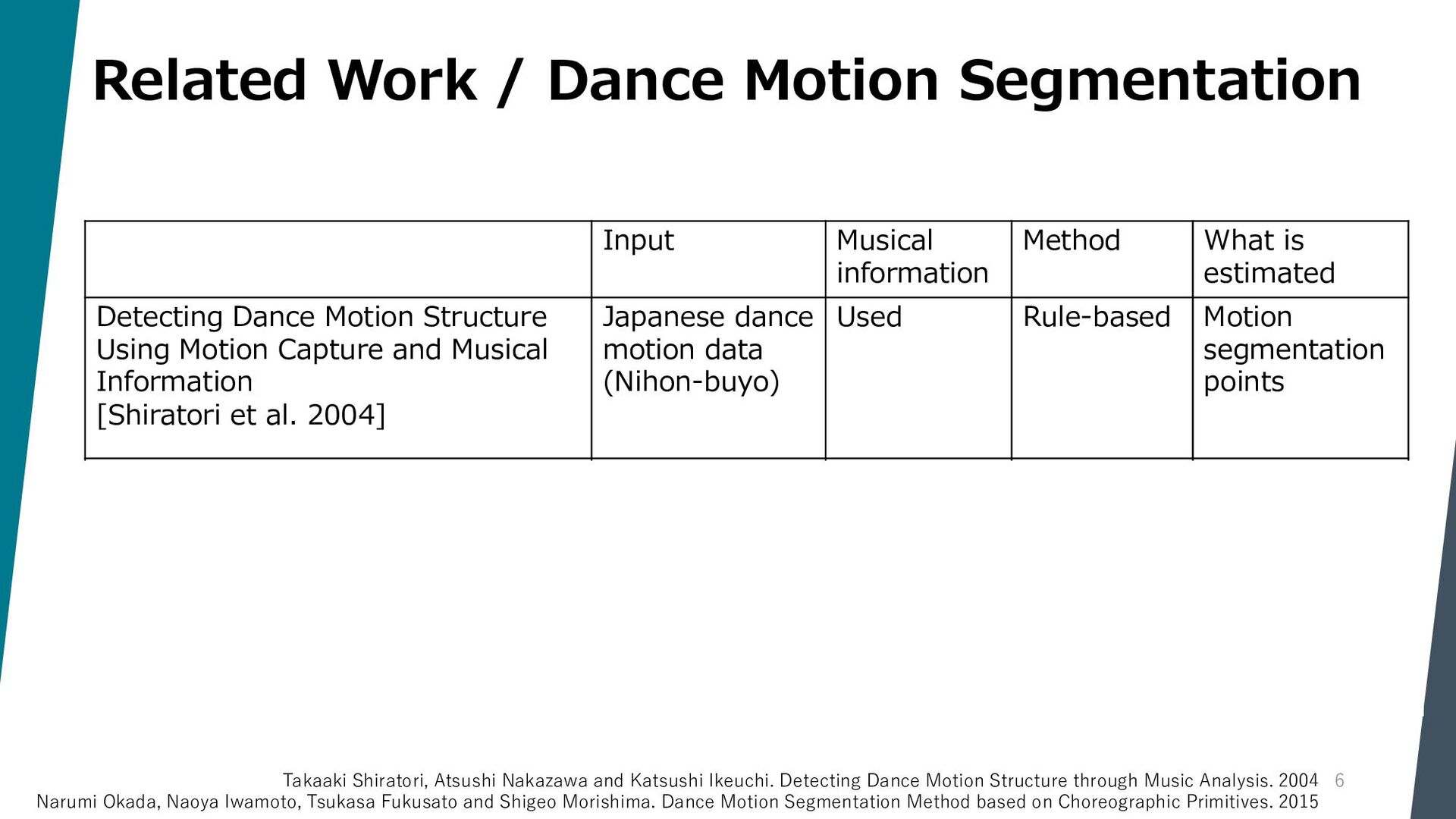
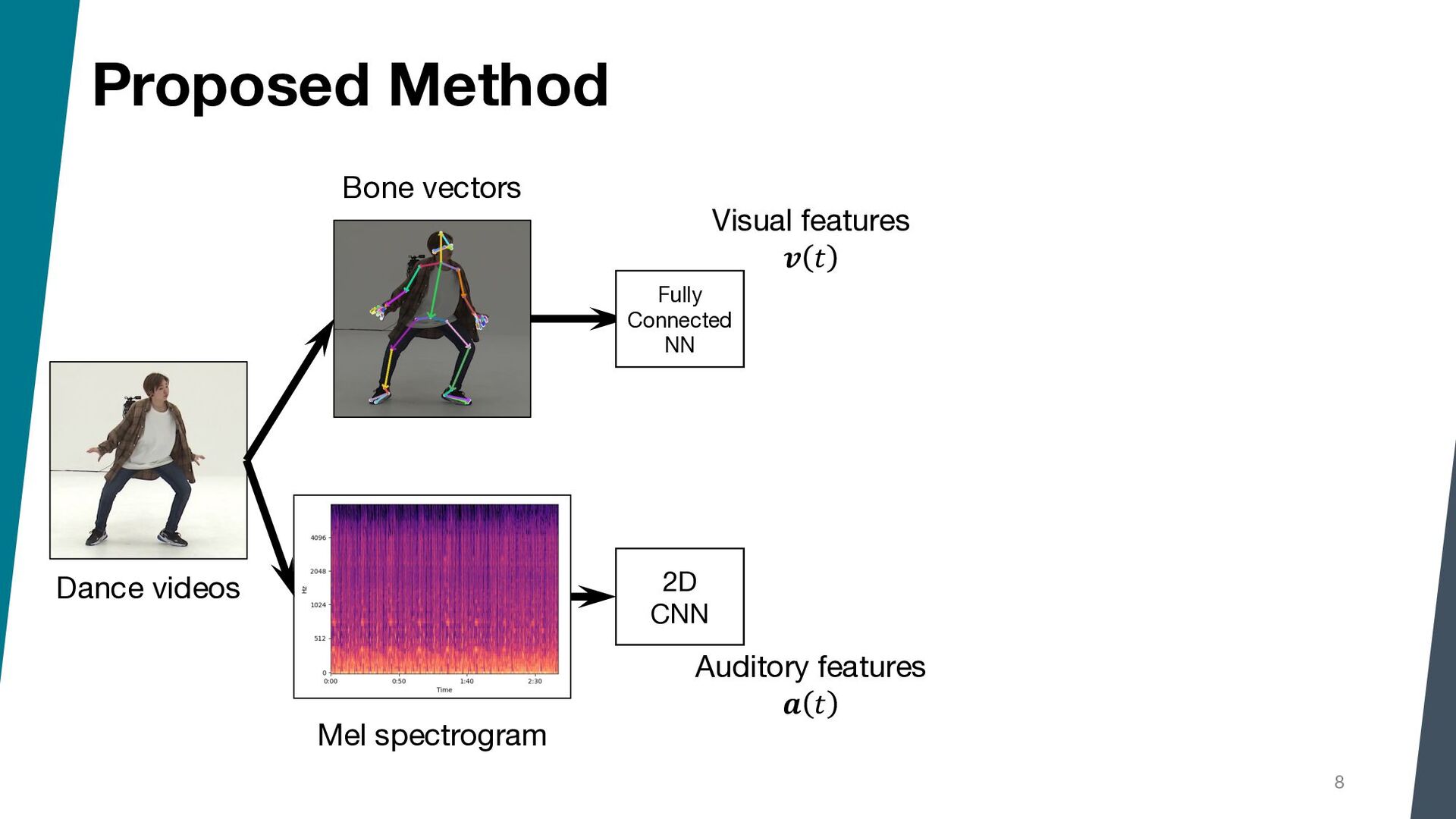
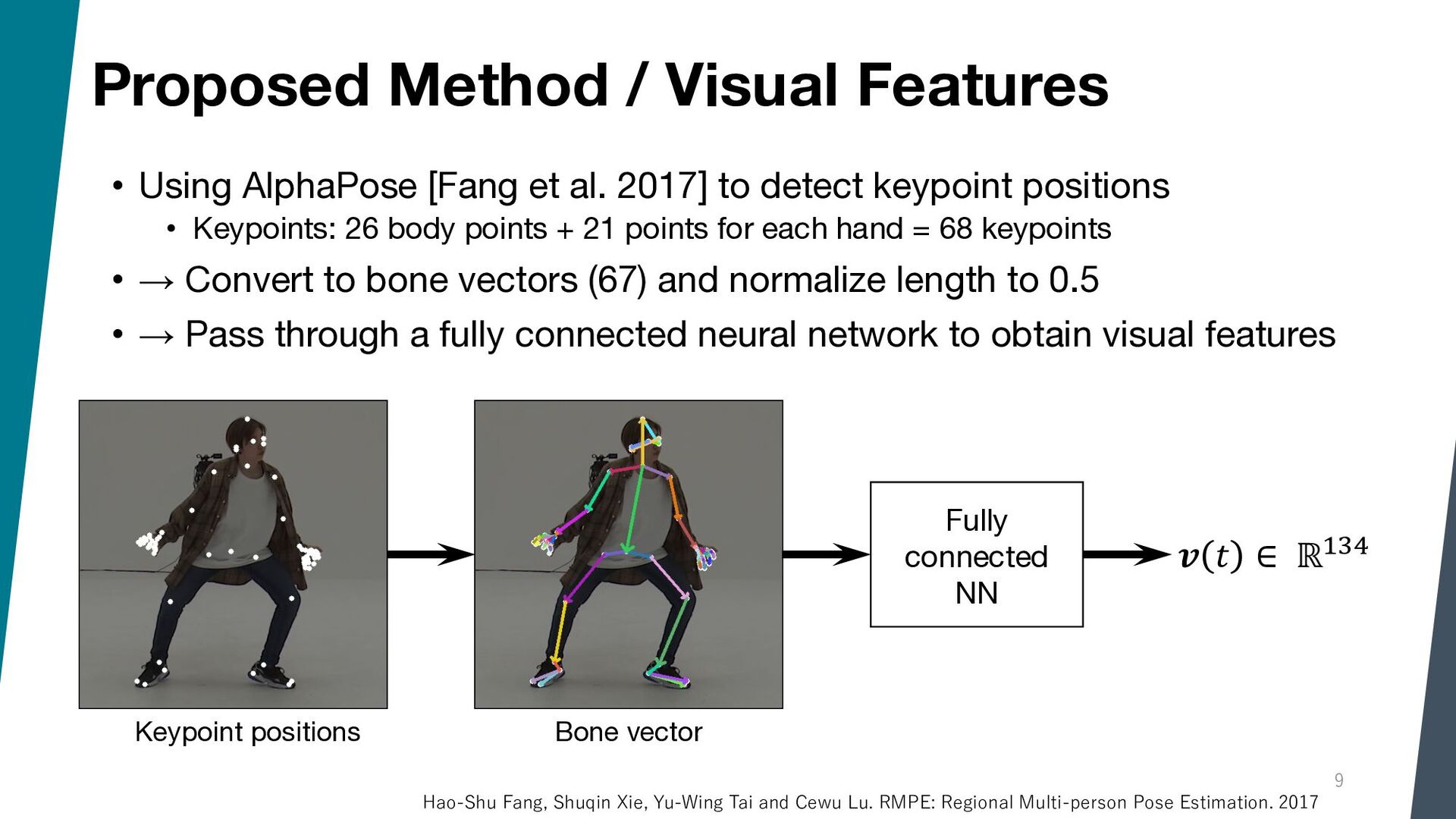
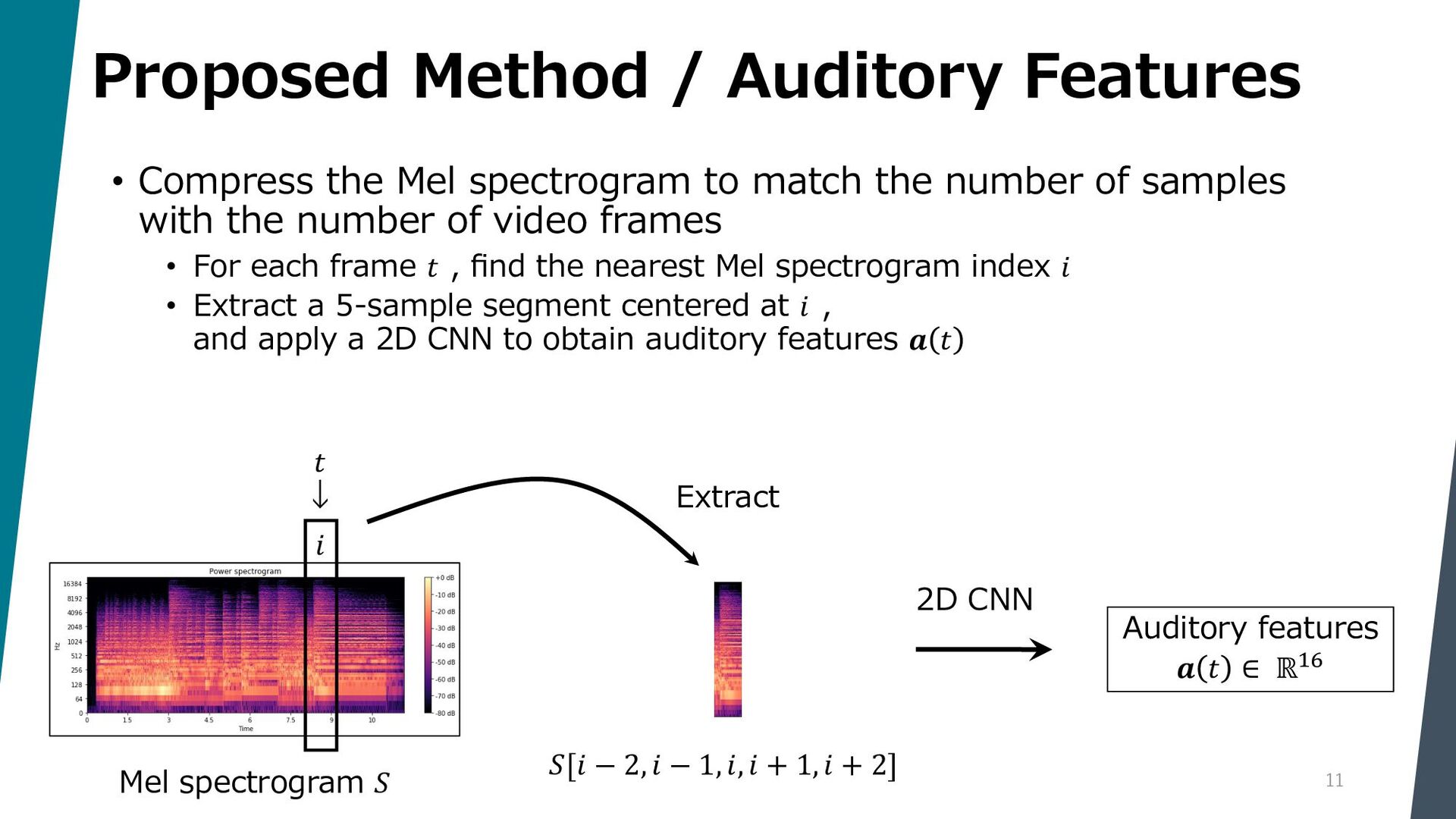
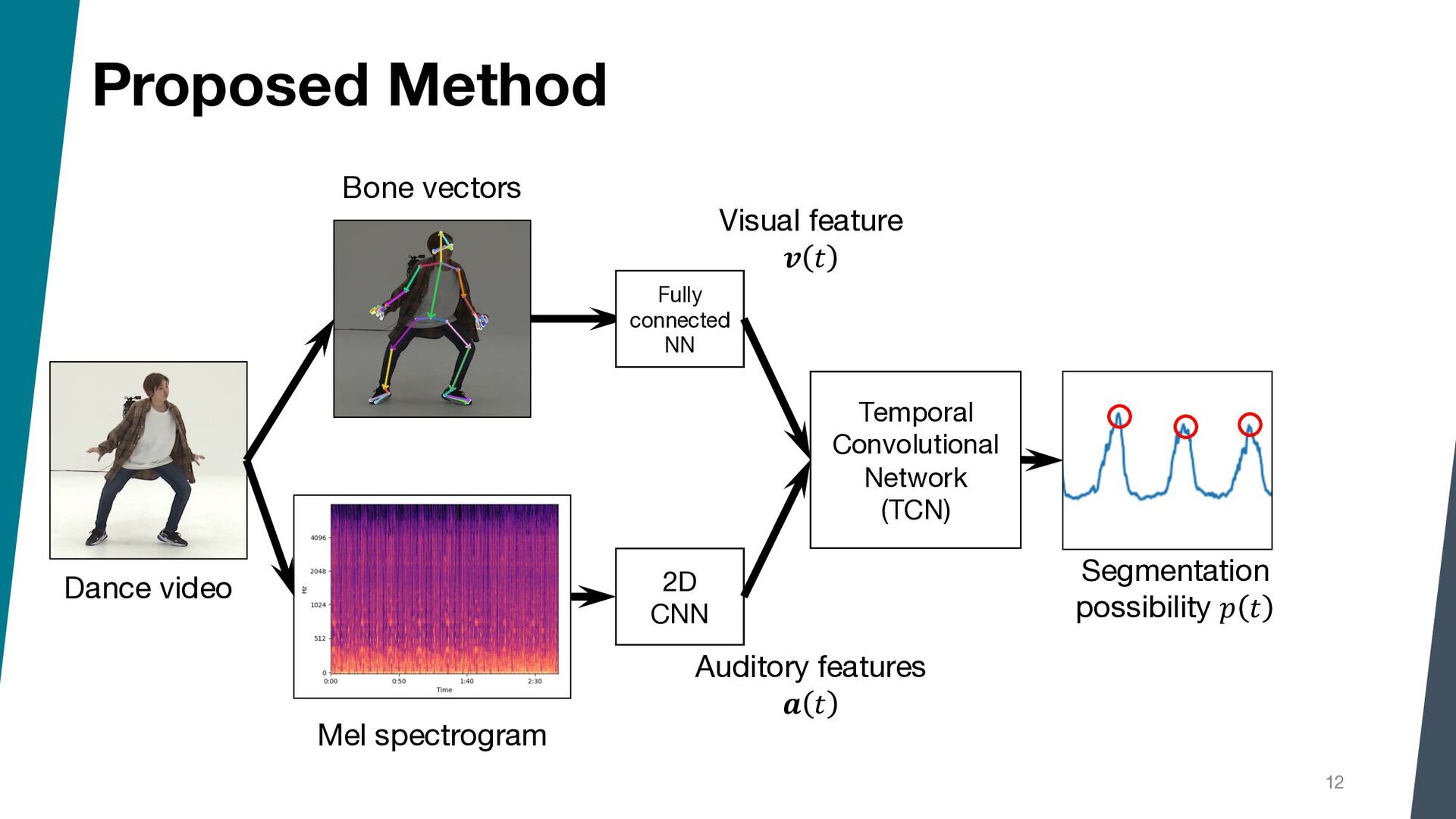
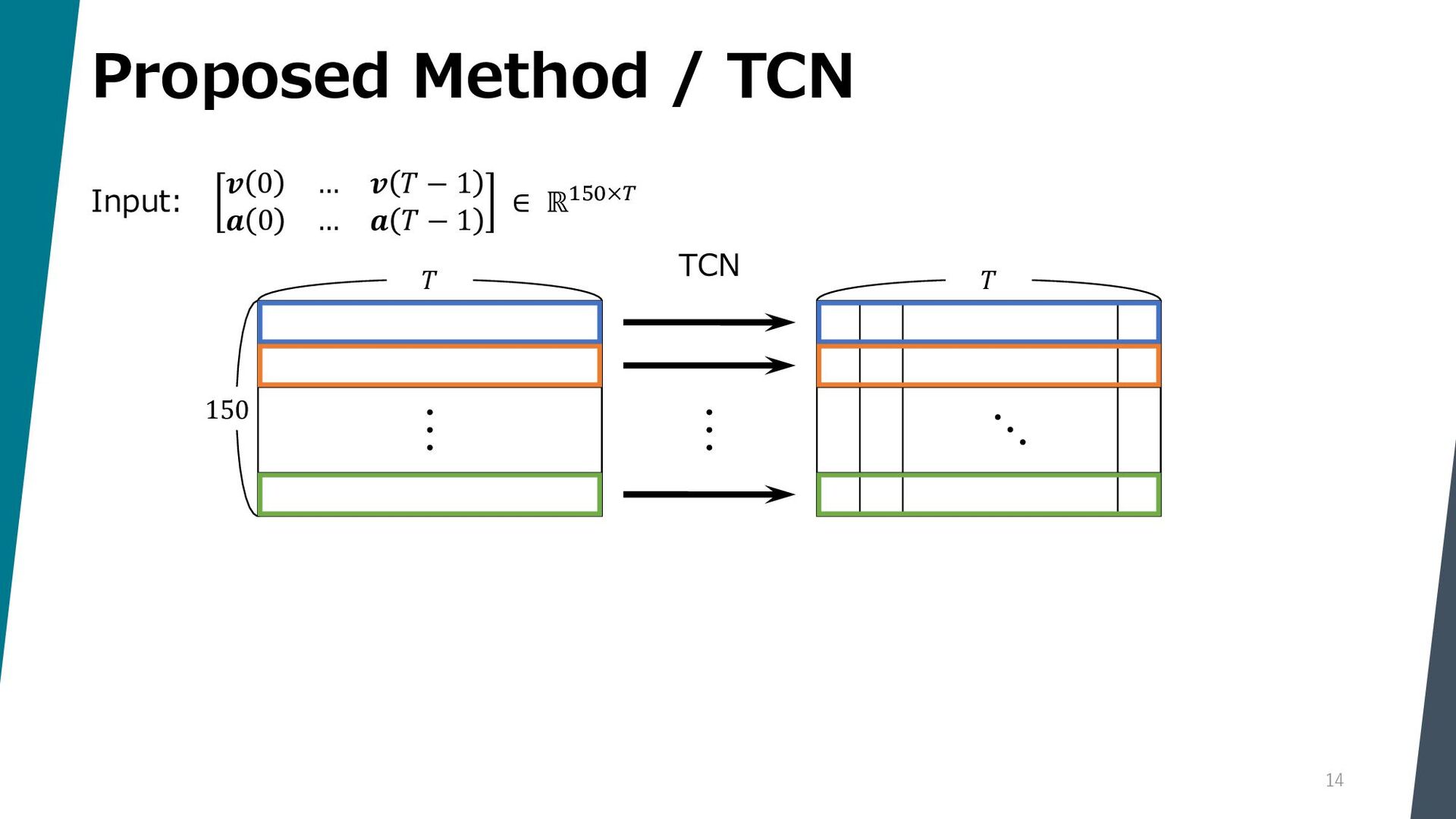
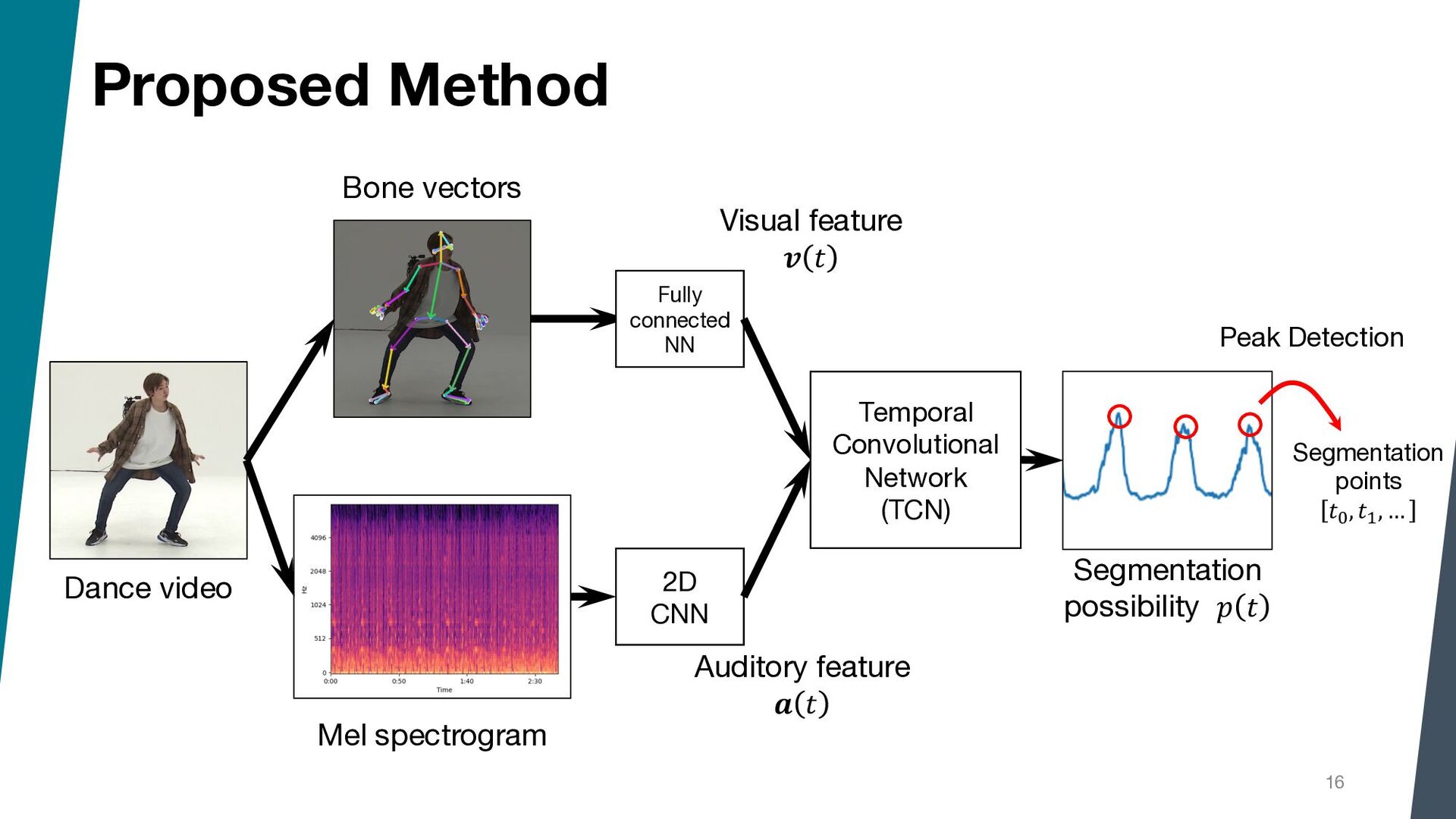
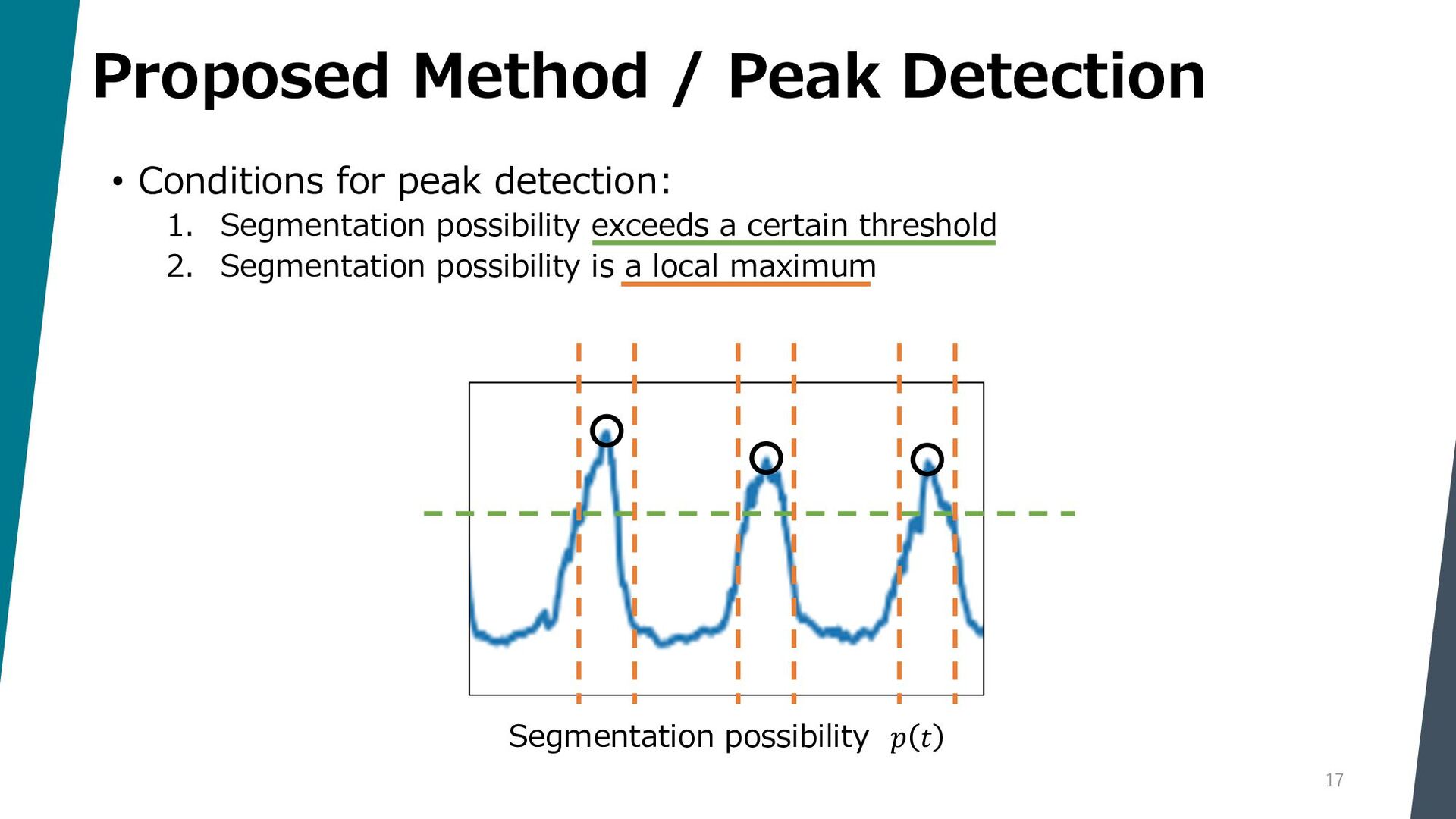
Segmenting dance video into short movements is a popular way to easily understand dance choreography. However, it is currently done manually and requires a significant amount of effort by experts. In this paper, we propose a method to automatically segment a dance video into each movement. Given a dance video as input, we first extract visual and audio features: the former is computed from the keypoints of the dancer in the video, and the latter is computed from the Mel spectrogram of the music in the video. Next, these features are passed to a Temporal Convolutional Network (TCN), and segmentation points are estimated by picking peaks of the network output.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
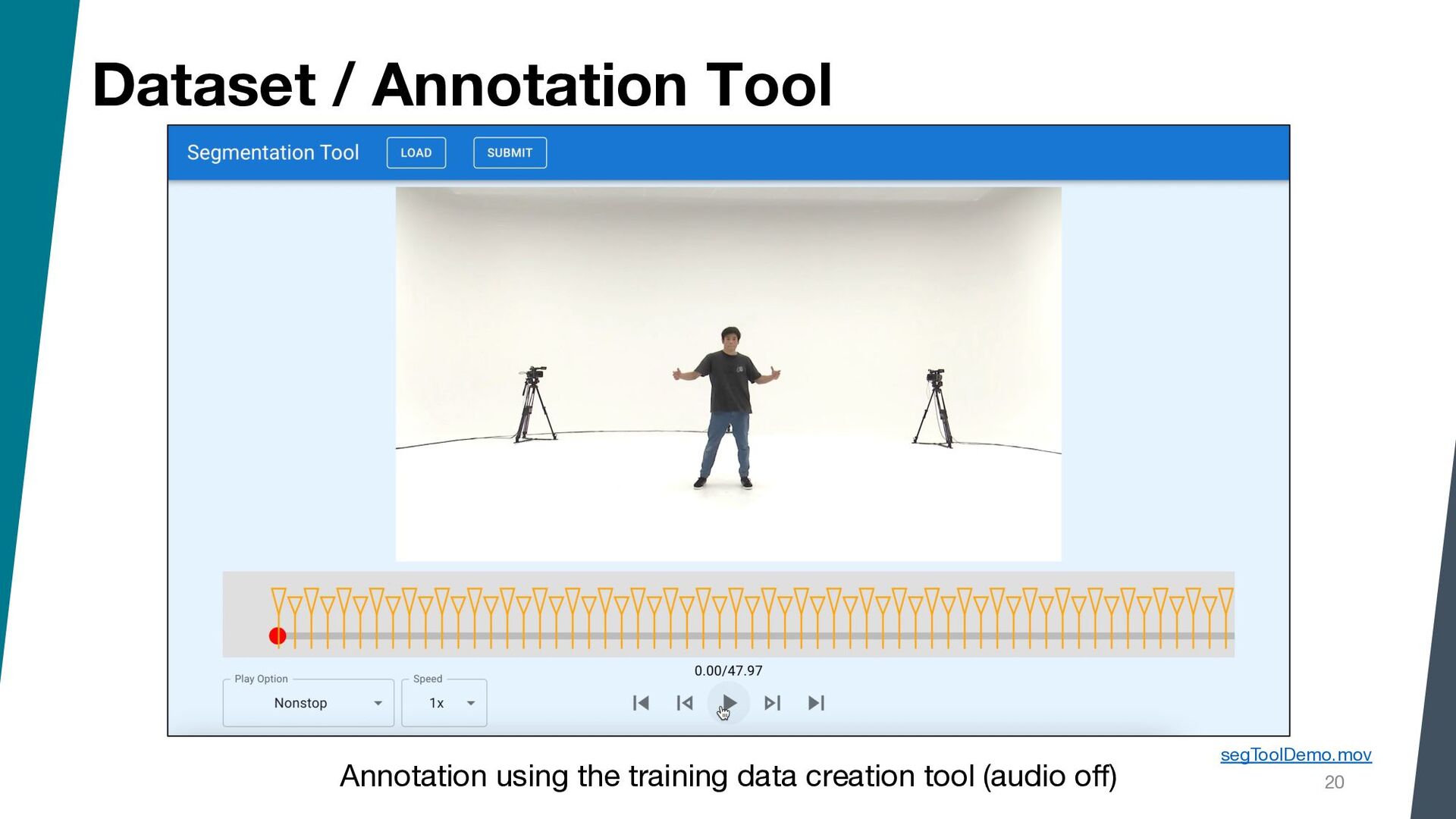{kind=link}
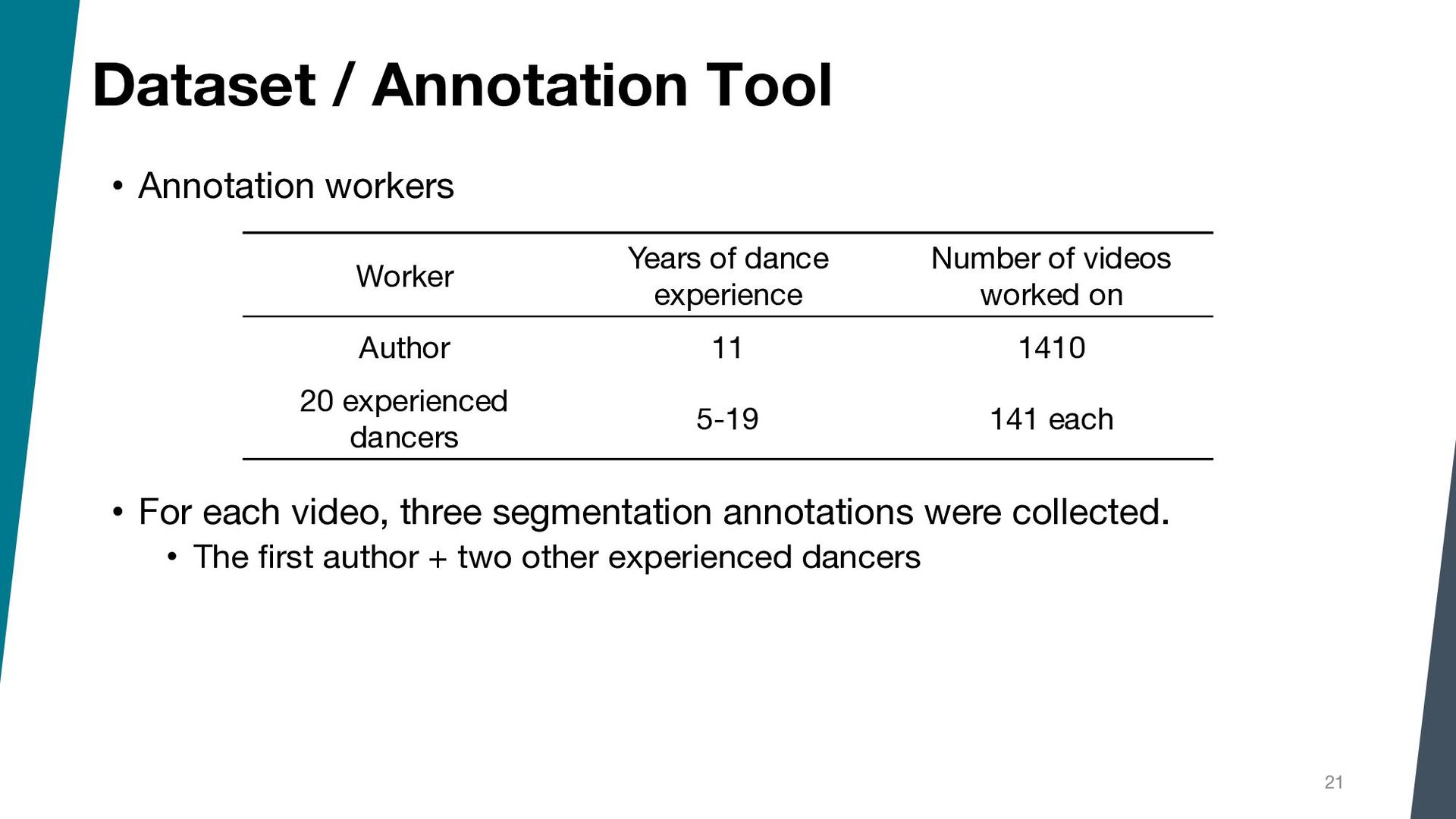{kind=link}
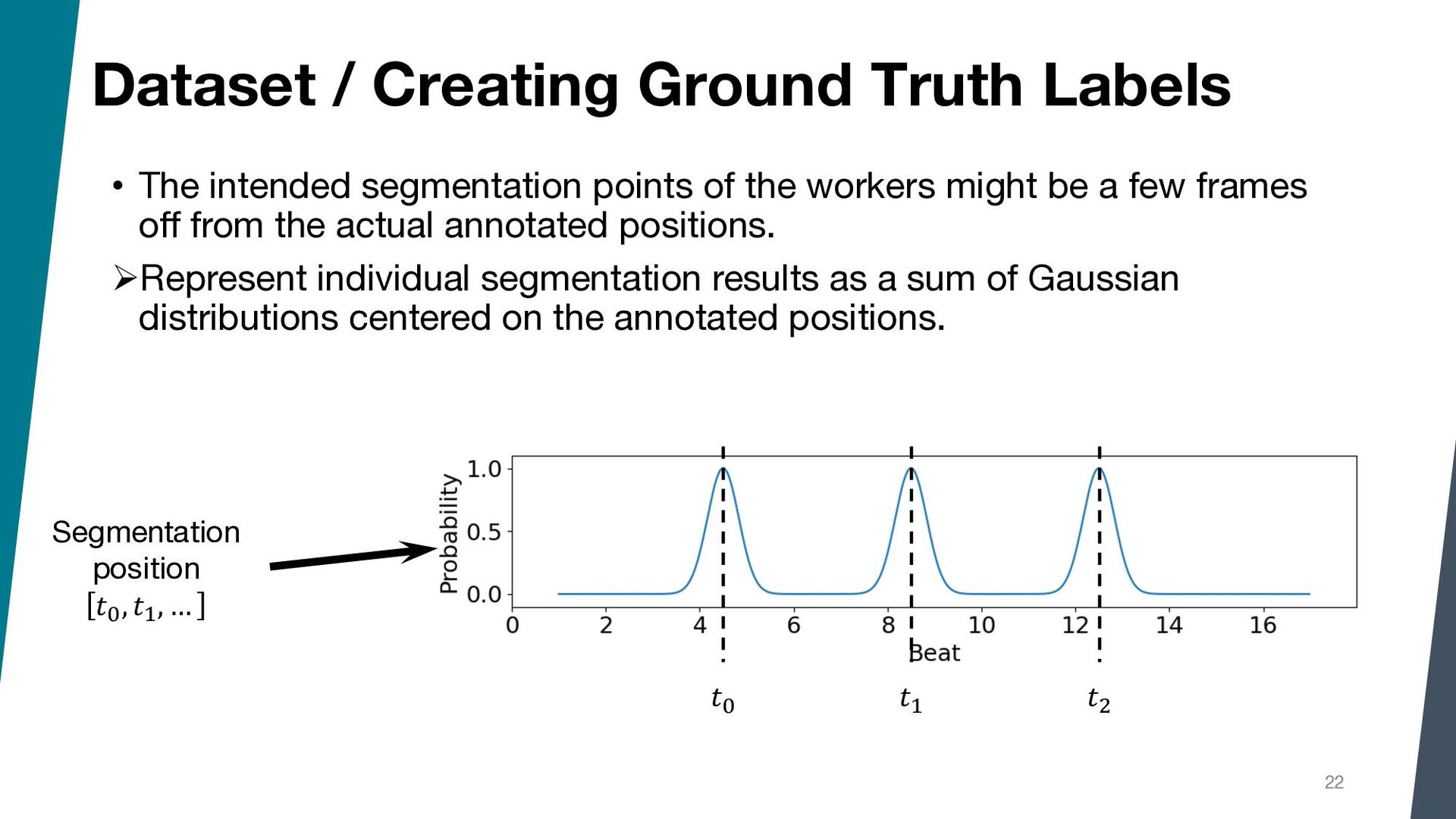{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
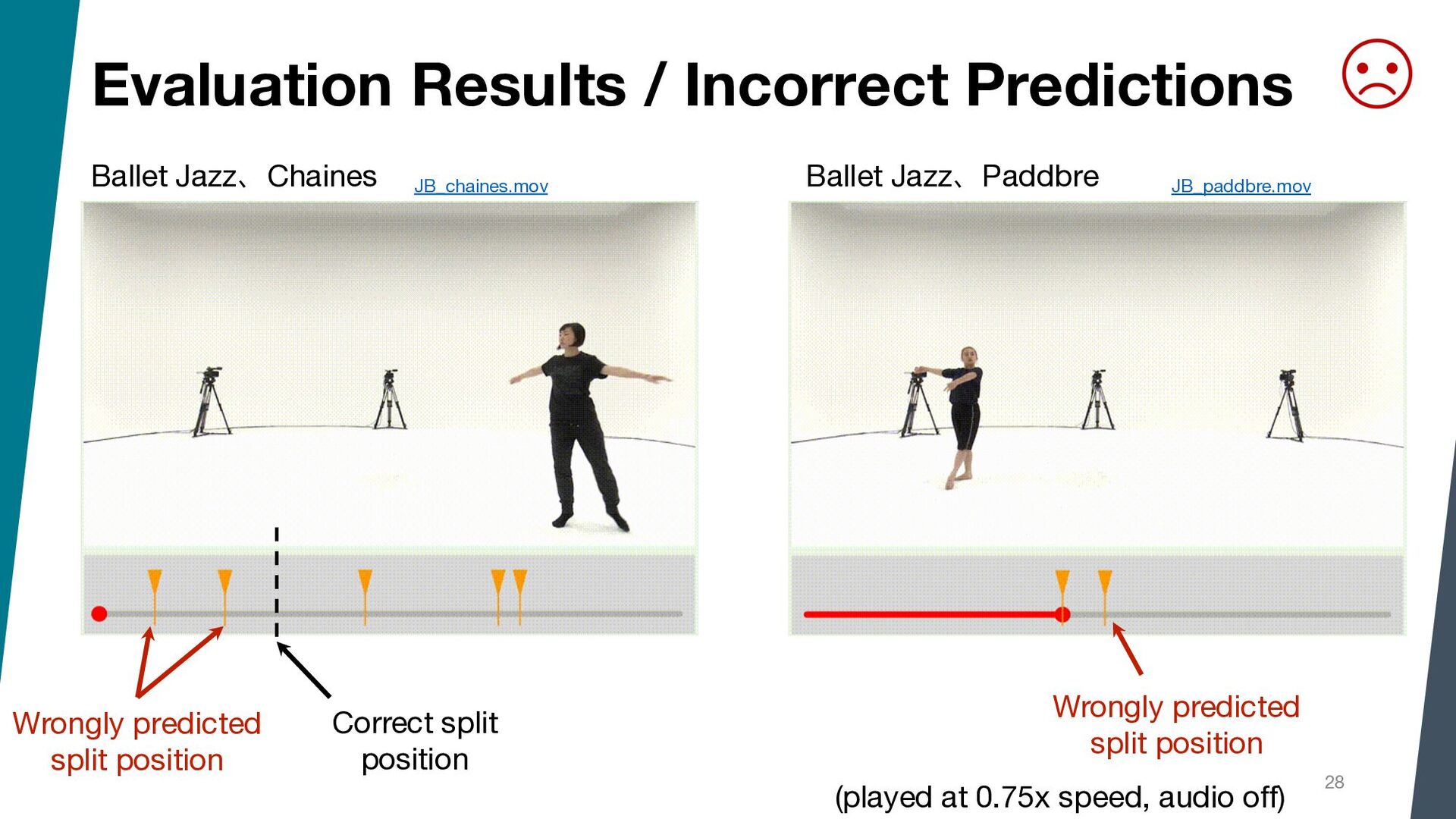{kind=link}
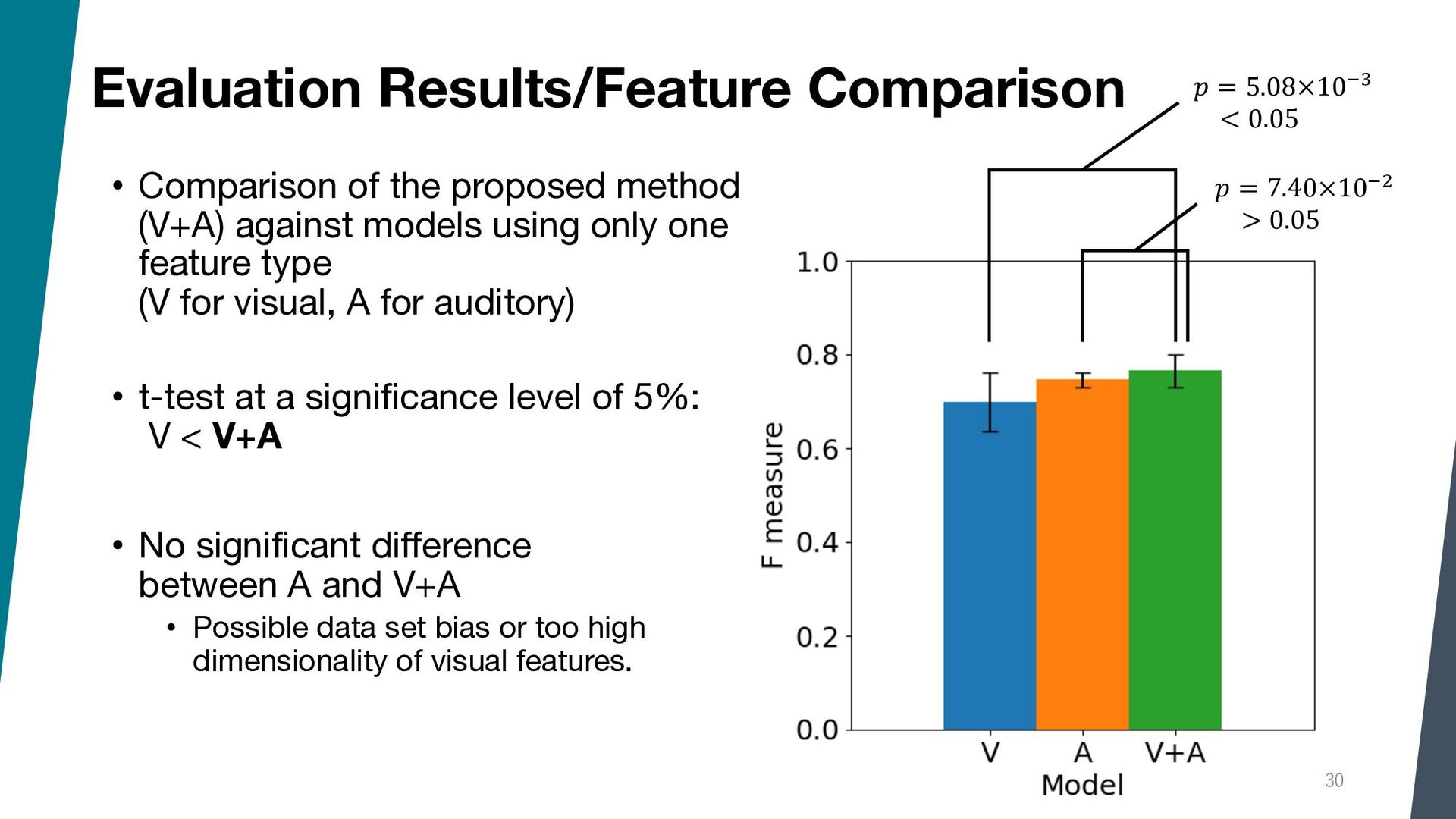{kind=link}
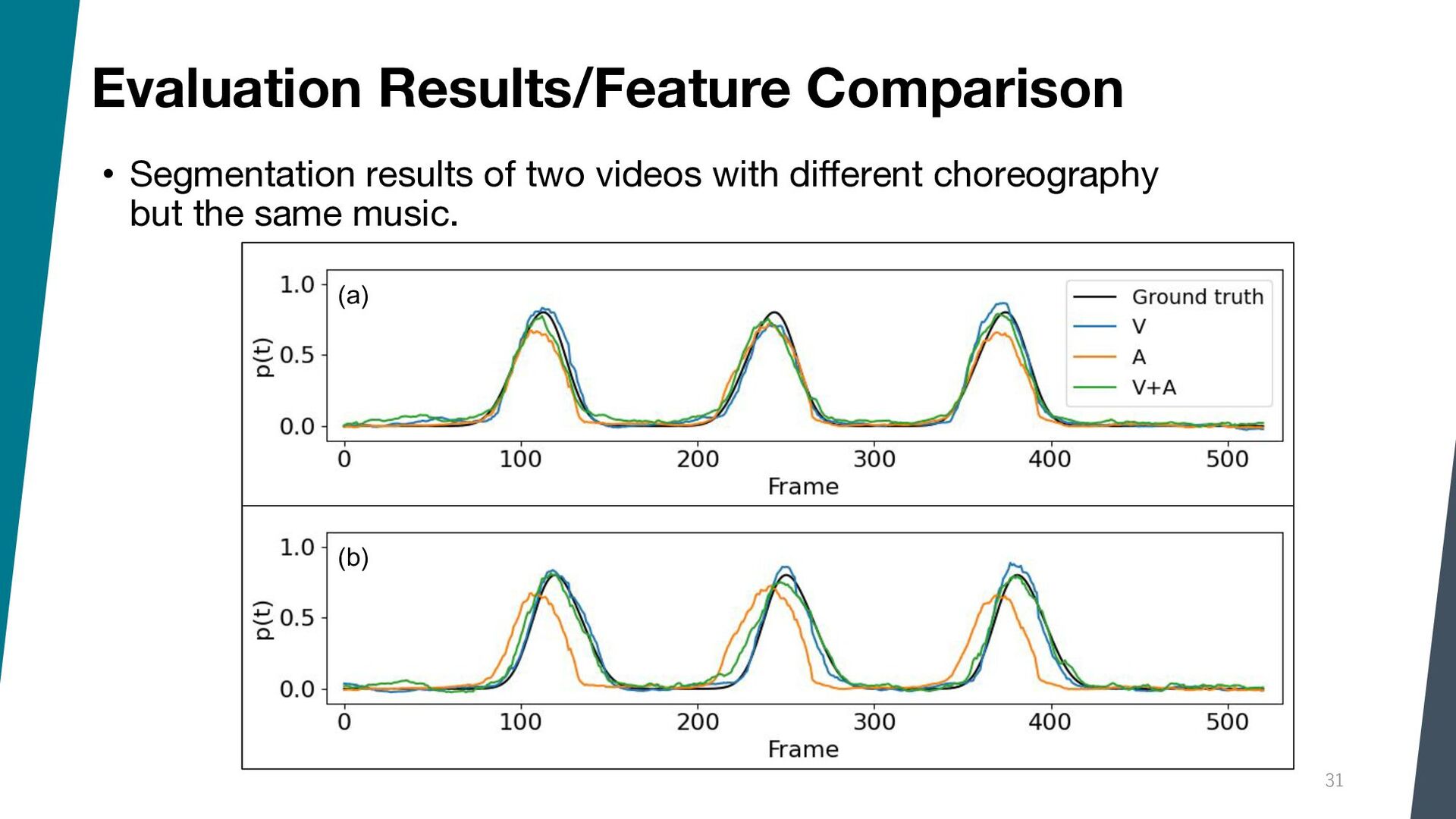{kind=link}
{kind=link}
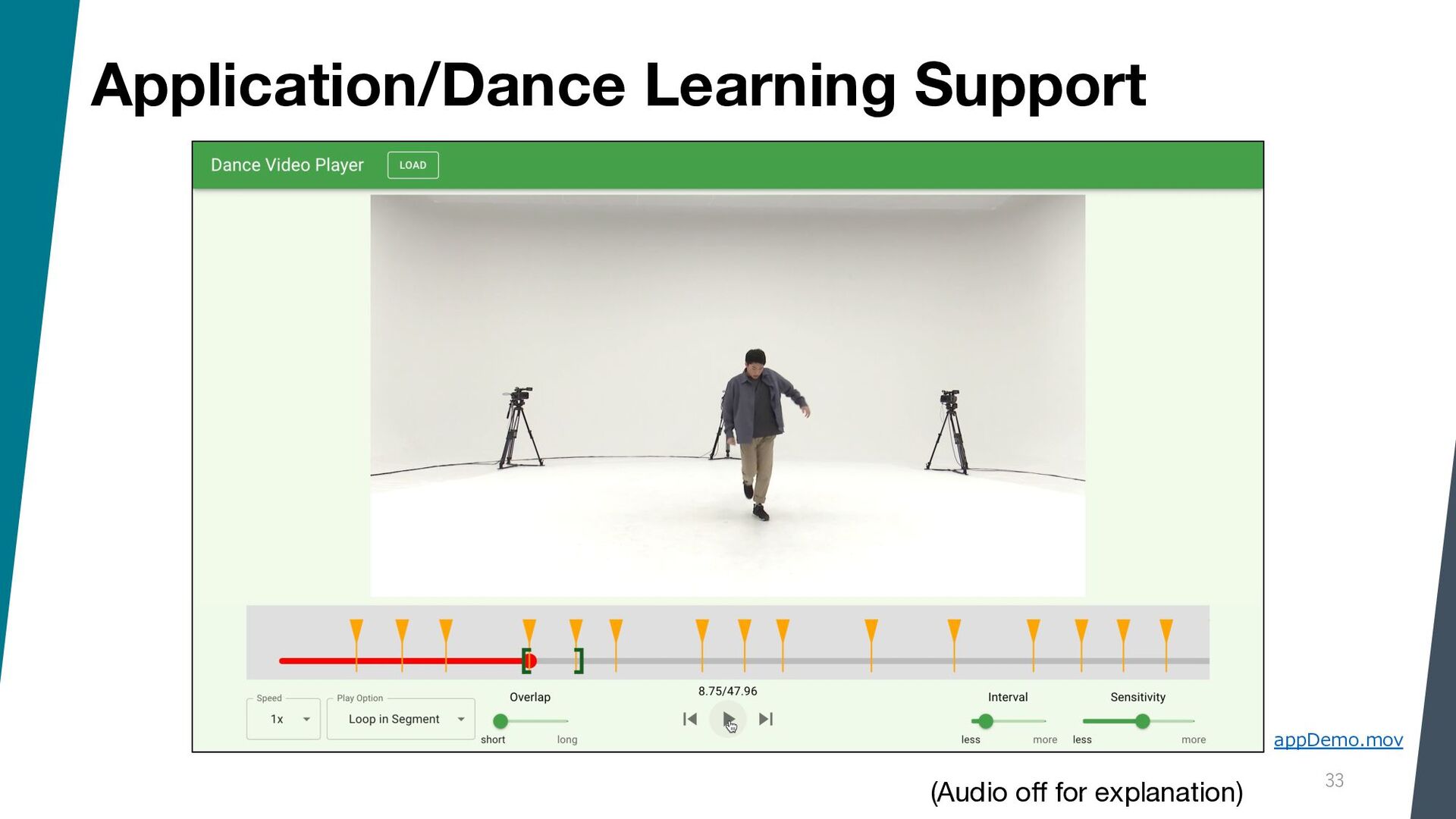{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}