Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AlphaGoの論文について
Search
Shunta Furukawa
April 09, 2016
Technology
93
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AlphaGoの論文について
AlphaGoの論文「Mastering the game of Go with deep neural networks and tree search」について発表した際の資料です。
Shunta Furukawa
April 09, 2016
More Decks by Shunta Furukawa
See All by Shunta Furukawa
パーソナライズド広告配信 における純広告の在庫管理
shuntafurukawa
2
2.6k
Machida Tech Night #2 My Failure on Wally Game with Machine Learning
shuntafurukawa
0
88
Machida Tech Night #1 My First Use of Chainer
shuntafurukawa
0
54
路線認知地図の構築を支援するナビゲーションシステム
shuntafurukawa
1
150
Helpal - Help Exchanging Platform
shuntafurukawa
0
110
Other Decks in Technology
See All in Technology
実践が先生だった— 新卒サーバーエンジニア1年目のリアル
mixi_engineers
PRO
0
220
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
1.2k
SnowflakeCoCoでデータエンジニアリング!
foursue
0
110
組織にどうSREを根付かせるか?〜IVRyの場合〜
abnoumaru
0
240
AI工学特論: MLOps・継続的評価
asei
11
3.1k
エンタープライズデータへ安全につなぐ Production-ready なエージェント設計 ― AI × MCP リファレンスアーキテクチャ ― #AIDevDay
cdataj
1
450
AI時代の強いチームの作り方
yuukiyo
23
13k
A Bag-of-Documents Model for Query Specificity
dtunkelang
0
190
[しろおび夏祭り2026] チャットするAIから、作業するAIへ - 使われ方の変化と、その裏側で起きていること
kk0n
0
730
PLaMo 3.0 Primeの事後学習
pfn
PRO
0
240
「待ち時間」の消滅と「自我消耗」の加速:生成AI時代のエンジニアを救うメンタル・リソース管理
poropinai1966
0
400
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
8
2k
Featured
See All Featured
Google's AI Overviews - The New Search
badams
0
1.1k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
230
First, design no harm
axbom
PRO
2
1.2k
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
650
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
250
A Tale of Four Properties
chriscoyier
163
24k
Color Theory Basics | Prateek | Gurzu
gurzu
0
400
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
64
56k
Claude Code のすすめ
schroneko
67
230k
Balancing Empowerment & Direction
lara
6
1.2k
Designing for humans not robots
tammielis
254
26k
Statistics for Hackers
jakevdp
799
230k
Transcript
Mastering the game of Go with deep neural networks and
tree search @Shunter
About Myself ࣗݾհ
ࣗݾհ 4 ໊લ 4 ݹढ़ଠ 4 ৬ۀ 4 גࣜձࣾ NTTυίϞ
4 ৽نࣄۀ։ൃ 4 ษڧձࢀՃͷಈػ 4 ৽نϏδωεʹਓೳ ͷՄೳੑΛײ͓ͯ͡Γɺ ͖ͪΜͱཧղΛ͍ͨͨ͠ Ίɻ
About Paper จʹ͍ͭͯ
จʹ͍ͭͯ 4 20161݄27ʹɺͦΕ·Ͱ ਓೳ͕উͭ͜ͱ͕͠ ͍ͱݴΘΕ͍ͯͨޟʹ͓͍ ͯɺGoogle(DeepMind) ͕ ։ൃͨ͠ʮAlphaGoʯ͕ϓ ϩΛഁͬͨɻ 4
ͦΕ·Ͱ௨ৗͷޟͰػց͕ϓ ϩʹউͬͨྫ͕ແ͘ɺউͭͷ ʹ10͔͔ΔͱݴΘΕ͍ͯͨ ͜ͱΛୡɻ 4 ຊจ͜ͷʮAlphGoʯʹ ͍ͭͯͷจͰ͋Δɻ
⚪ Background ⚫ എܠ
ͳͥޟ͍͠ͷ͔ʁ 4 ήʔϜͷใɺ ͱ͍͏ՁؔͰදݱͰ͖Δɻ 4 ήʔϜͷঢ়ଶͰɺͦͷঢ়ଶ͔ΒՁʢήʔϜͷ݁ ՌʣΛฦ͢ɻ 4 ήʔϜʹউͭʹɺՁ؍Λͬͯɺ࠷దͳखΛ࠶ؼ తʹܭࢉ͢Ε͍͍ɻ
4 खॱɺ୳ࡧͰදݱ͕Ͱ͖ɺͦͷେ͖͞ Ͱ͋Δɻ 4 : ࣍खͰબՄೳͳީิͷʢ༿ʣ 4 : ήʔϜͷ͞ʢਂ͞ʣ
ͳͥޟ͍͠ͷ͔ʁ 4 : ࣍खͰબՄೳͳީิͷʢ༿ʣ 4 : ήʔϜͷ͞ʢਂ͞ʣ 4 νΣε 4
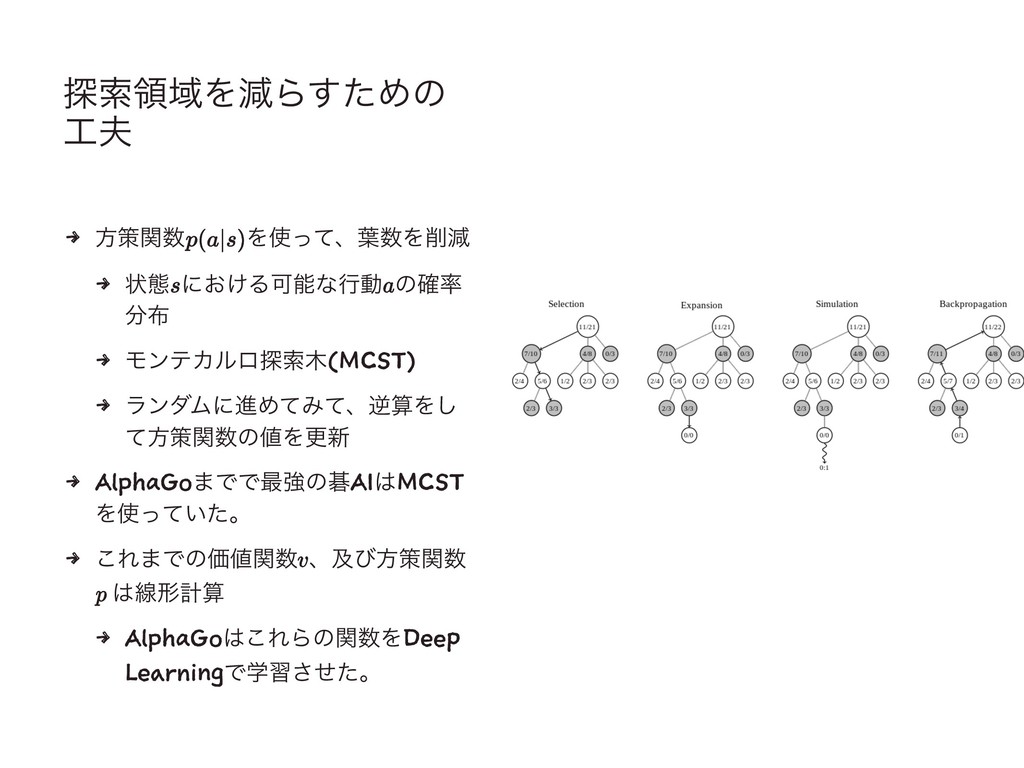
4 4 ޟ 4 4 ! 4 શ෦୳͢ͷݱ࣮త͡Όͳ͍...
୳ࡧྖҬΛݮΒͨ͢Ίͷ 4 ํࡦؔ Λͬͯɺ༿Λݮ 4 ঢ়ଶ ʹ͓͚ΔՄೳͳߦಈ ͷ֬
4 ϞϯςΧϧϩ୳ࡧ(MCST) 4 ϥϯμϜʹਐΊͯΈͯɺٯࢉΛ͠ ͯํࡦؔͷΛߋ৽ 4 AlphaGo·ͰͰ࠷ڧͷޟAIMCST Λ͍ͬͯͨɻ 4 ͜Ε·ͰͷՁؔ ɺٴͼํࡦؔ ઢܗܭࢉ 4 AlphaGo͜ΕΒͷؔΛDeep LearningͰֶशͤͨ͞ɻ
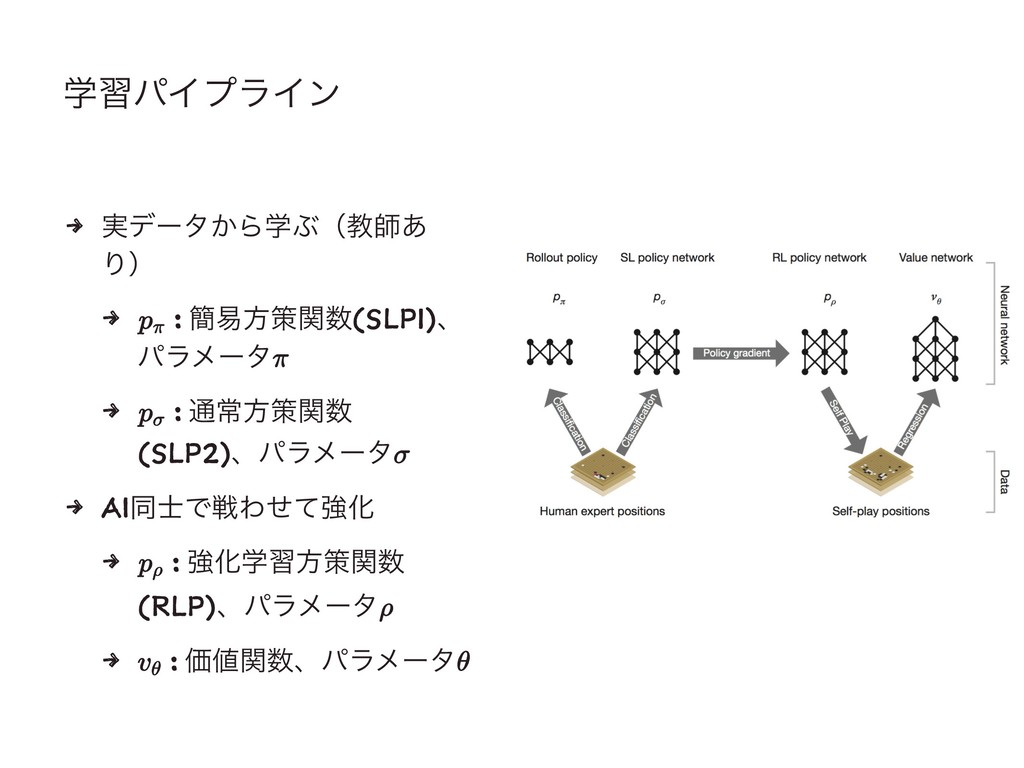
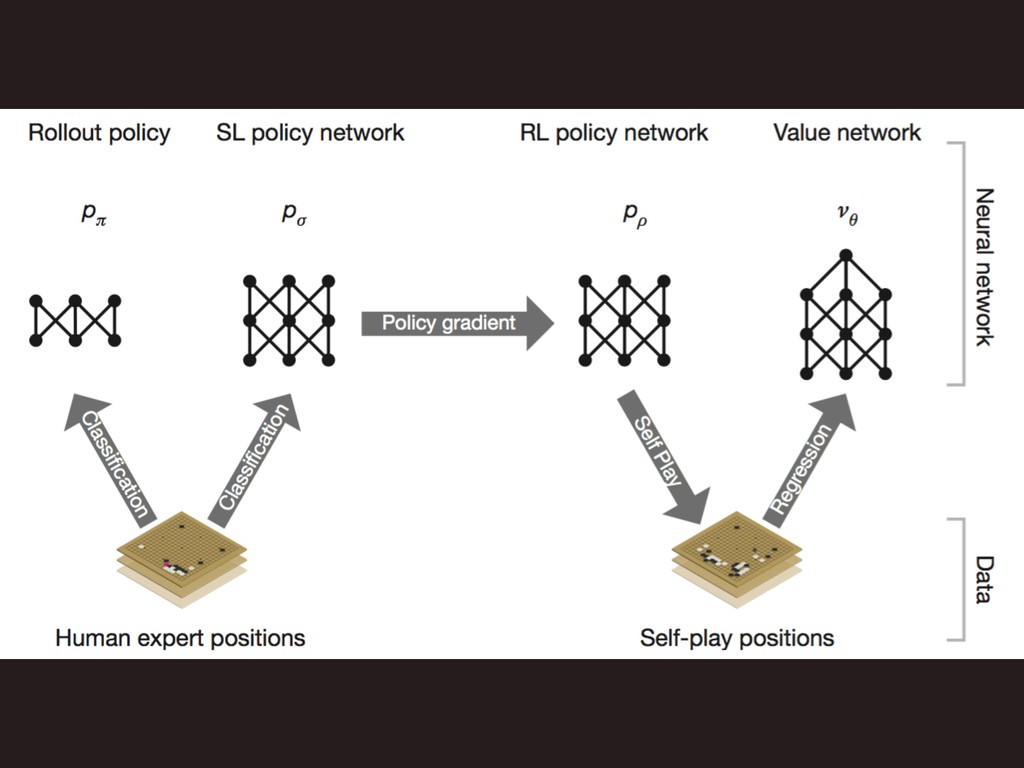
⚪ Pipeline ⚫ ֶशύΠϓϥΠϯ
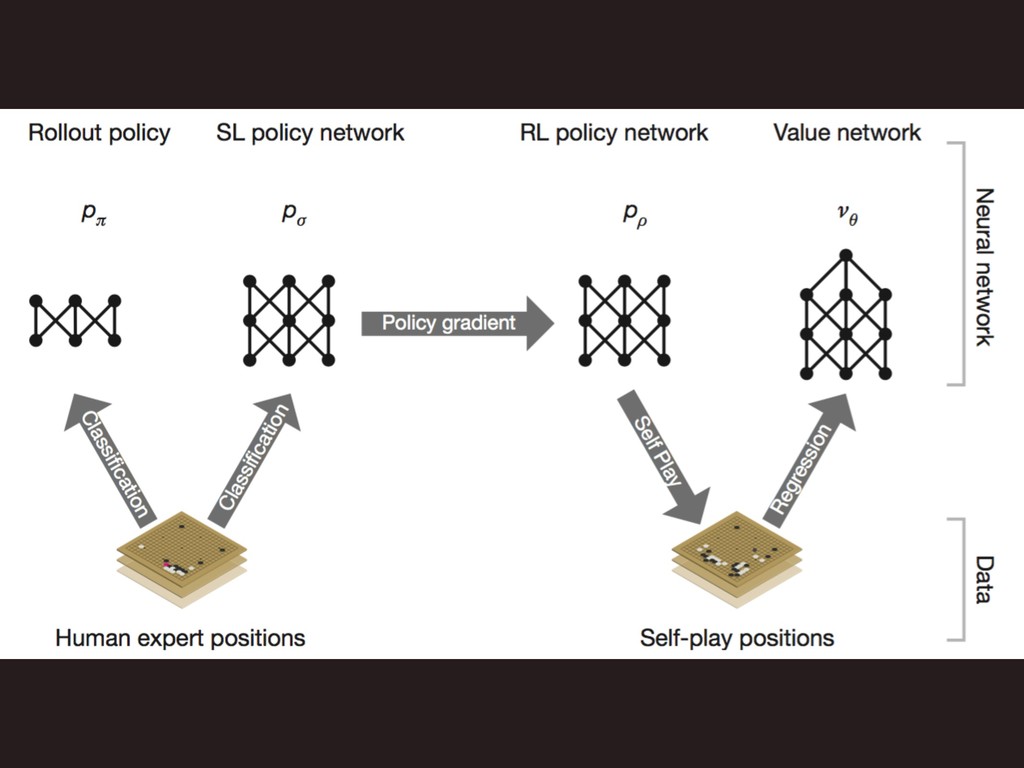
ֶशύΠϓϥΠϯ 4 ࣮σʔλ͔ΒֶͿʢڭࢣ͋ Γʣ 4 : ؆қํࡦؔ(SLP1)ɺ ύϥϝʔλ 4 :
௨ৗํࡦؔ (SLP2)ɺύϥϝʔλ 4 AIಉ࢜ͰઓΘͤͯڧԽ 4 : ڧԽֶशํࡦؔ (RLP)ɺύϥϝʔλ 4 : Ձؔɺύϥϝʔλ
⚪ Supervised leaerning of policy network ⚫ ڭࢣ͋Γֶश ํࡦؔ
None
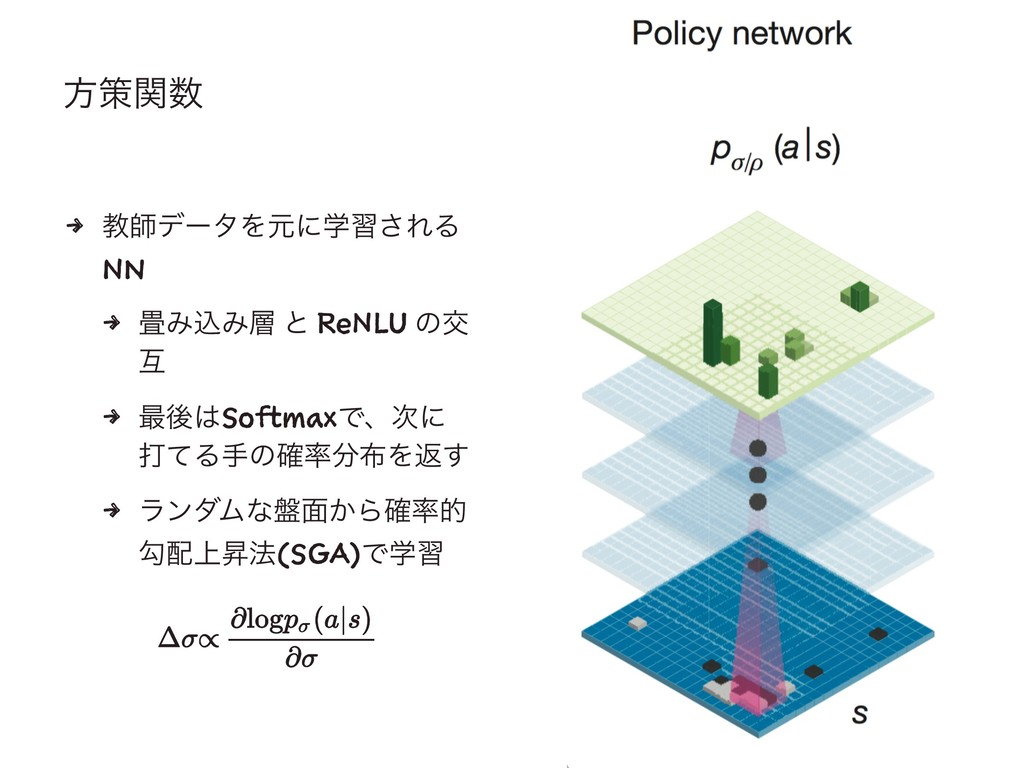
ํࡦؔ 4 ڭࢣσʔλΛݩʹֶश͞ΕΔ NN 4 ΈࠐΈ ͱ ReNLU ͷަ ޓ
4 ࠷ޙSoftmaxͰɺ࣍ʹ ଧͯΔखͷ֬Λฦ͢ 4 ϥϯμϜͳ൫໘͔Β֬త ޯ্ঢ๏(SGA)Ͱֶश
2छྨͷํࡦؔ : ڭࢣ͋Γֶशํࡦؔɺύϥϝʔλ 4 ύϑΥʔϚϯεॏࢹ 4 ҰճͷΞΫγϣϯΛ༧ଌ͢ΔͨΊʹɺ3ms 4 ਖ਼֬ੑ 57.0%
ʢઌߦ༧ଌثͰ44.4%͕࠷ߴʣ : ؆қํࡦؔɺύϥϝʔλ 4 ಛྔΛগͳ͘ɺ׆ੑԽؔʹ ReLUΛͬͨͷ 4 ҰճͷΞΫγϣϯΛ༧ଌ͢ΔͨΊʹɺ2μs 4 ਖ਼֬ੑ 24.2%
⚪ Reinforcement learning of policy networks ⚫ ڧԽֶश ํࡦؔ
None
ڧԽֶश ํࡦؔ 4 ઌ΄Ͳͷํࡦؔͷύϥϝʔλ Λෳ 4 ৽ͨʹํࡦؔ Λ࡞ 4 ํࡦؔಉ࢜ΛͬͯɺઓΘͤΔ
4 ରઓ૬खաڈͷύϥϝʔλͷঢ়ଶ͔ΒϥϯμϜʹ 4 ϥϯμϜʹ͢Δ͜ͱͰաֶशࢭ 4 ใुؔ ΛԾఆɻ 4 : ਐߦ͍ͯ͠Δ࣌ؒ, : ֬ఆͨ࣌ؒ͠ 4 ࢼ߹ΛਐΊͯɺউ͕ͪ1, ෛ͚͕0 4 ࢼ߹͕֬ఆͨ͠ΒใुؔΛͬͯɺḪͬͯ
ڧԽֶश ํࡦؔͷධՁ 4 ڭࢣ͋Γֶशͷํࡦؔ ͱ͘Βͯ 80% ͷউ 4 KGS
ୈ̎Ґͷ࣮ྗͷΦʔϓϯιʔεAIɺPachi ͱରܾ 4 MCS ϕʔεɻ̍ख͋ͨΓ10ສͷݕࡧɻ 4 RLP ͷউ 85% (SLP 11%)
⚪ Reinforcement learning of value networks ⚫ ڧԽֶश Ձؔ
None
Ձ؍ 4 : ϙϦγʔpͷ࣌ʹ͋Δঢ়ଶ͔ΒɺউͯΔظΛฦ͢ 4 ࣮ࡍʹશͳՁ؍( )Λ࡞Δͷ͍͠ͷͰ ઌʹ࡞ͬͨ࠷ڧͷํؔ ( )͔Βࢉग़
: 4 ύϥϝʔλ : 4 ωοτϫʔΫߏɺํؔʹ͍͕ۙɺग़ྗ͕̍ͭɻ 4 ঢ়ଶ(s) ͱ ݁Ռ(z) ͷΈ߹ΘͤΛڭࢣͱֶͯ͠शΛ͍ͯ͘͠ɻ
Ձ؍ͷֶशͷࣦഊ 4 ਓؒͷعේ͚ͩͰֶश͠Α͏ͱ͢Δͱɺաֶश͕ى͖͢ ͍ɻ 4 Ұ࿈ͷعේ࿈ଓ͓ͯ͠Γɺউͪෛ͚ͷใΛҰ؏ͯ͠อ ͍࣋ͯ͠ΔͨΊ 4 MSEֶ͕शσʔλͰ 19%
͕ͩ ݕূσʔλͰ 37% ͱͳͬ ͯ͠·ͬͨɻ 4 RLPͷعේ͔Β3000ສ݅ͷʮผࢼ߹ʯͷ(s,z)ηοτΛநग़ 4 MSEֶ͕शσʔλͰ22.6%, ݕূ༻σʔλͰ 23.4% 4 ̎ͭʹ͕ࠩগͳ͍ͷͰաֶश͍ͯ͠ͳ͍ɻ
⚪ Searching with policy and value networks ⚫ ํͱՁؔʹΑΔݕࡧ
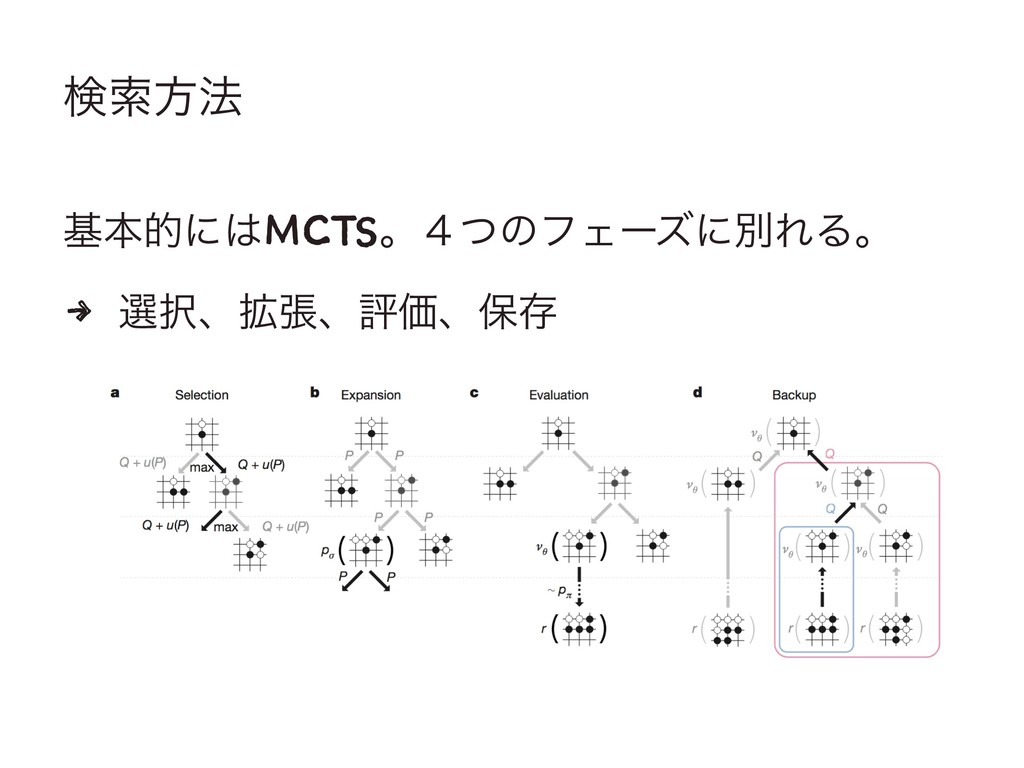
ݕࡧํ๏ جຊతʹMCTSɻ̐ͭͷϑΣʔζʹผΕΔɻ 4 બɺ֦ுɺධՁɺอଘ
બ ( Selection ) 4 ߦಈՁؔQͱϘʔφεؔͷ߹ܭ͕࠷େʹͳΔͷΛબͿɻ 4 Ϙʔφεؔɺͦͷঢ়ଶͷ֬( )ͱ๚ճ( )Ͱܾ·Δɻ
: ڭࢣ͋Γֶशͷํࡦؔ 4 ๚ճ͕૿͑Δ΄ͲɺP͕ݮ͍ͬͯ͘ͷɺ֦ுΛଅਐ͢Δͨ Ί
֦ுͱධՁ ( Expantion & Evaluation ) 4 ͕ࠓ·ͰγϛϡϨʔγϣϯͨ͜͠ͱͳ͍( )ͩ ͬͨ߹ʹɺ༿Λ֦ு͢Δɻ
4 ֦ுͨ͋͠ͱʹɺͦͷʹ͍ͭͯධՁΛߦ͏ɻ(ධՁؔ ) 4 ؆қํࡦؔ ΛͬͯઓΘͤͨ݁Ռ[0,1] 4 ύϥϝʔλ ΛͬͯɺՁ؍ͱૉૣ͍γϛϡϨʔγϣ ϯʹΑΔ݁ՌΛࠞͥ͋Θ͍ͤͯΔɻ
อଘ ( Backup ) 4 γϛϡϨʔγϣϯ͕ऴΘͬͨΒɺ֤༿ϊʔυͷؔΛߋ৽͍ͯ͘͠ɻ 4 ๚ճͱߦಈՁ؍Qͷߋ৽ ճʹ
Λ௨͔ͬͨͲ͏͔ɻ[1,0] γϛϡϨʔγϣϯ͕ऴΘͬͨஈ֊Ͱɺϧʔτ͔Β ͕Ұ൪େ͖͍$ $a$ߦಈΛબ͢Δɻ
ิ 4 ͷܭࢉ ΑΓ ͷ΄͏͕ྑ͍ 4 ͷܭࢉٯɻ ΑΓ ͷ΄͏͕ྑ͍ɻ 4
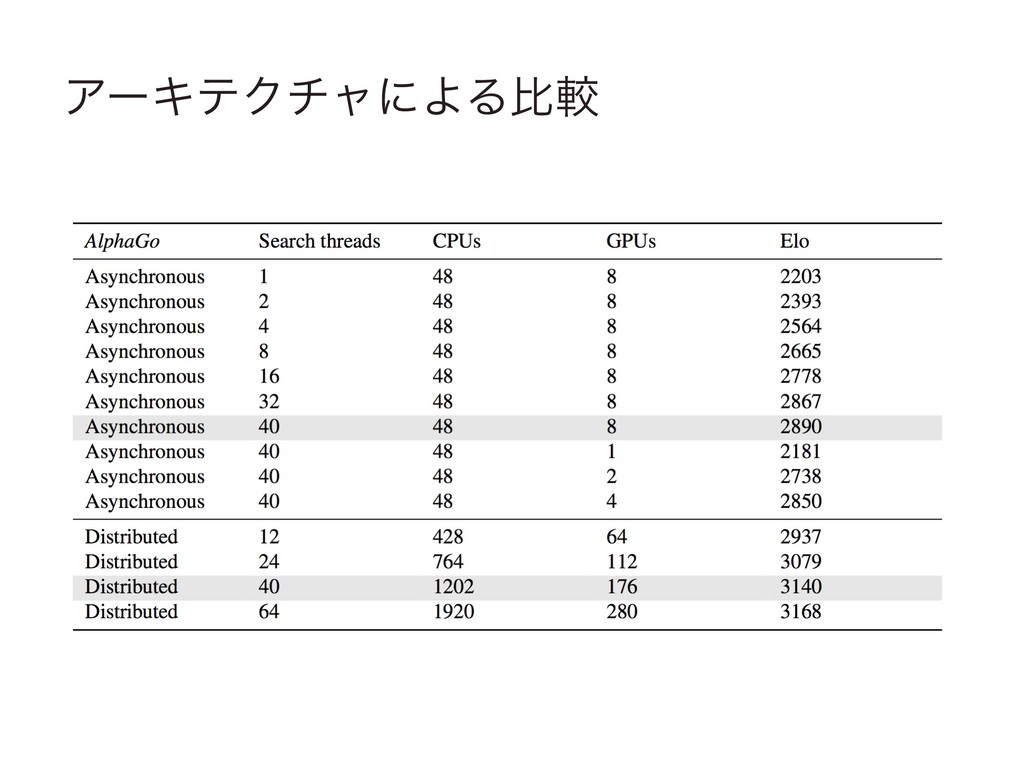
࠷దͳ̍खΛ୳͘͢࠷దԽ͞Ε͓ͯΓɺ֬ͱͯ͠ ͔ͨΑΔɻ 4 ਓؒͷଧͬͨखͷू߹Ͱ͋Γɺଧͪͦ͏ͳखΛΑΓද͍ͯ͠ Δɻ 4 MCTS ͷγϛϡϨʔγϣϯCPUͰඇಉظϚϧνεϨου࣮ߦ 4 Ձ؍ํࡦؔGPUͰฒߦͰॲཧ͍ͯ͠Δɻ 4 AlphaGo 40εϨουɺ48CPUs, 8GPUs 4 ࢄAlphaGo 40εϨουɺ1202CPUsɺ176GPUs
⚪ How Strong Alpha Go is? ⚫ ݁Ռ
ΠϩϨʔτ (WikipediaΑΓ) 4 ήʔϜͷ݁ՌҰํͷউͪɺҰํͷෛ͚ͷΈͱ͠ɺҾ͖͚ߟྀ͠ͳ͍ ʢ0.5উ0.5ഊͱѻ͏ͷͱ͢Δʣɻ 4 200ͷϨʔτ͕ࠩ͋ΔରہऀؒͰɺϨʔτͷߴ͍ଆ͕76ύʔηϯ τͷ֬Ͱউར͢Δɻ 4 ฏۉతͳରہऀͷϨʔτΛ1500ͱ͢Δɻ
4 ఆͰ͋ΓɺϓϩϨϕϧͰ16ɺ௨ৗ32ΛͱΔ͜ͱ͕ଟ͍ɻ
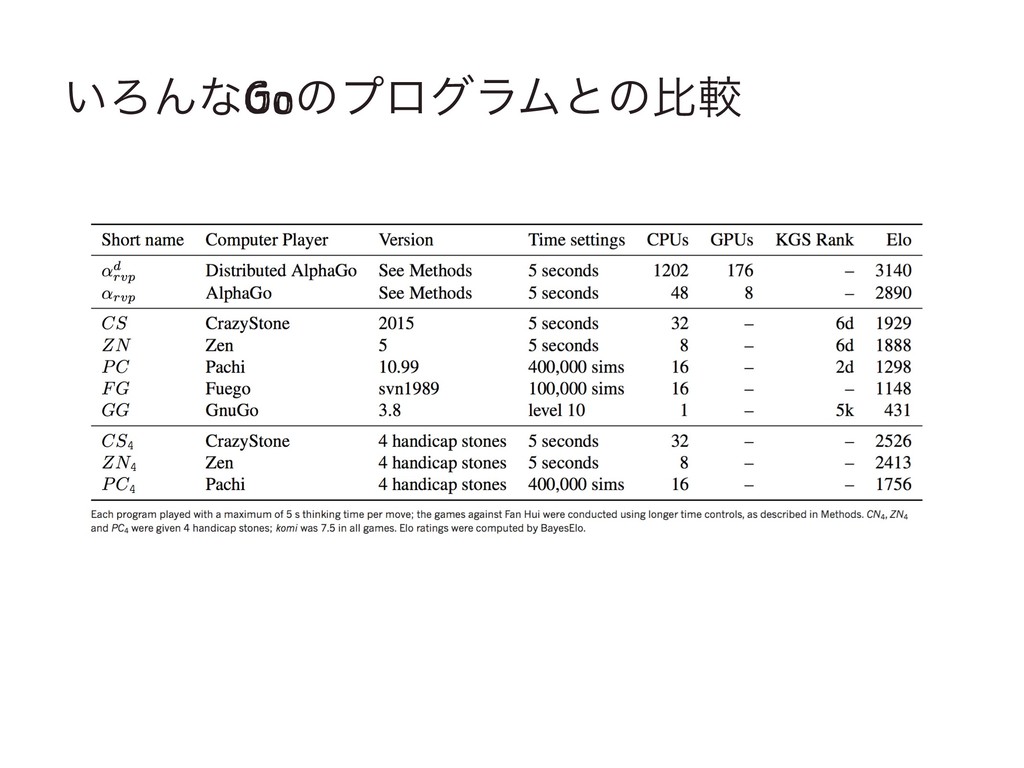
͍ΖΜͳGoͷϓϩάϥϜͱͷൺֱ
͍ΖΜͳGoͷϓϩάϥϜͱͷൺֱ
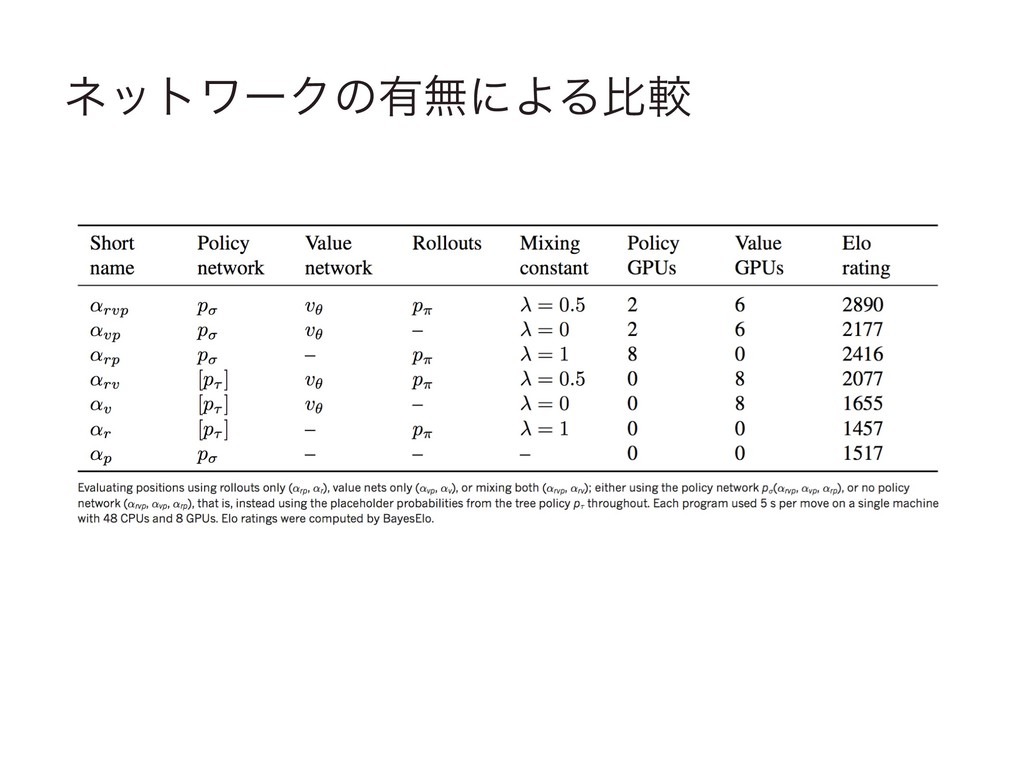
ωοτϫʔΫͷ༗ແʹΑΔൺֱ
ΞʔΩςΫνϟʹΑΔൺֱ
⚪ ͝ਗ਼ௌ͋Γ͕ͱ͏͍͟͝·ͨ͠ɻ ⚫
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}