Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
BigQueryMLハンズオン勉強会
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
yaginuuun
November 09, 2018
Technology
1k
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
BigQueryMLハンズオン勉強会
11/9 ハンズオン勉強会
yaginuuun
November 09, 2018
More Decks by yaginuuun
See All by yaginuuun
メルカリホーム画面におけるレコメンド改善事例 - Long-tailを考慮した辞書拡張
shyaginuma
3
1.7k
メルカリにおけるA/Bテストワークフローの改善 これまでとこれから
shyaginuma
2
2k
メルカリにおけるA/Bテスト標準化への取り組み
shyaginuma
20
14k
A/BテストにおけるVariance reduction
shyaginuma
1
3k
初めての機械学習PJを やってみて得た知見
shyaginuma
2
4.7k
過去コンペベースの学習をやってみたら意外と良かった話
shyaginuma
0
810
Kaggleもくもく会イントロ
shyaginuma
0
260
1on1 SQL Introduction at Globis
shyaginuma
1
1.5k
SlackへのKPI通知Botを作ったら いろいろ捗った話
shyaginuma
1
2.4k
Other Decks in Technology
See All in Technology
論語・武士道・産業革命から見る かわるもの、かわらないもの
ichimichi
7
1.1k
どこまでAIに任せるか 〜確率論と決定論の境界決定〜
shukob
0
520
AI_Dev_Day_製造業領域でのAI活用から見た活用の罠と成功に導く実践知.pdf
kintotechdev
0
210
テックカンファレンス三大ステークホルダーの文化人類学 ─ 違いを認め合う関係性作り
bash0c7
2
630
GoでCコンパイラを作った話
repunit
0
160
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
6
1.5k
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
880
Jitera Company Deck
jitera
0
550
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
510
探索・可視化・自動化を一本化 Amazon Quickでデータ活用スピードを上げる方法
koheiyoshikawa
0
200
発表と総括 / Presentations and Summary
ks91
PRO
0
210
数値で見る Microsoft MVP 〜Spec Kit と GitHub Copilot Agent で作るデータ可視化ダッシュボード〜
yutakaosada
0
150
Featured
See All Featured
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
510
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
610
30 Presentation Tips
portentint
PRO
1
350
Accessibility Awareness
sabderemane
1
160
Deep Space Network (abreviated)
tonyrice
0
230
Design in an AI World
tapps
1
270
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
520
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
780
Transcript
BigQueryMLハンズオン 柳沼 慎哉 グロービス データサイエンティスト 2018/11/9
自己紹介 柳沼 慎哉 - 株式会社グロービス データサイエンティスト - Tableau, DataStudioなどBIツールが得意 -
機械学習、統計学勉強中 twitter : @shinmaidssin Qiita : @s_yaginuma
これの分析やってます - 「BigQuery ML」でSQLを書いて機械学習モデルを構築&予測でき る! - BigqueryMLで作成したモデルをGoogle Data Studioで可視化してみ た
- ビギナーズラックで跳ねた記事: 新米データサイエンティスト、研修プログラムを考える。
Qiita書いてます - 「BigQuery ML」でSQLを書いて機械学習モデルを構築&予測でき る! - BigqueryMLで作成したモデルをGoogle Data Studioで可視化してみ た
アジェンダ - BigQueryMLの概要 - ハンズオン - BigQueryMLの強み、弱み - 懇親会
アジェンダ - BigQueryMLの概要 - ハンズオン - BigQueryMLの強み、弱み - 懇親会
BigQueryMLの概要 ・BigQuery:SQLライクなクエリを用いて大規模なデータに対しても高速 に結果を返すことのできるDW ・BigQueryML:BigQueryのクエリエディタ上からSQLを書くように機械学 習モデルの構築、評価、予測ができる Docs : すべての BigQuery ML
ドキュメント
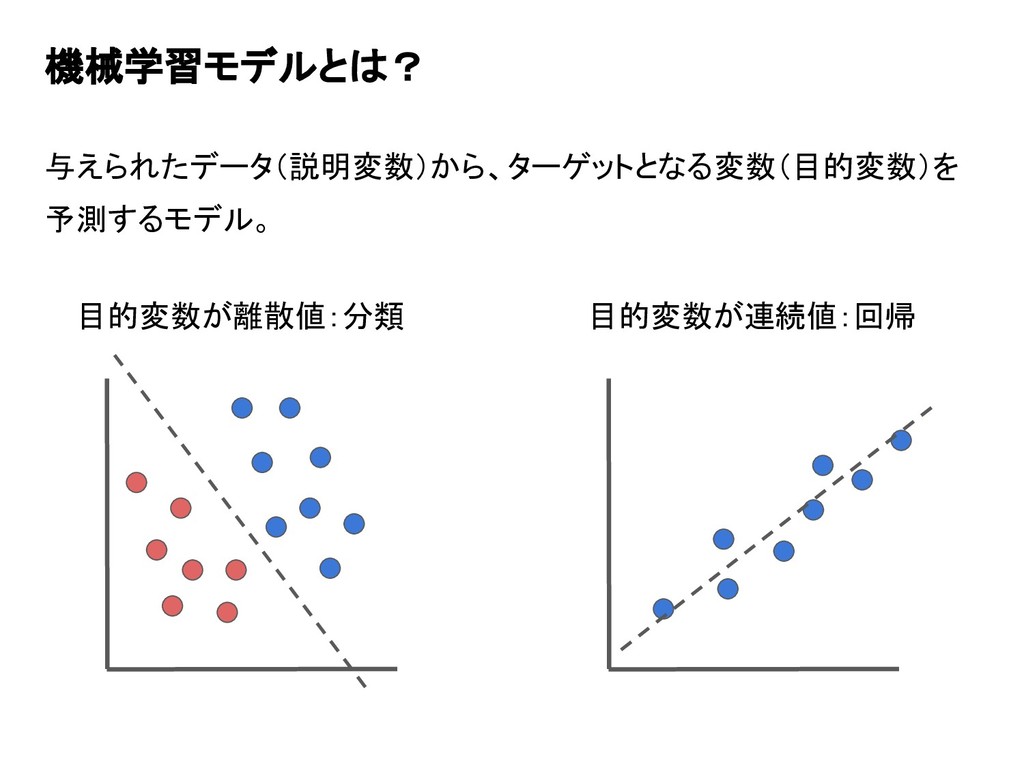
機械学習モデルとは? 与えられたデータ(説明変数)から、ターゲットとなる変数(目的変数)を 予測するモデル。 目的変数が離散値:分類 目的変数が連続値:回帰
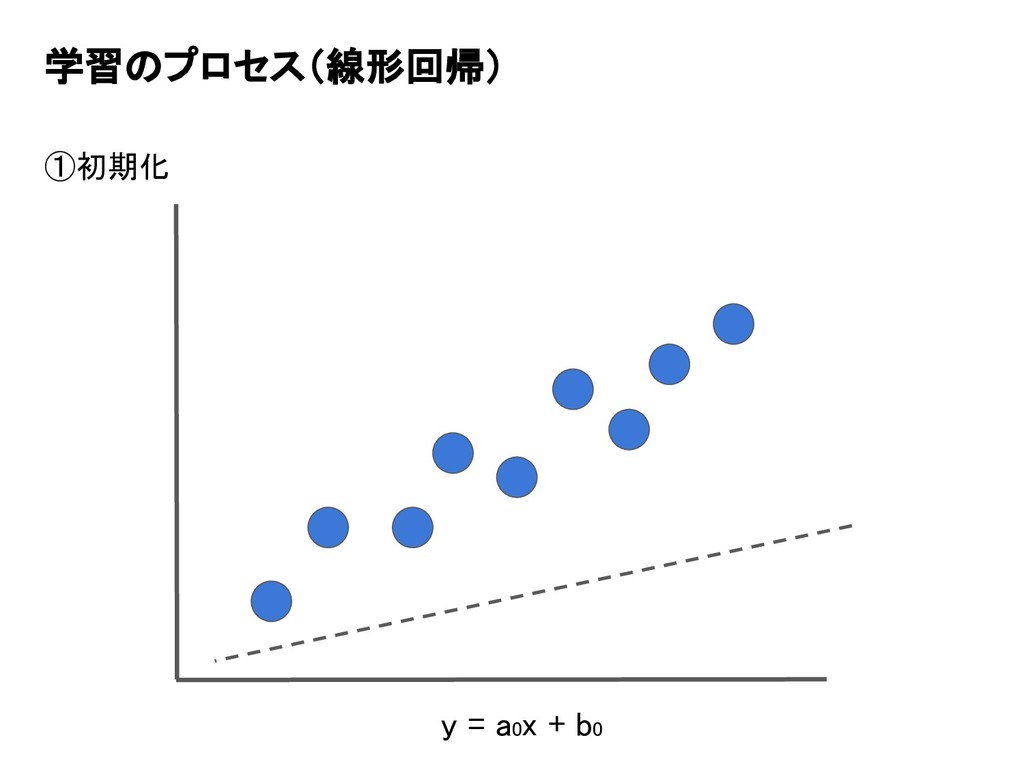
学習のプロセス(線形回帰) ①初期化 y = a0x + b0
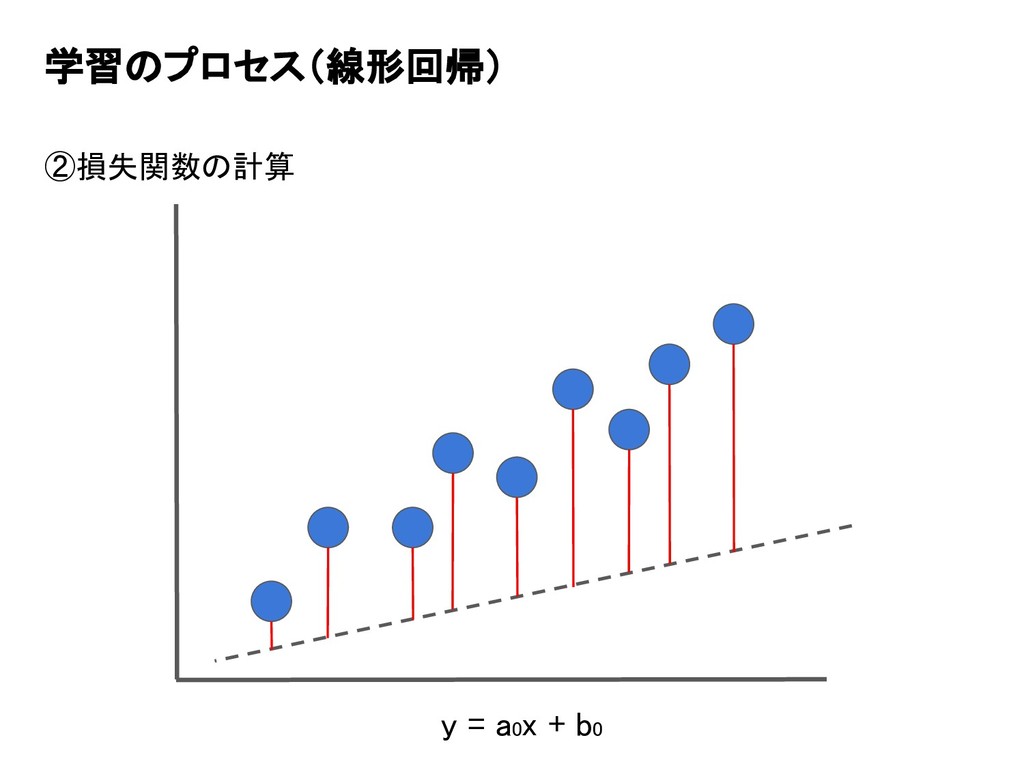
学習のプロセス(線形回帰) ②損失関数の計算 y = a0x + b0
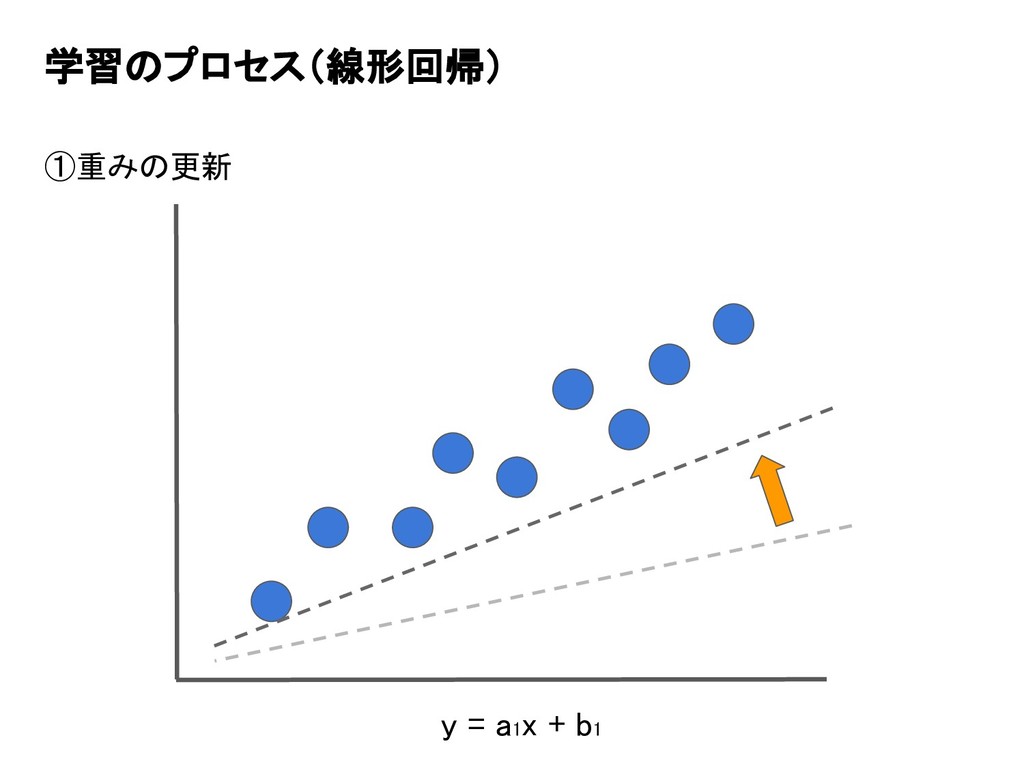
学習のプロセス(線形回帰) ①重みの更新 y = a1x + b1
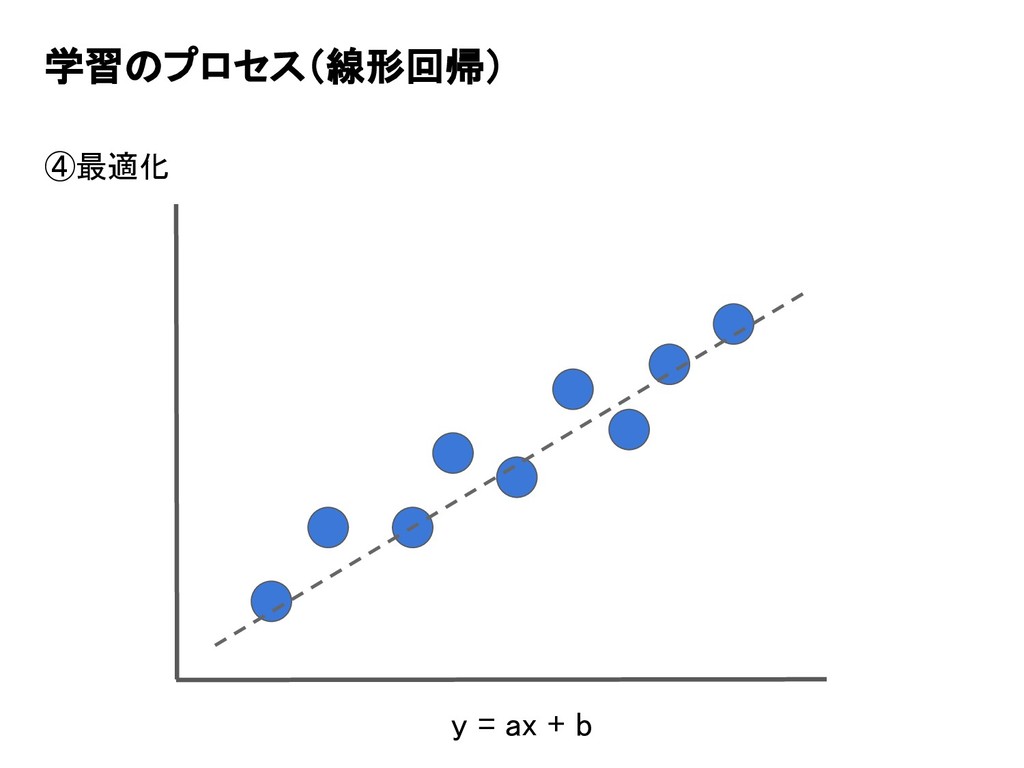
学習のプロセス(線形回帰) ④最適化 y = ax + b
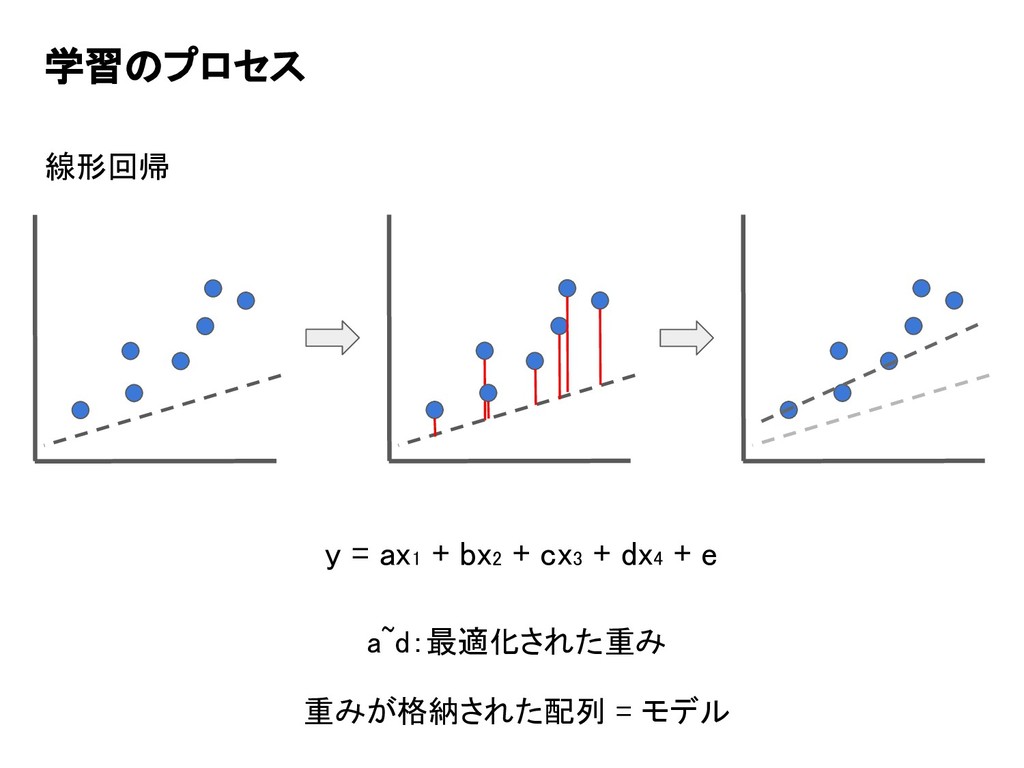
学習のプロセス 線形回帰 y = ax1 + bx2 + cx3 +
dx4 + e a~d:最適化された重み 重みが格納された配列 = モデル
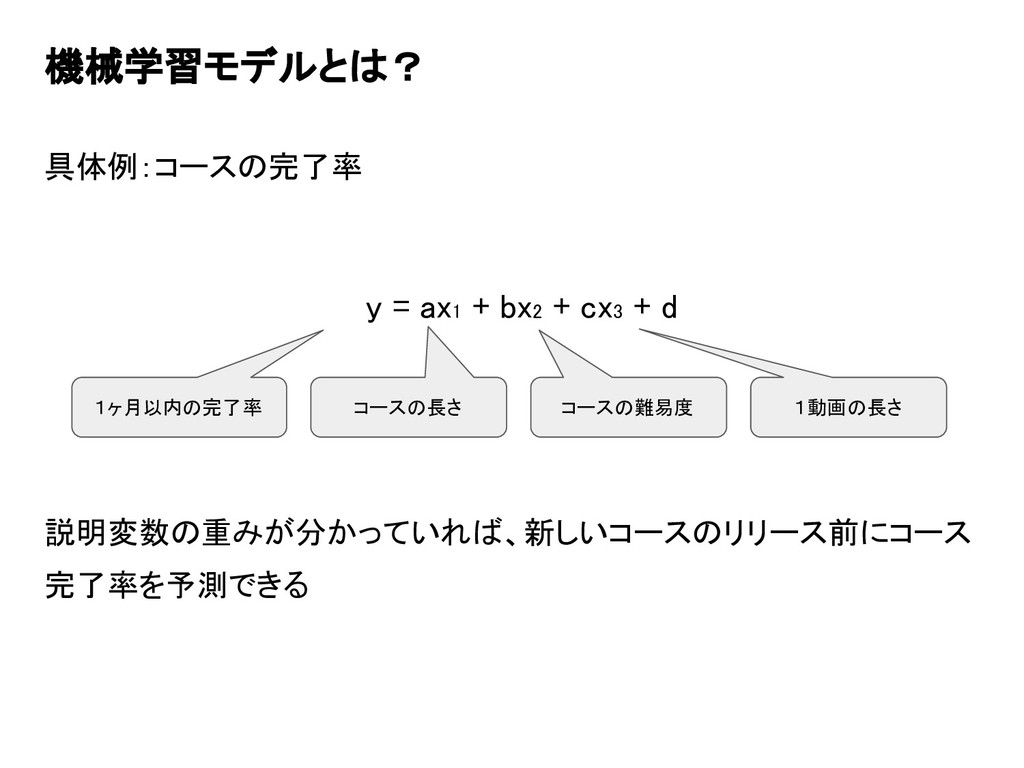
機械学習モデルとは? 具体例:コースの完了率 y = ax1 + bx2 + cx3 +
d 1ヶ月以内の完了率 コースの長さ コースの難易度 1動画の長さ 説明変数の重みが分かっていれば、新しいコースのリリース前にコース 完了率を予測できる
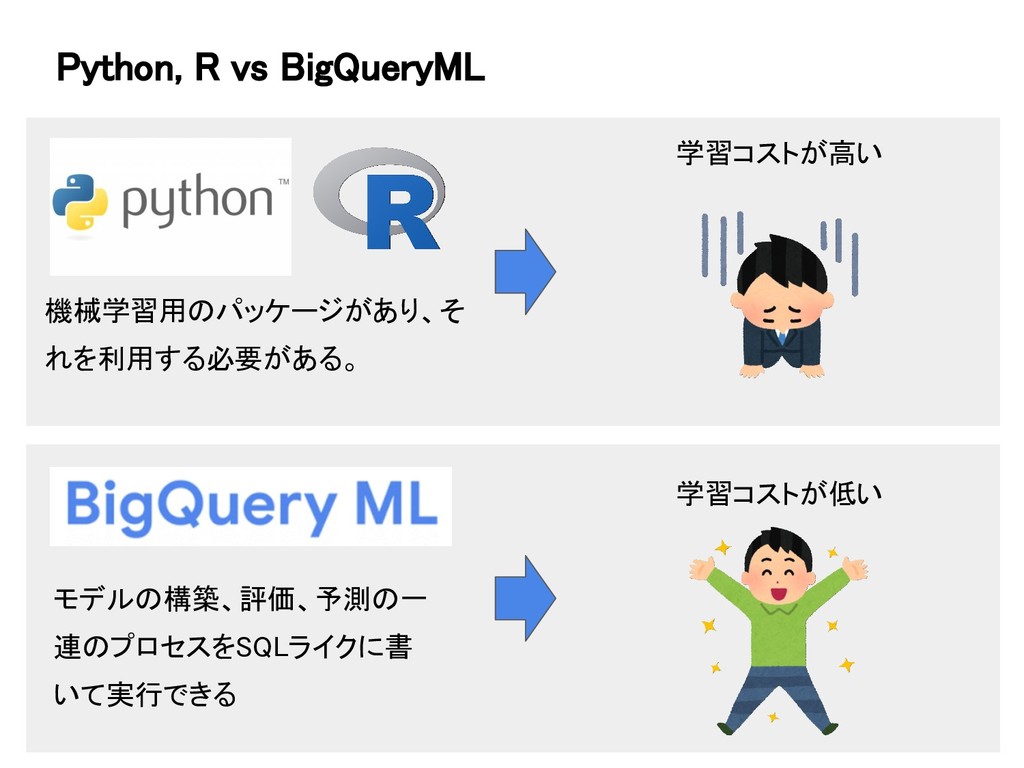
Python, R vs BigQueryML 機械学習用のパッケージがあり、そ れを利用する必要がある。 モデルの構築、評価、予測の一 連のプロセスをSQLライクに書 いて実行できる 学習コストが高い
学習コストが低い
アジェンダ - BigQueryMLの概要 - ハンズオン - BigQueryMLの強み、弱み - 懇親会
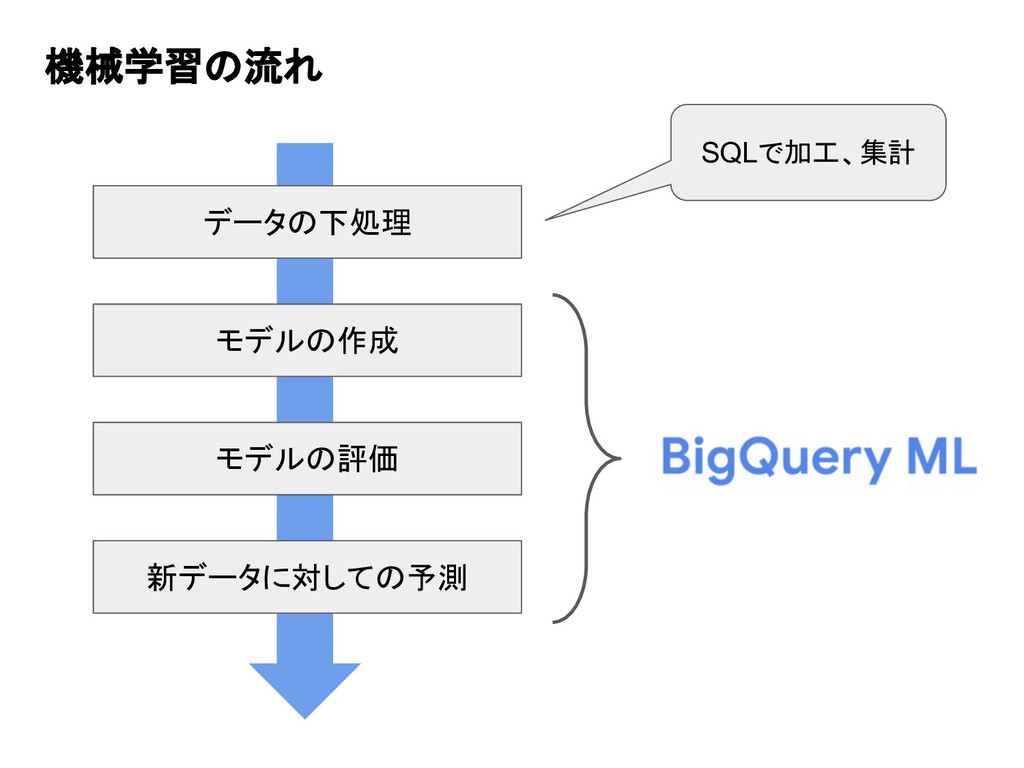
機械学習の流れ データの下処理 モデルの作成 モデルの評価 新データに対しての予測 SQLで加工、集計
Boston Housing データ ・ボストン近辺の住宅価格の予測 https://www.kaggle.com/c/boston-housing
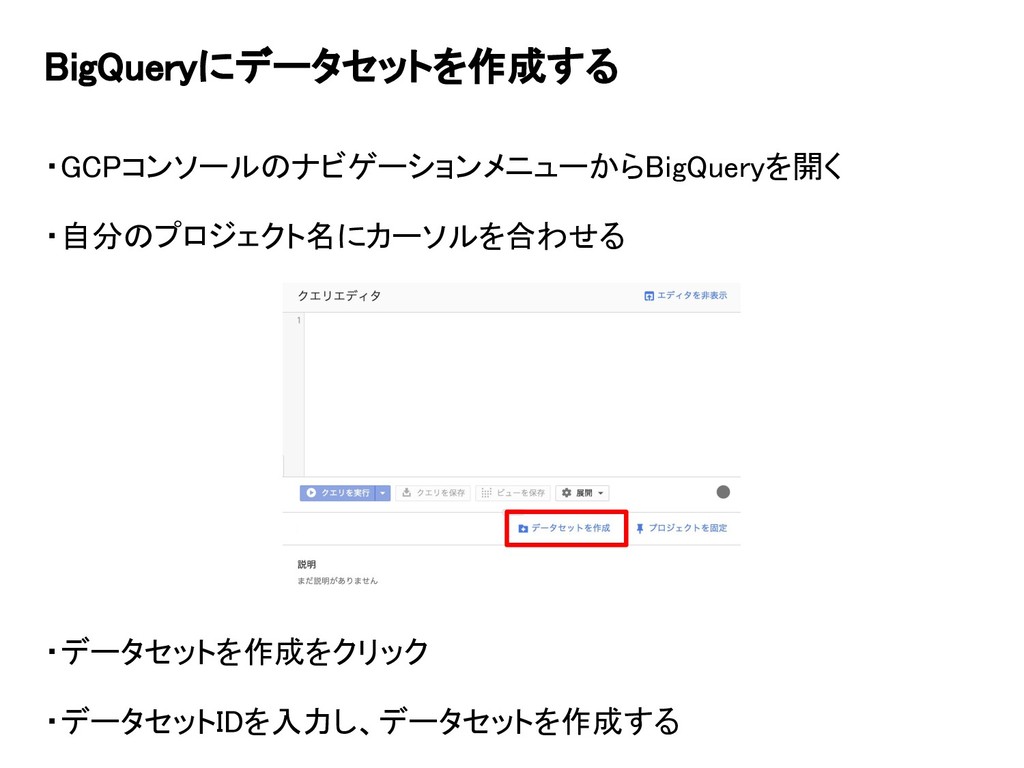
BigQueryにデータセットを作成する ・GCPコンソールのナビゲーションメニューからBigQueryを開く ・自分のプロジェクト名にカーソルを合わせる ・データセットを作成をクリック ・データセットIDを入力し、データセットを作成する
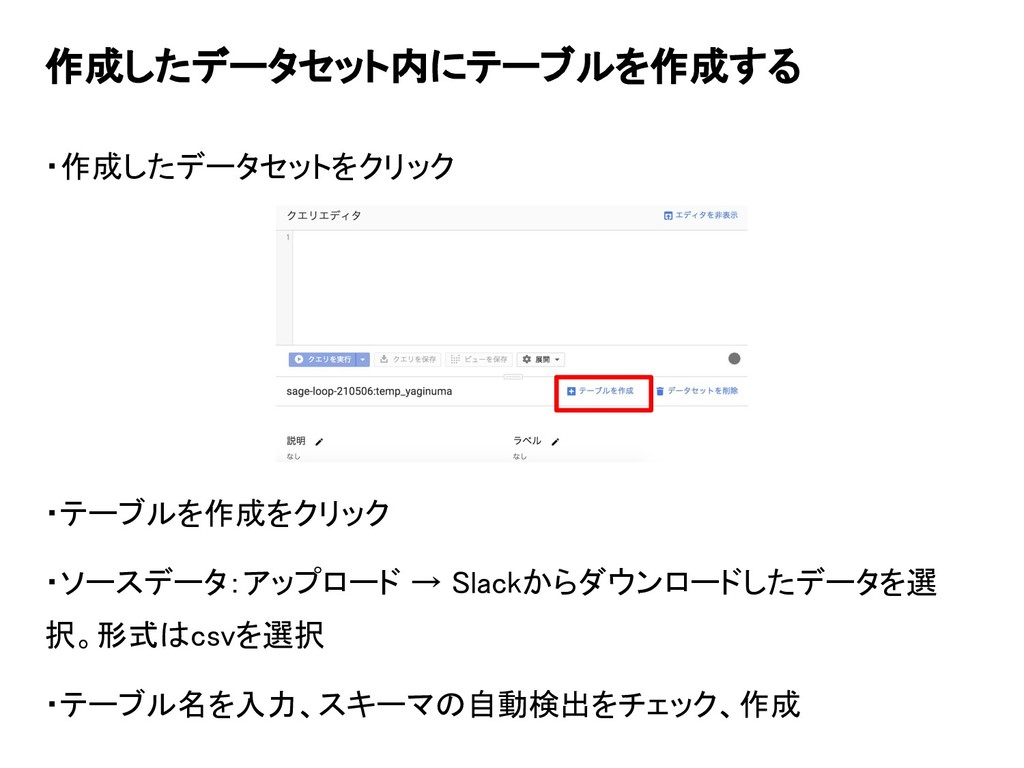
・作成したデータセットをクリック ・テーブルを作成をクリック ・ソースデータ:アップロード → Slackからダウンロードしたデータを選 択。形式はcsvを選択 ・テーブル名を入力、スキーマの自動検出をチェック、作成 作成したデータセット内にテーブルを作成する
データの中身 - 目的変数 - medv : 区画の家の値段の中央値(/1000$) - 説明変数(13個): -
crim : 犯罪発生率 - zn : 住宅地の割合 - indus : 非小売業種の割合 - chas : チャールズ川の河川境界線かどうか - nox : 窒素酸化物濃度 - rm : 住居あたりの部屋数 - age : 1940年以前に建設された建物の割合 - dis : 5つのボストン雇用センターまでの距離の加重平均 - rad : 高速道路へのアクセスの良さ - tax : 1万ドルあたりの固定資産税率 - ptratio : 生徒と教師の比率 - black : 黒色人種居住者の割合 - lstat : 低所得者の割合
機械学習モデルの作成 CREATE MODEL ステートメント CREATE MODEL `<データセット名>.<モデル名>` OPTIONS( model_type='<使用するアルゴリズム>', input_label_cols=['<ターゲットのカラム名>'],
...) AS ( SELECT <学習に使用するデータを抽出するクエリ> ...)
トレーニングデータと評価データについて データ ・NGなケース 学習用 評価用 モデルは学習データに対して適合するので、評価用データに学習用 データと同じものを使うと実際よりも高い精度で予測され、真に未知の データに対しての予測性能が測定できない!
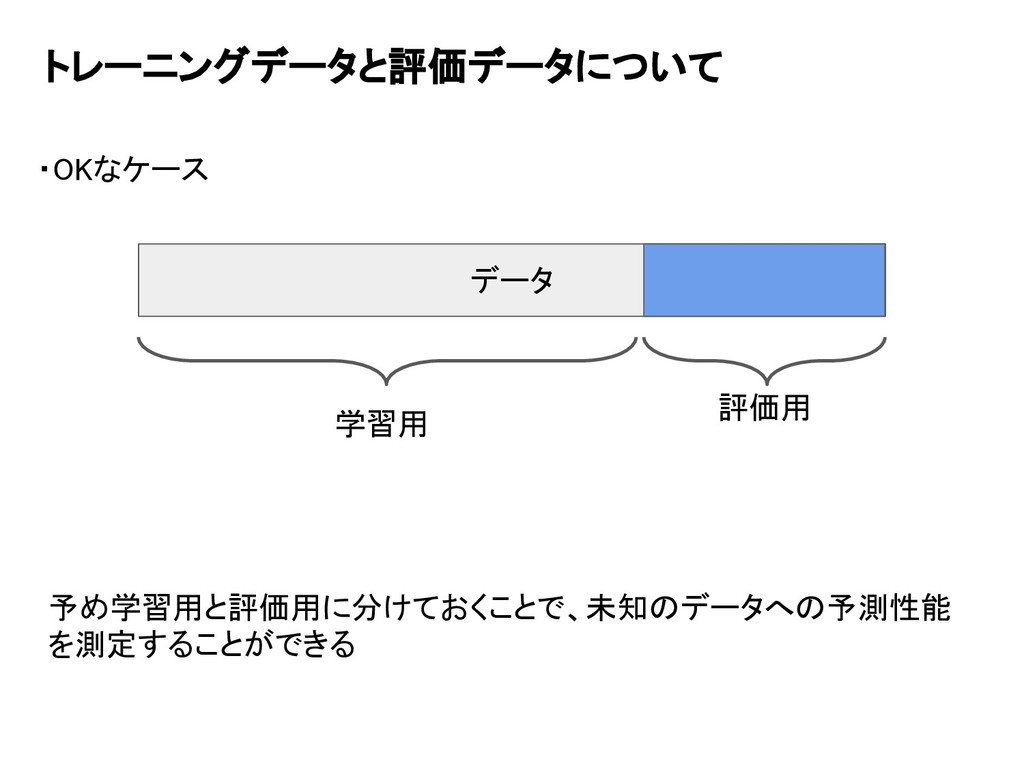
トレーニングデータと評価データについて データ ・OKなケース 学習用 評価用 予め学習用と評価用に分けておくことで、未知のデータへの予測性能 を測定することができる
機械学習モデルの評価 ML.EVALUATE 関数 SELECT * FROM ML.EVALUATE(MODEL `<モデル名>`, (<モデル作成に使用した特徴量を抽出するクエリ>))
モデルの評価 出力される評価指標: - mean_absolute_error:平均絶対値誤差 - mean_squared_error:平均二乗誤差 - mean_squared_log_error:平均二乗対数誤差 - median_absolute_error:絶対値誤差の中央値
- r2_score:決定係数 - explained_variance:因子寄与 平均二乗誤差:データに対するズレ → 低い方が良い 決定係数:データに対する当てはまり → 1に近い方が良い
作成したモデルで予測 ML.PREDICT 関数 SELECT * FROM ML.PREDICT(MODEL `<モデル名>`, (<予測するのに必要な特徴量を抽出するクエリ>))
特徴量の重みの確認 ML.WEIGHTS 関数 SELECT * FROM ML.WEIGHTS(MODEL `<モデル名>` y =
ax1 + bx2 + cx3 + d
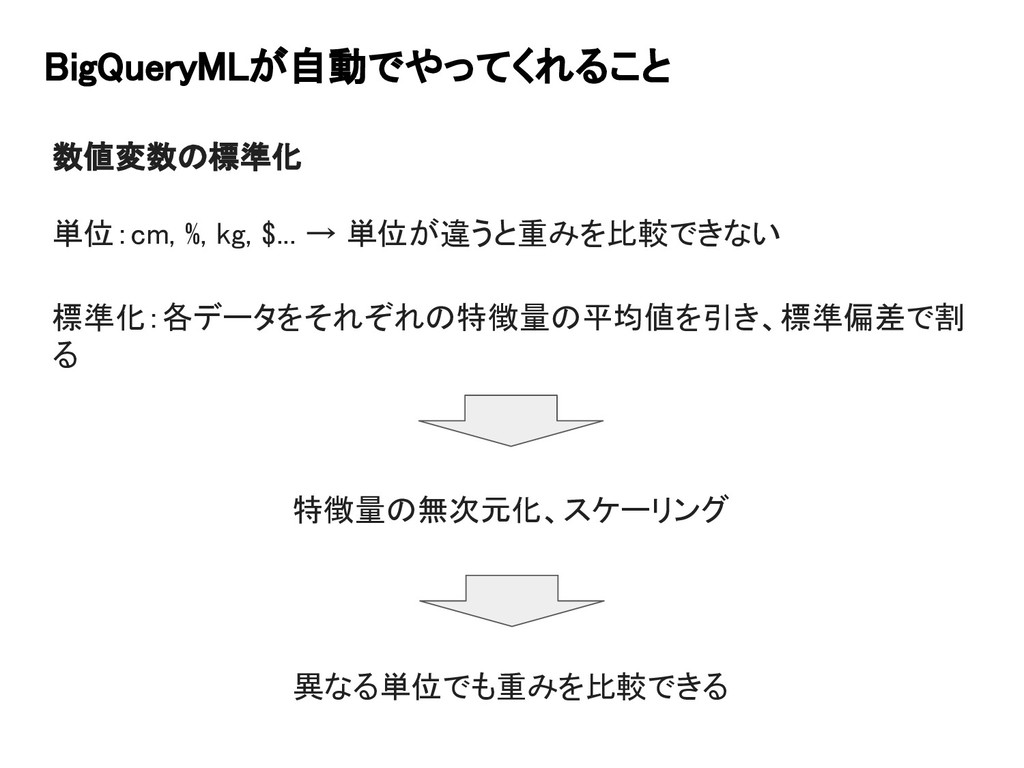
BigQueryMLが自動でやってくれること 数値変数の標準化 単位:cm, %, kg, $... → 単位が違うと重みを比較できない 標準化:各データをそれぞれの特徴量の平均値を引き、標準偏差で割 る
特徴量の無次元化、スケーリング 異なる単位でも重みを比較できる
分類:アイリスデータの分類 BigQueryMLで多クラス分類が可能に! Google Cloud ブログ 折角なのでやってみましょう。
分類:アイリスデータの分類 - 特徴量: - sepal length(cm) - sepal width(cm) -
petal length(cm) - petal width(cm) - クラス: - Setosa - Versicolour - Virginica
手順: - BigQueryにアイリスデータを読み込む - iris/create_model.sqlでモデルを作成 - iris/evaluate_model.sqlでモデルを検証 - iris/predict.sqlで予測結果を出力
分類モデルの評価 出力: - 予測値 - 予測確率
アジェンダ - BigQueryMLの概要 - ハンズオン - BigQueryMLの強み、弱み - 懇親会
BigQueryMLの良いところ - 簡単! - データと同じ場所にモデルを置いておける - BIツールと連携しやすい(可視化) - 自動で色々やってくれる(データの分割、標準化)
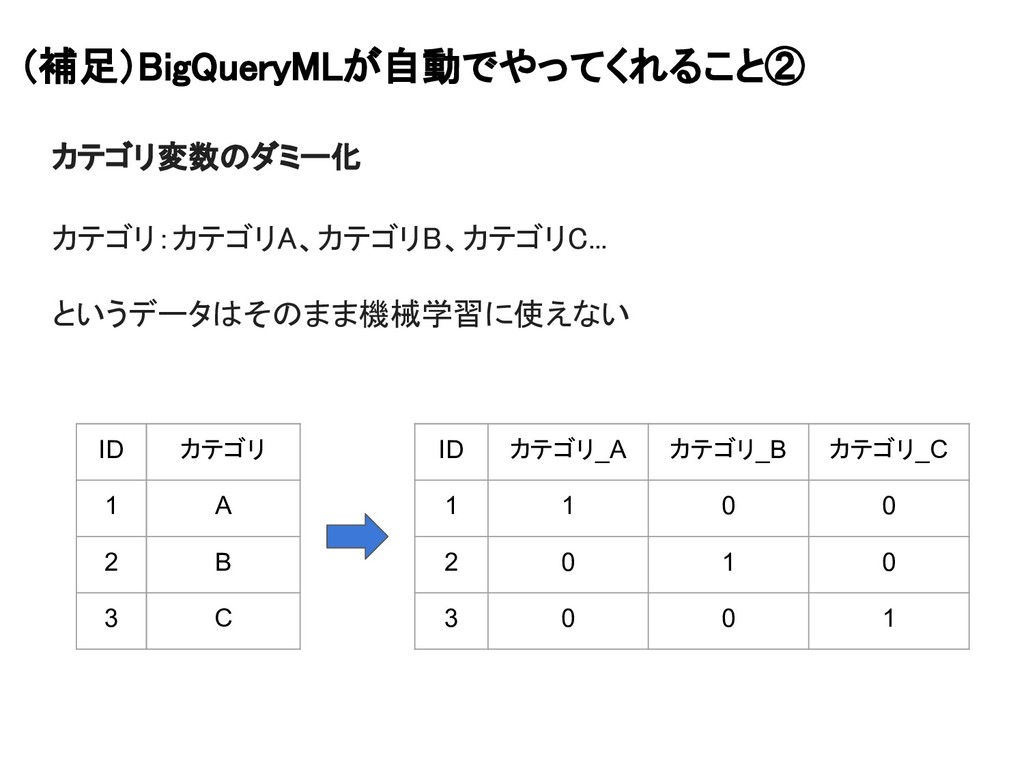
(補足)BigQueryMLが自動でやってくれること② カテゴリ変数のダミー化 カテゴリ:カテゴリA、カテゴリB、カテゴリC... というデータはそのまま機械学習に使えない ID カテゴリ 1 A 2 B
3 C ID カテゴリ_A カテゴリ_B カテゴリ_C 1 1 0 0 2 0 1 0 3 0 0 1
BigQueryMLの微妙なところ - 現状使用可能なモデルが少ない - BigQueryML単体だと可視化ができない - パラメータサーチがしづらい
BigQueryMLの微妙なところ 現状使用可能なモデルが少ない 機械学習 教師あり学習 教師なし学習:未対応 回帰:線形回帰のみ 分類:ロジスティック回帰のみ クラスタリングや、人気のあるランダムフォレストなどの手法に対応して いない。
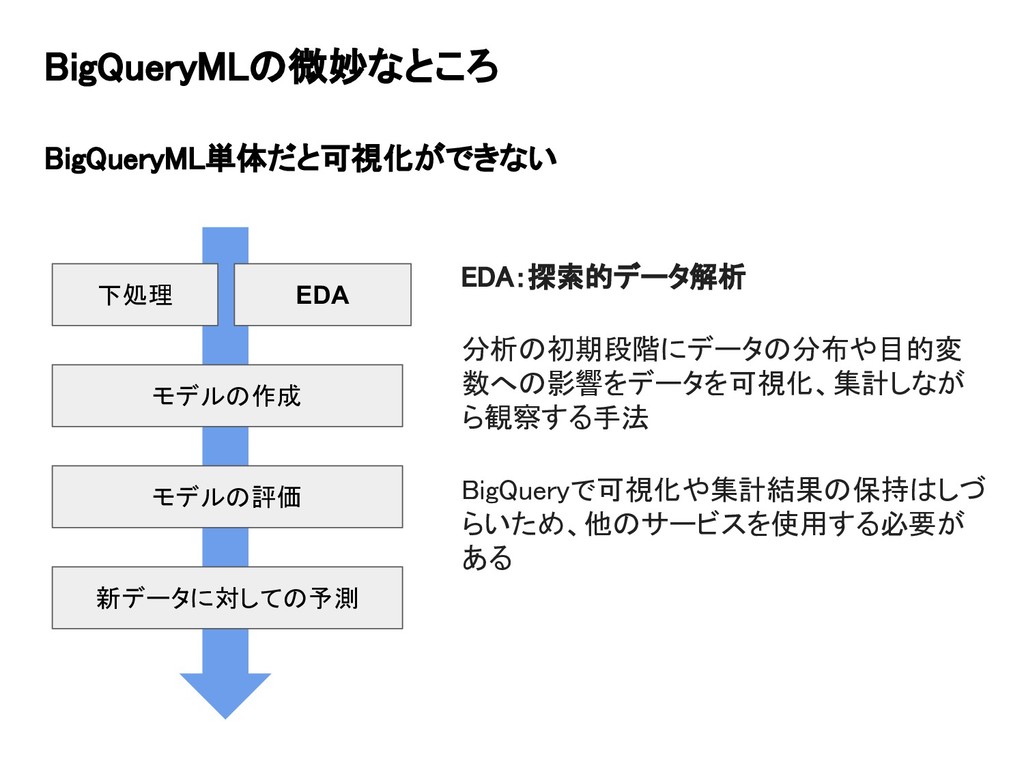
BigQueryMLの微妙なところ BigQueryML単体だと可視化ができない 下処理 モデルの作成 モデルの評価 新データに対しての予測 EDA EDA:探索的データ解析 分析の初期段階にデータの分布や目的変 数への影響をデータを可視化、集計しなが
ら観察する手法 BigQueryで可視化や集計結果の保持はしづ らいため、他のサービスを使用する必要が ある
BigQueryMLの微妙なところ パラメータサーチがしづらい ハイパーパラメータ:人間が設定する必要のあるパラメータ (例)最適なパラメータAを探したい場合: A = 0, 1, 2, 3,
4, 5, 10, ...に対しモデルを作成し精度を計算 最も精度の高いパラメータの値が最適と判断、採用 しかし、BigQueryMLではループ処理をサポートしていないため、不可能
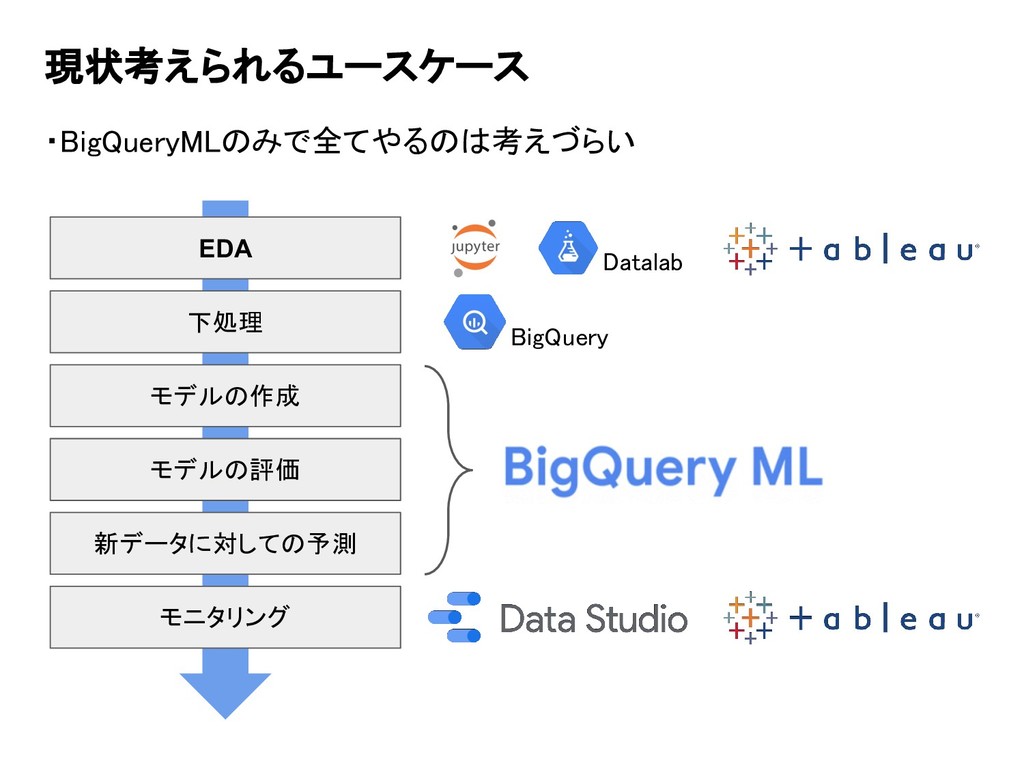
現状考えられるユースケース ・BigQueryMLのみで全てやるのは考えづらい 下処理 モデルの作成 モデルの評価 新データに対しての予測 EDA モニタリング Datalab BigQuery
ご静聴ありがとうございました!
懇親会!!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![機械学習モデルの作成 CREATE MODEL ステートメント CREATE MODEL `<データセット名>.<モデル名>` OPTIONS( model_type='<使用するアルゴリズム>', input_label_cols=['<ターゲットのカラム名>'],](https://files.speakerdeck.com/presentations/af204fb3fb4b4057a4da280c7648469c/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}