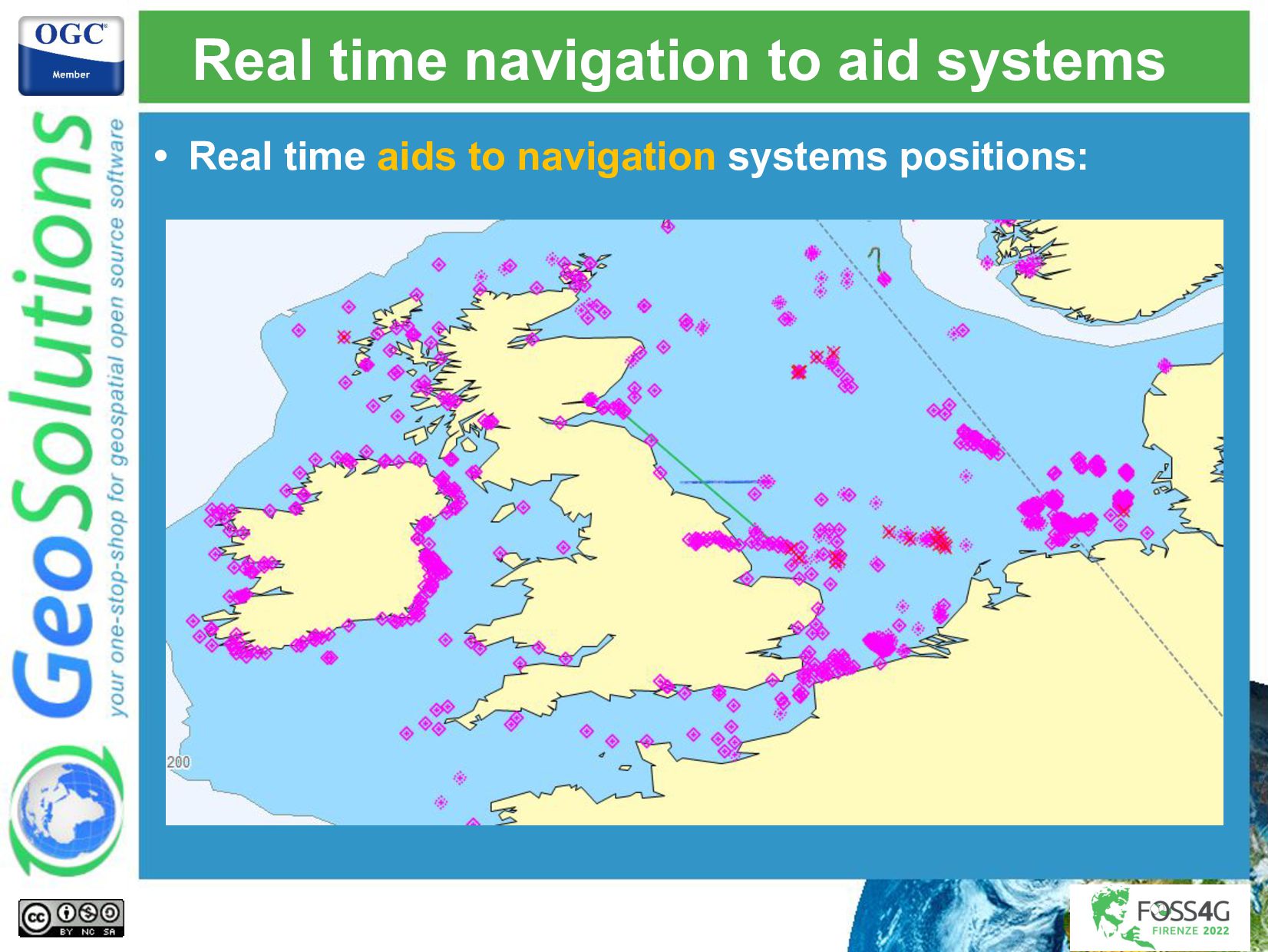
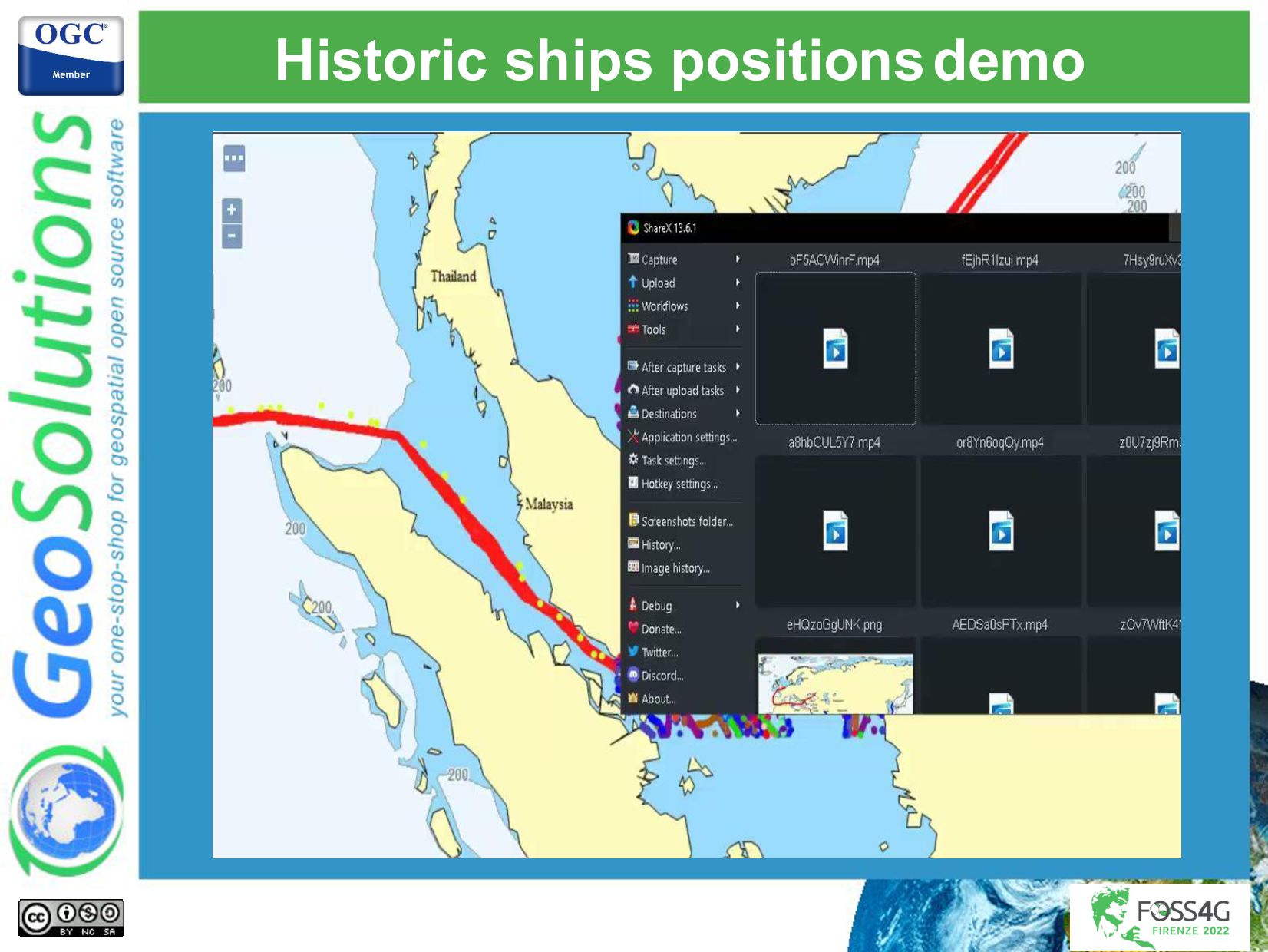
The amount of data we have to process and publish keeps growing every day, fortunately, the infrastructure, technologies, and methodologies to handle such streams of data keep improving and maturing. GeoServer is a web service for publishing your geospatial data using industry standards for vector, raster, and mapping. It powers a number of open source projects like GeoNode and geOrchestra and it is widely used throughout the world by organizations to manage and disseminate data at scale. We integrated GeoServer with some well-known big data technologies like Kafka and Databricks, and deployed the systems in Azure cloud, to handle use cases that required near-realtime displaying of the latest received data on a map as well background batch processing of historical data.
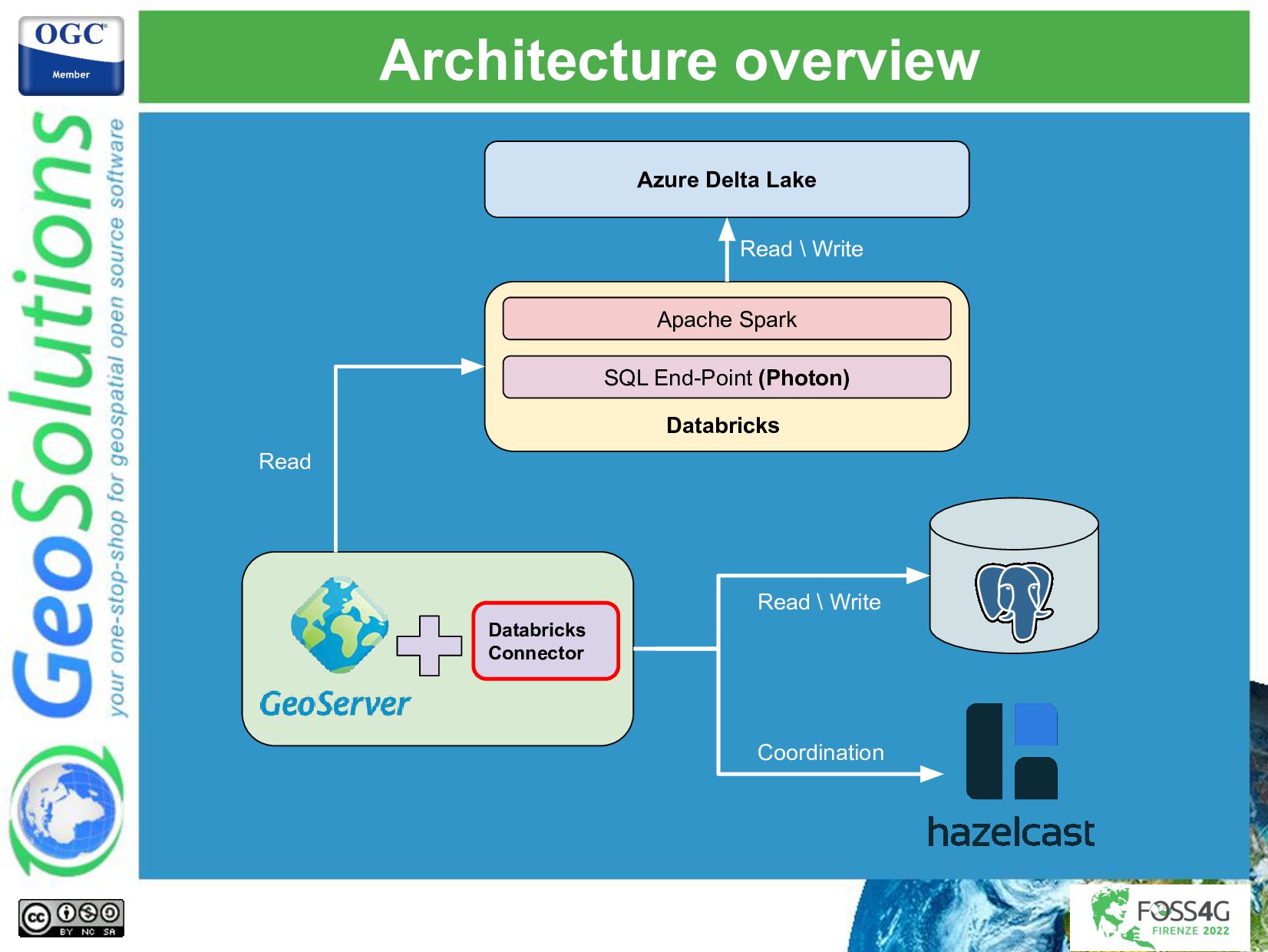
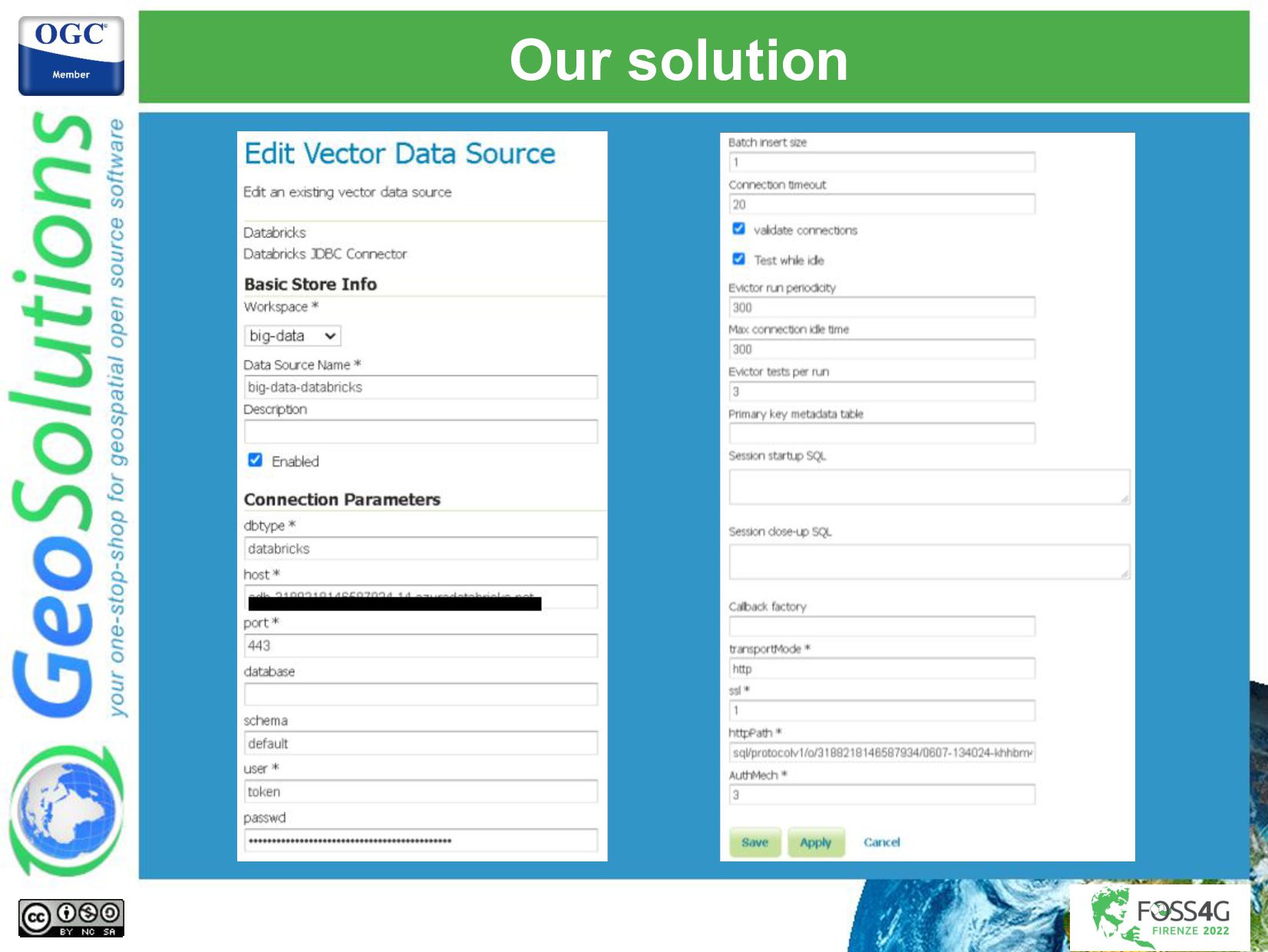
This presentation will describe the architecture put in place, and the challenges that GeoSolutions had to overcome to publish big data through GeoServer OGC services (WMS, WFS, and WPS), finding the correct balance that maximized ingestion performance and visualization performance. We had to integrate with a streaming processing platform that took care of most of the processing and storing of the data in an Azure data lake that allows GeoServer to efficiently query for the latest available features, respecting all the authorization policies that were put in place. A few custom GeoServer extensions were implemented to handle the authorization complexity, the advanced styling needs, and big data integration needs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![The End Questions? primary author email secondary author email [email protected]](https://files.speakerdeck.com/presentations/e083b322b1dd48aeb7715669a248a52a/slide_42.jpg){kind=link}