Twitter, feel free to tweet about this session (use hashtag #VMUG) • I encourage you to take photos or videos of today’s session and share them online • This presentation will be made available online after the event
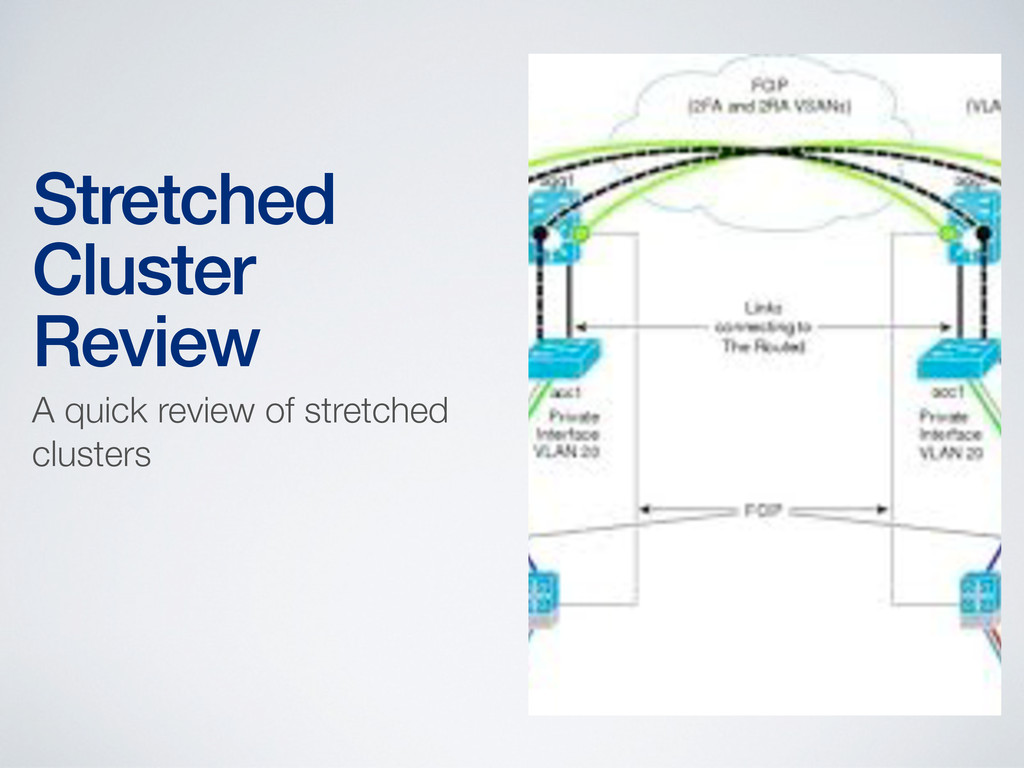
with ESX/ESXi hosts in different physical locations, usually different geographic sites • Stretched clusters are typically built as a way to create “active/active” data centers in order to: • Provide high availability across sites • Do dynamic workload balancing across sites
stretched cluster, although they are typically deployed • Most pros and cons of stretched clusters stem directly from the use of HA/DRS • Stretched clusters are not a requirement for long-distance vMotion
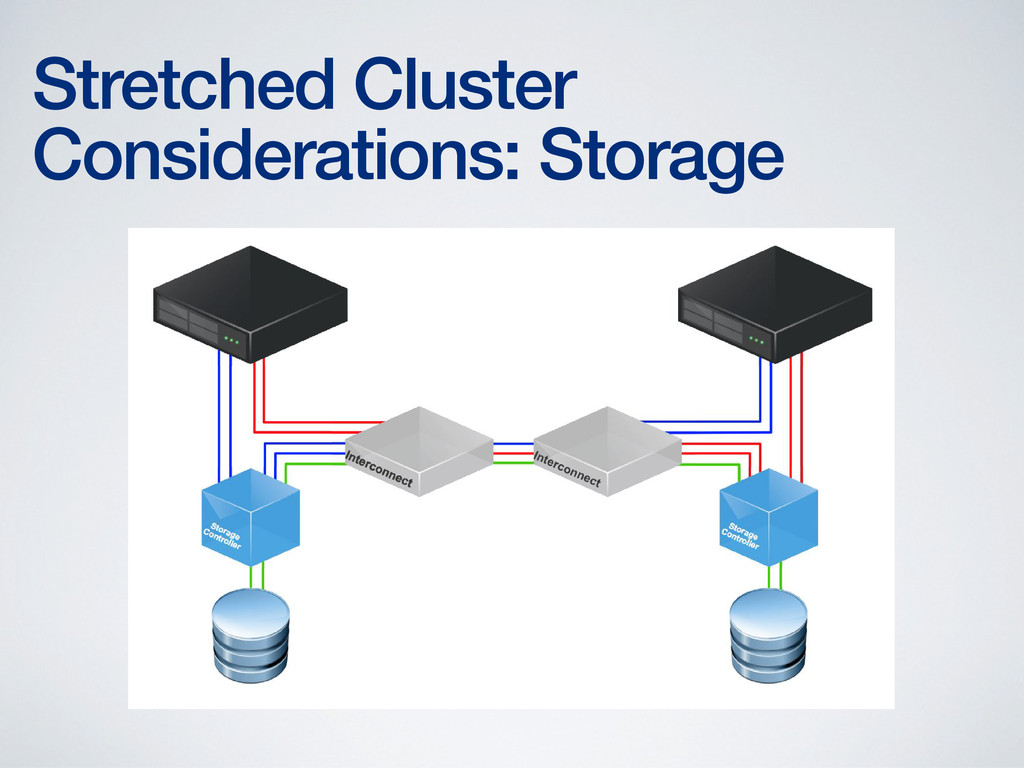
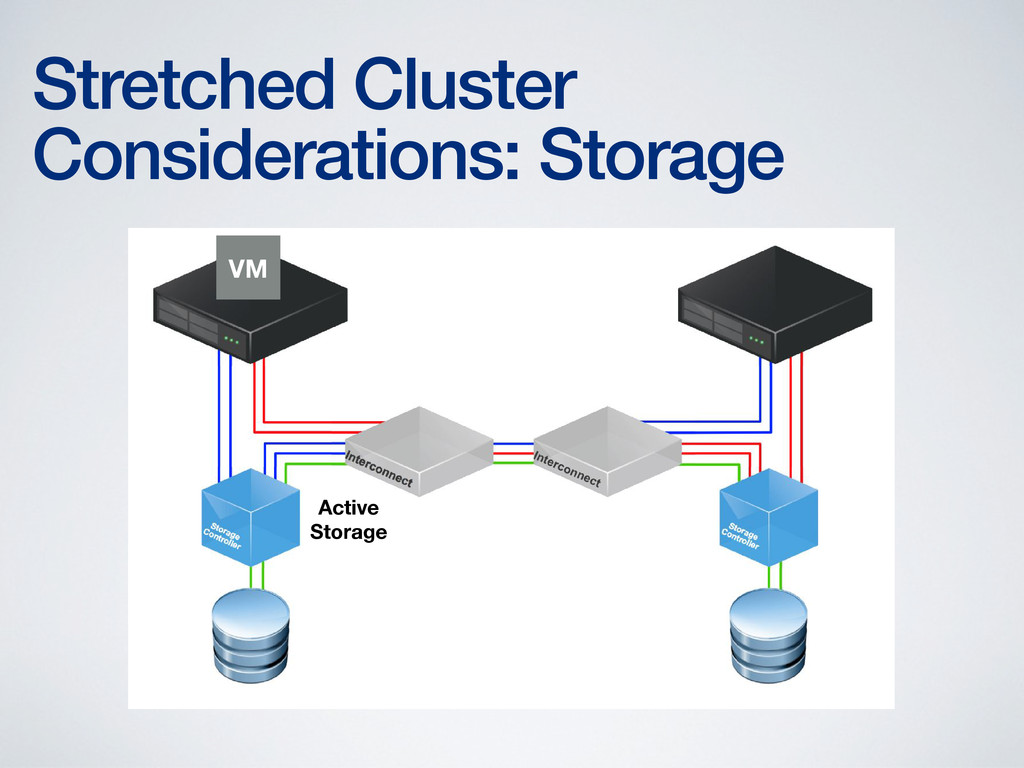
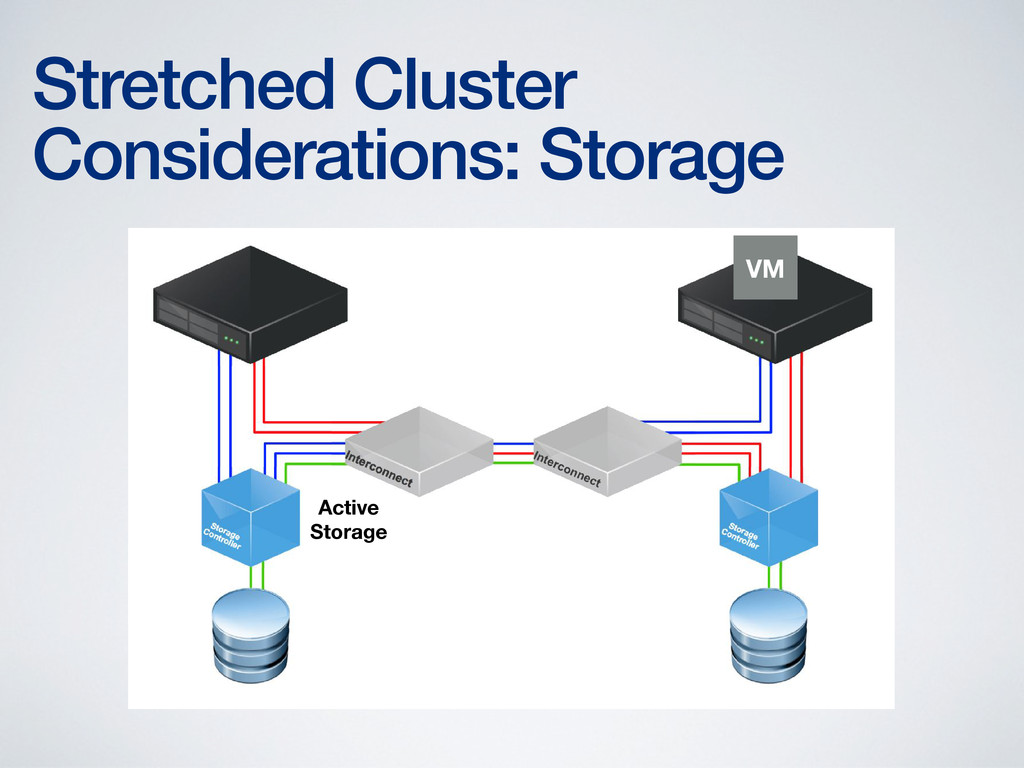
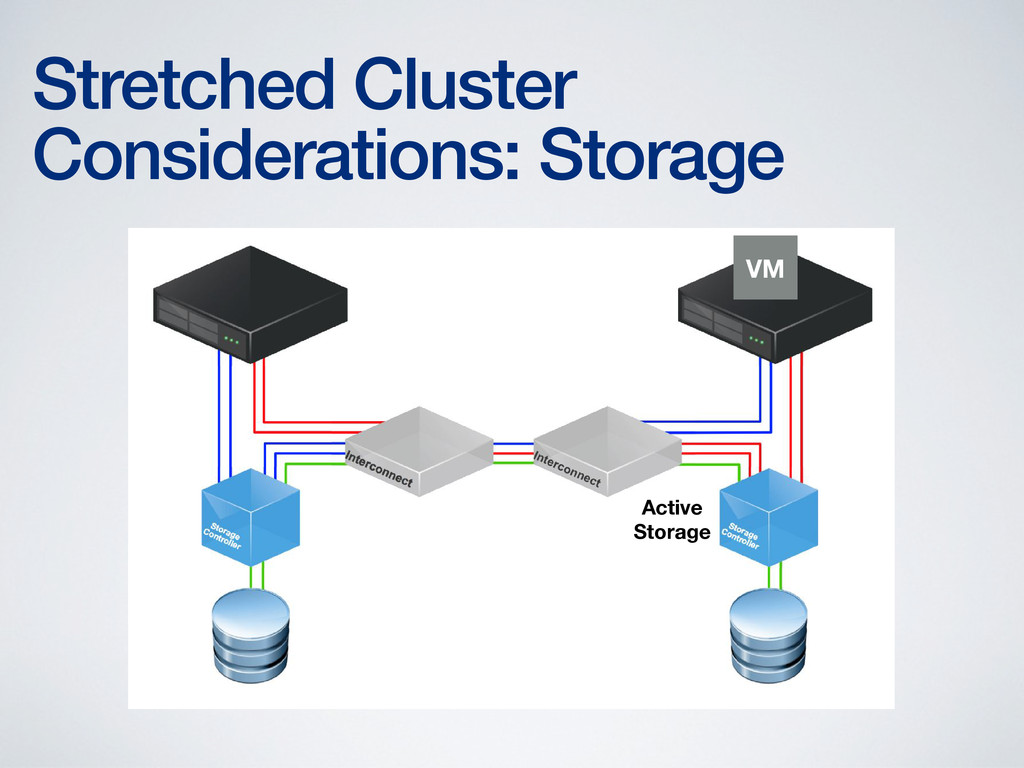
storage at both ends • Storage performance suffers otherwise • Storage vMotion required to fix the performance hit • Only a few products capable of providing read/write storage at both ends of the stretched cluster • Solutions are generally limited to synchronous (~100km) distances
failover • However, VMware HA is not currently “site aware” • You can’t control failover destination • Can’t designate or define things like: • Per-site failover capacity • Per-site failover hosts • Per-site admission controls
in HA-enabled stretched clusters or you’ll run afoul of HA primary node limitations • Can only deploy 4 hosts or less per site per cluster • Ensures distribution of HA primary nodes • No supported method to increase the number of primary nodes or to specify HA primary nodes
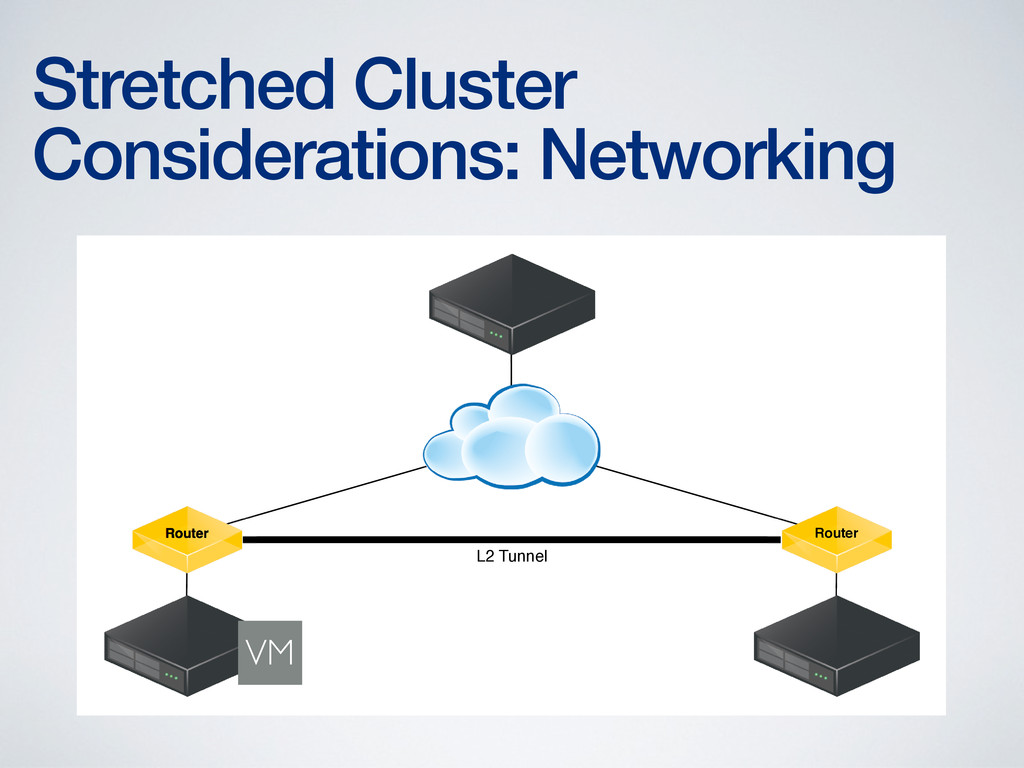
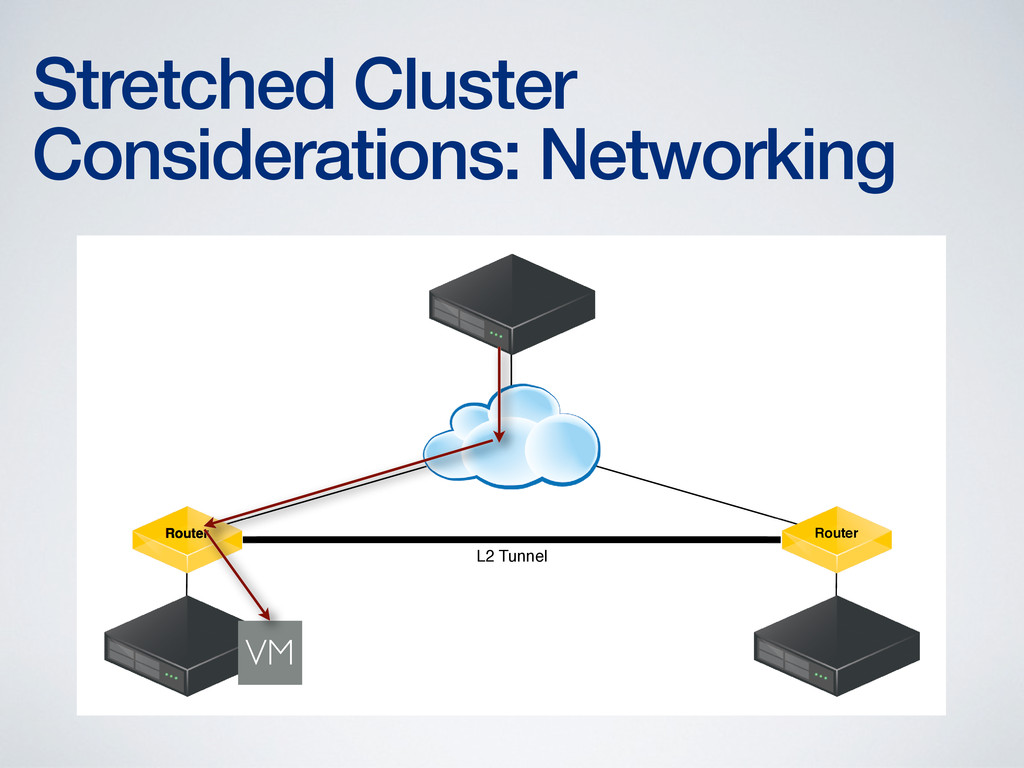
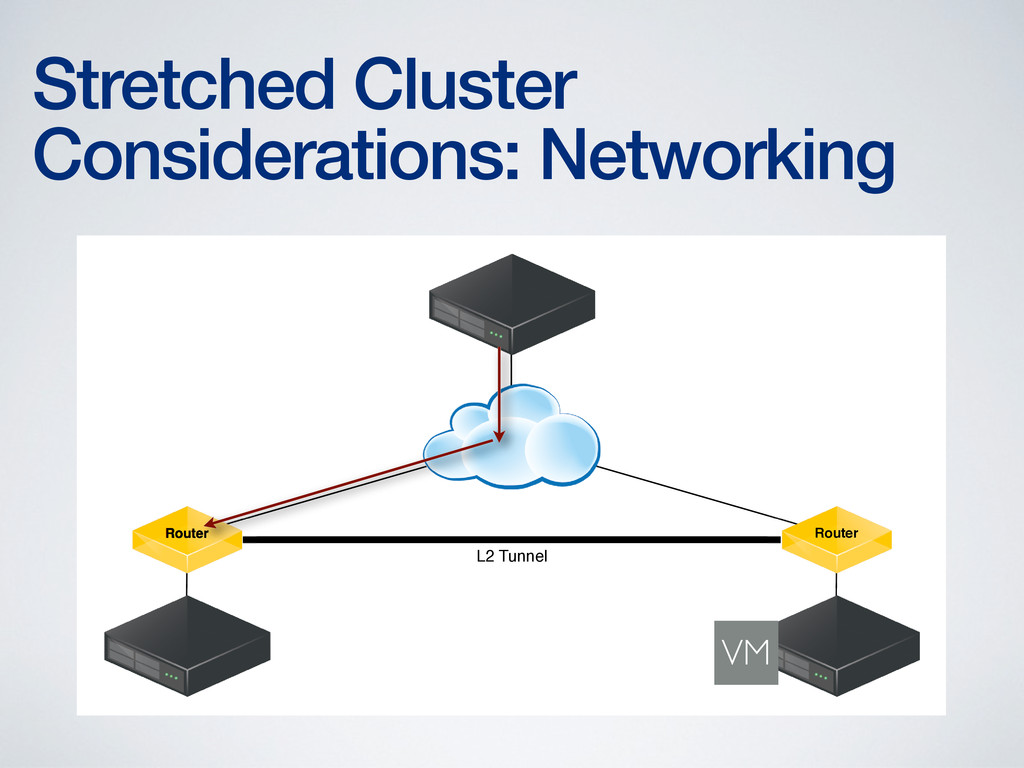
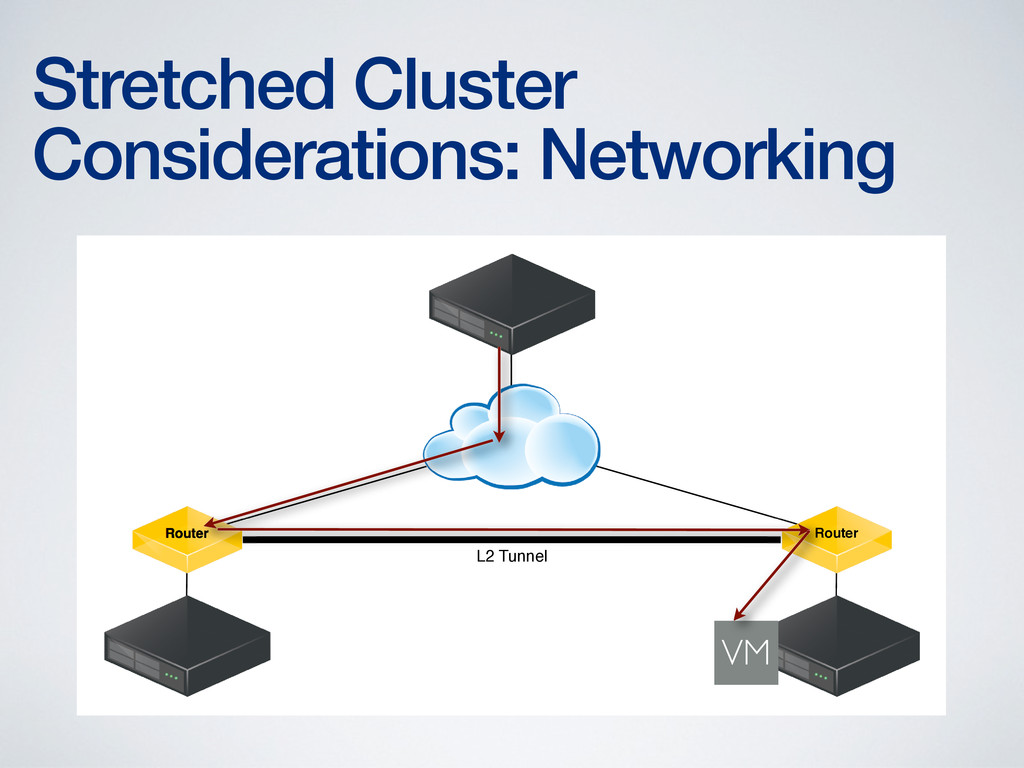
of networking complexity • More complex network configuration is required to provide Layer 2 adjacency (or its equivalent) • More complex networking required to address routing issues created by VM mobility • Technologies to address these concerns are new (OTV, LISP) and require networking expertise to configure and maintain
strength and greatest weakness” for stretched clusters • Stretched clusters will directly benefit from any improvements to HA/DRS in these areas: • Primary/secondary node behaviors • HA admission control algorithm • More scalable/dynamic DRS host affinity rule management (policy-based placement)
from further networking developments such as: • LISP (or equivalent) to decouple network routing from network identity • OTV, VPLS, or other equivalents to enable Layer 2 adjacency • In the longer-term future, the need for Layer 2 adjacency needs to be addressed and resolved
will help stretched clusters • Active/active read-write storage at greater distances • Better handling of “split brain” scenarios • Better/more direct integration with replication for topologies with >2 sites (Sync-Sync-Async, for example)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}