Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ローカルLLMバイブコーディングのすすめ
Search
soukouki
May 16, 2026
Technology
97
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ローカルLLMバイブコーディングのすすめ
Zli 大LT 2026 春 in Aizu (2026-05-16) にて発表したスライドです。
soukouki
May 16, 2026
More Decks by soukouki
See All by soukouki
ゲーム画面をブラウザから見られるサイトを作った話
soukouki
0
86
Simutrans CityView (日本語版)
soukouki
0
140
Simutrans CityView (English)
soukouki
0
110
10分で学ぶ すてきなモナド
soukouki
1
200
Misskey自鯖を建ててみた
soukouki
1
120
1年前の日記を要約するツールをローカルLLM&自作MCPサーバーで作った話
soukouki
0
540
自作Cコンパイラ 8時間の奮闘
soukouki
0
1.9k
定理証明支援系Coq(セキュリティキャンプLT会)
soukouki
1
280
Coqで選択公理を形式化してみた
soukouki
0
540
Other Decks in Technology
See All in Technology
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
13
2k
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
2
3.9k
[2026-07-15] AI Ready なはずだったアーキテクチャと、見えてきた課題・次に目指す状態
wxyzzz
6
3.2k
Claude Code公式skillで 自分の仕事を少しずつ手放そう!(Claude Code開発ノウハウ大公開スペシャル by クラスメソッド)
kaym
1
330
AI時代の EM への処方箋
staka121
PRO
0
140
世界、断片、モデル。そして理解
ardbeg1958
1
110
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
3
340
インフラと開発の垣根を超えていき!〜元AWSインフラエンジニアがAWS開発で奮闘している話〜
hatahata021
2
180
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
0
120
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
2.7k
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
290
ruby.wasmとPicoRuby.wasmに対応した仮想DOMライブラリを作ってる話 #kaigieffect_kaigi
sue445
PRO
0
150
Featured
See All Featured
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
Being A Developer After 40
akosma
91
590k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
350
Why Our Code Smells
bkeepers
PRO
340
58k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Scaling GitHub
holman
464
140k
Facilitating Awesome Meetings
lara
57
7k
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.6k
How STYLIGHT went responsive
nonsquared
100
6.2k
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
650
The Pragmatic Product Professional
lauravandoore
37
7.4k
Accessibility Awareness
sabderemane
1
150
Transcript
自己紹介 sou7といいます。 修士1年、28卒予定 趣味 : なろう小説を読み漁る こと、鉄道(ライト勢) 好きな作品があったらぜひ 教えてください! 最近読んだ小説
サイレントウィッチ (本編と外伝で計285万字) トリニティアイ -転生平民 魔術師の往生勤務- (65万字更新中) 1
連絡先 ActivityPub/Misskey: @
[email protected]
→ Twitter: @sou7_ _ _ GitHub: @soukouki
2
世は大LLM時代 皆さんにアンケート : バイブコーディングツールを使った経験は? Claude Code Antigravity Codex GitHub Copilot
Chat Cline Cursor etc… 3
試したいなと思っている人は、よくこんなふうに思っているのでは? 課金しないと使えない 学生には月数千円はちょっと高いなぁ 試してみたいけれど、コードそんな書かないのに数千円はちょっとなぁ 試した人もこんなふうに思っているのでは? レートリミットが厳しくて、今のプランだと辛い プライベートな情報をクラウドで扱いたくないなぁ 会社でAIを推進したいけれど、このコードは外部のLLMサービスには送れ ないなぁ 4
【令和8年最新版】今すぐ止めて。AI課金はもう 古い。課金なし/レートミットなし/安全にバイブ コーディング・AIエージェントを使う方法【無 料】 Zli 大LT 2026春 2026-05-16 5
どうやるのか 用意するもの : GPU なお電気代は考えないこととします (300WのGPUを1時間フルに動かしても約10円なので) 6
みなさん情報系の学生ですから 自宅にGPUくらいありますよね! 7
ローカルLLMバイブコーディングのススメ Zli 大LT 2026春 2026-05-16 8
ローカルLLMとは? クラウドサービスを使わず、自宅などのローカル環境で動かすLLMのことで す。 計算能力をかなり要求し、生成速度や賢さがほしければGPUが必要 ローカルLLMにはモデルという、学習済みの重みデータが必要で、このモ デルはGoogleやAlibabaなどがいくつか公開している 実際に家庭で動かせるレベルのモデルは、クラウドのモデルに比べてかな り性能が落ちる モデルを動かすためにはランタイムが必要 簡単なのはLM
Studioで、これらはモデルのダウンロードからチャットUI、 MCPツールの設定まで一通りをGUIで提供してくれる 9
Qwen3.5とGemma 4の登場 今年の2月から4月にかけて、前世代と比べて性能が大幅に向上したモデル群が リリースされました。 2026年2月16日 : AlibabaがQwen3.5をリリース 2026年4月2日 : GoogleがGemma
4をリリース これより前の家庭用GPUで動くモデルでは、Claude Codeなどのバイブコーデ ィングツールはほとんど動作しませんでした。(ツール呼び出しが1回でも上手 く行けば御の字、大抵はツール呼び出しすら出来ず、意味不明な文字列を出力 することも多かった。 ) この新世代のモデルでは、VRAM16〜32GB程度の家庭用GPUで、これらのツ ールが十分に動作するようになりました。 10
普段どんな構成で使ってるの? GPU : RTX 5070 Ti VRAM16GBで、購入時の価格は125,800円でした。 中の上、あるいは上の下くらいの性能 モデル :
unslothによるQwen3.6 27BのIQ2_M量子化モデル コンテキスト長を伸ばすために、2ビット量子化モデルを使用しています。 ランタイム : llama.cpp RTX 5070 Ti用のオプションを付けて自前でビルドしています。 また、モデル切り替えとTTL管理のためにllama-swapも使用しています。 11
AIエージェント : Hermes Claude Codeのようなコーディング特化のエージェントではなく、汎用的な エージェントを使用しています。 Claude CodeはProプラン以上じゃないと(APIプランでは)検索ツールが使えず、 しかも検索ツールをLLMのプロンプトから外すことすら出来ません。 Hermesのウリは「会話内容から自動でスキルとメモリを追加・修正してく
れること」です。自然と会話を最適化してくれるので、賢くないモデルとの 相性が良いです。 webuiは、公式のもの、nesquena/hermes-webui、EKKOLearnAI/hermes- web-uiの3つがあり、好みのものを選べばいいと思います。sou7は nesquena/hermes-webuiを使用しています。 ※ Hermesはフランス語で、フランス語では先頭のHは発音しません。 12
クラウドのモデルと比べると? sou7の体感や周りの人の話を合わせると、大体このくらいのモデルと同じく らいの性能です。 Claude Haiku 4.5 Gemini 3.1 Flash Lite
GPT-5.4 mini ※ 量子化の度合いや与えるタスクによって性能はかなり変わります。あくまで目安程度に考えてください。 13
どんなことが出来るの? 1000〜2000行のコードで、具体的に指示をすればコーディング可能 コードやWeb検索を使った簡単な調査も出来る ただし、安定性に欠ける 頻繁にループする 日本語の中に韓国語や中国語の単語が混ざる(Qwen系の場合) コンテキストにループや質の悪い文章が入ると以降の出力の質が落ちる ※ 安定性については、VRAM不足により量子化度合いの強いモデルを使っているからというのもあります。 14
辛いこと VRAMが足りないため、量子化度合い/コンテキスト長 というトレードオフを 迫られます。 量子化を強めると、安定性が落ちます。 AIエージェントにはかなりのコンテキスト長が必要で、コンテキストの圧 縮処理も考えると最低でも100Kトークン、できれば150Kトークンは無い と辛いです。 sou7宅の場合、コンテキストを伸ばした結果、IQ2_Mというかなり強い量子 化モデルを使うことになりました。そのために、安定性や性能がかなり犠牲に
なっています。 15
あるある sou7「AではなくBです!べらべらべら…」 16
あるある sou7「AではなくBです!べらべらべら…」 AIエージェント「つまりAってことですね!」 17
あるある sou7「AではなくBです!べらべらべら…」 AIエージェント「つまりAってことですね!」 sou7「違う〜!! 」 18
あるある2 sou7「AをしてBをしてCをしてください!」 19
あるある2 sou7「AをしてBをしてCをしてください!」 AIエージェント「ではまずはBから作業を始めます!」 20
あるある2 sou7「AをしてBをしてCをしてください!」 AIエージェント「ではまずはBから作業を始めます!」 sou7「Aからやってほしいのに!!(泣)」 21
あるある3 sou7「Aが壊れてるように見えるからそこをデバッグしてくれ」 22
あるある3 sou7「Aが壊れてるように見えるからそこをデバッグしてくれ」 AIエージェント「わかりました!ではBを確認します」 23
あるある3 sou7「Aが壊れてるように見えるからそこをデバッグしてくれ」 AIエージェント「わかりました!ではBを確認します」 sou7「(# 丶Д゚) ピキピキ」 24
ローカルLLMの未来は明るい それでも、3ヶ月前に比べて格段に実用的になりました。 最近は、簡単な質問や調べごとにはローカルLLMを使っています。 性能を揃えると、3.3ヶ月で、パラメータ数が半減するという研究があり ます^1。 つまり、半年後には今の120B級相当、1年後には今の480B級相当のモデ ルが自宅で動かせるようになるかも! ちなみに、クラウドと比べるとコスパは圧倒的に悪いです。 付録として、GPUの選び方、おすすめのGPU、MoEについて、トークン生成速度の目安も載せておきます。LTで は時間の都合で割愛しますが、興味がある人はぜひスライドを見てください!
25
出典 1. Chaojun Xiao et al., “Densing Law of LLMs,”
arXiv:2412.04315, 2024. URL: https://arxiv.org/abs/2412.04315 26
余談 このスライドの大半は真心のこもった人の手入力によって書かれていま す。sou7の体感の話ばかりで、基になる情報が無いので… 出典を書くところや、Marpのテーマの修正、インタラクティブな紙芝居 の部分など、Hermesを活用している部分もあります。 Marpのテーマが、前回は200行だったのが420行に増えました。どうして こんなことに… スライド作成RTAの記録は7時間46分でした 27
付録 1. GPUの選び方 2. おすすめのGPU 3. MoEってどうなの? 4. トークン生成速度の目安 28
GPUの選び方 VRAM量を重視しましょう。処理性能も大事ですが。 VRAMは最低限16GB、できれば24GB以上ほしいところです。 複数枚GPUは結構アリです。 VRAMは足し算されます。 トークン生成速度は足し算されません(性能の低い方に引っ張られます)。 代わりに、同時に複数の生成を走らせても性能が落ちにくくなります。 29
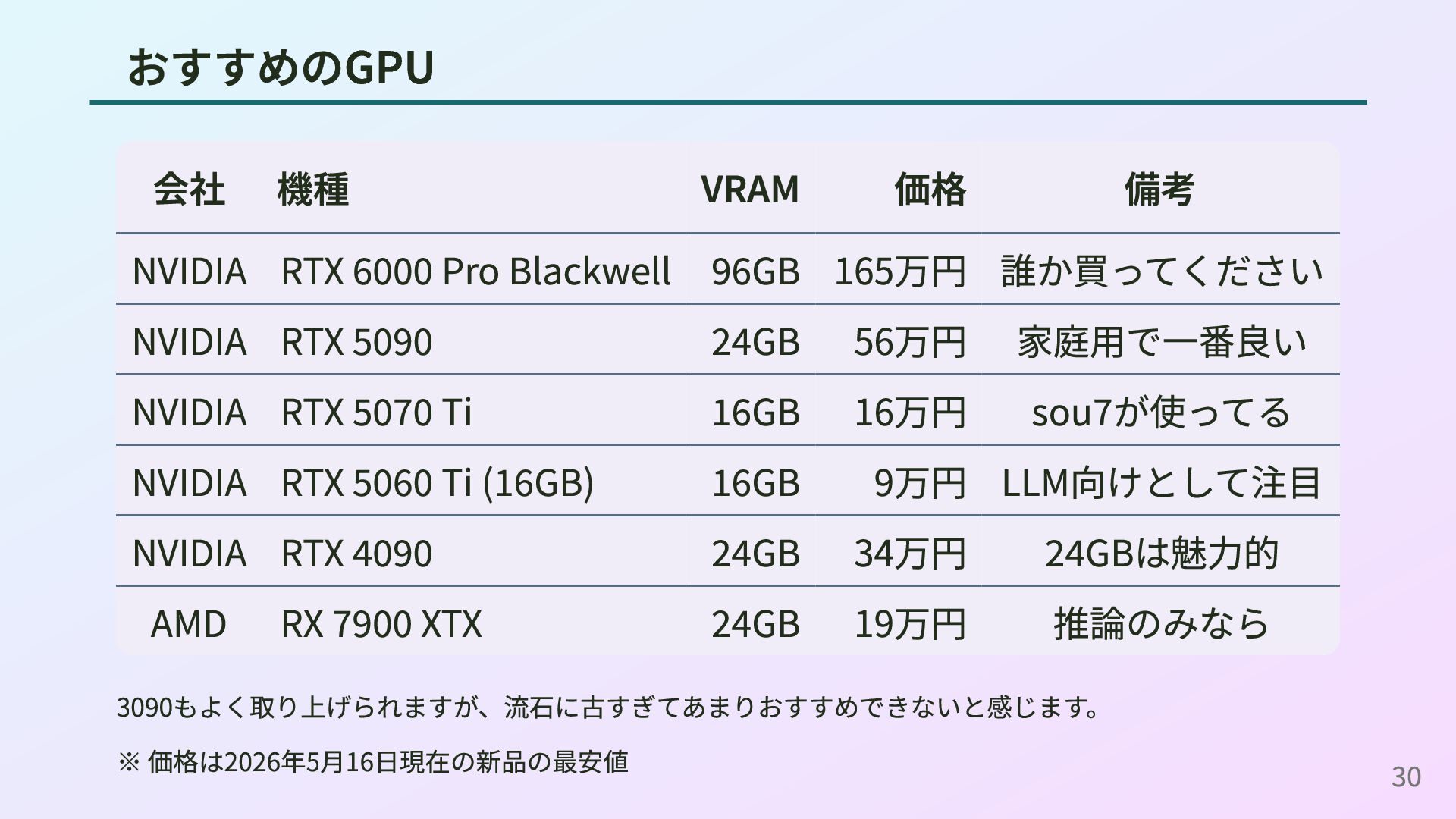
おすすめのGPU 会社 機種 VRAM 価格 備考 NVIDIA RTX 6000 Pro
Blackwell 96GB 165万円 誰か買ってください NVIDIA RTX 5090 32GB 56万円 家庭用で一番良い NVIDIA RTX 5070 Ti 16GB 16万円 sou7が使ってる NVIDIA RTX 5060 Ti (16GB) 16GB 9万円 LLM向けとして注目 NVIDIA RTX 4090 24GB 34万円 24GBは魅力的 AMD RX 7900 XTX 24GB 19万円 推論のみなら 3090もよく取り上げられますが、流石に古すぎてあまりおすすめできないと感じます。 ※ 価格は2026年5月16日現在の新品の最安値 30
MoEってどうなの? MoEは萌え〜 Mixture of Expertsの略で、パラメータの一部をいくつかの 部分パラメータ(エキスパート/専門家と呼ばれる)に分け、トークンごとに 適切なエキスパートを複数選んで生成していく手法です。 1つのトークンを生成するパラメータ数(アクティブパラメータ)が3B程度 であれば、処理性能が限られたコンピュータでも高速に生成できます。 同じ総パラメータ数では、MoEを使っていないモデルの方が高性能です。
50B以上の大規模なモデルでは、たいていMoEが採用されています。 ちなみに、DRAM(マザボに指すメモリ)側に置いたパラメータは必ずCPU で処理されます。PCIeの転送速度はかなり遅く、DRAM側のパラメータを GPU側に転送するのは非常に非効率です。 ※ Mistral Medium 3.5 128BのようなクソデカDenseモデル一応あります。 31
トークン生成速度の目安 5〜10 トークン/秒 夜間にバッチ処理を走らせるのであれば十分 チャットには厳しい CPUで20B〜のDenseモデルを使うとこれくらいになりがち 10〜30 トークン/秒 チャットにはちょっと遅いと感じる AIエージェントやバイブコーディングには厳しい
30〜80 トークン/秒 チャットは快適 AIエージェントやバイブコーディングだと遅いと思うことはあるが耐え 80 トークン/秒以上 AIエージェントやバイブコーディングも快適 32
{kind=link}
![連絡先 ActivityPub/Misskey: @[email protected] → Twitter: @sou7_ _ _ GitHub: @soukouki](https://files.speakerdeck.com/presentations/4fbfe67cbd274d0995d269c684c7b3d0/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}