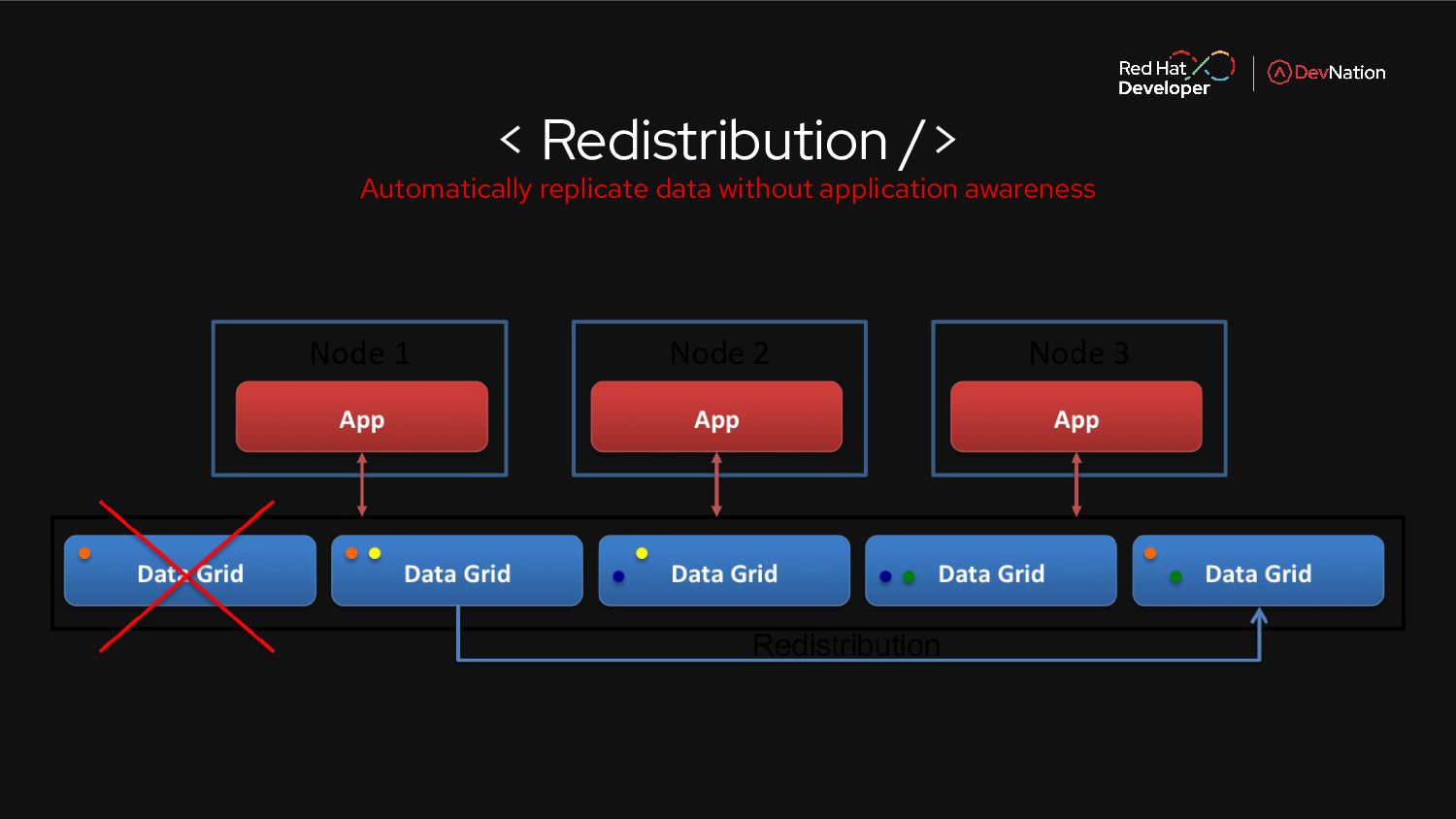
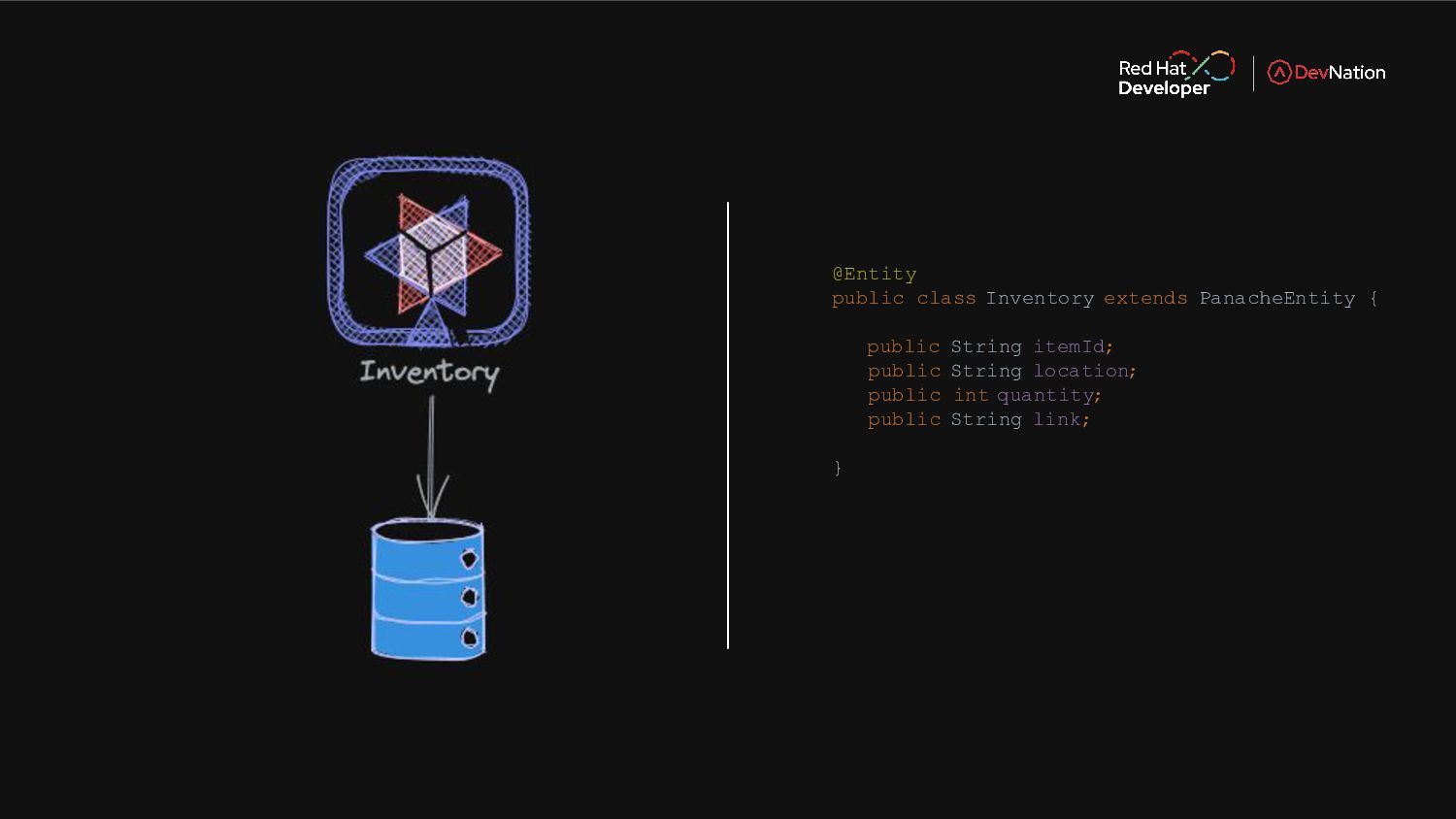
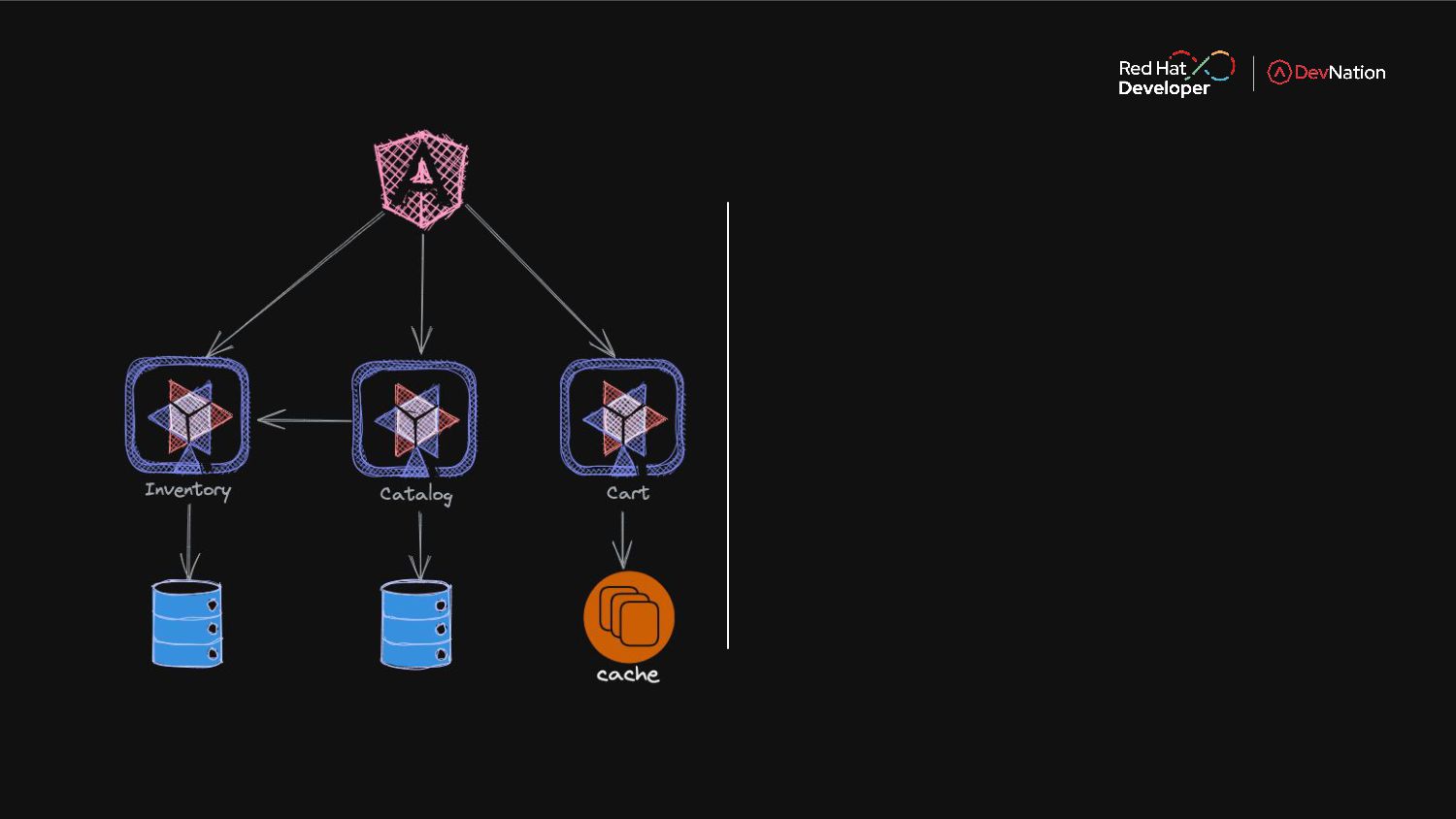
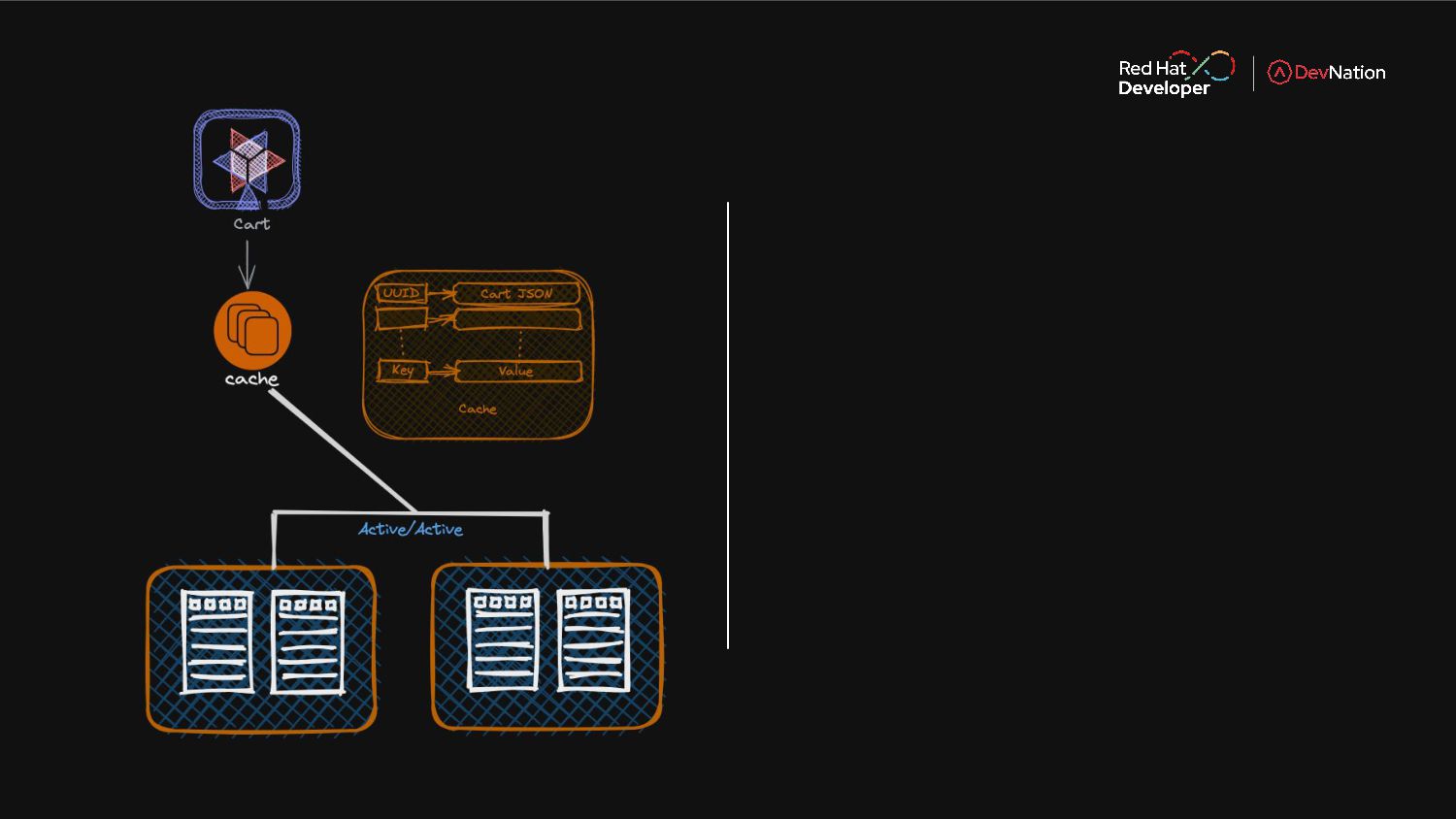
Once you have decided on that path to microservices. you need to be able to manage the state and also ensure that your applications is high performing and secure. Enter the cloud native world with Red Hat Data Grid, that ensures a true cloud native experience and enables microservices to perform faster and scale as your architecture grows. In this live demo session you will learn more about Data Grid and its abilities to scale across clouds.
Join this session and learn how it integrates with modern frameworks like Quarkus, Node, etc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![dn.dev/kubemaster2 • [TP] New connector for Redis protocol ◦ Initial](https://files.speakerdeck.com/presentations/e0058ccc31f04e268832c66030612e08/slide_24.jpg){kind=link}
{kind=link}