한국 커뮤니티에서 관련된 많은 논의가 발생하길 바랍니다. - 청중에게 발표하기 부끄럽고 부족한 실력이지만 모아둔 짧은 인사이트들을 공유하려고 합니다. - 주제에 대한 뚜렷한 대안은 저조차도 없지만, 그 동안 학계, 커뮤니티의 연구에서 짚고 넘어갈 사실들을 정리했습니다. - 정신 없이 흘러가는 최근 동향들에서 잠시 멀어지고, 처음부터 짧게 되짚으면서 시작하려고 합니다. About Presentation
Using AI as RecSys(Shopping), Classification(Finance), OCR … - AI: Small component of system, secondary role of system - After Higher Performance LLM(2023 ~) - AI: Service domain, rich platform feature, enhanced RecSys, Classification - AI: Core component of system.
as RecSys(Shopping), Classification(Finance), OCR … - AI: Small component of system, secondary role of system - After Higher Performance LLM(2023 ~) - AI: Service domain, rich platform feature, enhanced RecSys, Classification - AI: Core component of system. - Three perspective of AI for business for success - Performance, Efficiency of model: - High barrier: Resources, Researchers, Engineers, Cost … - Serve the model - High barrier: Resources, Researchers, Engineers, Cost … - Utilizing the model: Presentation Target - Low barrier: Just junior engineers and API cost LLM guarantee the lower-boundary performance of service. Background History
box system: - Core component of Chat interface, Query Classification … - Focus on broad capabilities like fluence, domain knowledge understanding - Service quality depends on Performance of LLM - Cooperative system component - Core component of Chat interface, Query Classification … - Focus on specific capabilities like decision, code generation - Service quality depends on System Architecture & Performance of LLM Current practice of LLM usage: Mixture of both.
of both - LLM as Completion method - AI Community: Try to make better LLM. - 👍 Decreasing cost of LLM API: OpenAI, Claude, Together.ai, … - 👍 Better LLM API: OpenAI, Claude, Together.ai, … - 👍 Better Public LLM: Korean Continual Learning Llama2, Yi, Qwen, … - LLM as Cooperative system component - AI Community: Try to make better System Architecture of LLM usage. - 👍 Modularized AI constructs for easy creation: Langchain, LlamaIndex, .. - 👍 Well-crafted research, project: Taskweaver, AutoGPT, … - ❓ Build Productizable AI architecture for business field: Enterprise role - Easy to serve and maintain, less cost/latency, Multi-modal I/O - Langchain and LlamaIndex are library, doesn’t provide architecture - Maybe Agent Frameworks: Taskweaver, AutoGPT?.. ➡ Hard to use in various scenario. - Hidden practice
다수 포함. - 기업이 추구하는 목표와 연구(특히 Open-source contributors들의 노고)의 성격이 다름을 인지하고 여러 인사이트들을 공유하려고 합니다. - 그럼에도 한국 필드에서 AI system architecture와 관련된 다양한 논의들의 시작점이 되었으면 하는 마음에 여러가지 생각들을 정리해봤습니다. About Presentation
Eat, 2. Run, 3. Sleep - Reasoning: To infer about a problem - e.g., A is B, B is C. So, A is C. - LLM Performance: Fluency, Domain-knowledge understanding, mathematical, logical thinking …, every ability of LLM.
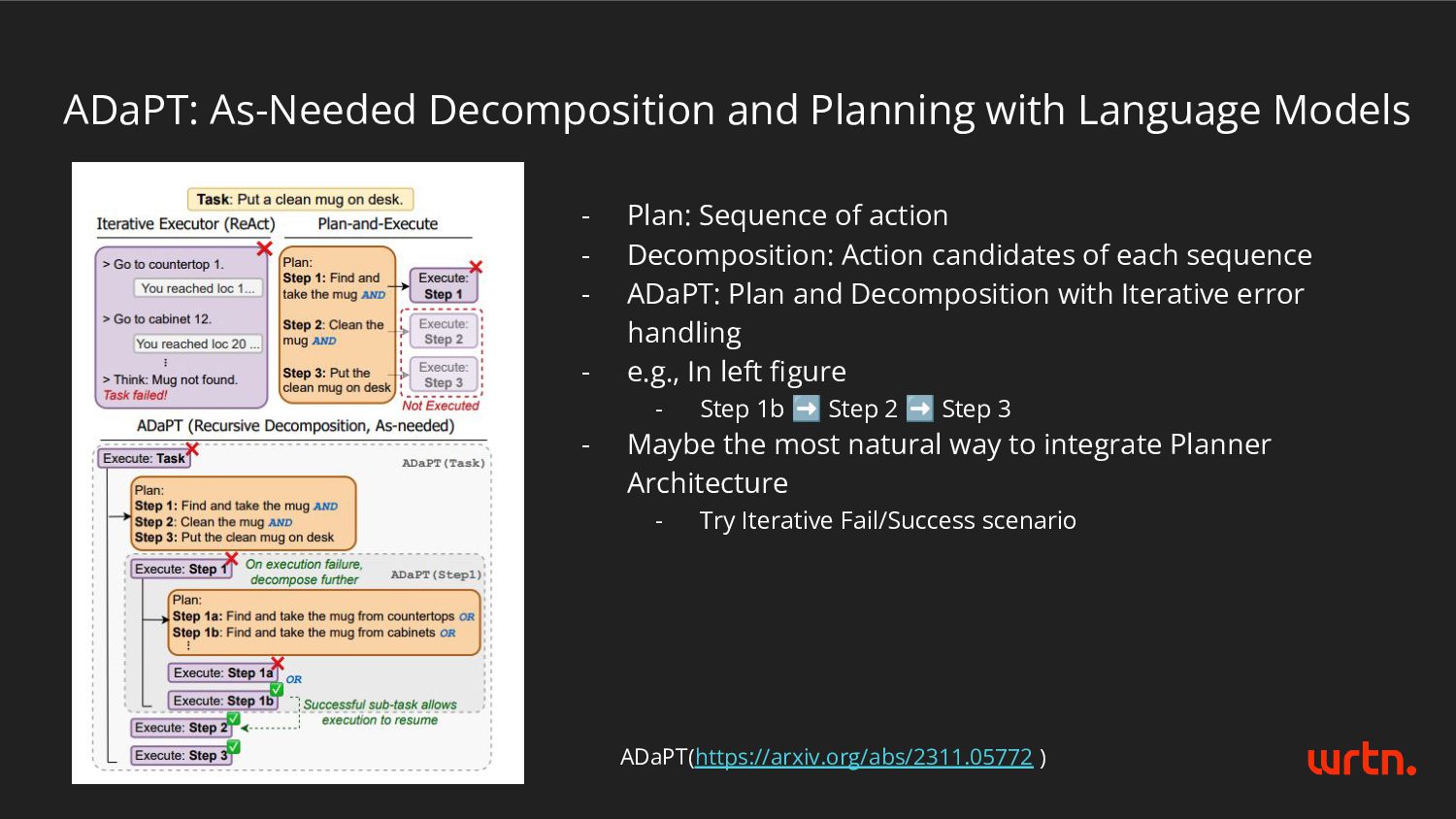
- Plan: Sequence of action - Decomposition: Action candidates of each sequence - ADaPT: Plan and Decomposition with Iterative error handling - e.g., In left figure - Step 1b ➡ Step 2 ➡ Step 3 - Maybe the most natural way to integrate Planner Architecture - Try Iterative Fail/Success scenario
) LLM-powered embodied lifelong learning agent in Minecraft - continuously explores the world - acquires diverse skills - makes novel discoveries without human intervention - ever-growing skill library of executable code for storing and retrieving complex behaviors - a new iterative prompting mechanism that incorporates environment feedback, execution errors, and self-verification for program improvement. - Environment(mineflayer-collectblock) is key!
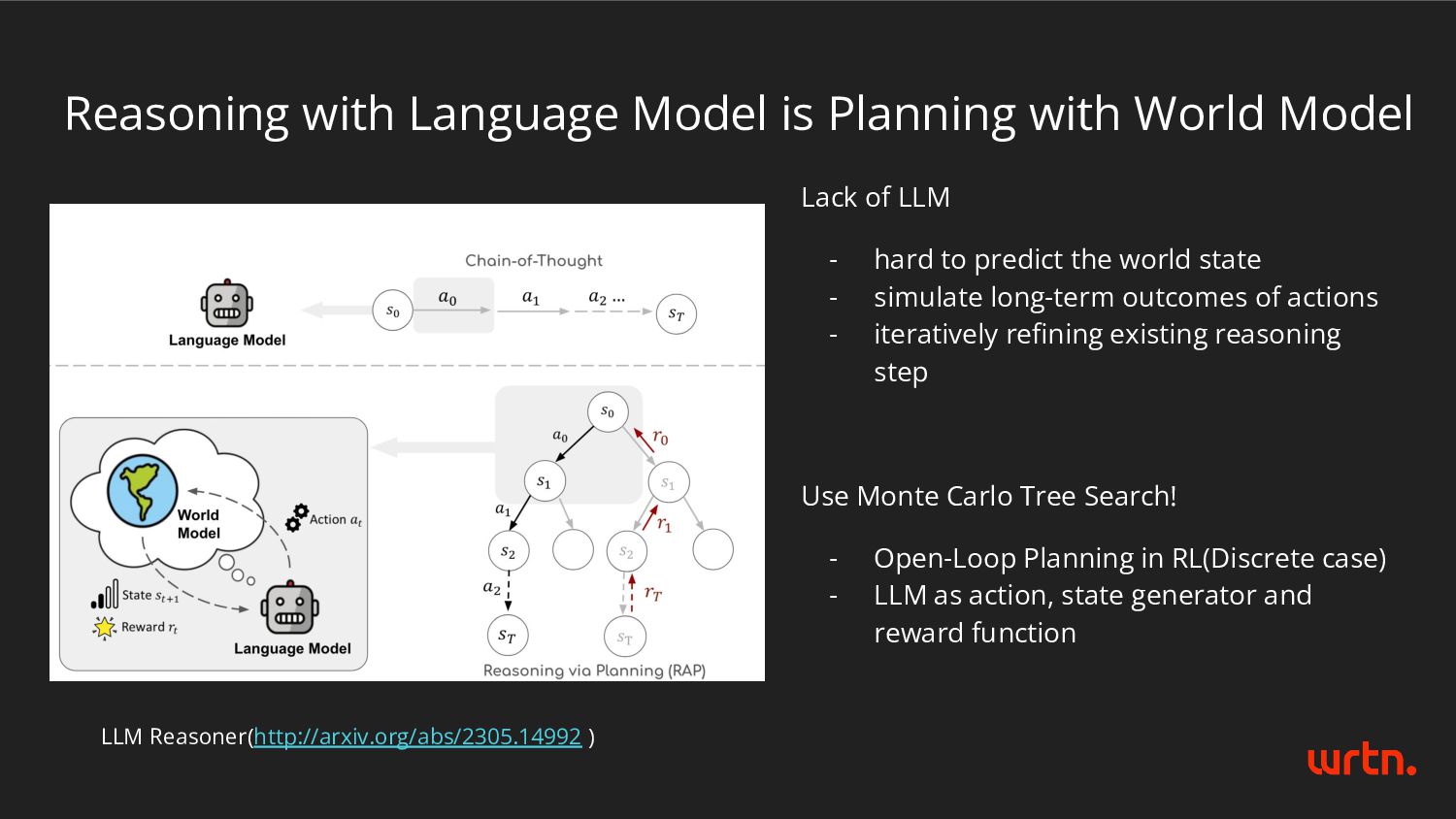
Reasoner(http://arxiv.org/abs/2305.14992 ) Lack of LLM - hard to predict the world state - simulate long-term outcomes of actions - iteratively refining existing reasoning step Use Monte Carlo Tree Search! - Open-Loop Planning in RL(Discrete case) - LLM as action, state generator and reward function
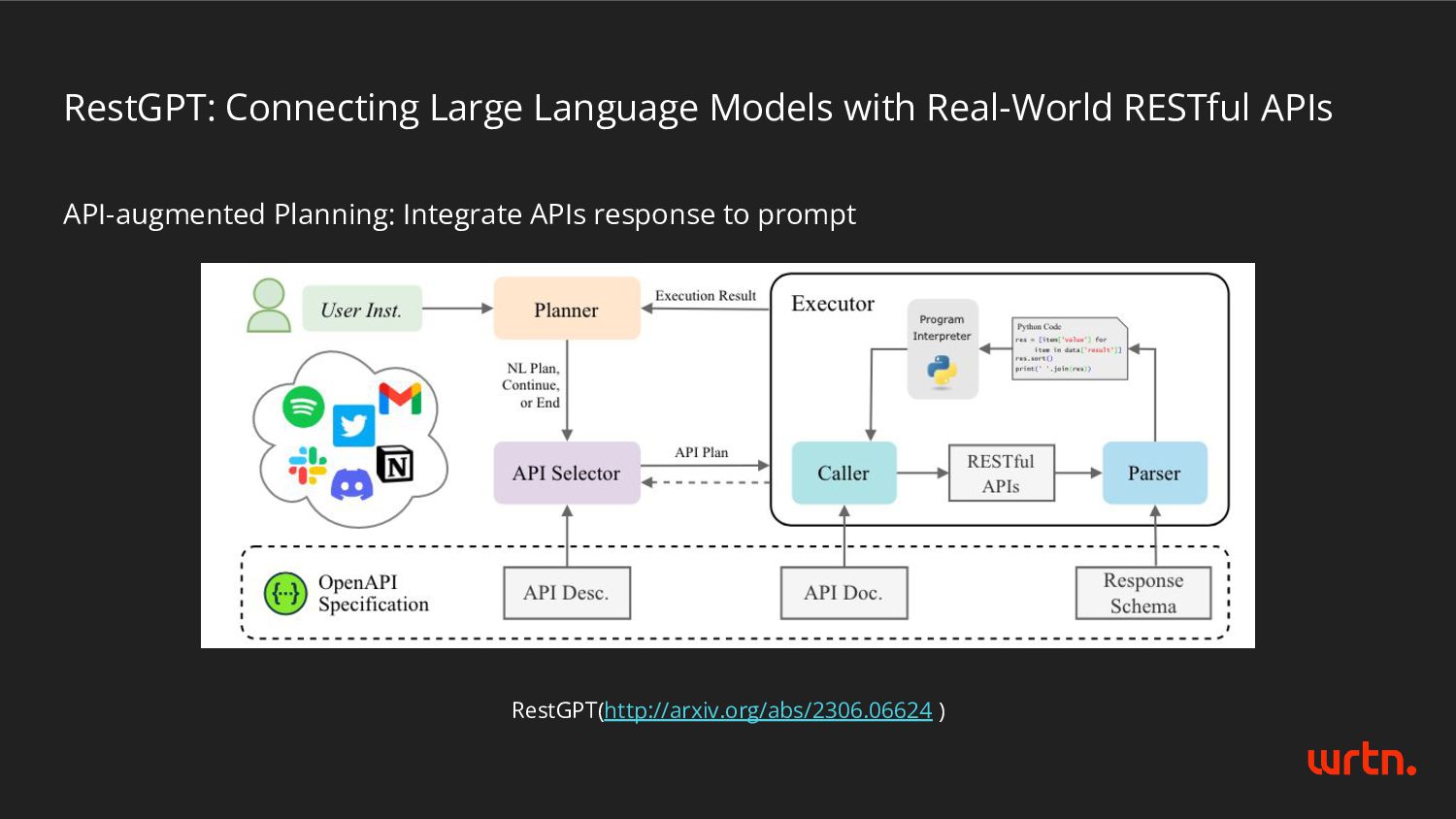
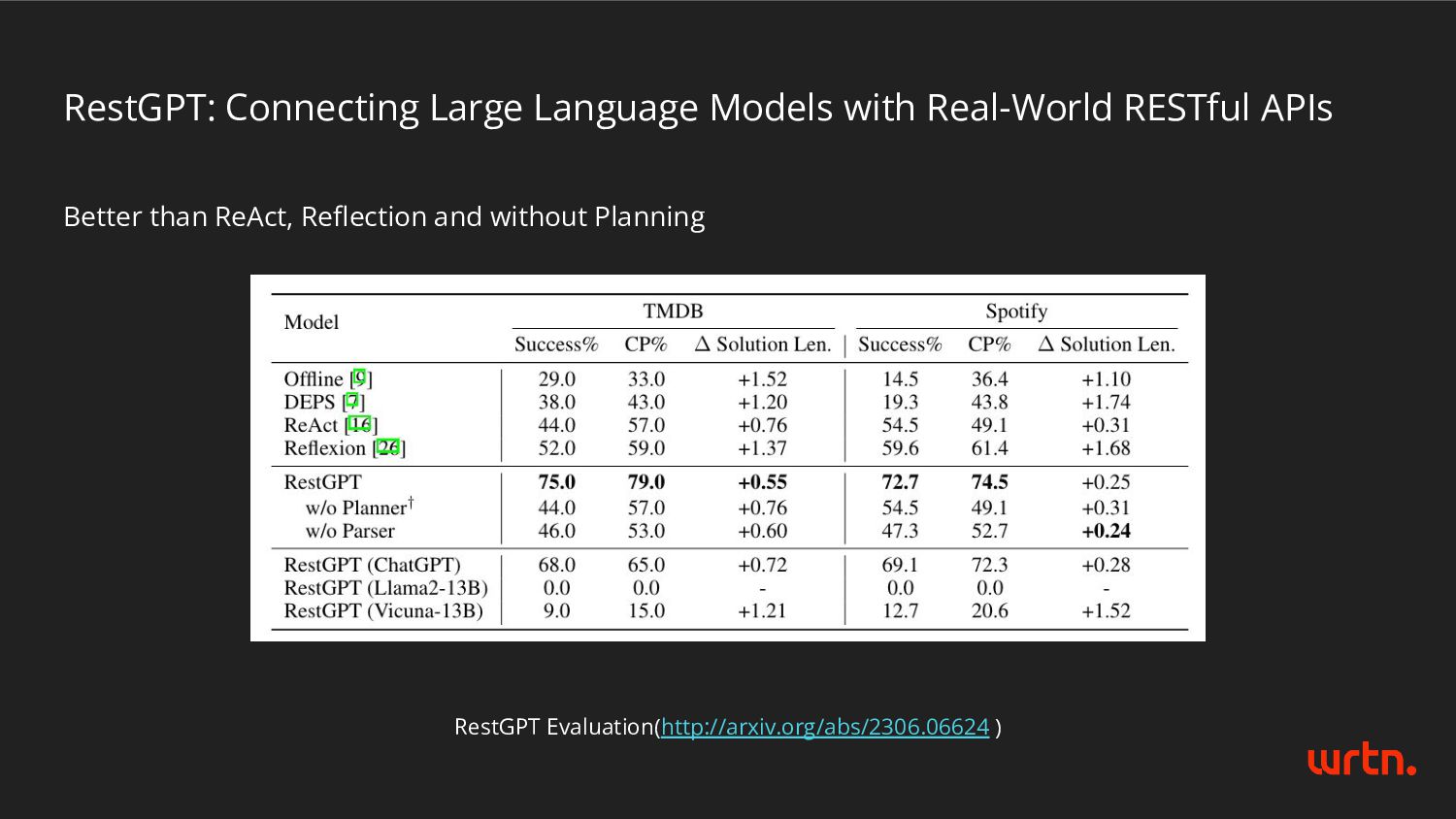
- RestGPT - Handling response as system component - Expected response type like type checking in Programming Language - e.g., The system expects valid json format response to LLMs like {“thought”: “something..”, “action”: “something…”} - Believe LLM capability and performance - e.g., LLM can make valid JSON format using regex constraints. - Utilize the APIs or python function as tool - e.g., LLM can call the search function. - Paper and Open-Source Projects provide lots of idea! - Thanks for the researchers and contributors. - (Optional) Code generation task is core component Common Points of Previous Works
is sitting in front of the notebook. His goal is making something impressive chat system. But he found the limitations of previous works. - Hard to generalize - e.g., In the common conversation service, MCTS isn’t easy to adapt. - e.g., Many research targets benchmark to prove the ability of proposed methods. - Evaluation metrics(Acc) ≠ Service metrics(MOU, Retention) - It’s necessary to evaluate using benchmark. - But system metrics and effectiveness is different. - Too complicated to maintain - Hard coupling with the old modules.. - Hard to find the best practice solution for utilizing the LLM
Objective definition: Set the target use case and overcome or solve the use case - Use LLM as components - Systematic features should be concerned… e.g., JSON mode, Latency, Cost … Systematic Solution
limitations - Good. AutoGPT can run few weeks to solve the problem. This was an amazing experience at the time(2023.03) - ✅ Objective definition: Set the target use case and overcome or solve the use case - Good. - ✅ Use LLM as components - Yes. Typical practice using LLM as components in the system.
Forge of AutoGPT supports this philosophy. - ❌ Handle the performance of AutoGPT - Hard to handle the quality of answer - Iterative reasoning can be lead to wrong answer. - ❌ Good to use in general purpose like ChatGPT - Can’t handle the error of commands. - Too expensive. - Too slow. - Hard to change the behavior of AutoGPT.
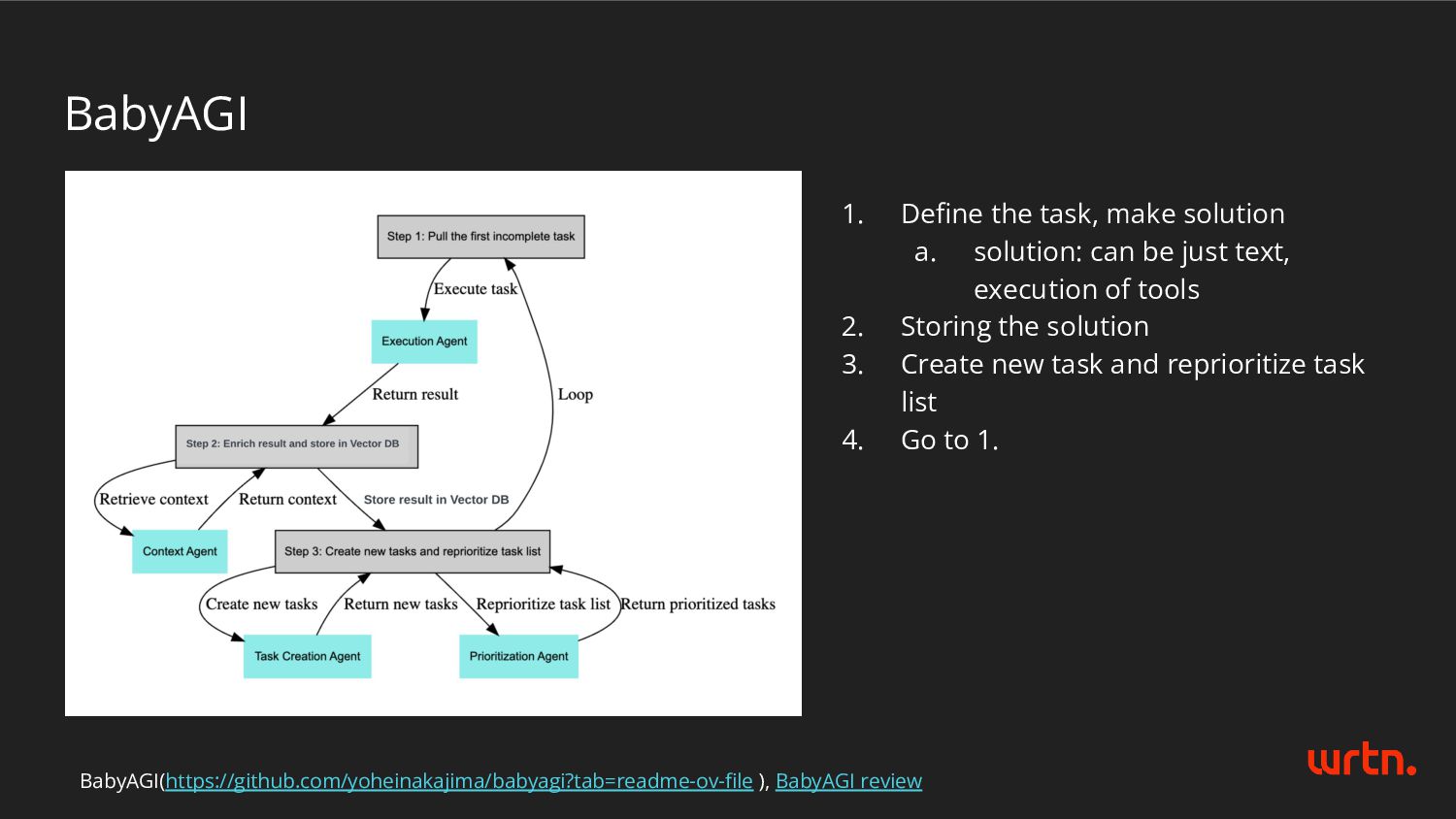
be just text, execution of tools 2. Storing the solution 3. Create new task and reprioritize task list 4. Go to 1. BabyAGI(https://github.com/yoheinakajima/babyagi?tab=readme-ov-file ), BabyAGI review
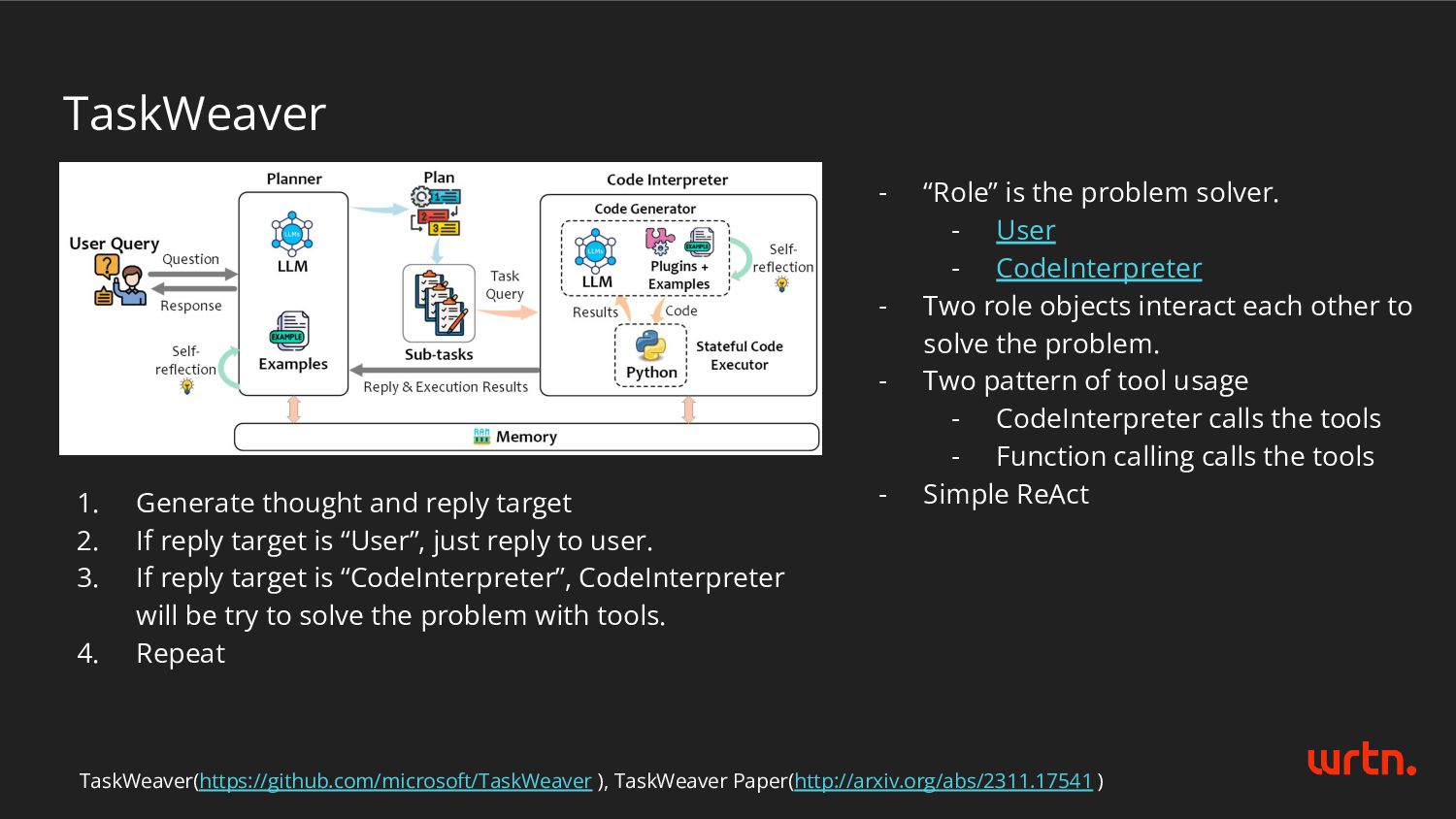
target is “User”, just reply to user. 3. If reply target is “CodeInterpreter”, CodeInterpreter will be try to solve the problem with tools. 4. Repeat TaskWeaver(https://github.com/microsoft/TaskWeaver ), TaskWeaver Paper(http://arxiv.org/abs/2311.17541 ) - “Role” is the problem solver. - User - CodeInterpreter - Two role objects interact each other to solve the problem. - Two pattern of tool usage - CodeInterpreter calls the tools - Function calling calls the tools - Simple ReAct
limitations - Good. TaskWeaver can a lot of use case. - ✅ Objective definition: Set the target use case and overcome or solve the use case - Good. - ✅ Use LLM as components - Yes. Typical practice using LLM as components in the system. - Planner prompt - json response schema: init_plan, plan, current_plan_step, send_to, message - Experience module - Forced not to repeat mistakes in Code Interpreter - e.g., tool argument generation, function usage scenario - LLM in the Plugin(e.g., summary, speech-to-text)
ChatGPT - Yes. It provide very similar experience when using CodeInterpreter. - It provide SerpAPI and web_search_plugin like Web Browsing in ChatGPT - ✅ Good to survey the code-based studying - Well-crafted code architecture compared to other python agent frameworks - ❌ Good to adapt in business service - Hard to customize the framework - Hard to adapt the framework into the online server. This is only the framework to research and find the possibilities/limitations. - ❌ Good to make own agent - No. It’s very hard to implement the new planner. - Very hard to modify the architecture. - ❌ Handle the performance of TaskWeaver. - Same as AutoGPT. Iterative reasoning can be lead to wrong answer.
- ✅ Good to make own agent - ✅ Good to use in general purpose like ChatGPT - ✅ Good to adapt in business service - ✅ Well-crafted code architecture - ✅ Faster, Cheaper, Simplify, Easy-prompt-debugging - ✅ Handle the performance There is no public solution that meets all of these.
and prompt results - ❓ Good to evaluate the system performance on offline - Simple evaluation: Just use public benchmark to approximate the service performance - ❓ Good to unit test the LLM component - Simple unit test for very small amount of dataset: Examples of Liner - ❓ Easy to utilize larger context of tool response - How to manage the large crawling response? - ❓ Good to log the service performance on online - If response of component generates the probability, record and log. - ❓ More domain-specific requirements … - Understanding domain knowledge Unit test reference: https://speakerdeck.com/huffon/autonomous-agent-in-production?slide=81
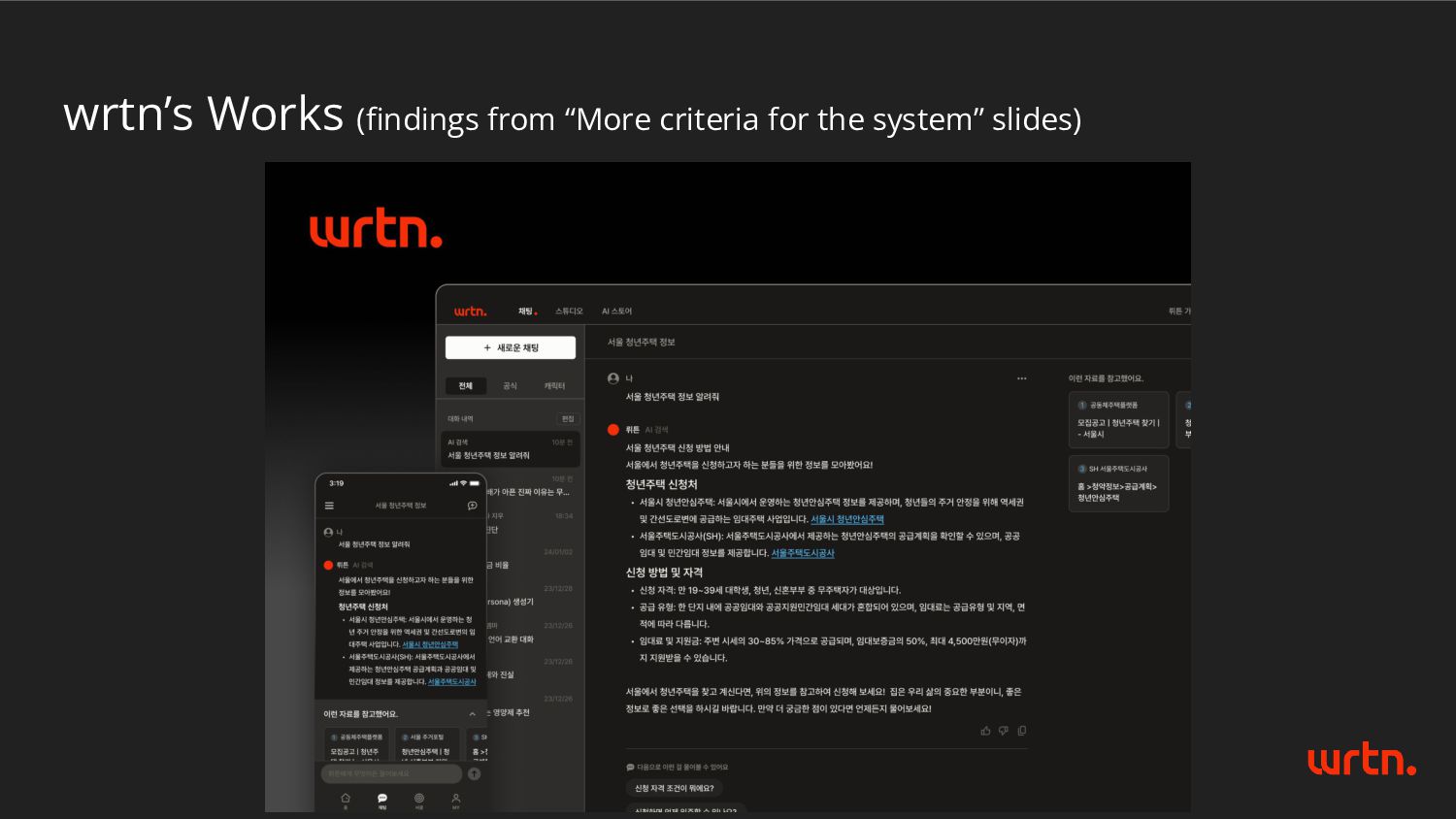
system” slides) - ✅ Easy-debugging for service and prompt results - Promptflow: doesn't provide debugging features, but visualization and modularization of promptflow leads to easy-debugging. ➡ Developoers should divide the features into graph flow. - 🏋 Good to evaluate the system performance on offline - ✅ Simple evaluation: Just use public benchmark to approximate the service performance Promptflow: provides simple evaluation feature. - 🏋 Better Inner-Benchmark systems - ✅ Good to unit test the LLM component - ✅ Simple unit test for very small amount of dataset Promptflow: provides flow-driven development and becomes easy to unit test. - ✅ Easy to utilize larger context of tool response - ✅ How to manage the large crawling response? ➡ “wrtn search” was trying to solve this problem and was accomplished. Promptflow isn’t ultimate solution, but very useful.
- ❓ Good to log the service performance on online (perspective of AI service) - Hard to define the score of AI service. - How to define the score of answer on the online service? - Maybe other engineering, service management is the solution. - e.g., RAG service can log the similarity score, but this isn’t the user satisfaction. - ❓ More domain-specific requirements … - 🏋 How do you define meaningful things to user and how will the system take it? - Areas the company will always need to address and prove
and natural methods of building AI service - Easy to compose complex functional requirements as service - Easy to overcome LLM performance 👎 Cons - Hard to accomplish good architecture design - Hard to debug, cooperative engineering - Complicated metrics and evaluation for research and service - All the quality of system are depends on response of tool - Depends on too many outer service. It makes expensive service.
engineering and LLM components - Always follow up the new methods, and decide to adapt - LLM library isn’t always the solution. It can be burden. - Easy Evaluation, Easy Scoring for fast-prototyping. - But still needs Korean Agent Benchmark.
어려웠던 부분들이 많았습니다. - 그럼에도 Stable Diffusion이 열풍에서 많은 분들이 Open-source model들의 성장, use case 도출, 생성 툴 architecture 개선들을 관찰했듯이 TaskWeaver, AutoGen과 같은 LLM project architecture 관점의 다양한 시도들이 Open-Source 진영에서 일어나기 바랍니다. - 개인적으로 국내외 많은 contributor들의 수혜를 받고 있는만큼 더 많은 기여를 하고자 노력하겠습니다. - 부족한 발표였던만큼 관련 커뮤니티에서 AI system 구성에 관한 추가적인 논의들로 좋은 관점들을 보충해주시면 좋겠습니다. Another Conclusion
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}