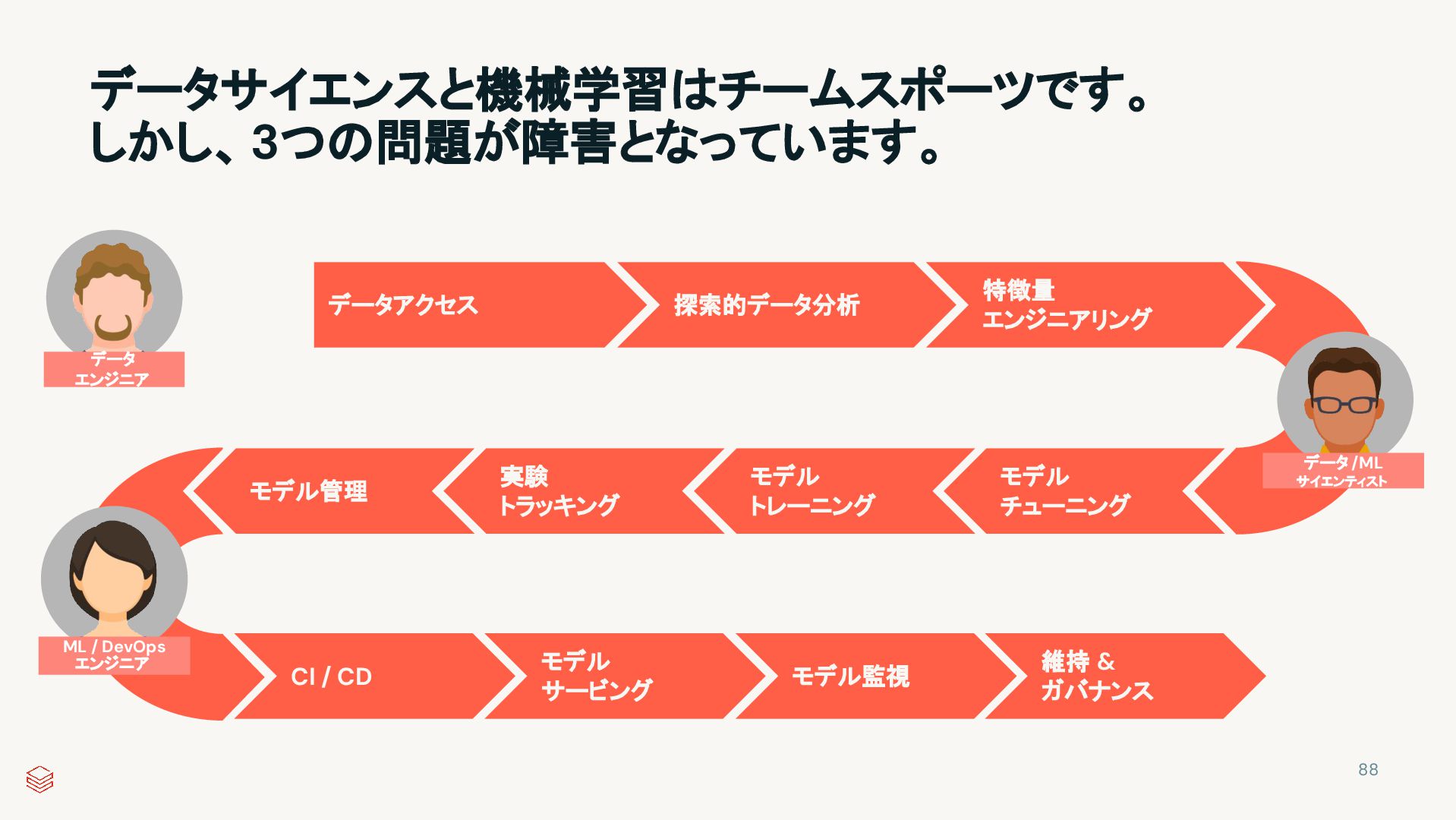
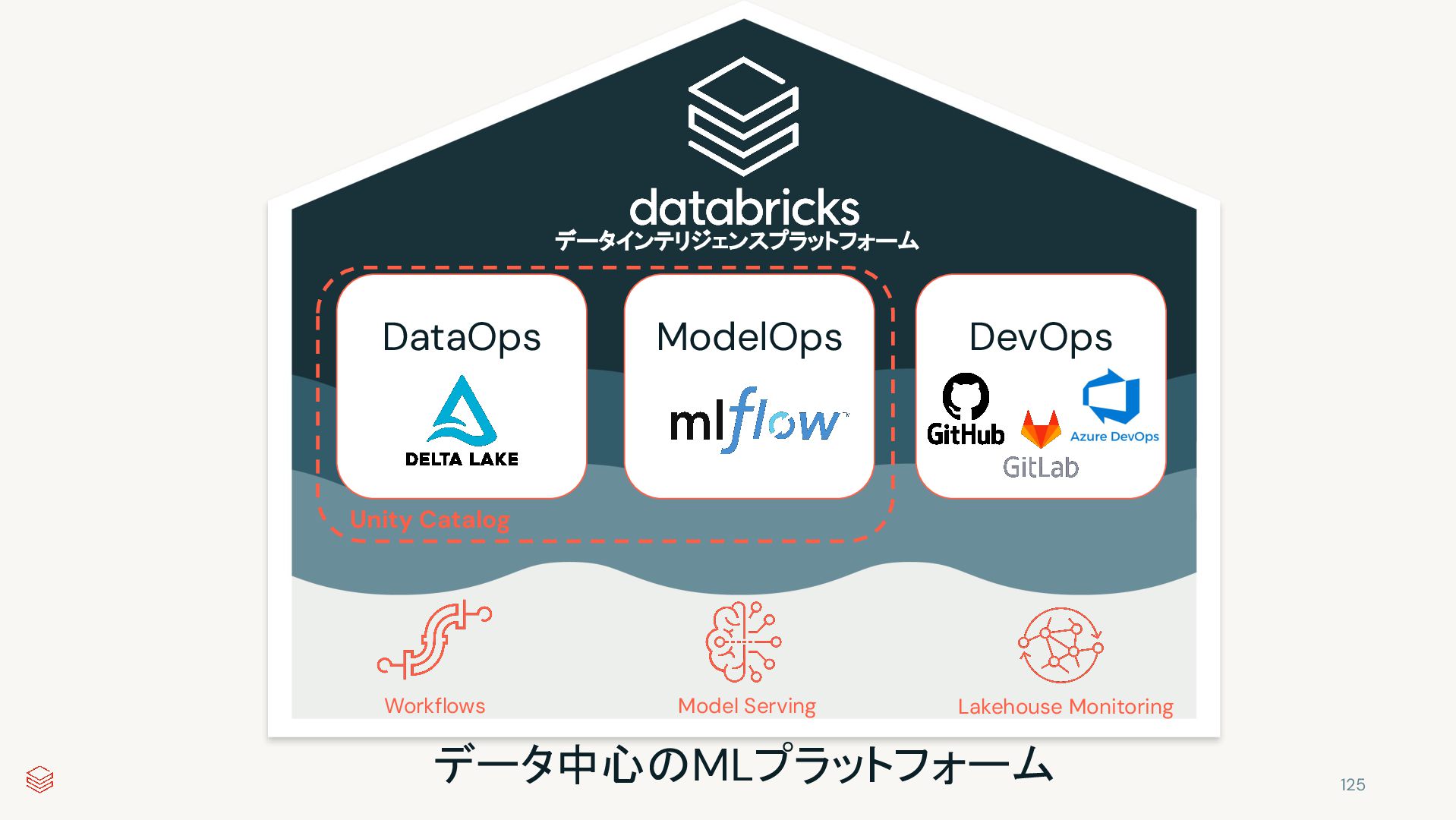
Tuning Model Training Experiment Tracking Model Management CI / CD Model Serving Model Monitoring Maintenance & Governance < Data Engineers> < Data Scientists > < MLOps + DevOps > データ / ML サイエンティスト ML / DevOps エンジニア The hardest part of data science is data 実験は複雑なものです MLの本格運用は困難です コラボレーティブデータ探索ワークスペース ビルトインのデータ準備機能 | ネイティブの可視化機能 | 最適化されたランタイム 38
Tuning Model Training Experiment Tracking Model Management CI / CD Model Serving Model Monitoring Maintenance & Governance < Data Engineers> < Data Scientists > < MLOps + DevOps > ML / DevOps エンジニア The hardest part of data science is data Experimentation is complex MLの本格運用は困難です コラボレーティブデータ探索ワークスペース ビルトインのデータ準備機能 | ネイティブの可視化機能 | 最適化されたランタイム 実験環境 特徴量ストア | 実験トラッキング | モデルレジストリ 39
Model Training Experiment Tracking Model Management CI / CD Model Serving Model Monitoring Maintenance & Governance < Data Engineers> < Data Scientists > < MLOps + DevOps > The hardest part of data science is data Experimentation is complex Productionizing ML is difficult コラボレーティブデータ探索ワークスペース ビルトインのデータ準備機能 | ネイティブの可視化機能 | 最適化されたランタイム 実験環境 特徴量ストア | 実験トラッキング | モデルレジストリ MLOps + DevOpsの本格運用 Git連携 | モデルサービング | モデル監視 40
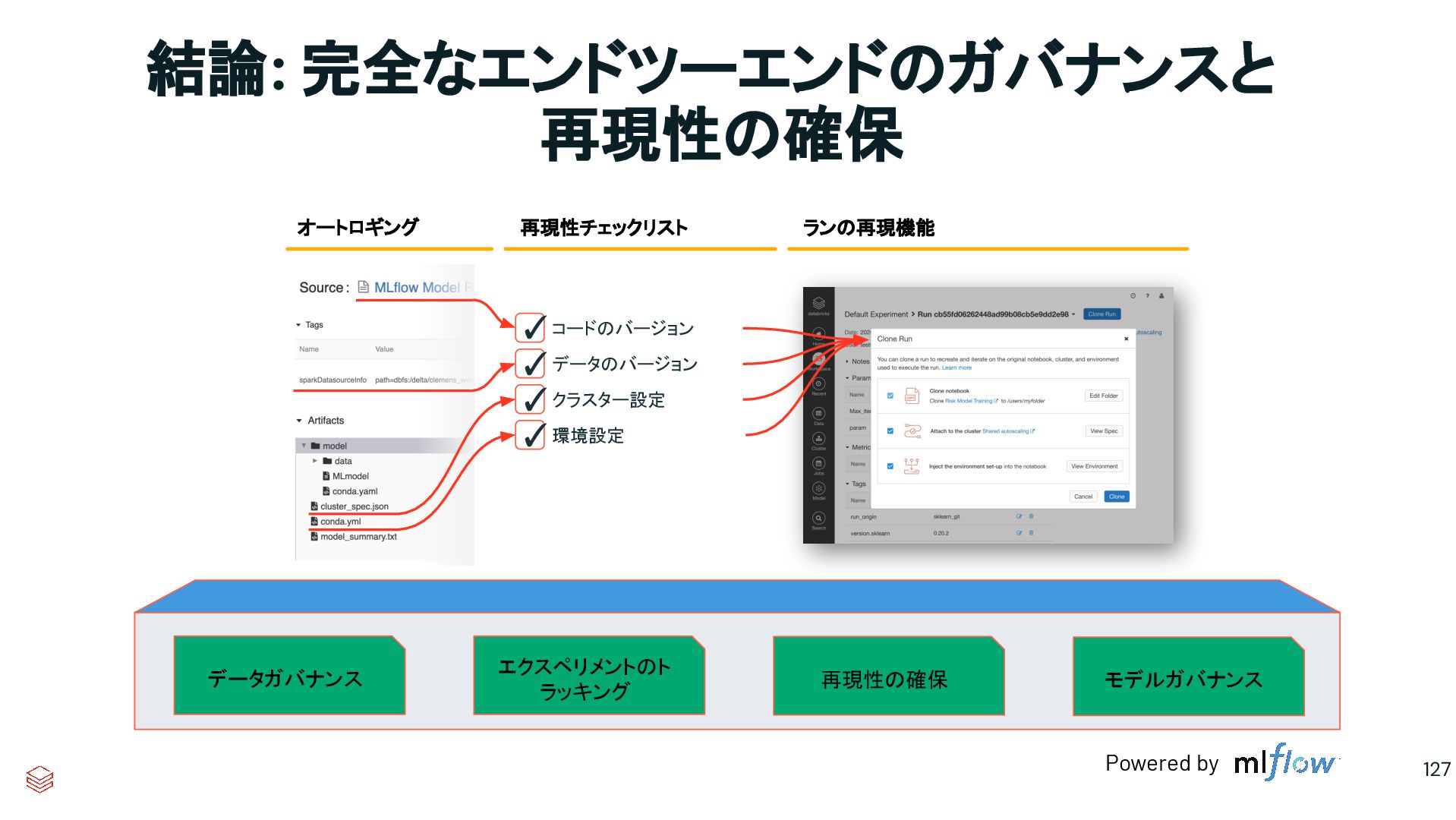
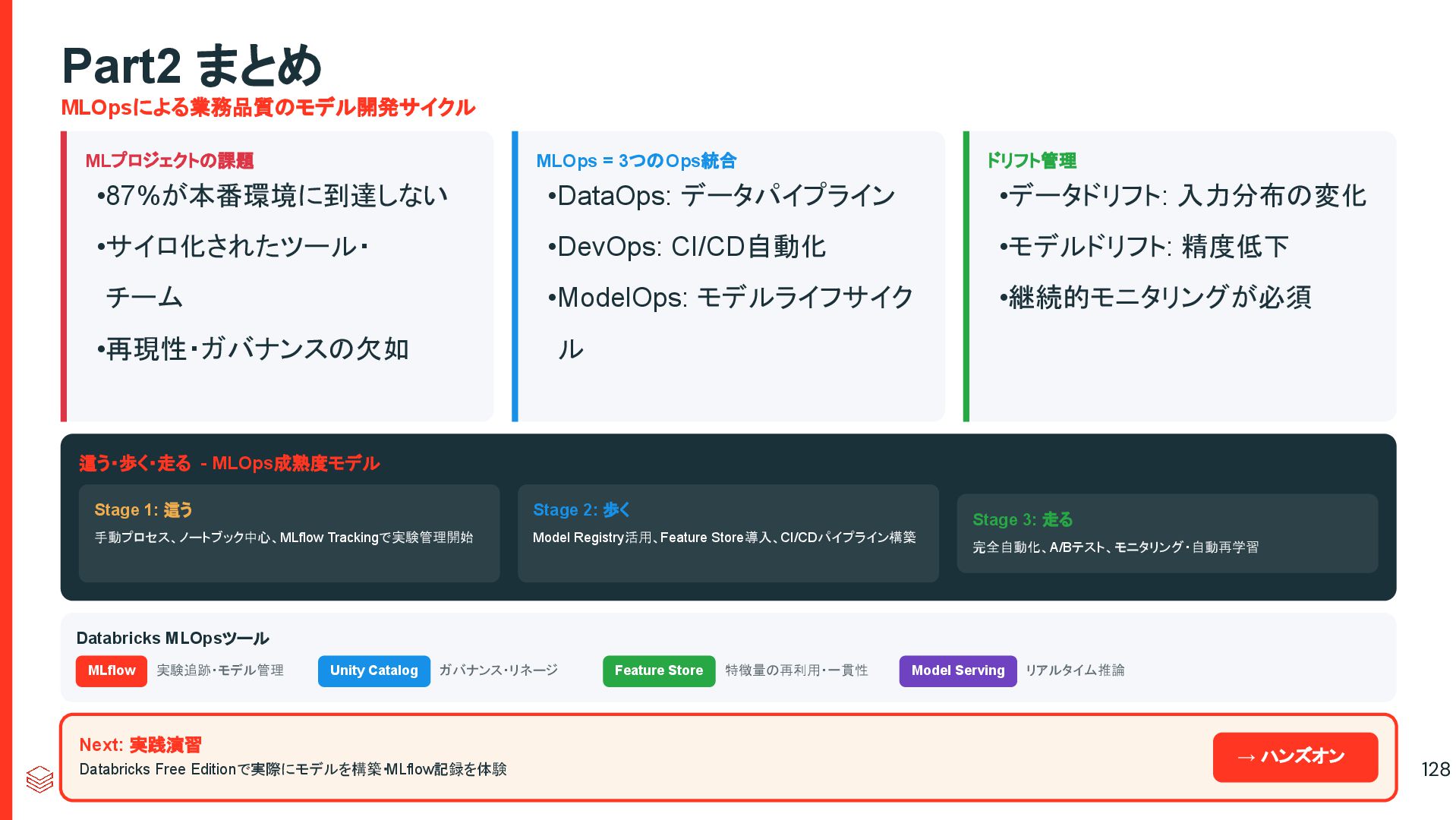
took me 3 weeks to develop the model. It’s been >11 months, and it’s still not deployed.” @DineshNirmallBM #StrataData #strataconf 10:19 AM - Mar 7, 2018 • TweetDeck 企業における機械学習の物語: モデル構築に3週間かかったけど、 11ヶ月以上経ってもデプロイされてい ません。 86
took me 3 weeks to develop the model. It’s been >11 months, and it’s still not deployed.” @DineshNirmallBM #StrataData #strataconf 10:19 AM - Mar 7, 2018 • TweetDeck 混沌としたツールチェイン 環境に散在する異なる目的に特化したML ツール 実世界で求められる パフォーマンスの欠如 時間経過に伴うモデルドリフト、 貧弱な観察可能性、説明可能性 企業における機械学習の物語: モデル構築に3週間かかったけど、 11ヶ月以上経ってもデプロイされてい ません。 なぜMLOpsは それほど難しい のでしょうか? 87
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
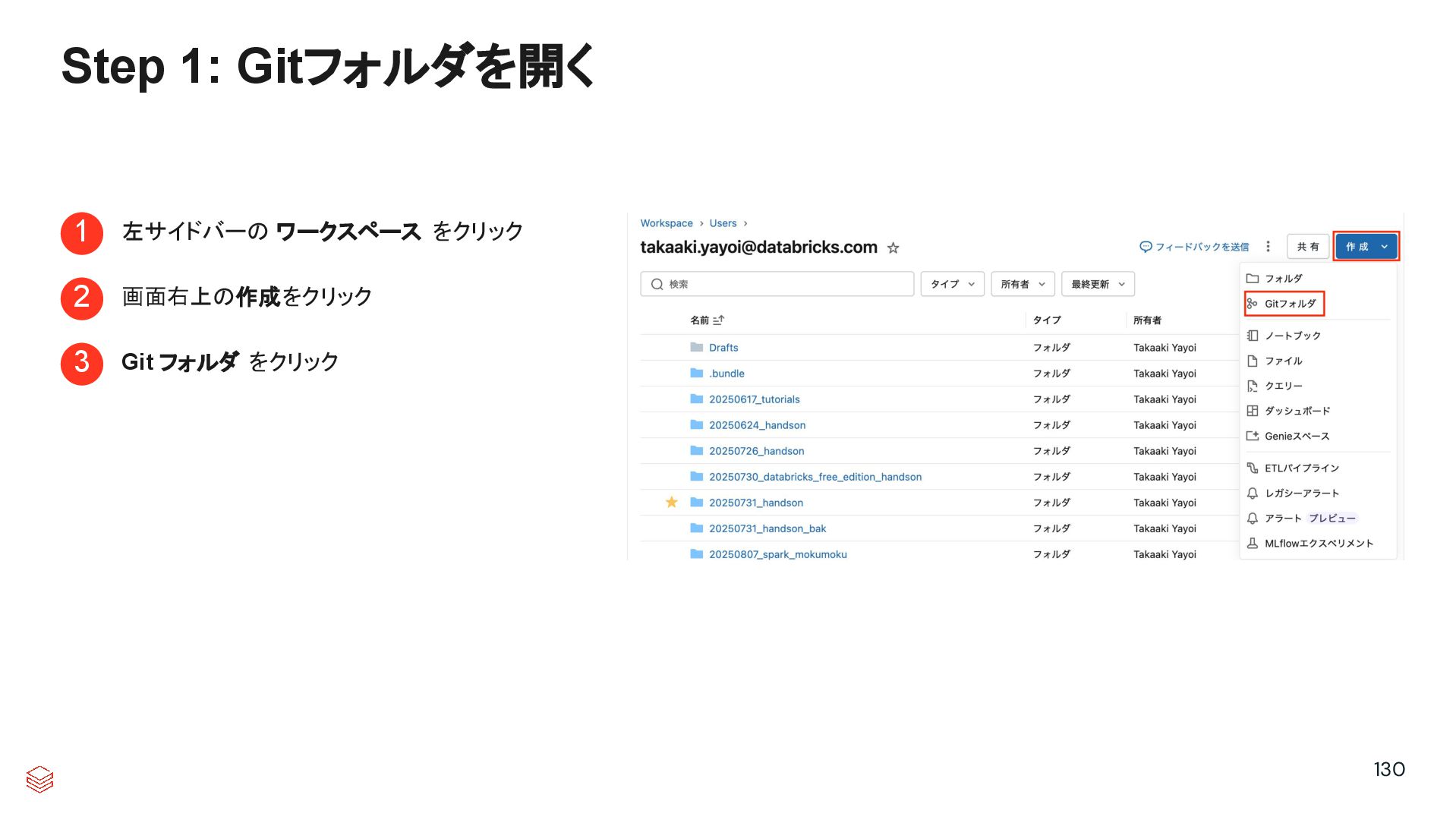
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考資料 135 • Qiita記事(機械学習・ MLflow基礎) • [2024年版] Databricksにおける機械学習モデル構築のエンドツーエンドのサンプル • MLflowのご紹介:オープンソース機械学習プラットフォーム](https://files.speakerdeck.com/presentations/20686a54ced44ea8a73c6acb1de7fef4/slide_134.jpg){kind=link}
{kind=link}