to conference sessions ◦ Extract characteristic words from their title and description with NLP(Natural Language Processing) ◦ But I’m NOT familiar with NLP, so I want to use as easy tools as possible ◦ Easy tools - Cloud APIs
Cloud Natural Language API (GCP) ◦ Syntactic analysis • Text Analytics API (Azure) ◦ Key-phrase extraction API -> These APIs are directly available in Japanese!!
spreadsheet ◦ Japan Container Days 2018 (no descriptions) ◦ Scala Kansai Summit 2018 ◦ JAWS DAYS 2019 ◦ Scala Matsuri 2019 ◦ Google Cloud Next Tokyo 2019 • Export as CSV (script input) ◦ id, title ◦ id, title + description
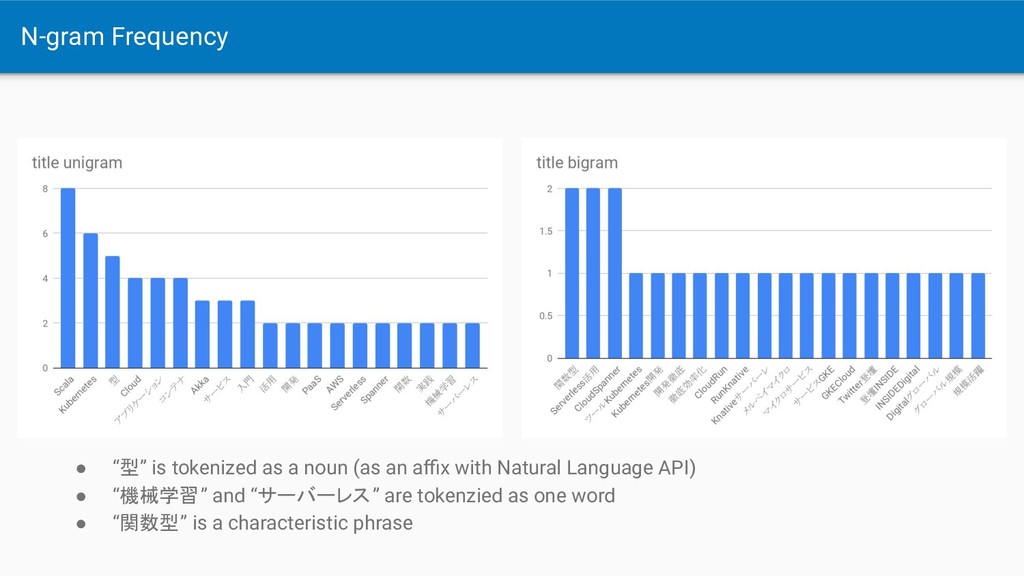
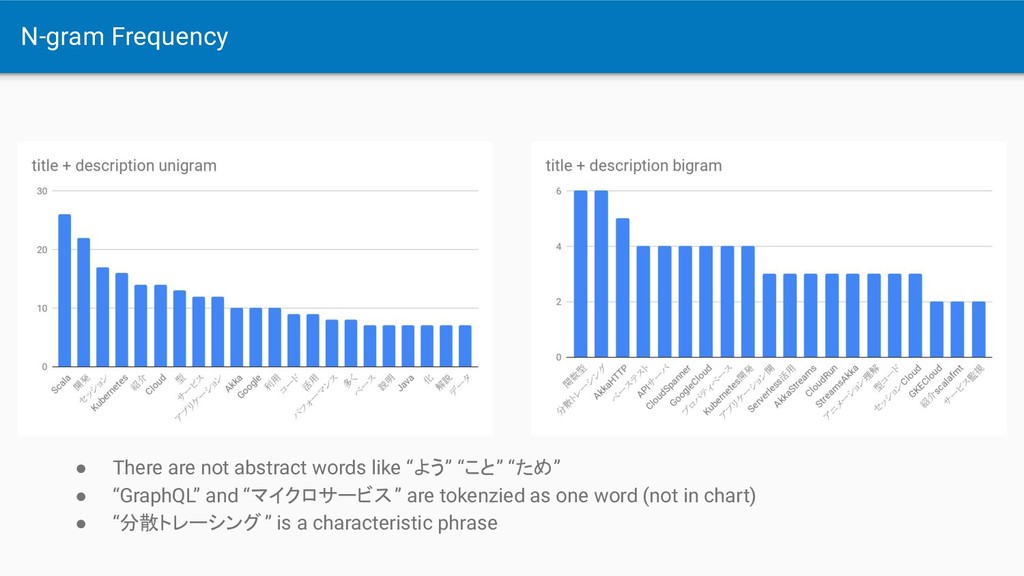
the low frequency(Max=4, mostly 1) • [title + description] the high frequency(Max=9) but they are not technical words • “Kubernetes” is 4 in title, but is 3 in title + description
Spanner ◦ The frequency depends on title and description quality • Cloud APIs are useful • Key-phrase is not enough, using N-gram too is better • MeCab + NEologd can analyze better than Native Language API (in Japanese/specific category?)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Key-phrase frequency • [title] find technical words but they are](https://files.speakerdeck.com/presentations/b2024485b2c74831ba95aa1eddbe2c69/slide_7.jpg){kind=link}
{kind=link}
![N-gram Frequency • [title unigram] More general topics (ex. Scala,](https://files.speakerdeck.com/presentations/b2024485b2c74831ba95aa1eddbe2c69/slide_9.jpg){kind=link}
![N-gram Frequency • [title + desc bigram] more understandable words](https://files.speakerdeck.com/presentations/b2024485b2c74831ba95aa1eddbe2c69/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}