at Yahoo! JAPAN). 2012~ Advertising background engineer 2015~ Researcher and developer of news recommendations In 2016, We introduced the first deep learning model for news recommendation to Yahoo Japan top page. And since then, we have continued to improve the model in parallel with user analysis. Shumpei Okura (Yahoo Japan Corp.)
our systems - Today’s main theme: 1. How this module is implemented? 2. What are difficult issues? How are we coping or trying to coping to them? Recommend for you
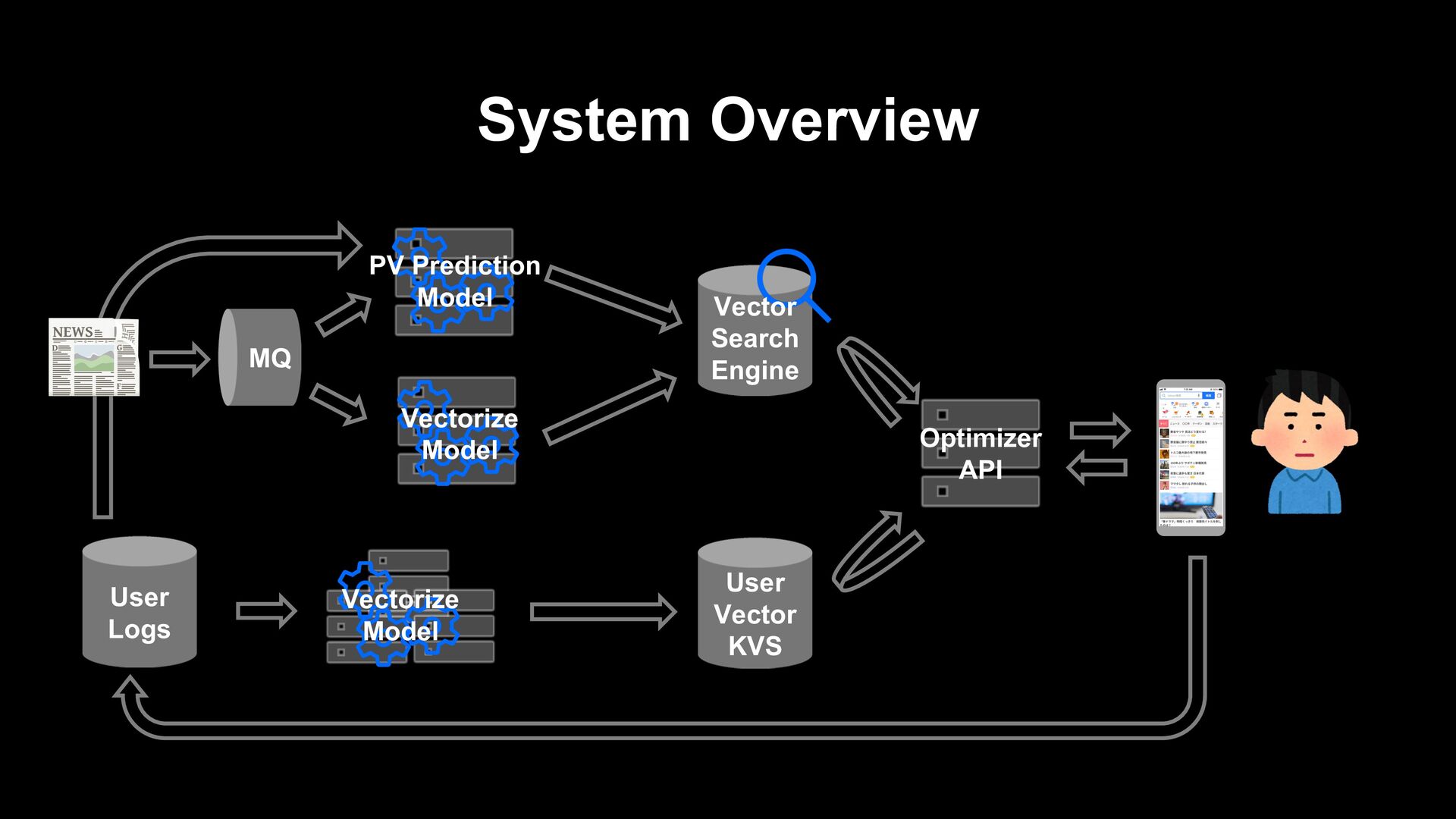
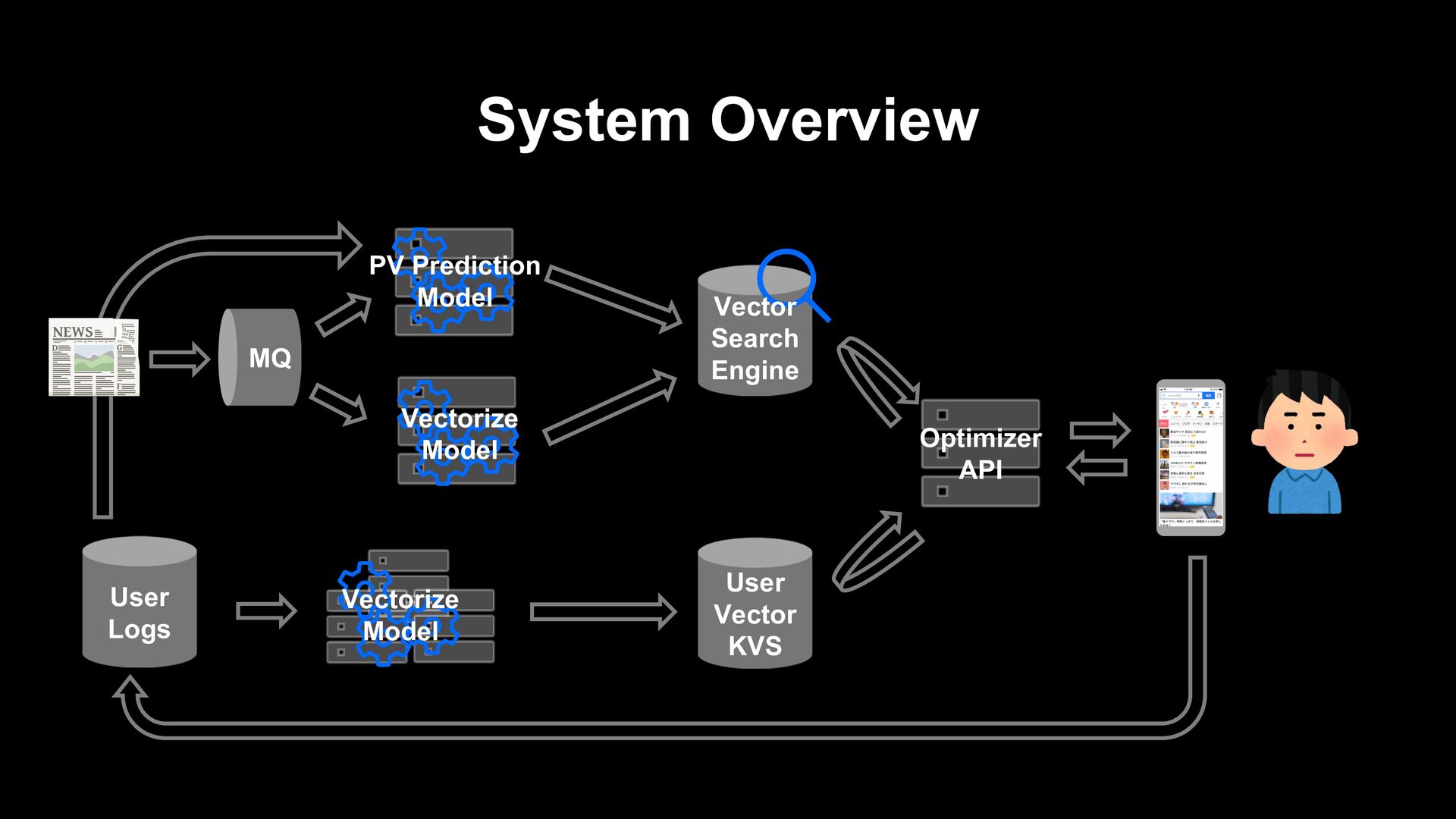
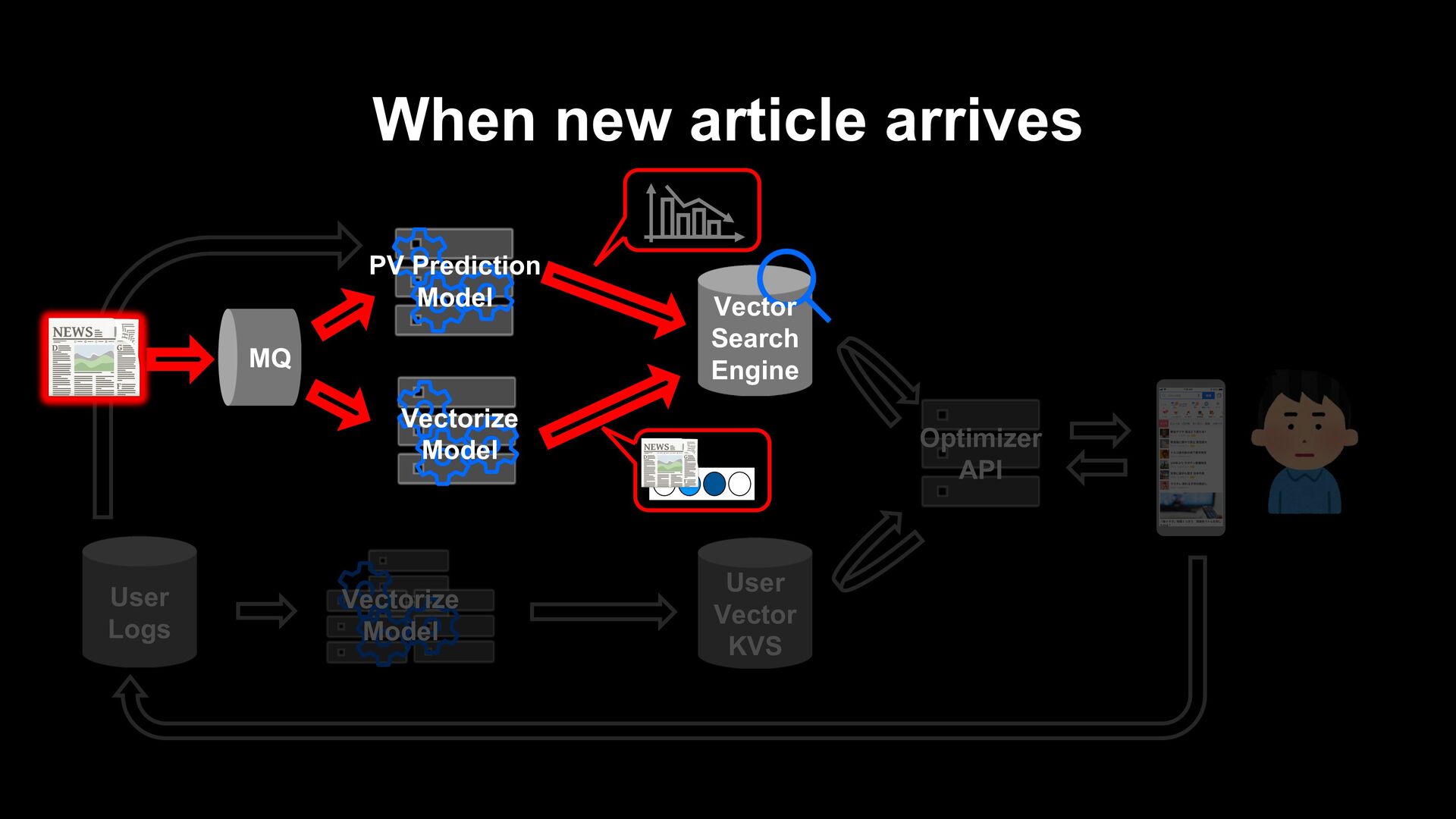
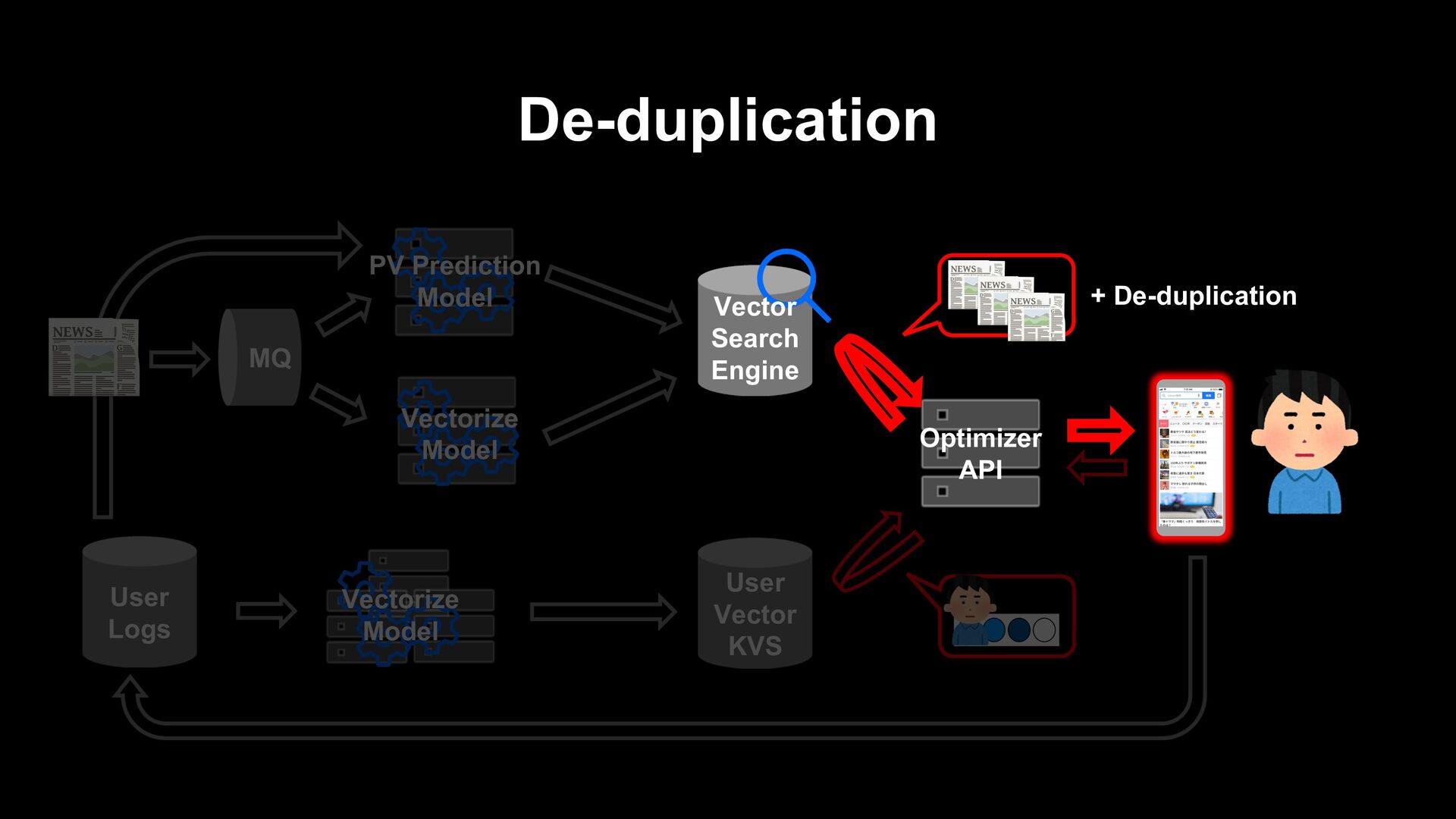
articles. - When updated information arrives, old information is no longer useful, and the next day it will be no longer interesting to users. Posted new articles immediately appear in the recommendation list.
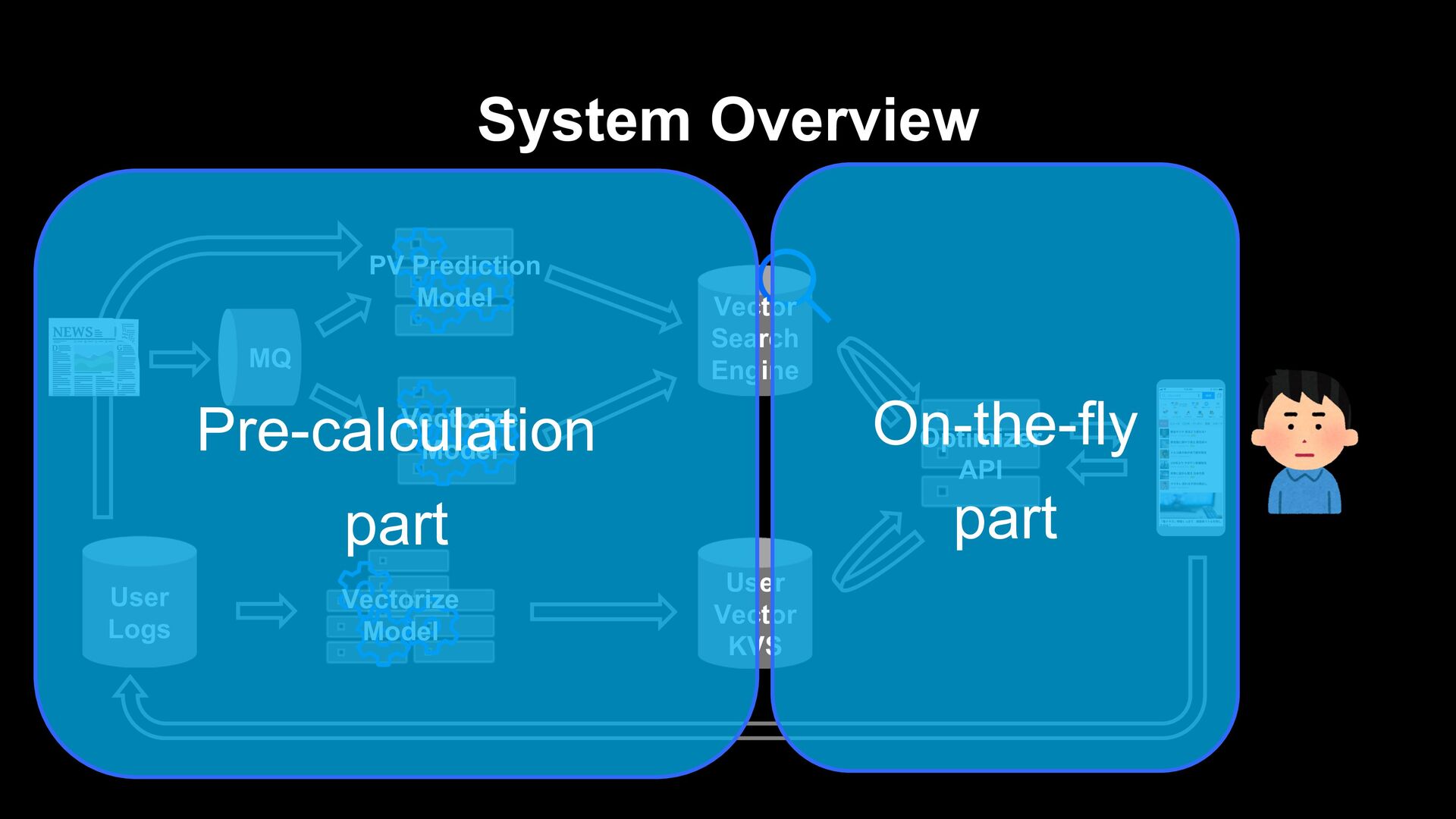
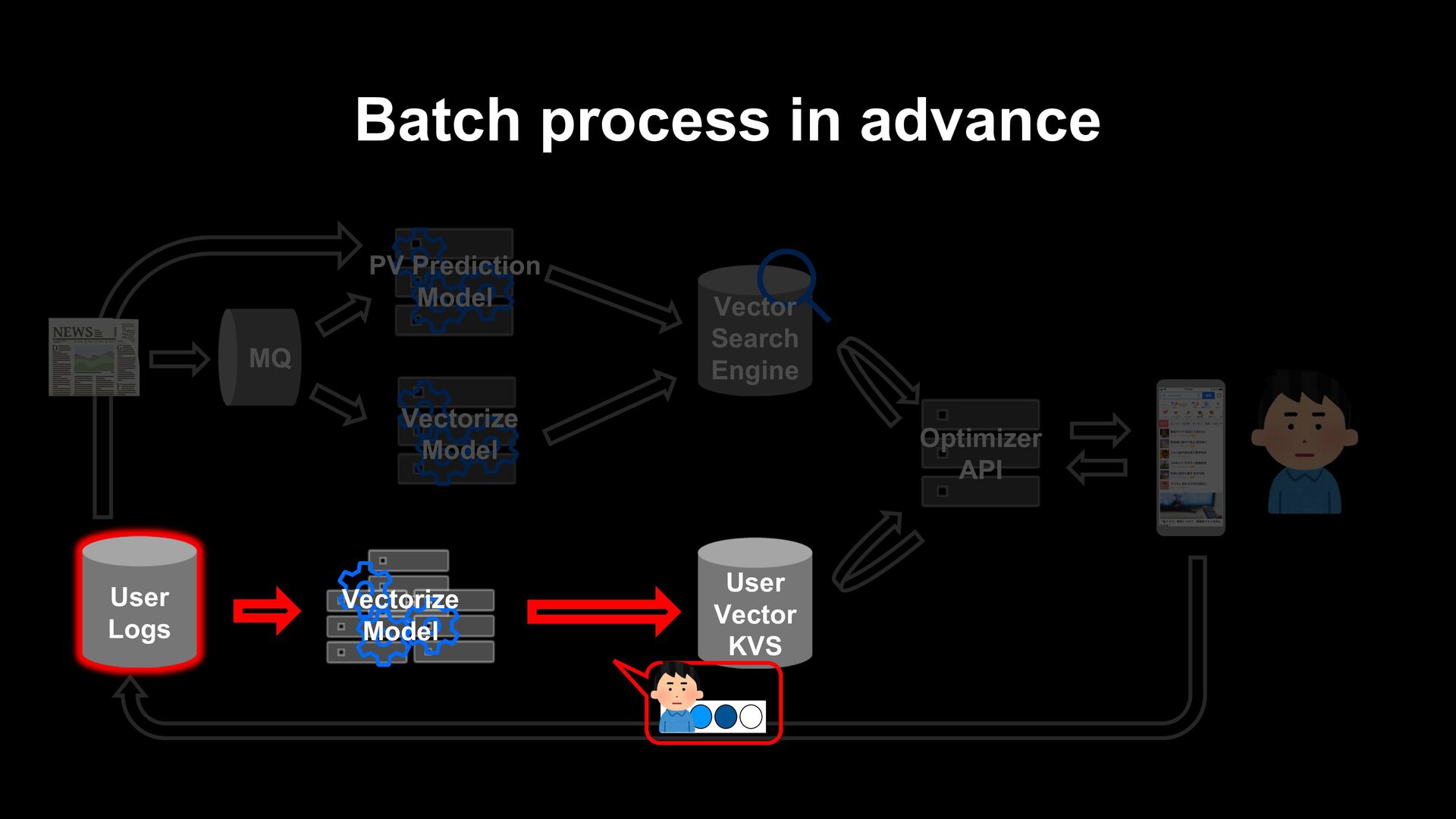
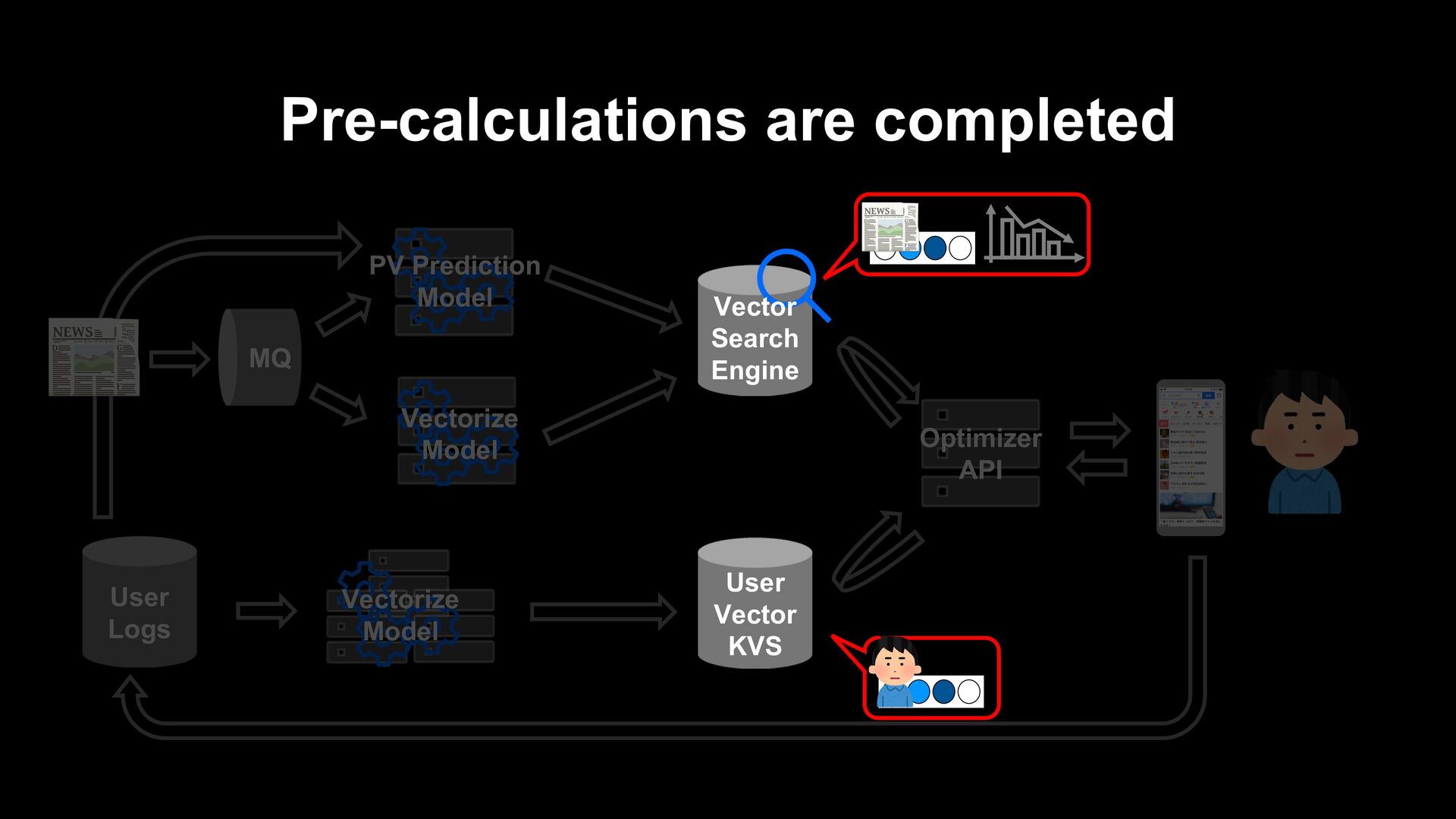
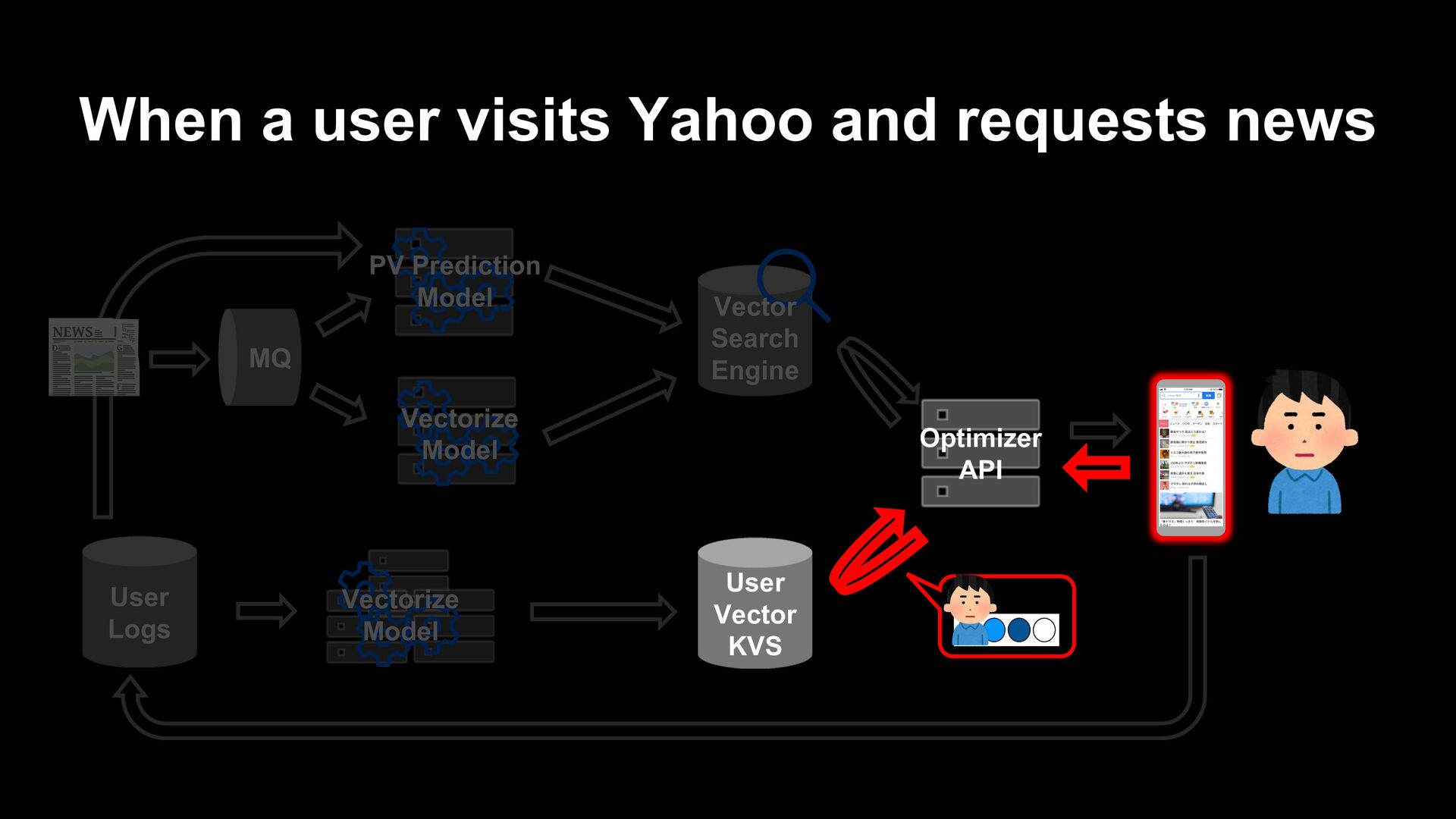
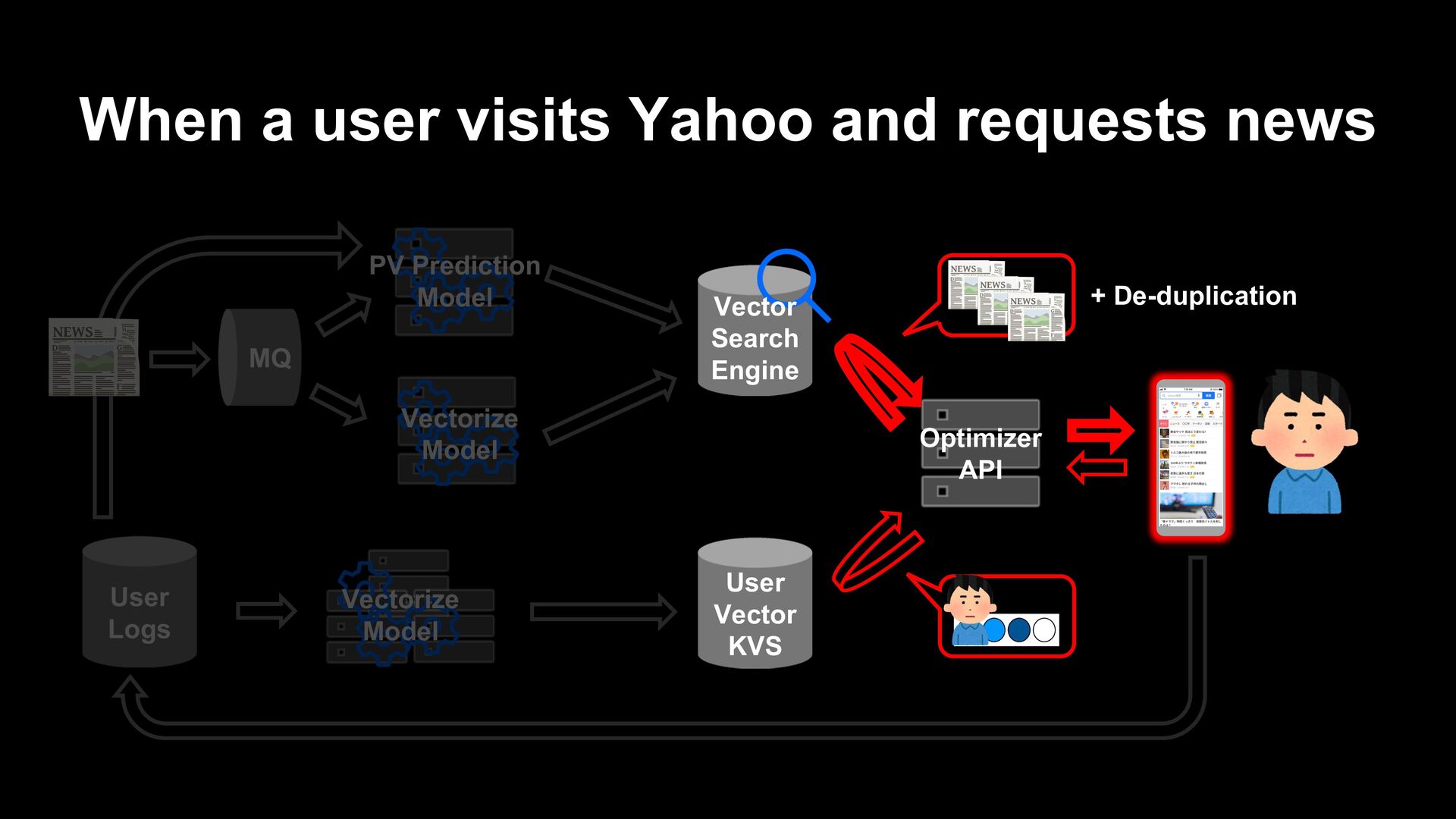
article itself (e.g. collaborative filtering) Generate a recommendation list from fresh articles on the fly when a user visits. Prepare a list of recommendations in advance
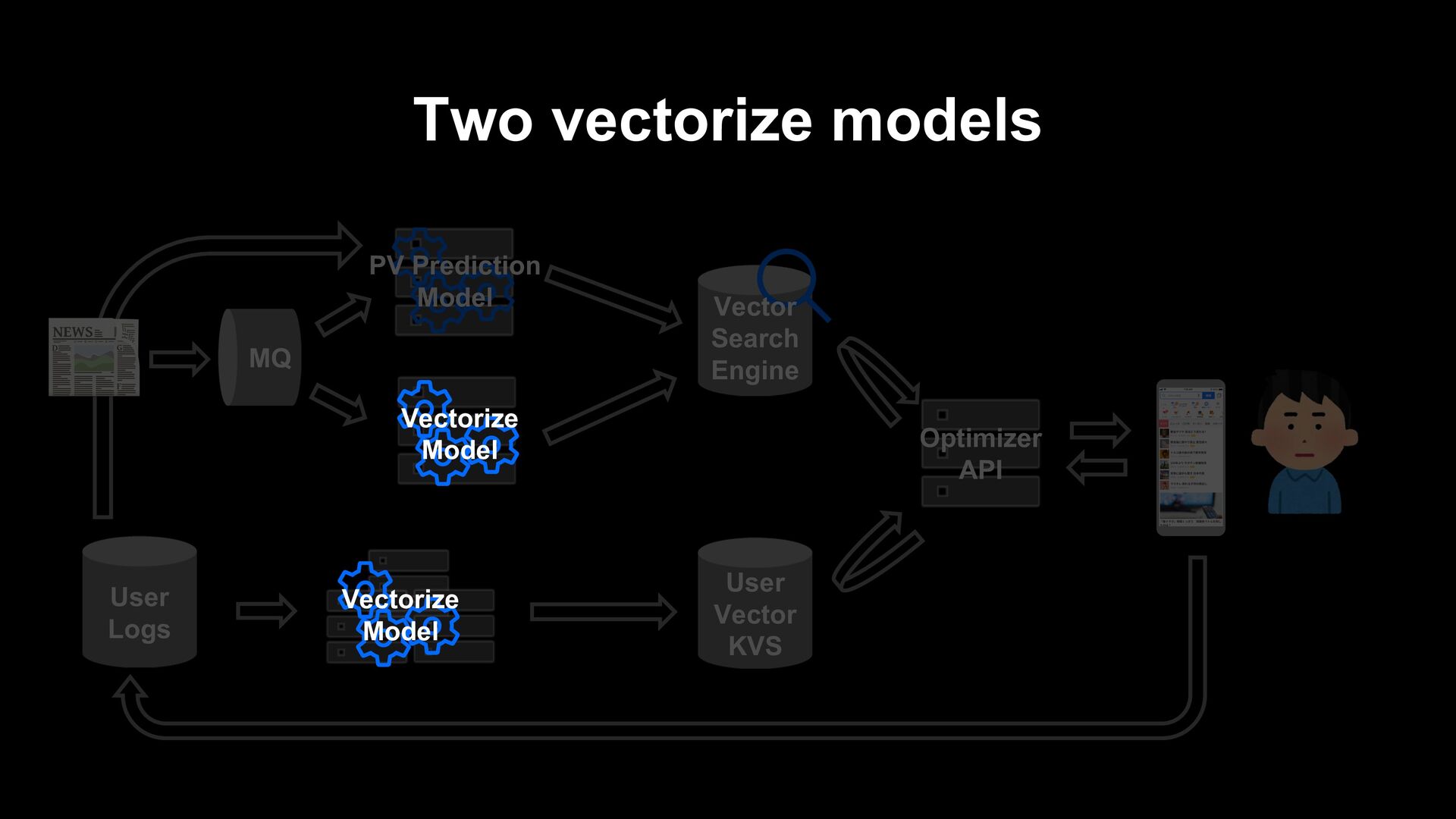
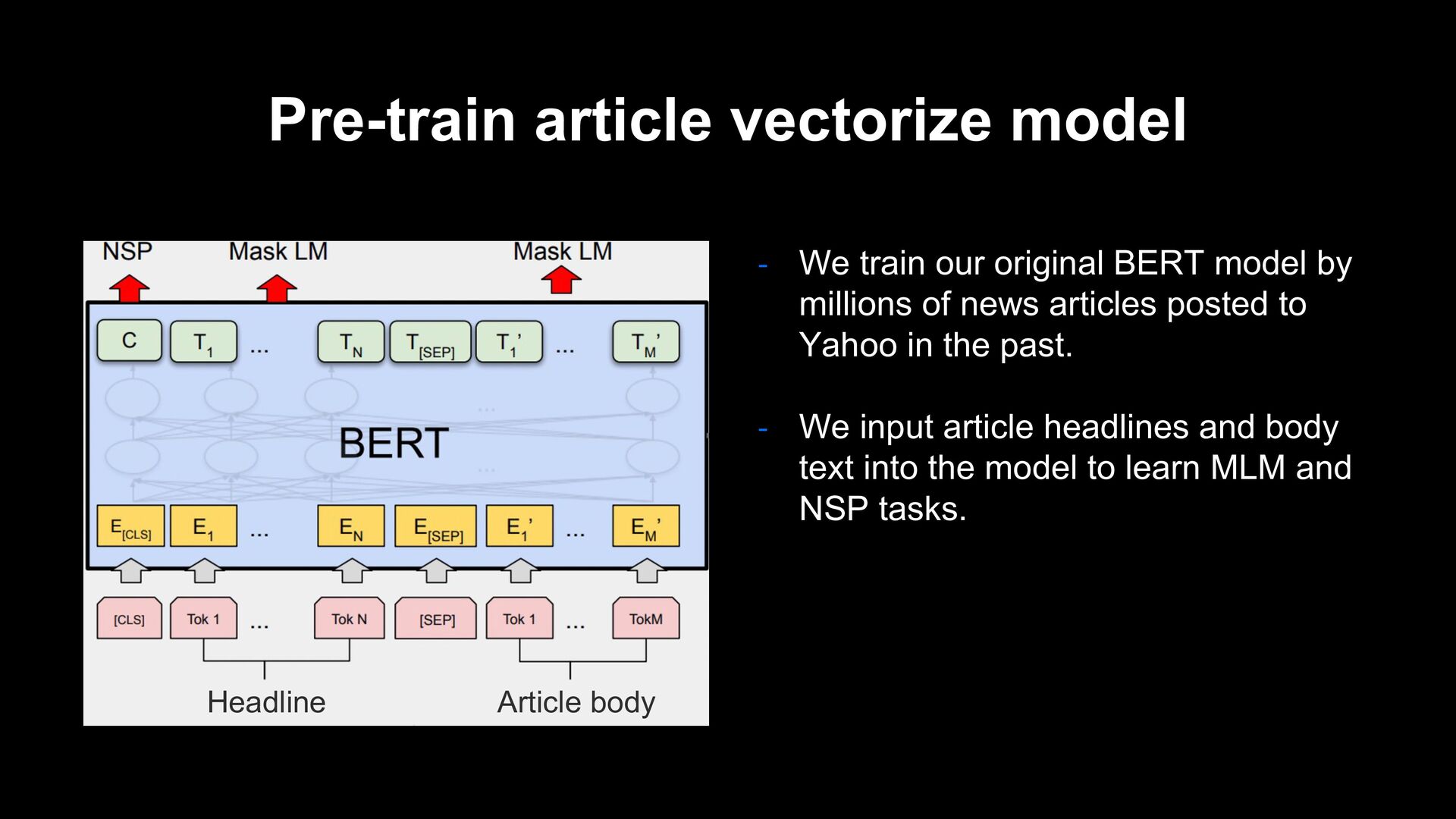
model by millions of news articles posted to Yahoo in the past. - We input article headlines and body text into the model to learn MLM and NSP tasks. Headline Article body
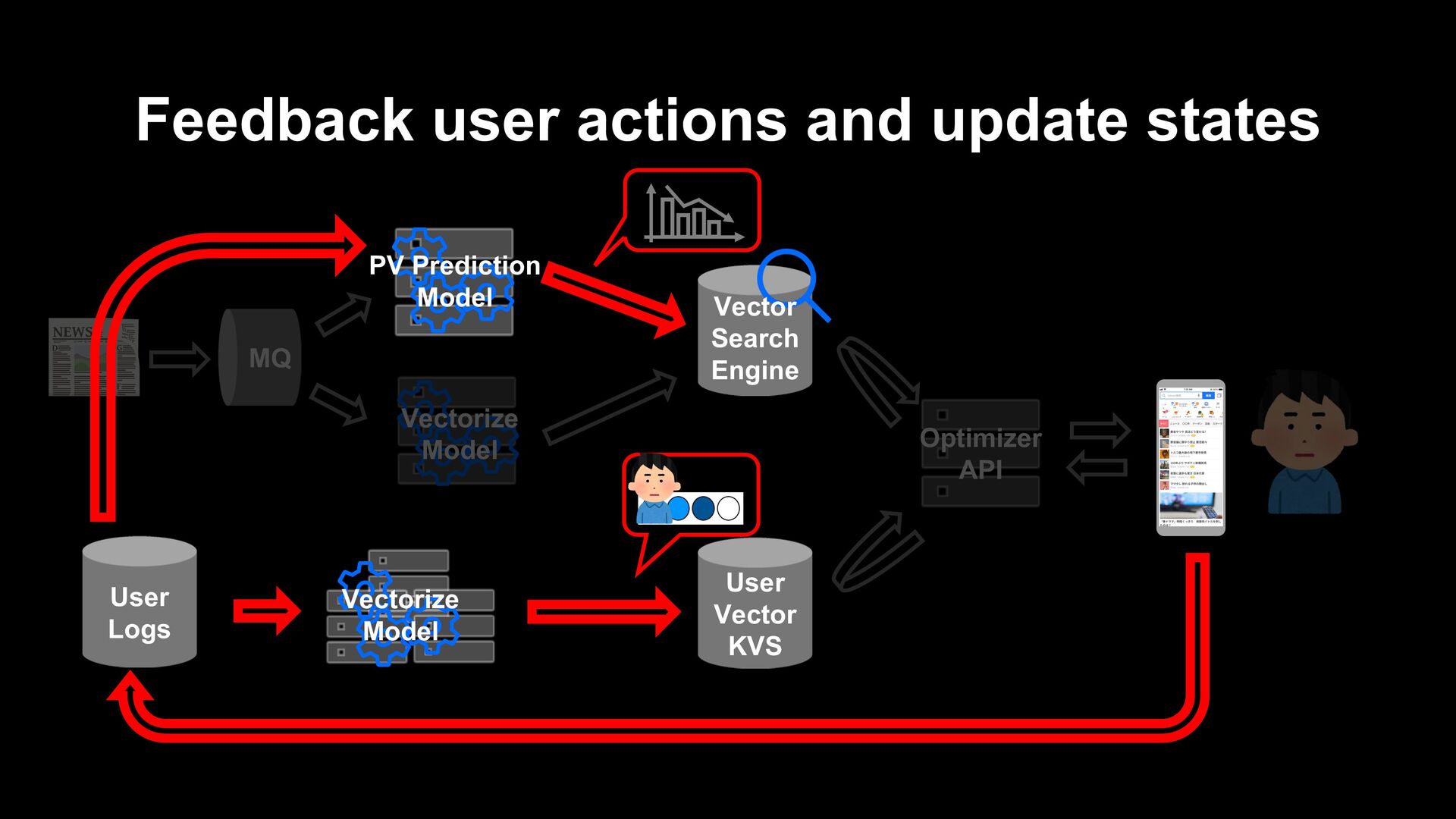
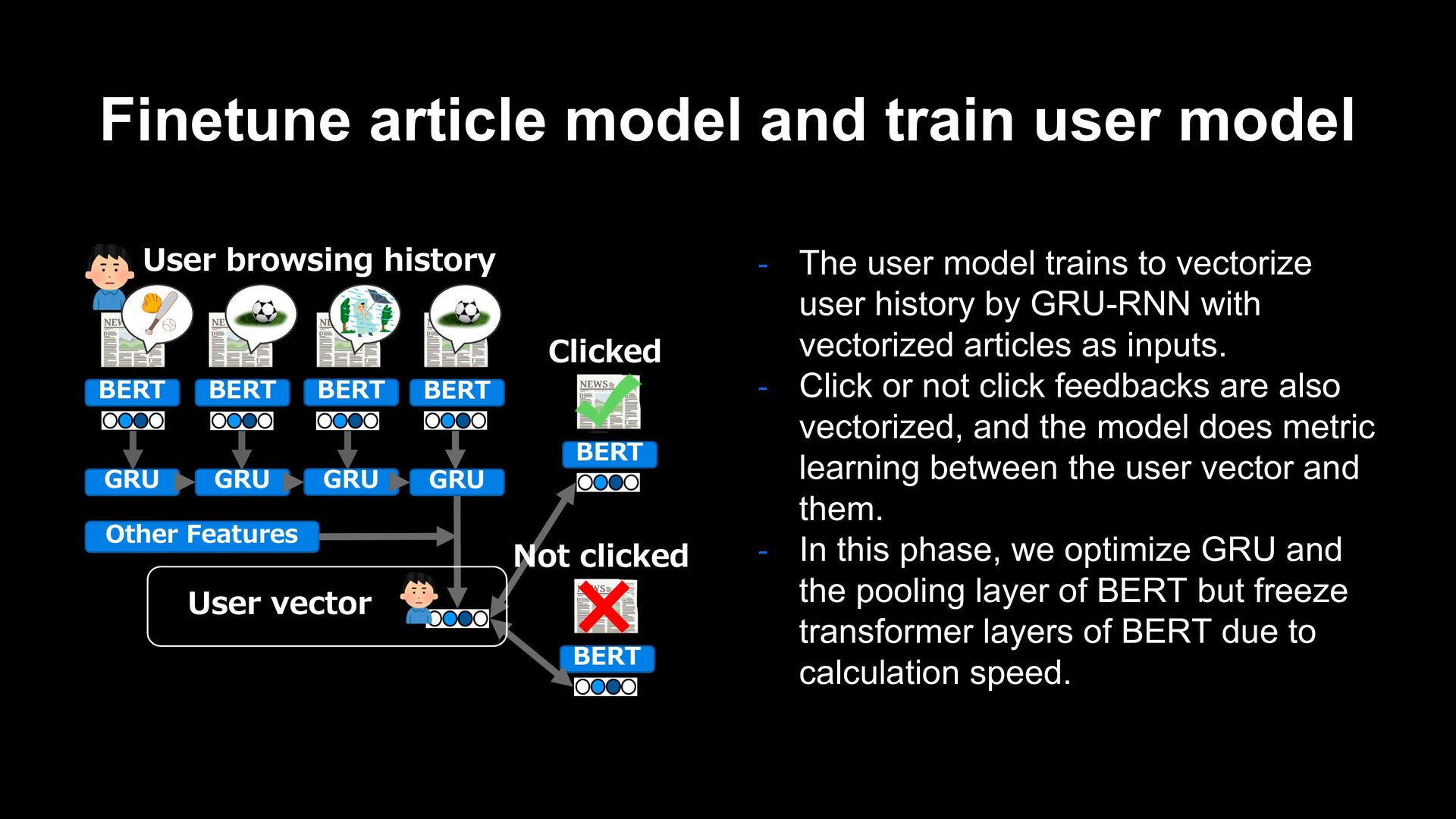
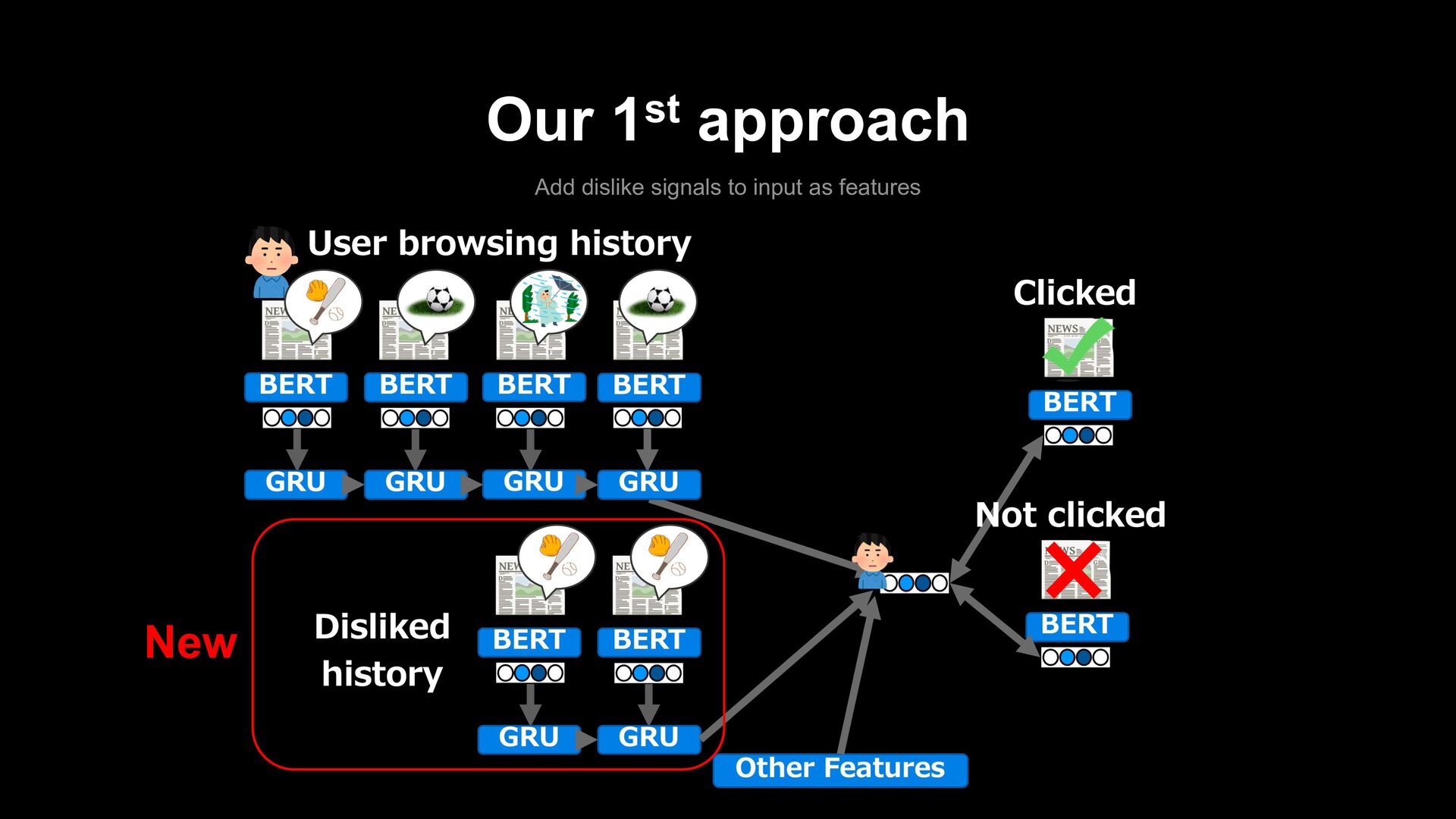
model trains to vectorize user history by GRU-RNN with vectorized articles as inputs. - Click or not click feedbacks are also vectorized, and the model does metric learning between the user vector and them. - In this phase, we optimize GRU and the pooling layer of BERT but freeze transformer layers of BERT due to calculation speed.
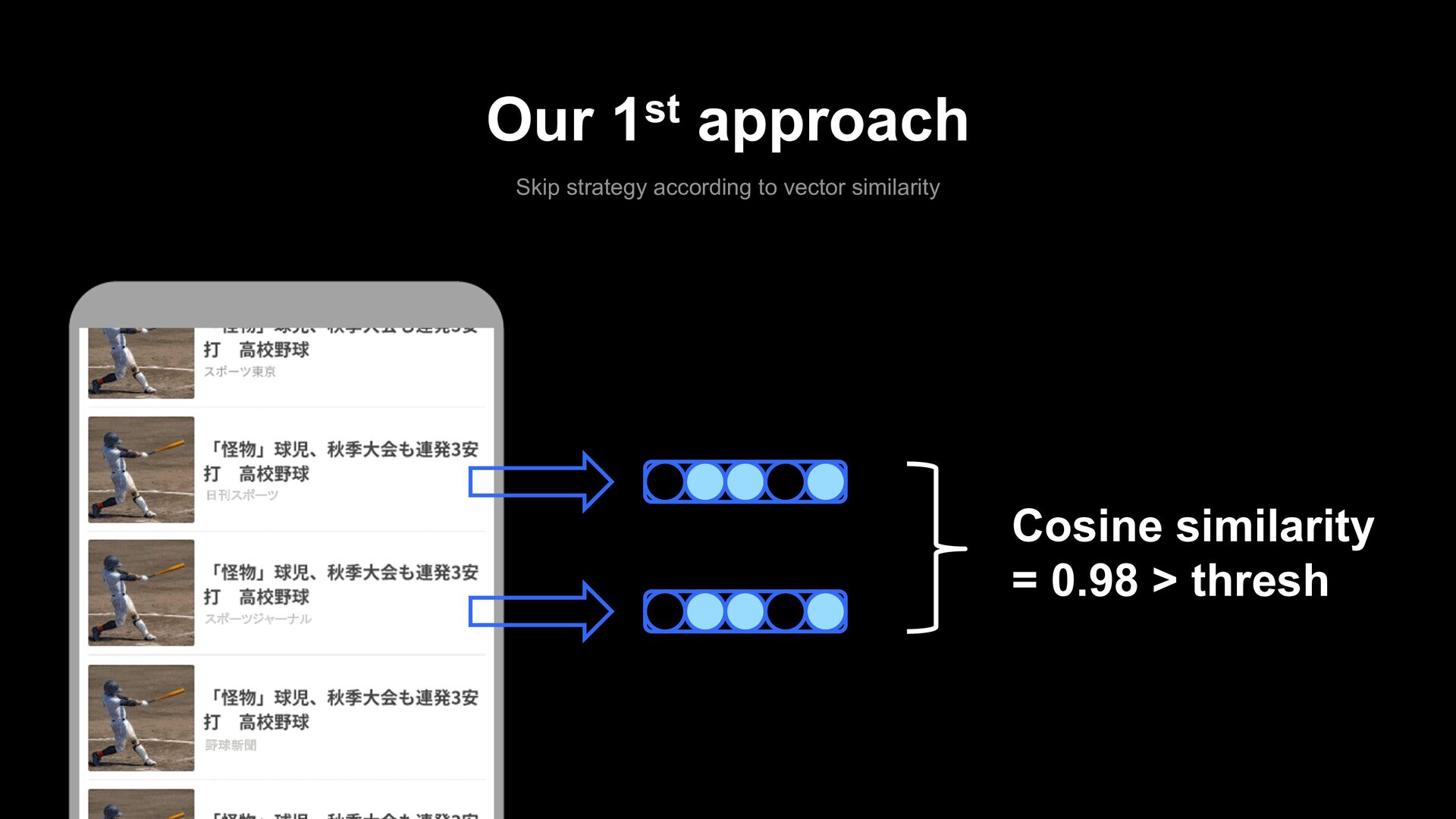
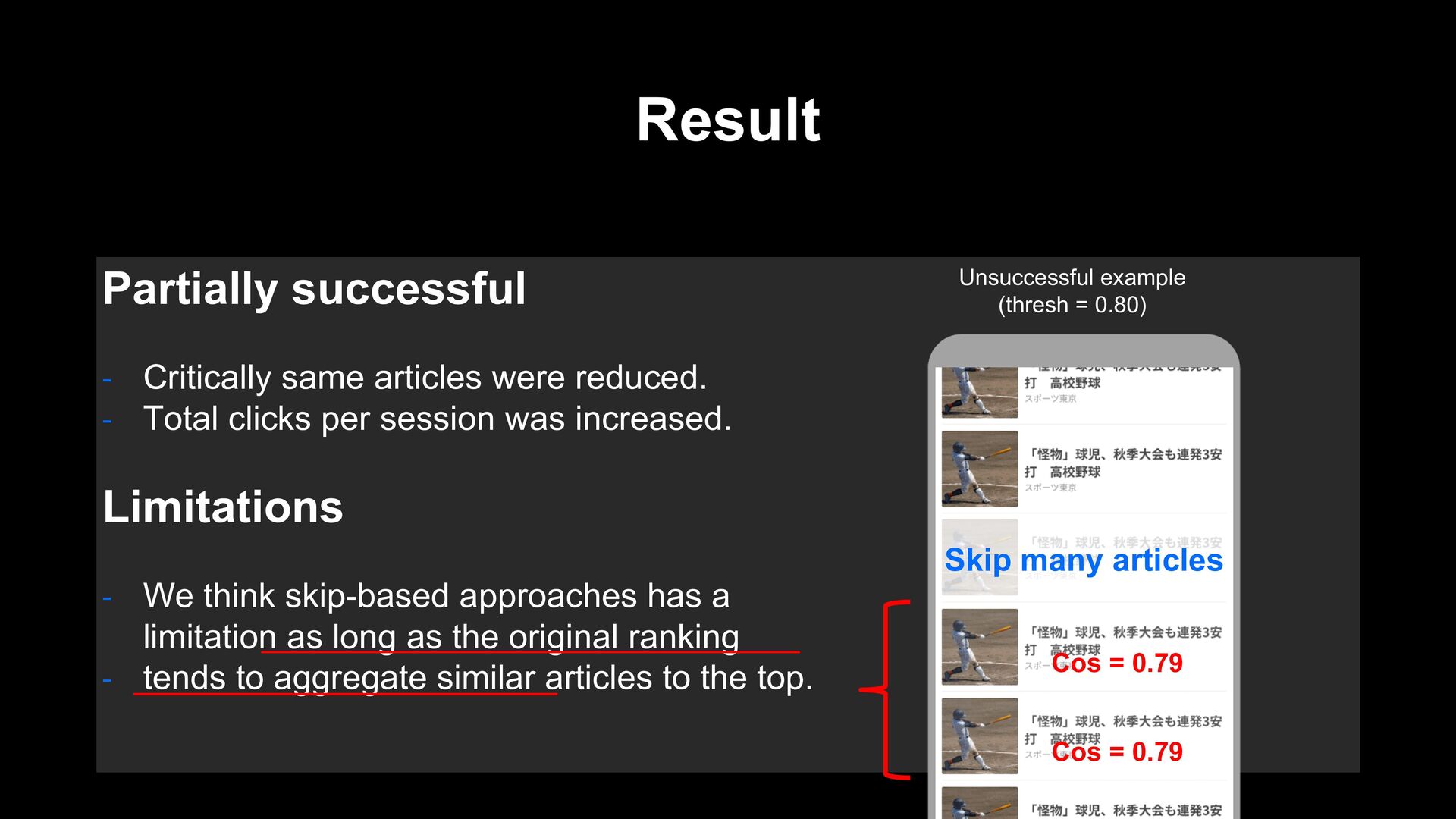
Total clicks per session was increased. Limitations - We think skip-based approaches has a limitation as long as the original ranking - tends to aggregate similar articles to the top. Unsuccessful example (thresh = 0.80) Skip many articles Cos = 0.79 Cos = 0.79
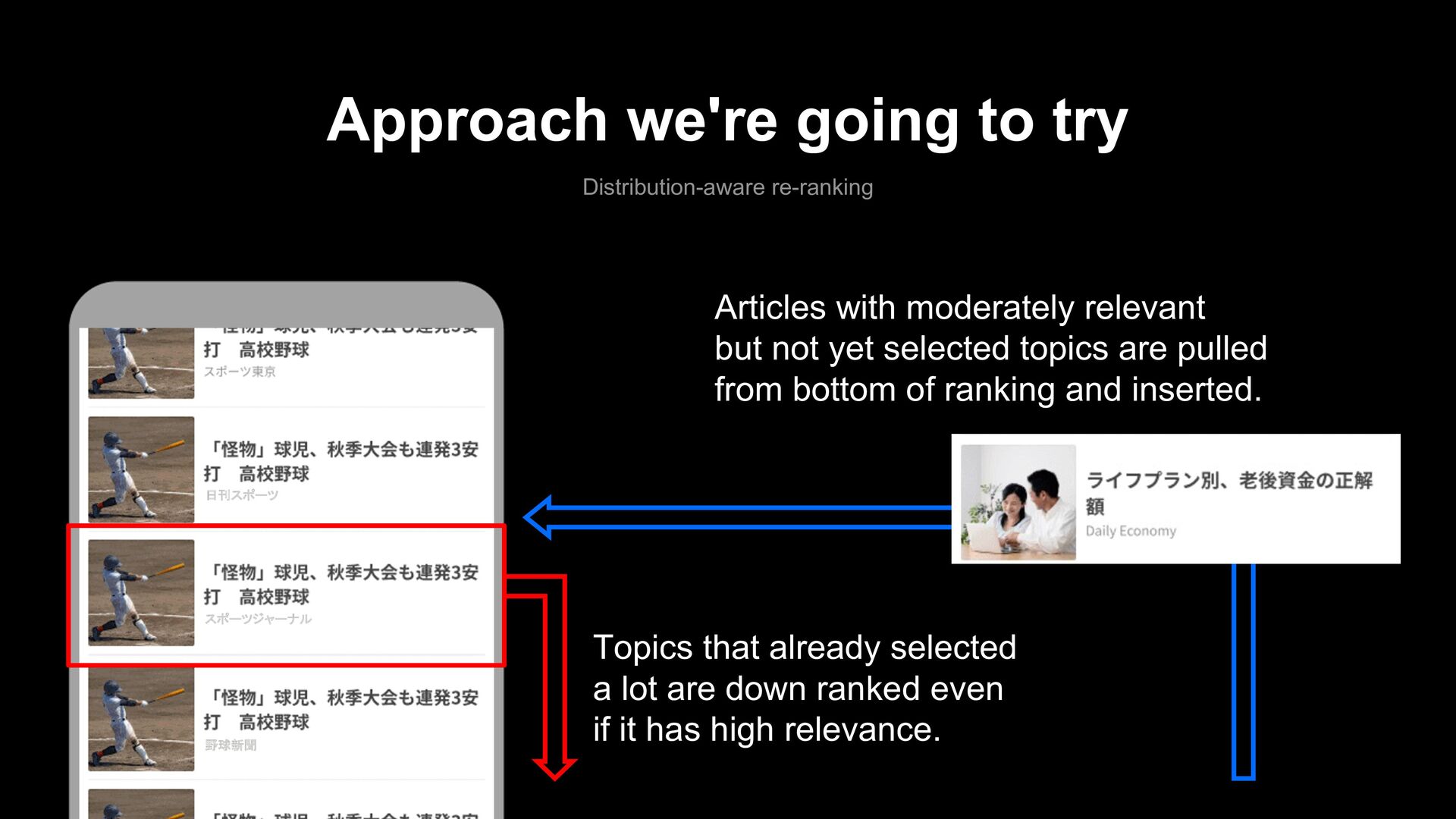
= Relevance(x) – λ KL(p, selected + x) Target topic distribution Distribution of selected articles Penalty term for topic distribution Score of interest to article x
selected a lot are down ranked even if it has high relevance. Articles with moderately relevant but not yet selected topics are pulled from bottom of ranking and inserted. 日刊スポーツ スポーツジャーナル 野球新聞
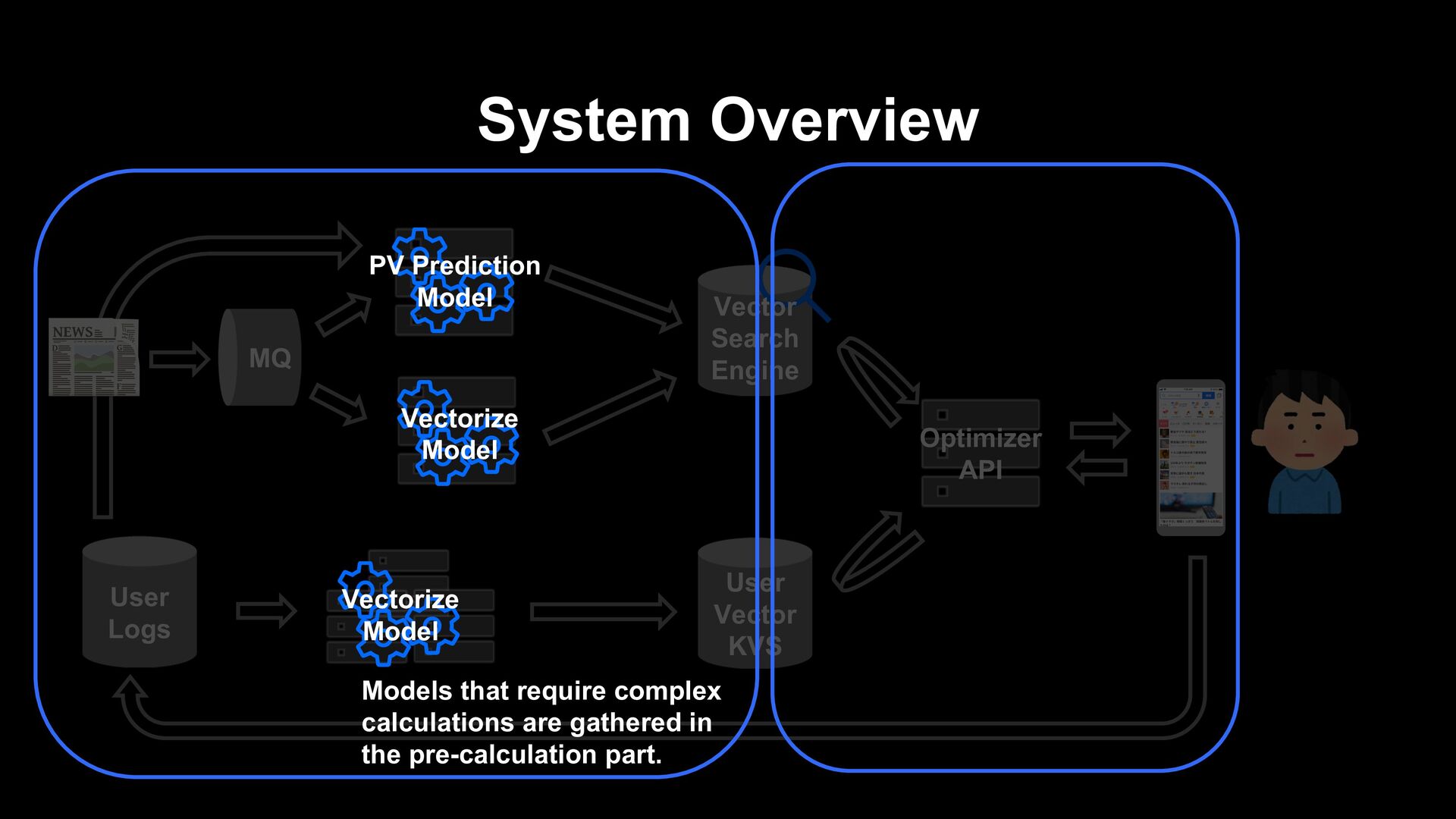
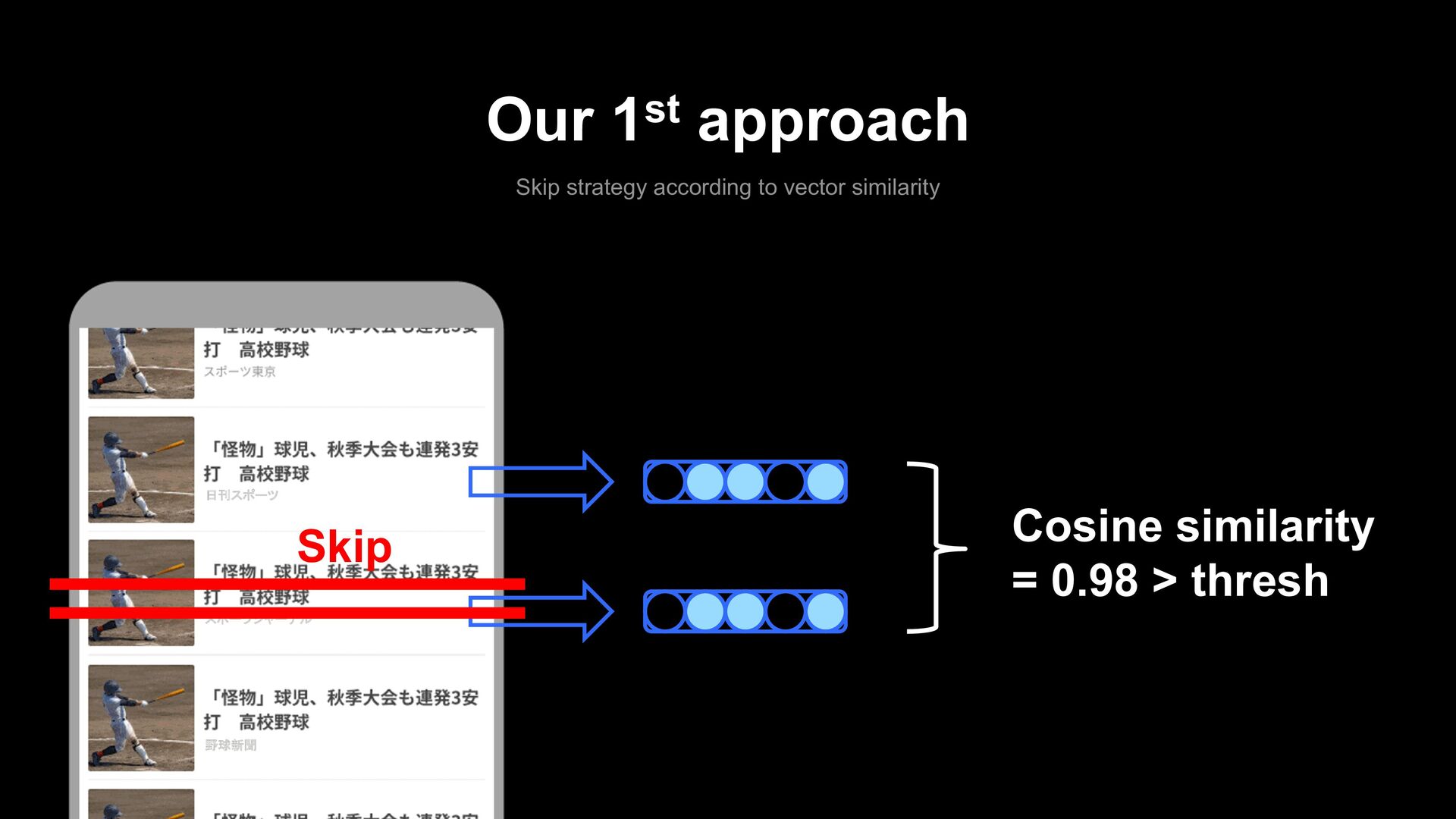
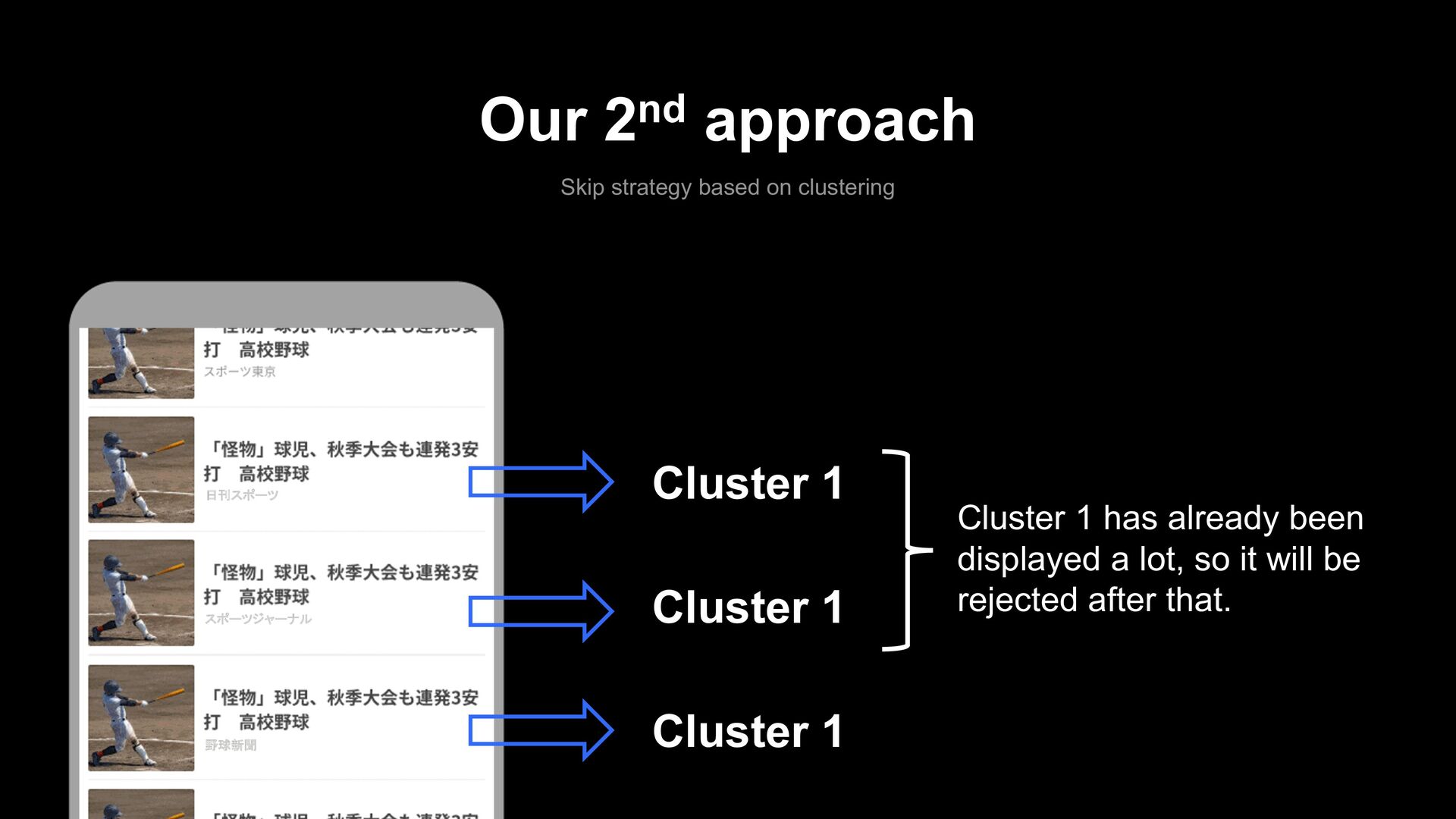
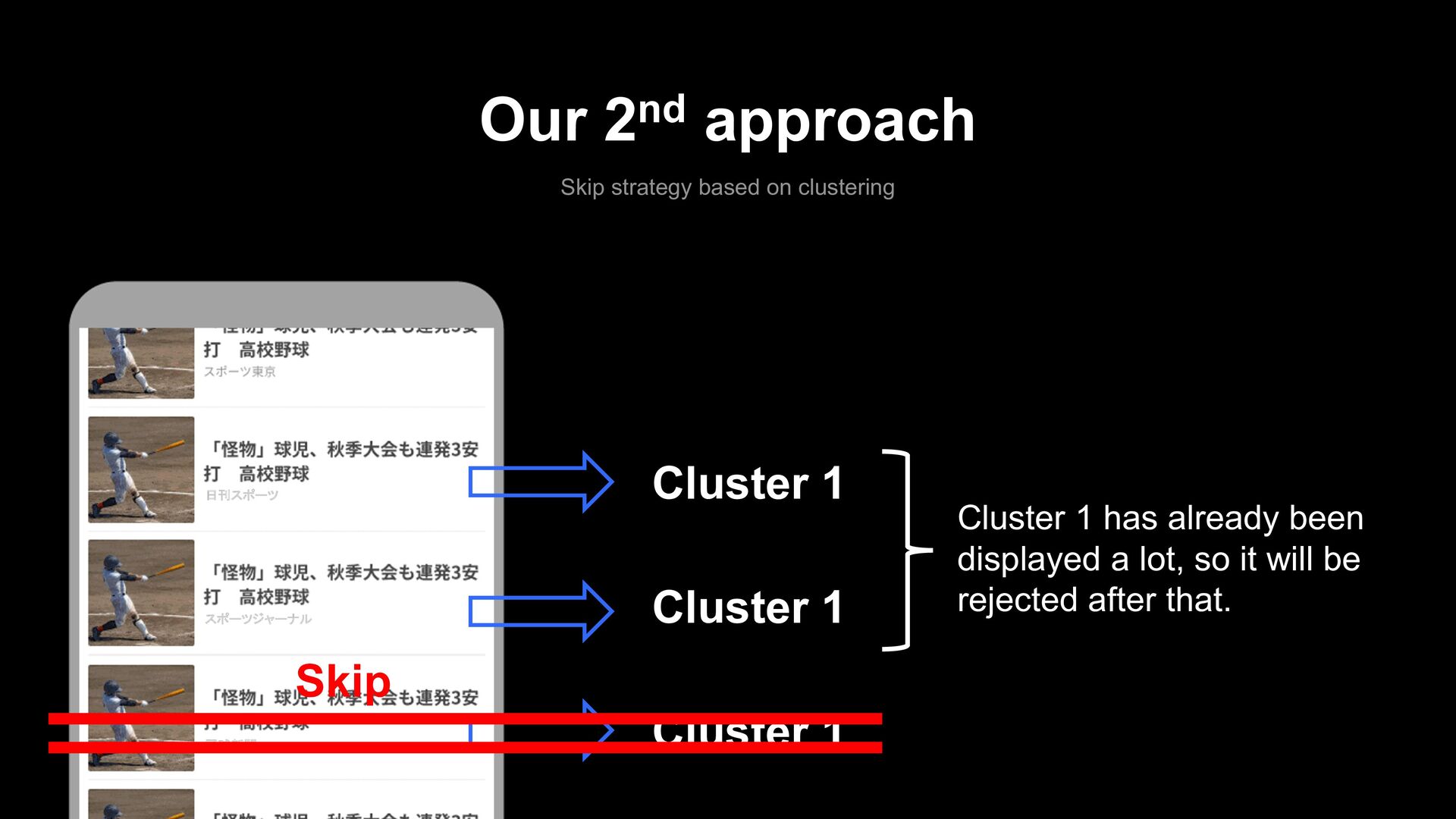
- It requires a lot of computation. - Skip-based approaches require calculating the score only once for each article. - The re-ranking approach requires re-calculating each article's score and sorting them each time one article is selected.
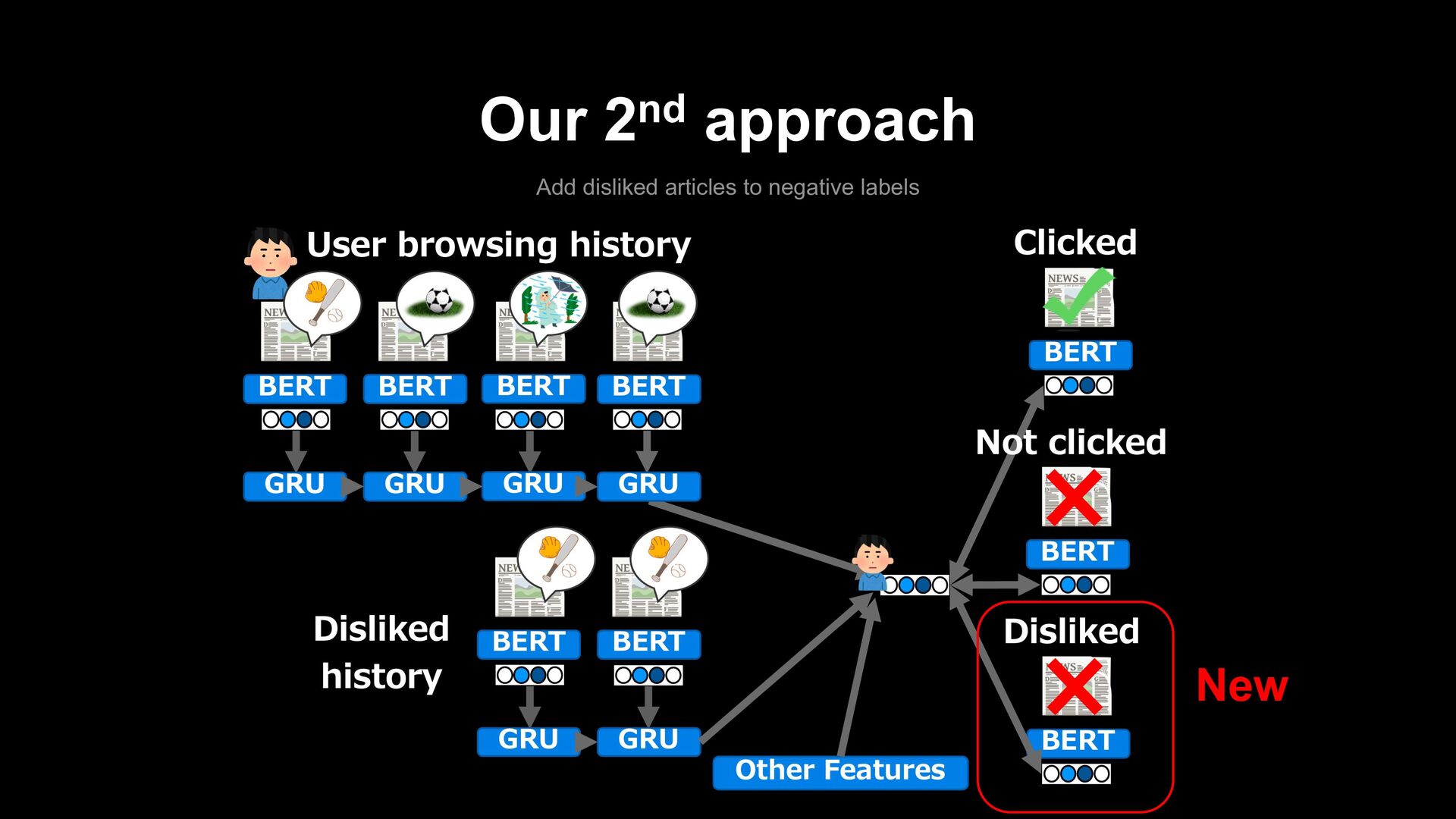
requirements 1. Reduce the recommendation of articles similar to that received the dislike signal in subsequent sessions. 2. Use that signal to improve the overall quality of the recommendations. Dislike feedback … Reduce similar articles ※ This feature has been available in Yahoo News App, but not in Yahoo JAPAN App yet.
+ 2) Requirement 1: Reduce similar articles in subsequent sessions The number of articles of the same genre as the article disliked hardly decreased. The re-recommended rate of the same genre decreased from around 30% to 10%. Requirement 2: Improve the overall quality of the recommendations Contribution to the improvement of quality was limited. Total clicks were decreased.
Increase dislike resolution … Reduce similar article “Similar” is too ambiguous. - He may not be interested in movies. - Or maybe he likes movies but just hates this actress.
Increase dislike resolution … • Reduce about movies • Reduce this actress • Reduce this media “Similar” is too ambiguous. - He may not be interested in movies. - Or maybe he likes movies but just hates this actress.
Realize reduce instead of keep or delete … Assuming you love baseball, the recommendations would look like the left image. You think "I love baseball, but want any other article too", and click "reduce". Then … … 日刊スポーツ スポーツジャーナル 野球新聞 Reduce similar article
Realize reduce instead of keep or delete … Assuming you love baseball, the recommendations would look like the left image. You think "I love baseball, but want any other article too", and click "reduce". Then … Articles about baseball were completely disappeared. …
Realize reduce instead of keep or delete Ranking by interest score does not allow to reduce the frequency of a particular genre without lowering the rank of all articles of that genre. Therefore, we believe that the distribution-aware re-ranking mentioned in the previous section will be necessary also to solve this issue. Reduce 日刊スポーツ スポーツジャーナル 野球新聞
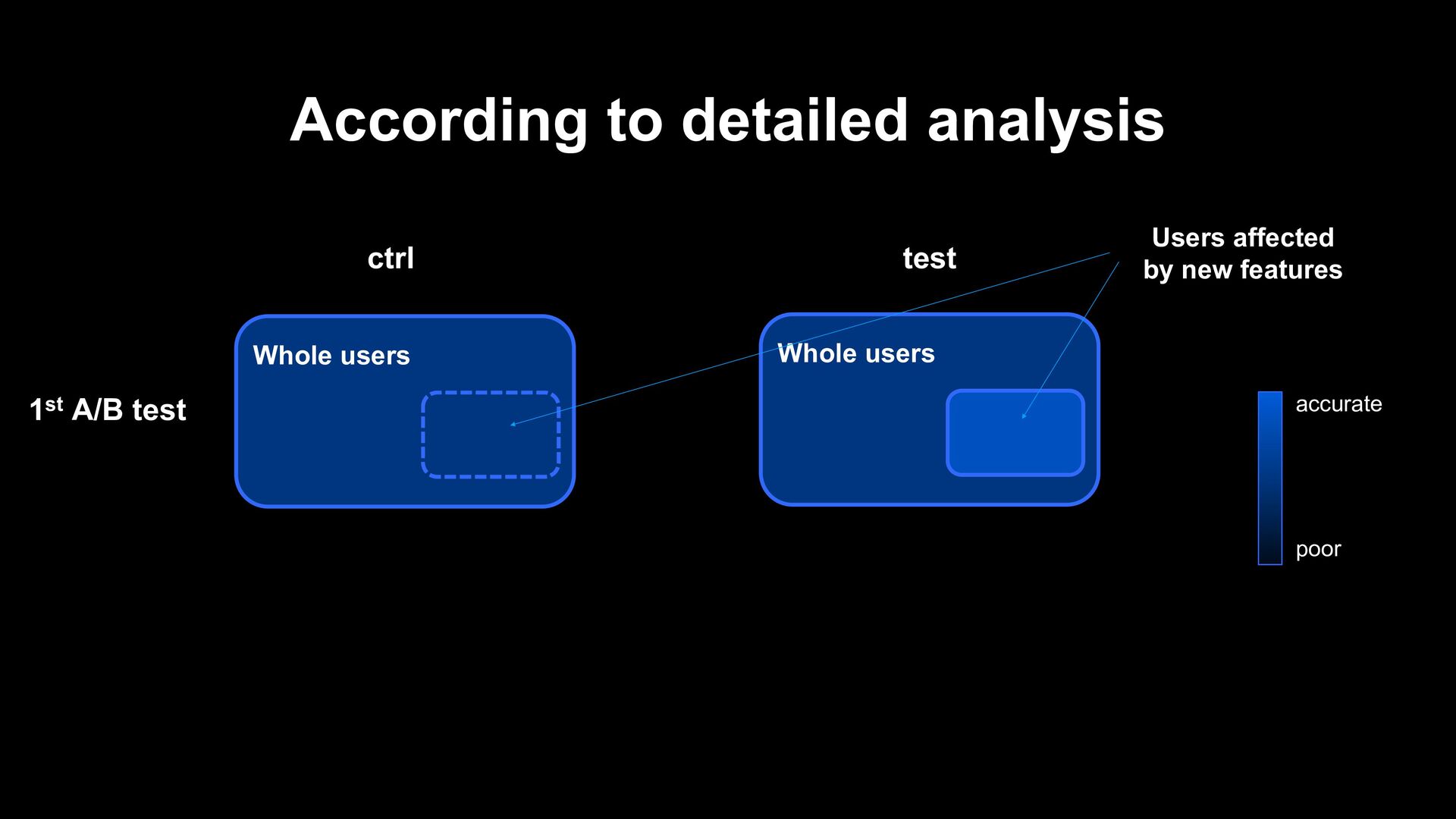
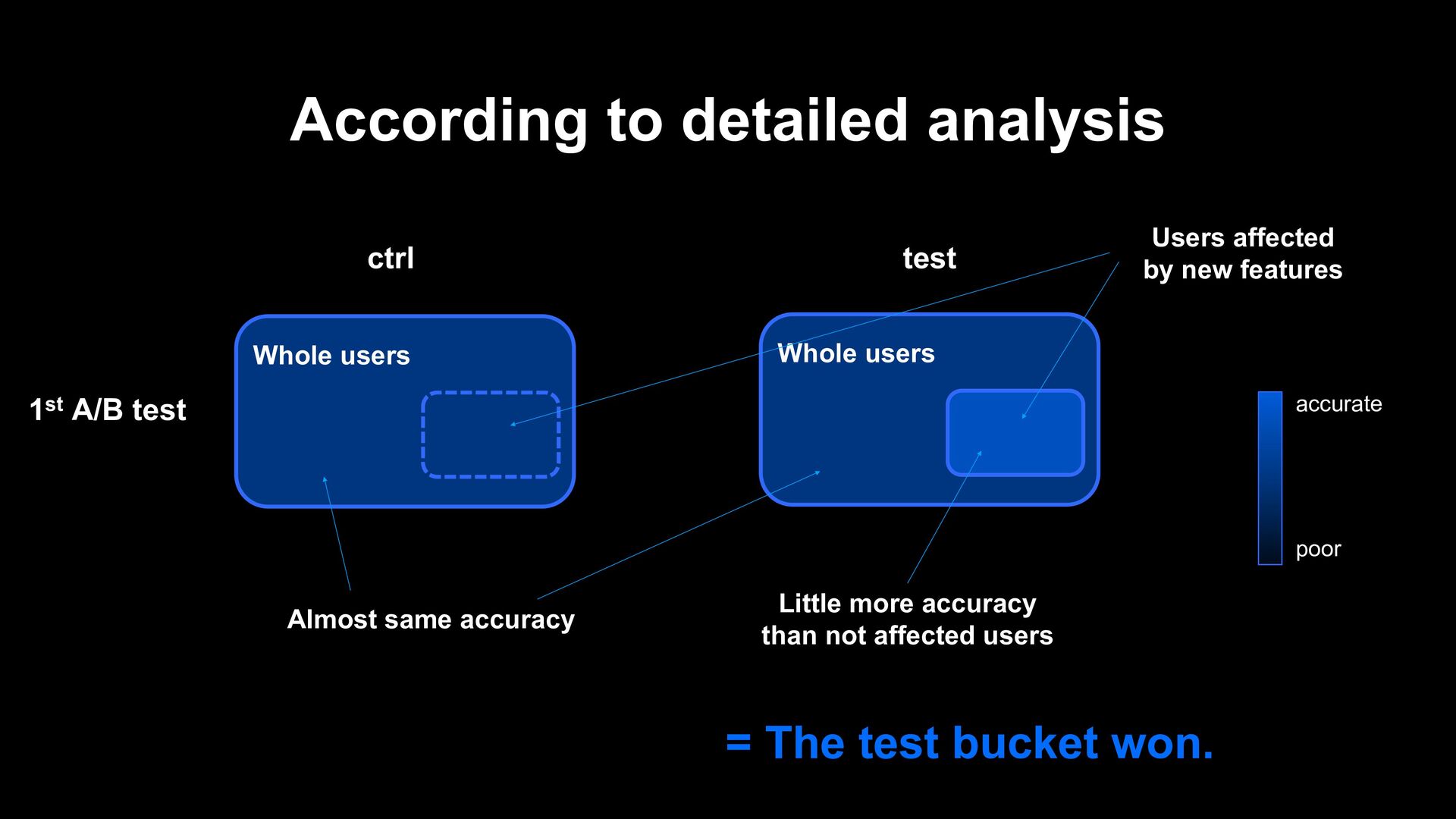
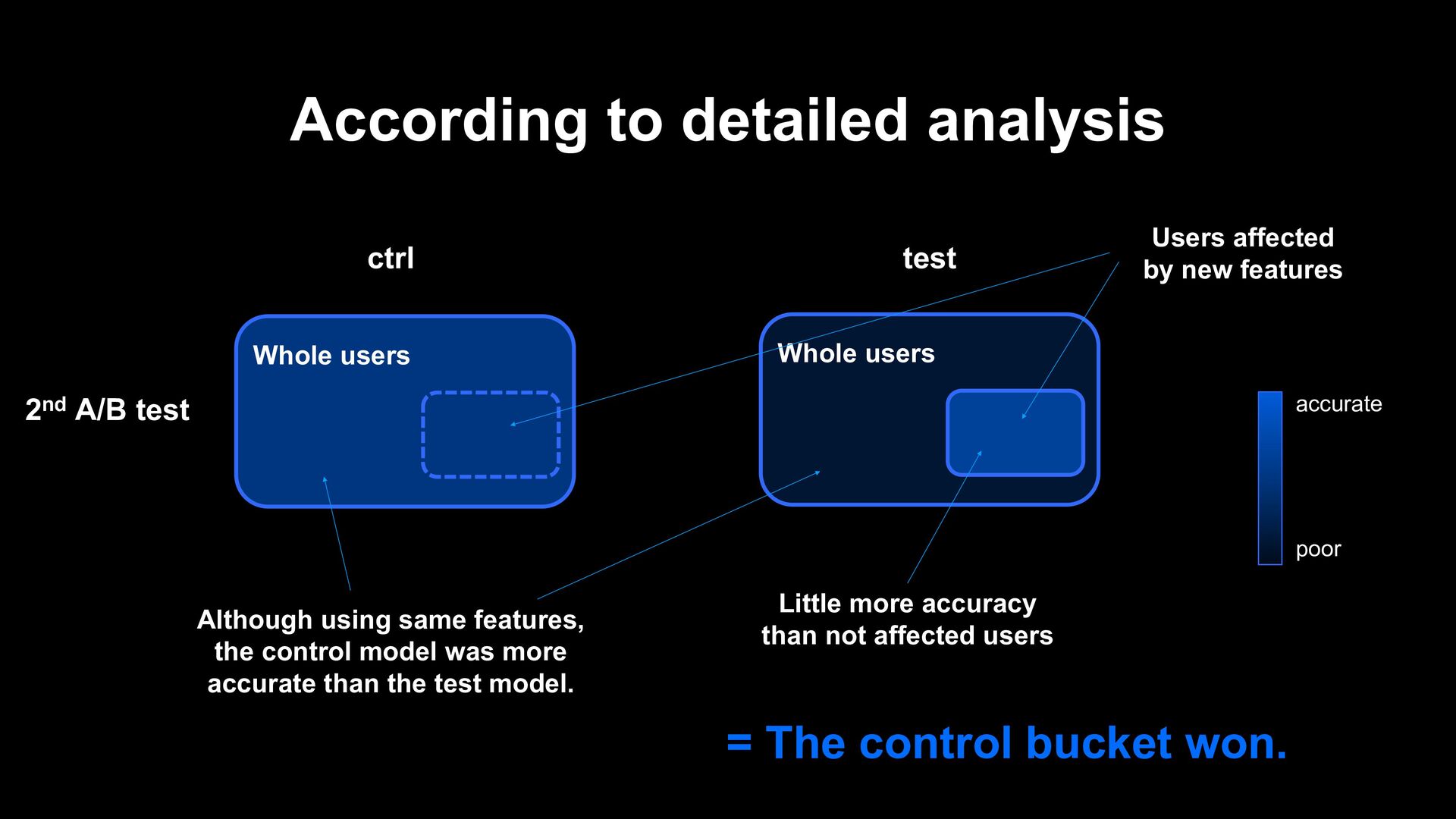
by new features 2nd A/B test ctrl test Although using same features, the control model was more accurate than the test model. Little more accuracy than not affected users = The control bucket won. accurate poor
ctrl test Control Model Test Model ≒ Almost same accuracy except for new features Control Model Test Model 2nd A/B test Re-train by latest training dataset Re-train by latest training dataset with unlucky random seed >
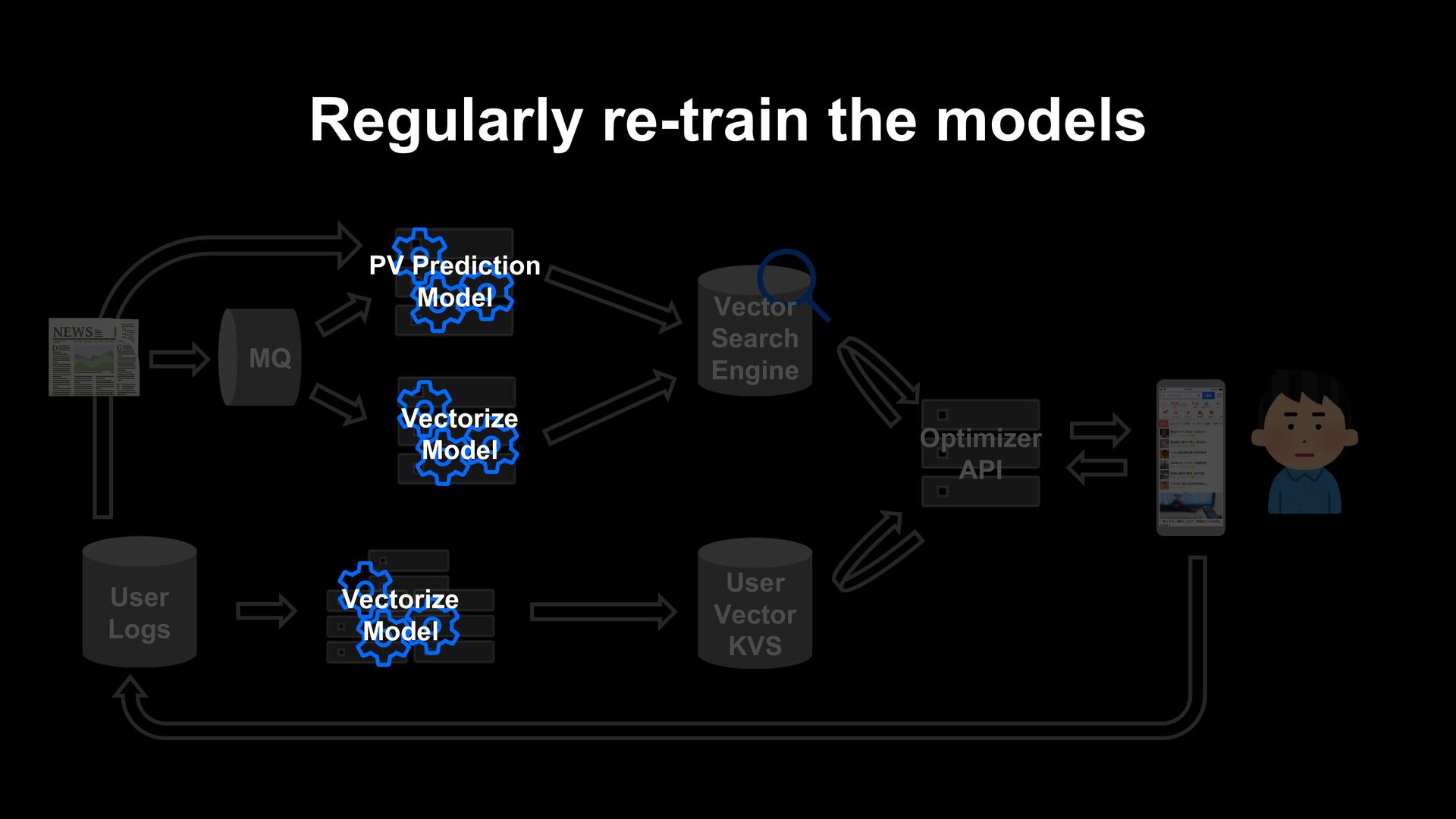
models can be affected by the hit or miss of random numbers used for initialization. • When testing model updates that affect only a small number of users, random numbers can dominate the overall impact of users, even if the added logic is indeed effective. • Since then, we construct the model selection system that train multiple times with different random seeds, even though in regularly automatic re-training.
overview of our news recommendation system. • I explained how to learn our models. • I introduced some recent issues in our systems and how to deal with them. Thanks for listening
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}