We all are more or less used to relational data base systems like MySQL or SQL Server. Over the last 10 years or so, NoSQL DBs like MongoDB have become more popular and have seen traction in certain tech stacks and for certain applications.
An underutilised approach to storing and managing information are wide-column stores like Apache Cassandra. This talk will introduce the concept of wide-column stores and the more general idea of column-oriented data bases and what they’re useful for in the first place.
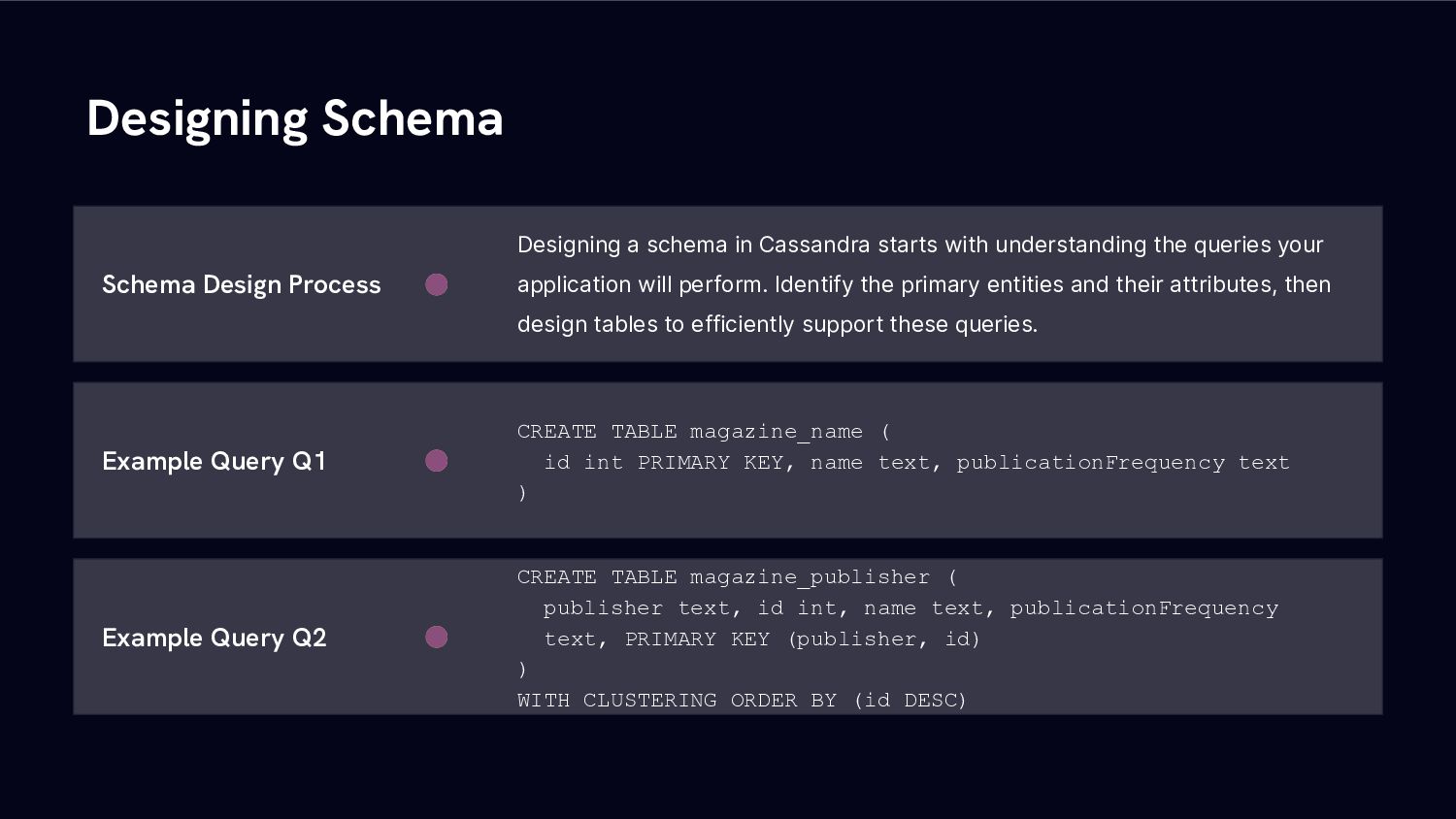
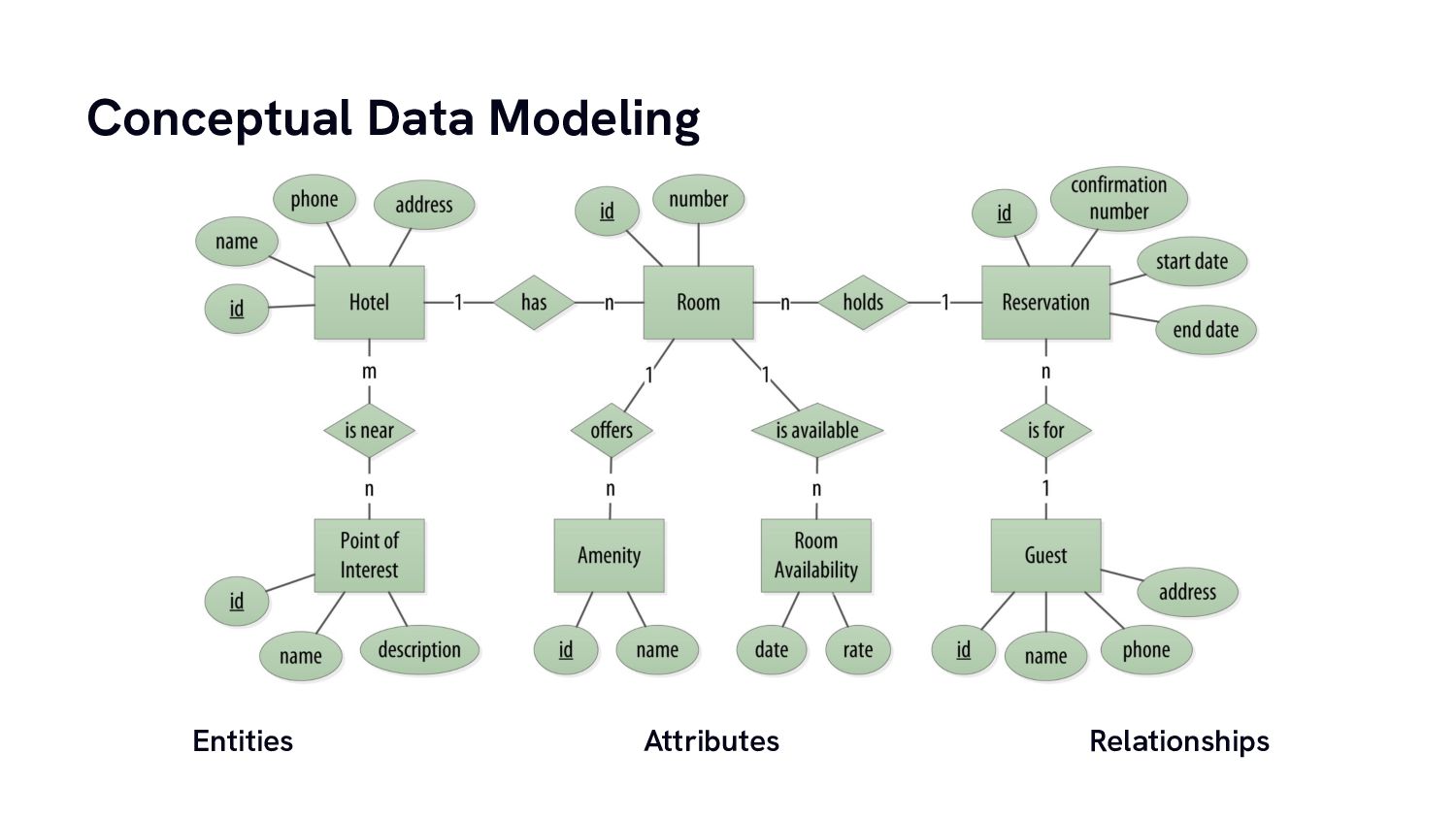
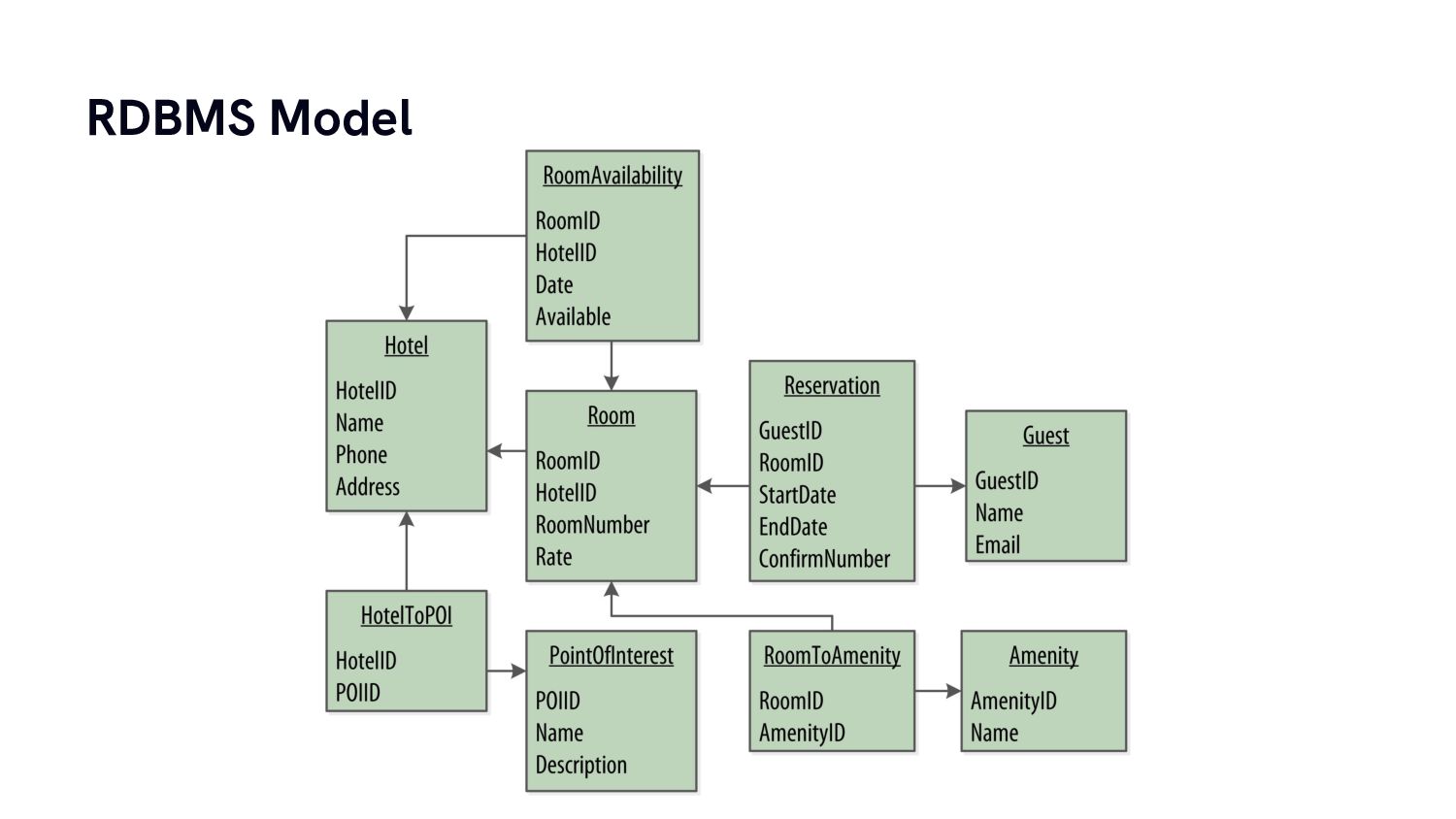
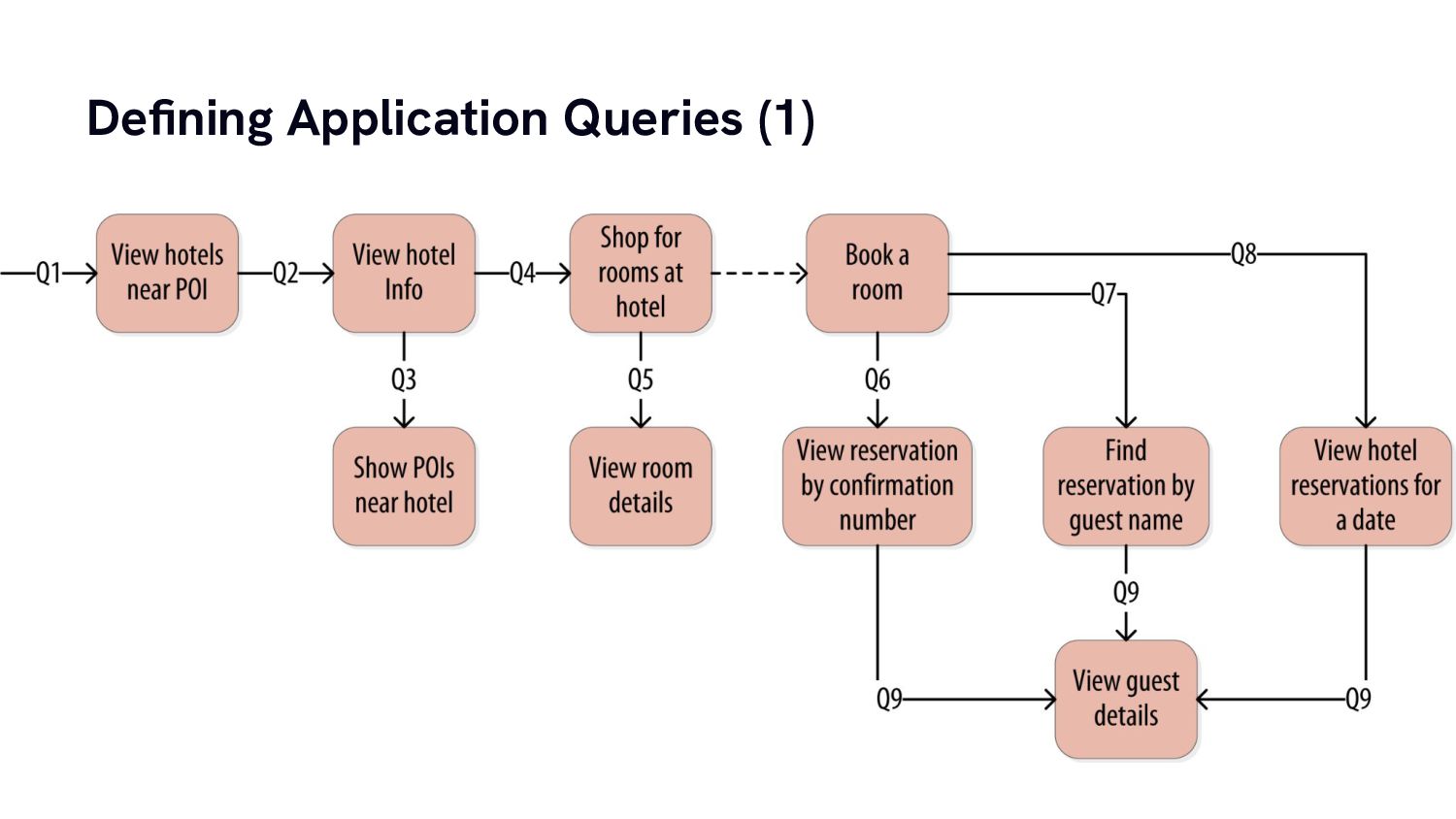
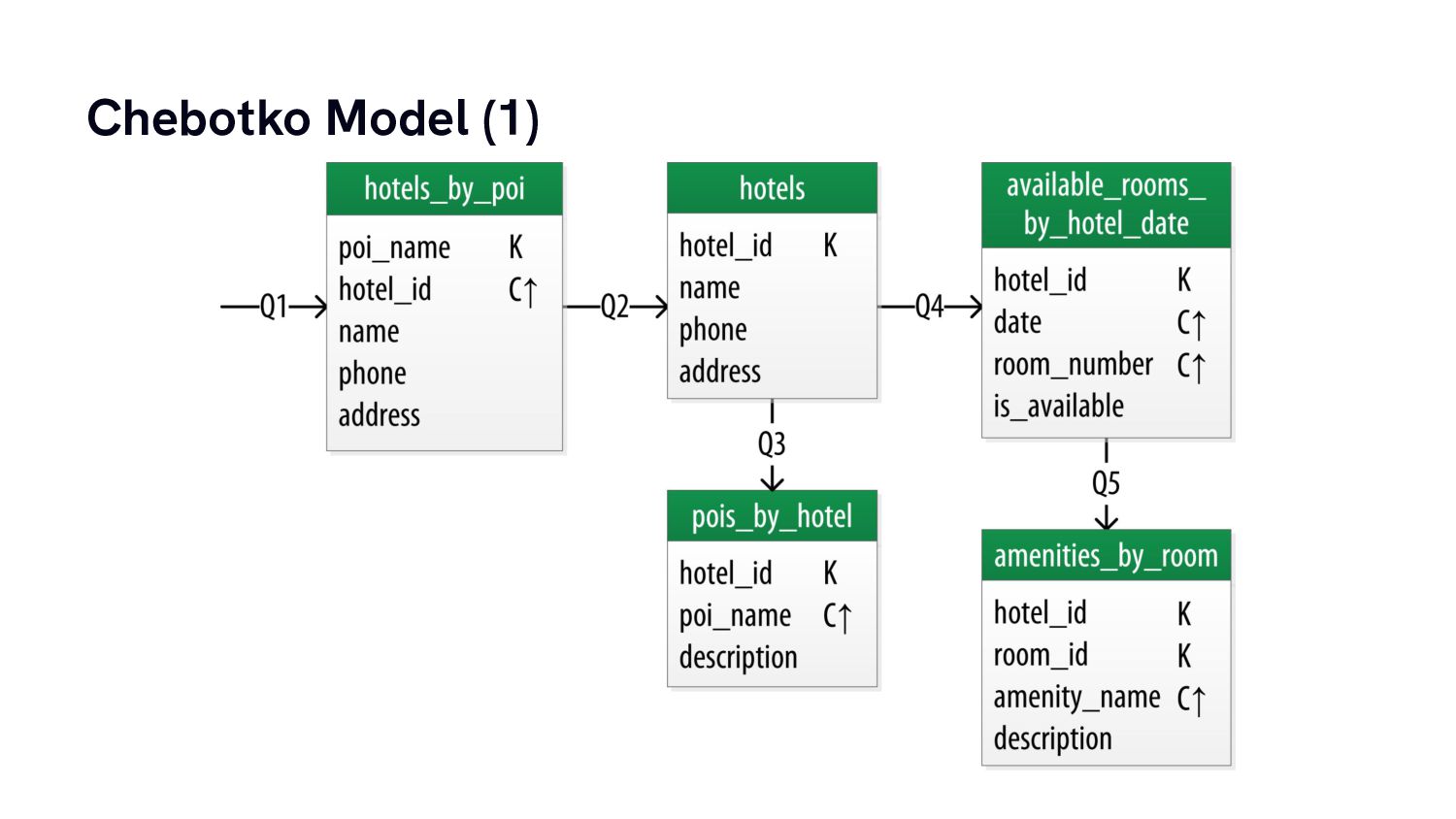
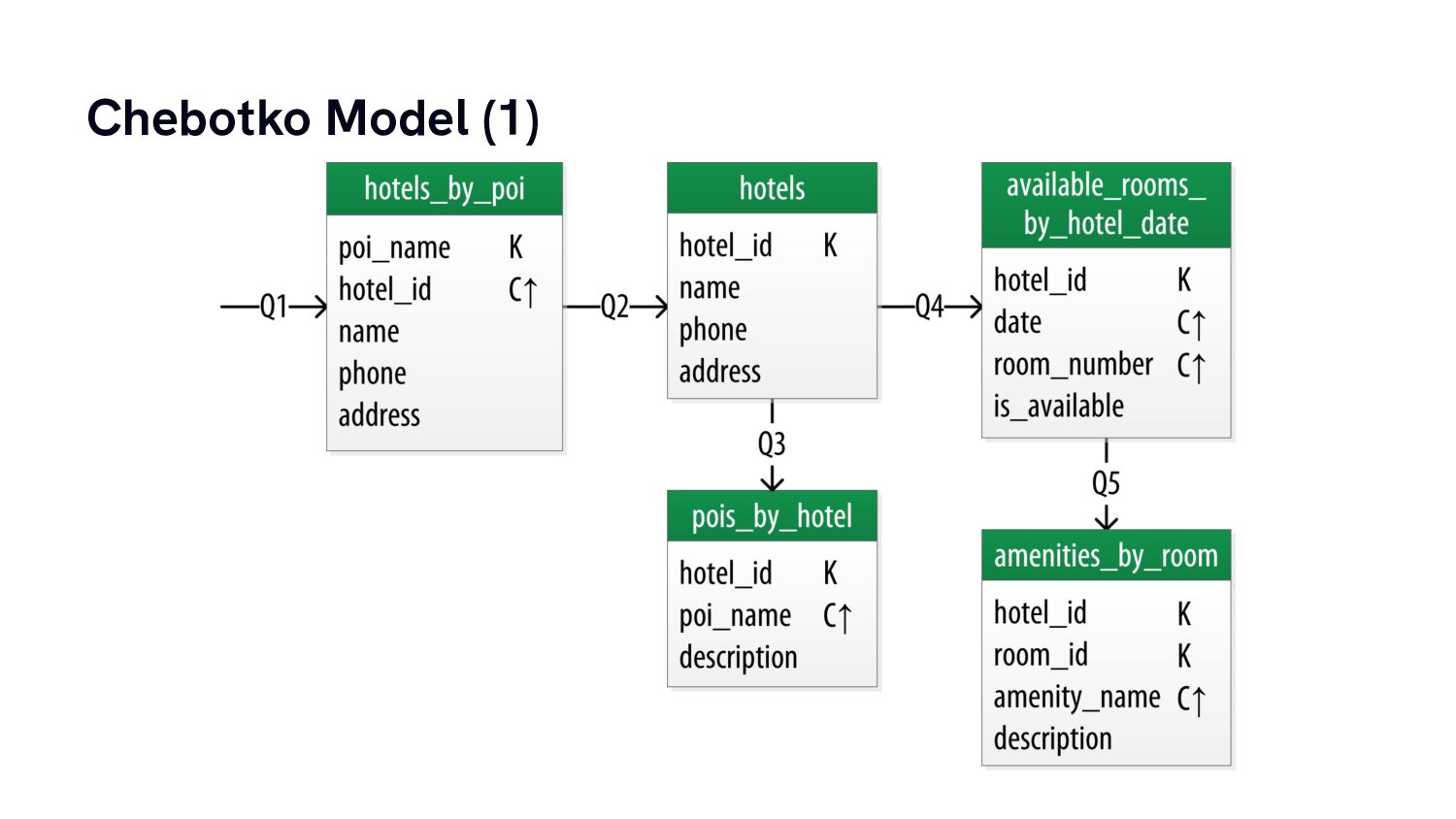
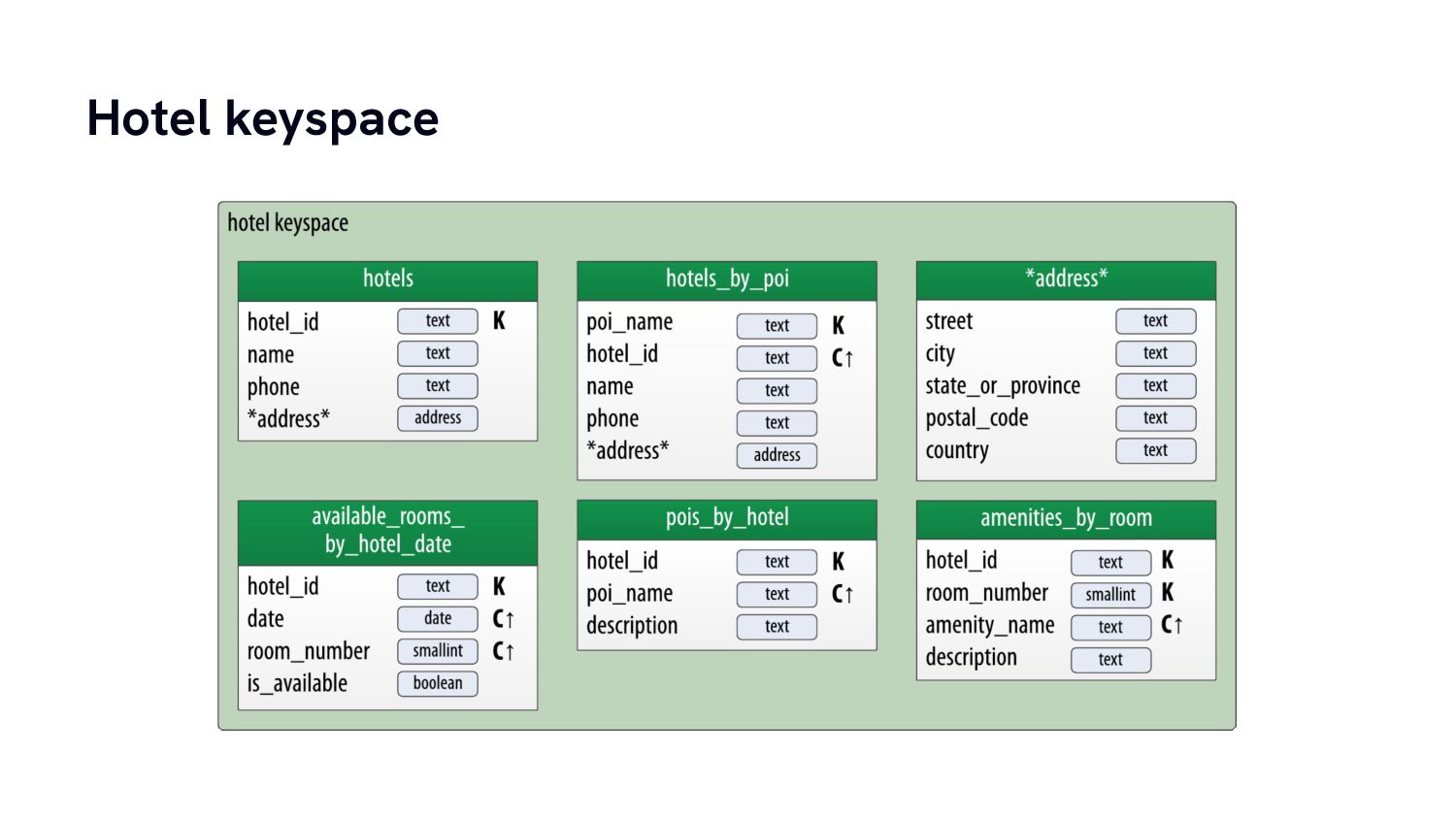
From there we’re going to build a simple data model for a practical use case and have a look at how data modelling for column stores is very different from what we almost intuitively do for traditional relational database systems.
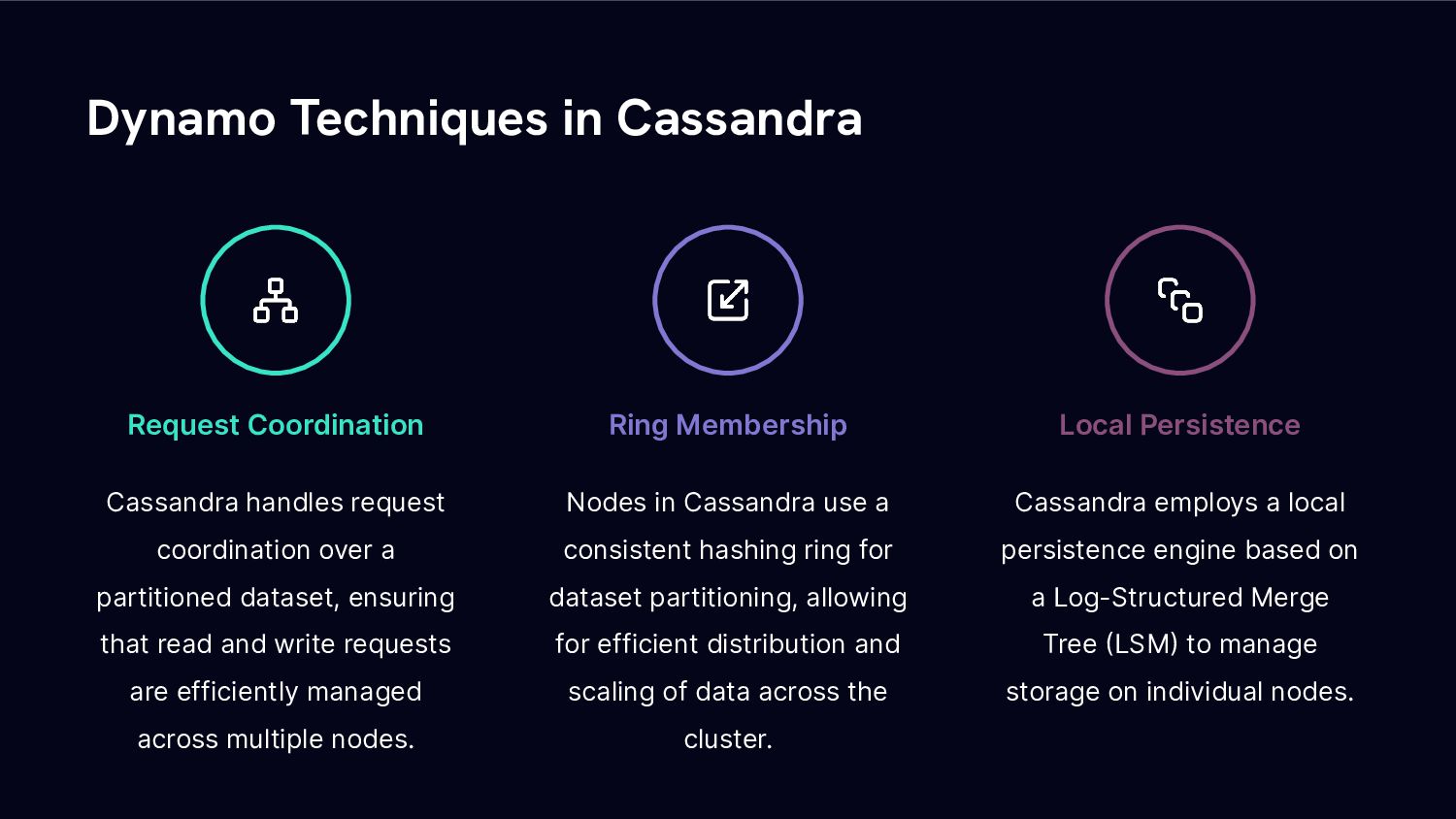
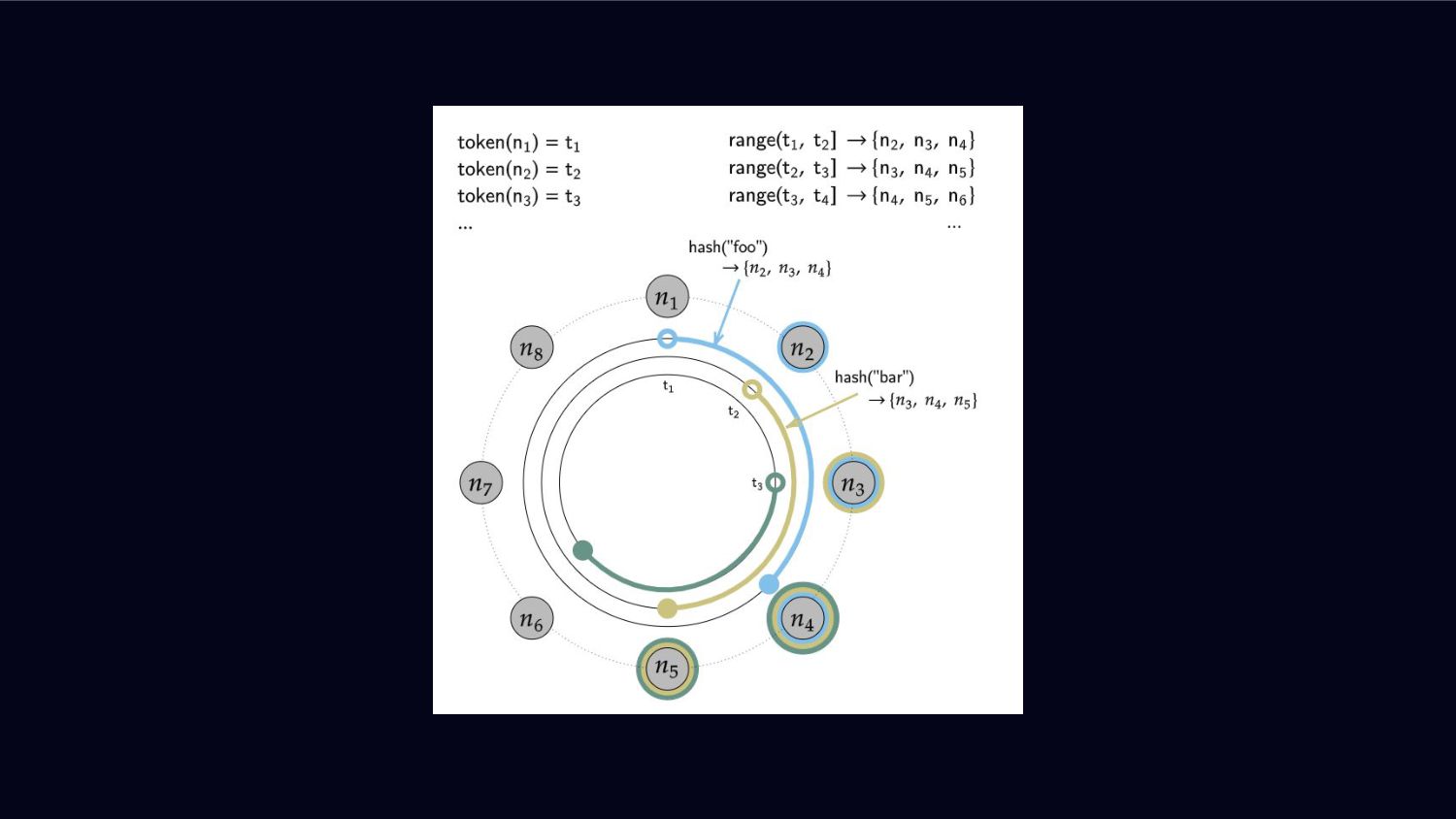
Cassandra is also distributed and highly fault-tolerant on commodity hardware and offers linear scalability and its own query language CQL, so we’re looking into how this works with a ring-based cluster setup and quorum-based availability. Finally - we’re putting all of this together and look at how to use Cassandra with CFML.
At the end of the talk, people will have a better understanding of when, where and how it makes sense to use column stores in their application architectures.
This version of the talk was given at CFCamp Germany 2024 on June 14, 2024.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Get in touch Kai Koenig Email: [email protected] CFML Slack: @Agentk](https://files.speakerdeck.com/presentations/686b75a7779f4317bf116f1032c21395/slide_46.jpg){kind=link}